 Rail-Only拓撲與PCI Switch:GPU集群間高效通信的核心邏輯
Rail-Only拓撲與PCI Switch:GPU集群間高效通信的核心邏輯

當前AI推理面臨兩大核心矛盾
算力需求激增:大模型應用爆發(如實時交互、多模態生成),企業亟需更低延遲、更高吞吐的推理能力;
資源浪費嚴重:傳統架構下,GPU算力閑置率超30%,長文本處理場景首Token延遲飆升至秒級,用戶體驗流失率增加40%。
DeepSeek-V3/R1的給我們的啟示:混合專家模型(MoE)雖需320卡起步,卻為超大規模云計算廠商提供了差異化競爭力——吞吐效率提升50%,單用戶推理成本降低20%。而對中小客戶,“高性價比”仍是剛需,Dense模型憑借靈活部署穩占80%市場份額。
組網架構的“黃金分割”
行業需求驅動架構革新
分離架構:適合頭部云廠商(如AWS、阿里云),通過獨立優化Prefill(算力密集型)和Decode(帶寬密集型)集群,實現超大規模并發下的極致性能,客戶可溢價30%提供“高端推理服務”。
統一架構:中小廠商的“降本利器”——單網絡支持智能流量調度,硬件投資減少25%,運維成本降低40%,兼容80%現有基礎設施,快速搶占中端市場。
采用星融元CX-N系列交換機+RoCEv2技術,單設備支持400G/800G帶寬,滿足“既要大吞吐又要低延遲”的矛盾需求。
從實驗室到生產線:組網設計的成本與效益平衡
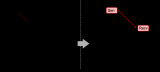
Rail-Only拓撲:4 GPU/組共享PCIe鏈路,服務器內直連減少跳數,適合百卡以下集群,硬件成本降低30%。
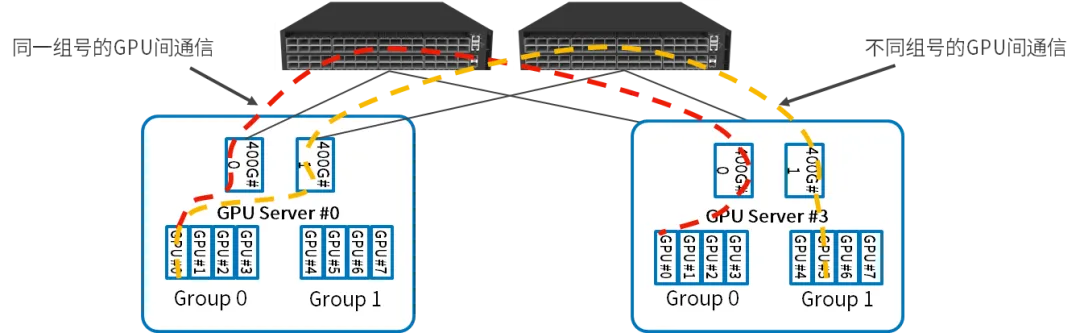
GPU服務器內部:每四個GPU作為一組,共享一個并行推理網卡,連接到同一個PCI Switch,兩組GPU之間的通信通過兩個PCI Switch之間的直連通道完成;
GPU服務器之間:同一組號的GPU之間的通信通過交換機直接完成;不同組號的GPU之間的通信,先通過PCI Swtitch將流量路由到另一組的網卡,然后通過交換機完成;
小規模場景:低成本敏捷部署
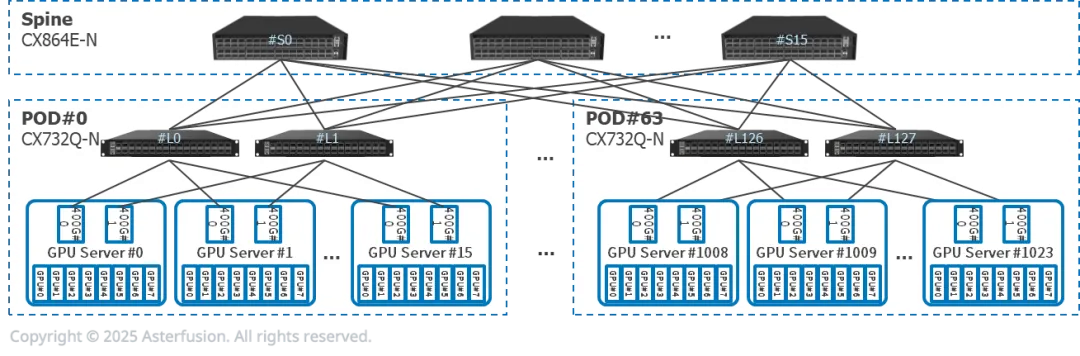
每臺推理服務器有8張GPU,2張400G網卡,雙歸連接到兩臺CX732Q-N
16個推理服務器(128張GPU)和2個CX732Q-N組成一個PoD。Prefill和Decode服務器可能屬于不同PoD
可橫向擴展至64個PoD
中大規模場景:性能與擴展性優先
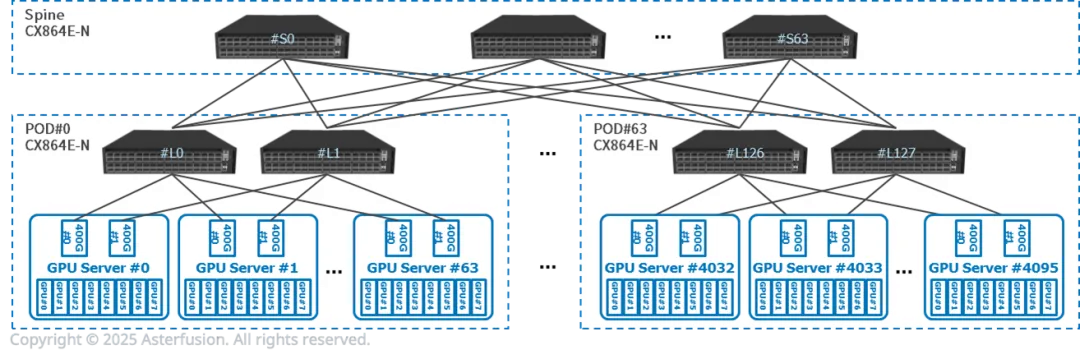
模塊化PoD設計:以512 GPU為單元構建獨立集群,Prefill與Decode服務器同PoD內一跳互聯,時延控制在10μs以內。
橫向擴展能力:可橫向擴展至64個PoD,支持萬卡級集群無縫擴容,滿足云計算平臺彈性需求。
未來展望:開放生態與硬件迭代的雙重助力
盡管DeepSeek尚未開源,但其PD分離架構為行業提供了關鍵思路。未來趨勢將圍繞兩大方向:
軟硬件協同優化:如DPU卸載KV緩存傳輸任務,進一步釋放GPU算力;
邊緣AI輕量化:通過模型剪枝與專用推理芯片,在10卡以下環境中實現MoE模型部署。
【參考文獻】
https://asterfusion.com/a20250306-scale-out/
審核編輯 黃宇
-
gpu
+關注
關注
28文章
4944瀏覽量
131217 -
PCI
+關注
關注
5文章
679瀏覽量
131988 -
AI
+關注
關注
88文章
35109瀏覽量
279587 -
組網
+關注
關注
1文章
392瀏覽量
22860
發布評論請先 登錄
熱插拔算力集群
如何破解GPU集群集合通信路徑的“黑盒”難題?
iTOP-3588S開發板四核心架構GPU內置GPU可以完全兼容0penGLES1.1、2.0和3.2。

ADA4511-2: Precision, 40 V, Rail-to-Rail Input and Output Op Amp with DigiTrim Data Sheet adi

小米加速布局AI大模型,搭建GPU萬卡集群
分布式通信的原理和實現高效分布式通信背后的技術NVLink的演進
華迅光通AI計算加速800G光模塊部署
GPU服務器AI網絡架構設計






 工商網監
工商網監
評論