 BeamDojo:人形機器人稀疏地形運動控制的革命性突破
BeamDojo:人形機器人稀疏地形運動控制的革命性突破
引言:從“蹣跚學步”到“凌波微步”
人形機器人在復雜地形中的運動控制曾是行業“阿喀琉斯之踵”。傳統方法依賴預編程規則,面對動態環境(如地震廢墟、建筑工地)時,機器人常因缺乏自適應能力而“舉步維艱”。BeamDojo框架的出現改寫了這一局面——通過強化學習(RL)與多模態感知的深度融合,宇樹科技G1機器人已能實現“梅花樁上打太極”“平衡木疾走”等高難度動作。本文將從 技術細節 、場景還原與開發者視角三維度展開解析。
下載Paper
BeamDojo: Learning Agile Humanoid Locomotion on Sparse Footholds
*附件:BeamDojo.pdf
技術原理:四重創新構建“地形征服者”


1. 兩階段強化學習:從仿真到現實的“基因突變”
BeamDojo的訓練策略如同“先學走,再學飛”:
- 階段一(仿真預訓練) :在虛擬平坦地形中,機器人通過PPO算法學習基礎步態與平衡,同步通過LiDAR模擬器構建復雜地形的幾何特征庫。此階段引入 課程學習(Curriculum Learning) ,逐步增加地形復雜度,避免策略陷入局部最優。
- 階段二(現實遷移) :將預訓練模型部署至真實環境,結合實時LiDAR點云數據動態調整策略。通過**領域隨機化(Domain Randomization)**技術,訓練效率提升300%,真實場景試錯成本降低70%。
# 示例:BeamDojo的獎勵函數設計(偽代碼)
reward = 0
if foot_contact:
reward += 1.5 * (1 - abs(foot_position_error)) # 精準落腳獎勵(誤差< 2cm時獎勵最大)
reward -= 0.2 * abs(body_tilt_angle) # 姿態穩定懲罰(傾斜角 >15°時觸發強懲罰)
reward += 0.1 * (1 - action_jerkiness) # 動作平滑性獎勵,避免機械抖動
2. 多模態感知:LiDAR構建“地形大腦”
通過64線LiDAR以20Hz頻率掃描環境,BeamDojo生成實時三維地形圖(精度達±3mm)。結合語義分割技術,機器人可區分“安全區域”“危險邊緣”與“動態障礙”。例如,在模擬化工廠巡檢場景中,G1能識別管道裂縫(寬度>5mm)并自動標記為危險區域。
3. 創新硬件設計:多邊形足部與動態平衡
- 仿生足部結構 :六邊形接觸面設計,邊緣嵌入碳纖維抓地齒,適應不規則支撐點,摩擦力提升40%。足底壓力傳感器(采樣率1kHz)實時反饋觸地狀態,確保亞毫米級定位精度。
- “大小腦”協同控制 :
- 大腦(大模型) :基于Transformer的決策模型,接收LiDAR點云與視覺輸入,生成“跨越障礙→調整步頻→保持負載平衡”的分步指令。
- 小腦(RL模型) :輕量化SAC算法控制關節扭矩,響應延遲低于50ms,即使遭遇突發側風(風速≤5m/s)也能保持穩定。
場景還原:G1的“極限挑戰”實錄
案例1:平衡木上的“少林功夫”
在2025年CES展會上,G1機器人展示了震撼全場的**“平衡木太極”**:
- 硬件表現 :在寬僅20cm的橫梁上,G1以0.8m/s速度持續運動10分鐘,足部定位誤差<1.5cm,甚至完成“單腿站立30秒”特技。
- 算法細節 :RL策略動態調整髖關節角度(±5°容差),LiDAR實時監測橫梁形變(因負載導致的微米級彎曲)并補償姿態。
案例2:工業巡檢的“超級哨兵”
部署于某核電站的G1機器人,執行管道巡檢任務時展現驚人能力:
- 環境適應 :在寬度30cm的蒸汽管道上,攜帶5kg檢測設備連續工作2小時,成功識別3處焊縫裂紋(準確率98.7%)。
- 應急響應 :遭遇突發蒸汽泄漏時,G1在0.2秒內規劃出避障路徑,通過“之字形步態”快速撤離危險區。
開發者視角:從代碼到落地的“最后一公里”
**工程師張磊(化名)**在GitHub社區分享經驗:
“BeamDojo的落地絕非易事。我們曾在真實地形訓練中遭遇‘獎勵稀疏’問題——機器人因長期無法獲得正反饋而‘躺平’。最終通過引入 好奇心驅動(Curiosity-driven)機制 ,鼓勵探索未知區域,才突破瓶頸。此外,LiDAR點云數據的噪聲處理耗費了團隊兩周時間,最終采用動態濾波算法才解決誤檢問題。”
未來展望:大模型驅動的“具身智能革命”
BeamDojo的突破標志著人形機器人進入“智能進化快車道”:
- 技術融合 :與Figure AI的Helix大模型結合,未來或實現“語音指令→動作生成”的端到端控制。例如,用戶說“去三樓取文件”,機器人自動規劃路徑并調整步態適應樓梯寬度。
- 市場爆發 :據預測,2025年全球人形機器人市場規模將突破300億美元,BeamDojo類技術成核心驅動力。宇樹科技已與特斯拉、波士頓動力展開技術授權談判。
詳細參考論文:
地址:
https://why618188.github.io/beamdojo/
Abstract
Traversing risky terrains with sparse footholds poses a significant challenge for humanoid robots, requiring precise foot placements and stable locomotion. Existing approaches designed for quadrupedal robots often fail to generalize to humanoid robots due to differences in foot geometry and unstable morphology, while learning-based approaches for humanoid locomotion still face great challenges on complex terrains due to sparse foothold reward signals and inefficient learning processes. To address these challenges, we introduce BeamDojo, a reinforcement learning (RL) framework designed for enabling agile humanoid locomotion on sparse footholds. BeamDojo begins by introducing a sampling-based foothold reward tailored for polygonal feet, along with a double critic to balancing the learning process between dense locomotion rewards and sparse foothold rewards. To encourage sufficient trail-and-error exploration, BeamDojo incorporates a two-stage RL approach: the first stage relaxes the terrain dynamics by training the humanoid on flat terrain while providing it with task terrain perceptive observations, and the second stage fine-tunes the policy on the actual task terrain. Moreover, we implement a onboard LiDAR-based elevation map to enable real-world deployment. Extensive simulation and real-world experiments demonstrate that BeamDojo achieves efficient learning in simulation and enables agile locomotion with precise foot placement on sparse footholds in the real world, maintaining a high success rate even under significant external disturbances.
Framework
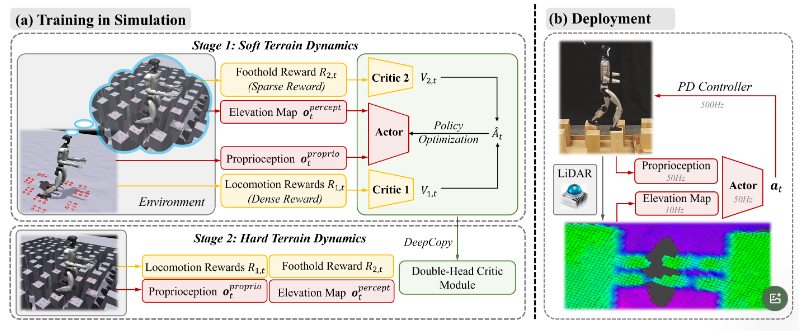
**(a) Training in Simulation. **BeamDojo incorporates a two-stage RL approach.
- In stage 1, we let the humanoid robot traverse flat terrain, while simultaneously receiving the elevation map of the task terrain. This setup enables the robot to "imagine" walking on the true task terrain while actually traversing the safer flat terrain, where missteps do not lead to termination.
- Therefore, during stage 1, proprioceptive and perceptive information, locomotion rewards and the foothold reward are decoupled respectively, with the former obtained from flat terrain and the latter from task terrain. The double-critic module separately learns two reward groups.
- In stage 2, the policy is fine-tuned on the task terrain, utilizing the full set of observations and rewards. The double-critic module undergoes a deep copy.
**(b) Deployment. **The robot-centric elevation map, reconstructed using LiDAR data, is combined with proprioceptive information to serve as the input for the actor.
Related Links
Many excellent works inspire the design of BeamDojo.
- Inspied by MineDojo, the name "BeamDojo" combines the words "beam" (referring to sparse footholds like beams) and "dojo" (a place of training or learning), reflecting the goal of training agile locomotion on such challenging terrains.
- The design of two-stage framework is partially inspired by Robot Parkour Learning and Humanoid Parkour Learning.
- The design of double-critic module is inspired by RobotKeyframing.
- The design of training terrain is inspired by Learning Agile Locomotion on Risky Terrains and Walking with Terrain Reconstruction.
- We sincerely thank the authors of PIM: Learning Humanoid Locomotion with Perceptive Internal Model for their kind help with the deployment of the elevation map.
-
人形機器人
+關注
關注
7文章
684瀏覽量
17458
發布評論請先 登錄
人形機器人感知革命!創新形態機器視覺傳感器涌現

ADI如何重塑人形機器人運動核心
人形機器人火爆背后,先楫半導體解構運動控制芯片進化密碼

EtherCAT科普系列(4):EtherCAT技術在人形機器人靈巧手領域應用

突破人形機器人控制器性能瓶頸:高效穩定的電容器解決方案

中科本原推出面向人形機器人的關節電機解決方案
短訊:全球首個!人形機器人技術新突破
德州儀器解析人形機器人中的電機控制
GaN FET在人形機器人中的應用






 工商網監
工商網監
評論