") 基于RV1126開發(fā)板的AI算法開發(fā)流程
基于RV1126開發(fā)板的AI算法開發(fā)流程
1. 概述

2. 需求分析
算法的功能常常可以用一個短詞概括,如人臉識別、司機行為檢測、商場顧客行為分析等系統(tǒng),但是卻需要依靠多個子算法的有序運作才能達(dá)成。其原因在于子算法的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)各有不同,這些結(jié)構(gòu)的差異化優(yōu)化了各個子算法在其功能上的實現(xiàn)效果。
| 模型分類名稱 | 功能 |
| 目標(biāo)檢測模型 | 檢測圖像中是否存在目標(biāo)物體,并給出其在圖像中的具體坐標(biāo),可同時提供分類功能 |
| 關(guān)鍵點定位模型 | 檢測圖像中的特定目標(biāo),并標(biāo)出關(guān)鍵點位,常見骨骼點位、面部器官點位等 |
| 相似度比對模型 | 比較兩個不同的個體的相似度,常見人臉、豬臉識別,商品識別 |
| 分割模型 | 檢測圖像中存在的物體,按輪廓或其他標(biāo)準(zhǔn)分割出物體所在的不規(guī)則像素區(qū)域,可同時帶分類功能 |
| OCR模型 | 識別字體 |
以下我們列出組成例子:
例子a: 人臉識別算法 = 人臉檢測(檢測模型)+ 矯正人臉姿態(tài)模型(關(guān)鍵點定位模型)+ 人臉比對模型(相似度比對模型)
??例子b: 司機行為檢測算法 = 人臉識別算法(具體組成如上例)+ 抽煙玩手機等危險動作識別(檢測模型) + 疲勞駕駛檢測(關(guān)鍵點定位模型)+ 車道線偏移檢測(檢測模型)
??例子c: 商場分析 = 人臉識別算法(具體組成如首例)+ 人體跟蹤算法(檢測模型 + 相似度比對模型)
??只有在確定了具體需求所需要的步驟后,我們才能有的放矢的采集數(shù)據(jù),優(yōu)化模型,訓(xùn)練出合乎我們需求的模型。
3. 準(zhǔn)備數(shù)據(jù)
即使準(zhǔn)備數(shù)據(jù)在大多數(shù)人看來是繁瑣重復(fù)的工作,這期間仍有許多細(xì)節(jié)需要注意的。
數(shù)據(jù)樣本需要良好的多樣性。樣本多樣性是保證算法泛化能力的基礎(chǔ),例如想要識別農(nóng)產(chǎn)品的功能中,假如我們只是搜集紅蘋果的數(shù)據(jù),那么訓(xùn)練出來的網(wǎng)絡(luò)就很難將綠色的蘋果準(zhǔn)確識別出。同時還需要加入充足的負(fù)樣本,例如我們只是單純地把農(nóng)產(chǎn)品的圖片數(shù)據(jù)喂給神經(jīng)網(wǎng)絡(luò),那么我們就很難期望訓(xùn)練出來的神經(jīng)網(wǎng)絡(luò)可以有效區(qū)分真蘋果還有塑料蘋果。為了增強算法的可靠性,我們就需要充分的考慮到實際應(yīng)用場景中會出現(xiàn)什么特殊情況,并將該種情況的數(shù)據(jù)添加進(jìn)我們的訓(xùn)練數(shù)據(jù)里面。
??數(shù)據(jù)樣本是否可被壓縮。單個樣本數(shù)據(jù)的大小往往決定了網(wǎng)絡(luò)模型的運行效率,在保證效果的情況下,應(yīng)當(dāng)盡量壓縮圖片的大小來提高運行效率,如112x112的圖片,在相同環(huán)境下的處理速度將比224x224圖片的快4倍左右。但是有些場景卻是需要完整的圖片來保證圖片信息不會丟失,如山火檢測一般需要很高的查全率,過度的壓縮都會導(dǎo)致查全率下降導(dǎo)致算法效果不佳。
??數(shù)據(jù)需要合適正確的標(biāo)注與預(yù)處理。數(shù)據(jù)標(biāo)注在一定程度上決定了訓(xùn)練效果能達(dá)到的高度,過多的錯誤標(biāo)記將帶來一個無效的訓(xùn)練結(jié)果。而數(shù)據(jù)的預(yù)處理,是指先對數(shù)據(jù)做出一定的操作,使其更容易被機器讀懂,例如農(nóng)產(chǎn)品在畫面中的位置,如果是以像素點為單位,如農(nóng)產(chǎn)品的中心點在左起第200個像素點,這種處理方式雖然直觀準(zhǔn)確,但是會因為不同像素點之間的差距過大,導(dǎo)致訓(xùn)練困難,這個時候就需要將距離歸一化,如中心點在圖中左起40%寬的位置上。而音頻的預(yù)處理更為多樣,不同的分詞方式、傅里葉變換都會影響訓(xùn)練結(jié)果。
??數(shù)據(jù)的準(zhǔn)備不一定得在一開始就做到毫無遺漏。模型訓(xùn)練完成后,如果有一定的效果但還存在部分缺陷,就可以考慮添加或優(yōu)化訓(xùn)練樣本數(shù)據(jù),對已有模型進(jìn)行復(fù)訓(xùn)練修正。即使是后期的優(yōu)化,增添合適的照片往往是最有效的效果。所以對數(shù)據(jù)的考量優(yōu)化應(yīng)該貫穿整個流程,不能在只是在開頭階段才關(guān)注數(shù)據(jù)樣本的問題。
4. 選取模型
通常來講,對于同一個功能,存在著不同的模型,它們在精度、計算速率上各有長處。模型來發(fā)現(xiàn)主要來源于學(xué)術(shù)研究、公司之間的公開比賽等,所以在研發(fā)過程中,就需從業(yè)人員持續(xù)地關(guān)注有關(guān)ai新模型的文章;同時對舊模型的積累分析也是十分重要的,這里我們在 下表 中列出目前在各個功能上較優(yōu)的模型結(jié)構(gòu)以供參考。
| 模型類型 | 模型名稱 | 效果 | 速率 |
| 檢測模型 | yolov5 | 精度高 | 中等 |
| 檢測模型 | ssd | 精度中等,對小物體的識別一般 | 快速 |
| 關(guān)鍵點定位模型 | mtcnn | 精度一般,關(guān)鍵點較少 | 快 |
| 關(guān)鍵點的定位模型 | openpose | 精度高,關(guān)鍵點多 | 中等 |
| 相似度比對模型 | resnet18 | 精度高 | 快速 |
| 相似度比對模型 | resnet50 | 精度高,魯棒性強,有比較強的抗干擾能力 | 中等 |
| 分割模型 | mask-rcnn | 精度中,分割出畫面中的不規(guī)則物體 | 慢 |
5. 訓(xùn)練模型
對于有AI開發(fā)經(jīng)驗的研發(fā)人員,可以用自己熟悉的常見框架訓(xùn)練即可,如tensorflow、pytorch、caffe等主流框架,我們的開發(fā)套件可以將其轉(zhuǎn)為EASY EAI Nano的專用模型。
6. 模型轉(zhuǎn)換
研發(fā)tensorflow、pytorch、caffe等自主的模型后,需先將模型轉(zhuǎn)換為rknn模型。同時一般需要對模型進(jìn)行量化與預(yù)編譯,以達(dá)到運行效率的提升。
6.1 模型轉(zhuǎn)換環(huán)境搭建
6.1.1 概述
模型轉(zhuǎn)換環(huán)境搭建流程如下所示:

6.1.2 下載模型轉(zhuǎn)換工具
為了保證模型轉(zhuǎn)換工具順利運行,請下載網(wǎng)盤里“AI算法開發(fā)/RKNN-Toolkit模型轉(zhuǎn)換工具/rknn-toolkit-v1.7.1/docker/rknn-toolkit-1.7.1-docker.tar.gz”。
網(wǎng)盤下載鏈接:https://pan.baidu.com/s/1LUtU_-on7UB3kvloJlAMkA 提取碼:teuc
6.1.3 把工具移到ubuntu18.04
把下載完成的docker鏡像移到我司的虛擬機ubuntu18.04的rknn-toolkit目錄,如下圖所示:
6.1.4 運行模型轉(zhuǎn)換工具環(huán)境
(1)打開終端
在該目錄打開終端:
(2)加載docker鏡像
執(zhí)行以下指令加載模型轉(zhuǎn)換工具docker鏡像:
docker load --input /home/developer/rknn-toolkit/rknn-toolkit-1.7.1-docker.tar.gz
(3)進(jìn)入鏡像bash環(huán)境
執(zhí)行以下指令進(jìn)入鏡像bash環(huán)境:
docker run -t -i --privileged -v /dev/bus/usb:/dev/bus/usb rknn-toolkit:1.7.1 /bin/bash
現(xiàn)象如下圖所示:
(4)測試環(huán)境
輸入“python”加載python相關(guān)庫,嘗試加載rknn庫,如下圖環(huán)境測試成功:
至此,模型轉(zhuǎn)換工具環(huán)境搭建完成。
6.2 模型轉(zhuǎn)換示例
6.2.1 模型轉(zhuǎn)換流程介紹
EASY EAI Nano支持.rknn后綴的模型的評估及運行,對于常見的tensorflow、tensroflow lite、caffe、darknet、onnx和Pytorch模型都可以通過我們提供的 toolkit 工具將其轉(zhuǎn)換至 rknn 模型,而對于其他框架訓(xùn)練出來的模型,也可以先將其轉(zhuǎn)至 onnx 模型再轉(zhuǎn)換為 rknn 模型。
模型轉(zhuǎn)換操作流程入下圖所示:

6.2.2 模型轉(zhuǎn)換Demo下載
下載百度網(wǎng)“AI算法開發(fā)/模型轉(zhuǎn)換Demo/model_convert.tar.bz2”。把model_convert.tar.bz2解壓到虛擬機,如下圖所示:
下載鏈接:https://pan.baidu.com/s/1OjDXM8kGXDbn5BqIeErpmw 提取碼:drv0
6.2.3 進(jìn)入模型轉(zhuǎn)換工具docker環(huán)境
執(zhí)行以下指令把工作區(qū)域映射進(jìn)docker鏡像,其中/home/developer/rknn-toolkit/model_convert為工作區(qū)域,/test為映射到docker鏡像,/dev/bus/usb:/dev/bus/usb為映射usb到docker鏡像:
docker run -t -i --privileged -v /dev/bus/usb:/dev/bus/usb -v /home/developer/rknn-toolkit/model_convert:/test rknn-toolkit:1.7.1 /bin/bash
執(zhí)行成功如下圖所示:
6.2.4 模型轉(zhuǎn)換操作說明
(1)模型轉(zhuǎn)換Demo目錄結(jié)構(gòu)
模型轉(zhuǎn)換測試Demo由coco_object_detect和quant_dataset組成。coco_object_detect存放軟件腳本,quant_dataset存放量化模型所需的數(shù)據(jù)。如下圖所示:
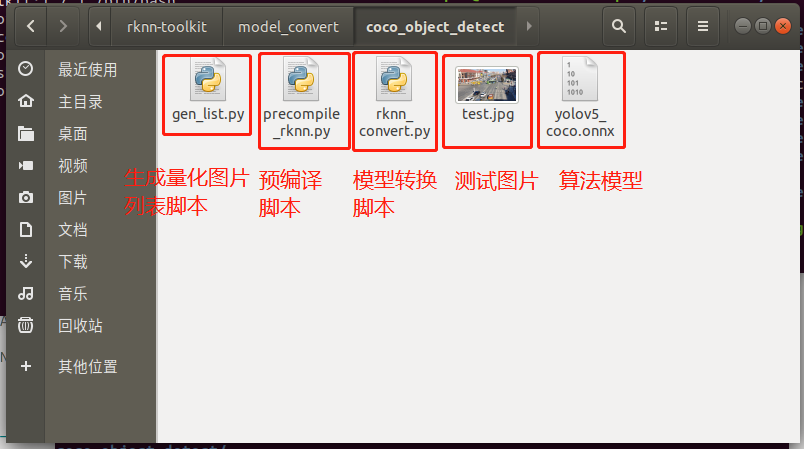
coco_object_detect文件夾存放以下內(nèi)容,如下圖所示:
(2)生成量化圖片列表
在docker環(huán)境切換到模型轉(zhuǎn)換工作目錄:
cd /test/coco_object_detect/
如下圖所示:

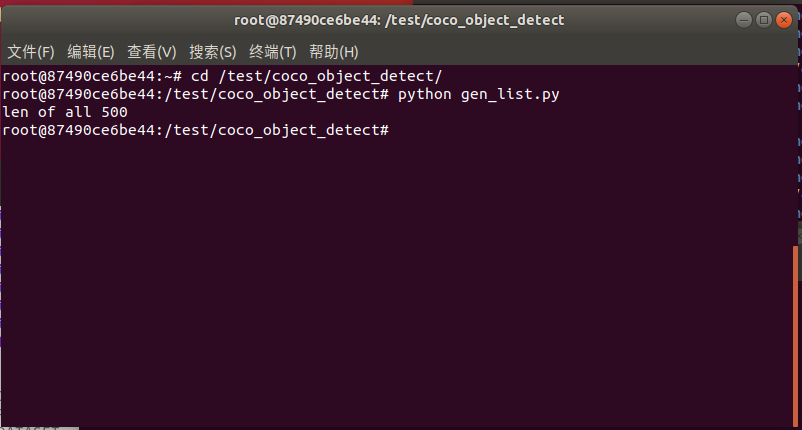
執(zhí)行g(shù)en_list.py生成量化圖片列表:
python gen_list.py
命令行現(xiàn)象如下圖所示:
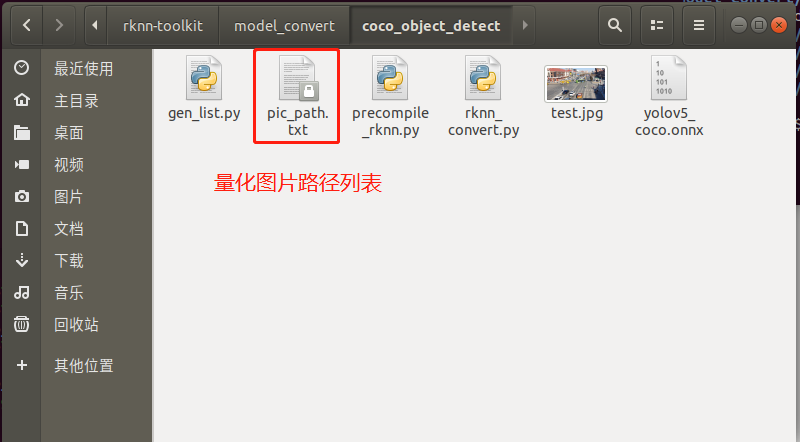
生成“量化圖片列表”如下文件夾所示:
(3)onnx模型轉(zhuǎn)換為rknn模型
rknn_convert.py腳本默認(rèn)進(jìn)行int8量化操作,腳本代碼清單如下所示:
import os import urllib import traceback import time import sys import numpy as np import cv2 from rknn.api import RKNN ONNX_MODEL = 'yolov5_coco.onnx' RKNN_MODEL = './yolov5_coco_rv1126.rknn' DATASET = './pic_path.txt' QUANTIZE_ON = True if __name__ == '__main__': # Create RKNN object rknn = RKNN(verbose=True) if not os.path.exists(ONNX_MODEL): print('model not exist') exit(-1) # pre-process config print('--> Config model') rknn.config(reorder_channel='0 1 2', mean_values=[[0, 0, 0]], std_values=[[255, 255, 255]], optimization_level=3, target_platform = 'rv1126', output_optimize=1, quantize_input_node=QUANTIZE_ON) print('done') # Load ONNX model print('--> Loading model') ret = rknn.load_onnx(model=ONNX_MODEL) if ret != 0: print('Load yolov5 failed!') exit(ret) print('done') # Build model print('--> Building model') ret = rknn.build(do_quantization=QUANTIZE_ON, dataset=DATASET) if ret != 0: print('Build yolov5 failed!') exit(ret) print('done') # Export RKNN model print('--> Export RKNN model') ret = rknn.export_rknn(RKNN_MODEL) if ret != 0: print('Export yolov5rknn failed!') exit(ret) print('done')
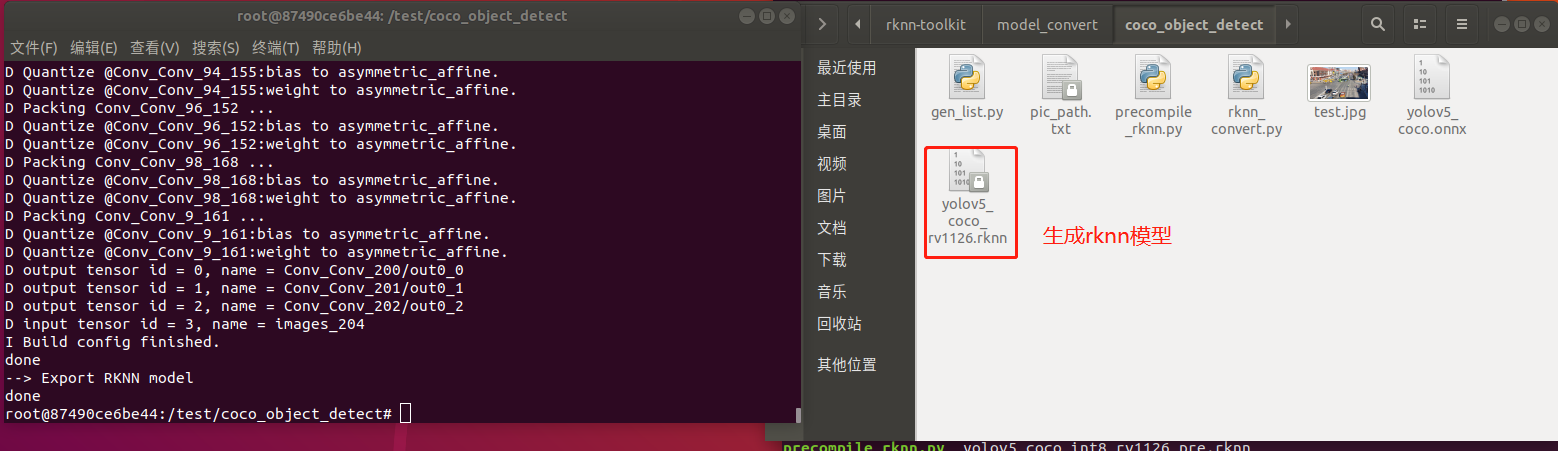
在執(zhí)行rknn_convert.py腳本進(jìn)行模型轉(zhuǎn)換:
python rknn_convert.py
生成模型如下圖所示,此模型可以在rknn環(huán)境和EASY EAI Nano環(huán)境運行:
(4)運行rknn模型
用yolov5_coco_test.py腳本在PC端的環(huán)境下可以運行rknn的模型,如下圖所示:
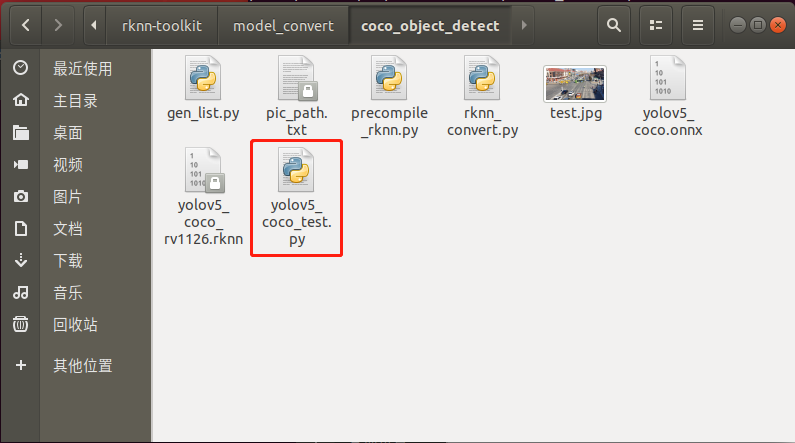
yolov5_coco_test.py腳本程序清單如下所示:
import os
import urllib
import traceback
import time
import sys
import numpy as np
import cv2
import random
from rknn.api import RKNN
RKNN_MODEL = 'yolov5_coco_rv1126.rknn'
IMG_PATH = './test.jpg'
DATASET = './dataset.txt'
BOX_THRESH = 0.25
NMS_THRESH = 0.6
IMG_SIZE = 640
CLASSES = ("person", "bicycle", "car","motorbike ","aeroplane ","bus ","train","truck ","boat","traffic light",
"fire hydrant","stop sign ","parking meter","bench","bird","cat","dog ","horse ","sheep","cow","elephant",
"bear","zebra ","giraffe","backpack","umbrella","handbag","tie","suitcase","frisbee","skis","snowboard","sports ball","kite",
"baseball bat","baseball glove","skateboard","surfboard","tennis racket","bottle","wine glass","cup","fork","knife",
"spoon","bowl","banana","apple","sandwich","orange","broccoli","carrot","hot dog","pizza ","donut","cake","chair","sofa",
"pottedplant","bed","diningtable","toilet ","tvmonitor","laptop","mouse","remote ","keyboard ","cell phone","microwave ",
"oven ","toaster","sink","refrigerator ","book","clock","vase","scissors ","teddy bear ","hair drier", "toothbrush")
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def xywh2xyxy(x):
# Convert [x, y, w, h] to [x1, y1, x2, y2]
y = np.copy(x)
y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x
y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y
y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x
y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y
return y
def process(input, mask, anchors):
anchors = [anchors[i] for i in mask]
grid_h, grid_w = map(int, input.shape[0:2])
box_confidence = sigmoid(input[..., 4])
box_confidence = np.expand_dims(box_confidence, axis=-1)
box_class_probs = sigmoid(input[..., 5:])
box_xy = sigmoid(input[..., :2])*2 - 0.5
col = np.tile(np.arange(0, grid_w), grid_w).reshape(-1, grid_w)
row = np.tile(np.arange(0, grid_h).reshape(-1, 1), grid_h)
col = col.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2)
row = row.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2)
grid = np.concatenate((col, row), axis=-1)
box_xy += grid
box_xy *= int(IMG_SIZE/grid_h)
box_wh = pow(sigmoid(input[..., 2:4])*2, 2)
box_wh = box_wh * anchors
box = np.concatenate((box_xy, box_wh), axis=-1)
return box, box_confidence, box_class_probs
def filter_boxes(boxes, box_confidences, box_class_probs):
"""Filter boxes with box threshold. It's a bit different with origin yolov5 post process!
# Arguments
boxes: ndarray, boxes of objects.
box_confidences: ndarray, confidences of objects.
box_class_probs: ndarray, class_probs of objects.
# Returns
boxes: ndarray, filtered boxes.
classes: ndarray, classes for boxes.
scores: ndarray, scores for boxes.
"""
box_scores = box_confidences * box_class_probs
box_classes = np.argmax(box_class_probs, axis=-1)
box_class_scores = np.max(box_scores, axis=-1)
pos = np.where(box_confidences[...,0] >= BOX_THRESH)
boxes = boxes[pos]
classes = box_classes[pos]
scores = box_class_scores[pos]
return boxes, classes, scores
def nms_boxes(boxes, scores):
"""Suppress non-maximal boxes.
# Arguments
boxes: ndarray, boxes of objects.
scores: ndarray, scores of objects.
# Returns
keep: ndarray, index of effective boxes.
"""
x = boxes[:, 0]
y = boxes[:, 1]
w = boxes[:, 2] - boxes[:, 0]
h = boxes[:, 3] - boxes[:, 1]
areas = w * h
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x[i], x[order[1:]])
yy1 = np.maximum(y[i], y[order[1:]])
xx2 = np.minimum(x[i] + w[i], x[order[1:]] + w[order[1:]])
yy2 = np.minimum(y[i] + h[i], y[order[1:]] + h[order[1:]])
w1 = np.maximum(0.0, xx2 - xx1 + 0.00001)
h1 = np.maximum(0.0, yy2 - yy1 + 0.00001)
inter = w1 * h1
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= NMS_THRESH)[0]
order = order[inds + 1]
keep = np.array(keep)
return keep
def yolov5_post_process(input_data):
masks = [[0, 1, 2], [3, 4, 5], [6, 7, 8]]
anchors = [[10, 13], [16, 30], [33, 23], [30, 61], [62, 45],
[59, 119], [116, 90], [156, 198], [373, 326]]
boxes, classes, scores = [], [], []
for input,mask in zip(input_data, masks):
b, c, s = process(input, mask, anchors)
b, c, s = filter_boxes(b, c, s)
boxes.append(b)
classes.append(c)
scores.append(s)
boxes = np.concatenate(boxes)
boxes = xywh2xyxy(boxes)
classes = np.concatenate(classes)
scores = np.concatenate(scores)
nboxes, nclasses, nscores = [], [], []
for c in set(classes):
inds = np.where(classes == c)
b = boxes[inds]
c = classes[inds]
s = scores[inds]
keep = nms_boxes(b, s)
nboxes.append(b[keep])
nclasses.append(c[keep])
nscores.append(s[keep])
if not nclasses and not nscores:
return None, None, None
boxes = np.concatenate(nboxes)
classes = np.concatenate(nclasses)
scores = np.concatenate(nscores)
return boxes, classes, scores
def scale_coords(x1, y1, x2, y2, dst_width, dst_height):
dst_top, dst_left, dst_right, dst_bottom = 0, 0, 0, 0
gain = 0
if dst_width > dst_height:
image_max_len = dst_width
gain = IMG_SIZE / image_max_len
resized_height = dst_height * gain
height_pading = (IMG_SIZE - resized_height)/2
print("height_pading:", height_pading)
y1 = (y1 - height_pading)
y2 = (y2 - height_pading)
print("gain:", gain)
dst_x1 = int(x1 / gain)
dst_y1 = int(y1 / gain)
dst_x2 = int(x2 / gain)
dst_y2 = int(y2 / gain)
return dst_x1, dst_y1, dst_x2, dst_y2
def plot_one_box(x, img, color=None, label=None, line_thickness=None):
tl = line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1 # line/font thickness
color = color or [random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
if label:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(img, label, (c1[0], c1[1] - 2), 0, tl / 3, [225, 255, 255], thickness=tf, lineType=cv2.LINE_AA)
def draw(image, boxes, scores, classes):
"""Draw the boxes on the image.
# Argument:
image: original image.
boxes: ndarray, boxes of objects.
classes: ndarray, classes of objects.
scores: ndarray, scores of objects.
all_classes: all classes name.
"""
for box, score, cl in zip(boxes, scores, classes):
x1, y1, x2, y2 = box
print('class: {}, score: {}'.format(CLASSES[cl], score))
print('box coordinate x1,y1,x2,y2: [{}, {}, {}, {}]'.format(x1, y1, x2, y2))
x1 = int(x1)
y1 = int(y1)
x2 = int(x2)
y2 = int(y2)
dst_x1, dst_y1, dst_x2, dst_y2 = scale_coords(x1, y1, x2, y2, image.shape[1], image.shape[0])
#print("img.cols:", image.cols)
plot_one_box((dst_x1, dst_y1, dst_x2, dst_y2), image, label='{0} {1:.2f}'.format(CLASSES[cl], score))
'''
cv2.rectangle(image, (dst_x1, dst_y1), (dst_x2, dst_y2), (255, 0, 0), 2)
cv2.putText(image, '{0} {1:.2f}'.format(CLASSES[cl], score),
(dst_x1, dst_y1 - 6),
cv2.FONT_HERSHEY_SIMPLEX,
0.6, (0, 0, 255), 2)
'''
def letterbox(im, new_shape=(640, 640), color=(0, 0, 0)):
# Resize and pad image while meeting stride-multiple constraints
shape = im.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
return im, ratio, (dw, dh)
if __name__ == '__main__':
# Create RKNN object
rknn = RKNN(verbose=True)
print('--> Loading model')
ret = rknn.load_rknn(RKNN_MODEL)
if ret != 0:
print('load rknn model failed')
exit(ret)
print('done')
# init runtime environment
print('--> Init runtime environment')
ret = rknn.init_runtime()
# ret = rknn.init_runtime('rv1126', device_id='1126')
if ret != 0:
print('Init runtime environment failed')
exit(ret)
print('done')
# Set inputs
img = cv2.imread(IMG_PATH)
letter_img, ratio, (dw, dh) = letterbox(img, new_shape=(IMG_SIZE, IMG_SIZE))
letter_img = cv2.cvtColor(letter_img, cv2.COLOR_BGR2RGB)
# Inference
print('--> Running model')
outputs = rknn.inference(inputs=[letter_img])
print('--> inference done')
# post process
input0_data = outputs[0]
input1_data = outputs[1]
input2_data = outputs[2]
input0_data = input0_data.reshape([3,-1]+list(input0_data.shape[-2:]))
input1_data = input1_data.reshape([3,-1]+list(input1_data.shape[-2:]))
input2_data = input2_data.reshape([3,-1]+list(input2_data.shape[-2:]))
input_data = list()
input_data.append(np.transpose(input0_data, (2, 3, 0, 1)))
input_data.append(np.transpose(input1_data, (2, 3, 0, 1)))
input_data.append(np.transpose(input2_data, (2, 3, 0, 1)))
print('--> transpose done')
boxes, classes, scores = yolov5_post_process(input_data)
print('--> get result done')
#img_1 = cv2.cvtColor(img, cv2.COLOR_RGB2BGR)
if boxes is not None:
draw(img, boxes, scores, classes)
cv2.imwrite('./result.jpg', img)
#cv2.imshow("post process result", img_1)
#cv2.waitKeyEx(0)
rknn.release()
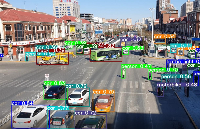
執(zhí)行yolov5_coco_test.py腳本測試rknn模型:
python yolov5_coco_test.py
執(zhí)行后得到result.jpg如下圖所示:
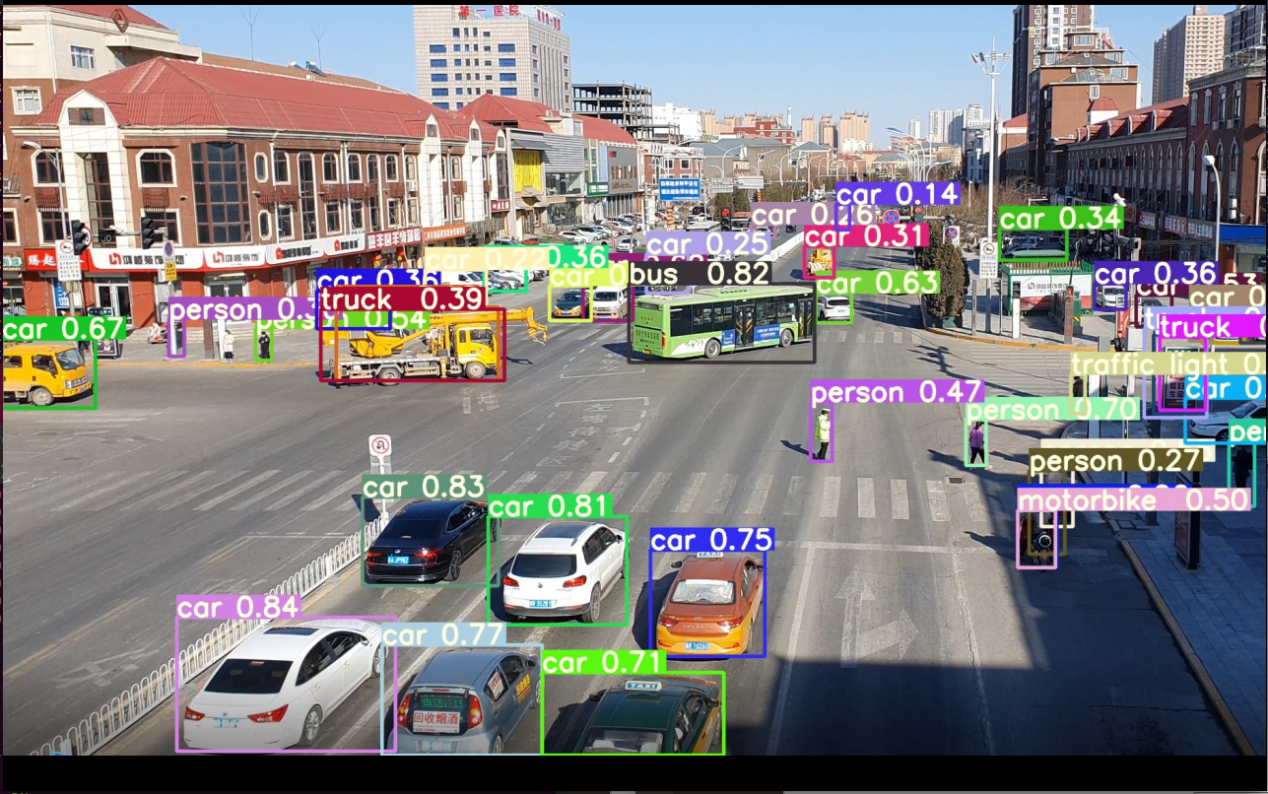
(5)模型預(yù)編譯
由于rknn模型用NPU API在EASY EAI Nano加載的時候啟動速度會好慢,在評估完模型精度沒問題的情況下,建議進(jìn)行模型預(yù)編譯。預(yù)編譯的時候需要通過EASY EAI Nano主板的環(huán)境,所以請務(wù)必接上adb口與ubuntu保證穩(wěn)定連接。
板子端接線如下圖所示,撥碼開關(guān)需要是adb:

虛擬機要保證接上adb設(shè)備:
由于在虛擬機里ubuntu環(huán)境與docker環(huán)境對adb設(shè)備資源是競爭關(guān)系,所以需要關(guān)掉ubuntu環(huán)境下的adb服務(wù),且在docker里面通過apt-get安裝adb軟件包。以下指令在ubuntu環(huán)境與docker環(huán)境里各自執(zhí)行:
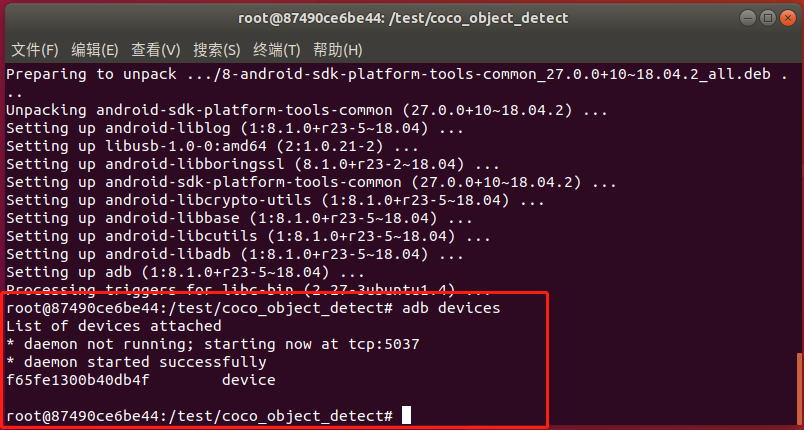
在docker環(huán)境里執(zhí)行adb devices,現(xiàn)象如下圖所示則設(shè)備連接成功:
運行precompile_rknn.py腳本把模型執(zhí)行預(yù)編譯:
python precompile_rknn.py
執(zhí)行效果如下圖所示,生成預(yù)編譯模型yolov5_coco_int8_rv1126_pre.rknn:
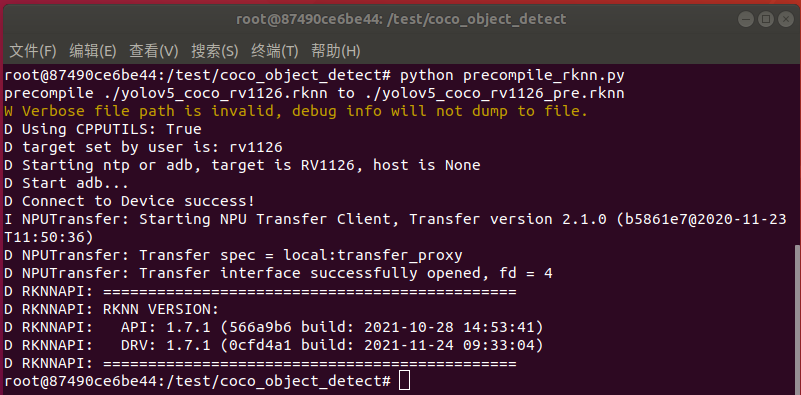
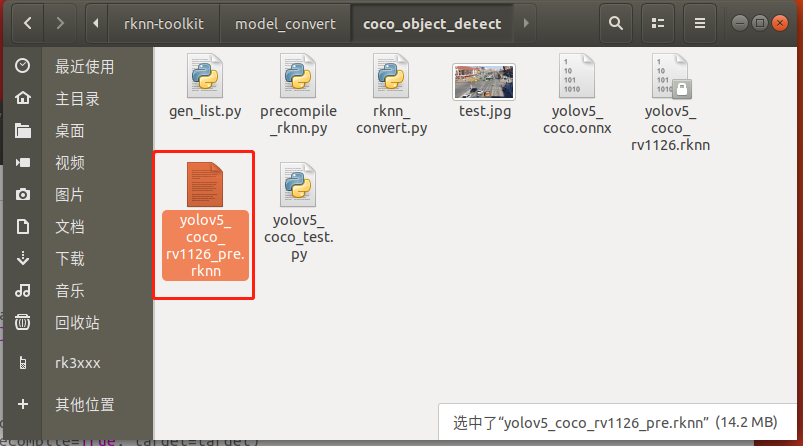
至此預(yù)編譯部署完成,模型轉(zhuǎn)換步驟已全部完成。生成如下預(yù)編譯后的int8量化模型:
6.3 模型轉(zhuǎn)換API說明
6.3.1 RKNN 初始化及對象釋放
在使用 RKNN-Toolkit 的所有 API 接口時,都需要先調(diào)用 RKNN()方法初始化 RKNN 對象,并 不再使用該對象時,調(diào)用該對象的 release()方法進(jìn)行釋放。
初始化 RKNN 對象時,可以設(shè)置 verbose 和 verbose_file 參數(shù),以打印詳細(xì)的日志信息。其中 verbose 參數(shù)指定是否要在屏幕上打印詳細(xì)日志信息;如果設(shè)置了 verbose_file 參數(shù),且 verbose 參 數(shù)值為 True,日志信息還將寫到該參數(shù)指定的文件中。如果出現(xiàn) Error 級別的錯誤,而 verbose_file 又被設(shè)為 None,則錯誤日志將自動寫到 log_feedback_to_the_rknn_toolkit_dev_team.log 文件中。
反饋錯誤信息給 Rockchip NPU 團(tuán)隊時,建議反饋完整的錯誤日志。
舉例如下:
# 將詳細(xì)的日志信息輸出到屏幕,并寫到 mobilenet_build.log 文件中 rknn = RKNN(verbose=True, verbose_file=’./mobilenet_build.log’) # 只在屏幕打印詳細(xì)的日志信息 rknn = RKNN(verbose=True) … rknn.release()
6.3.2 RKNN 模型配置
在構(gòu)建 RKNN 模型之前,需要先對模型進(jìn)行通道均值、通道順序、量化類型等的配置,這些 操作可以通過 config 接口進(jìn)行配置。
| API | config |
| 描述 | 設(shè)置模型參數(shù) |
| 參數(shù) | batch_size:批處理大小,默認(rèn)值為 100。量化時將根據(jù)該參數(shù)決定每一批次參與運算的數(shù)據(jù)量,以校正量化結(jié)果。如果dataset中的數(shù)據(jù)量小于batch_size,則該參數(shù)值將自動調(diào)整為dataset中的數(shù)據(jù)量。如果量化時出現(xiàn)內(nèi)存不足的問題,建議將這個值設(shè)小一點,例如 8。 |
| mean_values:輸入的均值。該參數(shù)與 channel_mean_value參數(shù)不能同時設(shè)置。參數(shù)格式是一個列表,列表中包含一個或多個均值子列表,多輸入模型對應(yīng)多個子列表,每個子列表的長度與該輸入的通道數(shù)一致,例如[[128,128,128]],表示一個輸入的三個通道的值減去128。如果 reorder_channel設(shè)置成’2 1 0‘,則優(yōu)先做通道調(diào)整,再做減均值。 | |
| std_values:輸入的歸一化值。該參數(shù)與channel_mean_value參數(shù)不能同時設(shè)置。參數(shù)格式是一個列表,列表中包含一個或多個歸一化值子列表,多輸入模型對應(yīng)多個子列表,每個子列表的長度與該輸入的通道數(shù)一致,例如[[128,128,128]],表示設(shè)置一個輸入的三個通道的值減去均值后再除以128。如果 reorder_channel設(shè)置成’2 1 0‘,則優(yōu)先做通道調(diào)整,再減均值和除以歸一化值。 | |
| epochs:量化時的迭代次數(shù),每迭代一次,就選擇 batch_size 指定數(shù)量的圖片進(jìn)行量化校正。默認(rèn)值為-1,此時 RKNN-Toolkit 會根據(jù)dataset中的圖片數(shù)量自動計算迭代次數(shù)以最大化利用數(shù)據(jù)集中的數(shù)據(jù)。 | |
| reorder_channel:表示是否需要對圖像通道順序進(jìn)行調(diào)整,只對三通道輸入有效。’0 1 2’表示按照輸入的通道順序來推理,比如圖片輸入時是 RGB,那推理的時候就根據(jù) RGB順序傳給輸入層;’2 1 0’表示會對輸入做通道轉(zhuǎn)換,比如輸入時通道順序是RGB,推理時會將其轉(zhuǎn)成 BGR,再傳給輸入層,同樣的,輸入時通道的順序為 BGR 的話,會被轉(zhuǎn)成 RGB 后再傳給輸入層。如果有多個輸入,每個輸入的參數(shù)以“#”進(jìn)行分 隔,如 ’0 1 2#0 1 2’。該參數(shù)的默認(rèn)值是 None,對于 Caffe 框架的三通道輸入模型,表示需要做通道順序的調(diào)整,其他框架的三通道輸入模型,默認(rèn)不做通道順序調(diào)整。 | |
| need_horizontal_merge:是否需要進(jìn)行水平合并,默認(rèn)值為 False。如果模型是 inception v1/v3/v4,建議開啟該選項,可以提高推理時的性能。 | |
| quantized_dtype:量化類型,目前支持的量化類型有 asymmetric_quantized-u8、dynamic_fixed_point-i8、dynamic_fixed_point-i16,默認(rèn)值為 asymmetric_quantized-u8。 | |
| quantized_algorithm: 量化參數(shù)優(yōu)化算法。當(dāng)前版本支持的算法有:normal,mmse和kl_divergence,默認(rèn)值為normal。其中normal 算法的特點是速度較快。而mmse算 法,因為需要對量化參數(shù)進(jìn)行多次調(diào)整,其速度會慢很多,但通常能得到比normal算法更高的精度;kl_divergence所用時間會比 normal多一些,但比 mmse 會少很多,在某些場景下可以得到較好的改善效果。 | |
| mmse_epoch:mmse量化算法的迭代次數(shù),默認(rèn)值為 3。通常情況下,迭代次數(shù)越多,精度往往越高。 | |
| optimization_level:模型優(yōu)化等級。通過修改模型優(yōu)化等級,可以關(guān)掉部分或全部模型轉(zhuǎn)換過程中使用到的優(yōu)化規(guī)則。該參數(shù)的默認(rèn)值為 3,打開所有優(yōu)化選項。值為2或1時關(guān)閉一部分可能會對部分模型精度產(chǎn)生影響的優(yōu)化選項,值為0時關(guān)閉所有 優(yōu)化選項。 | |
| target_platform:指定RKNN模型目標(biāo)運行平臺。目前支持RK1806、RK1808、RK3399Pro、RV1109和RV1126。其中基于RK1806、RK1808 或 RK3399Pro生成的RKNN模型可以在這三個平臺上通用,基于 RV1109或RV1126生成的RKNN模型可以在這兩個平臺通用。如果模型要在RK1806、RK1808或RK3399Pro上運行,該參數(shù)的值可以是 [“rk1806”], [“rk1808”], [“rk3399pro”]或 [“rk1806”, “rk1808”, “rk3399pro”]等;如果模型要在RV1109 或 RV1126 上運行,該參數(shù)的值可以是 [“rv1126”], [“rv1109”]或[“rv1109”, “rv1126”]等。這個參數(shù)的值不可以是類似[“rk1808”, “rv1126”]這樣的組合,因為這兩款芯片互不兼容。如果不填該參數(shù),則默認(rèn)是 [“rk1808”],生成的RKNN 模型可以在 RK1806、RK1808和RK3399Pro 平臺上運行。 該參數(shù)的值大小寫不敏感。 | |
| quantize_input_node: 開啟后無論模型是否量化,均強制對模型的輸入節(jié)點進(jìn)行量化。 輸入節(jié)點被量化的模型,在部署時會有性能優(yōu)勢,rknn_input_set接口的耗時更少。當(dāng) RKNN-Toolkit 量化沒有按理想情況對輸入節(jié)點進(jìn)行量化(僅支持輸入為圖片的模型)、或用戶選擇加載深度學(xué)習(xí)框架已生成的量化模型時可以啟用(這種情況下,第一層的quantize_layer會被合并到輸入節(jié)點)。默認(rèn)值為 False。 | |
| merge_dequant_layer_and_output_node: 將模型輸出節(jié)點與上一層的dequantize_layer,合并成一個被量化的輸出節(jié)點,允許模型在部署時返回 uint8或 float類型的推理結(jié)果。此配置僅對加載深度學(xué)習(xí)框架已生成的量化模型有效。默認(rèn)為 False。 | |
| 返回值 | 無 |
舉例如下:
# model config
rknn.config(mean_values=[[103.94, 116.78, 123.68]],
std_values=[[58.82, 58.82, 58.82]],
reorder_channel=’0 1 2’,
need_horizontal_merge=True,
target_platform=[‘rk1808’, ‘rk3399pro’]
6.3.3 模型加載
RKNN-Toolkit 目前支持Caffe, Darknet, Keras, MXNet, ONNX, PyTorch, TensorFlow,和TensorFlow Lite等模型的加載轉(zhuǎn)換,這些模型在加載時需調(diào)用對應(yīng)的接口,以下為這些接口的詳細(xì)說明。
(1)Caffe 模型加載接口
| API | load_caffe |
| 描述 | 加載 caffe 模型 |
| 參數(shù) | model:caffe 模型文件(.prototxt 后綴文件)所在路徑。 |
| proto:caffe模型的格式(可選值為’caffe’或’lstm_caffe’)。為了支持RNN 模型,增加了相關(guān)網(wǎng)絡(luò)層的支持,此時需要設(shè)置 caffe 格式為’lstm_caffe’。 | |
| blobs:caffe模型的二進(jìn)制數(shù)據(jù)文件(.caffemodel 后綴文件)所在路徑。該參數(shù)值可以為 None,RKNN-Toolkit將隨機生成權(quán)重等參數(shù)。 | |
| 返回值 | 0:導(dǎo)入成功 |
| -1:導(dǎo)入失敗 |
舉例如下:
#從當(dāng)前路徑加載 mobilenet_v2 模型
ret = rknn.load_caffe(model=’./mobilenet_v2.prototxt’,
proto=’caffe’,
blobs=’./mobilenet_v2.caffemodel’)
(2)Darknet 模型加載接口
| API | load_darknet |
| 描述 | 加載 Darknet模型 |
| 參數(shù) | model:Darknet模型文件(.cfg 后綴)所在路徑。 |
| weight:權(quán)重文件(.weights 后綴)所在路徑 | |
| 返回值 | 0:導(dǎo)入成功 |
| -1:導(dǎo)入失敗 |
舉例如下:
# 從當(dāng)前目錄加載yolov3-tiny模型
ret= rknn.load_darknet(model=‘./yolov3-tiny.cfg’,
weight=’./yolov3.weights’)
(3)Keras 模型加載接口
| API | load_keras |
| 描述 | 加載 Keras模型 |
| 參數(shù) | model:Keras模型文件(后綴為.h5)。必填參數(shù)。 |
| convert_engine:轉(zhuǎn)換引擎,可以是’Keras’或’tflite’。默認(rèn)轉(zhuǎn)換引擎為 Keras。可選參數(shù)。 | |
| 返回值 | 0:導(dǎo)入成功 |
| -1:導(dǎo)入失敗 |
舉例如下:
# 從當(dāng)前目錄加載 xception 模型 ret = rknn.load_keras(model=’./xception_v3.h5’)
(4)MXNet 模型加載接口
| API | load_mxnet |
| 描述 | 加載 MXNet模型 |
| 參數(shù) | symbol:MXNet模型的網(wǎng)絡(luò)結(jié)構(gòu)文件,后綴是json。必填參數(shù)。 |
| params:MXnet模型的參數(shù)文件,后綴是 params。必填參數(shù)。 | |
| input_size_list :每個輸入節(jié)點對應(yīng)的圖片的尺寸和通道數(shù)。例如 [[1,224,224],[ 3,224,224]]表示有兩個輸入,其中一個輸入的 shape是[1,224,224],另外一個輸入的 shape 是[3,224,224]。必填參數(shù)。 | |
| 返回值 |
0:導(dǎo)入成功 -1:導(dǎo)入失敗 |
舉例如下:
# 從當(dāng)前目錄加載 resnext50 模型
ret = rknn.load_mxnet(symbol=’resnext50_32x4d-symbol.json’,
params=’resnext50_32x4d-4ecf62e2.params’,
input_size_list=[[3,224,224]] )
(5)ONNX 模型加載
| API | load_onnx |
| 描述 | 加載ONNX模型 |
| 參數(shù) | model:ONNX模型文件(.onnx 后綴)所在路徑。 |
| inputs:指定模型的輸入節(jié)點,數(shù)據(jù)類型為列表。例如示例中的 resnet50v2模型,其輸入節(jié)點是['data']。默認(rèn)值是 None,此時工具自動從模型中查找輸入節(jié)點。可選參數(shù)。 | |
|
input_size_list:每個輸入節(jié)點對應(yīng)的數(shù)據(jù)形狀。例如示例中的 resnet50v2模型,其輸入節(jié)點對應(yīng)的輸入尺寸是[[3, 224, 224]]。可選參數(shù)。 注: 1. 填寫輸入數(shù)據(jù)形狀時不要填 batch 維。如果要批量推理,請使用 build 接口的 rknn_batch_size 參數(shù)。 2. 如果指定了 inputs 節(jié)點,則該參數(shù)必須填寫。 |
|
| outputs:指定模型的輸出節(jié)點,數(shù)據(jù)類型為列表。例如示例中的 resnet50v2模型,其 輸出節(jié)點是['resnetv24_dense0_fwd']。默認(rèn)值是 None,此時工具將自動從模型中搜索輸出節(jié)點。可選參數(shù)。 | |
| 返回值 |
0:導(dǎo)入成功 -1:導(dǎo)入失敗 |
舉例如下:
# 從當(dāng)前目錄加載 resnet50v2 模型
ret = rknn.load_onnx(model = './resnet50v2.onnx',
inputs = ['data'],
input_size_list = [[3, 224, 224]],
outputs=['resnetv24_dense0_fwd'])
(6)PyTorch 模型加載接口
| API | load_pytorch |
| 描述 | 加載 PyTorch模型 |
| 參數(shù) | model:PyTorch模型文件(.pt后綴)所在路徑,而且需要是 torchscript格式的模型。 必填參數(shù)。 |
| input_size_list :每個輸入節(jié)點對應(yīng)的圖片的尺寸和通道數(shù)。例如 [[1,224,224],[ 3,224,224]]表示有兩個輸入,其中一個輸入的 shape 是[1,224,224],另外一個輸入的 shape是[3,224,224]。必填參數(shù)。 | |
| 返回值 |
0:導(dǎo)入成功 -1:導(dǎo)入失敗 |
舉例如下:
# 從當(dāng)前目錄加載 resnet18 模型
ret = rknn. Load_pytorch(model = ‘./resnet18.pt’,
input_size_list=[[3,224,224]])
(7)TensorFlow 模型加載接口
| API | load_tensorflow |
| 描述 | 加載TensorFlow模型 |
| 參數(shù) | tf_pb:TensorFlow模型文件(.pb 后綴)所在路徑。 |
| inputs:模型輸入節(jié)點,支持多個輸入節(jié)點。所有輸入節(jié)點名放在一個列表中。 | |
| input_size_list:每個輸入節(jié)點對應(yīng)的數(shù)據(jù)形狀。如示例中的 mobilenet-v1模型,其輸入節(jié)點對應(yīng)的輸入尺寸是[[224, 224, 3]]。 | |
| outputs:模型的輸出節(jié)點,支持多個輸出節(jié)點。所有輸出節(jié)點名放在一個列表中。 | |
| predef_file:為了支持一些控制邏輯,需要提供一個npz格式的預(yù)定義文件。可以通過以下方法生成預(yù)定義文件:np.savez(‘prd.npz’,placeholder_name=prd_value)。如果 “placeholder_name”中包含’/’,請用’#’替換。 | |
| 返回值 | 0:導(dǎo)入成功 |
| -1:導(dǎo)入失敗 |
舉例如下:
# 從當(dāng)前目錄加載 ssd_mobilenet_v1_coco_2017_11_17 模型
ret = rknn.load_tensorflow(
tf_pb=’./ssd_mobilenet_v1_coco_2017_11_17.pb’,
inputs=[‘FeatureExtractor/MobilenetV1/MobilenetV1/Conv2d_0
/BatchNorm/batchnorm/mul_1’],
outputs=[‘concat’, ‘concat_1’],
input_size_list=[[300, 300, 3]])
(8)TensorFlow Lite 模型加載接口
| API | load_tflite |
| 描述 |
加載 TensorFlow Lite 模型。 注:因為tflite不同版本的schema之間是互不兼容的,所以構(gòu)建的tflite模型使用與RKNNToolkit不同版本的schema可能導(dǎo)致加載失敗。目前RKNN-Toolkit使用的tflite schema 是基于官網(wǎng) master 分支上的提交: 0c4f5dfea4ceb3d7c0b46fc04828420a344f7598。 官網(wǎng)地址如下: https://github.com/tensorflow/tensorflow/commits/master/tensorflow/lite/schema/schema.f bs |
| 參數(shù) | model:TensorFlow Lite 模型文件(.tflite 后綴)所在路徑 |
| 返回值 | 0:導(dǎo)入成功 |
| -1:導(dǎo)入失敗 |
舉例如下:
# 從當(dāng)前目錄加載 mobilenet_v1 模型 ret = rknn.load_tflite(model = ‘./mobilenet_v1.tflite’)
6.3.4 構(gòu)建 RKNN 模型
| API | build |
| 描述 | 依照加載的模型結(jié)構(gòu)及權(quán)重數(shù)據(jù),構(gòu)建對應(yīng)的 RKNN模型。 |
| 參數(shù) | do_quantization:是否對模型進(jìn)行量化,值為 True或 False。 |
|
ataset:量化校正數(shù)據(jù)的數(shù)據(jù)集。目前支持文本文件格式,用戶可以把用于校正的圖片(jpg或 png格式)或 npy文件路徑放到一個.txt 文件中。文本文件里每一行一條路徑信息。如: a.jpg b.jpg 或 a.npy b.npy 如有多個輸入,則每個輸入對應(yīng)的文件用空格隔開,如: a.jpg a2.jpg b.jpg b2.jpg 或 a.npy a2.npy b.npy b2.npy |
|
|
pre_compile:模型預(yù)編譯開關(guān)。預(yù)編譯 RKNN 模型可以減少模型初始化時間,但是無法通過模擬器進(jìn)行推理或性能評估。如果 NPU 驅(qū)動有更新,預(yù)編譯模型通常也需要重新構(gòu)建。 注: 1. 該選項只在 Linux x86_64 平臺上有效。 2. RKNN-Toolkit-V1.0.0 及以上版本生成的預(yù)編譯模型不能在 NPU 驅(qū)動版本小于0.9.6 的設(shè)備上運行;RKNN-Toolkit-V1.0.0 以前版本生成的預(yù)編譯模型不能在NPU 驅(qū) 動 版 本 大 于 等 于 0.9.6 的 設(shè) 備 上 運 行 。 驅(qū) 動 版 本 號 可 以 通 過get_sdk_version 接口查詢。 |
|
|
rknn_batch_size:模型的輸入 Batch 參數(shù)調(diào)整,默認(rèn)值為 1。如果大于 1,則可以在一次推理中同時推理多幀輸入圖像或輸入數(shù)據(jù),如 MobileNet 模型的原始input 維度為[1, 224, 224, 3],output 維度為[1, 1001],當(dāng) rknn_batch_size 設(shè)為 4 時,input 的維度變?yōu)閇4, 224, 224, 3],output 維度變?yōu)閇4, 1001]。 注: 1. rknn_batch_size 的調(diào)整并不會提高一般模型在 NPU 上的執(zhí)行性能,但卻會顯著增加內(nèi)存消耗以及增加單幀的延遲。 2. rknn_batch_size 的調(diào)整可以降低超小模型在 CPU 上的消耗,提高超小模型的平均幀率。(適用于模型太小,CPU 的開銷大于 NPU 的開銷)。 3. rknn_batch_size 的值建議小于 32,避免內(nèi)存占用太大而導(dǎo)致推理失敗。 4. rknn_batch_size 修改后,模型的 input/output 維度會被修改,使用 inference 推理模型時需要設(shè)置相應(yīng)的 input 的大小,后處理時,也需要對返回的 outputs 進(jìn)行處理。 |
|
| 返回值 |
0:構(gòu)建成功 -1:構(gòu)建失敗 |
注:如果在執(zhí)行腳本前設(shè)置RKNN_DRAW_DATA_DISTRIBUTE 環(huán)境變量的值為1,則 RKNN Toolkit會將每一層的weihgt/bias(如果有)和輸出數(shù)據(jù)的直方圖保存在當(dāng)前目錄下的 dump_data_distribute文件夾中。使用該功能時推薦只在dataset.txt中存放單獨一個(組)輸入。
舉例如下:
# 構(gòu)建 RKNN 模型,并且做量化 ret = rknn.build(do_quantization=True, dataset='./dataset.txt')
6.3.5 導(dǎo)出 RKNN 模型
通過該接口導(dǎo)出 RKNN 模型文件,用于模型部署。
| API | export_rknn |
| 描述 | 將 RKNN模型保存到指定文件中(.rknn 后綴)。 |
| 參數(shù) | export_path:導(dǎo)出模型文件的路徑。 |
| 返回值 | 0:導(dǎo)入成功 ; |
| -1:導(dǎo)入失敗 |
舉例如下:
…… # 將構(gòu)建好的 RKNN 模型保存到當(dāng)前路徑的 mobilenet_v1.rknn 文件中 ret = rknn.export_rknn(export_path = './mobilenet_v1.rknn') ……
6.3.6 加載 RKNN模型
| API | load_rknn |
| 描述 | 加載 RKNN 模型。 |
| 參數(shù) | path:RKNN模型文件路徑。 |
| load_model_in_npu:是否直接加載npu中的rknn模型。其中path為rknn 模型在npu中的路徑。只有當(dāng)RKNN-Toolkit運行在RK3399Pro Linux 開發(fā)板或連有 NPU 設(shè)備 的 PC 上時才可以設(shè)為 True。默認(rèn)值為 False。 | |
| 返回值 | 0:導(dǎo)入成功 |
| -1:導(dǎo)入失敗 |
舉例如下:
# 從當(dāng)前路徑加載 mobilenet_v1.rknn 模型 ret = rknn.load_rknn(path='./mobilenet_v1.rknn')
6.3.7 初始化運行時環(huán)境
在模型推理或性能評估之前,必須先初始化運行時環(huán)境,明確模型在的運行平臺(具體的目標(biāo)硬件平臺或軟件模擬器)。
| API | init_runtime |
| 描述 | 初始化運行時環(huán)境。確定模型運行的設(shè)備信息(硬件平臺信息、設(shè)備 ID);性能評估時是否啟用debug 模式,以獲取更詳細(xì)的性能信息。 |
| 參數(shù) | target:目標(biāo)硬件平臺,目前支持“rk3399pro”、“rk1806”、“rk1808”、“rv1109”、 “rv1126”。默認(rèn)為 None,即在 PC 使用工具時,模型在模擬器上運行,在RK3399Pro Linux 開發(fā)板運行時,模型在RK3399Pro自帶NPU上運行,否則在設(shè)定的target上 運行。其中“rk1808”包含了TB-RK1808 AI 計算棒。 |
|
device_id:設(shè)備編號,如果PC連接多臺設(shè)備時,需要指定該參數(shù),設(shè)備編號可以通過”list_devices”接口查看。默認(rèn)值為 None。 注:MAC OS X 系統(tǒng)當(dāng)前版本還不支持多個設(shè)備。 |
|
| perf_debug:進(jìn)行性能評估時是否開啟debug 模式。在 debug 模式下,可以獲取到每一層的運行時間,否則只能獲取模型運行的總時間。默認(rèn)值為 False。 | |
| eval_mem: 是否進(jìn)入內(nèi)存評估模式。進(jìn)入內(nèi)存評估模式后,可以調(diào)用 eval_memory 接口獲取模型運行時的內(nèi)存使用情況。默認(rèn)值為 False。 | |
| async_mode:是否使用異步模式。調(diào)用推理接口時,涉及設(shè)置輸入圖片、模型推理、獲取推理結(jié)果三個階段。如果開啟了異步模式,設(shè)置當(dāng)前幀的輸入將與推理上一幀同時進(jìn)行,所以除第一幀外,之后的每一幀都可以隱藏設(shè)置輸入的時間,從而提升性能。 在異步模式下,每次返回的推理結(jié)果都是上一幀的。該參數(shù)的默認(rèn)值為 False。 | |
| 返回值 | 0:構(gòu)建成功 |
| -1:構(gòu)建失敗 |
舉例如下:
# 初始化運行時環(huán)境
ret = rknn.init_runtime(target='rk1808', device_id='012345789AB')
if ret != 0:
print('Init runtime environment failed')
exit(ret)
6.3.8 模型推理
在進(jìn)行模型推理前,必須先構(gòu)建或加載一個 RKNN 模型。
| API | inference |
| 描述 |
對當(dāng)前模型進(jìn)行推理,返回推理結(jié)果。 如果 RKNN-Toolkit運行在PC上,且初始化運行環(huán)境時設(shè)置 target 為Rockchip NPU設(shè)備,得到的是模型在硬件平臺上的推理結(jié)果。 如果 RKNN-Toolkit 運行在PC上,且初始化運行環(huán)境時沒有設(shè)置 target,得到的是模型在模擬器上的推理結(jié)果。模擬器可以模擬 RK1808,也可以模擬RV1126,具體模擬哪款芯片,取決于RKNN 模型的 target_platform 參數(shù)值。 如果 RKNN-Toolkit運行在 RK3399Pro Linux開發(fā)板上,得到的是模型在實際硬件上的推理結(jié)果。 |
| 參數(shù) | inputs:待推理的輸入,如經(jīng)過 cv2 處理的圖片。格式是 ndarray list。 |
| data_type:輸入數(shù)據(jù)的類型,可填以下值:’float32’, ‘float16’, ‘int8’, ‘uint8’, ‘int16’。默認(rèn)值為’uint8’。 | |
| data_format:數(shù)據(jù)模式,可以填以下值: “nchw”, “nhwc”。默認(rèn)值為’nhwc’。這兩個的 不同之處在于 channel 放置的位置。 | |
| inputs_pass_through:將輸入透傳給NPU 驅(qū)動。非透傳模式下,在將輸入傳給NPU驅(qū)動之前,工具會對輸入進(jìn)行減均值、除方差等操作;而透傳模式下,不會做這些操作。這個參數(shù)的值是一個數(shù)組,比如要透傳input0,不透徹input1,則這個參數(shù)的值為[1, 0]。默認(rèn)值為None,即對所有輸入都不透傳。 | |
| 返回值 | results:推理結(jié)果,類型是 ndarray list。 |
對于分類模型,如mobilenet_v1,模型推理代碼如下(完整代碼參考 example/tflite/mobilent_v1):
# 使用模型對圖片進(jìn)行推理,輸出 TOP5 …… outputs = rknn.inference(inputs=[img]) show_outputs(outputs) ……
輸出的 TOP5 結(jié)果如下:
-----TOP 5----- [156]: 0.85107421875 [155]: 0.09173583984375 [205]: 0.01358795166015625 [284]: 0.006465911865234375 [194]: 0.002239227294921875
6.3.9 模型性能評估
| API | eval_perf |
| 描述 | 評估模型性能。模型運行在PC上,初始化運行環(huán)境時不指定 target,得到的是模型在模擬器上運行的性能數(shù)據(jù),包含逐層的運行時間及模型完整運行一次需要的時間。模擬器可以模擬 RK1808,也可以模擬 RV1126,具體模擬哪款芯片,取決于RKNN模型的target_platform參數(shù)值。 模型運行在與PC連接的Rockchip NPU上,且初始化運行環(huán)境時設(shè)置perf_debug為False,則獲得的是模型在硬件上運行的總時間;如果設(shè)置perf_debug為 True,除了返回總時間外,還將返回每一層的耗時情況。模型運行在RK3399Pro Linux開發(fā)板上時,如果初始化運行環(huán)境時設(shè)置perf_debug為False,獲得的也是模型在硬件上運行的總時間;如果設(shè)置perf_debug為 True,返回總時間及每一層的耗時情況。 |
| 參數(shù) | loop_cnt::指定RKNN模型推理次數(shù),用于計算平均推理時間。該參數(shù)只在init_runtime中的 target為非模擬器,且perf_debug設(shè)成 False時生效。該參數(shù)數(shù)據(jù)類型為整型,默認(rèn)值為 1。 |
| 返回值 | perf_result:性能評估結(jié)果,詳細(xì)說明請參考 5.3 章節(jié)。 |
舉例如下:
# 對模型性能進(jìn)行評估 …… rknn.eval_perf(inputs=[image], is_print=True) ……
6.3.10 獲取內(nèi)存使用情況
| API | eval_memory |
| 描述 |
獲取模型在硬件平臺運行時的內(nèi)存使用情況。 模型必須運行在與 PC 連接的 Rockchip NPU 設(shè)備上,或直接運行在 RK3399Pro Linux 開發(fā)板上。 注: 1. 使用該功能時,對應(yīng)的驅(qū)動版本必須要大于等于 0.9.4。驅(qū)動版本可以通過 get_sdk_version 接口查詢。 |
| 參數(shù) | is_print: 是否以規(guī)范格式打印內(nèi)存使用情況。默認(rèn)值為 True。 |
| 返回值 | memory_detail:內(nèi)存使用情況。詳細(xì)說明請參考 6.3 章節(jié)。 |
舉例如下:
# 對模型內(nèi)存使用情況進(jìn)行評估 …… memory_detail = rknn.eval_memory() ……
如 example/tflite 中的 mobilenet_v1,它在 RK1808 上運行時內(nèi)存占用情況如下:
============================================== Memory Profile Info Dump ============================================== System memory: maximum allocation : 22.65 MiB total allocation : 72.06 MiB NPU memory: maximum allocation : 33.26 MiB total allocation : 34.57 MiB Total memory: maximum allocation : 55.92 MiB total allocation : 106.63 MiB INFO: When evaluating memory usage, we need consider the size of model, current model size is: 4.10 MiB ==============================================
6.3.11 混合量化
(1)hybrid_quantization_step1
使用混合量化功能時,第一階段調(diào)用的主要接口是 hybrid_quantization_step1,用于生成模型結(jié)構(gòu)文件( {model_name}.json )、權(quán)重文件( {model_name}.data ) 和量化配置文件({model_name}.quantization.cfg)。接口詳情如下:
| API | hybrid_quantization_step1 |
| 描述 | 根據(jù)加載的原始模型,生成對應(yīng)的模型結(jié)構(gòu)文件、權(quán)重文件和量化配置文件。 |
| 參數(shù) |
dataset::量化校正數(shù)據(jù)的數(shù)據(jù)集。目前支持文本文件格式,用戶可以把用于校正的圖片(jpg或 png格式)或npy文件路徑放到一個.txt 文件中。文本文件里每一行一條路徑信息。 如: a.jpg b.jpg 或 a.npy b.npy |
| 返回值 |
0:成功 -1:失敗 |
舉例如下:
# Call hybrid_quantization_step1 to generate quantization config …… ret = rknn.hybrid_quantization_step1(dataset='./dataset.txt') ……
(2)hybrid_quantization_step2
使用混合量化功能時,生成混合量化 RKNN模型階段調(diào)用的主要接口是 hybrid_quantization_step2。接口詳情如下:
| API | hybrid_quantization_step2 |
| 描述 | 接收模型結(jié)構(gòu)文件、權(quán)重文件、量化配置文件、校正數(shù)據(jù)集作為輸入,生成混合量化后的 RKNN 模型。 |
| 參數(shù) | model_input:第一步生成的模型結(jié)構(gòu)文件,例如“{model_name}.json”。數(shù)據(jù)類型為字符串。必填參數(shù)。 |
| data_input:第一步生成的權(quán)重數(shù)據(jù)文件,例如“{model_name}.data”。數(shù)據(jù)類型為字符串。必填參數(shù)。 | |
|
dataset:量化校正數(shù)據(jù)的數(shù)據(jù)集。目前支持文本文件格式,用戶可以把用于校正的圖片(jpg 或 png 格式)或 npy 文件路徑放到一個.txt 文件中。文本文件里每一行一條路徑信息。 如: a.jpg b.jpg 或 a.npy b.npy |
|
|
pre_compile:模型預(yù)編譯開關(guān)。預(yù)編譯 RKNN模型可以減少模型初始化時間,但是無法通過模擬器進(jìn)行推理或性能評估。如果 NPU 驅(qū)動有更新,預(yù)編譯模型通常也需要重新構(gòu)建。 注: 1. 該選項不能在 RK3399Pro Linux 開發(fā)板/Windows PC/Mac OS X PC 上使用。 2. RKNN-Toolkit-V1.0.0及以上版本生成的預(yù)編譯模型不能在 NPU 驅(qū)動版本小于0.9.6 的設(shè)備上運行;RKNN-Toolkit-V1.0.0 以前版本生成的預(yù)編譯模型不能在NPU驅(qū)動版本大于等于 0.9.6 的設(shè)備上運行。驅(qū)動版本號可以通過get_sdk_version 接口查詢。 |
|
| 返回值 | 0:成功 |
| -1:失敗 |
舉例如下:
# Call hybrid_quantization_step2 to generate hybrid quantized RKNN model
……
ret = rknn.hybrid_quantization_step2(
model_input='./ssd_mobilenet_v2.json',
data_input='./ssd_mobilenet_v2.data',
model_quantization_cfg='./ssd_mobilenet_v2.quantization.cfg',
dataset='./dataset.txt')
……
6.3.12 量化精度分析
| API | accuracy_analysis |
| 描述 |
逐層對比浮點模型和量化模型的輸出結(jié)果,輸出余弦距離和歐式距離,用于分析量化模型精度下降原因。 注: 1.該接口在build或hybrid_quantization_step1或 hybrid_quantization_step2之后調(diào)用,并且原始模型應(yīng)該為浮點模型,否則會調(diào)用失敗。 2. 該接口使用的量化方式與 config 中指定的一致。 |
| inputs:包含輸入圖像或數(shù)據(jù)的數(shù)據(jù)集文本文件(與量化校正數(shù)據(jù)集 dataset 格式相同, 但只能包含一組輸入)。 | |
| output_dir:輸出目錄,所有快照都保存在該目錄。該目錄內(nèi)容的詳細(xì)說明見 4.3.3 章 節(jié)。 | |
| calc_qnt_error:是否計算量化誤差(默認(rèn)為 True)。 | |
| target:指定設(shè)備類型。如果指定 target,在逐層量化誤差分析時,將連接到 NPU上獲取每一層的真實結(jié)果,跟浮點模型結(jié)果相比較。這樣可以更準(zhǔn)確的反映實際運行時的誤差。 | |
| device_id:如果 PC 連接了多個NPU設(shè)備,需要指定具體的設(shè)備編號。 | |
| dump_file_type:精度分析過程中會輸出模型每一層的結(jié)果,這個參數(shù)指定了輸出文件的類型。有效值為’tensor’和’npy’,默認(rèn)值是’tensor’。如果指定數(shù)據(jù)類型為’npy’, 可以減少精度分析的耗時。 | |
| 返回值 | 0:成功 |
| -1:失敗 |
注:如果在執(zhí)行腳本前設(shè)置 RKNN_DRAW_DATA_DISTRIBUTE 環(huán)境變量的值為 1,則 RKNNToolkit 會將每一層的 weihgt/bias(如果有)和輸出數(shù)據(jù)的直方圖保存在當(dāng)前目錄下的 dump_data_distribute 文件夾中。
舉例如下:
……
print('--> config model')
rknn.config(channel_mean_value='0 0 0 1', reorder_channel='0 1 2')
print('done')
print('--> Loading model')
ret = rknn.load_onnx(model='./mobilenetv2-1.0.onnx')
if ret != 0:
print('Load model failed! Ret = {}'.format(ret))
exit(ret)
print('done')
# Build model
print('--> Building model')
ret = rknn.build(do_quantization=True, dataset='./dataset.txt')
if ret != 0:
print('Build rknn failed!')
exit(ret)
print('done')
print('--> Accuracy analysis')
rknn.accuracy_analysis(inputs='./dataset.txt', target='rk1808')
print('done')
……
6.3.13 注冊自定義算子
| API | register_op |
| 描述 | 注冊自定義算子。 |
| 參數(shù) | op_path:算子編譯生成的 rknnop 文件的路徑 |
| 返回值 | 無 |
參考代碼如下所示。注意,該接口要在模型轉(zhuǎn)換前調(diào)用。自定義算子的使用和開發(fā)請參考 《Rockchip_Developer_Guide_RKNN_Toolkit_Custom_OP_CN》文檔。
rknn.register_op('./resize_area/ResizeArea.rknnop')
rknn.load_tensorflow(…)
6.3.14 導(dǎo)出預(yù)編譯模型(在線預(yù)編譯)
構(gòu)建RKNN模型時,可以指定預(yù)編譯選項以導(dǎo)出預(yù)編譯模型,這被稱為離線編譯。同樣,RKNN Toolkit 也提供在線編譯的接口:export_rknn_precompile_model。使用該接口,可以將普通 RKNN 模型轉(zhuǎn)成預(yù)編譯模型。
| API | export_rknn_precompile_model |
| 描述 |
經(jīng)過在線編譯后導(dǎo)出預(yù)編譯模型。 注: 1. 使用該接口前必須先調(diào)用 load_rknn 接口加載普通 rknn 模型; 2. 使用該接口前必須調(diào)用 init_runtime 接口初始化模型運行環(huán)境,target 必須是RK NPU 設(shè)備,不能是模擬器;而且要設(shè)置 rknn2precompile 參數(shù)為 True。 |
| 參數(shù) | export_path:導(dǎo)出模型路徑。必填參數(shù)。 |
| 返回值 |
0:成功 -1:失敗 |
舉例如下:
from rknn.api import RKNN
if __name__ == '__main__':
# Create RKNN object
rknn = RKNN()
# Load rknn model
ret = rknn.load_rknn('./test.rknn')
if ret != 0:
print('Load RKNN model failed.')
exit(ret)
# init runtime
ret = rknn.init_runtime(target='rk1808', rknn2precompile=True)
if ret != 0:
print('Init runtime failed.')
exit(ret)
# Note: the rknn2precompile must be set True when call init_runtime
ret = rknn.export_rknn_precompile_model('./test_pre_compile.rknn')
if ret != 0:
print('export pre-compile model failed.')
exit(ret)
rknn.release()
6.3.15 導(dǎo)出分段模型
該接口的功能是將普通的 RKNN 模型轉(zhuǎn)成分段模型,分段的位置由用戶指定。
| API | export_rknn_sync_model |
| 描述 | 在用戶指定的模型層后面插入sync層,用于將模型分段,并導(dǎo)出分段后的模型。 |
| 參數(shù) | input_model: 待分段的rknn模型路徑。數(shù)據(jù)類型為字符串。必填參數(shù)。 |
|
sync_uids: 待插入 sync 節(jié)點層的層uid列表,RKNN-Toolkit 將在這些層后面插入sync層。 注: 1. uid 只能通過 eval_perf 接口獲取,且需要在 init_runtime 時設(shè)置 perf_debug 為True,target 不能是模擬器。 2. uid 的值不可以隨意填寫,一定需要是在 eval_perf 獲取性能詳情的 uid 列表中,否則可能出現(xiàn)不可預(yù)知的結(jié)果。 |
|
| output_model:導(dǎo)出模型的保存路徑。數(shù)據(jù)類型:字符串。默認(rèn)值為 None,如果不填該參數(shù),導(dǎo)出的模型將保存在 input_model 指定的文件中。 | |
| 返回值 | 0:成功 |
| -1:失敗 |
舉例如下:
from rknn.api import RKNN
if __name__ == '__main__':
rknn = RKNN()
ret = rknn.export_rknn_sync_model(
input_model='./ssd_inception_v2.rknn',
sync_uids=[206, 186, 152, 101, 96, 67, 18, 17],
output_model='./ssd_inception_v2_sync.rknn')
if ret != 0:
print('export sync model failed.')
exit(ret)
rknn.release()
6.3.16 導(dǎo)出加密模型
該接口的功能是將普通的 RKNN 模型進(jìn)行加密,得到加密后的模型。
| API | export_encrypted_rknn_model |
| 描述 | 根據(jù)用戶指定的加密等級對普通的 RKNN 模型進(jìn)行加密。 |
| 參數(shù) | input_model:待加密的RKNN模型路徑。數(shù)據(jù)類型為字符串。必填參數(shù)。 |
| output_model:模型加密后的保存路徑。數(shù)據(jù)類型為字符串。選填參數(shù),如果不填該參數(shù),則使用{original_model_name}.crypt.rknn作為加密后的模型的名字。 | |
| crypt_level:加密等級。等級越高,安全性越高,解密越耗時;反之,安全性越低,解密越快。數(shù)據(jù)類型為整型,默認(rèn)值為 1,目前安全等級有 3 個等級,1,2 和 3。 | |
| 返回值 | 0:成功 |
| -1:失敗 |
舉例如下:
from rknn.api import RKNN
if __name__ == '__main__':
rknn = RKNN()
ret = rknn.export_encrypted_rknn_model('test.rknn')
if ret != 0:
print('Encrypt RKNN model failed.')
exit(ret)
rknn.release()
6.3.17 查詢 SDK 版本
| API | get_sdk_version |
| 描述 |
獲取 SDK API 和驅(qū)動的版本號。 注:使用該接口前必須完成模型加載和初始化運行環(huán)境。且該接口只有在target是 Rockchip NPU 或 RKNN-Toolkit 運行在 RK3399Pro Linux 開發(fā)板才可以使用。 |
| 參數(shù) | 無 |
| 返回值 | sdk_version:API 和驅(qū)動版本信息。類型為字符串。 |
舉例如下:
# 獲取 SDK 版本信息 …… sdk_version = rknn.get_sdk_version() ……
返回的 SDK 信息如下:
==============================================
RKNN VERSION:
API: 1.7.1 (566a9b6 build: 2021-10-28 14:53:41)
DRV: 1.7.1 (566a9b6 build: 2021-11-12 20:24:57)
==============================================
6.3.18 獲取設(shè)備列表
| API | list_devices |
| 描述 |
列出已連接的RK3399PRO/RK1808/RV1109/RV1126或TB-RK1808 AI 計算棒。 注:目前設(shè)備連接模式有兩種:ADB 和 NTB。其中RK3399PRO 目前只支持ADB 模 式,TB-RK1808 AI計算棒只支持NTB模式,RK1808/RV1109 支持 ADB/NTB 模式。多設(shè)備連接時請確保他們的模式都是一樣的。 |
| 參數(shù) | 無 |
| 返回值 |
返回adb_devices列表和ntb_devices 列表,如果設(shè)備為空,則返回空列表。例如我們的環(huán)境里插了兩個 TB-RK1808 AI 計算棒,得到的結(jié)果如下: adb_devices = [] ntb_devices = ['TB-RK1808S0', '515e9b401c060c0b'] |
舉例如下:
from rknn.api import RKNN
if __name__ == '__main__':
rknn = RKNN()
rknn.list_devices()
rknn.release()
返回的設(shè)備列表信息如下(這里有兩個 RK1808 開發(fā)板,它們的連接模式都是 adb):
************************* all device(s) with adb mode: ['515e9b401c060c0b', 'XGOR2N4EZR'] *************************
注:使用多設(shè)備時,需要保證它們的連接模式都是一致的,否則會引起沖突,導(dǎo)致設(shè)備通信失敗。
6.3.19 查詢模型可運行平臺
| API | list_support_target_platform |
| 描述 | 查詢給定 RKNN 模型可運行的芯片平臺。 |
| 參數(shù) | rknn_model:RKNN模型路徑。如果不指定模型路徑,則按類別打印 RKNN-Toolkit 當(dāng)前支持的芯片平臺。 |
| 返回值 | support_target_platform: Returns runnable chip platforms, or None if the model path is empty. |
參考代碼如下所示:
rknn.list_support_target_platform(rknn_model=’mobilenet_v1.rknn’)
參考結(jié)果如下:
************************************************** Target platforms filled in RKNN model: [] Target platforms supported by this RKNN model: ['RK1806', 'RK1808', 'RK3399PRO'] **************************************************
7. 模型部署
模型轉(zhuǎn)換為rknn模型后,需再參考NPU API說明文檔,編寫應(yīng)用工程。經(jīng)過編譯后傳輸至EASY EAI Nano平臺上實現(xiàn)部署。
7.1 模型部署示例
7.1.1 模型部署示例介紹
本小節(jié)展示yolov5模型的在EASY EAI Nano的部署過程,該模型僅經(jīng)過簡單訓(xùn)練供示例使用,不保證模型精度。
7.1.2 準(zhǔn)備工作
(1)硬件準(zhǔn)備
EASY EAI Nano開發(fā)板,microUSB數(shù)據(jù)線,帶linux操作系統(tǒng)的電腦。需保證EASY EAI Nano與linux系統(tǒng)保持adb連接。
(2)開發(fā)環(huán)境準(zhǔn)備
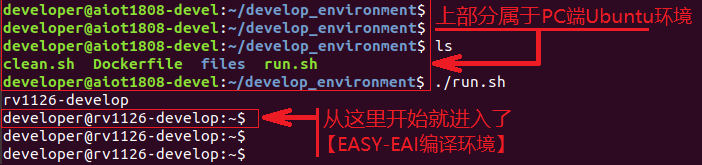
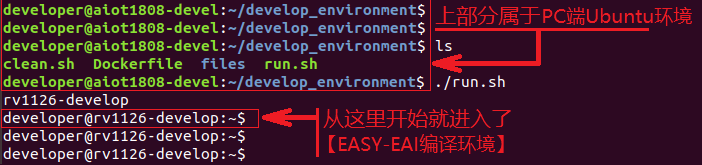
如果您初次閱讀此文檔,請閱讀《入門指南/開發(fā)環(huán)境準(zhǔn)備/Easy-Eai編譯環(huán)境準(zhǔn)備與更新》,并按照其相關(guān)的操作,進(jìn)行編譯環(huán)境的部署。
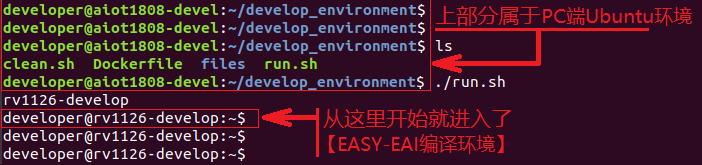
在PC端Ubuntu系統(tǒng)中執(zhí)行run腳本,進(jìn)入EASY-EAI編譯環(huán)境,具體如下所示。
cd ~/develop_environment ./run.sh
7.1.3 源碼下載以及例程編譯
下載yolov5 C Demo示例文件。
百度網(wǎng)盤鏈接:https://pan.baidu.com/s/1xmEgBGQCMrvHm9kfU9uBkg (提取碼:lanz )。
下載解壓后如下圖所示:
在EASY-EAI編譯環(huán)境下,切換到例程目錄執(zhí)行編譯操作:
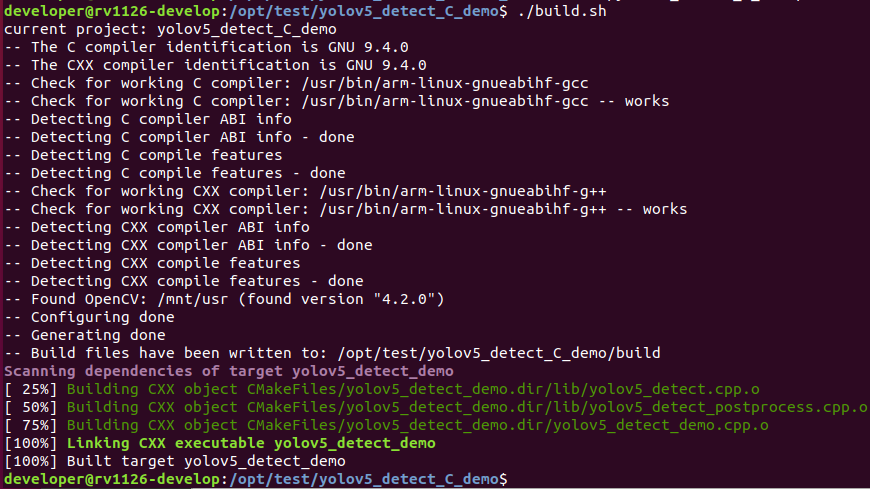
cd /opt/test/yolov5_detect_C_demo ./build.sh
注:
* 由于依賴庫部署在板卡上,因此交叉編譯過程中必須保持adb連接。
7.1.4 在開發(fā)板執(zhí)行yolov5 demo
在EASY-EAI編譯環(huán)境下,在例程目錄執(zhí)行以下指令把可執(zhí)行程序推送到開發(fā)板端:
cp yolov5_detect_demo_release/ /mnt/userdata/ -rf
通過按鍵Ctrl+Shift+T創(chuàng)建一個新窗口,執(zhí)行adb shell命令,進(jìn)入板卡運行環(huán)境:
adb shell
進(jìn)入板卡后,定位到例程上傳的位置,如下所示:
cd /userdata/yolov5_detect_demo_release/
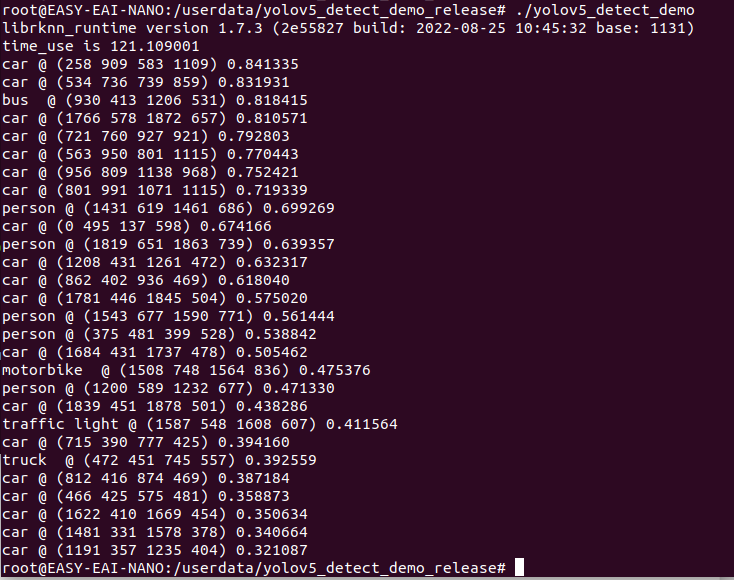
運行例程命令如下所示:
./yolov5_detect_demo
執(zhí)行結(jié)果如下圖所示:
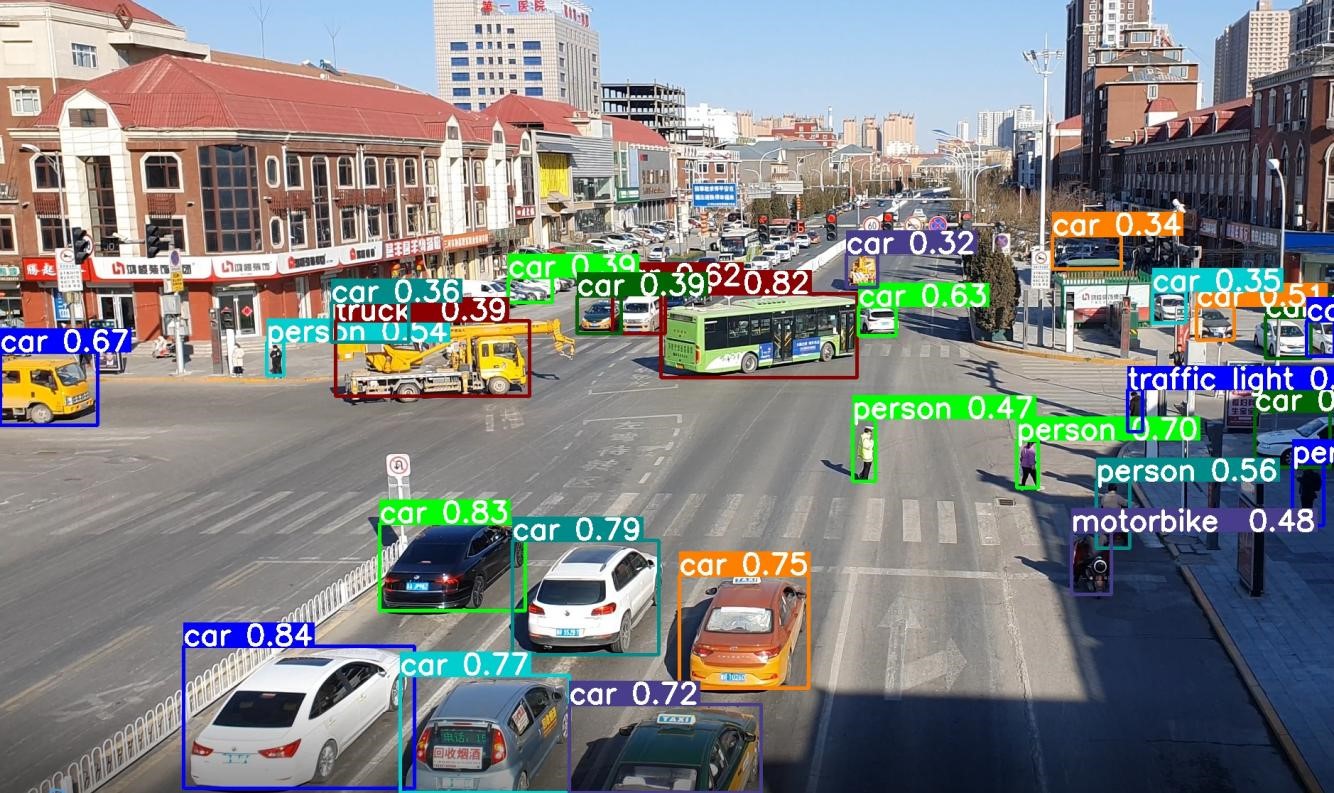
退出板卡環(huán)境,取回測試圖片:
exit adb pull /userdata/yolov5_detect_demo_release/result.jpg .
測試結(jié)果如下圖所示:
7.2 模型部署API說明
7.2.1 API流程說明
從 RKNN API V1.6.0 版本開始,新增加了一組設(shè)置輸入的函數(shù):
rknn_inputs_map
rknn_inputs_sync
rknn_inputs_unmap
以及一組獲取輸出的函數(shù):
rknn_outputs_map
rknn_outputs_sync
rknn_outputs_unmap
在設(shè)置輸入時,用戶可以使用 rknn_inputs_set 或者 rknn_inputs_map 系列函數(shù)。獲取推理的輸出時,使用 rknn_outputs_get 或者 rknn_outputs_map 系列函數(shù)。特定場景下,使用 map 系列接口可以減少內(nèi)存拷貝的次數(shù),提高完整推理的速度。
rknn_inputs_map 系列接口和 rknn_inputs_set 接口的調(diào)用流程不同 rknn_outputs_map 系列接口和rknn_outputs_get 接口的調(diào)用流程也不同。兩個系列API調(diào)用流程差異如下圖所示,其中圖 1.1(a)為set/get系列接口調(diào)用流程,圖 1.1(b)為map系列接口調(diào)用流程。
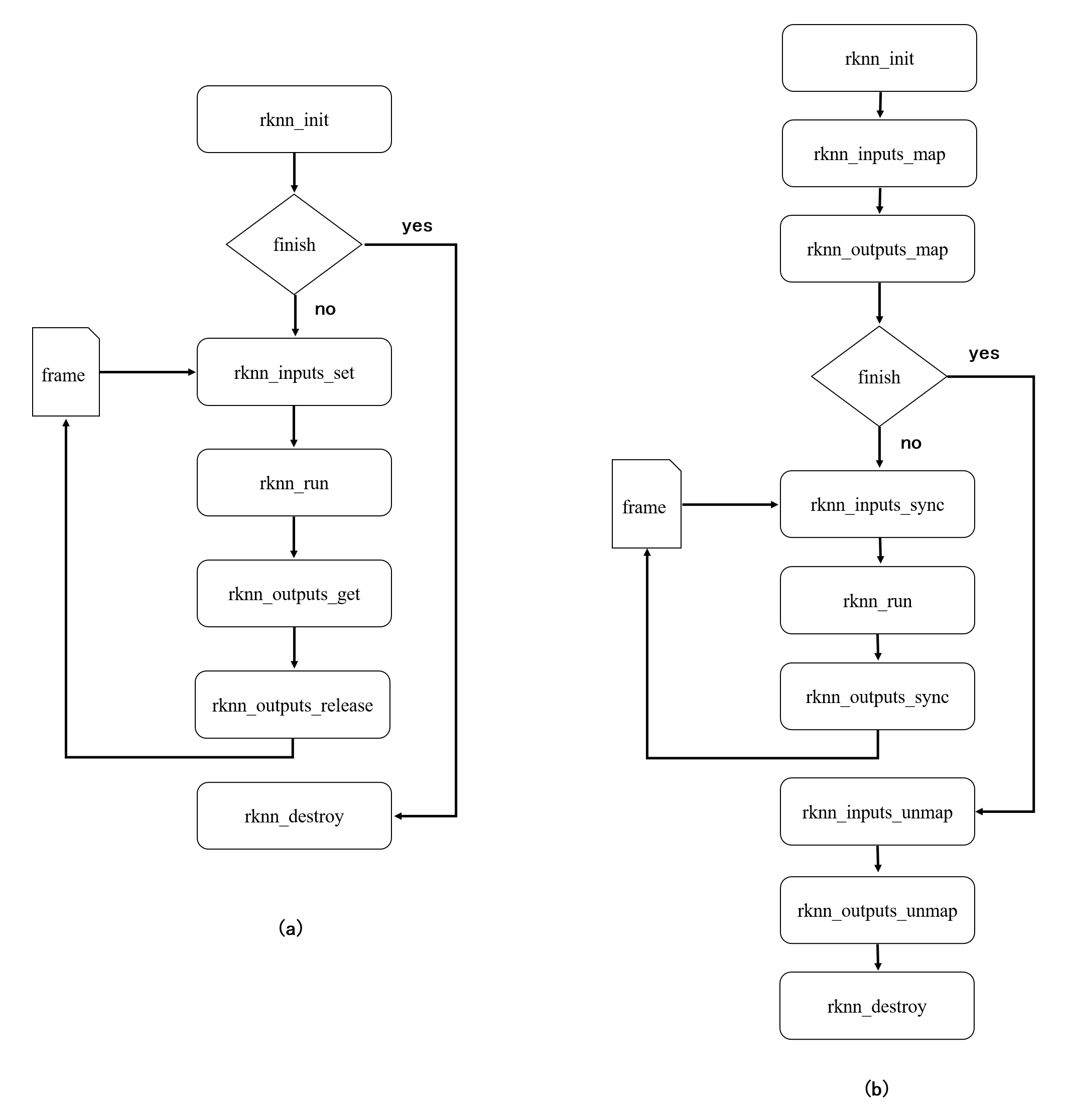 圖 1.1? 使用 set/get 系列(a)和 map 系列(b)接口流
圖 1.1? 使用 set/get 系列(a)和 map 系列(b)接口流
設(shè)置輸入和獲取輸出接口沒有綁定關(guān)系,因此可以混合使用 set/get 系列接口和 map 系列接口。如圖 1.2(a),用戶可以使用 rknn_inputs_map 系列接口設(shè)置輸入,再通過rknn_outputs_get 接口獲取輸出,或者如圖 1.2(b)通過 rknn_inputs_set 系列接口設(shè)置 輸入,再使用 rknn_outputs_map 接口獲取輸出。
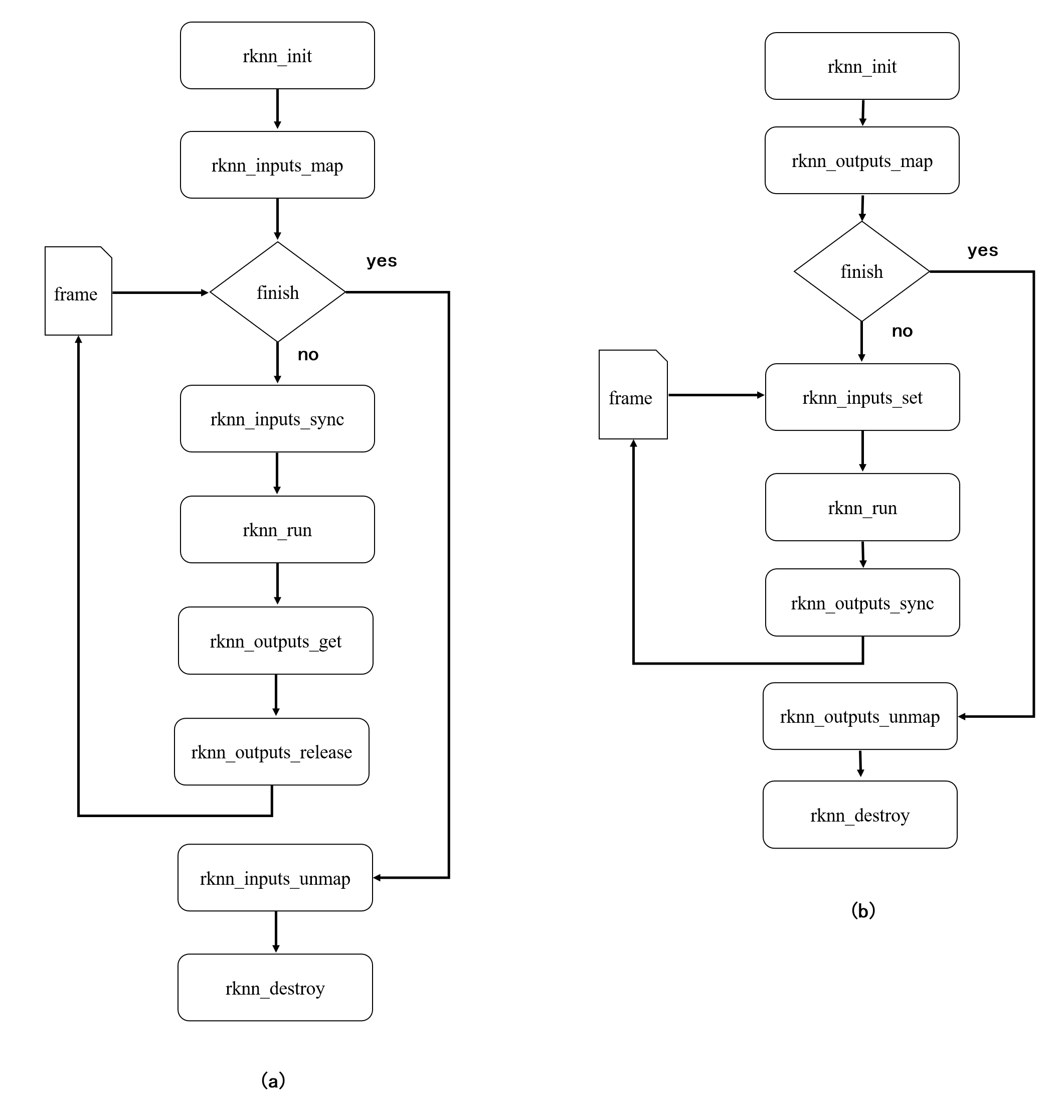 圖 1.2? 混合使用 set/get 系列和 map 系列接口的調(diào)用流程
圖 1.2? 混合使用 set/get 系列和 map 系列接口的調(diào)用流程
(1)API內(nèi)部處理流程
在推理 RKNN 模型時,原始數(shù)據(jù)要經(jīng)過輸入處理、NPU 運行模型、輸出處理三大流程。
在典型的圖片推理場景中,假設(shè)輸入數(shù)據(jù) data 是 3 通道的圖片且為 NHWC 排布格式,運行時(Runtime)對數(shù)據(jù)處理的流程如圖 1.3所示。在 API 層面上,rknn_inputs_set 接口(當(dāng) pass_through=0 時,詳見 rknn_input 結(jié)構(gòu)體)包含了顏色通道交換、歸一化、量化、NHWC 轉(zhuǎn)換成 NCHW 的過程,rknn_outputs_get 接口(當(dāng)want_float=1時,詳見 rknn_output 結(jié)構(gòu)體)包含了反量化的過程。
 圖 1.3? 完整的圖片數(shù)據(jù)處理流
圖 1.3? 完整的圖片數(shù)據(jù)處理流
(2)量化和反量化
當(dāng)使用rknn_inputs_set(pass_through=1)和 rknn_inputs_map 時,表明在 NPU 推理之前的流程要用戶處理。rknn_outputs_map獲取輸出后,用戶也要做反量化得到 32位浮點結(jié)果。
量化和反量化用到的量化方式、量化數(shù)據(jù)類型以及量化參數(shù),可以通過 rknn_query 接口查詢。目前,RK1808/RK3399Pro/RV1109/RV1126 (EASY EAI Nano為RV1126)的NPU有非對稱量化和動態(tài)定點 量化兩種量化方式,每種量化方式指定相應(yīng)的量化數(shù)據(jù)類型。總共有以下四種數(shù)據(jù)類型和量化方式組合:
uint8(非對稱量化)
int8(動態(tài)定點)
int16(動態(tài)定點)
float16(無)
通常,歸一化后的數(shù)據(jù)用 32 位浮點數(shù)保存,32 位浮點轉(zhuǎn)換成 16 位浮點數(shù)請參考 IEEE-754標(biāo)準(zhǔn)。假設(shè)歸一化后的32位浮點數(shù)據(jù)是D,下面介紹量化流程:
(2.1)float32 轉(zhuǎn) uint8
假設(shè)輸入tensor的非對稱量化參數(shù)是S(q),ZP ,數(shù)據(jù)D量化過程表示為下式:
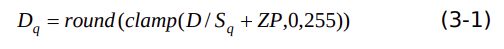
上式中,clamp表示將數(shù)值限制在某個范圍。round表示做舍入處理。
(2.2)float32 轉(zhuǎn) int8
假設(shè)輸入tensor的動態(tài)定點量化參數(shù)是fl,數(shù)據(jù) D 量化過程表示為下式:
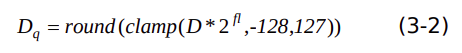
(2.3)float32 轉(zhuǎn) int16
假設(shè)輸入tensor的動態(tài)定點量化參數(shù)是fl,數(shù)據(jù)D量化過程表示為下式:
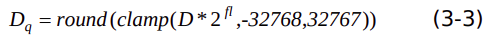
反量化流程是量化的逆過程,可以根據(jù)上述量化公式反推出反量化公式,這里不做贅述。
(3)零拷貝
在特定的條件下,可以把輸入數(shù)據(jù)拷貝次數(shù)減少到零,即零拷貝。比如,當(dāng)RKNN模型是非對稱量化,量化數(shù)據(jù)類型是uint8,3通道的均值是相同的整數(shù)同時縮放因子相同的情況下,歸一化和量化可以省略。證明如下:
假設(shè)輸入圖像數(shù)據(jù)是D(f),量化參數(shù)是 S(q),ZP 。M(i)表示第 i 通道的均值, S(i)表示第 i 通道的歸一化因子。則第i通道歸一化后的數(shù)據(jù) 如下式子:
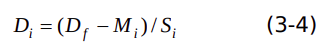
數(shù)據(jù) D(i)量化過程表示為下式:
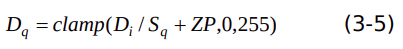
上述兩個式子合并后,可以得出
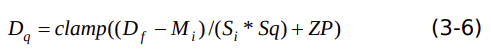
假設(shè)量化圖片矯正集數(shù)據(jù)范圍包含0到 255的整數(shù)值,當(dāng) M1=M2 =M3 ,S1 =S2 =S3 時, 歸一化數(shù)值范圍表示如下:
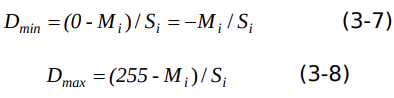
因此,量化參數(shù)計算如下:
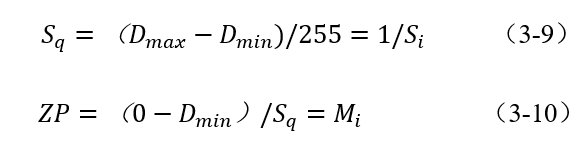
把式(3-9)和式(3-10)代入式(3-6),可以得出
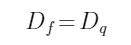
,即符合零拷貝的條件下:3 通道的均值是相同的整數(shù)同時歸一化的縮放因子相同,輸入uint8 數(shù)據(jù)等于量化后的uint8數(shù)據(jù)。
輸入零拷貝能降低 CPU 負(fù)載,提高整體的推理速度。針對 RGB 或 BGR 輸入數(shù)據(jù),實現(xiàn) 輸入零拷貝的步驟如下:
1)三個通道的均值是相同的整數(shù)同時歸一化的縮放因子相同。
2)在 rknn-toolkit 的 config 函數(shù)中,設(shè)置 force_builtin_perm=True,導(dǎo)出 NHWC輸入的 RKNN 模型。
3)使用 rknn_inputs_map 接口,獲取輸入 tensor 內(nèi)存地址信息。
4)往內(nèi)存地址填充輸入數(shù)據(jù),比如調(diào)用 RGA 縮放函數(shù),目標(biāo)地址使用 rknn_inputs_map獲取的物理地址。
5)調(diào)用 rknn_inputs_sync 接口。
6)調(diào)用 rknn_run 接口。
7)調(diào)用獲取輸出接口。
7.2.2 API詳細(xì)說明
(1)rknn_init
rknn_init初始化函數(shù)將創(chuàng)建 rknn_context 對象、加載 RKNN 模型以及根據(jù) flag執(zhí)行 特定的初始化行為。
| API | rknn_init |
| 功能 | 初始化 rknn |
| 參數(shù) | rknn_context *context:rknn_context指針。函數(shù)調(diào)用之后,context 將會被賦值。 |
| void *model:RKNN 模型的二進(jìn)制數(shù)據(jù)。 | |
| uint32_t size:模型大小。 | |
| uint32_t flag:特定的初始化標(biāo)志。目前 RK1808 平臺僅支持以下標(biāo)志: RKNN_FLAG_COLLECT_PERF_MASK:打開性能收集調(diào)試開關(guān),打開之后能夠通過rknn_query 接口查詢網(wǎng)絡(luò)每層運行時間。需要注意,該標(biāo)志被設(shè)置后rknn_run的運行時間將會變長。 | |
| 返回值 | int錯誤碼(見rknn 返回值錯誤碼)。 |
示例代碼如下:
rknn_context ctx; int ret = rknn_init(&ctx, model_data, model_data_size, 0);
(2)rknn_destroy
rknn_destroy 函數(shù)將釋放傳入的 rknn_context及其相關(guān)資源。
| API | rknn_destroy |
| 功能 | 銷毀 rknn_context 對象及其相關(guān)資源。 |
| 參數(shù) | rknn_context context:要銷毀的 rknn_context 對象。 |
| 返回值 | int 錯誤碼(見 rknn 返回值錯誤碼)。 |
示例代碼如下:
int ret = rknn_destroy (ctx);
(3)rknn_query
rknn_query 函數(shù)能夠查詢獲取到模型輸入輸出、運行時間以及 SDK 版本等信息。
| API | rknn_query |
| 功能 | 查詢模型與 SDK 的相關(guān)信息。 |
| 參數(shù) | rknn_context context:rknn_context 對象。 |
| rknn_query_cmd cmd:查詢命令。 | |
| void* info:存放返回結(jié)果的結(jié)構(gòu)體變量。 | |
| uint32_t size:info 對應(yīng)的結(jié)構(gòu)體變量的大小。 | |
| 返回值 | int 錯誤碼(見 rknn 返回值錯誤碼) |
當(dāng)前 SDK 支持的查詢命令如下表所示:
| 查詢命令 | 返回結(jié)果結(jié)構(gòu)體 | 功能 |
| RKNN_QUERY_IN_OUT_N UM | rknn_input_output_num | 查詢輸入輸出 Tensor 個數(shù) |
| RKNN_QUERY_INPUT_ATT R | rknn_tensor_attr | 查詢輸入 Tensor 屬性 |
| RKNN_QUERY_OUTPUT_A TTR | rknn_tensor_attr | 查詢輸出 Tensor 屬性 |
| RKNN_QUERY_PERF_DET AIL | rknn_perf_detail | 查詢網(wǎng)絡(luò)各層運行時間 |
| RKNN_QUERY_SDK_VERSI ON | rknn_sdk_version | 查詢 SDK 版 |
接下來的將依次詳解各個查詢命令如何使用。
(3.1)查詢輸入輸出 Tensor 個數(shù)
傳入 RKNN_QUERY_IN_OUT_NUM 命令可以查詢模型輸入輸出 Tensor 的個數(shù)。其中 需要先創(chuàng)建rknn_input_output_num 結(jié)構(gòu)體對象。
示例代碼如下:
rknn_input_output_num io_num;
ret = rknn_query(ctx, RKNN_QUERY_IN_OUT_NUM, &io_num,
sizeof(io_num));
printf("model input num: %d, output num: %dn",
io_num.n_input, io_num.n_output);
(3.2)查詢輸入 Tensor 屬性
傳入 RKNN_QUERY_INPUT_ATTR 命令可以查詢模型輸入 Tensor 的屬性。其中需要先 創(chuàng)建 rknn_tensor_attr 結(jié)構(gòu)體對象。
示例代碼如下:
rknn_tensor_attr input_attrs[io_num.n_input]; memset(input_attrs, 0, sizeof(input_attrs)); for (int i = 0; i < io_num.n_input; i++) { input_attrs[i].index = i; ret = rknn_query(ctx, RKNN_QUERY_INPUT_ATTR, &(input_attrs[i]), sizeof(rknn_tensor_attr)); }
(3.3)查詢輸出 Tensor 屬性
傳入RKNN_QUERY_OUTPUT_ATTR命令可以查詢模型輸出Tensor的屬性。其中需要先創(chuàng)建rknn_tensor_attr 結(jié)構(gòu)體對象。
示例代碼如下:
rknn_tensor_attr output_attrs[io_num.n_output];
memset(output_attrs, 0, sizeof(output_attrs));
for (int i = 0; i < io_num.n_output; i++) {
output_attrs[i].index = i;
ret = rknn_query(ctx, RKNN_QUERY_OUTPUT_ATTR, &(output_attrs[i]),
sizeof(rknn_tensor_attr));
}
(3.4)查詢網(wǎng)絡(luò)各層運行時間
如果在rknn_init函數(shù)調(diào)用時有設(shè)置RKNN_FLAG_COLLECT_PERF_MASK標(biāo)志,那么 在執(zhí)行rknn_run完成之后,可以傳入RKNN_QUERY_PERF_DETAIL命令來查詢網(wǎng)絡(luò)每層 運行時間。其中需要先創(chuàng)建rknn_perf_detail結(jié)構(gòu)體對象。
示例代碼如下:
rknn_perf_detail perf_detail;
ret = rknn_query(ctx, RKNN_QUERY_PERF_DETAIL, &perf_detail,
sizeof(rknn_perf_detail));
printf("%s", perf_detail.perf_data);
注意,用戶不需要釋放rknn_perf_detail中的perf_data,SDK會自動管理該Buffer內(nèi)存。
(3.5)查詢 SDK 版本
傳入RKNN_QUERY_SDK_VERSION命令可以查詢RKNN SDK的版本信息。其中需要先創(chuàng)建rknn_sdk_version結(jié)構(gòu)體對象。
示例代碼如下:
rknn_sdk_version version;
ret = rknn_query(ctx, RKNN_QUERY_SDK_VERSION, &version,
sizeof(rknn_sdk_version));
printf("sdk api version: %sn", version.api_version);
printf("driver version: %sn", version.drv_version);
(4)rknn_inputs_set
通過 rknn_inputs_set 函數(shù)可以設(shè)置模型的輸入數(shù)據(jù)。該函數(shù)能夠支持多個輸入,其中 每個輸入是 rknn_input 結(jié)構(gòu)體對象,在傳入之前用戶需要設(shè)置該對象。
| API | rknn_inputs_set |
| 功能 | 設(shè)置模型輸入數(shù)據(jù)。 |
| 參數(shù) | rknn_context context:rknn_contex 對象。 |
| uint32_t n_inputs:輸入數(shù)據(jù)個數(shù)。 | |
| rknn_input inputs[]:輸入數(shù)據(jù)數(shù)組,數(shù)組每個元素是 rknn_input 結(jié)構(gòu)體對象。 | |
| 返回值 | int 錯誤碼(見 rknn 返回值錯誤碼)。 |
示例代碼如下:
rknn_input inputs[1]; memset(inputs, 0, sizeof(inputs)); inputs[0].index = 0; inputs[0].type = RKNN_TENSOR_UINT8; inputs[0].size = img_width*img_height*img_channels; inputs[0].fmt = RKNN_TENSOR_NHWC; inputs[0].buf = in_data; ret = rknn_inputs_set(ctx, 1, inputs);
(5)rknn_inputs_map
rknn_inputs_map 函數(shù)用于獲取模型輸入tensor初始化后的存儲狀態(tài),存儲狀態(tài)包括虛擬地址,物理地址fd,存儲空間大小。它需要和rknn_inputs_sync接口(見rknn_inputs_sync 函數(shù))配合使用,在模型初始化后,用戶通過返回的的內(nèi)存位置設(shè)置輸入數(shù)據(jù),并且在推理前調(diào)用rknn_inputs_sync函數(shù)。存儲狀態(tài)使用rknn_tensor_mem結(jié)構(gòu)體表示。輸入?yún)?shù)mem 是rknn_tensor_mem結(jié)構(gòu)體數(shù)組。
目前,在 RK1808/RV1109/RV1126 芯片上,返回的fd是-1。當(dāng)返回的物理地址值是 0xffffffffffffffff(2的64次冪-1),表示無法獲取正確的物理地址,而虛擬地址仍然有效。如果有多個模型輸入tensor的存儲空間較大,用戶可以在掛載驅(qū)動時,適當(dāng)增加模型輸入和 輸出存儲空間或者擴增固件中的CMA內(nèi)存空間。以RV1109_RV1126為例,配置驅(qū)動存儲 空間,可以參考如下修改:
把/etc/init.d/S60NPU_init文件這一行:
insmod /lib/modules/galcore.ko contiguousSize=0x400000 gpuProfiler=1
改成
insmod /lib/modules/galcore.ko contiguousSize=0x600000 gpuProfiler=1
然后重啟生效。此配置應(yīng)該大于用戶模型輸入和輸出總大小,但不超過固件中可用的CMA空間大小。
| API | rknn_inputs_map |
| 功能 | 讀取輸入存儲狀態(tài)信息。 |
| 參數(shù) | rknn_context context:rknn_contex 對象。 |
| uint32_t n_inputs:輸入數(shù)據(jù)個數(shù)。 | |
| rknn_input inputs[]:輸入數(shù)據(jù)數(shù)組,數(shù)組每個元素是 rknn_input 結(jié)構(gòu)體對象。 | |
| 返回值 | int 錯誤碼(見rknn 返回值錯誤碼)。 |
示例代碼如下:
rknn_tensor_mem mem[1]; ret = rknn_inputs_map(ctx, 1, mem);
(6)rknn_inputs_sync
rknn_inputs_sync 函數(shù)將 CPU 緩存寫回內(nèi)存,讓設(shè)備能獲取正確的數(shù)據(jù)。
| API | rknn_inputs_sync |
| 功能 | 同步輸入數(shù)據(jù)。 |
| 參數(shù) | rknn_context context:rknn_contex 對象。 |
| uint32_t n_inputs:輸入數(shù)據(jù)個數(shù)。 | |
| rknn_tensor_mem mem[]:存儲狀態(tài)信息數(shù)組,數(shù)組每個元素是 rknn_tensor_mem結(jié)構(gòu)體對象。 | |
| 返回值 | int 錯誤碼(見 rknn 返回值錯誤碼) |
示例代碼如下:
rknn_tensor_mem mem[1]; ret = rknn_inputs_map(ctx, 1, mem); ret = rknn_inputs_sync(ctx, 1, mem);
(7)rknn_inputs_unmap
rknn_inputs_unmap 函數(shù)將清除 rknn_inputs_map函數(shù)獲取的輸入tensor的存儲位 置信息和標(biāo)志。
| API | rknn_inputs_unmap |
| 功能 | 清除rknn_inputs_map函數(shù)獲取的輸入tensor的存儲位置信息和標(biāo)志。 |
| 參數(shù) | rknn_context context:rknn_contex對象。 |
| uint32_t n_inputs:輸入數(shù)據(jù)個數(shù)。 | |
| rknn_tensor_mem mem[] : 存 儲 狀 態(tài) 信 息 數(shù) 組 , 數(shù) 組 每 個 元 素 是 rknn_tensor_mem 結(jié)構(gòu)體對象。 | |
| 返回值 | int 錯誤碼(見 rknn 返回值錯誤碼) |
示例代碼如下:
rknn_tensor_mem mem[1]; ret = rknn_inputs_map(ctx, 1, mem); ret = rknn_inputs_sync(ctx, 1, mem); ret = rknn_run(ctx, NULL); ret = rknn_inputs_unmap(ctx, 1, mem);
(8)rknn_run
rknn_run函數(shù)將執(zhí)行一次模型推理,調(diào)用之前需要先通過rknn_inputs_set函數(shù)設(shè)置輸入數(shù)據(jù)。
| API | rknn_run |
| 功能 | 執(zhí)行一次模型推理。 |
| 參數(shù) | rknn_context context:rknn_context 對象。 |
| rknn_run_extend* extend:保留擴展,當(dāng)前沒有使用,傳入 NULL 即可。 | |
| 返回值 | int 錯誤碼(見 rknn 返回值錯誤碼) |
示例代碼如下:
ret = rknn_run(ctx, NULL);
(9)rknn_outputs_get
rknn_outputs_get函數(shù)可以獲取模型推理的輸出數(shù)據(jù)。該函數(shù)能夠一次獲取多個輸出數(shù)據(jù)。其中每個輸出是rknn_output結(jié)構(gòu)體對象,在函數(shù)調(diào)用之前需要依次創(chuàng)建并設(shè)置每個 rknn_output對象。
對于輸出數(shù)據(jù)的buffer存放可以采用兩種方式:一種是用戶自行申請和釋放,此時 rknn_output對象的is_prealloc需要設(shè)置為1,并且將buf指針指向用戶申請的 buffer;另一種是由 rknn來進(jìn)行分配,此時rknn_output對象的is_prealloc設(shè)置為0即可,函數(shù)執(zhí)行之后 buf將指向輸出數(shù)據(jù)。
| API | rknn_outputs_get |
| 功能 | 獲取模型推理輸出。 |
| 參數(shù) | rknn_context context:rknn_context 對象。 |
| uint32_t n_outputs:輸出數(shù)據(jù)個數(shù)。 | |
| rknn_output outputs[]:輸出數(shù)據(jù)的數(shù)組,其中數(shù)組每個元素為 rknn_output 結(jié)構(gòu)體對象,代表模型的一個輸出。 | |
| rknn_output_extend* extend:保留擴展,當(dāng)前沒有使用,傳入 NULL 即可 | |
| 返回值 | int 錯誤碼(見 rknn 返回值錯誤碼) |
示例代碼如下:
rknn_output outputs[io_num.n_output];
memset(outputs, 0, sizeof(outputs));
for (int i = 0; i < io_num.n_output; i++) {
outputs[i].want_float = 1;
}
ret = rknn_outputs_get(ctx, io_num.n_output, outputs, NULL)
(10)rknn_outputs_release
rknn_outputs_release函數(shù)將釋放rknn_outputs_get函數(shù)得到的輸出的相關(guān)資源。
| API | rknn_outputs_release |
| 功能 | 釋放rknn_output對象。 |
| 參數(shù) | rknn_context context:rknn_context對象。 |
| uint32_t n_outputs:輸出數(shù)據(jù)個數(shù)。 | |
| rknn_output outputs[]:要銷毀的 rknn_output 數(shù)組。 | |
| 返回值 | int 錯誤碼(見rknn返回值錯誤碼) |
示例代碼如下
ret = rknn_outputs_release(ctx, io_num.n_output, outputs);
(11)rknn_outputs_map
rknn_outputs_map函數(shù)獲取模型初始化后輸出tensor 的存儲狀態(tài)。需要和rknn_outputs_sync函數(shù)(見 rknn_outputs_sync 函數(shù))配合使用,在模型初始化后調(diào)用 rknn_outputs_map 接口,接著每次推理完調(diào)用 rknn_outputs_sync 接口。如果用戶需要 32 位浮點類型的數(shù)據(jù),需要根據(jù)量化方式和量化的數(shù)據(jù)類型做反量化。
| API | rknn_outputs_map |
| 功能 | 讀取輸出存儲狀態(tài)信息。 |
| 參數(shù) | rknn_context context:rknn_context 對象。 |
| uint32_t n_outputs:輸出數(shù)據(jù)個數(shù)。 | |
| rknn_tensor_mem mem[]:存儲狀態(tài)信息數(shù)組,數(shù)組每個元 素 是 rknn_tensor_mem結(jié)構(gòu)體對象。 | |
| 返回值 | int 錯誤碼(見 rknn 返回值錯誤碼) |
示例代碼如下:
rknn_tensor_mem mem[1]; ret = rknn_outputs_map(ctx, 1, mem);
(12)rknn_outputs_sync
當(dāng)使用 rknn_outputs_map 接口映射完模型運行時模型輸出 tensor 存儲狀態(tài)信息后, 為確保緩存一致性,使用 rknn_outputs_sync 函數(shù)讓 CPU 獲取推理完最新的數(shù)據(jù)。
| API | rknn_outputs_sync |
| 功能 | 推理完,同步最新的輸出數(shù)據(jù)。 |
| 參數(shù) | rknn_context context:rknn_context 對象。 |
| uint32_t n_outputs:輸出數(shù)據(jù)個數(shù)。 | |
| rknn_tensor_mem mem[]:存儲狀態(tài)信息數(shù)組,數(shù)組每個元素是 rknn_tensor_mem 結(jié)構(gòu)體對象。 | |
| 返回值 | int 錯誤碼(見 rknn 返回值錯誤碼) |
示例代碼如下:
rknn_tensor_mem mem[1]; ret = rknn_run(ctx, NULL); ret = rknn_outputs_sync(ctx, io_num.n_output, mem)
(13)rknn_outputs_unmap
rknn_outputs_unmap函數(shù)將清除rknn_outputs_map函數(shù)獲取的輸出tensor的存儲狀態(tài)。
| API | rknn_outputs_unmap |
| 功能 | 清除 rknn_outputs_map 函數(shù)獲取的輸出 tensor 的存儲狀態(tài)。 |
| 參數(shù) | rknn_context context:rknn_context 對象。 |
| uint32_t n_outputs:輸出數(shù)據(jù)個數(shù)。 | |
| rknn_tensor_mem mem[]:存儲狀態(tài)信息數(shù)組,數(shù)組每個元素是 rknn_tensor_mem結(jié)構(gòu)體對象。 | |
| 返回值 | int 錯誤碼(見 rknn 返回值錯誤碼) |
示例代碼如下:
rknn_tensor_mem mem[1]; ret = rknn_outputs_unmap(ctx, io_num.n_output,mem);
7.2.3 RKNN 數(shù)據(jù)結(jié)構(gòu)定義
(1)rknn_input_output_num
結(jié)構(gòu)體rknn_input_output_num表示輸入輸出Tensor個數(shù),其結(jié)構(gòu)體成員變量如下表所示:
| 成員變量 | 數(shù)據(jù)類型 | 含義 |
| n_input | uint32_t | 輸入 Tensor個數(shù) |
| n_output | uint32_t | 輸出 Tensor個數(shù) |
(2)rknn_tensor_attr
結(jié)構(gòu)體 rknn_tensor_attr 表示模型的 Tensor 的屬性,結(jié)構(gòu)體的定義如下表所示:
| 成員變量 | 數(shù)據(jù)類型 | 含義 |
| index | uint32_t | 表示輸入輸出 Tensor 的索引位置。 |
| n_dims | uint32_t | Tensor 維度個數(shù)。 |
| dims | uint32_t[] | Tensor 各維度值。 |
| name | char[] | Tensor 名稱。 |
| n_elems | uint32_t | Tensor 數(shù)據(jù)元素個數(shù)。 |
| size | uint32_t | Tensor 數(shù)據(jù)所占內(nèi)存大小。 |
| fmt | rknn_tensor_form at |
Tensor 維度的格式,有以下格式: RKNN_TENSOR_NCHW RKNN_TENSOR_NHWC |
| type | rknn_tensor_type |
Tensor 數(shù)據(jù)類型,有以下數(shù)據(jù)類型: RKNN_TENSOR_FLOAT32 RKNN_TENSOR_FLOAT16 RKNN_TENSOR_INT8 RKNN_TENSOR_UINT8 RKNN_TENSOR_INT16 |
| qnt_type | rknn_tensor_qnt_type |
Tensor量化類型,有以下的量化類型: RKNN_TENSOR_QNT_NONE:未量化; RKNN_TENSOR_QNT_DFP:動態(tài)定點量 化; RKNN_TENSOR_QNT_AFFINE_ASYMM ETRIC:非對稱量化。 |
| fl | int8_t | RKNN_TENSOR_QNT_DFP 量化類型的參數(shù)。 |
| zp | uint32_t | RKNN_TENSOR_QNT_AFFINE_ASYMMETRI C 量化類型的參數(shù) |
| scale | float | RKNN_TENSOR_QNT_AFFINE_ASYMMETRI C 量化類型的參數(shù)。 |
(3)rknn_input
結(jié)構(gòu)體rknn_input 表示模型的一個數(shù)據(jù)輸入,用來作為參數(shù)傳入給rknn_inputs_set函數(shù)。結(jié)構(gòu)體的定義如下表所示:
| 成員變量 | 數(shù)據(jù)類型 | 含義 |
| index | uint32_t | 該輸入的索引位置。 |
| buf | void* | 輸入數(shù)據(jù) Buffer 的指針。 |
| size | uint32_t | 輸入數(shù)據(jù) Buffer 所占內(nèi)存大小。 |
| pass_through | uint8_t | 設(shè)置為 1 時會將 buf存放的輸入數(shù)據(jù)直接設(shè)置給 模型的輸入節(jié)點,不做任何預(yù)處理。 |
| type | rknn_tensor_type | 輸入數(shù)據(jù)的類型。 |
| fmt | rknn_tensor_form at | 輸入數(shù)據(jù)的格式。 |
(4)rknn_tensor_mem
結(jié)構(gòu)體 rknn_tensor_mem表示 tensor 初始化后的存儲狀態(tài)信息,用來作為參數(shù)傳入給 rknn_inputs_map系列和rknn_outputs_map系列函數(shù)。結(jié)構(gòu)體的定義如下表所示:
| 成員變量 | 數(shù)據(jù)類型 | 含義 |
| logical_addr | void* | 該輸入的虛擬地址。 |
| physical_addr | uint64_t | 該輸入的物理地址。 |
| fd | int32_t | 該輸入的 fd。 |
| size | uint32_t | 該輸入 tensor 占用的內(nèi)存大小。 |
| handle | uint32_t | 該輸入的 handle。 |
| priv_data | void* | 保留的數(shù)據(jù)。 |
| reserved_flag | uint64_t | 保留的標(biāo)志位。 |
(5)rknn_output
結(jié)構(gòu)體rknn_output表示模型的一個數(shù)據(jù)輸出,用來作為參數(shù)傳入給rknn_outputs_get 函數(shù),在函數(shù)執(zhí)行后,結(jié)構(gòu)體對象將會被賦值。結(jié)構(gòu)體的定義如下表所示:
| 成員變量 | 數(shù)據(jù)類型 | 含義 |
| want_float | uint8_t | 標(biāo)識是否需要將輸出數(shù)據(jù)轉(zhuǎn)為 float 類型輸出。 |
| is_prealloc | uint8_t | 標(biāo)識存放輸出數(shù)據(jù)的 Buffer 是否是預(yù)分配。 |
| index | uint32_t | 該輸出的索引位置。 |
| buf | void* | 輸出數(shù)據(jù) Buffer 的指針。 |
| size | uint32_t | 輸出數(shù)據(jù) Buffer 所占內(nèi)存大小。 |
(6)rknn_perf_detail
結(jié)構(gòu)體 rknn_perf_detail 表示模型的性能詳情,結(jié)構(gòu)體的定義如下表所示:
| 成員變量 | 數(shù)據(jù)類型 | 含義 |
| perf_data | char* | 性能詳情包含網(wǎng)絡(luò)每層運行時間,能夠直接打印 出來查看。 |
| data_len | uint64_t | 存放性能詳情的字符串?dāng)?shù)組的長度。 |
(7)rknn_sdk_version
結(jié)構(gòu)體 rknn_sdk_version 用來表示 RKNN SDK 的版本信息,結(jié)構(gòu)體的定義如下:
| 成員變量 | 數(shù)據(jù)類型 | 含義 |
| api_version | char[] | char[] SDK 的版本信息。 |
| drv_version | char[] | SDK所基于的驅(qū)動版本信息。 |
7.2.4 RKNN返回值錯誤碼
RKNN API 函數(shù)的返回值錯誤碼定義如下表所示
| 錯誤碼 | 錯誤詳情 |
| RKNN_SUCC(0) | 執(zhí)行成功 |
| RKNN_ERR_FAIL(-1) | 執(zhí)行出錯 |
| RKNN_ERR_TIMEOUT(-2) | 執(zhí)行超時 |
| RKNN_ERR_DEVICE_UNAVAILABLE (-3) | NPU 設(shè)備不可用 |
| RKNN_ERR_MALLOC_FAIL(-4) | 內(nèi)存分配失敗 |
| RKNN_ERR_PARAM_INVALID(-5) | 傳入?yún)?shù)錯誤 |
| RKNN_ERR_MODEL_INVALID(-6) | 傳入的 RKNN 模型無效 |
| RKNN_ERR_CTX_INVALID(-7) | 傳入的 rknn_context 無效 |
| RKNN_ERR_INPUT_INVALID(-8) | 傳入的 rknn_input 對象無 |
| RKNN_ERR_OUTPUT_INVALID(-9) | 傳入的 rknn_output 對象無效 |
| RKNN_ERR_DEVICE_UNMATCH(-10) | 版本不匹配 |
| RKNN_ERR_INCOMPATILE_PRE_COM PILE_MODEL(-11) | RKNN模型使用pre_compile 模式,但是和當(dāng)前驅(qū)動不兼容 |
| RKNN_ERR_INCOMPATILE_OPTIMIZAT ION_LEVEL_VERSION(-12) | RKNN模型設(shè)置了優(yōu)化等級的選項,但是和當(dāng)前驅(qū)動不兼容 |
| RKNN_ERR_TARGET_PLATFORM_UN MATCH(-13) | RKNN模型和當(dāng)前平臺不兼容,一般是將 RK1808的平臺的RKNN模型放到了 RV1109/RV1126上。 |
| RKNN_ERR_NON_PRE_COMPILED_M ODEL_ON_MINI_DRIVER(-14) | RKNN模型不是pre_compile模式,在mini-driver上無法執(zhí)行。 |
審核編輯 黃宇
-
開發(fā)板
+關(guān)注
關(guān)注
25文章
5499瀏覽量
102155 -
AI算法
+關(guān)注
關(guān)注
0文章
260瀏覽量
12591 -
rv1126
+關(guān)注
關(guān)注
0文章
106瀏覽量
3344
發(fā)布評論請先 登錄
基于RV1126開發(fā)板實現(xiàn)人臉檢測方案

基于RV1126開發(fā)板實現(xiàn)二維碼識別方案
基于RV1126開發(fā)板實現(xiàn)人臉檢測方案
基于RV1126開發(fā)板實現(xiàn)自學(xué)習(xí)圖像分類方案
基于RV1126開發(fā)板實現(xiàn)人臉識別方案
基于RV1126開發(fā)板實現(xiàn)人臉檢測方案
基于RV1126開發(fā)板實現(xiàn)安全帽檢測方案

基于RV1126開發(fā)板實現(xiàn)駕駛員行為檢測方案
基于RV1126開發(fā)板實現(xiàn)人員檢測方案
基于RV1126開發(fā)板實現(xiàn)人臉識別方案
基于RV1126開發(fā)板的AI算法開發(fā)流程






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論