") spss聚類分析步驟
spss聚類分析步驟
spss是一個非常好用的統(tǒng)計(jì)分析軟件,spss有一個聚類分析的功能哦,但是很多人不知道spss聚類分析功能怎么使用?spss聚類分析是一個將case分析的數(shù)據(jù)的功能哦
spss聚類分析使用步驟教程:
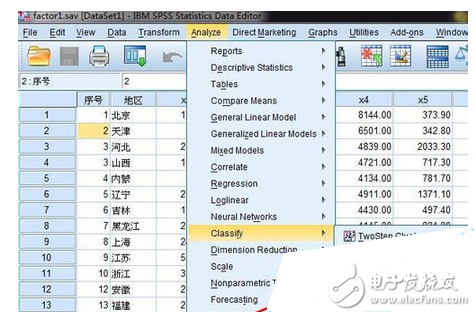
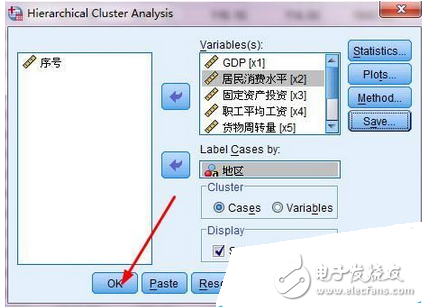
1、依次點(diǎn)擊:analyse--classify--hierarchical cluster,打開分層聚類對話框。如圖1所示
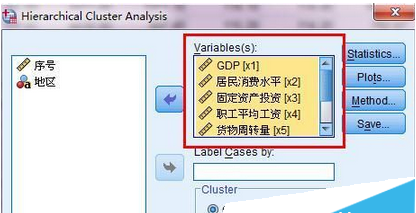
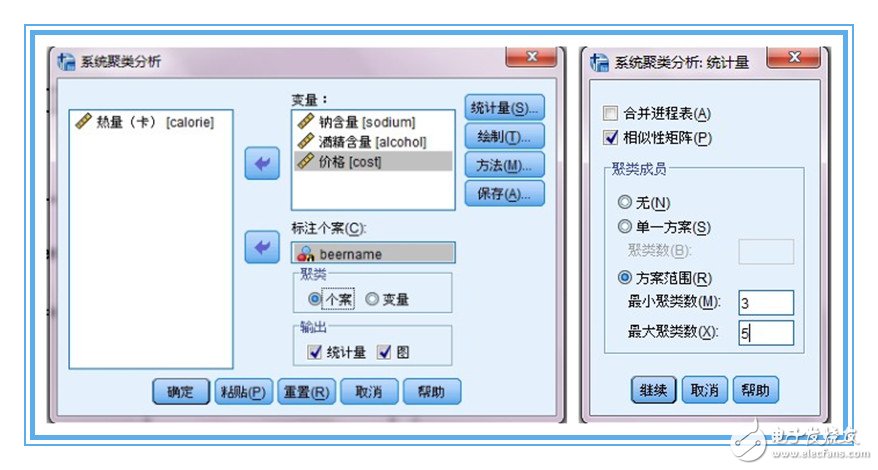
2、在聚類分析對話框中,將聚類用到的變量都放到variables中。如圖2所示
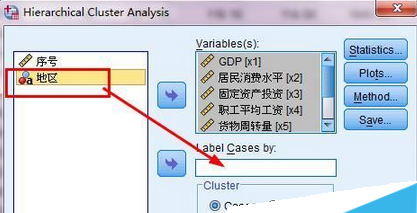
3、將地區(qū)變量放入case標(biāo)簽中,他的意思是每一個數(shù)據(jù)都用地區(qū)這個值來命名。如圖3所示
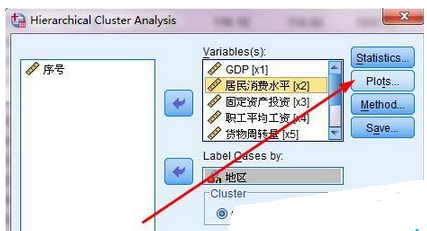
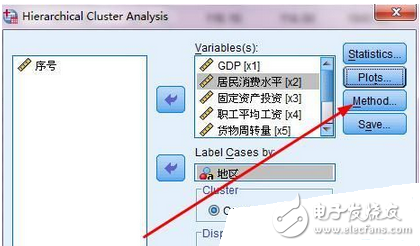
4、點(diǎn)擊plot按鈕,打開對話框,設(shè)置要輸出的圖。如圖4所示
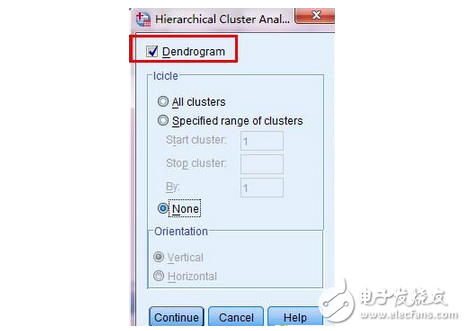
5、在打開的對話框中,勾選dendrogram,然后點(diǎn)擊continue按鈕。這個dendrogram是層次聚類譜系圖,最后我們還會分析這個圖。如圖5所示
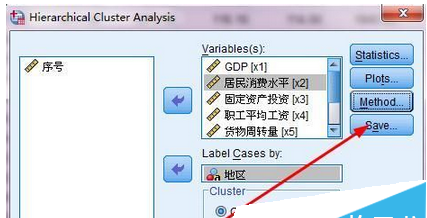
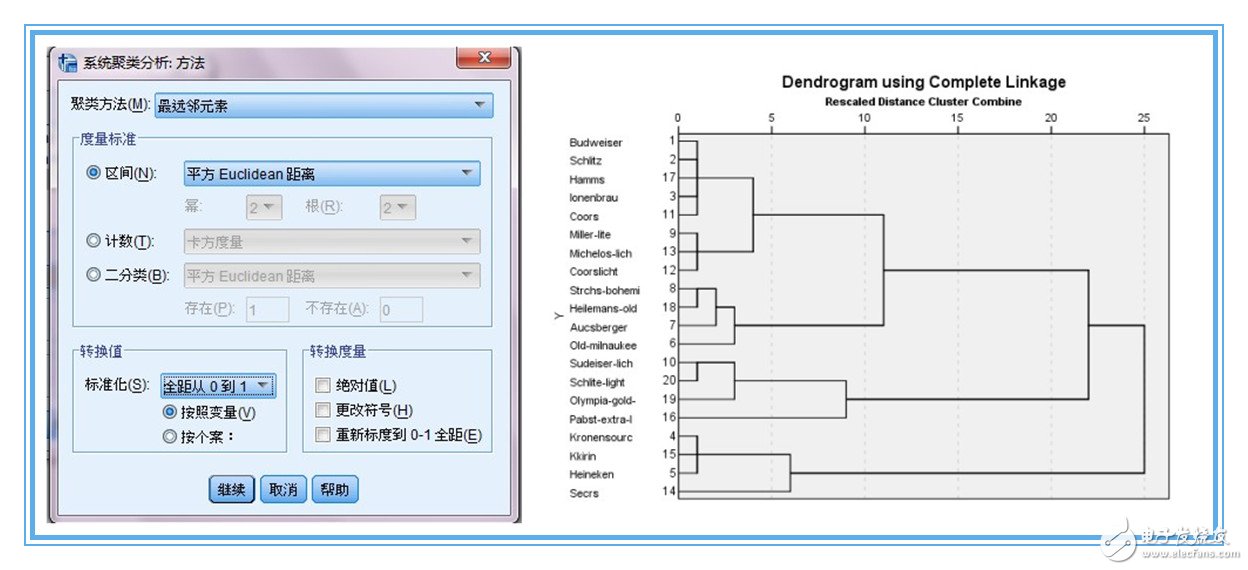
6、點(diǎn)擊method按鈕,設(shè)置聚類的方法。如圖6所示
7、通常我們用到的聚類方法是wards method,接著我們需要把變量轉(zhuǎn)換成z分?jǐn)?shù),點(diǎn)擊continue按鈕。如圖7所示

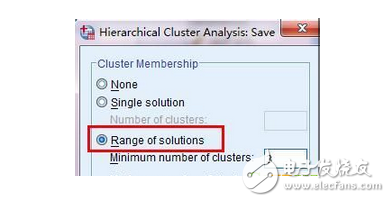
8、點(diǎn)擊save按鈕,填寫希望保存的聚類類別數(shù)范圍3--8,據(jù)此選項(xiàng),spss將在數(shù)據(jù)編輯窗口中添加7個變量,分別標(biāo)明聚類數(shù)位3--8類情況下各省市所屬的類。如圖8所示
9、設(shè)置輸出的聚類類別數(shù)范圍3--8,點(diǎn)擊continue按鈕。如圖9所示
10、點(diǎn)擊ok按鈕,開始輸出數(shù)據(jù)處理的結(jié)果。如圖10所示
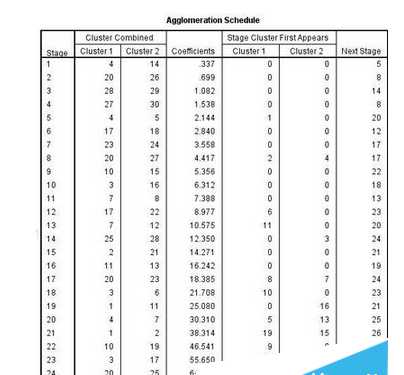
11、你看到的下面的這個表格叫做聚類過程表,其內(nèi)容并不是經(jīng)常被關(guān)注,因?yàn)榇蟛糠謱?shí)際應(yīng)用中,聚類的具體過程是被忽略的。但是聚類系數(shù)可以幫助我們判斷將數(shù)據(jù)分為幾類最合適,判斷的方法是,相鄰的兩個數(shù)據(jù)變化的幅度顯著大于前面的系數(shù)的變化范圍,這時候分類在這里就是最好的。如圖11所示
12、最后是層次聚類譜系圖,從這個圖中可看到聚類的過程,根據(jù)你的需求選擇分類的組數(shù)。如圖12所示

以上就是spss聚類分析功能的使用方法哦,大家安裝步驟一步步來就會操作了呢!
案例數(shù)據(jù)源:
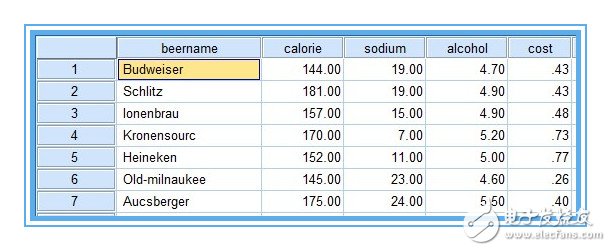
有20種12盎司啤酒成分和價(jià)格的數(shù)據(jù),變量包括啤酒名稱、熱量、鈉含量、酒精含量、價(jià)格。數(shù)據(jù)來自《SPSS for Windows 統(tǒng)計(jì)分析》data11-03。點(diǎn)擊下載
【一】問題一:選擇那些變量進(jìn)行聚類?——采用“R型聚類”
1、現(xiàn)在我們有4個變量用來對啤酒分類,是否有必要將4個變量都納入作為分類變量呢?熱量、鈉含量、酒精含量這3個指標(biāo)是要通過化驗(yàn)員的辛苦努力來測定,而且還有花費(fèi)不少成本,如果都納入分析的話,豈不太麻煩太浪費(fèi)?所以,有必要對4個變量進(jìn)行降維處理,這里采用spss R型聚類(變量聚類),對4個變量進(jìn)行降維處理。輸出“相似性矩陣”有助于我們理解降維的過程。
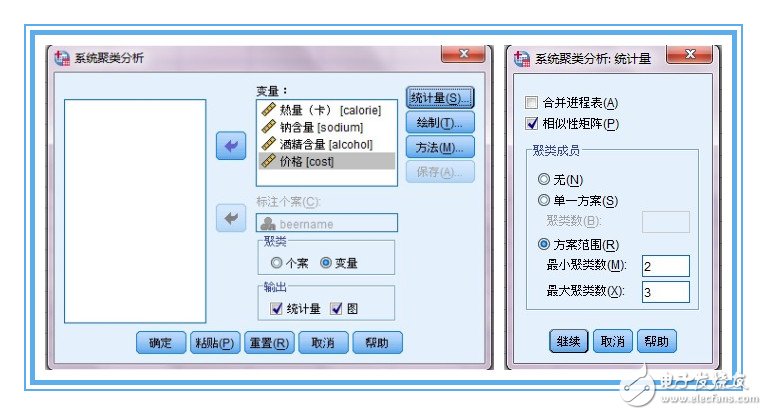
2、4個分類變量量綱各自不同,這一次我們先確定用相似性來測度,度量標(biāo)準(zhǔn)選用pearson系數(shù),聚類方法選最遠(yuǎn)元素,此時,涉及到相關(guān),4個變量可不用標(biāo)準(zhǔn)化處理,將來的相似性矩陣?yán)锏臄?shù)字為相關(guān)系數(shù)。若果有某兩個變量的相關(guān)系數(shù)接近1或-1,說明兩個變量可互相替代。
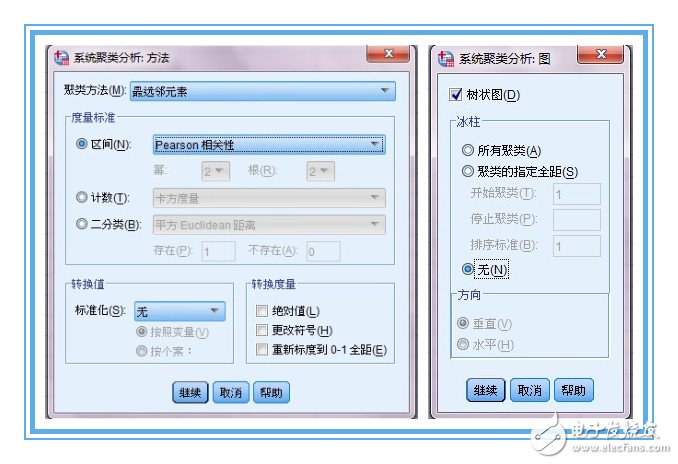
3、只輸出“樹狀圖”就可以了,個人覺得冰柱圖很復(fù)雜,看起來沒有樹狀圖清晰明了。從proximity matrix表中可以看出熱量和酒精含量兩個變量相關(guān)系數(shù)0.903,最大,二者選其一即可,沒有必要都作為聚類變量,導(dǎo)致成本增加。至于熱量和酒精含量選擇哪一個作為典型指標(biāo)來代替原來的兩個變量,可以根據(jù)專業(yè)知識或測定的難易程度決定。(與因子分析不同,是完全踢掉其中一個變量以達(dá)到降維的目的。)這里選用酒精含量,至此,確定出用于聚類的變量為:酒精含量,鈉含量,價(jià)格。
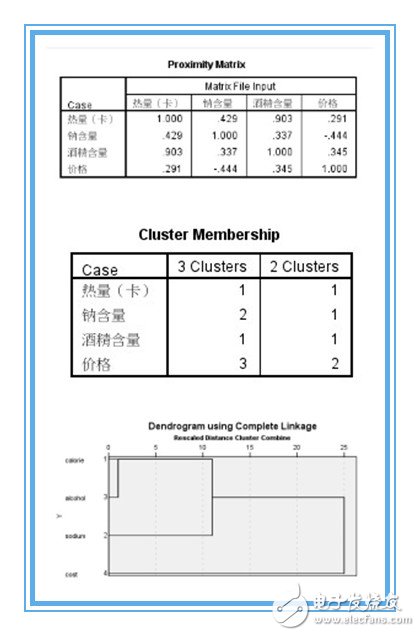
【二】問題二:20中啤酒能分為幾類?——采用“Q型聚類”
1、現(xiàn)在開始對20中啤酒進(jìn)行聚類。開始不確定應(yīng)該分為幾類,暫時用一個3-5類范圍來試探。Q型聚類要求量綱相同,所以我們需要對數(shù)據(jù)標(biāo)準(zhǔn)化,這一回用歐式距離平方進(jìn)行測度。
2、主要通過樹狀圖和冰柱圖來理解類別。最終是分為4類還是3類,這是個復(fù)雜的過程,需要專業(yè)知識和最初的目的來識別。我這里試著確定分為4類。選擇“保存”,則在數(shù)據(jù)區(qū)域內(nèi)會自動生成聚類結(jié)果。
【三】問題三:用于聚類的變量對聚類過程、結(jié)果又貢獻(xiàn)么,有用么?——采用“單因素方差分析”
1、聚類分析除了對類別的確定需討論外,還有一個比較關(guān)鍵的問題就是分類變量到底對聚類有沒有作用有沒有貢獻(xiàn),如果有個別變量對分類沒有作用的話,應(yīng)該剔除。
2、這個過程一般用單因素方差分析來判斷。注意此時,因子變量選擇聚為4類的結(jié)果,而將三個聚類變量作為因變量處理。方差分析結(jié)果顯示,三個聚類變量sig值均極顯著,我們用于分類的3個變量對分類有作用,可以使用,作為聚類變量是比較合理的。
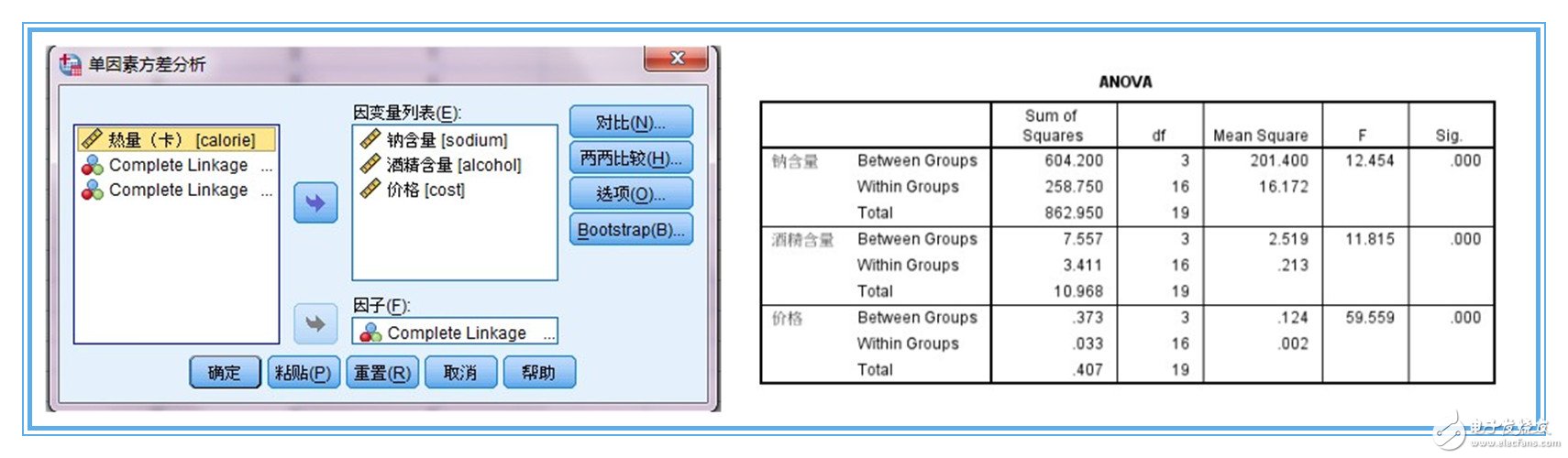
【四】問題四:聚類結(jié)果的解釋?——采用”均值比較描述統(tǒng)計(jì)“
1、聚類分析最后一步,也是最為困難的就是對分出的各類進(jìn)行定義解釋,描述各類的特征,即各類別特征描述。這需要專業(yè)知識作為基礎(chǔ)并結(jié)合分析目的才能得出。
2、我們可以采用spss的means均值比較過程,或者excel的透視表功能對各類的各個指標(biāo)進(jìn)行描述。其中,report報(bào)表用于描述聚類結(jié)果。對各類指標(biāo)的比較來初步定義類別,主要根據(jù)專業(yè)知識來判定。這里到此為止。
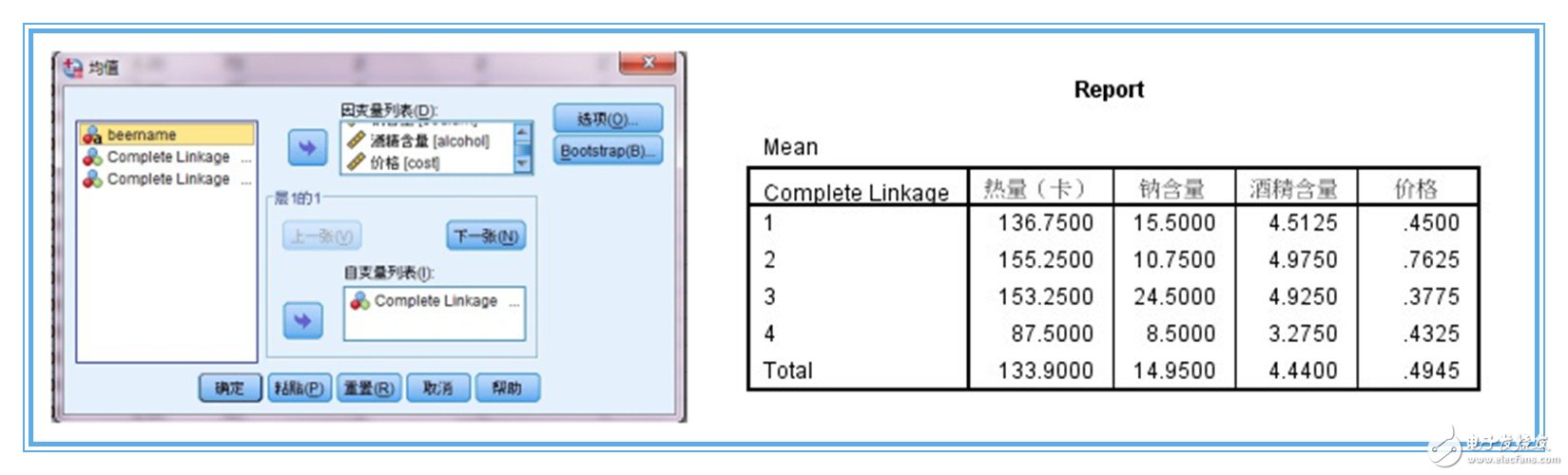
以上過程涉及到spss層次聚類中的Q型聚類和R型聚類,單因素方差分析,means過程等,是一個很不錯的多種分析方法聯(lián)合使用的案例。
-
SPSS
+關(guān)注
關(guān)注
1文章
10瀏覽量
10039
發(fā)布評論請先 登錄
labview可不可以與SPSS進(jìn)行連接通信呢
LabVIEW與SPSS有接口嗎?
SPSS統(tǒng)計(jì)分析軟件在氣、水層識別中的應(yīng)用
技術(shù)資料:IBM SPSS Modeler: 強(qiáng)大的預(yù)測性分析
基于Hadoop與聚類分析的網(wǎng)絡(luò)日志分析模型
R與SPSS、SAS相比較_Python 在數(shù)據(jù)分析工作中的地位與R語言、SAS、SPSS 比較如何?

spss聚類分析樹狀圖
聚類分析的簡單案例





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論