 AI應用如何不被淘汰?深耕RAG與數據底座是關鍵
AI應用如何不被淘汰?深耕RAG與數據底座是關鍵
截至2025年,生成式AI大模型的能力仍在迅速提升。如果關注這個領域,會發現有不少創業者花大量精力打造的AI應用,但往往很快就被新一代大模型“原生功能”所取代。
這一類應用被歸類是Prompt(提示詞)包裝層應用,這些應用通過設計提示詞調用大模型基礎能力,但沒有構建更深層次業務價值。因為應用的價值主要靠大模型的原始能力,所以很容易被不斷變強的大模型取代。
如何開發出不容易被大模型“抄家”的AI應用?
對此,英特爾技術專家認為,大模型應用開發不應僅僅沿著大模型本身能力的延展,直接基于大模型開發智能體,這樣很容易隨著大模型能力的提升而被淘汰。大模型應用開發要從大模型不擅長或無法克服的點進行切入,如解決數據地基的問題。
目前大模型最明顯的兩個問題都與數據有關。
首當其沖的就是幻覺。大模型本質上是在做概率運算,輸出的內容越多,概率偏差就越大。此外,訓練數據質量也會導致幻覺。而要在短期內徹底消除幻覺問題,則需要根本性的技術變革為前提。
第二,是大模型的知識無法實時更新。大模型預訓練都有固定的時間,可能是幾個月甚至是幾年之前,完全不知道新發生的事情,無法及時更新自己的知識庫。做出的回答也只能基于舊的已知內容。
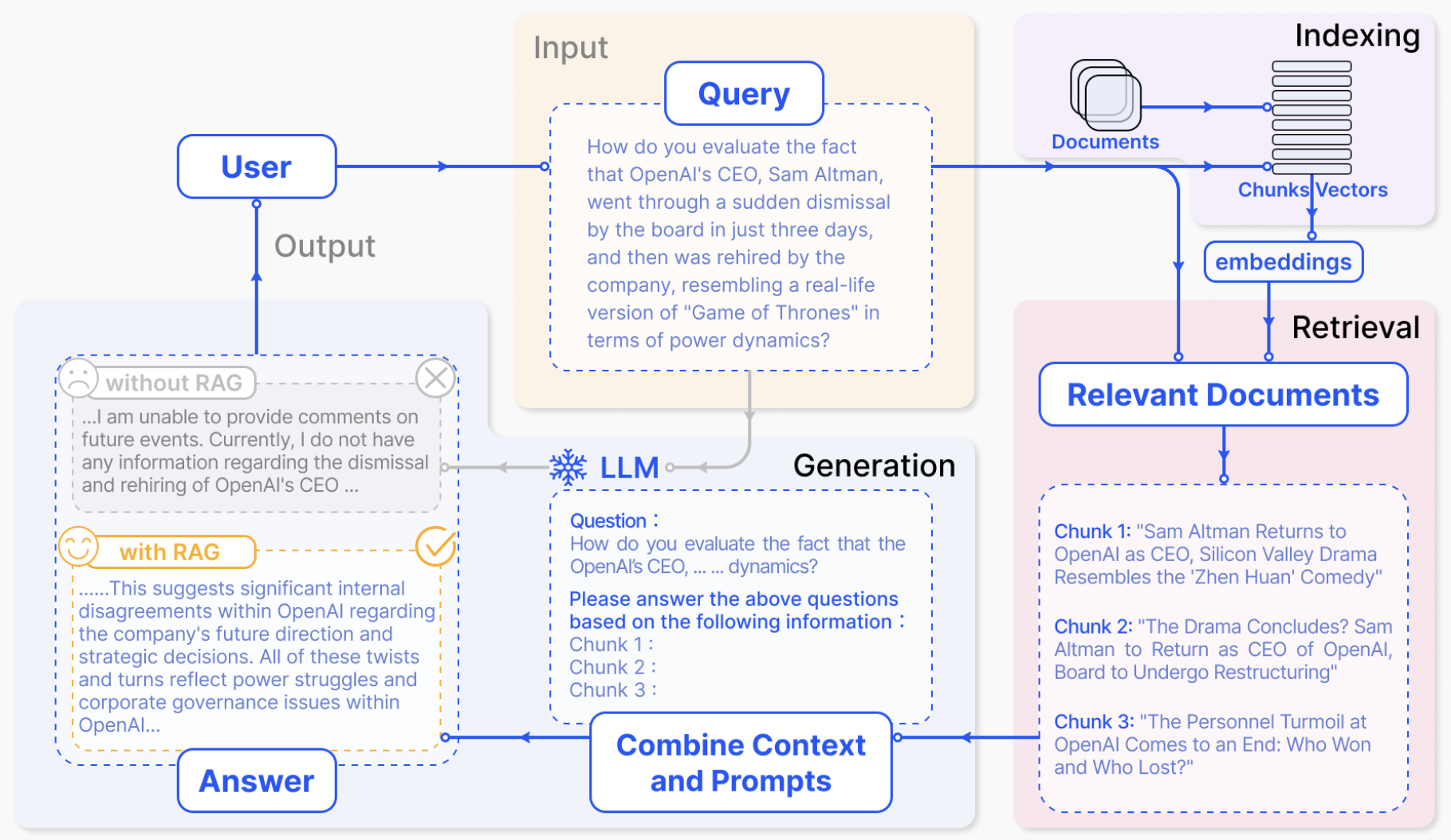
針對這兩大問題,業內達成的共識就是基于RAG(檢索增強生成)構建知識庫,它在預訓練的大模型基礎上連接外部的數據源,所有的任務和回答的內容上下文都從知識庫中提取,然后,由大模型做出回答。
具體操作中,企業需要把內部的文檔資料轉化為機器能讀懂的形式。先對文檔進行切分,然后再進行向量化處理,最后存到向量數據庫里。當用戶提出問題時,問題也被轉成向量,基于這些在向量數據庫里進行檢索,最后根據檢索到的內容生成答復。
在生成答復的時候,召回率和準確率是非常關鍵的指標。召回率看的是,在所有“真正相關”的文檔中,有多少被檢索到了。而準確率Precision看的是,在所有被檢索出來的文檔中,有多少是“真正相關”的。
英特爾專家表示,當看到這些技術細節后,就應該意識到,大模型的效果受到太多因素或環節的影響。比如,負責把文本轉換成向量的Embedding模型的選擇,切分文檔的大小,檢索數據的處理等等都會影響最后生成的結果。
在英特爾專家看來,做大模型開發,直接從智能體開始或許不是最優選。數據基礎上的微小差異,最終效果可能會差出很多。換言之,如果能處理好數據本身,而不只是單純依靠大模型本身的表現,則會創造更多不可替代的價值。
快速上手,在云上構建企業級RAG開發環境
目前,國內外多家大型企業都基于大語言模型和RAG技術構建了企業知識庫,而且很多一線員工都非常認可。鑒于RAG知識庫對企業非常重要,火山引擎推出了支持RAG場景的云主機鏡像。
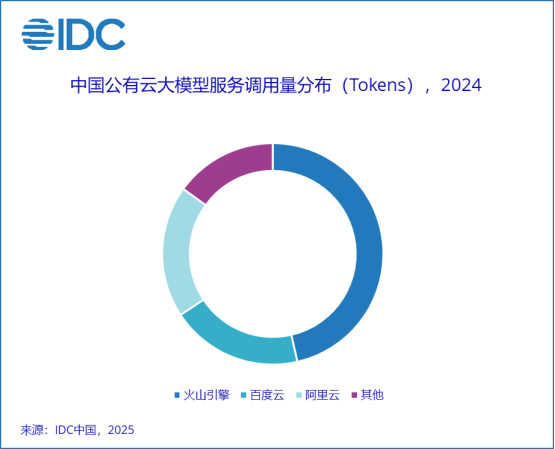
火山引擎在大模型服務領域表現非常亮眼。根據IDC發布的《中國公有云大模型服務市場格局分析,1Q25》報告,火山引擎在2024年中國公有云大模型調用量市場中占據了46.4%的份額,位居第一。
火山引擎不僅有火山方舟這種大模型服務平臺,還有扣子(Coze)這類低代碼AI應用開發平臺,以及HiAgent這樣的企業專屬AI應用創新平臺。新推出的RAG鏡像則是讓普通開發者以更低的門檻,開發出不容易被大模型“抄家”的AI應用。
RAG鏡像中不僅包含Embedding(嵌入式)模塊,還有向量數據庫、Re-rank模型和7B的DeepSeek蒸餾模型,甚至還提供了數據預處理服務,以及處理在線問答服務的模塊和前端頁面,而且所有軟件棧都經過了提前優化。
火山引擎的RAG鏡像作為面向企業的服務,參考了OPEA的架構。OPEA是英特爾在去年發起的開源社區,利用開放架構和模塊化組件的方式,幫助企業構建可擴展的AI應用部署基礎。相比普通的開源架構,火山引擎的鏡像具備更多企業級特性。
很多云廠商也提供了RAG服務,這些服務對普通用戶來說門檻更低,但對于專業開發者而言,這些“黑盒”屏蔽了大量技術細節。而火山引擎的RAG鏡像作為開源方案,讓開發者能夠看到更多底層細節,從多個技術維度進行優化,從而構建起真正的技術壁壘。
DeepSeek爆火之后,很多企業都計劃進行本地部署,市場上出現了很多一體機解決方案,一臺一體機里經常會有8張高性能顯卡,這套方案的成本并不低,在沒有明確業務需求之前,動輒幾十萬的成本投入或許并不明智。
現在,用戶只需要在火山引擎上選擇好虛擬機和鏡像,就能在三分鐘內搭建好一套開發環境,開始各種學習和實踐。為了幫助開發者提升能力,英特爾還準備了一系列課程,幫助大家補齊相關知識,更輕松地邁出從0到1的第一步,打好數據基礎。
大模型應用開發的三要素,硬件平臺是基礎

英特爾專家總結了大模型應用開發的三要素,除了剛才提到的軟件棧和配套的指導課程,硬件環境同樣至關重要。火山引擎基于英特爾至強處理器打造了多種云主機,最近推出的基于英特爾至強6性能核處理器的通用型實例 g4il,非常適合做大模型應用開發。

g4il是火山引擎的第四代通用型實例,其中 “g” 代表通用型,“4” 表示第四代,“i” 代表英特爾CPU平臺。與第三代相比,其整體性能有顯著提升,無論是在數據庫應用、Web應用,還是圖像渲染方面表現都更加出色,而在AI推理方面的優勢更是尤為突出。

得益于集成AMX加速器,英特爾至強6處理器已成為目前最擅長AI推理的x86架構處理器之一。在火山引擎的g4il實例中,用戶可以使用CPU完成AI推理。相比基于GPU的方案,它具備成本更低、資源更容易獲得的優勢,能滿足基本需求。
基于CPU的AI推理方案特別適合用于AI應用的開發和驗證階段。搭配前面提到的火山引擎RAG鏡像,用戶可以在云上快速搭建起一套大模型應用的開發環境,大大降低了對硬件資源的門檻。
而到了生產環節,通常需要采用CPU+GPU的異構計算架構。比如,可以使用帶有AMX的至強CPU來處理Embedding(文本嵌入)、Re-Rank、向量數據庫等輕量級AI負載,讓GPU專注于處理重型AI負載,從而提高資源利用率和整體處理能力。
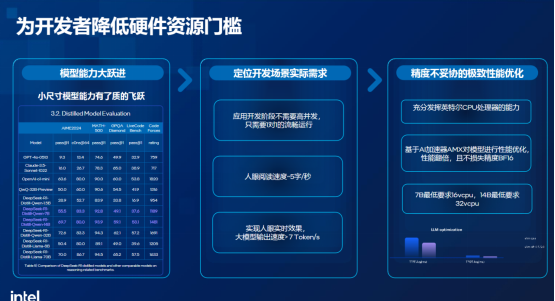
g4il的一大亮點在于:用戶只需選擇一臺配備16 vCPU或32 vCPU的云主機,即使不使用GPU,也能運行參數量為7或14B的DeepSeek蒸餾版模型。值得一提的是,該方案還支持DeepSeek推薦的高精度計算格式BF16,進一步提升推理質量。
小結
在技術快速演進的當下,借助云平臺進行開發,既能降低試錯成本,又能加快創新速度,為企業和開發者提供了更靈活的選擇。更重要的是,通過精細化RAG等技術深耕數據底座,而不只是單純靠巧妙的提示詞,才能打造出不容易被大模型“抄家”的AI應用。
審核編輯 黃宇
-
英特爾
+關注
關注
61文章
10164瀏覽量
173867 -
AI
+關注
關注
87文章
34122瀏覽量
275225 -
大模型
+關注
關注
2文章
3017瀏覽量
3795
發布評論請先 登錄
【「零基礎開發AI Agent」閱讀體驗】+ 入門篇學習
DevEco Studio AI輔助開發工具兩大升級功能 鴻蒙應用開發效率再提升

《AI Agent 應用與項目實戰》閱讀心得3——RAG架構與部署本地知識庫
利用OpenVINO和LlamaIndex工具構建多模態RAG應用

【「基于大模型的RAG應用開發與優化」閱讀體驗】RAG基本概念
【「基于大模型的RAG應用開發與優化」閱讀體驗】+第一章初體驗
【「基于大模型的RAG應用開發與優化」閱讀體驗】+Embedding技術解讀
旋轉測徑儀的底座如何保證穩定性?
RAG的概念及工作原理
Cloudera推出RAG Studio,助力企業快速部署聊天機器人
名單公布!【書籍評測活動NO.52】基于大模型的RAG應用開發與優化
使用OpenVINO和LlamaIndex構建Agentic-RAG系統
英特爾軟硬件構建模塊如何幫助優化RAG應用

TaD+RAG-緩解大模型“幻覺”的組合新療法





 工商網監
工商網監
評論