 一杯奶茶錢如何搞定大模型應用開發?
一杯奶茶錢如何搞定大模型應用開發?
一個很明顯的事實是,AI的進步速度依然很快,而且超出了很多人的預期。
文字創作方面,Claude 3.7 Sonnet這樣的大模型已經能夠應付大多數場景下的寫作需求,不僅輸出質量穩定,文筆也十分簡潔;而在圖片生成領域,GPT-4o對宮崎駿畫風的“神還原”則更讓人印象深刻。事實上,只要在提示詞上稍微下點功夫,AI完全可以應對部分內容生成的工作,用于有效提高生產力。
當然,在其他能力方面,AI的進步也同樣明顯,特別是在編程領域。
先是Gemini 2.5 Pro (I/O edition)以王者之姿登頂編程排行榜,后有云端AI編程智能體Codex半小時完成數天軟件工程任務,甚至連GitHub也在最近推出了Copilot AI代理,用來提升開發者的工作效率與代碼產出質量。
“人人都是開發者”的時代似乎馬上就要到來,但對開發者來說,這顯然不是什么好消息。
如何確保自己不被替代,在AI時代不被行業所拋棄,是一個不得不考慮的重要問題。
最直接的辦法是“打不過就加入”,大模型潛力固然很強,但一般不會單獨發揮作用,反而是和各種應用相結合才能在各種場景中落地,從這個角度來看,學習大模型應用開發是一個提升自我的有效途徑。
然而,極高的算力門檻、復雜的技術棧以及缺乏完整的能力提升路徑則成為了擺在大多數人面前的致命問題。
正是在這樣的背景下,英特爾攜手火山引擎團隊,圍繞基于英特爾至強6性能核的火山引擎第四代計算實例g4il展開了一系列工作,讓“一杯奶茶錢啟動大模型應用開發”成為了可能。
CPU: AI推理的“瑞士軍刀”
本地部署大模型,進行AI應用開發是一個好選擇嗎?是,也不是。
對企業來說,從數據隱私、響應速度等方面來看,本地部署能夠提供更穩定和可靠的計算能力,避免可能存在的網絡波動或服務中斷等影響,但伴隨而來的還有高昂的成本。
而從個人角度出發,更易獲得、支持快速部署且計費方式靈活的云服務,無疑是更適合應用開發的選擇。
這也讓英特爾與火山引擎多年來圍繞IaaS進行的深度合作變得更有意義。
作為最基礎的資源層,IaaS涵蓋了非常廣泛的場景和各種各樣的虛擬機云實例,包括通用型、本地盤、高主頻、突發/共享、網絡增強、內存增強、安全增強等等,火山引擎第四代通用型實例g4il正是在這樣的背景之下誕生的。
與前三代類似,第四代實例不僅實現了包括數據庫應用、Web應用、圖像渲染能力在內的通用性能提升,還實現了AI性能的顯著增強。

這實際上有些反常識,要知道在過去幾年里,很多人都認為CPU更適合通用算力,而不適合AI算力。但嚴格來說,這個看法并不完全準確,一個完整的AI工程可以劃分為數據收集、模型選型、推理、訓練、部署維護和迭代優化等各個步驟,每個步驟對算力的要求都有所不同,盡管GPU更擅長處理大量并行任務,在執行計算密集型任務時表現地更出色,但在進行AI推理時,如何比較CPU和GPU的性能差異其實一直缺乏一個明確的答案。
英特爾技術專家表示,從本質上來說,CPU可以理解為一把能夠執行多種任務的“瑞士軍刀”,特別是英特爾至強處理器在AMX加速器的賦能之下,在矩陣運算能力方面也有了顯著提升,特別適合資源有限、推理規模較小的開發驗證場景。

除此之外,目前業界普遍采用CPU和GPU混合推理的異構計算方式,具體來說,在開發驗證階段會以低成本易獲取的CPU為主,而在生產部署階段則會使用GPU進行大規模的推理運算,二者各自發揮優勢,協同工作,而不是相互替代的關系。
換句話說,CPU在AI時代仍然有很大的舞臺,特別是在大模型應用開發方面。
大模型應用開發三要素,缺一不可
當然,大模型開發對普通開發者來說也并非易事,一是大模型領域技術更新極快,RAG、MCP、A2A等新名詞層出不窮,讓開發者望而卻步;二是不知從何入手,缺乏具體的啟動策略;三是沒有系統性的學習支持,難以實現能力的階段性提升。
這也就引申出了大模型應用開發的三要素:第一是硬件環境,用于驗證和練習;第二是軟件棧,需要主流的軟件棧支持;第三則是由淺入深的指導課程,不僅能夠運行,更要深度理解,真正實現能力的進階。而英特爾與火山引擎合作的初衷,就是為開發者們打造一把低門檻的梯子,幫助更多人邁出跨越的第一步。

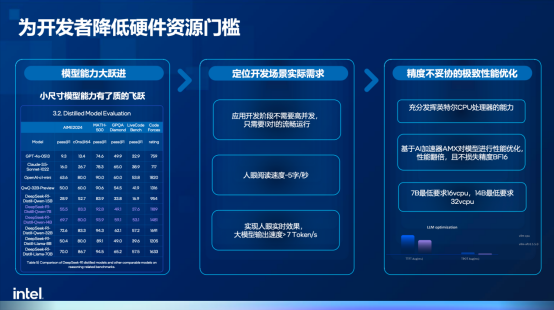
硬件方面,基于英特爾至強6處理器的第四代實例g4il在AMX加速器的賦能下擁有了更強的AI推理性能,據英特爾技術專家透露,基于CPU內置的AI加速器和軟硬件協同優化,可以做到在一個云實例中,僅使用16vCPU或32vCPU即可部署和運行7B或14B的大模型,而16vCPU在火山引擎官網的定價僅僅只有3.8元/小時,開發者可以通過極低的成本開啟大模型應用開發實踐,更關鍵的是,與市面上常見的4bit量化不同,該方案采用了BF16精度,可以在性能提升的同時最大化保留精度。
鏡像則基于英特爾開源社區OPEA(Open Platform for Enterprise AI)所構建,通過開放架構和組件式模塊化的架構,開發者可以通過“搭積木”的方式打造可擴展的AI應用部署基礎。此外,由于社區中積累了大量經過預先驗證的、優化的開源應用范例,英特爾也將這些范例和軟件棧打包成了虛擬機鏡像,開發者可以通過一鍵部署的方式快速搭建硬件和軟件環境。
為了能讓開發者從核心基礎開始循序漸進掌握大模型應用開發的相關知識,英特爾也和火山引擎共同打造了免費的實操課程,內容涵蓋基礎環境搭建、代碼開發環境配置、模型調優、性能優化等各個環節,旨在幫助基礎薄弱的開發者補齊知識儲備,理解技術原理,并通過實際操作來實現個人能力的提升。

英特爾技術專家表示,通過整套的課程,普通開發者能夠更加熟悉、更加了解大模型,也能實現對大模型的“祛魅”。
RAG實踐加速大模型應用落地
大模型是萬能的嗎?顯然不是。時至今日,大模型在數學能力的方面依然存疑,這是由大模型本身的架構所決定的,本質上講,大模型并沒有真正的記憶力,也無法主動更新知識庫,所有的輸出結果都是根據自身的參數來計算,這會導致兩個主要問題。
首先是幻覺。大模型的輸出內容基于概率,且隨著輸出內容長度的增加,概率偏差會逐漸累積,可能導致大模型產生幻覺,完全依賴自身記憶參數。這種幻覺在短期內難以消除,除非AI或大模型的計算范式發生顛覆性變化。
其次是大模型無法獲取知識更新。由于預訓練過程投喂的數據集是固定的,大模型并沒有能力預知未來發生的新變化。
正是因為這兩個缺陷的存在,當前幾乎所有的大模型應用都會強調,大模型的“記憶”需要外部數據源或者數據庫進行對接,來構建知識庫以更新或補充知識。所有任務和問答內容的上下文都要從知識庫中提取,然后由大模型輸出,因此,知識庫是大模型應用開發中非常重要的核心基礎。
此外,大模型效果不穩定的情況也很大程度上取決于數據的準確性,這也就意味著數據的基礎決定了應用的下限。而這個數據基礎的核心就是RAG(檢索增強)技術,這一技術的主要目的就是通過向量數據庫檢索、網頁檢索、圖數據庫檢索或關聯數據庫檢索等方式,實現和大模型的對接,但最基本的是向量數據庫與大模型的配合。
通常來說,RAG技術包括數據源準備和問答/任務處理兩個階段。在數據源準備過程,企業需要構建知識庫,也就是把相關的重要文檔加載到向量庫中,這一過程主要涉及到文檔分段及向量化等操作,其中向量化的目的不只是檢索關鍵詞,更重要的是實現語義檢索,以保證更廣泛的覆蓋面。
在問答/任務處理階段,則需要把問題做Embedding(語義匹配),例如衣服、褲子這些詞匯雖然字面上并不相同,但其實語義相關,然后VDB(檢索向量數據庫)會提取相關的上下文內容,并進行修改、調整和不相關內容的過濾,最后再將問題和相關內容提供給大模型生成回答。
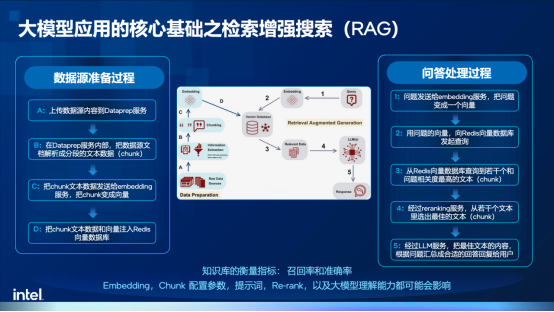
在整個過程中,數據基礎有兩個關鍵指標:召回率和準確率。前者代表檢索到的內容和問題的全面性和相關性,而后者則代表檢索到的內容和問題的相關程度。這兩個指標直接決定了大模型應用的體驗,因此,Embedding模型的選擇、chunk的大小和劃分方法等課題,都需要在實踐中進行反復優化,才能真正理解技術的精髓,從而為智能體開發打好基礎。
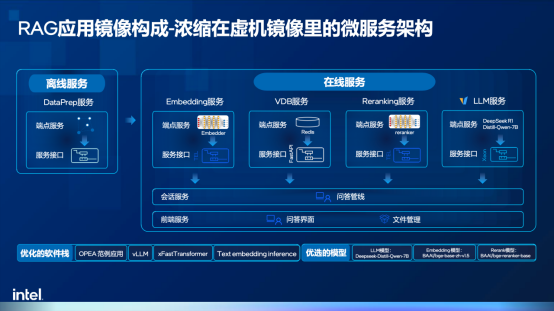
這也是英特爾和火山引擎推出RAG應用鏡像的原因之一,該鏡像實現了RAG全流程模快的集成,包含Embedding模塊、向量數據庫、Re-Rank,以及一個7B參數的DeepSeek蒸餾模型,并在文檔準備工作中提供了用于在線問答的服務Dataprep。而對開發者來說,通過火山引擎選擇云實例后,僅需3分鐘左右就能完成環境部署,掌握大模型應用開發的核心思路,為構建精準、合規的智能體應用奠定基礎。
結語
步入智能數字化時代,大模型技術正在加速AI應用的大規模應用。而英特爾與火山引擎的合作,正是對AI惠普的進一步實踐,通過基于英特爾至強6的g4il實例、軟件棧支持和配套課程,英特爾與火山引擎正在為廣大開發者們架起一座通向Agentic AI未來的橋梁。
審核編輯 黃宇
-
英特爾
+關注
關注
61文章
10165瀏覽量
173897 -
AI
+關注
關注
87文章
34146瀏覽量
275283 -
大模型
+關注
關注
2文章
3020瀏覽量
3805
發布評論請先 登錄
一文看懂空心杯電機

上線!國產AI語音開發板,定制你的聊天伙伴助手,可直接調用DeepSeek/豆包/通義千問

【「AI Agent應用與項目實戰」閱讀體驗】書籍介紹
藍橋杯物聯網開發板硬件組成

藍橋杯該如何備賽?
AI大語言模型開發步驟
大語言模型開發語言是什么
Air780E模組LuatOS開發實戰 —— 手把手教你搞定數據打包解包

云端語言模型開發方法
如何利用Verilog-A開發器件模型







 工商網監
工商網監
評論