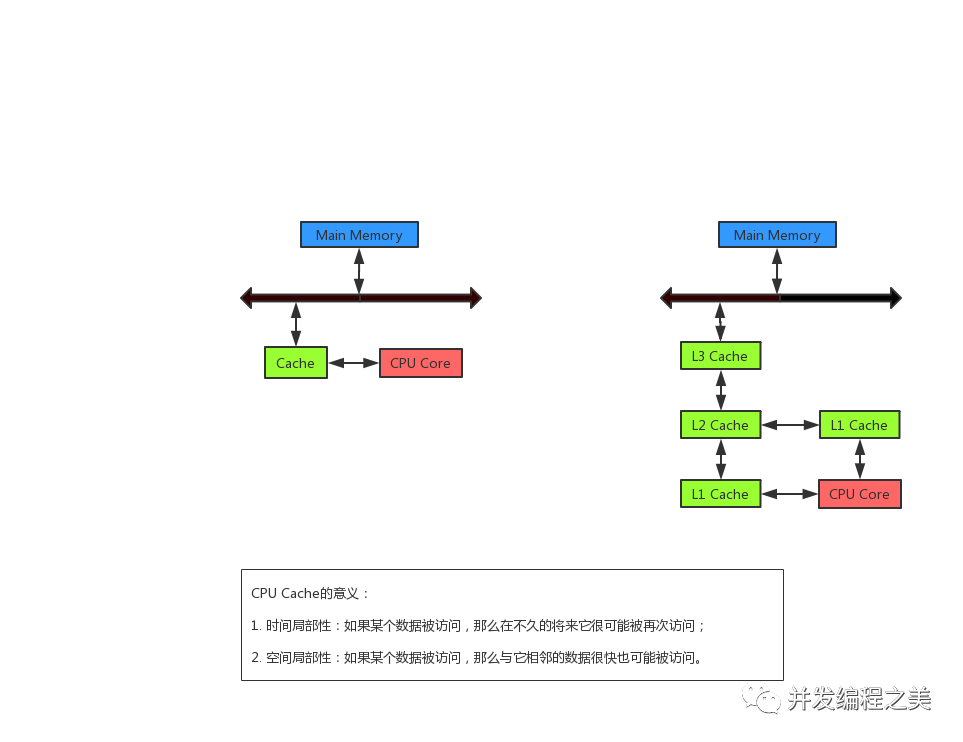
") 異構(gòu)計算下緩存一致性的重要性
異構(gòu)計算下緩存一致性的重要性
作者:張景濤
問題起源
這個問題來源于華為海思鯤鵬處理器首席架構(gòu)師兼昇騰AI處理器架構(gòu)師夏晶在知乎上發(fā)出的靈魂之問。
問題初答
在眾多回復(fù)中,李博杰同學(xué)的回答被認(rèn)為質(zhì)量最高。他首先將緩存一致性分為兩個主要場景:一是主機(jī)內(nèi)CPU與設(shè)備間的一致性;二是跨主機(jī)的一致性。
對于第一個場景(主機(jī)內(nèi)CPU與設(shè)備間),李博杰同學(xué)明確指出緩存一致性的重要性,并以在微軟研究院實習(xí)期間的一個項目為例,說明了使用FPGA將內(nèi)存連接到PCIe的bar空間上,導(dǎo)致Linux系統(tǒng)啟動時間從3秒延長到30分鐘,速度降低了600倍。這一現(xiàn)象揭示了PCIe不支持緩存一致性,CPU直接訪問設(shè)備內(nèi)存時只能是非緩存型(uncacheable)的。[注:在分析耗時時,除了緩存一致性外,還應(yīng)考慮PCIe與內(nèi)存帶寬的差異]
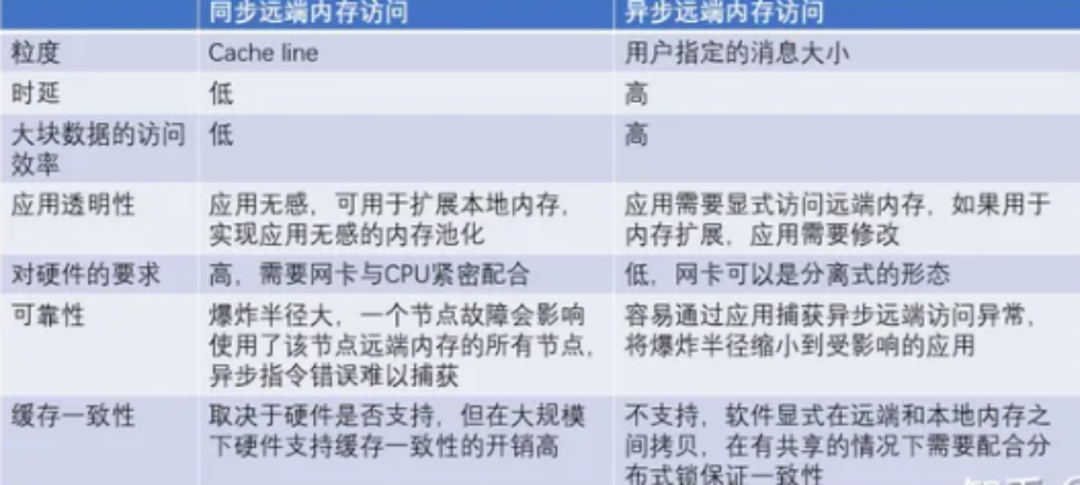
在第一種場景中,他還對比了同步和異步遠(yuǎn)程訪問的差異,但原文并未明確指出主機(jī)內(nèi)CPU和設(shè)備間一致性的具體優(yōu)勢。
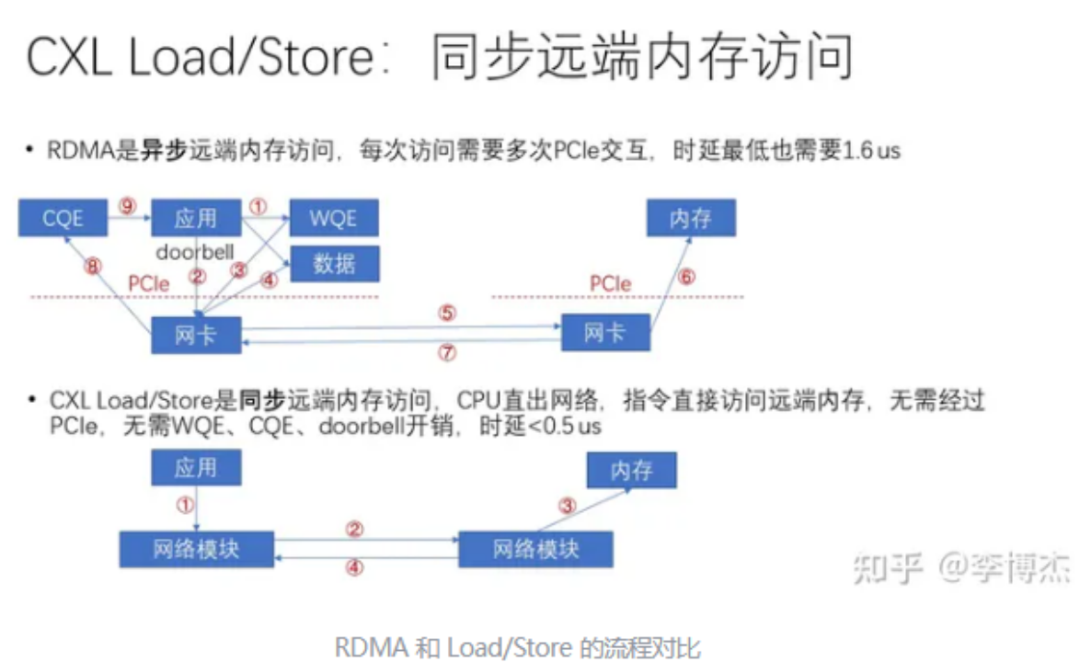
對于第二個場景(跨主機(jī)),跨主機(jī)的緩存一致性(CC)存在較大爭議。一方面,大規(guī)模分布式一致性的實現(xiàn)難度大,是學(xué)術(shù)界長期未解的問題。另一方面,許多人對應(yīng)用場景的理解并不清晰。
例如,在內(nèi)存池化方面,許多人認(rèn)為可以利用其他機(jī)器的空閑內(nèi)存來提高集群的內(nèi)存利用率,這種情況下不需要跨主機(jī)的CC,僅需Load/Store操作和主機(jī)內(nèi)的CC。因為借用的內(nèi)存僅由一臺機(jī)器使用,出借方和其他機(jī)器均無需訪問。
理想情況下,內(nèi)存池化可以由多臺機(jī)器共享內(nèi)存,并支持跨主機(jī)的CC。這將帶來諸多好處,如簡化編程、減少數(shù)據(jù)拷貝、提高內(nèi)存利用率。然而,現(xiàn)實中如何存儲龐大的共享者列表(sharer list)?如何降低緩存失效(Cache invalidation)的高開銷?盡管原文中提出了一些可行方案,例如擴(kuò)大緩存粒度、將共享列表數(shù)據(jù)結(jié)構(gòu)改為鏈表或分布式存儲、控制共享者數(shù)量,甚至使用租約概念替代共享者列表,但最有效的方法還是與業(yè)務(wù)結(jié)合,因為業(yè)務(wù)最清楚同步時機(jī)和共享數(shù)據(jù)的使用情況。
最后,李博杰同學(xué)指出,跨主機(jī)的CC主要應(yīng)用于Web服務(wù)、大數(shù)據(jù)、存儲等領(lǐng)域。目前,他尚未想到在AI和高性能計算(HPC)領(lǐng)域中的應(yīng)用,因為AI和HPC通常采用集合通信(collective operations),embedding也有邏輯上中心化的參數(shù)服務(wù)器(parameter server)來存儲,對多機(jī)共享內(nèi)存數(shù)據(jù)的需求似乎不大。
深入思考
針對夏晶老師的問題,筆者在實際工作中也有類似的疑問。在異構(gòu)計算場景下(尤其是主機(jī)內(nèi)CPU與設(shè)備之間),緩存一致性究竟能帶來多大的價值?盡管使用CXL等聲稱支持緩存一致性的總線可以將數(shù)據(jù)訪問延遲從PCIe的約500納秒降低到50納秒,實現(xiàn)了數(shù)量級的優(yōu)化,但在仔細(xì)分析延遲后可以得出明確結(jié)論:直接的延遲優(yōu)化主要是由于協(xié)議各層的優(yōu)化帶來的,而緩存一致性對延遲的優(yōu)化效果缺乏量化數(shù)據(jù)支持。直到看到論文《CC-NIC: a Cache-Coherent Interface to the NIC》,許多疑問才得以解答。
在這篇論文中,作者利用X86 CPU UPI接口提供的緩存一致性實現(xiàn)了一個NIC設(shè)備,從而驗證了緩存一致性對網(wǎng)卡的具體影響。
傳統(tǒng)的PCIE接口設(shè)備
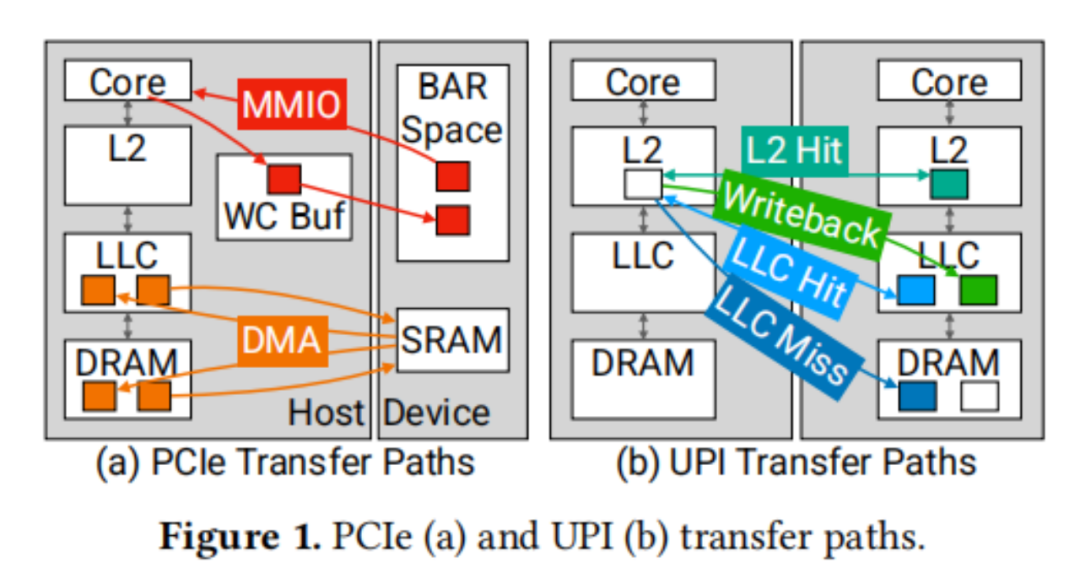
PCIe接口為設(shè)備與主機(jī)之間提供了一種非對稱的通信方式。圖1a展示了兩種傳輸機(jī)制:MMIO和DMA,分別由主機(jī)和設(shè)備發(fā)起。主機(jī)對NIC的讀寫操作通過內(nèi)存映射輸入/輸出(MMIO)實現(xiàn)。設(shè)備將內(nèi)存區(qū)域映射到主機(jī)的地址空間,這些區(qū)域被設(shè)置為不可緩存(UC)或?qū)懡M合(WC)內(nèi)存類型。這樣,主機(jī)可以對設(shè)備執(zhí)行加載和存儲操作,這些操作通過PCIe讀寫事務(wù)來執(zhí)行。然而,UC和WC內(nèi)存類型并不保證緩存一致性或在緩存層次結(jié)構(gòu)中的操作。因此,CPU必須通過PCIe往返行程來加載數(shù)據(jù),導(dǎo)致較高的訪問延遲。在ICX CPU平臺上,針對Intel E810 NIC的測試顯示,中位數(shù)的MMIO讀延遲分別為982納秒(對于8字節(jié)數(shù)據(jù))和1026納秒(對于64字節(jié)AVX512數(shù)據(jù))。而PCIe設(shè)備則通過直接內(nèi)存訪問(DMA)來讀取和寫入主機(jī)內(nèi)存。DMA操作的緩沖區(qū)大小通常比64B的MMIO寫組合緩沖區(qū)要大得多(例如,4KB),并且通常訪問標(biāo)準(zhǔn)寫回主機(jī)內(nèi)存。盡管傳統(tǒng)PCIe NIC不公開DMA延遲的統(tǒng)計數(shù)據(jù),但預(yù)計其往返延遲與MMIO相當(dāng),大約在1微秒左右。
PCIe的特性和性能對主機(jī)-NIC接口的性能提出了挑戰(zhàn)。具體來說,存在以下三個問題:首先,由于PCIe不是一致性互連,因此必須通過顯式的PCIe事務(wù)來通信或更新本地數(shù)據(jù)結(jié)構(gòu)。其次,PCIe操作的高延遲意味著減少互連遍歷的次數(shù)對于實現(xiàn)低延遲的數(shù)據(jù)包傳輸至關(guān)重要。最后,通過PCIe進(jìn)行的數(shù)據(jù)和元數(shù)據(jù)寫入對CPU來說在吞吐量和高延遲停頓方面代價高昂。這些問題共同定義了PCIe接口的性能權(quán)衡。理想的設(shè)計目標(biāo)是實現(xiàn)高數(shù)據(jù)包吞吐量、低延遲和高CPU效率,但PCIe的限制使得我們無法同時達(dá)到這三個目標(biāo)。
當(dāng)前的PCIe NIC設(shè)計通常優(yōu)先考慮CPU效率和吞吐量,而犧牲一定的延遲。數(shù)據(jù)結(jié)構(gòu)通常位于主機(jī)本地,并通過顯式的PCIe事務(wù)來通知更新。主機(jī)在本地內(nèi)存中維護(hù)數(shù)據(jù)包緩沖區(qū)和描述符環(huán),以減少對數(shù)據(jù)結(jié)構(gòu)訪問和更新的CPU開銷。在傳輸過程中,主機(jī)將TX數(shù)據(jù)包和TX描述符寫入本地內(nèi)存,并通過MMIO寫入設(shè)備端維護(hù)的隊列尾部寄存器。這種設(shè)計帶來了一種權(quán)衡:在MMIO上最小化數(shù)據(jù)傳輸,但代價是增加了對主機(jī)內(nèi)存中描述符和數(shù)據(jù)包的額外互連往返讀取。
支持緩存一致性接口
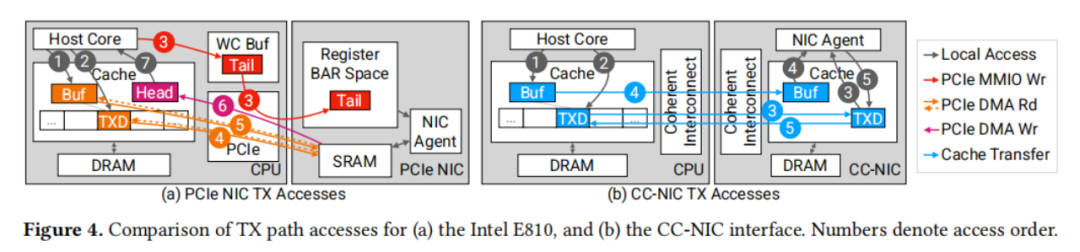
一致性互連技術(shù),如UPI(Universal Platform Interface)和CXL(Compute Express Link),與CPU的內(nèi)存數(shù)據(jù)路徑緊密集成,提供了與PCIe根本不同的接口特性。如圖1b所示,跨互連的訪問可以針對DRAM和緩存進(jìn)行。一致性協(xié)議管理著共享緩存的狀態(tài),確保在訪問內(nèi)存時,數(shù)據(jù)能夠傳輸?shù)奖镜鼐彺妗_@些協(xié)議要求寫入者在寫入之前獲得緩存行的獨占控制權(quán),并使任何遠(yuǎn)程緩存中的副本失效。同時,它們也允許多個緩存共享對同一行的讀取訪問,并能夠在緩存之間轉(zhuǎn)發(fā)數(shù)據(jù)。總的來說,一致性互連提供了一種新的信號和數(shù)據(jù)結(jié)構(gòu)共享形式,不受PCIe讀寫接口的限制。
與PCIe的非對稱接口不同,一致性互連提供了一個對稱的接口,消除了MMIO和DMA操作之間的權(quán)衡。然而,跨互連的傳輸性能受到緩存的存在和一致性狀態(tài)的影響,這在延遲、內(nèi)存控制器請求、協(xié)議元數(shù)據(jù)的開銷以及往返時間方面都有所體現(xiàn)。在一致性互連的上下文中,對緩存行狀態(tài)和緩存行為的控制手段有限,這為實現(xiàn)NIC數(shù)據(jù)結(jié)構(gòu)帶來了機(jī)遇和挑戰(zhàn)。
文章指出了實現(xiàn)一致性互連NIC(CC-NIC)時需要考慮的三個設(shè)計因素:
1、一致性接口信令和共享數(shù)據(jù)結(jié)構(gòu):PCIe NIC通常使用MMIO機(jī)制來處理數(shù)據(jù)和元數(shù)據(jù)的DMA傳輸以及TX通知。這導(dǎo)致了在接收信號后,通過DMA檢索TX元數(shù)據(jù)時需要多進(jìn)行一輪互連往返。而緩存一致性通過硬件執(zhí)行通知:當(dāng)遠(yuǎn)程端執(zhí)行寫入操作時,一致性協(xié)議會自動使任何本地緩存的副本失效,并在隨后的訪問中獲取新值。此外,一致性互連還允許在主機(jī)和NIC之間使用共享數(shù)據(jù)結(jié)構(gòu),從而實現(xiàn)共享緩沖池的管理。
2、數(shù)據(jù)傳輸機(jī)制和定位選擇:一致性互連提供了多種數(shù)據(jù)傳輸機(jī)制。CC-NIC可以選擇將寫回內(nèi)存作為目標(biāo),除了緩存繞過數(shù)據(jù)路徑,還可以將數(shù)據(jù)結(jié)構(gòu)定位在主機(jī)或NIC上,為CC-NIC提供了多種傳輸選項。跨互連的數(shù)據(jù)傳輸和緩存狀態(tài)轉(zhuǎn)換還取決于對象的當(dāng)前緩存駐留情況、可能的預(yù)取以及由先前訪問引起的緩存狀態(tài)。因此,小型對象(如信號和描述符元數(shù)據(jù))對布局非常敏感。
3、緩存管理:一致性協(xié)議在互連上交換緩存行的所有權(quán)。因此,遠(yuǎn)程訪問可能導(dǎo)致在后續(xù)的本地訪問時需要進(jìn)行額外的通信。這對于生產(chǎn)者-消費者工作負(fù)載尤其成問題。例如,在典型的TX路徑中,元數(shù)據(jù)和數(shù)據(jù)從主機(jī)傳輸?shù)絅IC,隨后NIC執(zhí)行數(shù)據(jù)傳輸,而數(shù)據(jù)不再被NIC需要。在一致性互連的上下文中,保留數(shù)據(jù)包緩沖區(qū)或描述符在NIC端的緩存中是沒有幫助的;它為隨后的主機(jī)訪問增加了開銷,因為這些訪問將不得不執(zhí)行遠(yuǎn)程緩存使失效操作。這表明,為了最小化開銷,需要選擇性地使緩存數(shù)據(jù)失效,這在典型的x86平臺上是不受支持的,或者需要重新設(shè)計數(shù)據(jù)結(jié)構(gòu)以避免這種訪問模式。
CC-NIC設(shè)計
利用緩存一致性減少軟件開銷
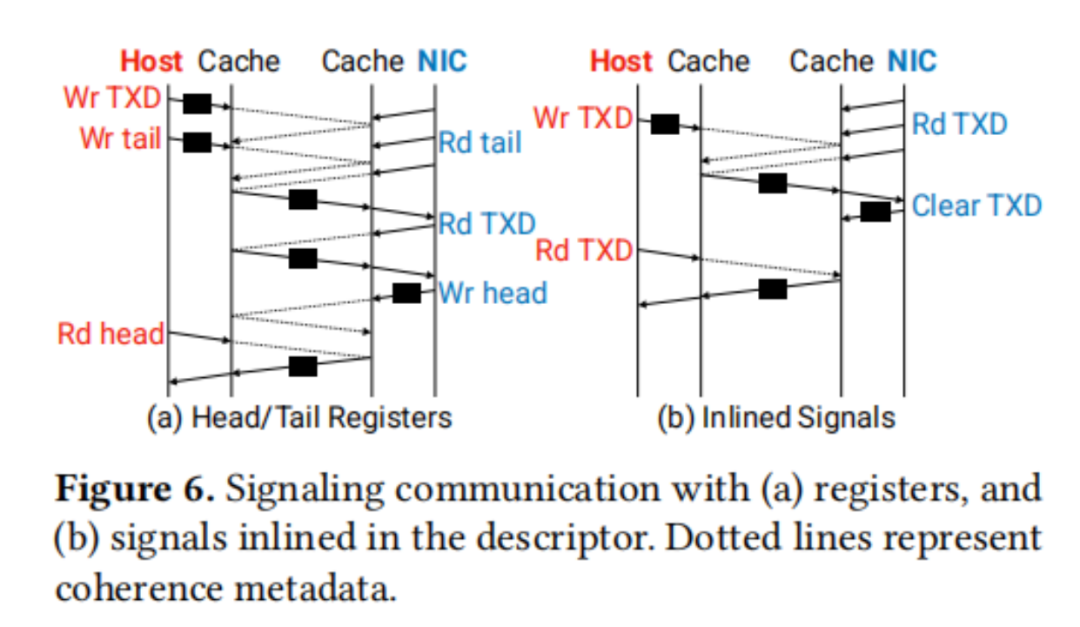
緩存一致性互連提供了一種底層硬件機(jī)制,它通過緩存狀態(tài)的轉(zhuǎn)換來傳輸數(shù)據(jù)并信令新數(shù)據(jù)的可用性。這種方法避免了傳統(tǒng)基于軟件的信令方式,即通過頭部和尾部索引寄存器進(jìn)行信令。在一致性緩存互連網(wǎng)絡(luò)(CC-NIC)中,采用了描述符內(nèi)聯(lián)信號的方法,通過一個標(biāo)志來指示描述符是否已經(jīng)準(zhǔn)備好供消費或處于空閑狀態(tài)。
將信號與描述符集成在一起的設(shè)計,消除了對每個信號單獨進(jìn)行緩存行傳輸?shù)男枰瑥亩?jié)省了跨socket緩存行訪問的延遲,如圖6所示。在傳輸過程中,NIC不再需要輪詢包含隊列尾部索引的寄存器,而是直接輪詢環(huán)中的下一個描述符。描述符的元數(shù)據(jù)中包含了一個就緒標(biāo)志,主機(jī)在寫入描述符的其他字段后會設(shè)置這個標(biāo)志。一旦這個標(biāo)志被設(shè)置,NIC就能夠在同一訪問中接收到信號和描述符的內(nèi)容,實現(xiàn)了事件驅(qū)動的處理方式。
為了進(jìn)一步優(yōu)化信令通信,一個一致性的NIC專用集成電路(ASIC)可以直接處理一致性協(xié)議消息。在這種設(shè)計中,設(shè)備不是通過緩存輪詢抽象來訪問描述符,而是直接響應(yīng)通過互連接收到的snoop消息。將一致性消息作為信號進(jìn)行處理,避免了在存在大量隊列計數(shù)時,基于軟件的輪詢所面臨的可擴(kuò)展性限制。這種設(shè)計不僅提高了效率,還增強(qiáng)了系統(tǒng)的擴(kuò)展性和性能。
元數(shù)據(jù)傳輸?shù)睦硐霐?shù)據(jù)路徑

由于一致性互連可能從DRAM或多個緩存層次結(jié)構(gòu)檢索數(shù)據(jù),我們測量每種傳輸情況的性能,以了解信號通信的性能影響。圖7顯示了在Ice Lake (ICX)和Sapphire Rapids (SPR)服務(wù)器平臺上,對齊的64B對象在各種緩存狀態(tài)下的中位數(shù)訪問延遲。我們發(fā)現(xiàn),訪問遠(yuǎn)程未緩存的DRAM大約是本地DRAM訪問延遲的兩倍。訪問遠(yuǎn)程L2緩存中的數(shù)據(jù)更快:在SPR上為171納秒,在ICX上為114納秒,對于在遠(yuǎn)程socket上托管的內(nèi)存(rh情況),對于在本地socket上托管的內(nèi)存(lh)則略高。
在這些情況下,遠(yuǎn)程CPU已將其L2緩存中的一行寫入并保留在M(修改)狀態(tài),然后本地讀取器訪問該地址。當(dāng)遠(yuǎn)程L2緩存中存在M狀態(tài)對象時,它不能存在于任何其他L2緩存中,因此總是本地L2缺失。對于reader homed的內(nèi)存,讀者的L2缺失導(dǎo)致除了向?qū)懭胝叩木彺嬲埱筮h(yuǎn)程請求外,還導(dǎo)致推測性內(nèi)存讀取。這種推測性讀取是不需要的,并且當(dāng)對象是reader-homed時,會增加總線利用率并降低性能,因為增加了不必要的流量。無論homing如何,遠(yuǎn)程L2訪問都比遠(yuǎn)程DRAM訪問更快,表明緩存到緩存?zhèn)鬏攲崿F(xiàn)了最佳延遲。CC-NIC在其設(shè)計中應(yīng)用了這些觀察結(jié)果。CC-NIC將元數(shù)據(jù)結(jié)構(gòu)放置在writer-homed的內(nèi)存中:TX描述符環(huán)位于主機(jī)上,RX環(huán)位于NIC home的內(nèi)存中。它通過使用定期緩存訪問而不是針對內(nèi)存的目標(biāo)非時間存儲來增強(qiáng)緩存到緩存?zhèn)鬏數(shù)目赡苄浴H欢琋IC接口的工作集大小影響性能,預(yù)取訪問也是如此。
確定最優(yōu)的內(nèi)存數(shù)據(jù)布局
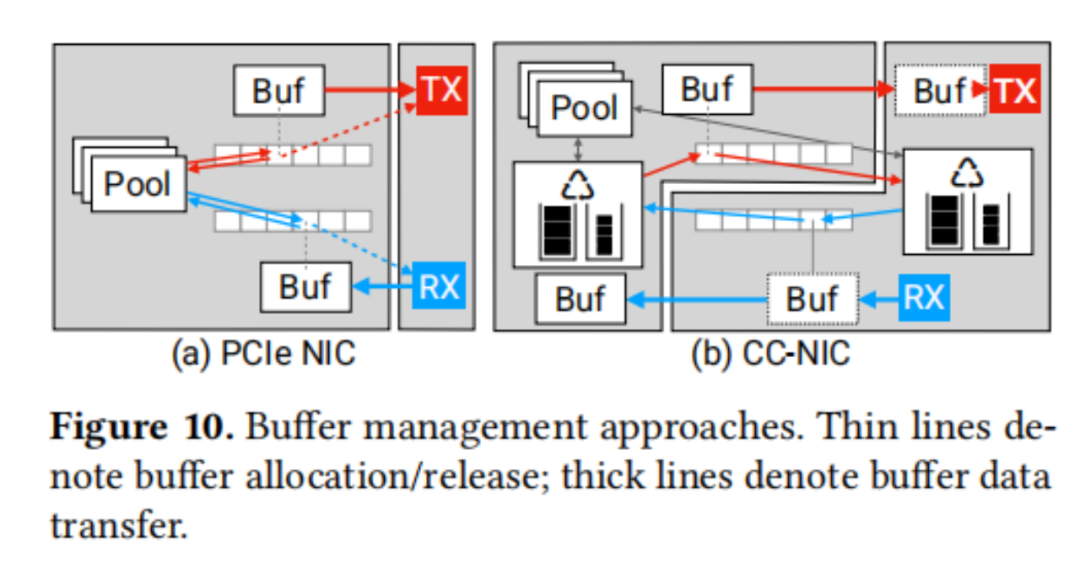
NIC元數(shù)據(jù),如描述符和信號,展示了每個描述符由一方寫入并由另一方讀取的生產(chǎn)者-消費者訪問模式。例如,TXDs由主機(jī)寫入,RXDs由NIC寫入。性能取決于緩存行的訪問模式,因為這決定了為確保一致性所必需的協(xié)議通信。
在典型的PCIe NIC接口中,RX緩沖區(qū)由主機(jī)在NIC實際接收數(shù)據(jù)包之前分配并發(fā)布到RX描述符。這使得在分配緩沖區(qū)到RX描述符時無法應(yīng)用對RX數(shù)據(jù)包突發(fā)的知識。CC-NIC通過利用緩存一致性共享緩沖區(qū)管理來克服這個問題。緩存一致性允許主機(jī)和NIC同時訪問緩沖池數(shù)據(jù)結(jié)構(gòu),而沒有與同時進(jìn)行的PCIe DMA和CPU訪問(例如,缺乏原子操作)相關(guān)的限制。共享緩沖池結(jié)構(gòu)允許NIC在傳輸后將TX緩沖區(qū)釋放回池。同樣,NIC可以根據(jù)需求分配RX緩沖區(qū)并將它們的地址寫入RX描述符環(huán)。這導(dǎo)致了一個對稱的設(shè)計,避免了額外的隊列來釋放已完成的TX數(shù)據(jù)包緩沖區(qū)和發(fā)布空白的RX數(shù)據(jù)包緩沖區(qū)。最后共享緩沖區(qū)管理使CC-NIC的緩沖區(qū)分配和描述符布局優(yōu)化成為可能。圖10比較了CC-NIC的緩沖區(qū)管理設(shè)計與傳統(tǒng)PCIe NIC的設(shè)計。
權(quán)衡高帶寬和低延遲需求
使用內(nèi)聯(lián)信號時,主機(jī)和NIC直接輪詢描述符環(huán)內(nèi)存而不是單獨的寄存器。這導(dǎo)致在寫入和輪詢一系列小于64B緩存行大小的描述符時,緩存行在socket之間抖動,增加了延遲。緩存對齊的描述符通過避免抖動來實現(xiàn)低延遲,但會浪費大量空間(例如,64B中的48B)。為了平衡這些因素,CC-NIC實現(xiàn)了一個優(yōu)化的解決方案:它將多達(dá)4個16B描述符打包到一個緩存行中,未使用的條目清零,并使用每個緩存行一個信號。如果消費者在中間遇到一個空白描述符,它將跳過到下一個緩存行以輪詢后續(xù)的描述符組。這在高吞吐量情況下避免了浪費空間,同時在低吞吐量、非批處理的情況下避免了抖動。通過每個描述符組使用一個信號,CC-NIC應(yīng)用批處理來充分利用每個描述符緩存行。
量化評估
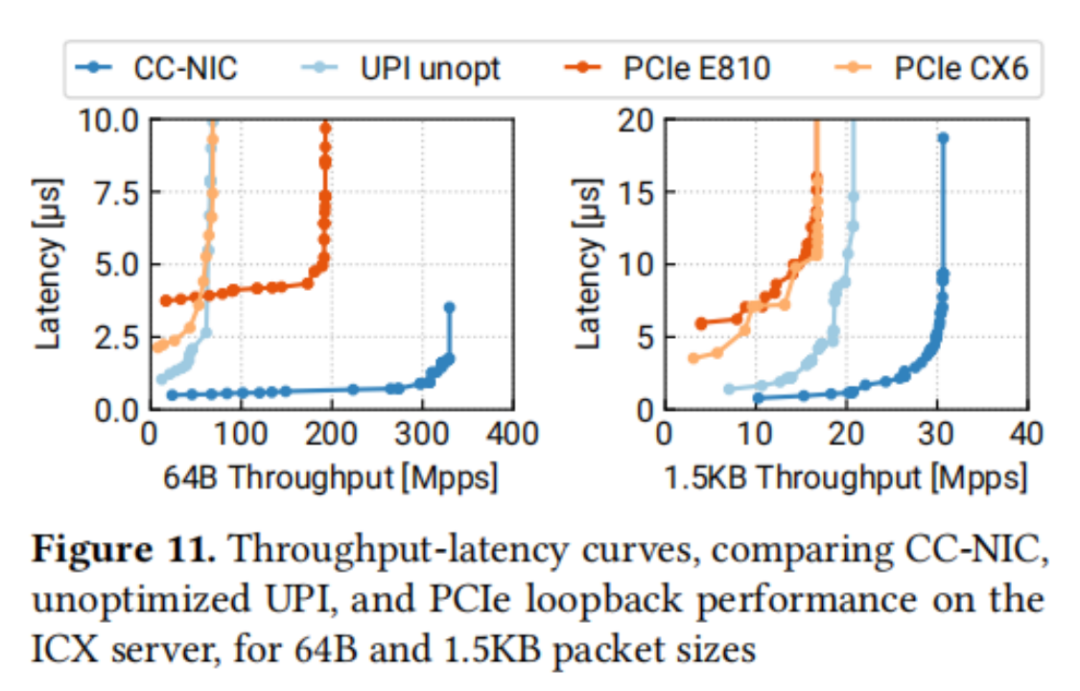
圖11顯示了在ICX服務(wù)器上的四種主機(jī)-NIC接口的比較:CX6和E810 PCIe NIC,以及在UPI上實現(xiàn)的E810接口的簡單實現(xiàn),以及CC-NIC。這些結(jié)果表明,CC-NIC在延遲改進(jìn)和高于PCIe的吞吐量方面展現(xiàn)了巨大優(yōu)勢。CC-NIC的最小延遲比CX6和E810分別低77%和86%。CC-NIC還實現(xiàn)了比E810和CX6高1.7倍和4.3倍的峰值包速率。對于1.5KB數(shù)據(jù)包,CC-NIC觀察到的比PCIe NIC高1.8倍的數(shù)據(jù)吞吐量。
總結(jié)分析
CC-NIC設(shè)計的核心內(nèi)容除了使用支持緩存一致性的總線接口外,以下幾個關(guān)鍵內(nèi)容對整體性能的提升至關(guān)重要:
1、內(nèi)聯(lián)信號:將通知功能內(nèi)聯(lián)到描述符環(huán),對于64B數(shù)據(jù)包,內(nèi)聯(lián)信號將最小延遲減少了37%,并將最大包速率提高了1.3倍。
2、描述符布局:由于UPI緩存?zhèn)鬏數(shù)?4B粒度以及內(nèi)聯(lián)信號所需的直接描述符輪詢,內(nèi)存布局顯著影響性能。通過將每個描述符緩存對齊(填充)實現(xiàn)低延遲,避免了抖動。將單個16B描述符打包到一個緩存行中通過2.9倍提高了吞吐量。優(yōu)化的描述符布局在每個緩存行中結(jié)合了一個單一的信號和一組描述符。這種布局在匹配最佳最小延遲的同時,實現(xiàn)了3.0倍的吞吐量提升。
3、批處理:批處理對于吞吐量至關(guān)重要,對于PCIe NIC,TX批處理允許使用一個MMIO門鈴提交多個數(shù)據(jù)包,更大的批處理尺寸減少了MMIO操作的速率。對于CC-NIC,TX批處理允許在單個緩存行內(nèi)傳輸多個描述符。主機(jī)端RX批處理主要影響描述符環(huán)和緩沖區(qū)池上的訪問模式,決定了緩沖區(qū)是單獨還是批量處理。
我的回答
結(jié)合上述分析,對本文最初提出的問題(本地CPU和設(shè)備互聯(lián)場景)的回答是:
緩存一致性互連技術(shù)為掛接的外部設(shè)備提供了實現(xiàn)高性能的可能性,但它的應(yīng)用并不局限于作為傳統(tǒng)接口的簡單替代。要充分利用緩存一致性的優(yōu)勢,需要對CPU與外部設(shè)備之間的交互機(jī)制進(jìn)行徹底的重構(gòu)。在這個重構(gòu)過程中,需要深入考慮幾個方面來最大化緩存一致性的收益,比如內(nèi)聯(lián)信號通知機(jī)制、優(yōu)化的數(shù)據(jù)和描述符布局以及批處理機(jī)制等。只有通過這樣的軟硬件融合優(yōu)化,才能實現(xiàn)一個高效、可擴(kuò)展和吞吐延遲均衡的系統(tǒng)。
-
處理器
+關(guān)注
關(guān)注
68文章
19799瀏覽量
233500 -
cpu
+關(guān)注
關(guān)注
68文章
11031瀏覽量
215957 -
緩存
+關(guān)注
關(guān)注
1文章
245瀏覽量
27038 -
異構(gòu)計算
+關(guān)注
關(guān)注
2文章
105瀏覽量
16583
原文標(biāo)題:在異構(gòu)計算場景下,緩存一致性究竟能帶來多大的價值?
文章出處:【微信號:SDNLAB,微信公眾號:SDNLAB】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
介紹ARM存儲一致性模型的相關(guān)知識
如何解決數(shù)據(jù)庫與緩存一致性

一致性規(guī)劃研究
CMP中Cache一致性協(xié)議的驗證
加速器一致性接口
Cache一致性協(xié)議優(yōu)化研究
自主駕駛系統(tǒng)將使用緩存一致性互連IP和非一致性互連IP
管理基于Cortex?-M7的MCU的高速緩存一致性

介紹下cpu緩存一致性(MESI協(xié)議)
使用CCIX進(jìn)行高速緩存一致性主機(jī)到FPGA接口的評估
管理基于Cortex-M7的MCU的高速緩存一致性

如何保證緩存一致性

Redis緩存與Mysql如何保證一致性?

深入理解數(shù)據(jù)備份的關(guān)鍵原則:應(yīng)用一致性與崩潰一致性的區(qū)別






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論