") 聊一聊Transformer中的FFN
聊一聊Transformer中的FFN
作者:潘梓正,莫納什大學(xué)博士生
最近看到有些問題[1]說為什么Transformer中的FFN一直沒有大的改動(dòng)。21年剛?cè)雽W(xué)做ViT的時(shí)候就想這個(gè)問題,現(xiàn)在讀博生涯也快結(jié)束了,剛好看到這個(gè)問題,打算稍微寫寫, 也算是對(duì)這個(gè)地方做一個(gè)小總結(jié)吧。
1. Transformer與FFN
Transformer的基本單位就是一層block這里,一個(gè)block包含 MSA + FFN,目前公認(rèn)的說法是,
?Attention作為token-mixer做spatial interaction。
?FFN(又稱MLP)在后面作為channel-mixer進(jìn)一步增強(qiáng)representation。
從2017至今,過去絕大部分Transformer優(yōu)化,尤其是針對(duì)NLP tasks的Efficient Transformer都是在Attention上的,因?yàn)槲谋居酗@著的long sequence問題。安利一個(gè)很好的總結(jié)Efficient Transformers: A Survey [2], 來自大佬Yi Tay[3]。到了ViT上又有一堆a(bǔ)ttention[4]改進(jìn),這個(gè)repo一直在更新,總結(jié)的有點(diǎn)多,可以當(dāng)輔助資料查閱。
而FFN這里,自從Transformer提出基本就是一個(gè) Linear Proj + Activation + Linear Proj的結(jié)構(gòu),整體改動(dòng)十分incremental。
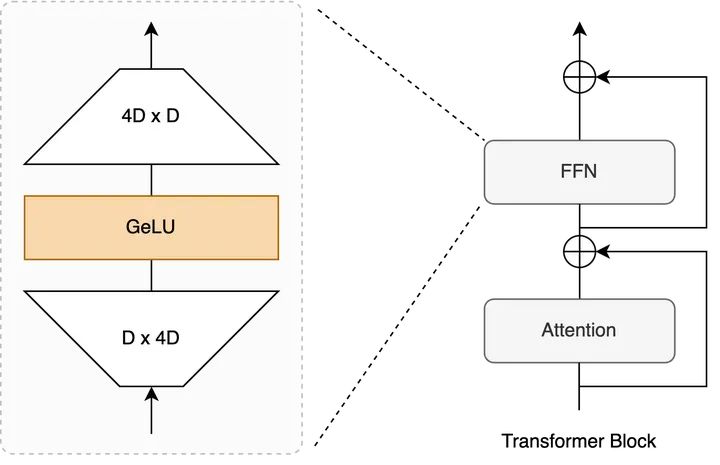
Transformer Block示意圖 + FFN內(nèi)部
2. Activation Function
經(jīng)歷了ReLU, GeLU,Swish, SwiGLU等等,基本都是empirical observations,但都是為了給representation加上非線性變換做增強(qiáng)。
?ReLU對(duì)pruning挺有幫助,尤其是過去對(duì)CNN做pruning的工作,激活值為0大致意味著某個(gè)channel不重要,可以去掉。相關(guān)工作可查這個(gè)repo[5]。即便如此,ReLU造成dead neurons,因此在Transformer上逐漸被拋棄。
?GeLU在過去一段時(shí)間占比相當(dāng)大,直到現(xiàn)在ViT上使用十分廣泛,當(dāng)然也有用Swish的,如MobileViT[6]。
?Gated Linear Units目前在LLM上非常流行,其效果和分析來源于GLU Variants Improve Transformer[7]。如PaLM和LLaMA都采用了SwiGLU, 谷歌的Gemma使用GeGLU。
不過,從個(gè)人經(jīng)驗(yàn)上來看(偏CV),改變FFN中間的activation function,基本不會(huì)有極大的性能差距,總體的性能提升會(huì)顯得incremental。NLP上估計(jì)會(huì)幫助reduce overfitting, improve generalization,但是與其花時(shí)間改這個(gè)地方不如好好clean data。。。目前來說
3. Linear Projections
說白了就是一個(gè)matrix multiplication, 已經(jīng)幾乎是GPU上的大部分人改model的時(shí)候遇到的最小基本單位。dense matrix multiplication的加速很難,目前基本靠GPU更新迭代。
不過有一個(gè)例外:小矩陣乘法可以結(jié)合軟硬件同時(shí)加速,比如instant-ngp的tiny cuda nn, 64 x 64這種級(jí)別的matrix multiplication可以使得網(wǎng)絡(luò)權(quán)重直接放到register, 激活值放到shared memory, 這樣運(yùn)算極快。
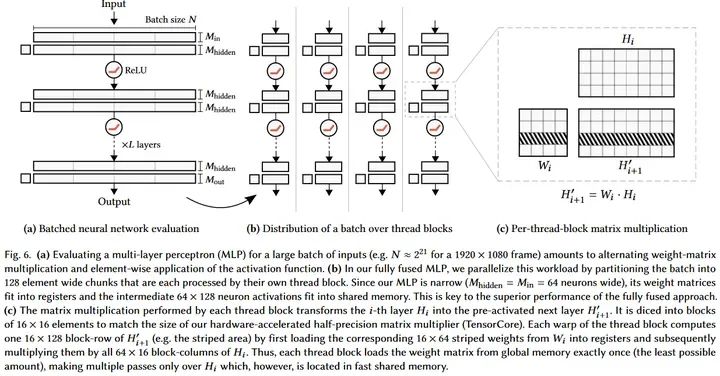
Source: https://github.com/nvlabs/tiny-cuda-nn
但是這對(duì)今天的LLM和ViT來講不現(xiàn)實(shí),最小的ViT-Tiny中,F(xiàn)FN也是個(gè)192 x (4 x 192)這種級(jí)別,更不用說LLM這種能> 10000的。
那為什么Linear Projection在Transformer里就需要這么大?
常見的說法是Knowledge Neurons。tokens在前一層attention做global interaction之后,通過FFN的參數(shù)中存放著大量training過程中學(xué)習(xí)到的比較抽象的knowledge來進(jìn)一步update。目前有些studies是說明這件事的,如
?Transformer Feed-Forward Layers Are Key-Value Memories[8]
?Knowledge Neurons in Pretrained Transformers[9]
?...
問題來了,如果FFN存儲(chǔ)著Transformer的knowledge,那么注定了這個(gè)地方不好做壓縮加速:
?FFN變小意味著model capacity也變小,大概率會(huì)讓整體performance變得很差。我自己也有過一些ViT上的實(shí)驗(yàn) (相信其他人也做過),兩個(gè)FC中間會(huì)有個(gè)hidden dimension的expansion ratio,一般設(shè)置為4。把這個(gè)地方調(diào)小會(huì)發(fā)現(xiàn)怎么都不如大點(diǎn)好。當(dāng)然太大也不行,因?yàn)镕FN這里的expansion ratio決定了整個(gè)Transformer 在推理時(shí)的peak memory consumption,有可能造成out-of-memory (OOM) error,所以大部分我們看到的expansion ration也就在4倍,一個(gè)比較合適的performance-memory trade-off.
?FFN中的activations非低秩。過去convnet上大家又發(fā)現(xiàn)activations有明顯的低秩特性,所以可以通過low rank做加速,如Kaiming的這篇文章[10],如下圖所示。但是FFN中間的outputs很難看出低秩的特性,實(shí)際做網(wǎng)絡(luò)壓縮的時(shí)候會(huì)發(fā)現(xiàn)pruning FFN的trade-off明顯不如convnets,而unstructured pruning又對(duì)硬件不友好。
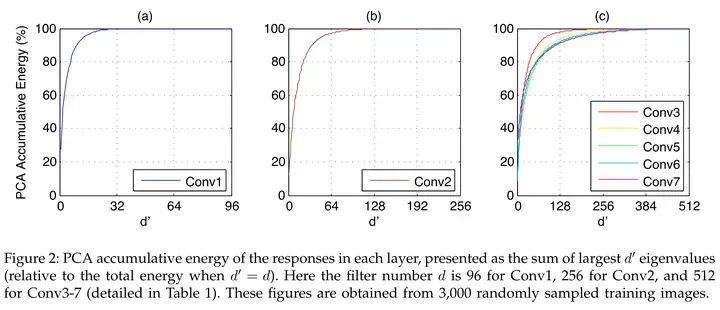
Source: Zhang et.al, Accelerating Very Deep Convolutional Networks for Classification and Detection
4. 所以FFN真的改不動(dòng)了嗎?
當(dāng)然不是。
我們想改動(dòng)一個(gè)model or module的時(shí)候,無非是兩個(gè)動(dòng)機(jī):1)Performance。2)Efficiency。
性能上,目前在NLP上可以做Gated MLP[11], 如Mamba[12]的block中,或者DeepMind的新結(jié)構(gòu)Griffin[13]。
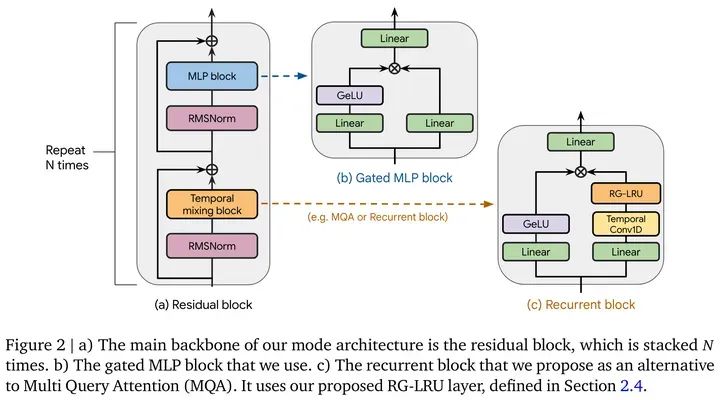
Source: Griffin: Mixing Gated Linear Recurrences with Local Attention for Efficient Language Models
但是難說這個(gè)地方的性能提升是不是來自于更多的參數(shù)量和模型復(fù)雜度。
在CV上,有個(gè)心照不宣的trick,那就是加depthwise convolution引入locality,試過的朋友都知道這個(gè)地方的提升在CV任務(wù)上有多明顯,例如CIFAR100上,DeiT-Ti可以漲接近10個(gè)點(diǎn)這樣子。。。
但是呢,鑒于最原始的FFN依然是目前采用最廣泛的,并且conv引入了inductive bias,破壞了原先permutation invariant的sequence(因?yàn)榫矸e要求規(guī)整的shape,width x height)。大規(guī)模ViT訓(xùn)練依然沒有采用depthwise conv,如CLIP, DINOv2, SAM, etc。
效率上,目前最promising是改成 **Mixture-of-Expert (MoE)**,但其實(shí)。。。GPT4和Mixtral 8x7B沒出來之前基本是Google在solo,沒人關(guān)注。當(dāng)然現(xiàn)在時(shí)代變了,Mixtral 8x7B讓MoE起死回生。最近這個(gè)地方的paper相當(dāng)多,簡單列幾個(gè)自己感興趣的:
?Soft MoE: From Sparse to Soft Mixtures of Experts[14]
?LoRA MoE: Alleviate World Knowledge Forgetting in Large Language Models via MoE-Style Plugin[15]
?DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models[16]
5. 達(dá)到AGI需要什么結(jié)構(gòu)?
目前這個(gè)階段,沒人知道一周以后會(huì)有什么大新聞,就像Sora悄無聲息放出來,一夜之間干掉U-Net,我也沒法說什么結(jié)構(gòu)是最有效的。
總體上,目前沒有任何結(jié)構(gòu)能真的完全beat Transformer,Mamba 目前 也不行,如這篇[17]發(fā)現(xiàn) copy and paste不太行,scaling和in-context能力也有待查看。
考慮到未來擴(kuò)展,優(yōu)秀的結(jié)構(gòu)應(yīng)該滿足這么幾個(gè)東西,個(gè)人按重要性排序:
?Scaling Law。如果model很難通過scale up提升性能,意義不大(針對(duì)AGI來講)。但是建議大家不要針對(duì)這個(gè)地方過度攻擊學(xué)術(shù)界paper,學(xué)術(shù)界很難有資源進(jìn)行這種實(shí)驗(yàn),路都是一步一步踩出來的,提出一個(gè)新architecture需要勇氣和信心,給一些寬容。嗯,說的就是Mamba。
?In-Context Learning能力。這個(gè)能力需要強(qiáng)大的retrieval能力和足夠的capacity,而對(duì)于Transformer來講,retrieval靠Attention,capacity靠FFN。scaling帶來的是兩者協(xié)同提升,進(jìn)而涌現(xiàn)強(qiáng)大的in-context learning能力。
?Better Efficiency。說到底這也是為什么我們想換掉Transformer。做過的朋友都知道Transformer訓(xùn)練太耗卡了,無論是NLP還是CV上。部署的時(shí)候又不像CNN可以做bn conv融合,inference memory大,low-bit quantization效果上也不如CNN,大概率是attention這個(gè)地方low-bit損失大。在滿足1,2的情況下,如果一個(gè)新結(jié)構(gòu)能在speed, memory上展現(xiàn)出優(yōu)勢那非常有潛力。Mamba能火有很大一部分原因是引入hardware-aware的實(shí)現(xiàn),極大提升了原先SSM的計(jì)算效率。
?Life-long learning。知識(shí)是不斷更新的,訓(xùn)練一個(gè)LLM需要海量tokens,強(qiáng)如OpenAI也不可能每次Common Crawl[18]放出新data就從頭訓(xùn)一遍,目前比較實(shí)際的方案是持續(xù)訓(xùn)練,但依然很耗資源。未來的結(jié)構(gòu)需要更高效且持久地學(xué)習(xí)新知識(shí)。
Hallucination問題我反倒覺得不是大問題,畢竟人也有幻覺,比如對(duì)于不知道的,或自以為是的東西很自信的胡說一通,強(qiáng)推Hinton懟Gary Marcus這個(gè)視頻[19]。我現(xiàn)在寫的東西再過幾年回來看,說不定也是個(gè)Hallucination。。。
總結(jié): FFN因?yàn)榻Y(jié)構(gòu)最簡單但是最有效,被大家沿用至今。相比之下,Transformer改進(jìn)的大部分精力都在Attention這個(gè)更明顯的bottleneck上,有機(jī)會(huì)再寫個(gè)文章聊一聊這里。
審核編輯:黃飛
-
gpu
+關(guān)注
關(guān)注
28文章
4908瀏覽量
130620 -
Transformer
+關(guān)注
關(guān)注
0文章
148瀏覽量
6382 -
nlp
+關(guān)注
關(guān)注
1文章
490瀏覽量
22469
原文標(biāo)題:聊一聊Transformer中的FFN
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評(píng)論請先 登錄
從焊接角度聊一聊,設(shè)計(jì)PCB的5個(gè)建議

聊一聊消息隊(duì)列技術(shù)選型的7種消息場景
來聊一聊Altium中Fill,Polygon Pour,Plane的區(qū)別和用法
聊一聊stm32的低功耗調(diào)試
聊一聊7系列FPGA的供電部分
聊一聊平衡小車代碼的實(shí)現(xiàn)
聊一聊FPGA的片內(nèi)資源相關(guān)知識(shí)
聊一聊IIC總線設(shè)計(jì)
小米米聊2月19日停止服務(wù) 米聊宣布關(guān)閉服務(wù)器
米聊復(fù)活了 能維持多久?
聊一聊FPGA中的彩色轉(zhuǎn)灰度的算法
【職場雜談】與嵌入式物聯(lián)網(wǎng)架構(gòu)師聊一聊幾個(gè)話題

聊一聊華為云彈性公網(wǎng)IP的那些事兒





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論