 暢享DeepSeek自由!憶聯高性能CSSD為端側大模型加速
暢享DeepSeek自由!憶聯高性能CSSD為端側大模型加速
當下,開源大模型DeepSeek憑借其強大的語言理解和生成能力,已成為全民追捧的AI工具。無論是文案創作還是代碼編寫,只需“DeepSeek一下”即可輕松解決。然而,隨著用戶訪問量的激增,服務器無響應、等待時間長等問題也屢見不鮮。一時間,能夠離線運行,且更具隱私性的DeepSeek端側部署也成為新風向。
本地部署雖具備諸多優點,但對電腦的硬件配置卻有一定的要求。大模型包含大量參數,即使是蒸餾過的小模型,模型大小也動輒幾十GB甚至上百GB。電腦除了需要CPU、GPU能夠高效運行之外,一款高性能的SSD也必不可少。 憶聯AM541搭載新一代Jaguar6020主控,內置高容量SRAM及IO加速模塊,順序讀取速度高達7000 MB/s,能夠輕松應對DeepSeek大模型加載等高負載場景,為用戶提供流暢的使用體驗,讓用戶真正實現“DeepSeek自由”。
適配度100%,大模型首次加載絲滑流暢
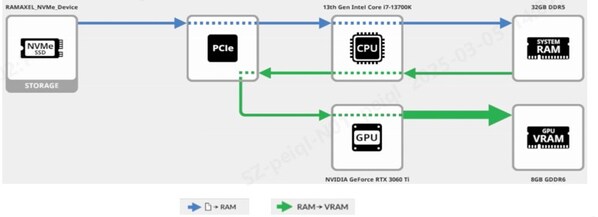
在DeepSeek本地加載運行過程中,SSD是整個數據流的第一棒。當DeepSeek完成本地部署后,模型文件即保存在SSD中。當用戶加載模型時,會先將大模型文件從SSD讀取到系統內存中,再由內存中轉傳輸到顯存,由GPU進行推理運算。因此,SSD的性能越好,就能越快將數據傳輸到GPU進行計算,體現在實際應用中就是大模型的加載時間越短。
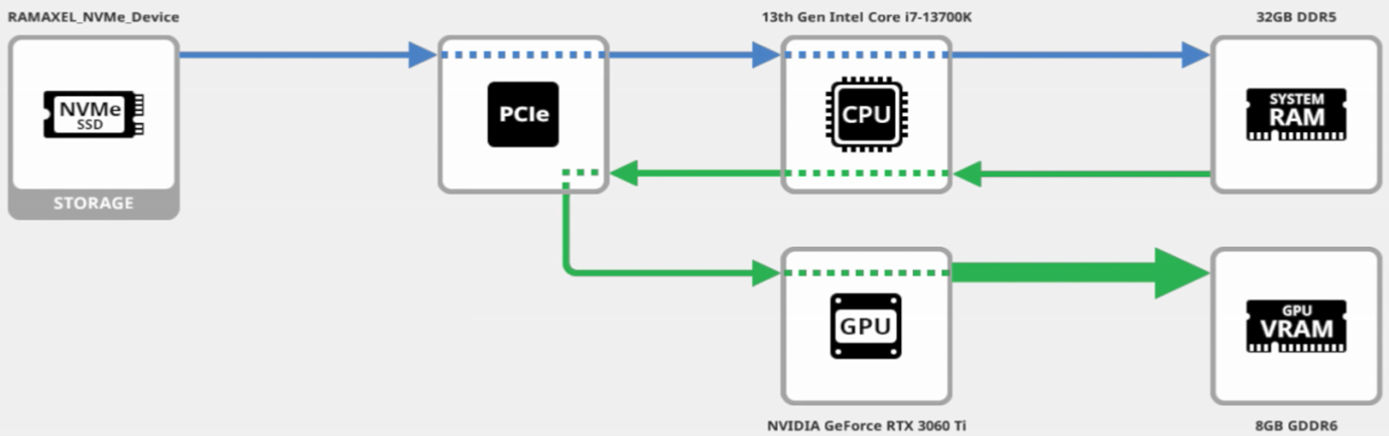 加載大模型時數據流方式
加載大模型時數據流方式
為了驗證憶聯AM541的性能及場景適配度,我們通過Ollama模型框架在本地部署了Deepseek-R1 8B模型,采用憶聯AM541 1TB SSD及國內友商1TB A產品搭配GeForce RTX 3060 Ti 顯卡,在同等環境下進行了模型加載測
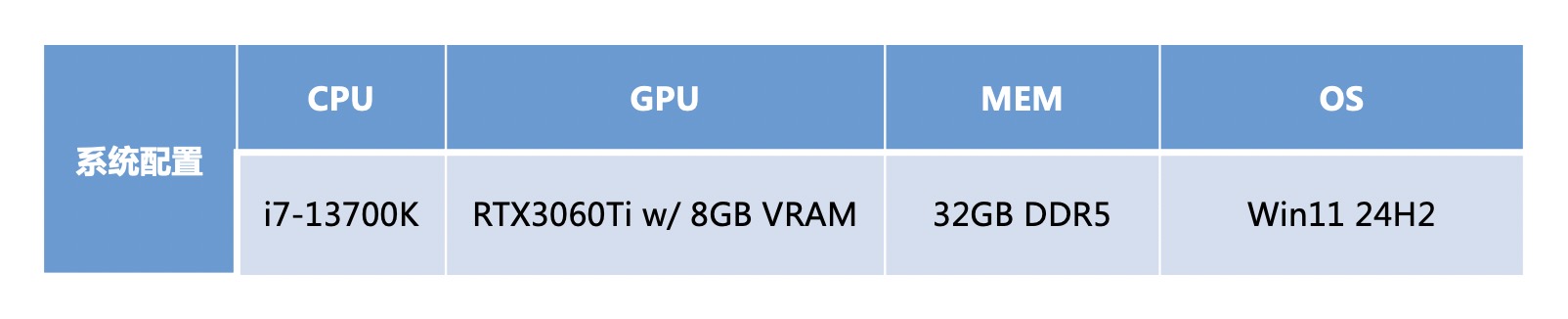 系統配置
系統配置
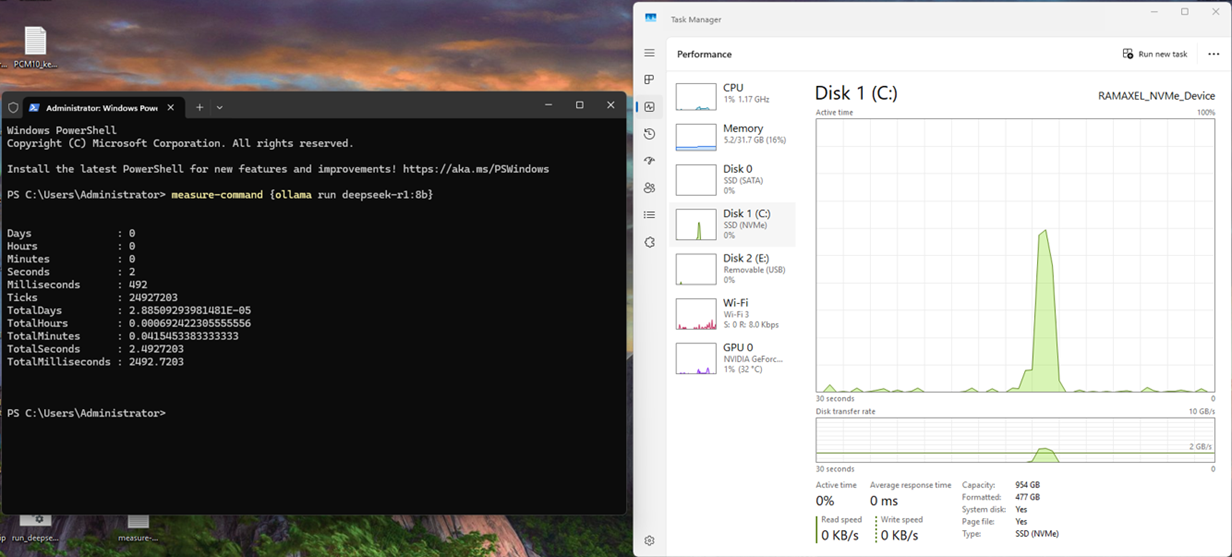 大模型加載時SSD狀態(見右側圖)
大模型加載時SSD狀態(見右側圖)
測試結果顯示,搭載AM541的PC在加載大模型時表現出色,首次加載時間(最快)僅為2.486秒,領先國內一線SSD廠商同類產品約9%。這一成績充分體現了AM541對DeepSeek等高負載應用100%適配,能夠為用戶帶來更加流暢的使用體驗。
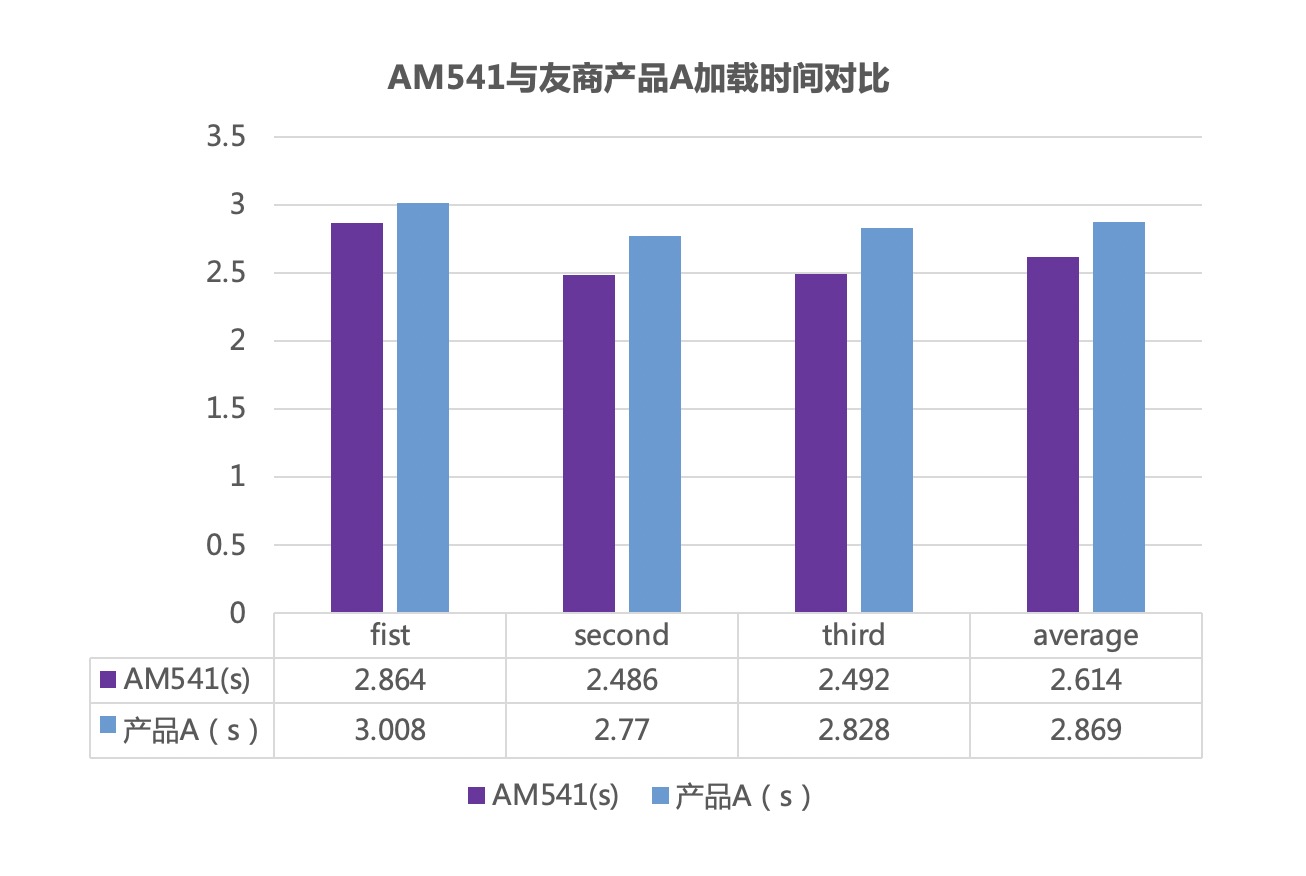
順序讀突破7GB/s,硬核性能助力用戶暢享“DeepSeek自由”
更短加載時間背后,反映的是SSD更高的性能及更加靈活的場景適應性。得益于SoC內置的加速模塊,AM541的標稱順序讀寫速度達到了7000 MB/s、5600 MB/s ,4KB隨機讀寫速度可達800K IOPS、800K IOPS。從DeepSeek加載時的pattern解析來看,AM541性能波峰接近7GB/s,這與其標稱的性能高度吻合。
AM541緣何更快?測試人員進一步對加載過程進行了trace解析,發現模型加載過程主要以大size命令的低QD順序讀為主,而AM541自帶的Big SRAM策略及延遲控制機制在處理此類命令時優勢明顯,使得大模型加載時間大幅領先友商。
此外,經測試發現,當大模型在搭載AM541的電腦上完成首次加載后,模型文件即被DRAM緩存,因此當設備Idle后再次加載時,模型文件可以直接從DRAM傳輸到VRAM,加載時間比首次更快,真正將DeepSeek變為用戶的“私人工具“,隨時暢享“DeepSeek自由”。
擁抱大模型,憶聯為AI生態持續助力
隨著AI本地化趨勢的加速,DeepSeek一體機等終端設備也逐漸普及。在消費電子領域,已有主流 PC廠商將DeepSeek大模型嵌入AIPC中,多款手機也開始發力AI大模型。未來,個人電腦、手機等終端設備極有可能會搭載多種大模型,甚至各種行業應用也會接入大模型。面對不同參數規模的AI模型,以及不同模型頻繁切換帶來的高頻讀寫過程,SSD不僅要有足夠大的容量,同時對SSD的全面性能及穩定性都是一種考驗。
依托硬件加速及先進的軟件算法,AM541不僅在低QD Latency上具備優勢,在多種混合讀寫中均有出色表現,可輕松應對多應用場景。
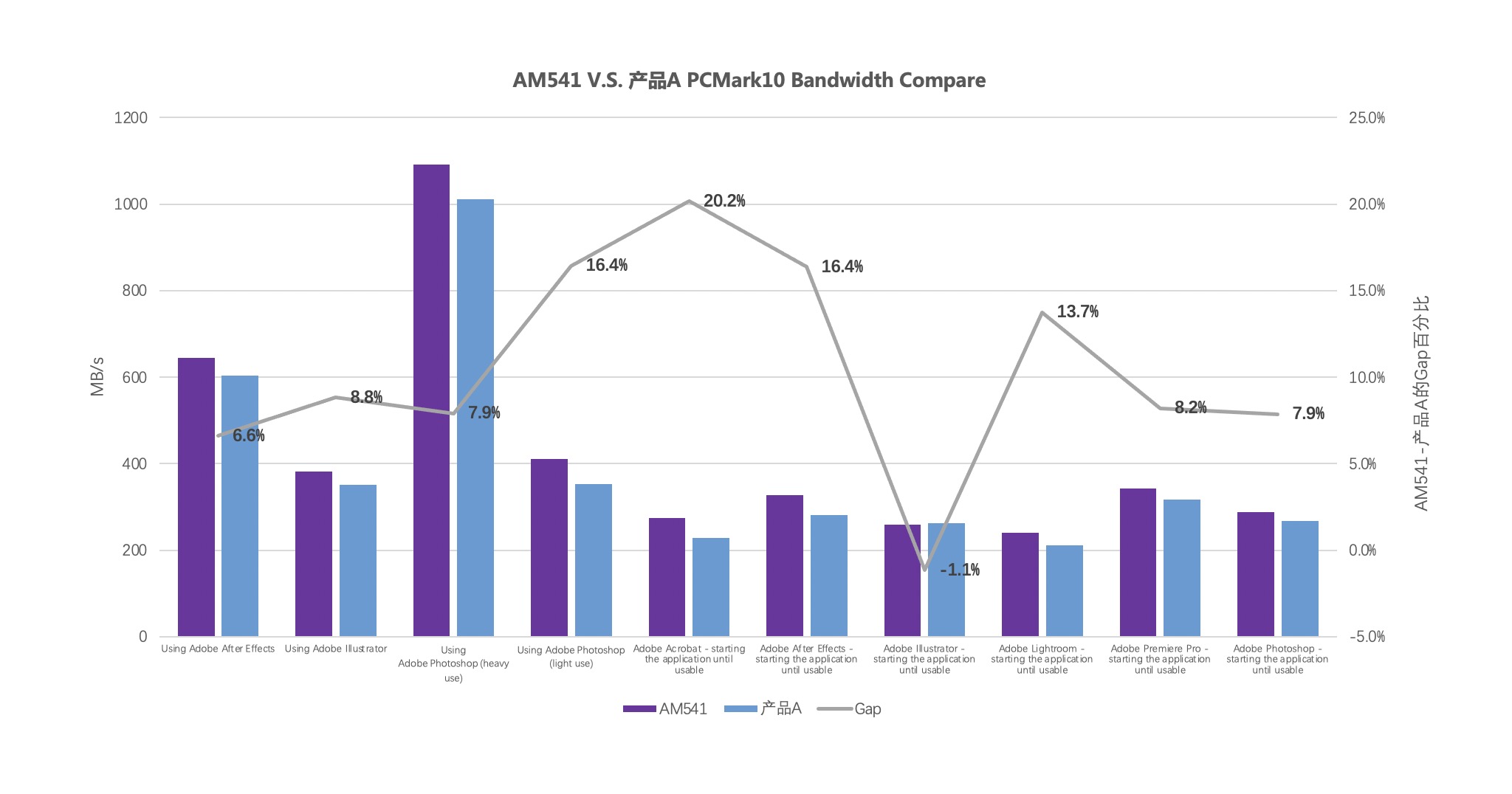
在PCMark10測試中,AM541跑分超過了3700,比友商同類產品A高出約300分,在辦公、游戲、內容創作等多個場景中性能領先,其中,在常見的數字內容創作中,AM541平均比友商同類產品快10.5%。
AI浪潮奔涌不停,技術創新日新月異,作為底層硬件支撐,SSD在AI本地化進程中扮演著關鍵角色。憶聯AM541憑借其硬核性能,不僅為DeepSeek大模型的本地化部署提供了高效解決方案,也為用戶帶來了前所未有的使用體驗。未來,憶聯將緊跟行業趨勢,聚焦端側大模型的技術痛點,推進技術創新與產品迭代,為AI生態的繁榮發展提供持續動能。
審核編輯 黃宇
-
存儲
+關注
關注
13文章
4499瀏覽量
87054 -
CSSD
+關注
關注
0文章
7瀏覽量
6624 -
大模型
+關注
關注
2文章
3020瀏覽量
3803 -
AI大模型
+關注
關注
0文章
362瀏覽量
497 -
DeepSeek
+關注
關注
1文章
772瀏覽量
1313
發布評論請先 登錄
首創開源架構,天璣AI開發套件讓端側AI模型接入得心應手
硅基覺醒已至前夜,聯發科攜手生態加速智能體化用戶體驗時代到來
暢享DeepSeek自由,憶聯高性能CSSD為端側大模型加速
聆思CSK6大模型語音開發板接入DeepSeek資料匯總(包含深度求索/火山引擎/硅基流動華為昇騰滿血版)
RK3588開發板上部署DeepSeek-R1大模型的完整指南
添越智創基于 RK3588 開發板部署測試 DeepSeek 模型全攻略
了解DeepSeek-V3 和 DeepSeek-R1兩個大模型的不同定位和應用選擇
移遠通信邊緣計算模組成功運行DeepSeek模型,以領先的工程能力加速端側AI落地

移遠通信邊緣計算模組成功運行DeepSeek模型,以領先的工程能力加速端側AI落地

DeepSeek模型成功部署,物通博聯在 AI 賦能工業上持續探索、不斷前行
寧暢AI服務器全面支持DeepSeek大模型
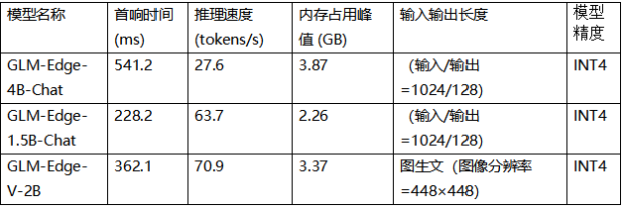
智譜推出四個全新端側模型 攜英特爾按下AI普及加速鍵





 工商網監
工商網監
評論