") 一種神經(jīng)語音克隆系統(tǒng)兩種方法在自然性和相似性方面表現(xiàn)良好
一種神經(jīng)語音克隆系統(tǒng)兩種方法在自然性和相似性方面表現(xiàn)良好
近日,百度研究者發(fā)表論文,利用兩種方法,只需少量樣本就能在幾秒鐘內(nèi)合成自然且相似度極高的語音。近些年關(guān)于高質(zhì)量的語音合成方法確實不少,但能在如此短時間內(nèi)完成的卻實屬罕見。
聲音克隆是個性化語音交互領(lǐng)域高度理想化的功能,基于神經(jīng)網(wǎng)絡(luò)的語音合成系統(tǒng)已經(jīng)可以為大量發(fā)言者生成高質(zhì)量語音了。在這篇論文中,百度的研究人員向我們介紹了一種神經(jīng)語音克隆系統(tǒng),只需要輸入少量的語音樣本,就能合成逼真的語音。這里研究了兩種方法:說話者適應(yīng)(speaker adaptation)和說話者編碼(speaker encoding),最終結(jié)果表明兩種方法在語音的自然性和相似性方面都表現(xiàn)良好。
由于研究者要從有限且陌生的語音樣本中進行語音克隆,這就相當于一個“語音在特定語境下的few-shot生成建模”問題。若樣本充足,為任何目標說話者訓練生成模型都不在話下。不過,few-shot生成模型雖然聽起來很吸引人,但卻是個挑戰(zhàn)。生成模型需要通過少量的信息學習說話者的特征,然后還要生成全新的語音。
語音克隆
我們計劃設(shè)計一個多說話者生成模型(multi-speaker generative model):f(ti,j,si; W,esi),ti表示文本,si表示說話者。模型以W進行參數(shù)化,作為編碼器和解碼器的訓練參數(shù)。esi是對應(yīng)到si的可訓練說話者嵌入。W和esi均通過最小化損失函數(shù)L進行優(yōu)化,損失函數(shù)L對生成音頻和真視音頻之間的差異進行懲罰。
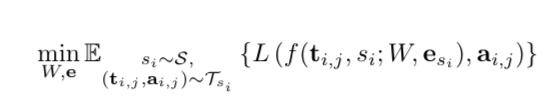
這里S是一組說話者,Tsi是為si準備的文字-音頻訓練集,ai和j是ti和j的真實音頻。期望值是通過所有訓練說話者的文本-音頻對來估計的。
在語音克隆中,實驗的目的是從一組克隆音頻Ask中提取出sk的聲音特征,并且用該聲音生成不一樣的音頻。衡量生成結(jié)果的標準有二:
看語音是否自然;
看生成的語音與原音頻是否相似。
下圖總結(jié)了說話者適應(yīng)和說話者編碼兩種方法的語音克隆方法:
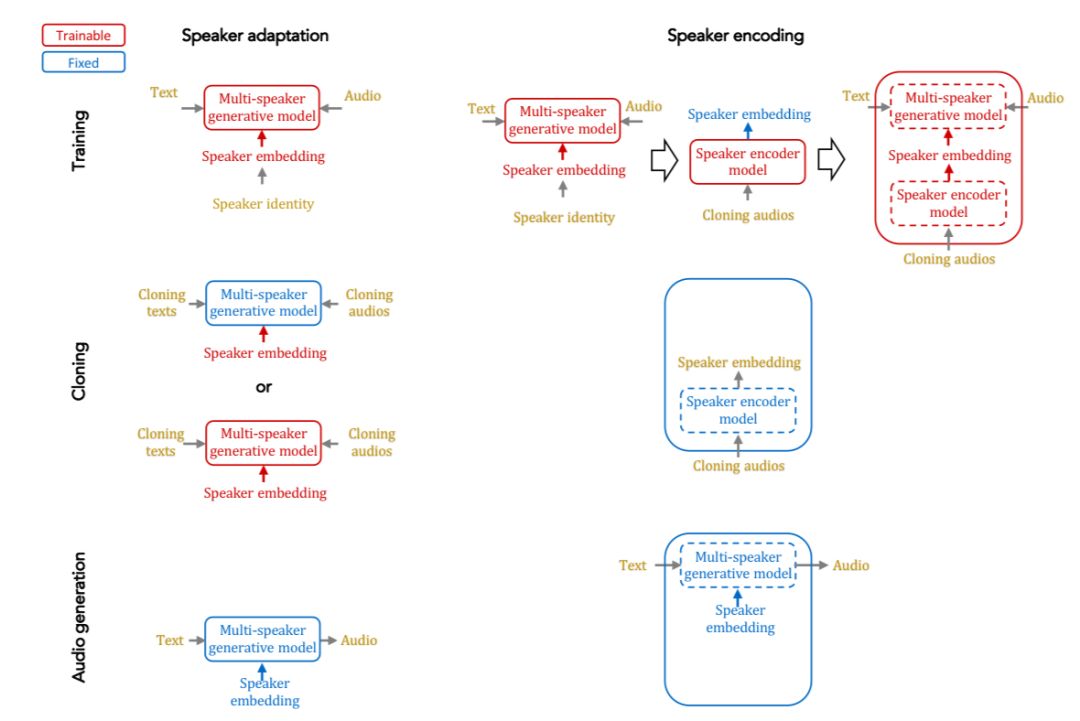
說話者適應(yīng)運用的是梯度下降原理,利用少數(shù)音頻和對應(yīng)的文本對多語音模型進行微調(diào),微調(diào)可以用于說話者嵌入或整個模型。
而說話者編碼的方法是從說話者的音頻樣本中估計說話者嵌入。這種模式并不需要在語音克隆的過程中進行微調(diào),因此它可以用于任何未知的說話者。
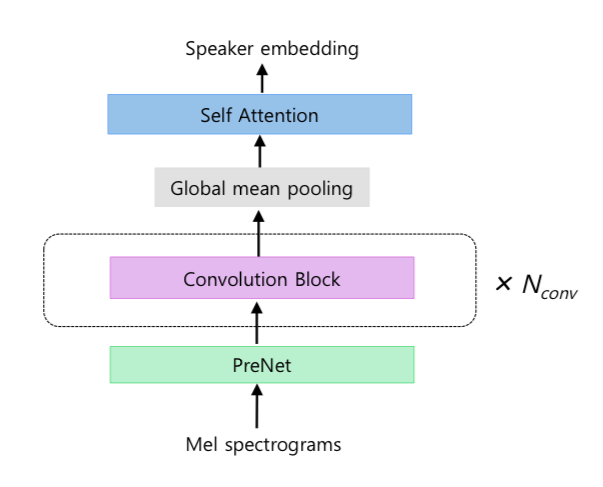
說話者編碼器結(jié)構(gòu)
語音克隆評估
語音克隆的結(jié)果可以通過眾包平臺經(jīng)過人類進行評估,但是這樣的模型開發(fā)過程是非常緩慢且昂貴的。研究人員利用判別模型提出了兩種評估方法。
1.說話者分類(Speaker Classification)
說話者分類器決定音頻樣本的來源。對于語音克隆評估,說話者分類器可以在用于克隆的語音上進行訓練。高質(zhì)量的語音克隆有助于提高分類器的精確度。
2.說話者驗證(Speaker Verification)
說話者驗證是用來檢測語音的相似性,具體來說,它利用二元分類識別測試音頻和生成音頻是否來自同一說話者。
實驗過程
我們對比了兩種方法(說話者適應(yīng)和說話者編碼)在語音克隆上的表現(xiàn)。對說話者適應(yīng),我們訓練了一個生成模型,讓其通過微調(diào)達到目標說話者的水平。對說話者編碼,我們訓練了一個多說話者生成模型和一個說話者編碼器,將嵌入輸入到多說話者生成模型中生成目標語音。
兩種方法訓練的數(shù)據(jù)集是LibriSpeech,該數(shù)據(jù)集包含2484個樣本音頻,總時長約820小時,16KHz。LibriSpeech是一個用于自動語音識別的數(shù)據(jù)集,它的音頻質(zhì)量比語音合成的數(shù)據(jù)集低。語音克隆是在VCTK數(shù)據(jù)集上進行的,其中包括了108種不同口音、以英語為母語的音頻。為了與LibriSpeech保持一致,VCTK中的音頻樣本被壓縮為16KHz。
下圖總結(jié)了不同的方法在語音克隆上的表現(xiàn):
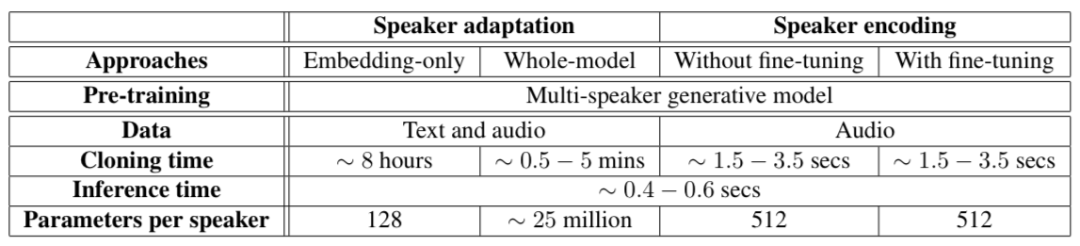
說話者適應(yīng)和說話者編碼在語音克隆上的不同需求。假設(shè)都在Titan X上進行
對于說話者適應(yīng)的方法,下圖表現(xiàn)了分類精確度與迭代時間的結(jié)果:
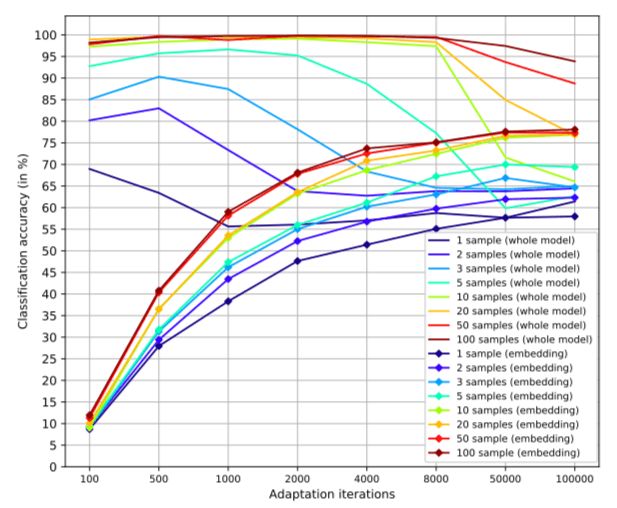
不同克隆樣本數(shù)量和微調(diào)次數(shù)的關(guān)系圖
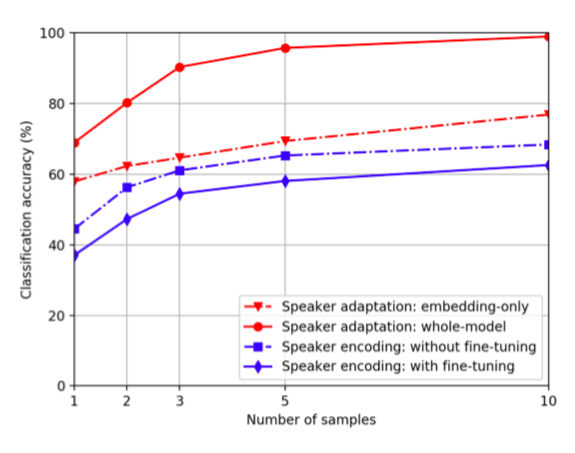
說話者適應(yīng)和說話者編碼在不同克隆樣本下的分類精度對比
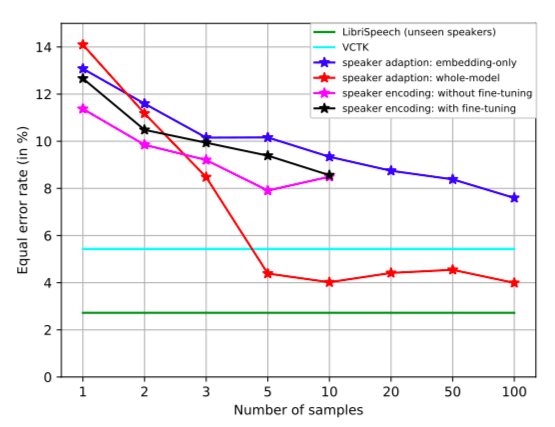
不同克隆樣本數(shù)量下,說話者驗證上的同等錯誤率(EER)
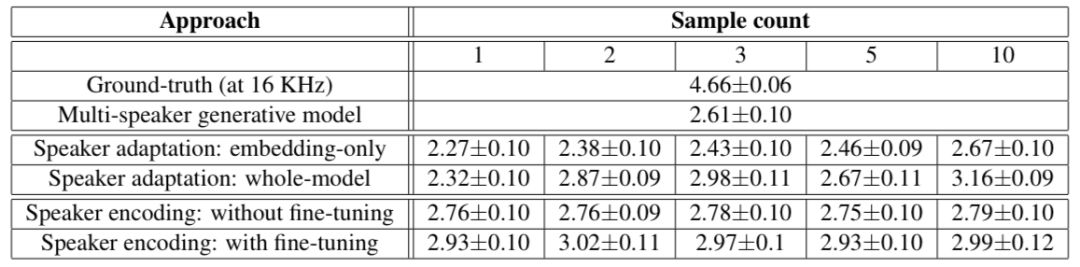
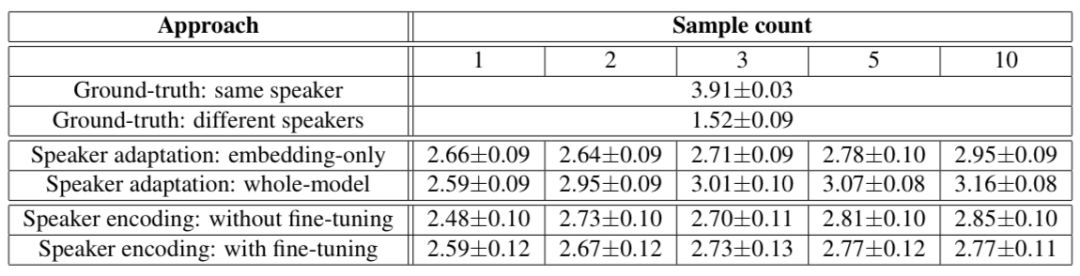
下面兩個表顯示了人類評估的結(jié)果,這兩個結(jié)果都表明克隆音頻越多,說話者適應(yīng)的方法越好。
結(jié)語
研究人員通過兩種方法,證明了他們可以用較少的聲音樣本生成自然、相似的新音頻。他們相信,語音克隆在未來依然有改善的前景。隨著元學習的進展,這一領(lǐng)域?qū)⒌玫接行У奶岣撸纾梢酝ㄟ^將說話者適應(yīng)或編碼這兩種方法整合到訓練中,或者通過比說話者嵌入更靈活的方式來推斷模型權(quán)重。
-
編碼器
+關(guān)注
關(guān)注
45文章
3772瀏覽量
137100 -
音頻
+關(guān)注
關(guān)注
29文章
3019瀏覽量
83018
原文標題:百度研究者利用少量樣本實現(xiàn)語音克隆
文章出處:【微信號:jqr_AI,微信公眾號:論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
基于序貫相似性測算法的圖像模板配準算法
基于相似性的圖像融合質(zhì)量的客觀評估方法
基于相似性度量的高維聚類算法的研究
基于項目相似性度量方法的項目協(xié)同過濾推薦算法
基于網(wǎng)絡(luò)本體語言O(shè)WL表示模型語義的相似性計算方法
一種基于SQL的圖相似性查詢方法
一種新的混合相似性權(quán)重的非局部均值去躁算法
基于劃分思想的文件結(jié)構(gòu)化相似性比較方法
云模型重疊度的相似性度量算法
基于節(jié)點相似性社團結(jié)構(gòu)劃分
一種基于程序向量樹的代碼克隆檢測方法

一種基于約束推導式的增強型相似性方法

一種快速計算動態(tài)網(wǎng)絡(luò)相似性的方法
PyTorch教程15.7之詞的相似性和類比

基于結(jié)構(gòu)相似性可靠性監(jiān)測結(jié)果





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論