") 一文讀懂,可重構(gòu)芯片為何是AI的完美搭檔
一文讀懂,可重構(gòu)芯片為何是AI的完美搭檔
來源:半導(dǎo)體行業(yè)觀察
在當(dāng)今數(shù)字化時(shí)代,人工智能(AI)無疑是最為耀眼的技術(shù)領(lǐng)域之一。從早期簡單的機(jī)器學(xué)習(xí)算法,到如今復(fù)雜的深度學(xué)習(xí)和 Transformer 模型,AI 算法正以前所未有的速度快速發(fā)展。這種快速演進(jìn)使得 AI 在各個(gè)領(lǐng)域的應(yīng)用不斷拓展,從邊緣端的高能效場景,如智能安防攝像頭、智能家居設(shè)備,到云端的大算力場景,如數(shù)據(jù)中心的智能分析、智能語音交互系統(tǒng)等,AI 正逐步滲透到人們生活和工作的方方面面。
在邊緣端,設(shè)備對能耗限制嚴(yán)格,需在有限電量下完成復(fù)雜任務(wù),像實(shí)時(shí)圖像識(shí)別、簡單語音指令處理等。而在云端,面對海量數(shù)據(jù)和復(fù)雜計(jì)算需求,如大規(guī)模圖像數(shù)據(jù)集處理、復(fù)雜自然語言處理任務(wù)等,需要強(qiáng)大計(jì)算能力支撐。無論哪種場景,AI 芯片都至關(guān)重要,其性能直接決定 AI 應(yīng)用效果。然而,隨著 AI 算法不斷革新,傳統(tǒng)固定架構(gòu)芯片逐漸暴露出諸多局限性,難以滿足 AI 算法日益增長的多樣化需求,無法充分發(fā)揮硬件性能優(yōu)勢。
現(xiàn)代神經(jīng)網(wǎng)絡(luò)模型作為AI算法的核心,具有一系列復(fù)雜多樣的特征,這些特征對芯片的設(shè)計(jì)和性能產(chǎn)生了深遠(yuǎn)的影響。
神經(jīng)網(wǎng)絡(luò)的拓?fù)浣Y(jié)構(gòu)復(fù)雜且不斷演變。早期神經(jīng)網(wǎng)絡(luò)主要由卷積層和全連接層構(gòu)成,結(jié)構(gòu)簡單,功能單一。但隨著技術(shù)發(fā)展,為提升網(wǎng)絡(luò)性能和處理復(fù)雜任務(wù)的能力,諸如 ResNet 的殘差連接結(jié)構(gòu)、注意力機(jī)制等復(fù)雜拓?fù)洳粩嘤楷F(xiàn)。ResNet 的殘差連接解決了梯度消失問題,使網(wǎng)絡(luò)可構(gòu)建得更深,學(xué)習(xí)更復(fù)雜特征;注意力機(jī)制通過動(dòng)態(tài)生成矩陣提取全局信息相關(guān)性,帶來不規(guī)則拓?fù)浣Y(jié)構(gòu),能更聚焦關(guān)鍵信息。例如在 2023 年特斯拉 AI Day 展示的網(wǎng)絡(luò)中,包含更多類型節(jié)點(diǎn)和更復(fù)雜連接,旨在模擬人類大腦神經(jīng)連接,實(shí)現(xiàn)更高級(jí)智能處理能力。不同網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)決定數(shù)據(jù)在網(wǎng)絡(luò)中的流動(dòng)和處理方式,對芯片的計(jì)算資源分配和數(shù)據(jù)傳輸路徑提出多樣化需求。
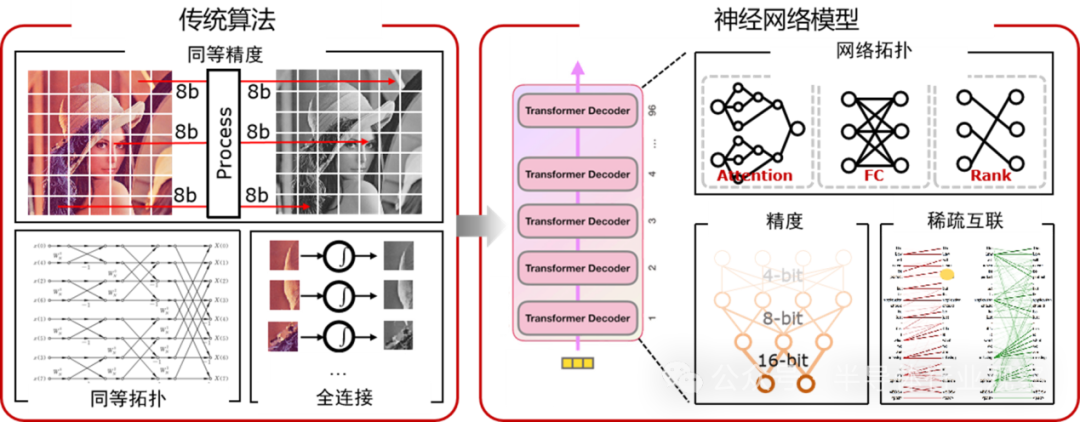 圖1. AI算法呈現(xiàn)出復(fù)雜演變的特點(diǎn)
圖1. AI算法呈現(xiàn)出復(fù)雜演變的特點(diǎn)
神經(jīng)網(wǎng)絡(luò)模型存在多維度的稀疏性,涵蓋輸入、權(quán)重和輸出。為模擬大腦中非活躍神經(jīng)元,提高計(jì)算效率,稀疏性在神經(jīng)網(wǎng)絡(luò)研究中備受關(guān)注。實(shí)際計(jì)算中,稀疏(0 值)操作數(shù)不影響計(jì)算結(jié)果,跳過無效計(jì)算可減少整體計(jì)算量和內(nèi)存訪問需求。早期對稀疏性的研究集中在基于剪枝的一維權(quán)重稀疏性,如今已發(fā)展到利用輸入、權(quán)重和輸出的三維稀疏性。例如,在一些模型中,通過檢測輸入數(shù)據(jù)中的 0 值元素,直接跳過相關(guān)計(jì)算,避免不必要的計(jì)算資源浪費(fèi)。
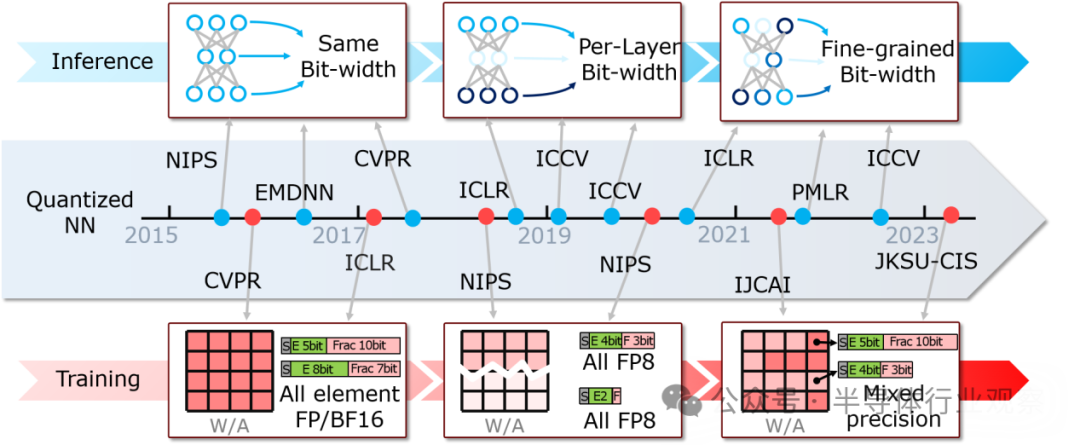
圖2. 神經(jīng)網(wǎng)絡(luò)模型精度不斷變化
神經(jīng)網(wǎng)絡(luò)模型在不同層對數(shù)據(jù)精度要求差異較大。推理階段,模型最初常被量化為統(tǒng)一精度,如 INT8,這種方式雖簡單,但在某些情況下無法充分發(fā)揮模型性能。后來發(fā)展為每層量化,根據(jù)不同層需求調(diào)整數(shù)據(jù)精度,提高推理效率。近期,甚至出現(xiàn)元素級(jí)混合精度應(yīng)用,進(jìn)一步優(yōu)化計(jì)算資源利用。訓(xùn)練階段,早期常用的 FP32 和 FP16 雖能保證較高計(jì)算精度,但會(huì)帶來較高內(nèi)存和功耗開銷。為降低訓(xùn)練成本,有人提出使用 FP8,但因其數(shù)據(jù)表示能力有限,會(huì)導(dǎo)致訓(xùn)練精度損失。因此,混合精度訓(xùn)練(如 FP16 和 FP8 混合)成為平衡訓(xùn)練精度和能效的有效解決方案。
這些復(fù)雜的模型特征給芯片設(shè)計(jì)帶來諸多嚴(yán)峻挑戰(zhàn)。不同網(wǎng)絡(luò)拓?fù)浣Y(jié)構(gòu)導(dǎo)致數(shù)據(jù)重用模式和數(shù)據(jù)訪問時(shí)間差異顯著。數(shù)據(jù)訪問,尤其是對 DRAM 的訪問,相較于計(jì)算會(huì)帶來顯著時(shí)間和功耗開銷。在高性能 AI 芯片設(shè)計(jì)中,減少內(nèi)存訪問成本至關(guān)重要,這就要求芯片具備靈活的數(shù)據(jù)流支持能力,以適應(yīng)不同數(shù)據(jù)重用模式,降低數(shù)據(jù)訪問量。不同類型的稀疏性特點(diǎn)不同,增加了芯片設(shè)計(jì)難度。輸入和權(quán)重稀疏性需逐元素計(jì)算跳過,輸出稀疏性導(dǎo)致逐向量計(jì)算跳過。AI 芯片要充分利用這些稀疏性消除冗余計(jì)算,必須具備靈活處理不同稀疏性的能力。不同應(yīng)用對數(shù)據(jù)位寬要求不同,AI 芯片需處理多種數(shù)據(jù)精度,這對處理器的計(jì)算單元提出很高要求,需要一個(gè)高效的 MAC 單元,既能滿足不同精度計(jì)算需求,又能在功耗和面積方面進(jìn)行優(yōu)化。
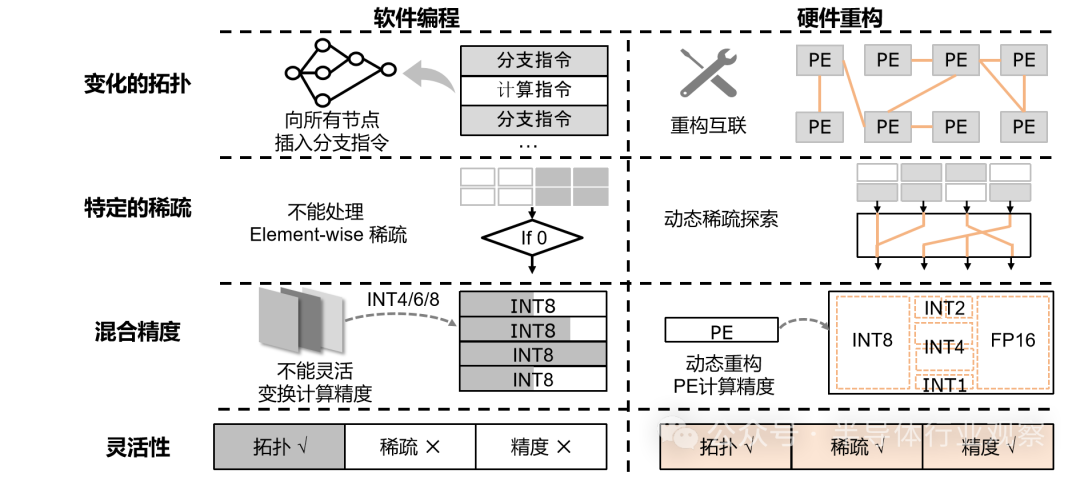
圖3. 硬件重構(gòu)優(yōu)于軟件編程
為應(yīng)對這些挑戰(zhàn),硬件重構(gòu)成為關(guān)鍵技術(shù),相較于軟件編程具有明顯優(yōu)勢。軟件編程在處理不同拓?fù)浣Y(jié)構(gòu)時(shí)具有一定靈活性,通過插入分支指令處理不同節(jié)點(diǎn),但在處理元素級(jí)稀疏性和多種精度時(shí)存在局限。軟件編程無法充分利用稀疏性優(yōu)化計(jì)算,對于不同精度計(jì)算也難以靈活切換,無法滿足 AI 芯片對靈活性的全面要求。例如,在處理大規(guī)模稀疏矩陣計(jì)算時(shí),軟件編程可能耗費(fèi)大量時(shí)間和資源處理 0 值元素,而硬件重構(gòu)能夠全面適應(yīng)神經(jīng)網(wǎng)絡(luò)的各種結(jié)構(gòu)、稀疏模式和計(jì)算精度。它可根據(jù)不同神經(jīng)網(wǎng)絡(luò)模型和任務(wù)需求,在硬件層面快速調(diào)整,實(shí)現(xiàn)資源高效利用。處理稀疏性時(shí),硬件重構(gòu)可通過專門電路設(shè)計(jì),直接對稀疏數(shù)據(jù)進(jìn)行處理,避免無效計(jì)算,提高計(jì)算效率。例如,通過設(shè)計(jì)特定的稀疏數(shù)據(jù)處理單元,可快速檢測和跳過 0 值操作數(shù),減少計(jì)算資源浪費(fèi)。應(yīng)對多種數(shù)據(jù)精度時(shí),硬件重構(gòu)能靈活切換計(jì)算單元精度模式,滿足不同層計(jì)算需求。例如,在同一芯片上,可根據(jù)不同層需求,動(dòng)態(tài)調(diào)整計(jì)算單元精度,從低精度的 INT4 到高精度的 FP16,實(shí)現(xiàn)資源優(yōu)化配置。
硬件重構(gòu)主要在芯片級(jí)、處理單元陣列(PEA)級(jí)和處理單元(PE)級(jí)三個(gè)層次進(jìn)行。芯片級(jí)重構(gòu)旨在處理輸入、權(quán)重和輸出的稀疏性,提高硬件利用率,可以通過 BENES 網(wǎng)絡(luò)實(shí)現(xiàn)。BENES 網(wǎng)絡(luò)由雙向開關(guān)單元組成,每個(gè)開關(guān)有旁路和交叉兩種模式。處理輸入和權(quán)重稀疏性時(shí),根據(jù)操作數(shù)是否為零,配置 BENES 網(wǎng)絡(luò)為對稱或不對稱結(jié)構(gòu),將非零操作數(shù)路由到 PE 進(jìn)行計(jì)算,并在計(jì)算后恢復(fù)結(jié)果的稀疏位置。對于輸出稀疏性,傳統(tǒng)順序計(jì)算存在硬件利用率低和數(shù)據(jù)重復(fù)訪問問題,而亂序計(jì)算通過 BENES 網(wǎng)絡(luò)優(yōu)化計(jì)算順序,減少向量內(nèi)存訪問,提高硬件資源利用率。例如,在處理大規(guī)模稀疏矩陣乘法時(shí),通過 BENES 網(wǎng)絡(luò)的亂序計(jì)算,可優(yōu)化原本需多次訪問內(nèi)存的數(shù)據(jù),減少內(nèi)存訪問次數(shù),提高計(jì)算效率。數(shù)據(jù)顯示:清微智能從邊緣端 TX5至云端TX8系列可重構(gòu)芯片 ,硬件利用率均可提升 50% 以上。
PEA 級(jí)重構(gòu)分為整體重構(gòu)和交錯(cuò)重構(gòu)。整體重構(gòu)中,整個(gè) PE 陣列以特定數(shù)據(jù)流運(yùn)行,適用于不同神經(jīng)網(wǎng)絡(luò)順序執(zhí)行的場景;交錯(cuò)重構(gòu)允許多個(gè)數(shù)據(jù)流在單個(gè) PE 陣列上同時(shí)運(yùn)行,適用于需同時(shí)計(jì)算多個(gè)神經(jīng)網(wǎng)絡(luò)的場景。其目的是通過改變數(shù)據(jù)流,根據(jù)不同神經(jīng)網(wǎng)絡(luò)模型的張量大小和數(shù)據(jù)重用模式,選擇固定某一張量,讓其他張量流動(dòng),從而最小化數(shù)據(jù)訪問。通過調(diào)整數(shù)據(jù)流向和計(jì)算順序,提高數(shù)據(jù)重用率,減少數(shù)據(jù)在內(nèi)存和計(jì)算單元之間的傳輸次數(shù),進(jìn)而降低功耗和提高計(jì)算效率。與 GPU 相比,GPU 硬件利用率通常僅達(dá) 50%,而可重構(gòu)芯片通過靈活的陣列級(jí)重構(gòu),能達(dá)到 80% 以上的硬件利用率。例如,在處理多個(gè)不同類型的神經(jīng)網(wǎng)絡(luò)任務(wù)時(shí),可重構(gòu)芯片的交錯(cuò)重構(gòu)能力可同時(shí)處理不同任務(wù)的數(shù)據(jù)流,充分利用硬件資源,避免資源閑置。清微智能的 TX8 系列可重構(gòu)大算力芯片通過這種數(shù)據(jù)流計(jì)算范式使中間數(shù)據(jù)直接在計(jì)算單元之間傳遞,避免大量重復(fù)訪存,計(jì)算性能和能效水平顯著提升。
PE 級(jí)重構(gòu)的目標(biāo)是支持多種數(shù)據(jù)精度,常見技術(shù)包括位串行、位融合、浮點(diǎn)融合和部分積重構(gòu)。位串行從最高有效位(MSB)到最低有效位(LSB)逐位計(jì)算,通過配置控制位決定計(jì)算周期,適用于超低功耗應(yīng)用,但吞吐量有限。位融合由多個(gè)并行的位磚單元組成,通過空間重組實(shí)現(xiàn)靈活的位寬配置,可支持不同精度計(jì)算,能顯著提升計(jì)算速度,但帶寬利用率較低。在訓(xùn)練中分離特征圖為 FP16 和 FP8 組,可提高訓(xùn)練能效,但存在硬件資源浪費(fèi)問題。浮點(diǎn)融合用于混合精度浮點(diǎn)訓(xùn)練,通過共享乘法器、對齊器、加法器和歸一化邏輯實(shí)現(xiàn)不同精度計(jì)算,從而顯著提高硬件資源利用率。部分積重構(gòu)支持混合整數(shù)和浮點(diǎn)計(jì)算,通過不同的部分積計(jì)算單元配置實(shí)現(xiàn)不同精度計(jì)算,硬件利用率較高,但功耗相對較大。例如,在對功耗要求極高的邊緣設(shè)備中,位串行技術(shù)可充分發(fā)揮其超低功耗優(yōu)勢;在對計(jì)算速度要求較高的云端應(yīng)用中,位融合技術(shù)可顯著提升計(jì)算速度。

圖4. 可重構(gòu)芯片可實(shí)現(xiàn)多層次硬件重構(gòu)
可重構(gòu)芯片憑借芯片級(jí)、陣列級(jí)和 PE 級(jí)三級(jí)重構(gòu)能力,在保持編程靈活性的情況下,通過對硬件資源的精細(xì)化重構(gòu)調(diào)度和高效利用,實(shí)現(xiàn)更高性能和更高能效的 AI 芯片設(shè)計(jì)。在芯片級(jí),由于 AI 處理的數(shù)據(jù)存在稀疏性,可重構(gòu)芯片的芯片級(jí)重構(gòu)能力能跳過無效的 0 值計(jì)算,減少內(nèi)存訪問次數(shù),提高硬件使用效率,更好發(fā)揮硬件性能并提高計(jì)算能效。在陣列級(jí),可重構(gòu)芯片能利用其陣列級(jí)重構(gòu)能力,實(shí)現(xiàn)數(shù)據(jù)流計(jì)算范式,減少中間數(shù)據(jù)在存儲(chǔ)器之間的反復(fù)搬運(yùn),降低訪存能耗,解決 “存儲(chǔ)墻” 問題,同時(shí)提高硬件資源利用效率。在 PE 級(jí),可重構(gòu)芯片利用其 PE 級(jí)多精度配置、定浮點(diǎn)融合和資源共享等重構(gòu)能力,精細(xì)控制和調(diào)度底層計(jì)算資源,顯著提高資源利用率,從而提高芯片面積利用率。
隨著 AI 技術(shù)的不斷發(fā)展,可重構(gòu)芯片的應(yīng)用前景將更加廣闊。它有望為 AI 的持續(xù)創(chuàng)新提供強(qiáng)大硬件支持,推動(dòng)人工智能技術(shù)邁向新高度。
在未來,隨著 AI 算法進(jìn)一步發(fā)展和應(yīng)用場景不斷拓展,可重構(gòu)芯片將在更多領(lǐng)域發(fā)揮重要作用。國內(nèi)規(guī)模最大的可重構(gòu)芯片廠商清微智能,目前已量產(chǎn)TX5和TX8兩大系列十余款芯片,覆蓋云邊端應(yīng)用場景,廣泛應(yīng)用至智能安防、智能機(jī)器人、智算中心,大模型市場,實(shí)現(xiàn)可重構(gòu)芯片從0到1的探索實(shí)踐。脫胎于斯坦福大學(xué)頂尖科研團(tuán)隊(duì)的 SambaNova Systems,在2023年就成為AI 芯片估值最高的獨(dú)角獸標(biāo)桿。
參考鏈接
1.Shouyi Yin. Reconfigurable Machine Learning Processor: Fundamental Concepts, Applications, and Future Trends.ASSCC 2023 Tutorial.
-
芯片
+關(guān)注
關(guān)注
459文章
52145瀏覽量
435734 -
AI
+關(guān)注
關(guān)注
87文章
34144瀏覽量
275234 -
人工智能
+關(guān)注
關(guān)注
1804文章
48677瀏覽量
246219
發(fā)布評論請先 登錄
得一微:AI存力芯片,重構(gòu)計(jì)算范式

**【技術(shù)干貨】Nordic nRF54系列芯片:傳感器數(shù)據(jù)采集與AI機(jī)器學(xué)習(xí)的完美結(jié)合**
2.5D封裝為何成為AI芯片的“寵兒”?

FPGA+AI王炸組合如何重塑未來世界:看看DeepSeek東方神秘力量如何預(yù)測......
名單公布!【書籍評測活動(dòng)NO.57】芯片通識(shí)課:一本書讀懂芯片技術(shù)
鯤云科技AI芯片CAISA 430成功適配DeepSeek R1模型

一文讀懂:LED 驅(qū)動(dòng)電路二極管挑選要點(diǎn)
一文讀懂什么是「雷電4」

TB1801線性車燈專用芯片可完美替代LAN1165E


AI芯片的混合精度計(jì)算與靈活可擴(kuò)展
一文讀懂汽車控制芯片(MCU)






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論