") 單攝像頭輸入的基于學(xué)習(xí)的動作捕捉模型實例分析
單攝像頭輸入的基于學(xué)習(xí)的動作捕捉模型實例分析

目前,從單攝像頭中進(jìn)行動作捕捉(motioncapture)的最好方法是優(yōu)化驅(qū)動的:通過優(yōu)化3D人體模型的參數(shù)從而使二次投影與視頻中的測量結(jié)果相匹配(例如,人像分割、光流、關(guān)鍵點檢測等)。優(yōu)化模型容易受到局部最小值(local minima)的影響。這成為了限制動作捕捉的瓶頸,致使每次捕捉動作時必須用干凈的綠布作為背景,并且要手動初始化或切換成多攝像頭作為輸入源。在本項研究中,我們提出了一個用于單攝像頭輸入的基于學(xué)習(xí)的動作捕捉模型。我們的模型沒有直接優(yōu)化網(wǎng)格和骨骼參數(shù),而是通過優(yōu)化神經(jīng)網(wǎng)絡(luò)權(quán)重來預(yù)測給定單目RGB視頻的3D形狀和骨骼構(gòu)造。我們的的模型是使用來自合成數(shù)據(jù)的強監(jiān)督與來自一個端到端框架中(a)骨骼關(guān)鍵點(b)密集型網(wǎng)格運動(c)人物背景分割可微渲染中的自監(jiān)督進(jìn)行聯(lián)合訓(xùn)練的通過檢驗,我們證實,我們的模型結(jié)合了監(jiān)督學(xué)習(xí)和測試時間優(yōu)化二者的優(yōu)點:監(jiān)督學(xué)習(xí)在適時情況下初始化參數(shù),在測試中確保良好的姿態(tài)和表面初始化,不需要手動操作。通過可微渲染的反向傳播進(jìn)行的自監(jiān)督,使得(無監(jiān)督的)模型適應(yīng)測試數(shù)據(jù),并且相較預(yù)訓(xùn)練固定模型而言,可提供更好的擬合性。我們在此表示,此次提出的模型將隨著經(jīng)驗的不斷積累,以及總結(jié)過去的低誤差解決方案而不斷改進(jìn)。
從“自然環(huán)境下”的單目裝置中詳細(xì)了解人體及其運動將為自動化健身房、舞蹈教師、康復(fù)指導(dǎo)、患者監(jiān)護(hù)以及更安全的人機交互的應(yīng)用開辟道路。這也會影響到電影行業(yè),因為目前,人物動作捕捉(MOCAP)和重定向,仍需要藝術(shù)家花費繁重的勞動力,或者使用昂貴的多攝像機設(shè)置和綠屏才能達(dá)到理想的精度。
當(dāng)前,大多數(shù)動作捕捉系統(tǒng)都是優(yōu)化驅(qū)動,其并不能從經(jīng)驗中獲益。單目動作捕捉系統(tǒng)優(yōu)化3D人體模型的參數(shù)以在視頻中與測量結(jié)果相匹配(如人像分割、光流等)。背景雜亂和優(yōu)化困難顯著影響追蹤性能,這導(dǎo)致過去在工作中總使用綠色的背景幕布,并且進(jìn)行細(xì)致的初始化工作。此外,通過這些費力的方法所捕捉到的動作數(shù)據(jù),并不能隨著時間的推移而改進(jìn)。這意味著每次處理視頻時,都需要從頭重復(fù)進(jìn)行優(yōu)化和手動操作。
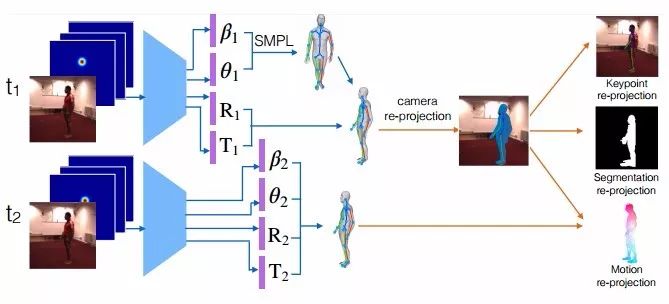
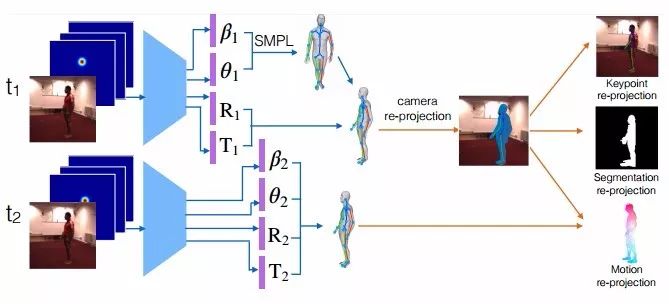
圖1 動作捕捉的自監(jiān)督學(xué)習(xí)
給定一個視頻序列和一組2D肢體關(guān)節(jié)熱圖,我們的網(wǎng)絡(luò)可預(yù)測SMPL3D人體網(wǎng)格模型的肢體參數(shù)。神經(jīng)網(wǎng)絡(luò)權(quán)重使用合成數(shù)據(jù)進(jìn)行預(yù)訓(xùn)練,并使用可微關(guān)鍵點、分割和二次投影誤差分別針對檢測到的2D關(guān)鍵點、2D分割和2D光流的自監(jiān)督缺失驅(qū)動(self-supervised losses driven)進(jìn)行微調(diào)。通過在測試時運用自監(jiān)督損失(self-supervised losses)微調(diào)其參數(shù),本文提出的模型要比基于模型的純監(jiān)督或純優(yōu)化具有更高的3D重建精度。其中,基于模型的純監(jiān)督或純優(yōu)化模型既不能適應(yīng)也不能從訓(xùn)練數(shù)據(jù)中受益。
我們提出了一個在單目視頻中進(jìn)行動作捕捉的神經(jīng)網(wǎng)絡(luò)模型,學(xué)習(xí)將一個圖像序列映射到一個相應(yīng)的3D網(wǎng)格序列中。深度學(xué)習(xí)模型的成功在于從大規(guī)模注釋數(shù)據(jù)集中進(jìn)行監(jiān)督。然而,詳細(xì)的3D網(wǎng)格標(biāo)注是非常繁瑣而耗時的,因此在實際生活中,大規(guī)模的標(biāo)注3D人體姿態(tài)是不現(xiàn)實的。在真實視頻中,我們的工作通過將手動渲染模型的大規(guī)模合成數(shù)據(jù)中的強監(jiān)督、與3D關(guān)鍵點的3D轉(zhuǎn)2D可微渲染、動作和分割以及真實獨目視頻中2D相應(yīng)檢測量的匹配中所包含的監(jiān)督相結(jié)合,從而避免了真實視頻中缺乏3D網(wǎng)格注釋這一問題。我們的自監(jiān)督利用了2D身體關(guān)節(jié)檢測、2D圖底分割和2D光流技術(shù)的最新研發(fā)成果,分別使用真實或合成數(shù)據(jù)集(如MPII、COCO和flying chairs)的強大監(jiān)督進(jìn)行學(xué)習(xí)。事實上,注釋2D身體關(guān)節(jié)比注釋3D關(guān)節(jié)或3D網(wǎng)格更容易,而光流被證明可以很容易地從合成數(shù)據(jù)泛化到真實數(shù)據(jù)。我們展示了最先進(jìn)的2D關(guān)節(jié)、光流和2D人像分割模型是如何用于推理出自認(rèn)環(huán)境下視頻中密集的3D人體結(jié)構(gòu)的,而這些工作是難以通過手動操作來完成。與之前基于優(yōu)化的動作捕捉研究相比,我們現(xiàn)在對光流和分割損耗使用的可微變形(differentiable warping)和可微相機投影技術(shù),使得模型可以通過標(biāo)準(zhǔn)的反向傳播進(jìn)行端對端的訓(xùn)練。
我們使用SMPL作為我們的密集人體3D網(wǎng)格模型。它由一定數(shù)量的固定拓?fù)浣Y(jié)構(gòu)頂點和三角形拓?fù)浣Y(jié)構(gòu)組成,其中,全局姿勢由身體各部分之間的角度θ控制,局部姿勢由網(wǎng)格表面參數(shù)β控制。對于給定姿勢和表面參數(shù),密集網(wǎng)格可以以一種分析法(可微分)形式生成,然后將其全局旋轉(zhuǎn)并轉(zhuǎn)換到期望的位置。我們模型的任務(wù)是對渲染過程進(jìn)行逆向工程,并且預(yù)測SMPL模型(θ和β)的參數(shù)以及每個輸入幀中的焦距、3D旋轉(zhuǎn)和3D翻譯,在檢測到的人身周圍提供圖像分割。
給定兩個連續(xù)幀中的3D網(wǎng)絡(luò)預(yù)測,我們可以對網(wǎng)格頂點的3D動作向量進(jìn)行差分投影,并將它們與已評估的2D可見光流向量進(jìn)行有針對性的匹配(圖1)。可微動作渲染和匹配需要對頂點可見性進(jìn)行評估,對于這一點,我們使用光線投射(ray casting),以及用來執(zhí)行代碼加速的我們神經(jīng)模型實現(xiàn)。類似地,在每一幀中,3D關(guān)鍵點都會被投影,并且他們與相應(yīng)被檢測到的2D關(guān)鍵點之間的距離將會被懲罰。最后,重要的是,可微分割匹配使用倒角距離(Chamferdistances)針對人類前景2D分割的投影頂點的欠擬合和過度擬合進(jìn)行懲罰。請注意,由于3D網(wǎng)格是無紋理的,因此我們的預(yù)測中,二次投影的誤差只存在于形態(tài)上而非設(shè)計的紋理上。
我們提供了在SURREAL和H3.6M數(shù)據(jù)集上進(jìn)行的3D密集型人體形態(tài)追蹤的定量和定性分析結(jié)果。我們將其與相應(yīng)的優(yōu)化版本進(jìn)行比較,在這些版本中,網(wǎng)格參數(shù)通過最小化我們的自監(jiān)督損失而優(yōu)化,并且在測試時不使用自監(jiān)督,進(jìn)而達(dá)到屏蔽監(jiān)督模型的效果。優(yōu)化基線很容易陷入局部極小值,而且它對初始化非常敏感。相比之下,我們的基于學(xué)習(xí)的MOCAP模型通過預(yù)訓(xùn)練(合成數(shù)據(jù))可在測試時提供良好的姿態(tài)初始化。此外,自監(jiān)督適應(yīng)模型比預(yù)訓(xùn)練的非適應(yīng)模型的3D重建誤差低。最后,我們的ablation研究突出了三種自監(jiān)督損失的互補性。
相關(guān)研究
3D動作捕捉
使用多臺攝像機進(jìn)行3D動作捕捉(四個或四個以上)是一個已被詳細(xì)研究的問題,其中現(xiàn)有的方法取得了令人印象深刻的結(jié)果。然而,即使對于僅有骨架的捕捉/追蹤,單個單目照相機的動作捕捉仍是一個尚待解決的問題。由于單目動作捕捉中的模糊和遮擋可能是嚴(yán)重的,大多數(shù)方法依賴于先前的姿勢和動作模型。早期的研究考慮線性動作模型。諸如高斯過程動力學(xué)模型、以及雙高斯過程這樣的非線性先驗,都已經(jīng)被提出,并且被證明優(yōu)于其線性對應(yīng)結(jié)構(gòu)。最近,Bogo等人提出了一種靜態(tài)圖像姿勢和3D密集形狀預(yù)測模型,其工作分為兩個階段:首先,從圖像中預(yù)測一個三維人體骨架,然后使用優(yōu)化過程將參數(shù)3D形狀擬合到預(yù)測骨架,在此過程中骨架保持不變。相反,我們的研究通過測試時間適應(yīng),將3D骨架和3D網(wǎng)格估計結(jié)合到一個端到端的可微框架中。
3D人體姿態(tài)評估
早期的3D姿態(tài)評估研究考慮了優(yōu)化方法和硬編碼的擬人約束(anthropomorphic constraints)(例如肢體對稱),以消除2D-to-3D提升期間的模糊性,。許多最近研究使用深度神經(jīng)網(wǎng)絡(luò)和大型監(jiān)督訓(xùn)練集,對于給定給定RGB圖像,學(xué)習(xí)直接復(fù)歸為3D人體姿勢。一些研究已經(jīng)探索使用2D身體姿態(tài)作為中間表征,或者作為多任務(wù)設(shè)置中的輔助任務(wù),其中豐富的被標(biāo)注的2D姿勢訓(xùn)練實例有助于特征學(xué)習(xí),并補充有限的3D人體姿勢監(jiān)督,這需要一個Vicon系統(tǒng),因此被限制只能在實驗室儀器化的環(huán)境中進(jìn)行。Rogez和Schmid通過將合成的3D人體模型與逼真的背景相結(jié)合,獲得了大規(guī)模的RGB到3D的合成注釋,也在這項研究中使用的數(shù)據(jù)集。
深度幾何學(xué)習(xí)
我們的可微渲染器遵循最近將深度學(xué)習(xí)和幾何推理相結(jié)合的研究。可微變形和可后置攝像頭投影已經(jīng)被用于學(xué)習(xí)3D攝像機動作,以及學(xué)習(xí)一個以端到端的自監(jiān)督的方式進(jìn)行的3D攝像機和3D物體聯(lián)合動作,從而使光度損失最小化。Garg等人學(xué)習(xí)單目深度預(yù)測器,由光度誤差監(jiān)督,給定一個立體圖像且已知基線作為輸入。《gvnn:幾何計算機視覺的神經(jīng)網(wǎng)絡(luò)庫》中貢獻(xiàn)了一個深度學(xué)習(xí)庫,有許多幾何操作,包括一個可后置的攝像頭投影層,類似于Yan等人和吳等人所使用的攝像頭。
結(jié)論
我們已經(jīng)提出了一個基于學(xué)習(xí)的用于密集人體3D動作追蹤的模型,用合成數(shù)據(jù)進(jìn)行監(jiān)督,并并通過動網(wǎng)格、關(guān)鍵點和分割的可微渲染進(jìn)行自監(jiān)督,并與2D等價量相匹配。我們發(fā)現(xiàn),我們的模型通過使用未標(biāo)記的視頻數(shù)據(jù)得到了改進(jìn),這對于動作捕捉非常有價值,其中,密集3D對照數(shù)據(jù)難以進(jìn)行標(biāo)記。未來研究的一個明確方向是對網(wǎng)格參數(shù)的迭代加性反饋,以獲得更高的3D重建精度,然后同樣以自監(jiān)督的方式,在參數(shù)SMPL模型的頂部學(xué)習(xí)殘差自由形態(tài)變形(residual free formdeformation)。 我們的模型在人類3D姿勢之外的擴展將使神經(jīng)智能體以人類的經(jīng)驗學(xué)習(xí)3D,而其僅由視頻動作進(jìn)行監(jiān)督。
-
攝像頭
+關(guān)注
關(guān)注
61文章
4976瀏覽量
98335 -
RGB
+關(guān)注
關(guān)注
4文章
807瀏覽量
59919
原文標(biāo)題:卡內(nèi)基梅隆大學(xué)提出基于學(xué)習(xí)的動作捕捉模型,用自監(jiān)督學(xué)習(xí)實現(xiàn)人類3D動作追蹤
文章出處:【微信號:AItists,微信公眾號:人工智能學(xué)家】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
【EASY EAI Orin Nano開發(fā)板試用體驗】--USB攝像頭使用
一文聊聊自動駕駛攝像頭
社區(qū)安裝IPC攝像頭,跟安裝一般安防監(jiān)控攝像頭有什么區(qū)別?


多光譜火焰檢測攝像頭

攝像頭及紅外成像的基本工作原理

用于環(huán)視和CMS攝像頭系統(tǒng)的四通道攝像頭應(yīng)用程序

物聯(lián)網(wǎng)系統(tǒng)中的視頻監(jiān)控解決方案_攝像頭模組分析
人流量檢測識別攝像頭

Jacinto 7攝像頭捕捉和成像子系統(tǒng)







 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論