") 一文掌握Python多線程
一文掌握Python多線程
目錄
- 1 多線程
- 1.1 簡(jiǎn)介
- 1.2 線程模塊
- 1.3 使用 _thread 創(chuàng)建線程
- 1.4 使用 threading 創(chuàng)建線程
- 1.5 線程同步鎖
- 1.6 線程優(yōu)先級(jí)隊(duì)列( Queue)
- 1.7 ThreadLocal
- 1.8 線程池
- 2 多進(jìn)程與多線程
- 2.1 區(qū)別
- 3.2 線程切換
- 3.3 CPU密集型&IO密集型
- 3.4 異步IO
1 多線程
1.1 簡(jiǎn)介
多線程類似于同時(shí)執(zhí)行多個(gè)不同程序,多線程運(yùn)行有如下優(yōu)點(diǎn):
使用線程可以把占據(jù)長(zhǎng)時(shí)間的程序中的任務(wù)放到后臺(tái)去處理。
用戶界面可以更加吸引人,比如用戶點(diǎn)擊了一個(gè)按鈕去觸發(fā)某些事件的處理,可以彈出一個(gè)進(jìn)度條來(lái)顯示處理的進(jìn)度。
程序的運(yùn)行速度可能加快。
在一些等待的任務(wù)實(shí)現(xiàn)上如用戶輸入、文件讀寫(xiě)和網(wǎng)絡(luò)收發(fā)數(shù)據(jù)等,線程就比較有用了。在這種情況下我們可以釋放一些珍貴的資源如內(nèi)存占用等等。
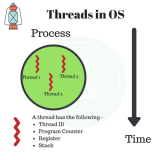
每個(gè)獨(dú)立的線程有一個(gè)程序運(yùn)行的入口、順序執(zhí)行序列和程序的出口。但是線程不能夠獨(dú)立執(zhí)行,必須依存在應(yīng)用程序中,由應(yīng)用程序提供多個(gè)線程執(zhí)行控制。
每個(gè)線程都有他自己的一組CPU寄存器,稱為線程的上下文,該上下文反映了線程上次運(yùn)行該線程的CPU寄存器的狀態(tài)。
指令指針和堆棧指針寄存器是線程上下文中兩個(gè)最重要的寄存器,線程總是在進(jìn)程得到上下文中運(yùn)行的,這些地址都用于標(biāo)志擁有線程的進(jìn)程地址空間中的內(nèi)存。
線程可以被搶占(中斷)。在其他線程正在運(yùn)行時(shí),線程可以暫時(shí)擱置(也稱為睡眠) -- 這就是線程的退讓。
線程可以分為:
內(nèi)核線程:由操作系統(tǒng)內(nèi)核創(chuàng)建和撤銷。
用戶線程:不需要內(nèi)核支持而在用戶程序中實(shí)現(xiàn)的線程。
Python3 線程中常用的兩個(gè)模塊為:_thread和threading(推薦使用)
thread模塊已被廢棄。用戶可以使用threading模塊代替。所以,在 Python3 中不能再使用thread模塊。為了兼容性,Python3 將thread重命名為_(kāi)thread。
1.2 線程模塊
Python3 通過(guò)兩個(gè)標(biāo)準(zhǔn)庫(kù)_thread和threading提供對(duì)線程的支持。
_thread提供了低級(jí)別的、原始的線程以及一個(gè)簡(jiǎn)單的鎖,它相比于threading模塊的功能還是比較有限的。
threading模塊除了包含_thread模塊中的所有方法外,還提供的其他方法:
threading. current_thread(): 返回當(dāng)前的線程變量。
threading.enumerate(): 返回一個(gè)包含正在運(yùn)行的線程的列表。正在運(yùn)行指線程啟動(dòng)后、結(jié)束前,不包括啟動(dòng)前和終止后的線程。
threading.active_count(): 返回正在運(yùn)行的線程數(shù)量,與len(threading.enumerate())有相同的結(jié)果。
threading.Thread(target, args=(), kwargs={}, daemon=None):
創(chuàng)建Thread類的實(shí)例。
target:線程將要執(zhí)行的目標(biāo)函數(shù)。
args:目標(biāo)函數(shù)的參數(shù),以元組形式傳遞。
kwargs:目標(biāo)函數(shù)的關(guān)鍵字參數(shù),以字典形式傳遞。
daemon:指定線程是否為守護(hù)線程。
threading.Thread類提供了以下方法與屬性:
__init__(self, group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None):
self:初始化Thread對(duì)象。
group:線程組,暫時(shí)未使用,保留為將來(lái)的擴(kuò)展。
target:線程將要執(zhí)行的目標(biāo)函數(shù)。
name:線程的名稱。
args:目標(biāo)函數(shù)的參數(shù),以元組形式傳遞。
kwargs:目標(biāo)函數(shù)的關(guān)鍵字參數(shù),以字典形式傳遞。
daemon:指定線程是否為守護(hù)線程。
start(self):?jiǎn)?dòng)線程。將調(diào)用線程的run()方法。
run(self):線程在此方法中定義要執(zhí)行的代碼。
join(self, timeout=None):等待線程終止。默認(rèn)情況下,join()會(huì)一直阻塞,直到被調(diào)用線程終止。如果指定了timeout參數(shù),則最多等待timeout秒。
is_alive(self):返回線程是否在運(yùn)行。如果線程已經(jīng)啟動(dòng)且尚未終止,則返回True,否則返回False。
getName(self):返回線程的名稱。
setName(self, name):設(shè)置線程的名稱。
ident屬性:線程的唯一標(biāo)識(shí)符。
daemon屬性:線程的守護(hù)標(biāo)志,用于指示是否是守護(hù)線程。
一個(gè)簡(jiǎn)單的線程實(shí)例:
import threading import time def print_numbers(): for i in range(5): time.sleep(1) print(i) # 創(chuàng)建線程 thread = threading.Thread(target=print_numbers) # 啟動(dòng)線程 thread.start() # 等待線程結(jié)束 thread.join() 輸出結(jié)果為: 0 1 2 3 4
1.3 使用 _thread 創(chuàng)建線程
Python中使用線程有兩種方式:函數(shù)或者用類來(lái)包裝線程對(duì)象。
函數(shù)式:調(diào)用_thread模塊中的start_new_thread()函數(shù)來(lái)產(chǎn)生新線程。語(yǔ)法如下:_thread.start_new_thread ( function, args[, kwargs] )
參數(shù)說(shuō)明:
function:線程函數(shù)。
args:傳遞給線程函數(shù)的參數(shù),他必須是個(gè)tuple類型。
kwargs:可選參數(shù)。
#!/usr/bin/python3
import _thread
import time
# 為線程定義一個(gè)函數(shù)
def print_time( threadName, delay):
count = 0
while count < 5:
time.sleep(delay)
count += 1
print ("%s: %s" % ( threadName, time.ctime(time.time()) ))
# 創(chuàng)建兩個(gè)線程
try:
_thread.start_new_thread( print_time, ("Thread-1", 2, ) )
_thread.start_new_thread( print_time, ("Thread-2", 4, ) )
except:
print ("Error: 無(wú)法啟動(dòng)線程")
while 1:
pass
執(zhí)行以上程序輸出結(jié)果如下:
Thread-1: Wed Jan 5 17:38:08 2022
Thread-2: Wed Jan 5 17:38:10 2022
Thread-1: Wed Jan 5 17:38:10 2022
Thread-1: Wed Jan 5 17:38:12 2022
Thread-2: Wed Jan 5 17:38:14 2022
Thread-1: Wed Jan 5 17:38:14 2022
Thread-1: Wed Jan 5 17:38:16 2022
Thread-2: Wed Jan 5 17:38:18 2022
Thread-2: Wed Jan 5 17:38:22 2022
Thread-2: Wed Jan 5 17:38:26 2022
執(zhí)行以上程后可以按下 ctrl-c 退出。
1.4 使用 threading 創(chuàng)建線程
我們可以通過(guò)直接從threading.Thread繼承創(chuàng)建一個(gè)新的子類,并實(shí)例化后調(diào)用 start() 方法啟動(dòng)新線程,即它調(diào)用了線程的 run() 方法:
#!/usr/bin/python3 import threading import time exitFlag = 0 class myThread (threading.Thread): def __init__(self, threadID, name, delay): threading.Thread.__init__(self) self.threadID = threadID self.name = name self.delay = delay def run(self): print ("開(kāi)始線程:" + self.name) print_time(self.name, self.delay, 5) print ("退出線程:" + self.name) def print_time(threadName, delay, counter): while counter: if exitFlag: threadName.exit() time.sleep(delay) print ("%s: %s" % (threadName, time.ctime(time.time()))) counter -= 1 # 創(chuàng)建新線程 thread1 = myThread(1, "Thread-1", 1) thread2 = myThread(2, "Thread-2", 2) # 開(kāi)啟新線程 thread1.start() thread2.start() thread1.join() thread2.join() print ("退出主線程") 執(zhí)行結(jié)果如下; 開(kāi)始線程:Thread-1 開(kāi)始線程:Thread-2 Thread-1: Wed Jan 5 17:34:54 2022 Thread-2: Wed Jan 5 17:34:55 2022 Thread-1: Wed Jan 5 17:34:55 2022 Thread-1: Wed Jan 5 17:34:56 2022 Thread-2: Wed Jan 5 17:34:57 2022 Thread-1: Wed Jan 5 17:34:57 2022 Thread-1: Wed Jan 5 17:34:58 2022 退出線程:Thread-1 Thread-2: Wed Jan 5 17:34:59 2022 Thread-2: Wed Jan 5 17:35:01 2022 Thread-2: Wed Jan 5 17:35:03 2022 退出線程:Thread-2 退出主線程
1.5 線程同步鎖
如果多個(gè)線程共同對(duì)某個(gè)數(shù)據(jù)修改,則可能出現(xiàn)不可預(yù)料的結(jié)果,為了保證數(shù)據(jù)的正確性,需要對(duì)多個(gè)線程進(jìn)行同步。
使用Thread對(duì)象的Lock和Rlock可以實(shí)現(xiàn)簡(jiǎn)單的線程同步,這兩個(gè)對(duì)象都有acquire方法和release方法,對(duì)于那些需要每次只允許一個(gè)線程操作的數(shù)據(jù),可以將其操作放到acquire和release方法之間。如下:
多線程的優(yōu)勢(shì)在于可以同時(shí)運(yùn)行多個(gè)任務(wù)(至少感覺(jué)起來(lái)是這樣)。但是當(dāng)線程需要共享數(shù)據(jù)時(shí),可能存在數(shù)據(jù)不同步的問(wèn)題。
考慮這樣一種情況:一個(gè)列表里所有元素都是 0,線程set從后向前把所有元素改成 1,而線程print負(fù)責(zé)從前往后讀取列表并打印。
那么,可能線程"set"開(kāi)始改的時(shí)候,線程"print"便來(lái)打印列表了,輸出就成了一半0一半1,這就是數(shù)據(jù)的不同步。為了避免這種情況,引入了鎖的概念。
鎖有兩種狀態(tài)——鎖定和未鎖定。每當(dāng)一個(gè)線程比如"set"要訪問(wèn)共享數(shù)據(jù)時(shí),必須先獲得鎖定;如果已經(jīng)有別的線程比如"print"獲得鎖定了,那么就讓線程"set"暫停,也就是同步阻塞;等到線程"print"訪問(wèn)完畢,釋放鎖以后,再讓線程"set"繼續(xù)。
經(jīng)過(guò)這樣的處理,打印列表時(shí)要么全部輸出0,要么全部輸出1,不會(huì)再出現(xiàn)一半0一半1的尷尬場(chǎng)面。
#!/usr/bin/python3
import threading
import time
class myThread (threading.Thread):
def __init__(self, threadID, name, delay):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.delay = delay
def run(self):
print ("開(kāi)啟線程: " + self.name)
# 獲取鎖,用于線程同步
threadLock.acquire()
print_time(self.name, self.delay, 3)
# 釋放鎖,開(kāi)啟下一個(gè)線程
threadLock.release()
def print_time(threadName, delay, counter):
while counter:
time.sleep(delay)
print ("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
threadLock = threading.Lock()
threads = []
# 創(chuàng)建新線程
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# 開(kāi)啟新線程
thread1.start()
thread2.start()
# 添加線程到線程列表
threads.append(thread1)
threads.append(thread2)
# 等待所有線程完成
for t in threads:
t.join()
print ("退出主線程")
輸出結(jié)果為:
開(kāi)啟線程: Thread-1
開(kāi)啟線程: Thread-2
Thread-1: Wed Jan 5 17:36:50 2022
Thread-1: Wed Jan 5 17:36:51 2022
Thread-1: Wed Jan 5 17:36:52 2022
Thread-2: Wed Jan 5 17:36:54 2022
Thread-2: Wed Jan 5 17:36:56 2022
Thread-2: Wed Jan 5 17:36:58 2022
退出主線程
獲得鎖的線程用完后一定要釋放鎖,否則那些苦苦等待鎖的線程將永遠(yuǎn)等待下去,成為死線程。所以盡量用try...finally來(lái)確保鎖一定會(huì)被釋放
1.6 線程優(yōu)先級(jí)隊(duì)列( Queue)
Python 的Queue模塊中提供了同步的、線程安全的隊(duì)列類,包括FIFO(先入先出)隊(duì)列Queue,LIFO(后入先出)隊(duì)列LifoQueue,和優(yōu)先級(jí)隊(duì)列 PriorityQueue。
這些隊(duì)列都實(shí)現(xiàn)了鎖原語(yǔ),能夠在多線程中直接使用,可以使用隊(duì)列來(lái)實(shí)現(xiàn)線程間的同步。
Queue 模塊中的常用方法:
Queue.qsize():返回隊(duì)列的大小
Queue.empty():如果隊(duì)列為空,返回True,反之False
Queue.full():如果隊(duì)列滿了,返回True,反之False,Queue.full 與 maxsize 大小對(duì)應(yīng)
Queue.get([block[, timeout]]):獲取隊(duì)列,timeout等待時(shí)間
Queue.get_nowait():相當(dāng)Queue.get(False)
Queue.put(item):寫(xiě)入隊(duì)列,timeout等待時(shí)間
Queue.put_nowait(item):相當(dāng)Queue.put(item, False)
Queue.task_done():在完成一項(xiàng)工作之后,Queue.task_done()函數(shù)向任務(wù)已經(jīng)完成的隊(duì)列發(fā)送一個(gè)信號(hào)
Queue.join():實(shí)際上意味著等到隊(duì)列為空,再執(zhí)行別的操作
#!/usr/bin/python3
import queue
import threading
import time
exitFlag = 0
class myThread (threading.Thread):
def __init__(self, threadID, name, q):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.q = q
def run(self):
print ("開(kāi)啟線程:" + self.name)
process_data(self.name, self.q)
print ("退出線程:" + self.name)
def process_data(threadName, q):
while not exitFlag:
queueLock.acquire()
if not workQueue.empty():
data = q.get()
queueLock.release()
print ("%s processing %s" % (threadName, data))
else:
queueLock.release()
time.sleep(1)
threadList = ["Thread-1", "Thread-2", "Thread-3"]
nameList = ["One", "Two", "Three", "Four", "Five"]
queueLock = threading.Lock()
workQueue = queue.Queue(10)
threads = []
threadID = 1
# 創(chuàng)建新線程
for tName in threadList:
thread = myThread(threadID, tName, workQueue)
thread.start()
threads.append(thread)
threadID += 1
# 填充隊(duì)列
queueLock.acquire()
for word in nameList:
workQueue.put(word)
queueLock.release()
# 等待隊(duì)列清空
while not workQueue.empty():
pass
# 通知線程是時(shí)候退出
exitFlag = 1
# 等待所有線程完成
for t in threads:
t.join()
print ("退出主線程")
執(zhí)行結(jié)果:
開(kāi)啟線程:Thread-1
開(kāi)啟線程:Thread-2
開(kāi)啟線程:Thread-3
Thread-3 processing One
Thread-1 processing Two
Thread-2 processing Three
Thread-3 processing Four
Thread-1 processing Five
退出線程:Thread-3
退出線程:Thread-2
退出線程:Thread-1
退出主線程
1.7 ThreadLocal
在多線程環(huán)境下,每個(gè)線程都有自己的數(shù)據(jù)。一個(gè)線程使用自己的局部變量比使用全局變量好,因?yàn)榫植孔兞恐挥芯€程自己能看見(jiàn),不會(huì)影響其他線程,而全局變量的修改必須加鎖,比較麻煩
因此,ThreadLocal應(yīng)運(yùn)而生,不用查找dict,ThreadLocal自動(dòng)做這件事:
import threading
# 創(chuàng)建全局ThreadLocal對(duì)象:
local_school = threading.local()
def process_student():
print ('Hello, %s (in %s)' % (local_school.student, threading.current_thread().name))
def process_thread(name):
# 綁定ThreadLocal的student:
local_school.student = name
process_student()
t1 = threading.Thread(target= process_thread, args=('Alice',), name='Thread-A')
t2 = threading.Thread(target= process_thread, args=('Bob',), name='Thread-B')
t1.start()
t2.start()
t1.join()
t2.join()
執(zhí)行結(jié)果:
Hello, Alice (in Thread-A)
Hello, Bob (in Thread-B)
全局變量local_school就是一個(gè)ThreadLocal對(duì)象,每個(gè)Thread對(duì)它都可以讀寫(xiě)student屬性,但互不影響。可以把local_school看成全局變量,但每個(gè)屬性如local_school.student都是線程的局部變量,可以任意讀寫(xiě)而互不干擾,也不用管理鎖的問(wèn)題,ThreadLocal內(nèi)部會(huì)處理。
可以理解為全局變量local_school是一個(gè)dict,不但可以用local_school.student,還可以綁定其他變量,如local_school.teacher等等。
ThreadLocal最常用的地方就是為每個(gè)線程綁定一個(gè)數(shù)據(jù)庫(kù)連接,HTTP請(qǐng)求,用戶身份信息等,這樣一個(gè)線程的所有調(diào)用到的處理函數(shù)都可以非常方便地訪問(wèn)這些資源。
1.8 線程池
點(diǎn)擊了解 線程池 multiprocessing.dummy.Pool
2 多進(jìn)程與多線程
2.1 區(qū)別
多進(jìn)程模式最大的優(yōu)點(diǎn)就是穩(wěn)定性高,因?yàn)橐粋€(gè)子進(jìn)程崩潰了,不會(huì)影響主進(jìn)程和其他子進(jìn)程。(當(dāng)然主進(jìn)程掛了所有進(jìn)程就全掛了,但是Master進(jìn)程只負(fù)責(zé)分配任務(wù),掛掉的概率低)著名的Apache最早就是采用多進(jìn)程模式。
多進(jìn)程模式的缺點(diǎn)是創(chuàng)建進(jìn)程的代價(jià)大,在Unix/Linux系統(tǒng)下,用fork調(diào)用還行,在Windows下創(chuàng)建進(jìn)程開(kāi)銷巨大。另外,操作系統(tǒng)能同時(shí)運(yùn)行的進(jìn)程數(shù)也是有限的,在內(nèi)存和CPU的限制下,如果有幾千個(gè)進(jìn)程同時(shí)運(yùn)行,操作系統(tǒng)連調(diào)度都會(huì)成問(wèn)題。
多線程模式通常比多進(jìn)程快一點(diǎn),但是也快不到哪去,而且,多線程模式致命的缺點(diǎn)就是任何一個(gè)線程掛掉都可能直接造成整個(gè)進(jìn)程崩潰,因?yàn)樗芯€程共享進(jìn)程的內(nèi)存。在Windows上,如果一個(gè)線程執(zhí)行的代碼出了問(wèn)題,經(jīng)常可以看到這樣的提示:該程序執(zhí)行了非法操作,即將關(guān)閉,其實(shí)往往是某個(gè)線程出了問(wèn)題,但是操作系統(tǒng)會(huì)強(qiáng)制結(jié)束整個(gè)進(jìn)程。
在Windows下,多線程的效率比多進(jìn)程要高,所以微軟的IIS服務(wù)器默認(rèn)采用多線程模式。由于多線程存在穩(wěn)定性的問(wèn)題,IIS的穩(wěn)定性就不如Apache。為了緩解這個(gè)問(wèn)題,IIS和Apache現(xiàn)在又有多進(jìn)程+多線程的混合模式,真是把問(wèn)題越搞越復(fù)雜。
3.2 線程切換
無(wú)論是多進(jìn)程還是多線程,只要數(shù)量一多,效率肯定上不去,為什么呢?
我們打個(gè)比方,假設(shè)學(xué)生正在準(zhǔn)備中考,每天晚上需要做語(yǔ)文、數(shù)學(xué)、英語(yǔ)、物理、化學(xué)這5科的作業(yè),每項(xiàng)作業(yè)耗時(shí)1小時(shí)。
如果先花1小時(shí)做語(yǔ)文作業(yè),做完了,再花1小時(shí)做數(shù)學(xué)作業(yè),這樣,依次全部做完,一共花5小時(shí),這種方式稱為單任務(wù)模型,或者批處理任務(wù)模型。
假設(shè)打算切換到多任務(wù)模型,可以先做1分鐘語(yǔ)文,再切換到數(shù)學(xué)作業(yè),做1分鐘,再切換到英語(yǔ),以此類推,只要切換速度足夠快,這種方式就和單核CPU執(zhí)行多任務(wù)是一樣的了,以幼兒園小朋友的眼光來(lái)看,就正在同時(shí)寫(xiě)5科作業(yè)。
但是,切換作業(yè)是有代價(jià)的,比如從語(yǔ)文切到數(shù)學(xué),要先收拾桌子上的語(yǔ)文書(shū)本、鋼筆(這叫保存現(xiàn)場(chǎng)),然后,打開(kāi)數(shù)學(xué)課本、找出圓規(guī)直尺(這叫準(zhǔn)備新環(huán)境),才能開(kāi)始做數(shù)學(xué)作業(yè)。操作系統(tǒng)在切換進(jìn)程或者線程時(shí)也是一樣的,它需要先保存當(dāng)前執(zhí)行的現(xiàn)場(chǎng)環(huán)境(CPU寄存器狀態(tài)、內(nèi)存頁(yè)等),然后,把新任務(wù)的執(zhí)行環(huán)境準(zhǔn)備好(恢復(fù)上次的寄存器狀態(tài),切換內(nèi)存頁(yè)等),才能開(kāi)始執(zhí)行。這個(gè)切換過(guò)程雖然很快,但是也需要耗費(fèi)時(shí)間。如果有幾千個(gè)任務(wù)同時(shí)進(jìn)行,操作系統(tǒng)可能就主要忙著切換任務(wù),根本沒(méi)有多少時(shí)間去執(zhí)行任務(wù)了,這種情況最常見(jiàn)的就是硬盤(pán)狂響,點(diǎn)窗口無(wú)反應(yīng),系統(tǒng)處于假死狀態(tài)。
所以,多任務(wù)一旦多到一個(gè)限度,就會(huì)消耗掉系統(tǒng)所有的資源,結(jié)果效率急劇下降,所有任務(wù)都做不好。
3.3 CPU密集型&IO密集型
是否采用多任務(wù)的第二個(gè)考慮是任務(wù)的類型。我們可以把任務(wù)分為CPU密集型和IO密集型
CPU密集型任務(wù)的特點(diǎn)是要進(jìn)行大量的計(jì)算,消耗CPU資源,比如計(jì)算圓周率、對(duì)視頻進(jìn)行高清解碼等等,全靠CPU的運(yùn)算能力。
這種計(jì)算密集型任務(wù)雖然也可以用多任務(wù)完成,但是任務(wù)越多,花在任務(wù)切換的時(shí)間就越多,CPU執(zhí)行任務(wù)的效率就越低,所以,要最高效地利用CPU,CPU密集型任務(wù)同時(shí)進(jìn)行的數(shù)量應(yīng)當(dāng)?shù)扔贑PU的核心數(shù)。
CPU密集型任務(wù)由于主要消耗CPU資源,因此,代碼運(yùn)行效率至關(guān)重要。Python這樣的腳本語(yǔ)言運(yùn)行效率很低,完全不適合CPU密集型任務(wù)。對(duì)于CPU密集型任務(wù),最好用C語(yǔ)言編寫(xiě)。
IO密集型,涉及到網(wǎng)絡(luò)、磁盤(pán)IO的任務(wù)都是IO密集型任務(wù),這類任務(wù)的特點(diǎn)是CPU消耗很少,任務(wù)的大部分時(shí)間都在等待IO操作完成(因?yàn)镮O的速度遠(yuǎn)遠(yuǎn)低于CPU和內(nèi)存的速度)。對(duì)于IO密集型任務(wù),任務(wù)越多,CPU效率越高,但也有一個(gè)限度。常見(jiàn)的大部分任務(wù)都是IO密集型任務(wù),比如Web應(yīng)用。
IO密集型任務(wù)執(zhí)行期間,99%的時(shí)間都花在IO上,花在CPU上的時(shí)間很少,因此,用運(yùn)行速度極快的C語(yǔ)言替換用Python這樣運(yùn)行速度極低的腳本語(yǔ)言,完全無(wú)法提升運(yùn)行效率。對(duì)于IO密集型任務(wù),最合適的語(yǔ)言就是開(kāi)發(fā)效率最高(代碼量最少)的語(yǔ)言,腳本語(yǔ)言是首選,C語(yǔ)言最差。
CPU密集型任務(wù)配置盡可能少的線程數(shù)量,如配置Ncpu+1個(gè)線程的線程池。IO密集型任務(wù)則由于需要等待IO操作,線程并不是一直在執(zhí)行任務(wù),則配置盡可能多的線程,如2*Ncpu
3.4 異步IO
考慮到CPU和IO之間巨大的速度差異,一個(gè)任務(wù)在執(zhí)行的過(guò)程中大部分時(shí)間都在等待IO操作,單進(jìn)程單線程模型會(huì)導(dǎo)致別的任務(wù)無(wú)法并行執(zhí)行,因此,我們才需要多進(jìn)程模型或者多線程模型來(lái)支持多任務(wù)并發(fā)執(zhí)行。
現(xiàn)代操作系統(tǒng)對(duì)IO操作已經(jīng)做了巨大的改進(jìn),最大的特點(diǎn)就是支持異步IO。如果充分利用操作系統(tǒng)提供的異步IO支持,就可以用單進(jìn)程單線程模型來(lái)執(zhí)行多任務(wù),這種全新的模型稱為事件驅(qū)動(dòng)模型,Nginx就是支持異步IO的Web服務(wù)器,它在單核CPU上采用單進(jìn)程模型就可以高效地支持多任務(wù)。在多核CPU上,可以運(yùn)行多個(gè)進(jìn)程(數(shù)量與CPU核心數(shù)相同),充分利用多核CPU。由于系統(tǒng)總的進(jìn)程數(shù)量十分有限,因此操作系統(tǒng)調(diào)度非常高效。用異步IO編程模型來(lái)實(shí)現(xiàn)多任務(wù)是一個(gè)主要的趨勢(shì)。
對(duì)應(yīng)到Python語(yǔ)言,單進(jìn)程的異步編程模型稱為協(xié)程,有了協(xié)程的支持,就可以基于事件驅(qū)動(dòng)編寫(xiě)高效的多任務(wù)程序。
鏈接:https://www.cnblogs.com/jingzh/p/18276352
-
cpu
+關(guān)注
關(guān)注
68文章
11031瀏覽量
215925 -
多線程
+關(guān)注
關(guān)注
0文章
279瀏覽量
20296 -
線程
+關(guān)注
關(guān)注
0文章
507瀏覽量
20068 -
多進(jìn)程
+關(guān)注
關(guān)注
0文章
14瀏覽量
2674
原文標(biāo)題:2 多進(jìn)程與多線程
文章出處:【微信號(hào):magedu-Linux,微信公眾號(hào):馬哥Linux運(yùn)維】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
Java多線程的用法
Python多線程編程運(yùn)行【python簡(jiǎn)單入門(mén)】
Python多線程編程原理
淺析Python使用多線程實(shí)現(xiàn)串口收發(fā)數(shù)據(jù)
python多線程和多進(jìn)程對(duì)比
python創(chuàng)建多線程的兩種方法
多線程好還是單線程好?單線程和多線程的區(qū)別 優(yōu)缺點(diǎn)分析
什么是多線程編程?多線程編程基礎(chǔ)知識(shí)
C#多線程技術(shù)
RT-Thread學(xué)習(xí)筆記 --(4)RT-Thread多線程學(xué)習(xí)過(guò)程總結(jié)

python創(chuàng)建多線程的兩種方法
Python多線程的使用
網(wǎng)絡(luò)工程師學(xué)Python-多線程技術(shù)簡(jiǎn)述
關(guān)于Python多進(jìn)程和多線程詳解
Python中多線程和多進(jìn)程的區(qū)別





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論