") ARM發(fā)布最新Compute Library
ARM發(fā)布最新Compute Library

開心了這么多天,該“收心”好好干活了,正好Arm有一個好消息要告訴大家,最新一季的Compute Library公開發(fā)行版(版本 17.9)現(xiàn)已推出,讓我們一起來看看重點新增的一些特性和函數(shù)吧。
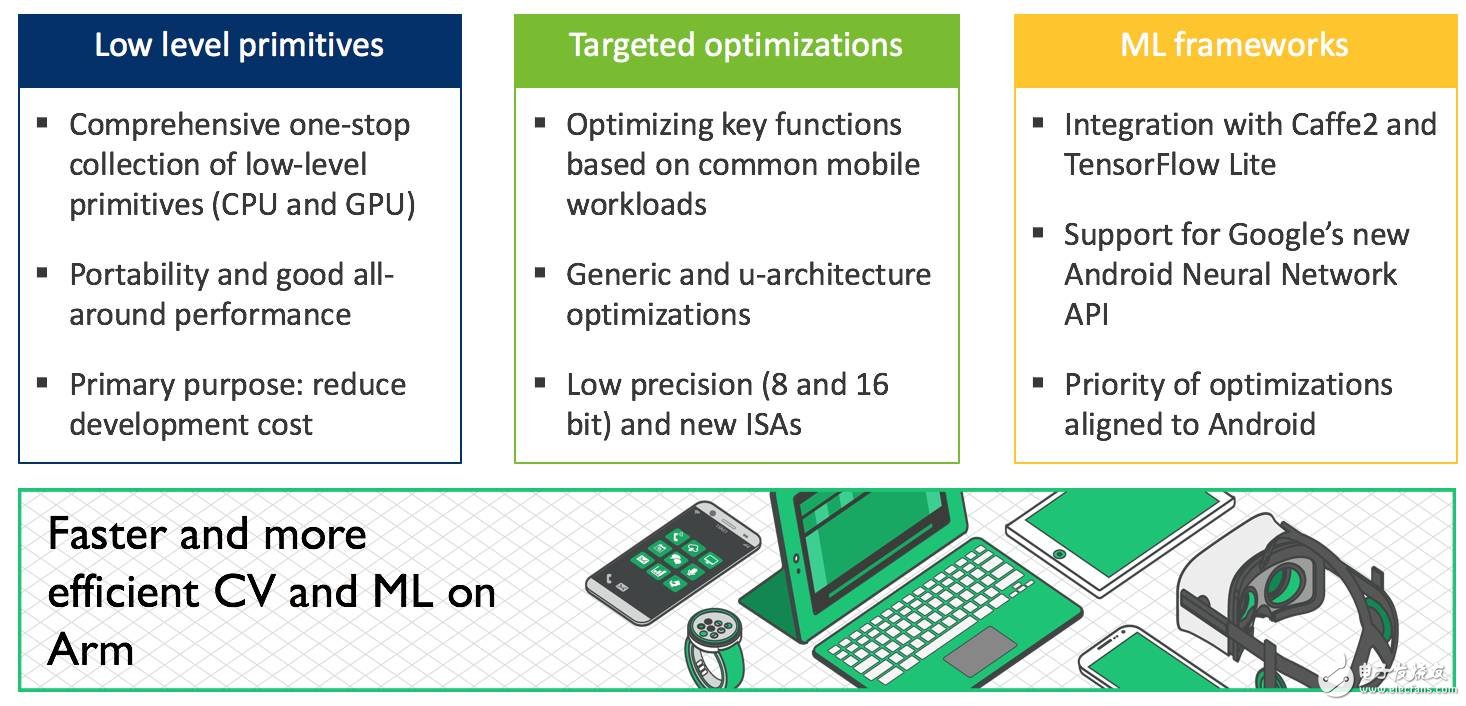
此發(fā)行版主要增添了以下特性:
-
多個新的面向 Arm CPU 和 Mali GPU 的機器學(xué)習(xí)函數(shù)
-
支持新的數(shù)據(jù)類型和精度(重點支持低精度數(shù)據(jù)類型)
-
支持利用 Arm-v8.2 CPU 架構(gòu)的新指令實現(xiàn) FP16 加速
-
針對關(guān)鍵的機器學(xué)習(xí)函數(shù)進(jìn)行微架構(gòu)優(yōu)化
-
降低復(fù)雜網(wǎng)絡(luò)內(nèi)存開銷的內(nèi)存管理工具
-
用于基本測試的基礎(chǔ)結(jié)構(gòu)框架
我們添加了許多新的函數(shù),滿足以 Arm 型平臺為目標(biāo)的開發(fā)人員的需求。這些新例程采用 OpenCL C 和 C(利用NEONIntrinsics)編寫。
OpenCL C(針對Mali GPU):
-
Bounded ReLu
-
Depth wise卷積(在 mobileNet 中使用)
-
反量化
-
Direct卷積 1x1
-
Direct卷積 3x3
-
Direct卷積 5x5
-
3D 張量展平
-
向下取整
-
全局池化(在 SqueezeNet 中使用)
-
Leaky ReLu
-
量化
-
Reduction 運算
-
ROI 池化
CPU (NEON):
-
Bounded ReLu
-
Direct卷積 5x5
-
反量化
-
向下取整
-
Leaky ReLu
-
量化
-
具有定點加速的新函數(shù)
Direct卷積是在經(jīng)典滑動窗口基礎(chǔ)上執(zhí)行卷積層的一種替代方法。在Mali GPU Bifrost 架構(gòu)的實現(xiàn)中,使用Direct卷積對于改進(jìn)我們 CNN 的性能很有幫助(我們觀察到,對 AlexNet 使用Direct卷積時性能最多可提升 1.5 倍)。
支持低精度在許多機器學(xué)習(xí)應(yīng)用場景中,可以通過降低計算精度來提升效率和性能。這是我們工程師上一季度的重點關(guān)注領(lǐng)域。我們利用低精度實施了現(xiàn)有函數(shù)的新版本,如 8 位和 16 位定點,這同時適用于 CPU 和 GPU。
GPU (OpenCL) - 8 位定點
-
Direct卷積 1x1
-
Direct卷積 3x3
-
Direct卷積 5x5
GPU (OpenCL) - 16 位定點
-
算術(shù)加法、減法和乘法
-
深度轉(zhuǎn)換
-
深度連接(concatenate)
-
深度卷積
-
GEMM
-
卷積層
-
全連接層
-
池化層
-
Softmax 層
NEON - 16 位定點
-
算術(shù)加法、減法和乘法
-
卷積層
-
深度連接(concatenate)
-
深度轉(zhuǎn)換
-
Direct卷積 1x1
-
全連接層
-
GEMM
-
Softmax 層
在 Compute Library 項目啟動之初,我們的宗旨主要是共享計算機視覺和機器學(xué)習(xí)的一整套底層函數(shù),要保障性能良好,最為重要的是要可靠且可移植。Compute Library 能夠為著眼于 Arm 處理器的開發(fā)人員和合作伙伴節(jié)省時間和成本;同時,Compute Library 在我們合作伙伴實施的許多系統(tǒng)配置中也有出色的表現(xiàn)。這也是我們將NEONintrinsic和 OpenCL C 作為目標(biāo)語言的原因。但在某些情形中,必須要充分發(fā)揮硬件的所有性能。因此,我們也著眼于在 Compute Library 中增加底層原語,這些底層原語利用專為目標(biāo) CPU 微架構(gòu)定制的手工匯編進(jìn)行了優(yōu)化。
在決定我們應(yīng)將重點放在哪些函數(shù)時,我們的研發(fā)團隊研究了利用 Caffe 框架的機器學(xué)習(xí)工作負(fù)載。
所用的三種工作負(fù)載為:
-
AlexNet,將圖像目標(biāo)分類到1000個可能類別的 大型網(wǎng)絡(luò)
-
LeNet,將手寫數(shù)字分類到10個可能類別的 中型網(wǎng)絡(luò)
-
ConvNet,將圖像分類到10個可能類別的 小型網(wǎng)絡(luò)
下圖顯示了這些工作負(fù)載的指令使用情況:
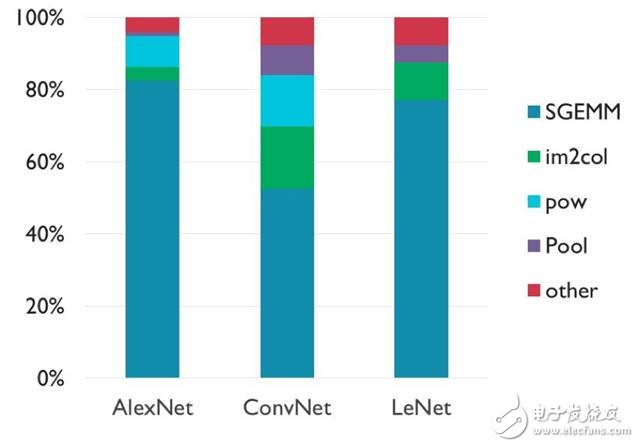
我們的團隊發(fā)現(xiàn),這些網(wǎng)絡(luò)大約有 50-80% 的計算在 SGEMM 函數(shù)內(nèi)發(fā)生,這個函數(shù)是將兩個浮點矩陣相乘。還有其他幾個函數(shù)也比較突出,例如冪函數(shù)和轉(zhuǎn)換矩陣維度的函數(shù)。其余的計算則分散在一個長尾分布中。
您可以發(fā)現(xiàn)這樣的一個趨勢,SGEMM 所占的比例隨著網(wǎng)絡(luò)規(guī)模變大而升高,但這種趨勢更有可能是因為層的配置所致,而不是與大小相關(guān)。從中我們可以意識到,矩陣乘法對神經(jīng)網(wǎng)絡(luò)確實非常重要。如果說哪個目標(biāo)函數(shù)最需要優(yōu)化,應(yīng)該就是它了。
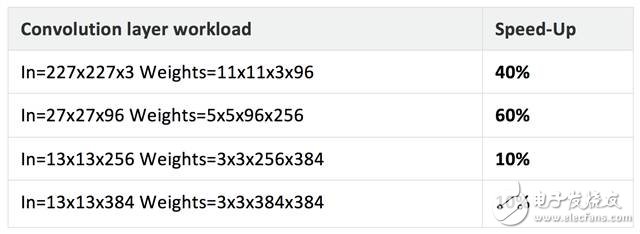
在此發(fā)行版的庫中,我們增加了面向Cortex-A53和Cortex-A72處理器的 CPU 匯編優(yōu)化版 SGEMM (FP32)。這些例程的性能視平臺而異,但我們在測試中看到總體性能有大幅提升。例如,我們對 Firefly 開發(fā)板(64 位,多線程)進(jìn)行了 AlexNet 基準(zhǔn)測試,在 Cortex-A72 上測量到性能提升了約 1.6 倍。
下表顯示了我們在相同平臺上使用新的優(yōu)化例程的一組基準(zhǔn)測試結(jié)果。
在關(guān)于17.6 發(fā)行版的介紹中(Arm計算庫第二個公開版本正式發(fā)布,這些廠商一直在用其進(jìn)行開發(fā)!),Arm計劃在 CPU 中支持用于機器學(xué)習(xí)的新架構(gòu)功能,而第一步就是在 Armv8.2 CPU 中支持 FP16。目前,庫中增加了面向 Armv8.2 FP16 的新函數(shù):
-
激活層
-
算術(shù)加法、減法和乘法
-
批量歸一化(Batch Normalization)
-
卷積層(基于 GEMM)
-
卷積層(Direct卷積)
-
局部連接
-
歸一化
-
池化層
-
Softmax 層
雖然我們沒有對這些函數(shù)做一些激進(jìn)的優(yōu)化(這些函數(shù)采用 NEON intrinsic而非手工優(yōu)化的匯編語言編寫),但與使用 FP32 且必須在不同格式之間轉(zhuǎn)換相比,性能有了大幅提升。下表比較了一些工作負(fù)載,從中可以看出,借助 v8.2 CPU 指令,可以減少計算所需的周期數(shù)。
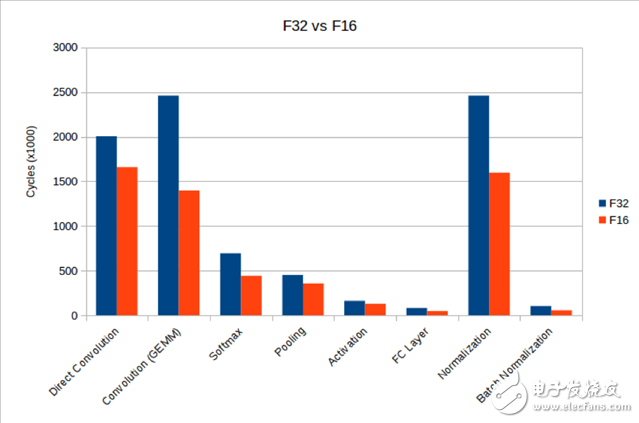
如今,許多移動合作伙伴正在利用 Mali GPU 來加快機器學(xué)習(xí)工作負(fù)載的速度。根據(jù)這些合作伙伴的反饋,我們在這個領(lǐng)域做了針對性的優(yōu)化。
新的Direct卷積 3x3 和 5x5 函數(shù)針對 Bifrost 架構(gòu)進(jìn)行了優(yōu)化,性能與上一發(fā)行版 (17.06) 中的例程相比有了顯著提升。在部分測試平臺上使用這些新例程時,我們發(fā)現(xiàn)性能普遍提高約 2.5 倍。此外,在 AlexNet 的多批量工作負(fù)載中,GEMM 中引入的新優(yōu)化幫助我們獲得了 3.5 倍的性能提升。性能因平臺和實現(xiàn)方法而異,但總體而言,我們預(yù)計這些優(yōu)化能夠在 Bifrost GPU 上顯著提升性能。
下圖顯示了在華為 Mate 9 智能手機上的一些測試結(jié)果,測試中禁用了 DVFS,取 10 次運行中最短的執(zhí)行時間作為結(jié)果。由此可見,新例程在性能上優(yōu)于舊版本。
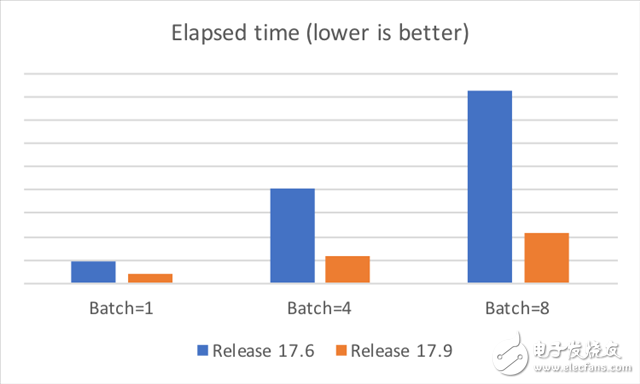
復(fù)雜工作負(fù)載(大型網(wǎng)絡(luò))會需要大量內(nèi)存,對于嵌入式平臺和移動平臺而言,這正是影響性能的癥結(jié)所在。我們聽取了合作伙伴的反饋,決定在庫的運行時組件中添加一個“內(nèi)存管理器”功能。內(nèi)存管理器通過循環(huán)利用臨時緩沖區(qū)降低通用算法/模型的內(nèi)存要求。
內(nèi)存管理器包含一個生命周期管理器(用于跟蹤注冊對象的生命周期)和一個池管理器(用于管理內(nèi)存池)。當(dāng)開發(fā)人員配置函數(shù)時,運行時組件會跟蹤內(nèi)存要求。例如,一些張量可能僅僅是暫時的,所以只分配所需的內(nèi)存。內(nèi)存管理器的配置應(yīng)從單一線程循序執(zhí)行,以便提高內(nèi)存利用率。
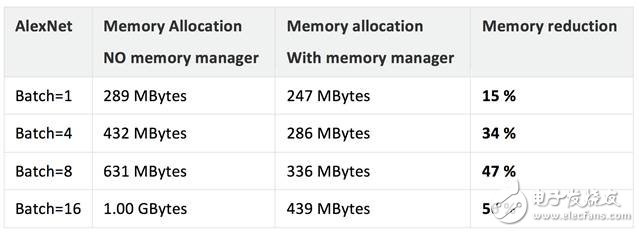
下表顯示了在使用內(nèi)存管理器時在我們測試平臺上測量到的內(nèi)存節(jié)省情況。結(jié)果因平臺、工作負(fù)載和配置而異。總體而言,我們認(rèn)為內(nèi)存管理器能夠幫助開發(fā)人員節(jié)省內(nèi)存。
接下來,我們計劃繼續(xù)根據(jù)合作伙伴和開發(fā)人員的需求,進(jìn)行具體的優(yōu)化。此外,我們還將重視與機器學(xué)習(xí)框架的集成,并與 Google Android NN 等新的 API 保持同步。
我們的目標(biāo)不是涵蓋所有數(shù)據(jù)類型和函數(shù),而是根據(jù)開發(fā)人員和合作伙伴的反饋,精選出最需要實施的函數(shù)。所以,我們期待著聽到您的聲音!
-
ARM
+關(guān)注
關(guān)注
134文章
9351瀏覽量
377435
原文標(biāo)題:節(jié)后第一個好消息就它了——Compute Library 17.9 正式發(fā)布!
文章出處:【微信號:arm_china,微信公眾號:Arm芯聞】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
W5500 ARM mbed 庫發(fā)布
PRI Compute Module – 樹莓派的繼任者
請問C2000支持IEC60730的library發(fā)布了嗎?
使用CRL“ARM CMSIS SIN COS”和SW4STM32發(fā)布構(gòu)建simulink項目代碼報錯怎么解決?
VHDL Library of Arithmetic Uni
VHDL Library of Arithmetic Uni
ARM系列—機密計算
Arm RAN 加速庫(RAN Acceleration Library, RAL)通過采用 BSD 開源許可證將代碼庫正式開源
RL78系列 Data Flash Library Type04軟件包3.0版發(fā)布說明

利用Arm Kleidi技術(shù)實現(xiàn)PyTorch優(yōu)化

Arm Neoverse CMN S3 推動Compute Express Link (CXL) 存儲創(chuàng)新





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論