") 在多FPGA集群上實(shí)現(xiàn)高級(jí)并行編程
在多FPGA集群上實(shí)現(xiàn)高級(jí)并行編程

今天我們看的這篇論文介紹了在多FPGA集群上實(shí)現(xiàn)高級(jí)并行編程的研究,其主要目標(biāo)是為非FPGA專家提供一個(gè)成熟且易于使用的環(huán)境,以便在多個(gè)并行運(yùn)行的設(shè)備上擴(kuò)展高性能計(jì)算(HPC)應(yīng)用。
背景
該論文的研究背景集中在解決高性能計(jì)算(HPC)領(lǐng)域中利用現(xiàn)場(chǎng)可編程門陣列(FPGA)進(jìn)行并行計(jì)算的挑戰(zhàn)。由于FPGA在HPC領(lǐng)域相對(duì)新穎,尚未形成一個(gè)成熟的生態(tài)系統(tǒng),能夠方便非FPGA專家在多個(gè)FPGA設(shè)備上擴(kuò)展并行應(yīng)用程序。論文指出,盡管FPGA具備高性能計(jì)算潛力,但在實(shí)際應(yīng)用中,缺乏一種有效的方法讓非專業(yè)人士能夠輕松地利用FPGA的并行處理能力。
FPGA在HPC領(lǐng)域的新興地位:FPGA技術(shù)在HPC中尚未得到充分開(kāi)發(fā),尤其是在構(gòu)建大規(guī)模并行計(jì)算環(huán)境方面。
并行編程的復(fù)雜性:直接編程FPGA通常需要深入的硬件知識(shí),這對(duì)非FPGA工程師來(lái)說(shuō)是一個(gè)重大障礙。
缺乏成熟的工具和平臺(tái):與傳統(tǒng)的CPU或GPU相比,用于FPGA的編程工具和平臺(tái)不夠成熟,難以支持大規(guī)模的并行應(yīng)用開(kāi)發(fā)。
基于上述背景,論文旨在開(kāi)發(fā)一種更友好的編程模型和平臺(tái),使得非FPGA工程師也能利用FPGA的并行計(jì)算能力,特別是在多FPGA集群的環(huán)境下。這涉及到創(chuàng)建一個(gè)支持消息傳遞接口(MPI)風(fēng)格通信的軟件堆棧,以及一個(gè)能夠跨多臺(tái)FPGA設(shè)備進(jìn)行高效并行計(jì)算的編程環(huán)境。此外,論文還提到了評(píng)估這一新環(huán)境的性能和效率,特別是在與傳統(tǒng)超級(jí)計(jì)算機(jī)的比較中,特別是在能耗比方面。
FPGA design
論文中關(guān)于FPGA設(shè)計(jì)的部分描述了一個(gè)高度優(yōu)化的架構(gòu),旨在促進(jìn)高級(jí)并行編程在多FPGA集群上的實(shí)現(xiàn)。
設(shè)計(jì)組成:
用戶應(yīng)用:這部分包含High-Level Synthesis (HLS) 加速器和運(yùn)行時(shí),它們與FPGA的High Bandwidth Memory (HBM) 和以太網(wǎng)開(kāi)關(guān)接口進(jìn)行交互。
以太網(wǎng)子系統(tǒng):這個(gè)子系統(tǒng)負(fù)責(zé)處理以太網(wǎng)頭信息和尋址系統(tǒng),為應(yīng)用程序提供一個(gè)簡(jiǎn)單的流式接口,用于發(fā)送和接收網(wǎng)絡(luò)消息。
用戶應(yīng)用與內(nèi)存互聯(lián):
設(shè)計(jì)中包括POM運(yùn)行時(shí)(Pico OmpSs Manager),HLS加速器,以及與內(nèi)存的互聯(lián)機(jī)制。
OMPIF運(yùn)行時(shí)被添加到設(shè)計(jì)中,它連接到以太網(wǎng)接口,允許消息發(fā)送者接收來(lái)自POM的任務(wù),并處理用戶傳遞的參數(shù)。
通信架構(gòu):
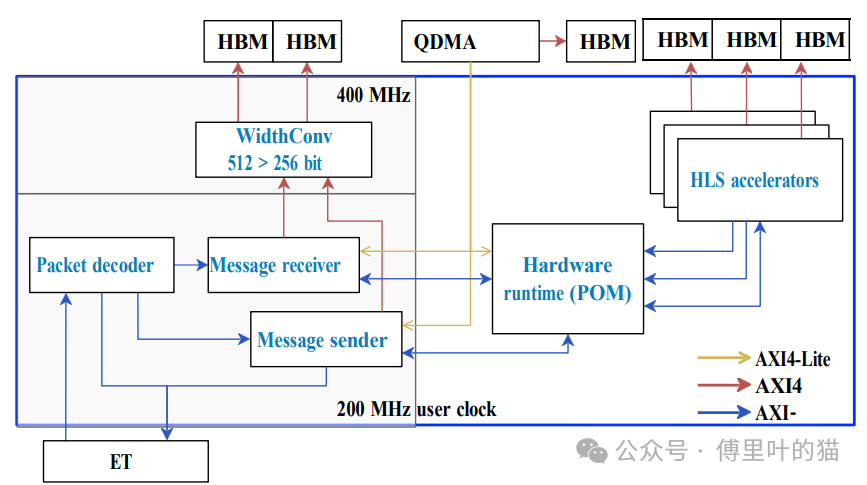
每個(gè)FPGA有兩個(gè)QSFP28端口,其中一個(gè)連接到以太網(wǎng)交換機(jī),另一個(gè)連接到鄰近的FPGA,但設(shè)計(jì)依賴于與交換機(jī)相連的端口,以實(shí)現(xiàn)整個(gè)集群的完全連通性。
自動(dòng)化設(shè)計(jì)生成:
FPGA設(shè)計(jì)和架構(gòu)可以自動(dòng)由Accelerator Integrator Tool (AIT)生成,該工具只需用戶HLS代碼作為輸入。
AIT是OmpSs@FPGA框架的一部分,框架還包括Xtasks庫(kù)和Nanos6運(yùn)行時(shí),用于處理FPGA設(shè)置、管理和通信。
以太網(wǎng)接口的抽象層:
為了使用以太網(wǎng)接口,設(shè)計(jì)中加入了一個(gè)抽象層,它簡(jiǎn)化了網(wǎng)絡(luò)消息的發(fā)送和接收,使應(yīng)用程序無(wú)需關(guān)心底層以太網(wǎng)協(xié)議細(xì)節(jié)。
HBM使用:
FPGA設(shè)計(jì)充分利用HBM,這是現(xiàn)代FPGA提供的一種高速存儲(chǔ)解決方案,可以顯著提高數(shù)據(jù)吞吐量和訪問(wèn)速度。
硬件與軟件協(xié)同:
硬件設(shè)計(jì)與軟件棧緊密配合,使得用戶可以專注于編寫基于任務(wù)和消息傳遞的高級(jí)并行代碼,而低級(jí)別的細(xì)節(jié)(如以太網(wǎng)、PCIe和JTAG管理)則對(duì)程序員透明。
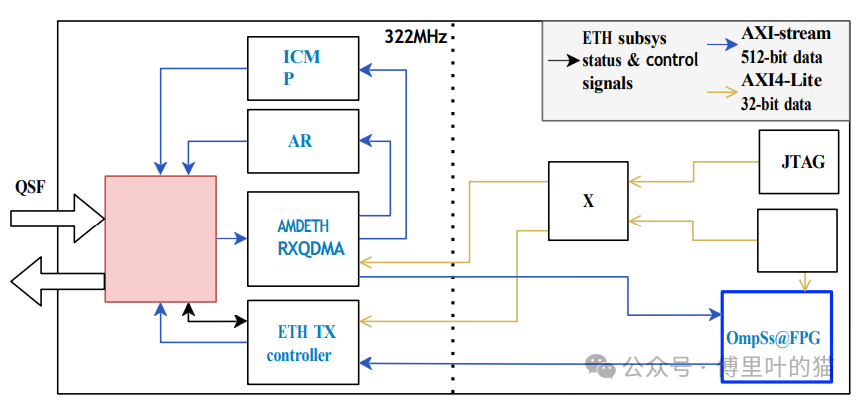
SOFTWARE STACK
論文中描述的軟件堆棧是為了使多FPGA集群的管理與使用更加高效和便捷,特別是對(duì)于那些基于高級(jí)并行編程模型的應(yīng)用程序。
Xtasks遠(yuǎn)程支持:
Xtasks庫(kù)是OmpSs@FPGA框架的一部分,用于卸載任務(wù)到FPGA加速器,并在FPGA和主機(jī)內(nèi)存之間復(fù)制數(shù)據(jù)。
新增了對(duì)遠(yuǎn)程FPGA節(jié)點(diǎn)的支持,這通過(guò)Xtasks遠(yuǎn)程實(shí)現(xiàn),它能描述集群中所有FPGA節(jié)點(diǎn),無(wú)論本地還是遠(yuǎn)程,以及一個(gè)名為Xtasks服務(wù)器的應(yīng)用程序。
這種改進(jìn)使得從單個(gè)CPU服務(wù)器可以管理整個(gè)FPGA集群,無(wú)論是通過(guò)本地PCIe還是通過(guò)網(wǎng)絡(luò)。
Nanos6運(yùn)行時(shí):
Nanos6運(yùn)行時(shí)用于分析任務(wù)依賴性和調(diào)度可并行執(zhí)行的任務(wù),它是OmpSs-2任務(wù)基礎(chǔ)編程模型的核心。
在FPGA上下文中,Nanos6運(yùn)行時(shí)通過(guò)Xtasks庫(kù)管理FPGA的設(shè)置、任務(wù)調(diào)度和通信。
OMPIF集成:
OMPIF(Open MPI over FPGA)是一種通信協(xié)議,允許類似MPI(Message Passing Interface)的通信模式在FPGA上運(yùn)行。
這一集成使得C/C++代碼能夠在FPGA上運(yùn)行,并且能夠調(diào)用類似于MPI_Send/Recv的功能,通過(guò)MEEP集群的100Gb以太網(wǎng)網(wǎng)絡(luò)進(jìn)行消息傳遞。
MEEP Manager:
提供了一個(gè)統(tǒng)一的界面來(lái)管理FPGA集群,包括加載位流、配置設(shè)備和傳輸數(shù)據(jù)到遠(yuǎn)程CPU節(jié)點(diǎn)所托管的FPGAs。
自動(dòng)化工具:
Accelerator Integrator Tool (AIT)用于自動(dòng)生成FPGA設(shè)計(jì)和架構(gòu),只需要用戶提供的HLS代碼作為輸入。
整體而言,軟件堆棧提供了一套完整的解決方案,使得非FPGA工程師也能夠利用多FPGA集群來(lái)擴(kuò)展他們的應(yīng)用,同時(shí)避免了與低級(jí)別硬件交互相關(guān)的復(fù)雜性。通過(guò)這一堆棧,程序員可以專注于編寫基于任務(wù)和消息傳遞的高級(jí)并行代碼,而無(wú)需擔(dān)心底層的以太網(wǎng)、PCIe或JTAG管理等技術(shù)細(xì)節(jié)。此外,堆棧還提供了對(duì)遠(yuǎn)程FPGA節(jié)點(diǎn)的管理能力,從而增強(qiáng)了集群的靈活性和可擴(kuò)展性。
EVALUATION
在論文的評(píng)估(Evaluation)部分,作者們展示了他們構(gòu)建的多FPGA集群——Marenostrum Exascale Emulation Platform (MEEP)的性能,特別是在高帶寬通信和高性能計(jì)算(HPC)應(yīng)用方面。
帶寬測(cè)量:
使用OMPIF (Open MPI over FPGA)在兩個(gè)FPGA之間測(cè)得的帶寬最高可達(dá)約4.5GB/s,當(dāng)數(shù)據(jù)量約為100MB時(shí)。
主機(jī)到FPGA以及反向的通信,包括本地(僅PCIe)和遠(yuǎn)程(PCIe+網(wǎng)絡(luò))的組合,顯示了不同的帶寬特性。在遠(yuǎn)程情況下,由于數(shù)據(jù)需要通過(guò)網(wǎng)絡(luò)傳輸,因此帶寬會(huì)受到顯著影響。
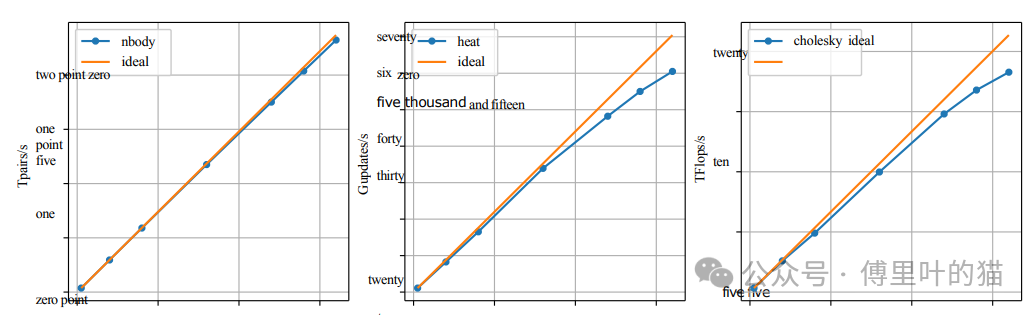
性能評(píng)估:
對(duì)三個(gè)基準(zhǔn)測(cè)試進(jìn)行了評(píng)估:N-body模擬、Heat擴(kuò)散模擬(使用Gauss-Seidel求解器)和Cholesky分解。
N-body基準(zhǔn)測(cè)試使用了4194304個(gè)粒子和16個(gè)步驟,在64個(gè)FPGA上的表現(xiàn)接近理想,效率達(dá)到98%,達(dá)到每秒2.3G對(duì)力的計(jì)算。
Heat基準(zhǔn)測(cè)試展示了熱傳導(dǎo)在二維矩陣上的模擬,使用Gauss-Seidel方法計(jì)算每個(gè)位置的平均值。結(jié)果顯示,該應(yīng)用能夠有效利用FPGA資源,處理大量的依賴關(guān)系。
與HPC的比較:
將MEEP集群的性能與MareNostrum 4超級(jí)計(jì)算機(jī)進(jìn)行了對(duì)比,發(fā)現(xiàn)在N-body和Heat基準(zhǔn)測(cè)試中,MEEP的性能功耗比分別提高了2.3倍和3.5倍。
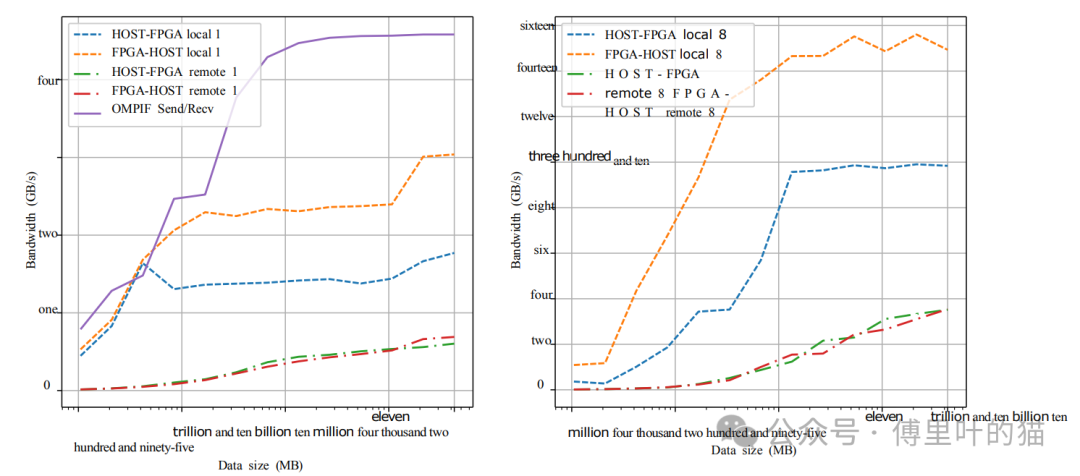
這些結(jié)果表明,MEEP集群在處理大規(guī)模并行計(jì)算任務(wù)時(shí)具有顯著的優(yōu)勢(shì),尤其是在功耗效率方面。同時(shí),該評(píng)估證明了使用OMPIF和100Gb以太網(wǎng)網(wǎng)絡(luò)在FPGA集群間實(shí)現(xiàn)高速通信的可行性。通過(guò)使用先進(jìn)的硬件和優(yōu)化的軟件堆棧,研究人員能夠展示出FPGA集群在HPC領(lǐng)域的潛力,尤其是在要求高性能和高效率的應(yīng)用場(chǎng)景中。
-
FPGA
+關(guān)注
關(guān)注
1645文章
22046瀏覽量
618300 -
gpu
+關(guān)注
關(guān)注
28文章
4944瀏覽量
131220 -
編程
+關(guān)注
關(guān)注
88文章
3689瀏覽量
95242 -
HPC
+關(guān)注
關(guān)注
0文章
333瀏覽量
24326
原文標(biāo)題:多FPGA集群上的High-Level并行編程
文章出處:【微信號(hào):傅里葉的貓,微信公眾號(hào):傅里葉的貓】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
FPGA的并行多通道激勵(lì)信號(hào)產(chǎn)生模塊
基于FPGA控制的多DSP并行處理系統(tǒng)
怎么實(shí)現(xiàn)以FPGA為核心器件的并行多通道信號(hào)產(chǎn)生模塊?
基于SMP集群的混合并行編程模型研究
MPI并行程序設(shè)計(jì)的負(fù)載平衡實(shí)現(xiàn)方法
并行CRC在FPGA上的實(shí)現(xiàn)研究
在FPGA上實(shí)現(xiàn)CRC算法的程序
如何在工程應(yīng)用中合理采用并行編程技術(shù)

如何使用OpenCL輕松實(shí)現(xiàn)FPGA應(yīng)用編程
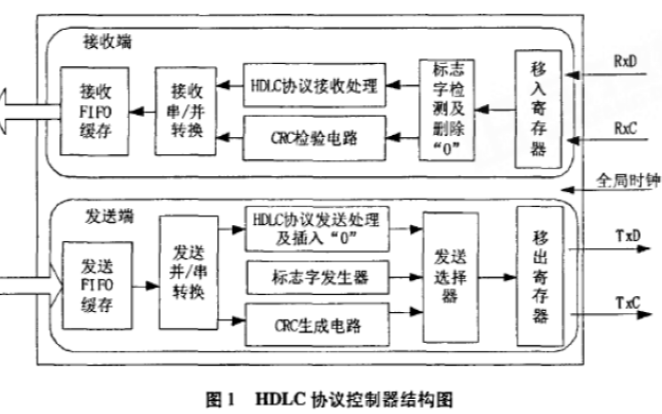
如何使用FPGA實(shí)現(xiàn)HDLC協(xié)議控制器
基于FPGA集群的NEST脈沖神經(jīng)網(wǎng)絡(luò)仿真器
多通道可編程并行通信接口芯片XDC05的設(shè)計(jì)實(shí)現(xiàn)

怎么用FPGA做算法 如何在FPGA上實(shí)現(xiàn)最大公約數(shù)算法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論