") 探索ICLR‘24 Spotlight中的首個十億級別3D通用大模型
探索ICLR‘24 Spotlight中的首個十億級別3D通用大模型
智源視覺團隊近期的工作:3D視覺大模型Uni3D在ICLR 2024的評審中獲得了688分,被選為Spotlight Presentation。在本文中,作者第一次將3D基礎(chǔ)模型成功scale up到了十億(1B)級別參數(shù)量,并使用一個模型在諸多3D下游應(yīng)用中取得SOTA結(jié)果。代碼和各個scale的模型(從6M-1B)均已開源:
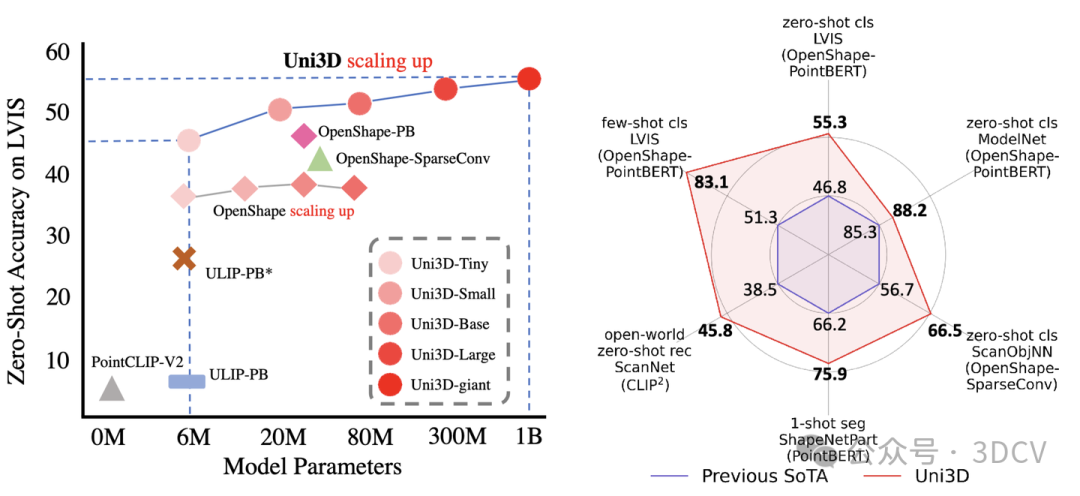
作者主要探索了3D視覺中scale up模型參數(shù)量和統(tǒng)一模型架構(gòu)的可能性。在NLP / 2D vision領(lǐng)域,scale up大模型(GPT-4,SAM,EVA等)已經(jīng)取得了很impressive的結(jié)果,但是在3D視覺中模型的scale up始終沒有成功。Uni3D旨在將NLP/2D中scale up的成功復(fù)現(xiàn)到3D表征模型上。
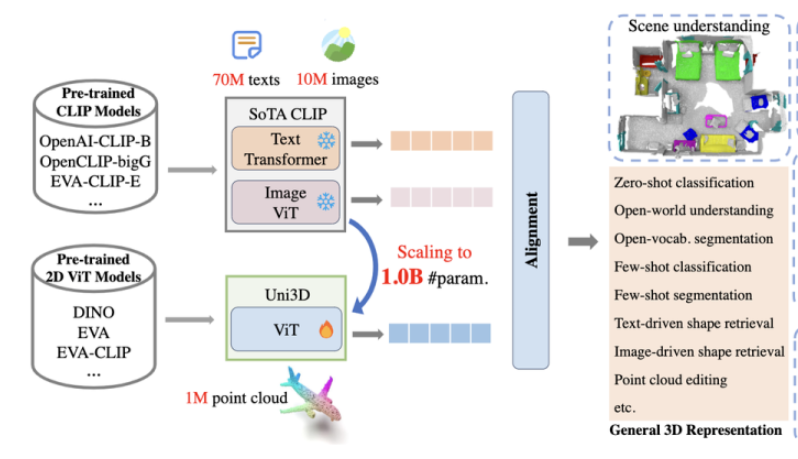
在這項工作中,作者提出了一個3D基礎(chǔ)大模型Uni3D,直接將3D backbone統(tǒng)一為ViT(Vision Transformer),以此利用豐富和強大的2D預(yù)訓(xùn)練大模型作為初始化。Uni3D使用CLIP模型中的文本/圖像表征作為訓(xùn)練目標(biāo),通過學(xué)習(xí)三個模態(tài)的表征對齊(點云-圖像-文本)實現(xiàn)3D點云對圖像和文本的感知。同時,通過使用ViT中成功的scale up策略,我們將Uni3D逐步 scale up,訓(xùn)練了從Tiny到giant的5個不同scale的Uni3D模型,成功地將Uni3D擴展到10億級別參數(shù)。
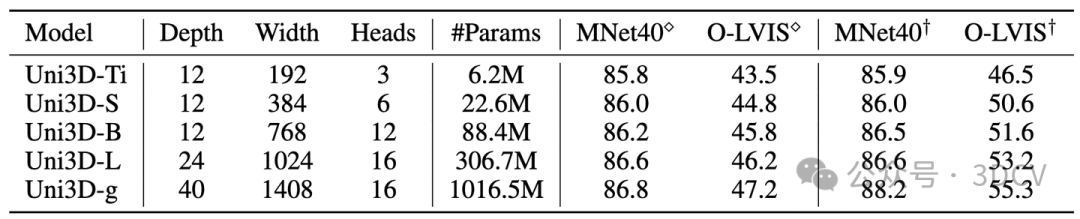
下游應(yīng)用:
Uni3D在多個3D任務(wù)上達到SoTA,如:zero-shot classification, few-shot classification,open-world understanding, open-world part segmentation.
零樣本/少樣本分類
Uni3D在ModelNet上實現(xiàn)了88.2%的零樣本分類準(zhǔn)確率,甚至接近了有監(jiān)督學(xué)習(xí)方法的結(jié)果(如PointNet 89.2 %);
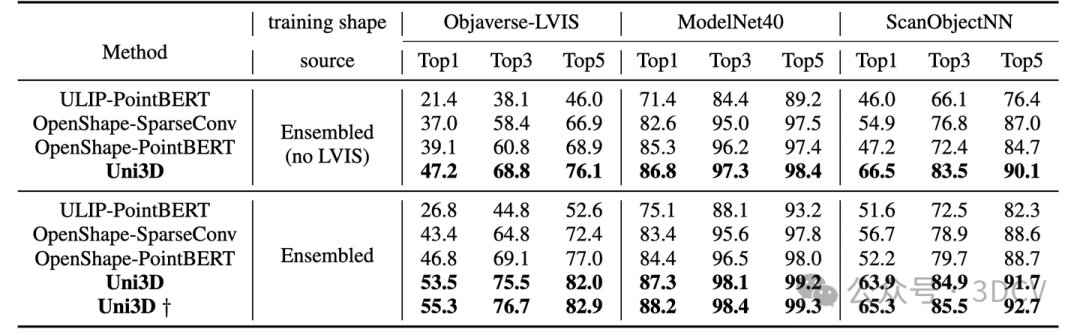
在最困難的Objaverse-LVIS基準(zhǔn)下,Uni3D取得了55.3%的零樣本分類準(zhǔn)確率,大幅刷新了該榜單。
而在Objaverse-LVIS基準(zhǔn)的少樣本分類測試中,Uni3D實現(xiàn)了83.1%的準(zhǔn)確率(16樣本下),明顯超過了以往的最先進基準(zhǔn)OpenShape 32%。
開放世界的理解能力
研究團隊采用與CLIP2相同的設(shè)置在ScanNet測試集下探究Uni3D在現(xiàn)實場景下的零樣本識別性能。與之前最先進的SOTA方法PointCLIP、PointCLIP V2 、CLIP2Point 和CLIP2 相比,Uni3D表現(xiàn)最佳。

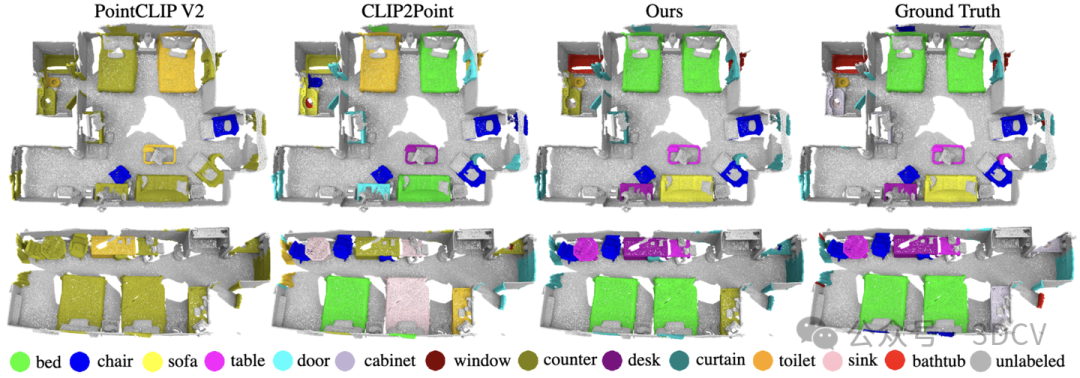
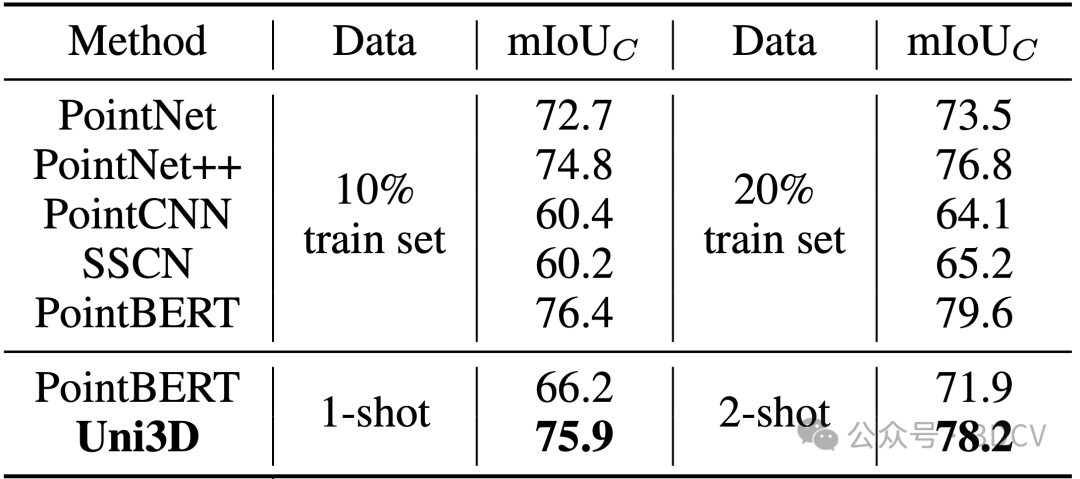
Uni3D在少樣本點云部件分割任務(wù)上也展示出了卓越的性能。下表結(jié)果顯示,在各種實驗條件下,Uni3D的性能都明顯優(yōu)于Point-BERT等基線方法。即便只使用每類一個樣本訓(xùn)練,Uni3D也達到了使用10%的訓(xùn)練數(shù)據(jù)的先前基線方法(如PointNet++,Point-BERT)的水平,在訓(xùn)練集的規(guī)模相對減少兩個數(shù)量級的情況下,仍能顯示出Uni3D更強的細粒度3D結(jié)構(gòu)理解能力。
由于學(xué)到了強大的多模態(tài)表征能力,Uni3D還能夠做一些有意思的應(yīng)用,如point cloud painting(點云繪畫),text/image-based 3D shape retrieval(基于圖像/文本的3D模型檢索),point cloud captioning(點云描述):
點云繪畫:體現(xiàn)了在3D AIGC上的潛在能力
給定一個文本,Uni3D通過優(yōu)化點云的顏色來提高點云和文本在特征空間的相似度,基于此實現(xiàn)文本操控的點云內(nèi)容創(chuàng)作和點云繪畫。

文本驅(qū)動/圖像驅(qū)動的三維形狀檢索:體現(xiàn)在構(gòu)建多模態(tài)檢索庫上的潛在能力
Uni3D通過學(xué)習(xí)到的統(tǒng)一的三維多模態(tài)表示,具有感知多個2D/語言信號的能力,可以通過圖像或文本輸入從大型3D數(shù)據(jù)集中檢索三維形狀。這是通過計算查詢圖像/文本提示的embedding與3D形狀的embedding入之間的余弦相似度來實現(xiàn)了對查詢的最相似3D形狀的獲取。
Uni3D 還可根據(jù)輸入文本來檢索 3D 形狀
將之前已經(jīng)成熟的“文搜圖/圖搜圖”擴展到“文搜3D/圖搜3D”,這使得檢索互聯(lián)網(wǎng)上大規(guī)模未標(biāo)定的繁雜三維模型成為可能,為相關(guān)三維領(lǐng)域從業(yè)者、創(chuàng)作者搜集素材提供實用工具。
Uni3D 還可給定點云生成對應(yīng)的文本描述
Uni3D擴展為Text-to-3D generation tasks的評測指標(biāo)
在text-to-3D研究領(lǐng)域,目前量化度量仍然是一個較難的問題。目前的量化指標(biāo)都是將生成的3D模型渲染為2D圖片,利用2D指標(biāo)衡量生成質(zhì)量。然而由于渲染角度互相獨立以及3D模型自遮擋等問題,2D評價指標(biāo)難以完全真實反映出3D生成模型的真實能力。如下圖,生成的3D模型有明顯的3D不一致性問題,但是單獨看其中大部分的視角渲染圖片都是正常的物體,導(dǎo)致2D評價指標(biāo)往往難以反映生成3D模型的不一致問題。
作者團隊近期推出的Text-to-3D generation 工作GeoDream提出利用目前最大最強的3D基礎(chǔ)模型Uni3D,直接對3D模型進行評估,避免渲染帶來的視角問題。相應(yīng)的評價指標(biāo)代碼也開源到GeoDream的代碼庫中 (https://github.com/baaivision/GeoDream) 。
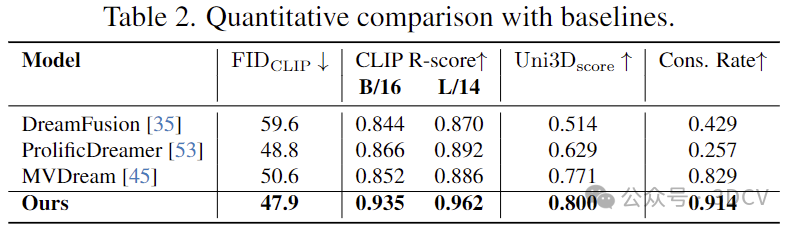
量化比較:在生成質(zhì)量和語義保持性的量化測試上,GeoDream相比于之前方法取得顯著提升。在基于渲染2D圖片的量化指標(biāo)(FID,CLIP-Score)和直接在3D空間度量生成的3D資產(chǎn)量化指標(biāo)(Uni3D-Score)上均有提升,說明GeoDream渲染的圖片和3D結(jié)構(gòu)均有優(yōu)勢。
審核編輯:黃飛
-
3D視覺
+關(guān)注
關(guān)注
4文章
446瀏覽量
28001 -
大模型
+關(guān)注
關(guān)注
2文章
2973瀏覽量
3730
原文標(biāo)題:ICLR‘24 Spotlight 首個十億級別3D通用大模型
文章出處:【微信號:3D視覺工坊,微信公眾號:3D視覺工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
ad19中3d模型不顯示?
LABVIEW如何驅(qū)動3D模型
Labview中如何導(dǎo)入3D 的模型
浩辰3D軟件中如何創(chuàng)建槽特征?3D模型設(shè)計教程!
浩辰3D軟件入門教程:如何比較3D模型
AD的3D模型繪制功能介紹
3D設(shè)計軟件中怎么創(chuàng)建風(fēng)扇葉模型?浩辰3D基礎(chǔ)教程
關(guān)于 AD 中如何創(chuàng)建 3D 模型及設(shè)計教程 Ver1.0
高分工作!Uni3D:3D基礎(chǔ)大模型,刷新多個SOTA!

- 設(shè)計技術(shù)
- 可編程邏輯
- 電源/新能源
- MEMS/傳感技術(shù)
- 測量儀表
- 嵌入式技術(shù)
- 制造/封裝
- 模擬技術(shù)
- RF/無線
- 接口/總線/驅(qū)動
- 處理器/DSP
- EDA/IC設(shè)計
- 存儲技術(shù)
- 光電顯示
- EMC/EMI設(shè)計
- 連接器
- 行業(yè)應(yīng)用
- LEDs
- 汽車電子
- 音視頻及家電
- 通信網(wǎng)絡(luò)
- 醫(yī)療電子
- 人工智能
- 虛擬現(xiàn)實
- 可穿戴設(shè)備
- 機器人
- 安全設(shè)備/系統(tǒng)
- 軍用/航空電子
- 移動通信
- 工業(yè)控制
- 便攜設(shè)備
- 觸控感測
- 物聯(lián)網(wǎng)
- 智能電網(wǎng)
- 區(qū)塊鏈
- 新科技
- 特色內(nèi)容
- 專欄推薦
- 學(xué)院
- 設(shè)計資源
- 設(shè)計技術(shù)
- 電子百科
- 電子視頻
- 元器件知識
- 工具箱
- VIP會員
- 最新技術(shù)文章
- 產(chǎn)品地圖
- 品牌地圖
- 供應(yīng)鏈服務(wù)
- 硬件開發(fā)
- 華秋電路
- 華秋商城
- 華秋智造
- nextPCB
- BOM配單
- 媒體服務(wù)
- 網(wǎng)站廣告
- 在線研討會
- 活動策劃
- 新聞發(fā)布
- 新品發(fā)布
- 小測驗
- 設(shè)計大賽
- 華秋
- 關(guān)于我們
- 投資關(guān)系
- 新聞動態(tài)
- 加入我們
- 聯(lián)系我們
- 舉報投訴
- 社交網(wǎng)絡(luò)
- 微博
- 移動端
- 發(fā)燒友APP
- 硬聲APP
- WAP
- 聯(lián)系我們
- 廣告合作
- 王婉珠:[email protected]
- 內(nèi)容合作
- 黃晶晶:[email protected]
- 內(nèi)容合作(海外)
- 張迎輝:[email protected]
- 供應(yīng)鏈服務(wù) PCB/IC/PCBA
- 江良華:[email protected]
- 投資合作
- 曾海銀:[email protected]
- 社區(qū)合作
- 劉勇:[email protected]
-
關(guān)注我們的微信

-
下載發(fā)燒友APP

-
電子發(fā)燒友觀察



版權(quán)所有 ? 湖南華秋數(shù)字科技有限公司
長沙市望城經(jīng)濟技術(shù)開發(fā)區(qū)航空路6號手機智能終端產(chǎn)業(yè)園2號廠房3層(0731-88081133)
電子發(fā)燒友 (電路圖) 湘公網(wǎng)安備43011202000918 工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
工商網(wǎng)監(jiān)
湘ICP備2023018690號-1
評論