 算力基礎篇:從零開始了解算力
算力基礎篇:從零開始了解算力
什么是算力
算力即計算能力(Computing Power),狹義上指對數字問題的運算能力,而廣義上指對輸入信息處理后實現結果輸出的一種能力。雖然處理的內容不同,但處理過程的能力都可抽象為算力。比如人類大腦、手機以及各類服務器對接收到的信息處理實際都屬于算力的應用。
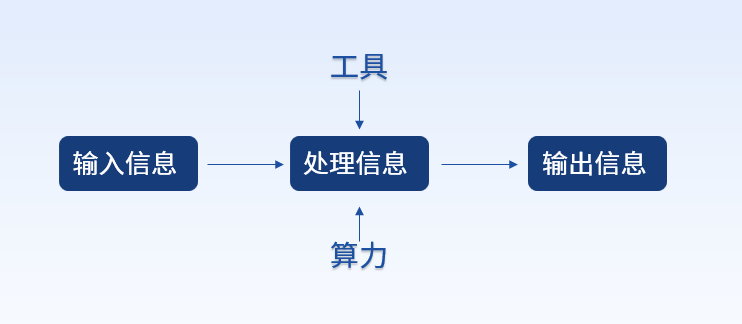
隨著信息技術的不斷發展,[《中國算力白皮書(2022)》]中將算力明確定義為數據中心的服務器通過對數據進行處理后實現結果輸出的一種能力。當前行業中討論的算力,狹義上可理解為CPU、GPU等芯片的計算能力,廣義上可理解為芯片技術的計算能力,內存、硬盤等存儲技術的存力,以及操作系統、數據庫等軟件技術的算法的三者集合。
算力的分類
隨著數字經濟時代的到來,算力發展迎來高潮,廣泛應用于各個領域,其中包括但不限于日常消費領域、人工智能領域、半導體技術領域。不同應用場景對算力的需求各異,需要不同類型的算力支撐。目前算力主要分為通用算力、智能算力和超算算力。未來還會出現比傳統計算更高效、更快速的新一代算力,例如量子算力等。
通用算力
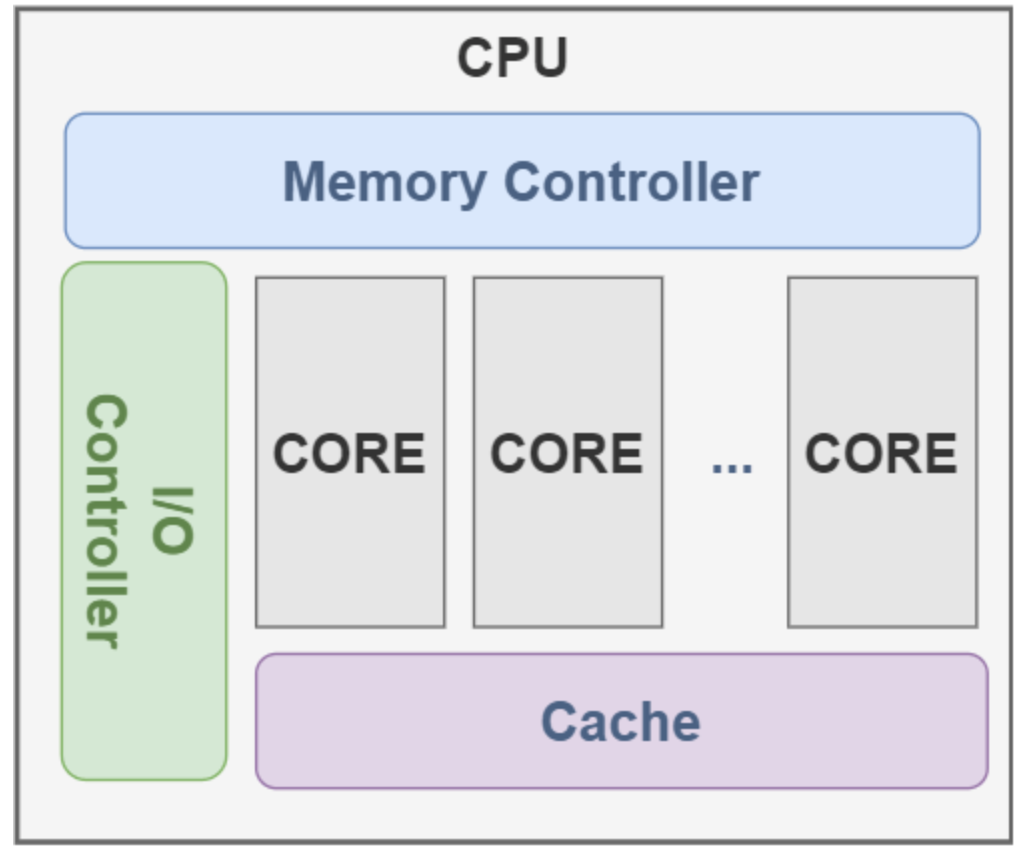
通用算力主要以CPU為代表,即CPU芯片執行計算任務時所表現出的計算能力。不同架構的CPU計算能力不同,因為CPU算力受核心數量、主頻、緩存大小等多種因素影響。目前可以根據DMIPS指標來衡量CPU性能。該指標表示CPU每秒能執行多少百萬條Dhrystone指令。
| 分類 | 特點 | 引領者 | 優劣勢 |
|---|---|---|---|
| x86 | 復雜指令集、單核能力強 | Intel、AMD、海光、兆芯 | 軟件生態好,占有率高;指令集實現復雜,功耗高 |
| ARM | 精簡指令集、追求多核、低功耗 | 安謀、高通、Amazon | 授權廠商多,能效比高;軟件生態劣于x86 |
| MIPS | 精簡指令集、低功耗 | 龍芯 | 軟件生態弱、市占率正在下降 |
| Power | 單核能力強、高可靠性、高成本 | IBM | IBM掌控技術,應用于金融領域 |
| RISC-V | 精簡指令集 | RISC-V基金會、阿里巴巴、兆易創新 | 完全開放開源、模塊化、可擴展 |
| Alpha | 精簡指令集、速度快 | 申威 | 軟件生態弱,市占率小 |
通用算力計算量小,但能夠提供高效、靈活、通用的計算能力。因為CPU的架構屬于少量的高性能核心結構,即核心數量少,但核心頻率高,更加擅長處理復雜的邏輯判斷和串行計算的單線程任務,如操作系統的管理、應用程序的執行以及各類后臺服務等。而這樣的設計在面對大規模并行計算任務時則顯得力不從心。
智能算力
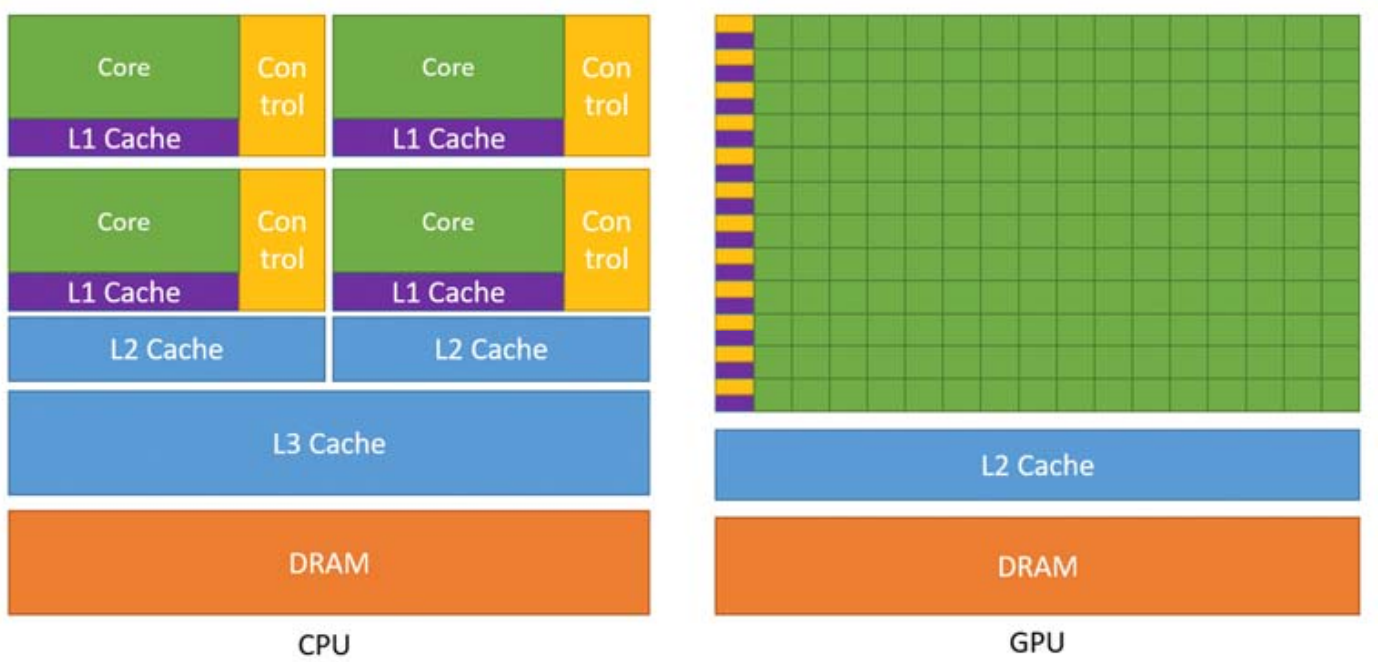
智能算力主要以GPU、FPGA、ASIC芯片為代表。每種類型的芯片具有各自的特點和優勢。
- GPU(Graphics Processing Unit,圖形處理器):GPU在設計之初用于圖形渲染,即同時處理大量簡單的計算任務。不同于CPU的少量高性能核心架構,GPU擁有大量的核心數但較小的控制單元和緩存,能夠完成高度并行的計算任務。GPU主要應用在機器學習的訓練階段,因為機器學習的操作并不依賴于復雜指令,而是大規模的并行計算。
- FPGA(Field Programmable Gate Array,現場可編程邏輯門陣列):FPGA是在PAL、GAL 等可編程器件的基礎上進一步發展的產物。FPGA是半定制集成電路,具有可重配置的邏輯結構。其內部的電路不是硬刻蝕的,而是可以通過HDL(硬件描述語言)編程來重新配置。這種可編程靈活性使其可以完成人工神經網絡的特定計算模式,輕松升級硬件以適應AI場景中新的應用需求。除此以外,FPGA的每個組件功能在重新配置階段都可以定制,因此在運行時無需指令,可顯著降低功耗并提高整體性能。
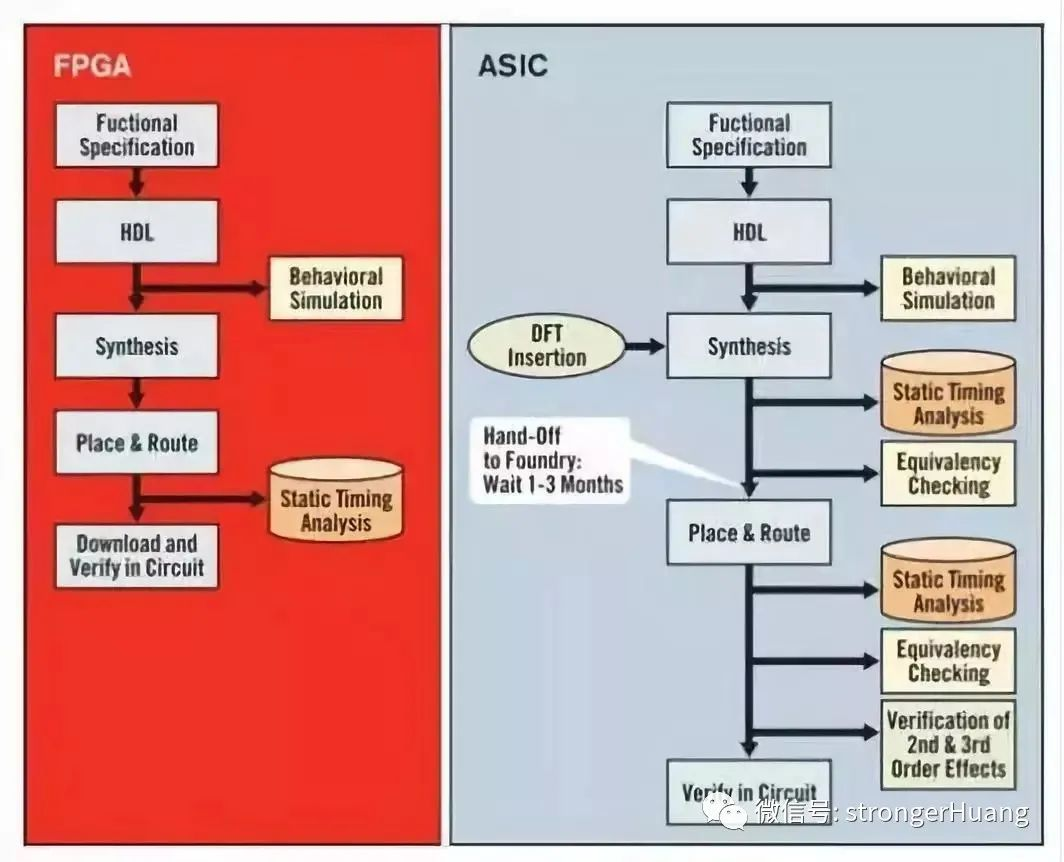
- ASIC(Application-Specific Integrated Circuit,應用特定集成電路):ASIC是專為滿足特定需求而設計的全定制集成電路芯片。ASIC的優勢在于其能夠針對特定任務進行深度優化,從而實現更高的性能和更低的功耗。一旦量產,其單位成本會顯著降低,尤其適合于大規模生產和應用。然而,ASIC設計周期長、成本高,一旦設計完成,很難進行修改或升級以適應新的應用需求。因此,在選擇使用ASIC還是FPGA時,需要根據具體的應用場景和需求進行權衡。對于需要高性能、低功耗且應用場景相對固定的系統,ASIC可能是更好的選擇;而對于需要快速適應新技術和市場需求變化的應用場景,FPGA則更具優勢。
GPU、FPGA、ASIC能力對比表格:
td {white-space:nowrap;border:1px solid #dee0e3;font-size:10pt;font-style:normal;font-weight:normal;vertical-align:middle;word-break:normal;word-wrap:normal;} | | GPU | FPGA | ASIC |
| -------------- | -------------------------- | -------------------------------- | ----------------------------- |
| 并行計算能力 | 強大 | 靈活配置 | 高效但定制 |
| 靈活性 | 較低(專用于圖形和計算) | 高(可編程) | 低(定制后固定) |
| 功耗 | 高 | 適中 | 低 |
| 成本 | 中等 | 低 | 高(設計和制造) |
| 整體性能 | 高 | 中等(因可重置而消耗芯片資源) | 非常高(高度定制針對性強 ) |
| 應用領域 | 圖形處理、機器學習等 | 實時計算、原型設計等 | 特定應用場景(如數據中心) |
超算算力
超算即超級計算,又稱高性能計算 (HPC),利用并行工作的多臺計算機系統的集中式計算資源,通過專用的操作系統來處理極端復雜的或數據密集型的問題。超算算力則是由這些超級計算機等高性能計算集群所提供的算力,主要應用于尖端科研、國防軍工等大科學、大工程、大系統中,是衡量一個國家或地區科技核心競爭力和綜合國力的重要標志。目前,美國的Frontier以 1.206 EFlop/s的HPL性能位居全球超級計算機Top500榜第一,達到了E級計算。
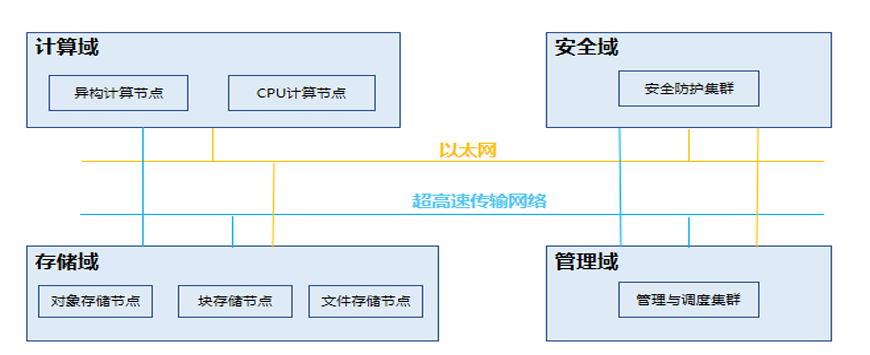
中國信息通信研究院結合業內實踐和設想,提出了超算參考架構,由計算系統、存儲系統、網絡系統、管理系統、安全系統五部分構成。
- 計算系統:由CPU和異構加速卡計算節點共同組成。
- 存儲系統:采用分布式存儲,可提供PB級別以上的容量來進行數據和算據存儲。
- 網絡系統:分為存儲網絡、業務網絡以及監控網絡等多個網絡平面,實現超算系統間各個硬件設備以及子系統間的通信互聯。
- 管理系統:包括資源與業務監控、告警監控、可視化等功能。
- 安全系統:由防火墻、負載均衡、堡壘機、抗DDoS、日志審計、漏洞掃描、DNS服務器等設備組成。
新一代算力
自人工智能加速應用后,算力需求激增,人們很難保證在未來經典計算能一直滿足指數級的算力增長并應用于重大計算問題。于是在全球科技競爭加劇、數字經濟快速發展以及新興技術的推動下出現了以量子計算為代表的新一代算力。
量子計算運用量子態的疊加性,使得量子比特擁有更強的信息編碼能力,并可實現多個量子比特的量子糾纏,性能上限遠超經典計算。量子計算機使用亞原子粒子的物理學領域來執行復雜的并行計算,從而取代了當今計算機系統中更簡單的晶體管。傳統計算機中的字符,要么打開,要么關閉,要么是 1,要么是 0。而在量子比特計算中,計算單元是可以打開,關閉或之間的任何值。量子比特的“疊加態”能力,為計算方程增加了強大的功能,使量子計算機在某種數學運算中更勝一籌。
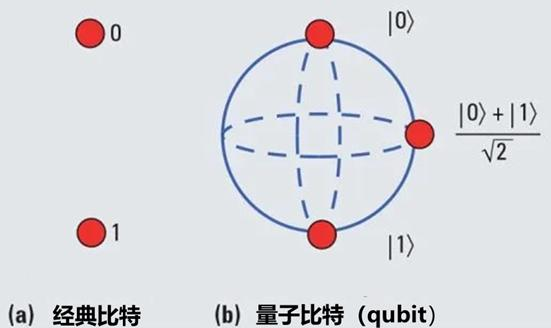
目前阿里巴巴、Google、Honeywell、IBM 、IonQ 和 Xanadu 等少數幾家公司都運營著量子計算機,但仍存在退相干、噪聲與誤差、可擴展性等問題,處于硬件開發的早期階段。根據專家預測,想要進入量子計算機真正有用的高保真時代,還得需要幾十年。
數據中心算力組成
數據中心的計算能力主要依賴于服務器。目前CPU類型的服務器幾乎部署在所有的數據中心中,而高性能算力GPU等更多的使用在AI應用場景中,小規模部署于部分數據中心中。然而隨著機器學習、人工智能、無人駕駛、工業仿真等新興技術領域的崛起,傳統數據中心遭遇通用CPU在處理海量計算、 海量數據時越來越多的性能瓶頸。 在數據中心加快步伐部署48核以及64核心等更高核心CPU來應對激增的算力需求的同時,為了應對計算多元化的需求,越來越多的場景開始引入加速芯片,如前文提到的GPU、 FPGA、 ASIC 等。這些加速硬件承擔了大部分的新算力需求。
然而實際上的數據中心是一個匯集大量服務器、存儲設備及網絡設備的基礎設施,數據中心算力是服務器、存儲及網絡設備合力作用的結果,計算、存儲及網絡傳輸能力相互協同才能促使數據中心算力水平的提升。單獨討論服務器的算力水平并不能反映數據中心的實際算力水平。
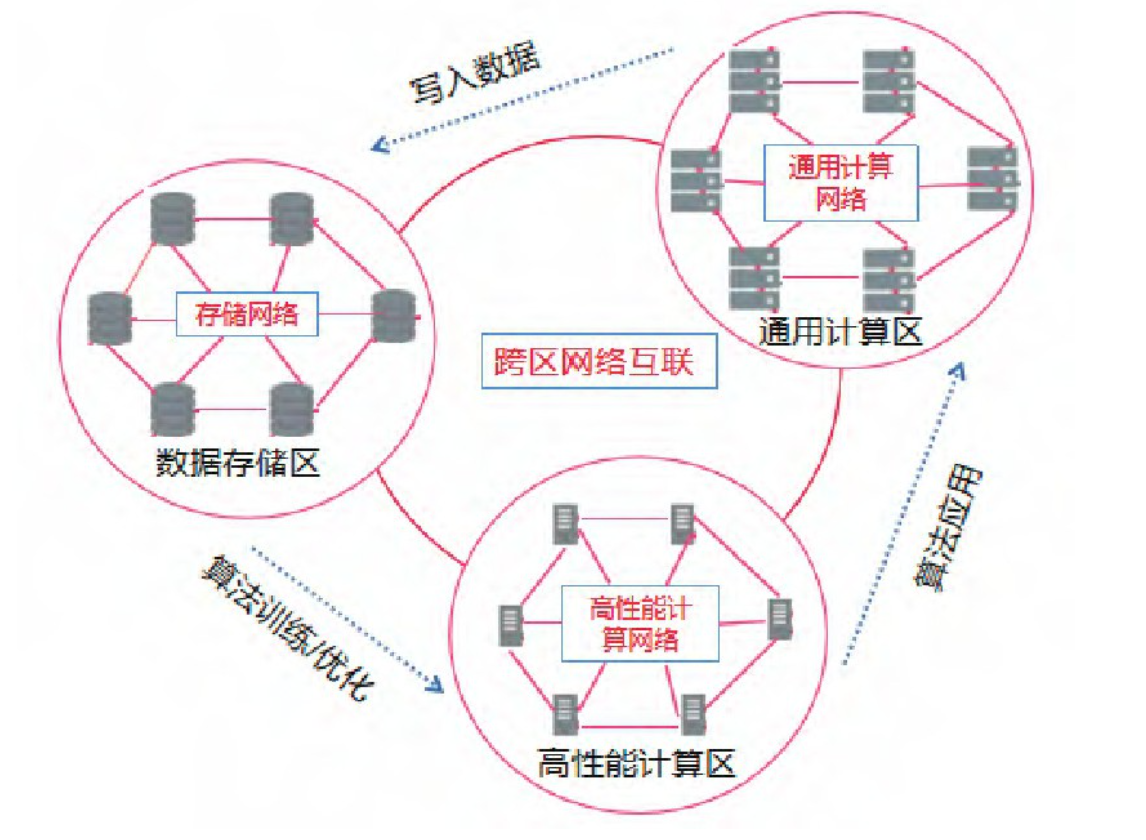
總之,數據中心是人工智能、物聯網、區塊鏈等應用服務的重要載體。數據中心算力水平的提升將會在很大程度上推動全社會總體算力供給,滿足各行業數字化轉型過程中的算力需求。
數據中心網絡設備
以實際情況來說,數據中心的算力水平不僅取決于服務器的算力,同時還會在很大程度上受到網絡設備的影響,如果網絡設備算力水平無法滿足要求,很有可能引發“木桶效應”,拉低整個數據中心的實際算力水平。
星融元[CX-N系列] 交換機可以幫助用戶構建超低時延、 靈活可靠、按需橫向擴展的數據中心網絡。
- 超低時延:所搭載的交換芯片具備業界領先的超低時延能力,最低時延達到400ns左右。
- 高可靠性:通過MC-LAG、EVPN Multihoming、ECMP構建無環路、高可靠、可獨立升級的數據中心網絡。
- RoCEv2能力:全系列標配RoCEv2能力,提供PFC、ECN等一系列面向生產環境的增強網絡特性。
- RESTful API:支持REST架構的第三方平臺和應用都能自動化地管理、調度星融元數據中心網絡。
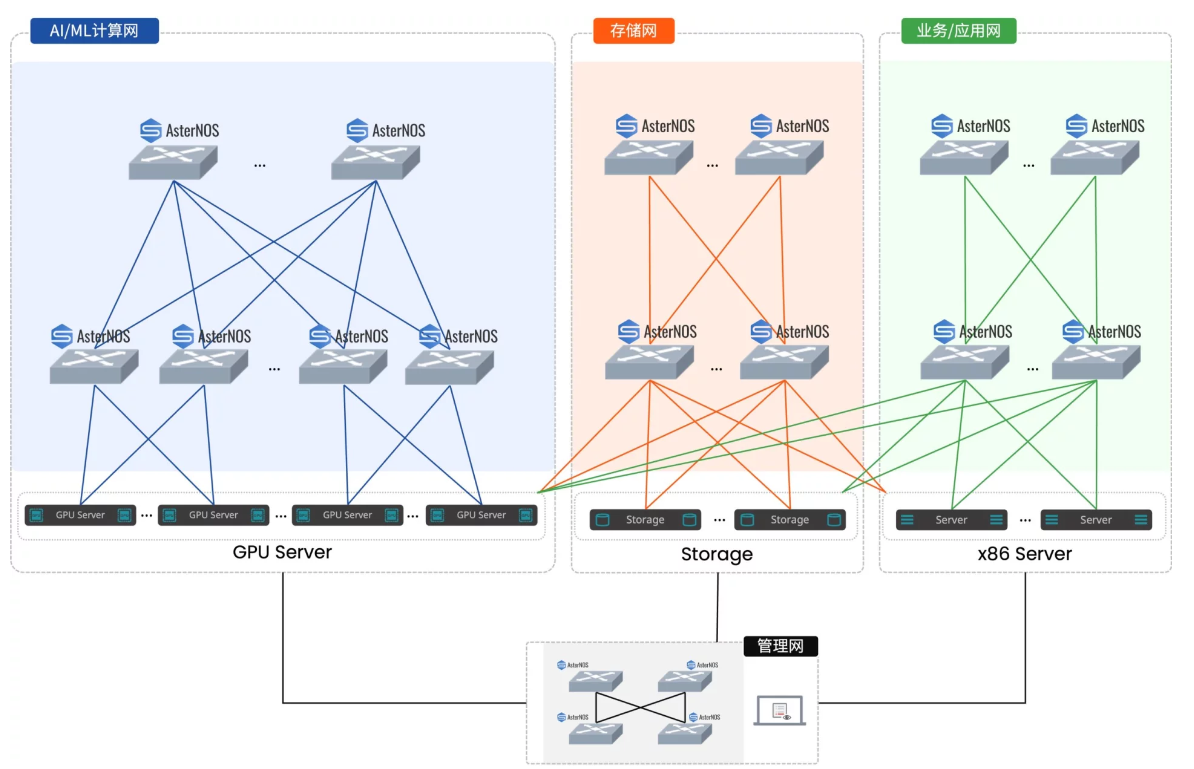
不論是在[AI智算] 還是[HPC高性能計算] 場景下,CX-N交換機都達到了媲美InfiniBand專用交換機的性能,以下是場景測試數據表:
表一:AIGC場景性能測試結果
| 帶寬 | 時延 | 備注 | |
|---|---|---|---|
| E2E網卡直連 | 392.95Gb/s | 1.95us | |
| E2E跨交換機 | 392.96Gb/s | 2.51us | 交換機時延560ns |
| NCCL網卡直連 | 371.27GB/s | / | |
| NCCL跨交換機 | 368.99GB/s | / | CX-N交換機端口利用率95%。 |
表二:HPC應用測試(對比IB交換機)
| HPC應用測試 | CX-N交換機 | MSB7000 | ||||||
|---|---|---|---|---|---|---|---|---|
| HPC應用 | Test1[sec] | Test2[sec] | Test1[sec] | avg[sec] | Test1[sec] | Test2[sec] | Test3[sec] | avg[sec] |
| WRF | 1140.35 | 1134.64 | 1128.35 | 1134.44 | 1106.72 | 1099.36 | 1112.68 | 1106.25 |
| LAMMPS | 341.25 | 347.19 | 342.61 | 343.69 | 330.47 | 335.58 | 332.46 | 332.83 |
參考文獻:
https://13115299.s21i.faiusr.com/61/1/ABUIABA9GAAgqvv2nAYowLyGBA.pdf
https://13115299.s21i.faiusr.com/61/1/ABUIABA9GAAgk4DrjQYo76ziRQ.pdf
審核編輯 黃宇
-
交換機
+關注
關注
21文章
2720瀏覽量
101326 -
數據中心
+關注
關注
16文章
5130瀏覽量
73177 -
AI算力
+關注
關注
0文章
87瀏覽量
9133 -
算力
+關注
關注
2文章
1141瀏覽量
15434
發布評論請先 登錄
搭建算力中心,從了解的GPU 特性開始

大算力芯片的生態突圍與算力革命
【一文看懂】什么是端側算力?


算智算中心的算力如何衡量?
杰和課堂|帶你認識算力

中金數據烏蘭察布零碳算力基地首批算力機房驗收交付







 工商網監
工商網監
評論