") 解析圖像分類器結(jié)構(gòu)搜索的正則化異步進(jìn)化方法 并和強(qiáng)化學(xué)習(xí)方法進(jìn)行對(duì)比
解析圖像分類器結(jié)構(gòu)搜索的正則化異步進(jìn)化方法 并和強(qiáng)化學(xué)習(xí)方法進(jìn)行對(duì)比
最近神經(jīng)網(wǎng)絡(luò)的成功不斷擴(kuò)展著模型的架構(gòu),并促成了架構(gòu)搜索的出現(xiàn),即神經(jīng)網(wǎng)絡(luò)自動(dòng)學(xué)習(xí)架構(gòu)。架構(gòu)搜索的傳統(tǒng)方法是神經(jīng)演化,如今,硬件的發(fā)展能實(shí)現(xiàn)大規(guī)模的演變,生成可以與手工設(shè)計(jì)相媲美的圖像分類模型。但是,新的技術(shù)雖然可行,卻無法讓開發(fā)者決定在具體的環(huán)境下(即搜索空間和數(shù)據(jù)集)使用哪種方法。
在本篇論文中,研究人員使用流行的異步進(jìn)化算法(asynchronous evolutionary algorithm)的正則化版本,并將其與非正則化的形式以及強(qiáng)化學(xué)習(xí)方法進(jìn)行比較。硬件條件、計(jì)算能力和神經(jīng)網(wǎng)絡(luò)訓(xùn)練代碼都相同,在這之中研究人員探索在不同的數(shù)據(jù)集、搜索空間和規(guī)模下模型的表現(xiàn)情況。以下是論智對(duì)論文的編譯總結(jié)。
實(shí)驗(yàn)方法
我們使用不同的算法搜索神經(jīng)網(wǎng)絡(luò)分類器的空間,進(jìn)行基線研究后,所得到的最好的模型將被擴(kuò)大尺寸,以生產(chǎn)更高質(zhì)量的圖像分類器。我們?cè)诓煌挠?jì)算規(guī)模上執(zhí)行搜索過程。另外,我們還研究了非神經(jīng)網(wǎng)絡(luò)模擬中的進(jìn)化算法。
1.搜索空間
所有神經(jīng)進(jìn)化和強(qiáng)化學(xué)習(xí)實(shí)驗(yàn)都使用基線研究的搜索空間設(shè)計(jì),它需要尋找兩個(gè)類似于Inception的模塊體系結(jié)構(gòu),這兩個(gè)結(jié)構(gòu)在前饋模式中堆疊以形成圖像分類器。
2.架構(gòu)搜索算法
對(duì)于進(jìn)化算法,我們使用聯(lián)賽選擇算法(tournament selection)或正則化的變體。標(biāo)準(zhǔn)的聯(lián)賽選擇算法是對(duì)訓(xùn)練模型P的數(shù)量進(jìn)行周期化的改進(jìn)。在每個(gè)循環(huán)中,隨機(jī)選擇一個(gè)S模型的樣本。樣本的最佳模型將生成具有變化架構(gòu)的另一模型,它將被訓(xùn)練然后添加到模型樣本中。最差的模型將被刪除。我們將這種方法稱為非正則進(jìn)化(NRE)。它的變體,正則化進(jìn)化(RE)則是一種自然的修正:無需刪除樣本中最差的模型,而是刪除樣本中最老的模型(即第一個(gè)被訓(xùn)練的模型)。在NRE和RE中,樣本初始化的架構(gòu)都是隨機(jī)的。
3.實(shí)驗(yàn)設(shè)置
為了對(duì)比進(jìn)化算法和強(qiáng)化學(xué)習(xí)算法,我們將在不同的計(jì)算規(guī)模上進(jìn)行實(shí)驗(yàn)。
小規(guī)模試驗(yàn)
首先進(jìn)行的實(shí)驗(yàn)可以在CPU上進(jìn)行,我們部署了SP-I、SP-II和SP-III三種搜索空間,利用G-CIFAR、MNIST或者G-ImageNet數(shù)據(jù)集進(jìn)行實(shí)驗(yàn)。
大規(guī)模實(shí)驗(yàn)
然后再部署基線研究的設(shè)置。這里僅用SP-I搜索空間和CIFAR-10數(shù)據(jù)集,兩種模型各在450個(gè)GPU上訓(xùn)練將近7天。
4.模型擴(kuò)展
我們要將進(jìn)化算法或強(qiáng)化學(xué)習(xí)發(fā)現(xiàn)的架構(gòu)轉(zhuǎn)化為全尺寸、精確的模型。擴(kuò)展后的模型將在CIFAR-10或ImageNet上進(jìn)行訓(xùn)練,程序與基線研究的相同。
實(shí)驗(yàn)結(jié)果
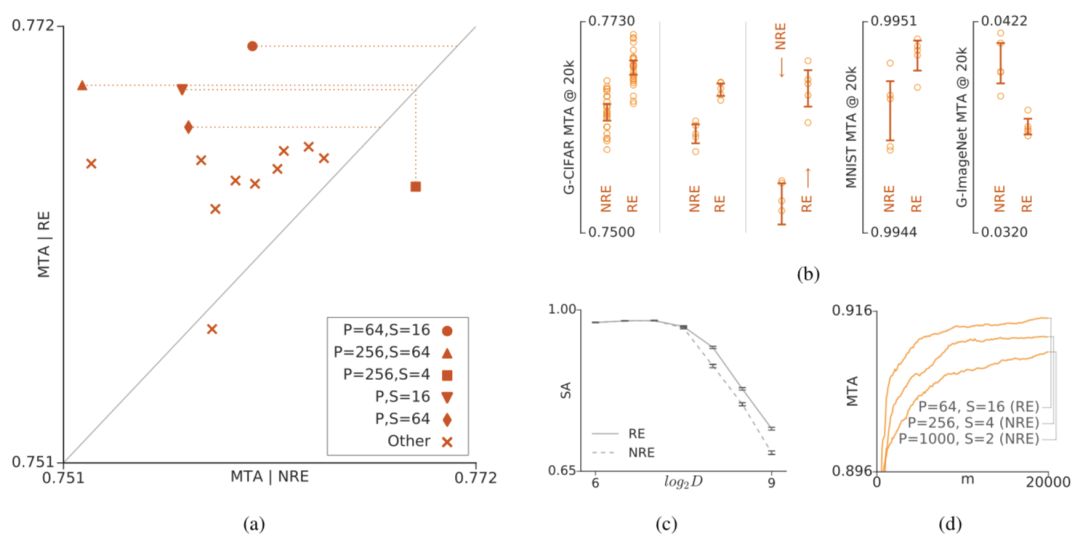
正則化與非正則化進(jìn)化的對(duì)比。(a)表示在G-CIFAR數(shù)據(jù)集上非正則化進(jìn)化和正則化進(jìn)化用不同的元參數(shù)進(jìn)行的小規(guī)模實(shí)驗(yàn)結(jié)果對(duì)比。P代表樣本數(shù)量,S代表樣本大小。(b)表示NRE和RE在五種不同情況下的表現(xiàn),從左至右分別為:G-CIFAR/SP-I、G-CIFAR/SP-II、G-CIFAR/SP-III、MNIST/SP-I和G-ImageNet/SP-I。(c)表示模擬結(jié)果,豎軸表示模擬的精確度,橫軸表示問題的維度。(d)表示在CIFAR-10上進(jìn)行的三次大規(guī)模試驗(yàn)。
接著,我們?cè)诓煌那闆r下對(duì)強(qiáng)化學(xué)習(xí)和進(jìn)化算法進(jìn)行了小規(guī)模實(shí)驗(yàn),結(jié)果如下:
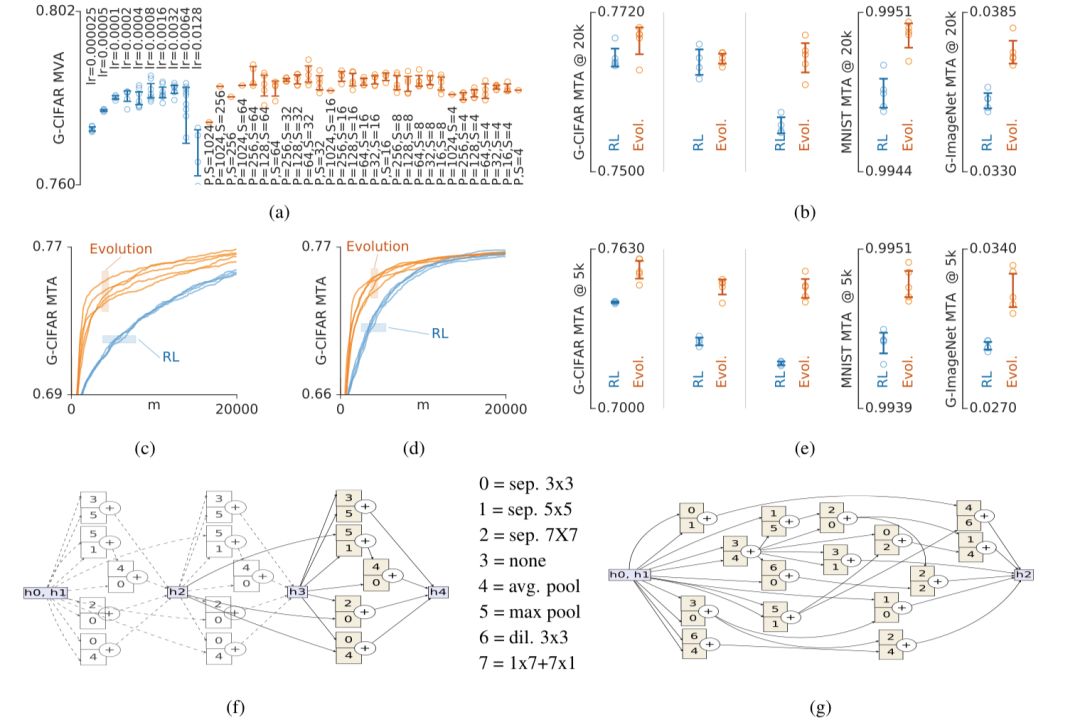
(a)顯示了在G-CIFAR上對(duì)超參數(shù)進(jìn)行優(yōu)化的實(shí)驗(yàn)總結(jié),豎軸表示實(shí)驗(yàn)中前100名的模型的平均有效精度。結(jié)果表明所所有方法都不夠敏感。(b)同樣是在模型五種不同情況下的表現(xiàn):G-CIFAR/SP-I、G-CIFAR/SP-II、G-CIFAR/SP-III、MNIST/SP-I和G-ImageNet/SP-I。(c)和(d)表示模型分別在G-CIFAR/SP-II和G-CIFAR/SP-III上的表現(xiàn)細(xì)節(jié),橫軸表示模型的數(shù)量。(e)表示在資源有限的情況下,可能需要盡早停止實(shí)驗(yàn)。說明了在初始狀態(tài)下,進(jìn)化算法的精確度比強(qiáng)化學(xué)習(xí)增長得快得多。(f)和(g)分別是SP-I和SP-III最頂尖的架構(gòu)。
比較完小規(guī)模實(shí)驗(yàn),接著進(jìn)行的是大規(guī)模實(shí)驗(yàn)。結(jié)果如下圖所示,黃色代表進(jìn)化算法,藍(lán)色代表強(qiáng)化學(xué)習(xí):
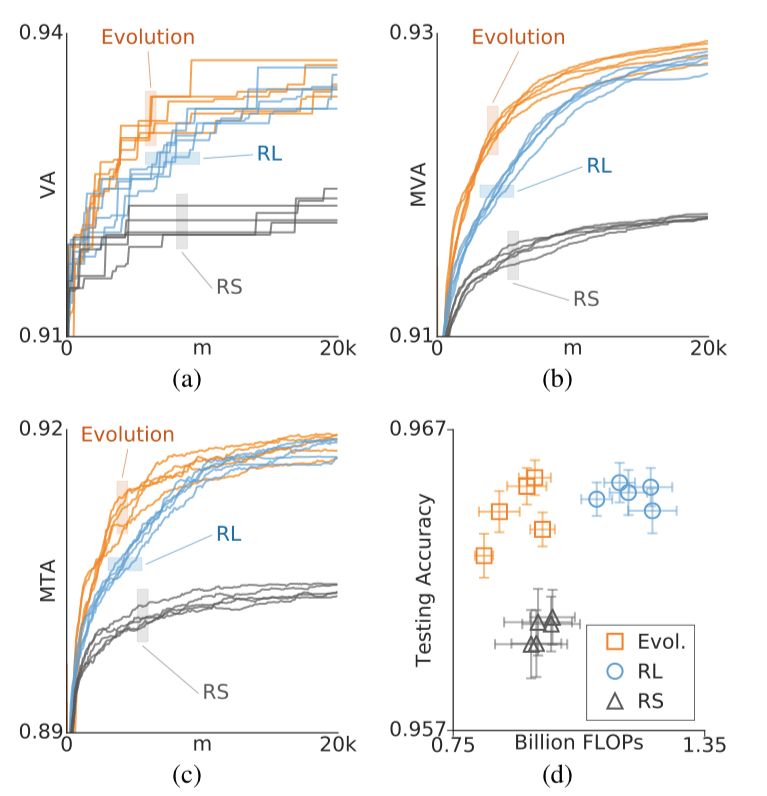
除了(d)圖,所有橫軸均表示模型的數(shù)量(m)。(a)、(b)、(c)三圖分別展示了三種算法在五次相同實(shí)驗(yàn)的情況,進(jìn)化算法和強(qiáng)化學(xué)習(xí)實(shí)驗(yàn)使用了最佳元參數(shù)。
經(jīng)過進(jìn)化實(shí)驗(yàn),我們確定了最佳模型并將其命名為AmoebaNet-A。通過調(diào)整N和F,我們可以降低測試錯(cuò)誤率,如表1所示:
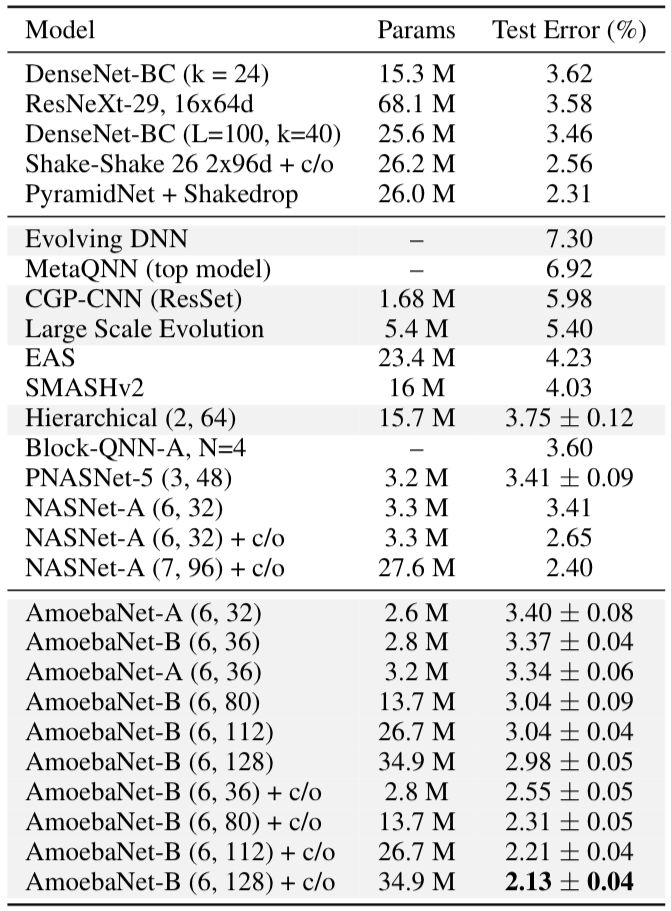
表1
在相同的實(shí)驗(yàn)條件下,基線研究得到了NASNet-A。表2顯示,在CIFAR-10數(shù)據(jù)集中,AmoebaNet-A在匹配參數(shù)時(shí)錯(cuò)誤率較低,在匹配錯(cuò)誤時(shí),參數(shù)較少。同時(shí)在ImageNet上的表現(xiàn)也是目前最好的。
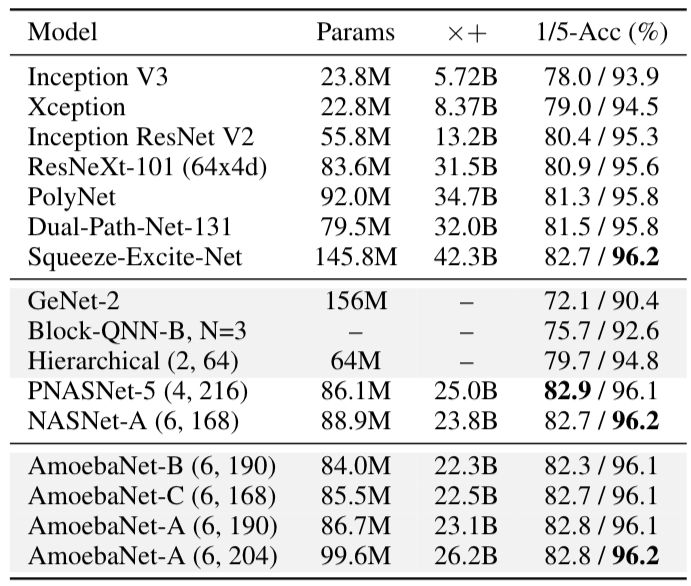
表2
最后我們對(duì)比了手動(dòng)設(shè)計(jì)、其他架構(gòu)以及我們模型的性能對(duì)比,準(zhǔn)確率均高于其他兩種。
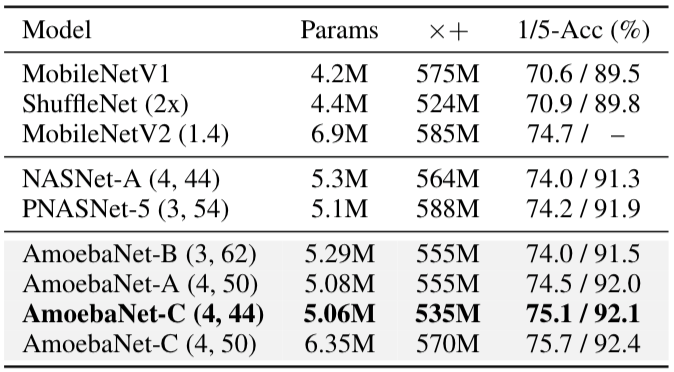
表3
結(jié)語
大規(guī)模的實(shí)驗(yàn)過程圖表明,強(qiáng)化學(xué)習(xí)和進(jìn)化算法都接近一般精度漸近線,所以我們需要關(guān)注的是哪個(gè)算法更快到達(dá)。圖中顯示強(qiáng)化學(xué)習(xí)要用兩倍的時(shí)間到達(dá)最高精度的一半,換句話說,進(jìn)化算法的速度大約比強(qiáng)化學(xué)習(xí)快一倍。但是我們忽略了進(jìn)一步量化這一效果。另外,搜索空間的大小還需進(jìn)一步評(píng)估。大空間所需專業(yè)資源較少,而小空間能更快更好地獲得結(jié)果。因此,在較小空間中很難區(qū)分哪種搜索算法更好。
不過,這一研究僅僅是在特定環(huán)境下分析進(jìn)化算法和強(qiáng)化學(xué)習(xí)之間關(guān)系的第一個(gè)實(shí)證研究,我們希望今后的工作能進(jìn)一步總結(jié)二者,闡釋兩種方法的優(yōu)點(diǎn)。
-
進(jìn)化算法
+關(guān)注
關(guān)注
0文章
10瀏覽量
7457 -
強(qiáng)化學(xué)習(xí)
+關(guān)注
關(guān)注
4文章
269瀏覽量
11514
原文標(biāo)題:圖像分類器結(jié)構(gòu)搜索的正則化異步進(jìn)化方法
文章出處:【微信號(hào):jqr_AI,微信公眾號(hào):論智】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
漸進(jìn)式神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)搜索技術(shù)
深度強(qiáng)化學(xué)習(xí)實(shí)戰(zhàn)
一種基于機(jī)器學(xué)習(xí)的建筑物分割掩模自動(dòng)正則化和多邊形化方法
深度學(xué)習(xí)技術(shù)的開發(fā)與應(yīng)用
圖像分類的方法之深度學(xué)習(xí)與傳統(tǒng)機(jī)器學(xué)習(xí)
基于數(shù)據(jù)挖掘的醫(yī)學(xué)圖像分類方法
斯坦福提出基于目標(biāo)的策略強(qiáng)化學(xué)習(xí)方法——SOORL

使用加權(quán)密集連接卷積網(wǎng)絡(luò)的深度強(qiáng)化學(xué)習(xí)方法說明
谷歌和DeepMind研究人員合作提出新的強(qiáng)化學(xué)習(xí)方法Dreamer 可利用世界模型實(shí)現(xiàn)高效的行為學(xué)習(xí)
深度學(xué)習(xí)中圖像分割的方法和應(yīng)用
以進(jìn)化算法為搜索策略實(shí)現(xiàn)神經(jīng)架構(gòu)搜索的方法
模型化深度強(qiáng)化學(xué)習(xí)應(yīng)用研究綜述

基于深度強(qiáng)化學(xué)習(xí)的無人機(jī)控制律設(shè)計(jì)方法
使用深度學(xué)習(xí)方法對(duì)音樂流派進(jìn)行分類






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論