") ClickHouse 的“獨孤九劍”:極速查詢的終極秘籍
ClickHouse 的“獨孤九劍”:極速查詢的終極秘籍
引言
在大數(shù)據(jù)時代的江湖,數(shù)據(jù)量呈爆炸式增長,如何高效地處理和分析海量數(shù)據(jù)成為了一個關(guān)鍵問題。各路英雄豪杰紛紛亮出自己的絕技,爭奪數(shù)據(jù)處理的巔峰寶座。而在這場激烈的角逐中,ClickHouse 以其“獨孤九劍”般的絕世武功,橫空出世,令群雄側(cè)目。
ClickHouse 是一個用于聯(lián)機分析處理(OLAP)的開源分布式數(shù)據(jù)管理系統(tǒng)。它由俄羅斯的 Yandex 公司開發(fā),為海量數(shù)據(jù)的實時分析處理提供高效的解決方案。
今天,就讓我們一同走進 ClickHouse 的江湖,揭開它極速查詢的終極秘籍。
ClickHouse “九劍”
總決式:整體架構(gòu)
從架構(gòu)角度來看,數(shù)據(jù)庫至少由存儲層和查詢處理層組成。存儲層負責(zé)保存、加載和維護表數(shù)據(jù),而查詢處理層則執(zhí)行用戶查詢。與其他數(shù)據(jù)庫相比,ClickHouse 在這兩個層上都提供了創(chuàng)新,可實現(xiàn)極快的插入和選擇查詢。不同于其他大數(shù)據(jù)計算引擎(如 Spark、Presto 等)的“計算服務(wù)于存儲”,ClickHouse 自有存儲層,不依賴外部存儲,可以在存儲層為查詢計算做出很多的優(yōu)化特性,即存儲服務(wù)于計算。
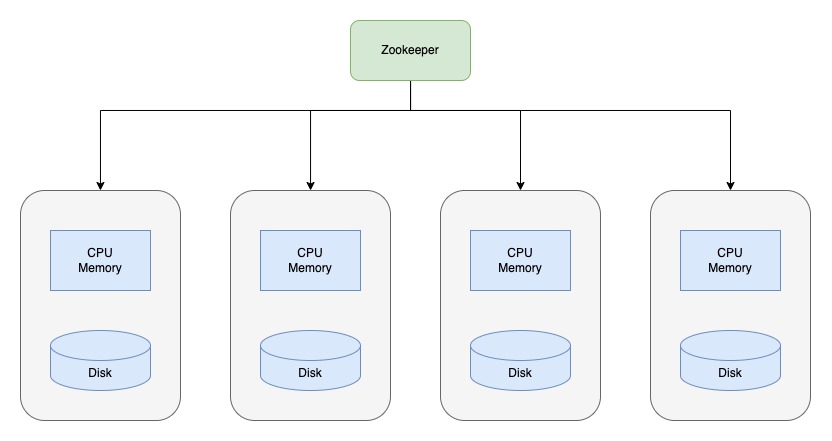
ClickHouse 采用 MPP(大規(guī)模并行處理)架構(gòu),集群中的每個節(jié)點都是對等的,可以獨立對外提供服務(wù)。這種架構(gòu)使得 ClickHouse 能夠高效地處理分布式查詢,通過將任務(wù)并行地分散到多個服務(wù)器節(jié)點上,在每個服務(wù)器節(jié)點進行計算。
同時,ClickHouse 對主鍵預(yù)排序,數(shù)據(jù)基于列式存儲,并采用向量化引擎等方式保證了 ClickHouse 的快速查詢分析。
破劍式:列式存儲
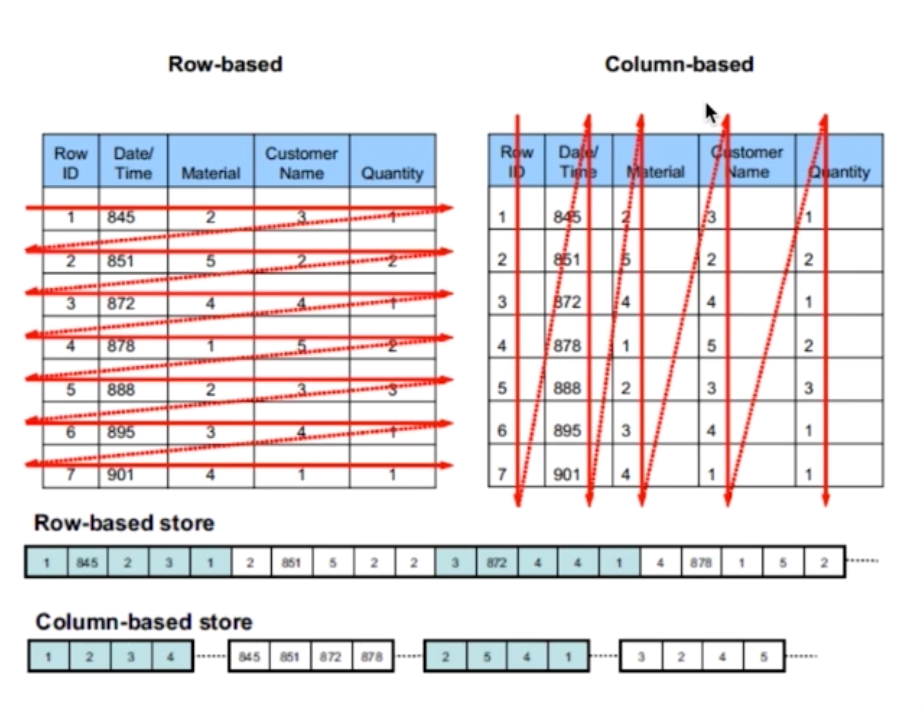
列式存儲,被廣泛應(yīng)用于大數(shù)據(jù)領(lǐng)域,Parquet、ORC 等文件格式都是列式存儲格式。
在存儲引擎的設(shè)計上,ClickHouse 同樣采用了基于列存儲的存儲結(jié)構(gòu)。每個列的數(shù)據(jù)單獨存儲在一個文件中,這種結(jié)構(gòu)使得讀取和過濾數(shù)據(jù)時可以只訪問相關(guān)的列,在很多場景中極大地降低了數(shù)據(jù)分析過程中讀取的數(shù)據(jù)量。
列存儲還為 ClickHouse 帶來另一個非常明顯的優(yōu)勢就是大幅提高了數(shù)據(jù)壓縮率。由于列中的數(shù)據(jù)通常具有相似的特征,壓縮效率更高,從而大幅減少壓縮后的數(shù)據(jù)大小,極大減少了磁盤的 I/O 時間。并且,每一列都可以使用不同的壓縮算法。在實際生產(chǎn)中,ClickHouse 基本可以達到 8:1 的壓縮比。
在查詢過程中,ClickHouse 只解壓涉及的列數(shù)據(jù)塊,而不是解壓整個數(shù)據(jù)塊,這樣可以減少解壓縮過程中的 I/O 操作,進一步提高查詢效率。
破刀式:向量化
向量化執(zhí)行不是一次處理一條數(shù)據(jù),而是將數(shù)據(jù)分成批量(通常是固定大小的數(shù)據(jù)塊),然后一次性處理整個批次的數(shù)據(jù)。例如,一次處理1024個數(shù)據(jù)元素。
在計算引擎上,ClickHouse 首次使用向量化計算引擎。ClickHouse 利用現(xiàn)代 CPU 提供的 SIMD(單指令多數(shù)據(jù))指令集進行向量化加速。SIMD 允許在一個指令中同時對多個數(shù)據(jù)進行操作,從而顯著提高了數(shù)據(jù)處理的速度。
并且,由于數(shù)據(jù)是批量處理的,數(shù)據(jù)的訪問模式更具順序性,減少了 CPU 緩存的未命中率。
因為采用了向量化計算引擎,從而使 ClickHouse 很大程度上提升了單機性能。在實際場景中,上億乃至幾十億的數(shù)據(jù),都可以使用單機解決。符合當(dāng)前大環(huán)境下的降本增效,而且,很大程度上解決了傳統(tǒng)大數(shù)據(jù)倉庫的效率低及成本高的問題。
特別地,受 ClickHouse 的影響,Spark、Presto、Doris、StarRocks 等都開始了向量化引擎的改造,像 Spark、Presto 的向量化引擎 Velox,甚至現(xiàn)在連 Flink 都開始搞起來向量化引擎。

破槍式:預(yù)排序
ClickHouse 使用類 LSM 的算法,在將數(shù)據(jù)寫入磁盤前進行排序,以保證數(shù)據(jù)在磁盤上有序。數(shù)據(jù)在寫入后定期在后臺進行 Compaction。通過類 LSM Tree 的結(jié)構(gòu),順序?qū)懘疟P,充分利用了磁盤的吞吐能力。
ClickHouse 在建表時,需要指定主鍵及排序鍵。如果只指定排序鍵,那么主鍵會被隱式設(shè)置為排序鍵。如果同時指定了主鍵和排序鍵,則主鍵必須是排序鍵的前綴。
并且,由于數(shù)據(jù)是有序的,在設(shè)計范圍查找及排序操作時,可以用來減少磁盤讀取的數(shù)據(jù)量,進而提升查詢速度。數(shù)據(jù)的預(yù)排序是 ClickHouse 很多特性的基礎(chǔ)。
破鞭式:表引擎
在 ClickHouse 中,表引擎通過各自的設(shè)計和優(yōu)化機制,使得 ClickHouse 能夠在不同的場景下實現(xiàn)高效的查詢性能,滿足各種數(shù)據(jù)分析需求。
表引擎決定了:
數(shù)據(jù)存儲的方式和位置、向何處寫入數(shù)據(jù)以及從何處讀取數(shù)據(jù); 支持哪些查詢,以及如何支持; 并發(fā)數(shù)據(jù)訪問; 使用索引(如果有的話); 是否可以執(zhí)行多線程請求; 數(shù)據(jù)復(fù)制參數(shù);
破索式:數(shù)據(jù)類型
Clickhouse 支持 100 多種數(shù)據(jù)類型。
| ·基本數(shù)據(jù)類型 ·Bool:布爾類型,在內(nèi)部存儲為 Uint8,true 為 1,false 為 0; ·UInt8, UInt16, UInt32, UInt64:無符號整數(shù)類型,分別占用 1 字節(jié)、2 字節(jié)、4 字節(jié)、8 字節(jié); ·Int8, Int16, Int32, Int64:有符號整數(shù)類型,分別占用 1 字節(jié)、2 字節(jié)、4 字節(jié)、8 字節(jié); ·Float32, Float64:浮點數(shù)類型,分別單精度和雙精度,分別占用 4 字節(jié)、8字節(jié); ·Decimal32,Decimal64,Decimal128:高精度類型,原生方式為 Decimal(P, S); ·String:字符串類型,可變長度; ·FixedString(N):固定長度字符串類型,指定長度為 N,插入的字符串長度少于 N,則補空,對于 N,則報異常; ·日期和時間數(shù)據(jù)類型 ·Date:日期類型,以 YYYY-MM-DD 格式存儲; ·DateTime:日期時間類型,以 YYYY-MM-DD HH:MM:SS 格式存儲; ·DateTime64(N):帶有精度 N 的日期時間類型,N 為從 1 到 9 的精度值; ·復(fù)雜類型 ·Array(T):數(shù)組類型,包含元素類型 T 的數(shù)組; ·Nested:嵌套類型,支持嵌套結(jié)構(gòu); ·Tuple(T1, T2, …):元組類型,包含多個字段,字段類型可以是不同的數(shù)據(jù)類型; ·Map(K ,V):鍵值類型,映射不唯一,即一個映射可以包含兩個具有相同鍵的元素; ·Enum:枚舉類型,用來定義常量; ·聚合類型 ·AggregateFunction:聚合函數(shù)類型,具有實現(xiàn)定義的中間狀態(tài),可以將其序列化為 AggregateFunction(...) 數(shù)據(jù)類型并存儲在表中,通常使用物化視圖來存儲。產(chǎn)生聚合函數(shù)狀態(tài)的常用方法是調(diào)用帶后綴的聚合函數(shù) -State。將來要獲得聚合的最終結(jié)果,必須使用帶 -Merge 后綴的相同聚合函數(shù); ·SimpleAggregateFunction:產(chǎn)生聚合函數(shù)值的常見方法是調(diào)用帶有 -SimpleState 后綴的聚合函數(shù),如 min、max、sum、groupArrayArray 等。SimpleAggregateFunction 比使用相同的聚合函數(shù)具有更好的性能 AggregateFunction; ·其他數(shù)據(jù)類型 ·UUID:UUID類型,用于存儲全局唯一標(biāo)識符; ·IPv4,IPv6 類型:IP類型,IPv4 基于 UInt32 封裝,IPv6 基于 FixedString(16) 封裝,包含格式檢查; ·Nullable(T):可空類型,包裝類型 T,允許存儲 NULL 值; ·LowCardinality(T):將其他數(shù)據(jù)類型的內(nèi)部表示更改為字典編碼,使用字典編碼數(shù)據(jù)進行操作可顯著提高許多應(yīng)用程序的 SELECT 查詢性能,一般而言字典包含少于 1 W 個不同的值,則會有更好的讀取及存儲效率,如果大于 10 W 的不同值,那么相比其他數(shù)據(jù)類型性能可能會更差; |
數(shù)據(jù)類型決定了數(shù)據(jù)在內(nèi)存中的組織形式、在磁盤中存儲的持久化和序列化方式以及在計算時的處理機制。
ClickHouse 中的列 (IColumn) 事實上是一個數(shù)組,存儲某一列的一個或多個數(shù)據(jù)。ClickHouse 會將列中的數(shù)據(jù)當(dāng)成整體進行處理,而不是將列中的數(shù)據(jù)一行一行地處理。
列是不可變的,任何對列的操作都會產(chǎn)生一個全新的對象。不可變的語義使得某些對列的操作可以并行處理,從而充分利用多核處理器。
在 ClickHouse 中,內(nèi)存對齊的數(shù)據(jù)類型只保存數(shù)據(jù)數(shù)組,內(nèi)存中無法對齊的數(shù)據(jù)還額外保存了一個用于定界的 offset 數(shù)組。
由于內(nèi)存對齊的數(shù)據(jù)類型在存儲時不需要額外存儲數(shù)據(jù)的邊界,在計算時也不需要額外處理數(shù)據(jù)邊界,因此內(nèi)存對齊的數(shù)據(jù)具有更高的存儲與計算效率。
在列式存儲中,每個列的數(shù)據(jù)單獨存儲,同一種數(shù)據(jù)類型的數(shù)據(jù),對于數(shù)據(jù)壓縮更加友好,壓縮效率更高。(詳見《破劍式:列式存儲》章節(jié))
數(shù)據(jù)類型的設(shè)計充分考慮了大數(shù)據(jù)場景下的性能,帶來了極高的查詢效率,但同時也對使用者提出了更高的要求,使用者必須正確了解數(shù)據(jù)特點且必須正確使用數(shù)據(jù)類型,否則可能造成內(nèi)存浪費、查詢緩慢等問題。
破掌式:分片與副本策略
在 ClickHouse 中,為了提升查詢性能及增加數(shù)據(jù)容錯性,分別在水平方向和垂直方向上劃分為分片(shard)及副本(replica)。

在分布式模式下,ClickHouse 會將數(shù)據(jù)在水平方向上分為多個分片,并且分布到不同節(jié)點上,不同分片間的數(shù)據(jù)不同。分片的目的主要是為了提升查詢性能,方便多線程及分布式查詢。在分布式查詢時,按照分片數(shù)量拆分成若干個對本地表的子查詢,然后依次查詢每個分片的數(shù)據(jù),再合并匯總返回。
在數(shù)據(jù)寫入時,需要考慮如何均勻地寫入至各個分片,以及在數(shù)據(jù)查詢時,需要考慮如何路由到每個分片,并計算匯總形成結(jié)果集,這是分片就需要結(jié)合 Distributed 表引擎一起使用。在集群配置分片規(guī)則時,每一個分片會配置一個權(quán)重,分片權(quán)重會影響數(shù)據(jù)在分片中的傾斜程度,分片權(quán)重越大,被寫入的數(shù)據(jù)越多。在創(chuàng)建 Distributed 表時,需要指定 sharding_key 即分片鍵,它必須是一個整數(shù)類型的值。分片鍵的分片策略一般有以下幾種:
?固定字段:按照用于指定的字段的余數(shù)進行劃分,字段需要是整數(shù)類型;
?隨機函數(shù):按照隨機數(shù)進行劃分;
?hash 函數(shù):按照指定字段的 hash 值進行劃分;
?
ClickHouse 會將數(shù)據(jù)在垂直方向上分為多個副本,即同一個數(shù)據(jù)可以在不同的節(jié)點上存儲,并且數(shù)據(jù)副本間的每份數(shù)據(jù)相同,通過增加數(shù)據(jù)存儲容易來防止數(shù)據(jù)丟失。可以在任意一個副本上執(zhí)行 INSERT 、ALTER 操作,效果是相同的,都會借助 Zookeeper 的協(xié)同能力被分發(fā)至每個副本以本地形式執(zhí)行。
?
在數(shù)據(jù)查詢時,一個表的一個分片會擁有多個副本,那么這時會存在分布式表引擎選擇哪個副本計算的問題。ClickHouse 使用負載均衡算法從多個副本中選擇一個,算法是由 load_balancing 參數(shù)控制,并提供了以下選擇副本的算法策略:
?Random(默認(rèn)):會對每個副本計算錯誤數(shù),查詢將發(fā)送到錯誤最少的副本,如果多個副本同時擁有同樣最小錯誤數(shù),則隨機選擇一個;
?Nearest hostname(最近主機):系統(tǒng)同樣會對每個副本計算錯誤數(shù),每 5 分鐘錯誤數(shù)會除以 2,同樣會選擇錯誤最少的副本,如果有多個副本有最小的錯誤數(shù),則會將查詢發(fā)送到配置文件中的服務(wù)器主機名同當(dāng)前分布式表所在節(jié)點的主機名最相似的副本;
?Hostname levenshtein distance(主機名編輯):類似 Nearest hostname,但它是以編輯距離的方式比較主機名;
?In Order(排序):具有相同錯誤數(shù)的副本將按照配置中指定的順序進行訪問,當(dāng)確切知道哪個副本更可取時,此方法是合適的。
?First or Random(第一個或者隨機):此算法選擇集合中第一個副本,如果第一個副本不可用,則隨機選擇副本。
?Round Robin(循環(huán)遍歷):此算法在具有相同錯誤數(shù)的副本中使用循環(huán)遍歷的策略選擇。
破箭式:索引設(shè)計
在 ClickHouse 中,索引是優(yōu)化查詢性能的關(guān)鍵部分。ClikcHouse 中主要支持是稀疏索引和跳數(shù)索引。
在 ClickHouse 中,主鍵索引采用稀疏索引實現(xiàn),僅對每個顆粒(index_granularity,默認(rèn)為 8192 行為一個顆粒)記錄一個索引條目(mark),索引條目存儲的是顆粒(index_granularity)第一行的主鍵列值,存儲到單獨的索引文件(primary.idx),并在標(biāo)記文件({列}.mrk)存儲每個顆粒到文件物理位置的映射。通過索引文件和標(biāo)記文件,才能共同確定一個數(shù)據(jù)所在的文件位置。在查詢時,首先通過索引確認(rèn)數(shù)據(jù)所在的個顆粒,然后依據(jù)標(biāo)記確認(rèn)個顆粒所在的物理地址,最后通過物理地址從硬盤上讀取數(shù)據(jù)。
這種索引設(shè)計允許主鍵索引很小,必須完全適合加載到內(nèi)存,同時仍可顯著加快查詢執(zhí)行的時間,尤其是對數(shù)據(jù)分析中常見的范圍查找。其核心邏輯是通過索引降低需要讀取的數(shù)據(jù)量,從而減少磁盤 I/O 時間,達到加速查詢的效果。


除了主鍵索引,ClickHouse 還支持跳數(shù)索引。跳數(shù)索引允許在查詢時跳過沒有匹配值的數(shù)據(jù)塊,減少掃描數(shù)據(jù)范圍。主要的跳數(shù)索引有 minmax、set、布隆過濾器三種類型。
minmax 類型的跳數(shù)索引,存儲每個塊的索引表達式的最大值及最小值。這種類型非常適合傾向于按值松散排序的列,且只能與標(biāo)量或者元組表達式一起正確工作(永遠不會應(yīng)用于返回數(shù)組或 MAP 數(shù)據(jù)類型的表達式),通常是查詢處理過程中成本最低的索引類型。
眾所周知,布隆過濾器允許以極小的誤差來高效地判斷一個元素是否存在于集合中。由于布隆過濾器可以更有效地處理大量離散值的測試,因此適用于產(chǎn)生更多值進行測試的條件表達式,比如數(shù)組和 MAP,以及對文本搜索也很多有用,特別是沒有單詞分隔符的語言(比如中文)。

通常,set 索引和布隆過濾器索引都是無序的,因此不適合用于范圍查找。相反,minmax 索引特別適合于范圍判斷,因為確定范圍是否相交是非常快的。
破氣式:計算引擎
從功能和整體架構(gòu)上講,ClickHouse 的計算引擎與其他數(shù)據(jù)庫的計算引擎并沒有很大的不同。功能都是將可描述的結(jié)構(gòu)化查詢語言(SQL)轉(zhuǎn)化翻譯為可以執(zhí)行的物理計劃以及執(zhí)行計算并獲得計算結(jié)果,而整體架構(gòu)都有包含 SQL 解析、翻譯解釋、計算執(zhí)行等部分。

從實現(xiàn)方面,ClickHouse 同樣采用了多線程及分布式查詢,成為其高性能和高擴展性的關(guān)鍵。通過線程級并行的方式提升性能,利用多核 CPU 的計算能力;通過采用分布式架構(gòu),支持分片和副本,通過將數(shù)據(jù)分布到多個節(jié)點實現(xiàn)存儲和計算的擴展。
特別地,ClickHouse 的計算引擎是相當(dāng)被詬病的。ClickHouse 沒有成熟的執(zhí)行計劃優(yōu)化器,并且對 JOIN 的支持相比其他數(shù)據(jù)庫及計算引擎相當(dāng)薄弱。所以,有人認(rèn)為 ClickHouse 的計算引擎缺乏優(yōu)化及對分布式的支持,就是個半成品。
?
最后
通過上述特點,我們可以清楚地看到,ClickHouse 的高性能查詢能力并非偶然,而是其架構(gòu)設(shè)計和技術(shù)創(chuàng)新的必然結(jié)果。無論是列式存儲、向量化執(zhí)行引擎,還是數(shù)據(jù)壓縮技術(shù)、分布式架構(gòu),這些特點共同作用,使得 ClickHouse 在處理大規(guī)模數(shù)據(jù)分析時表現(xiàn)出色,在大數(shù)據(jù)的江湖中獨步天下。
?
參考資料
陳峰 《Clickhouse 性能之巔:從架構(gòu)設(shè)計解讀性能之謎》 機械工業(yè)出版社
朱凱 《ClickHouse 原理解析與應(yīng)用實踐》 機械工業(yè)出版社
?ClickHouse官網(wǎng)?
?《ClickHouse 教程》?
?ClickHouse 的副本與分片?
審核編輯 黃宇
-
數(shù)據(jù)庫
+關(guān)注
關(guān)注
7文章
3900瀏覽量
65753 -
大數(shù)據(jù)
+關(guān)注
關(guān)注
64文章
8949瀏覽量
139448
發(fā)布評論請先 登錄
青銅劍技術(shù)亮相第九屆電氣化交通前沿技術(shù)論壇
10K-100K B3950-B3435NTC熱敏電阻快速查詢對照表
告別延遲!Ethernetip轉(zhuǎn)modbustcp網(wǎng)關(guān)在熔煉車間監(jiān)控的極速時代

IP地址查詢技術(shù)

ClickHouse:強大的數(shù)據(jù)分析引擎

九章云極DataCanvas公司「算力包」產(chǎn)品璀璨亮相2024中國算力大會!

根據(jù)ip地址查網(wǎng)頁怎么查詢?
《七劍下天山》之“七劍利刃”:“新一代”漏洞掃描管理系統(tǒng)
醫(yī)療PACS影像數(shù)據(jù)的極速分布式塊存儲解決方案

供應(yīng)鏈場景使用ClickHouse最佳實踐

九章云極DataCanvas公司入選北京市通用人工智能產(chǎn)業(yè)創(chuàng)新伙伴計劃

ClickHouse內(nèi)幕(3)基于索引的查詢優(yōu)化





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論