") 8x7B MoE與Flash Attention 2結(jié)合,不到10行代碼實(shí)現(xiàn)快速推理
8x7B MoE與Flash Attention 2結(jié)合,不到10行代碼實(shí)現(xiàn)快速推理

前段時(shí)間,Mistral AI 公布的 Mixtral 8x7B 模型爆火整個(gè)開(kāi)源社區(qū),其架構(gòu)與 GPT-4 非常相似,很多人將其形容為 GPT-4 的「縮小版」。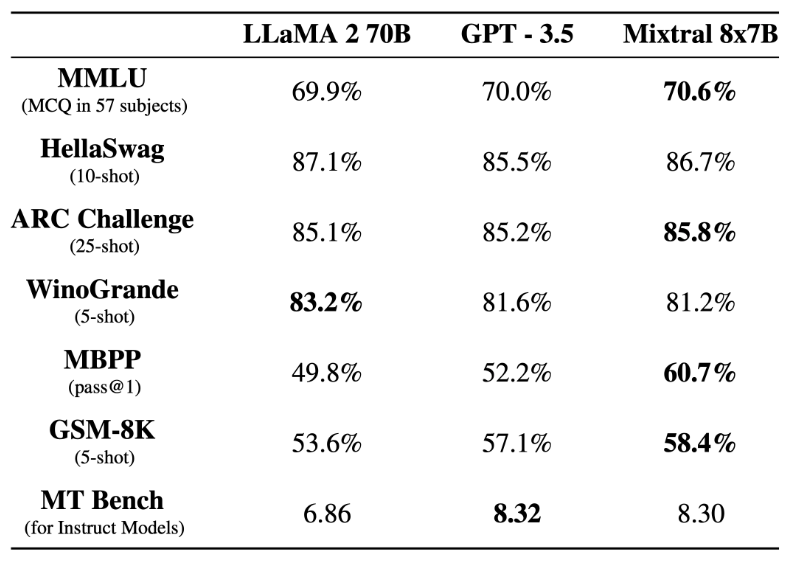
 ▲圖源 https://mistral.ai/news/mixtral-of-experts/
▲圖源 https://mistral.ai/news/mixtral-of-experts/
 ▲圖源 https://twitter.com/reach_vb/status/1741175347821883502
▲圖源 https://twitter.com/reach_vb/status/1741175347821883502 ?第三步是初始化 TextStreamer:
?第三步是初始化 TextStreamer:
 ?第四步對(duì)輸入進(jìn)行 Token 化:
?第四步對(duì)輸入進(jìn)行 Token 化:
 ?第五步生成:
?第五步生成:
 ?當(dāng)你配置好項(xiàng)目后,就可以與 Mixtral 進(jìn)行對(duì)話(huà),例如對(duì)于用戶(hù)要求「如何做出最好的美式咖啡?通過(guò)簡(jiǎn)單的步驟完成」,Mixtral 會(huì)按照 1、2、3 等步驟進(jìn)行回答。
?當(dāng)你配置好項(xiàng)目后,就可以與 Mixtral 進(jìn)行對(duì)話(huà),例如對(duì)于用戶(hù)要求「如何做出最好的美式咖啡?通過(guò)簡(jiǎn)單的步驟完成」,Mixtral 會(huì)按照 1、2、3 等步驟進(jìn)行回答。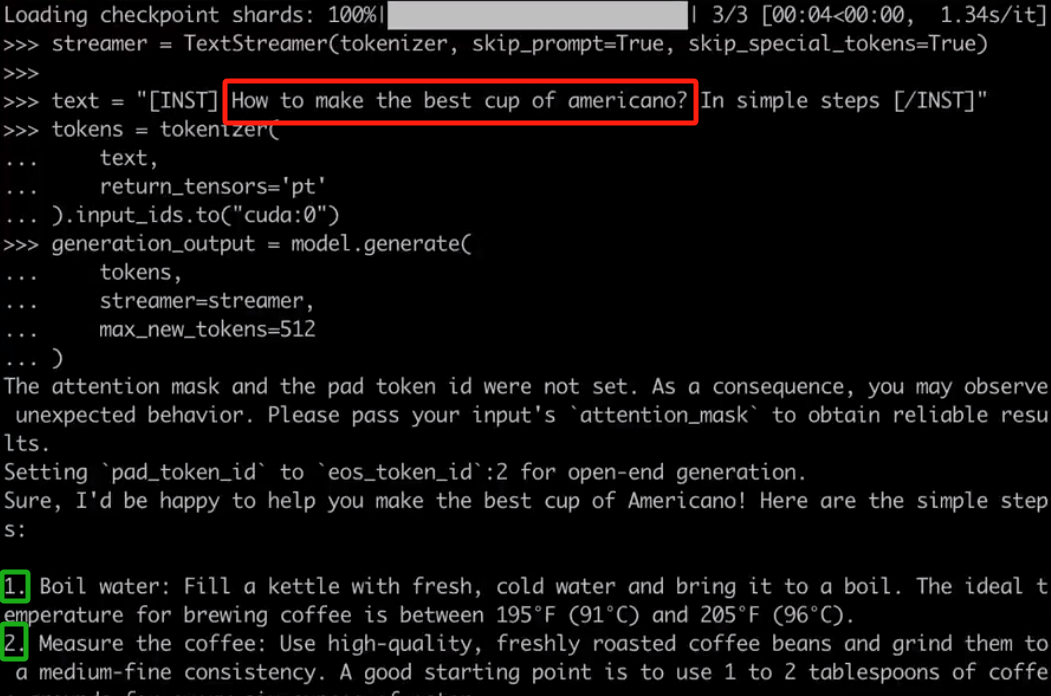
 ?
?
我們都知道,OpenAI 團(tuán)隊(duì)一直對(duì) GPT-4 的參數(shù)量和訓(xùn)練細(xì)節(jié)守口如瓶。Mistral 8x7B 的放出,無(wú)疑給廣大開(kāi)發(fā)者提供了一種「非常接近 GPT-4」的開(kāi)源選項(xiàng)。
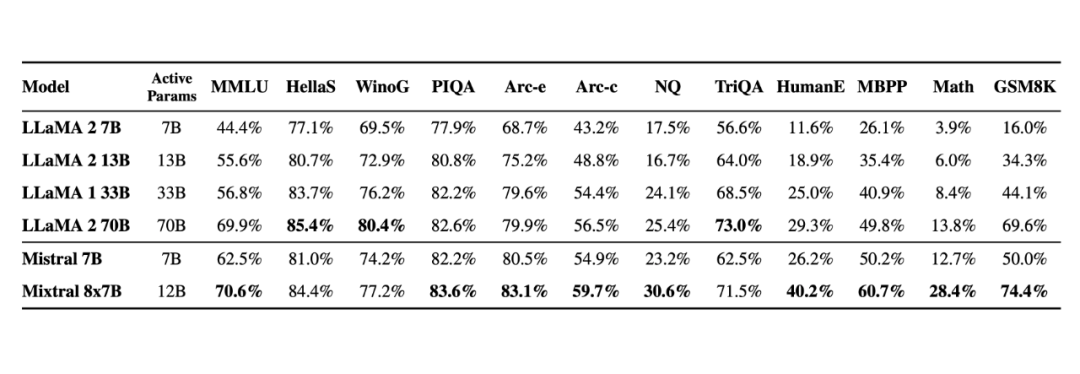
在基準(zhǔn)測(cè)試中,Mistral 8x7B 的表現(xiàn)優(yōu)于 Llama 2 70B,在大多數(shù)標(biāo)準(zhǔn)基準(zhǔn)測(cè)試上與 GPT-3.5 不相上下,甚至略勝一籌。
▲圖源 https://mistral.ai/news/mixtral-of-experts/隨著這項(xiàng)研究的出現(xiàn),很多人表示:「閉源大模型已經(jīng)走到了結(jié)局。」
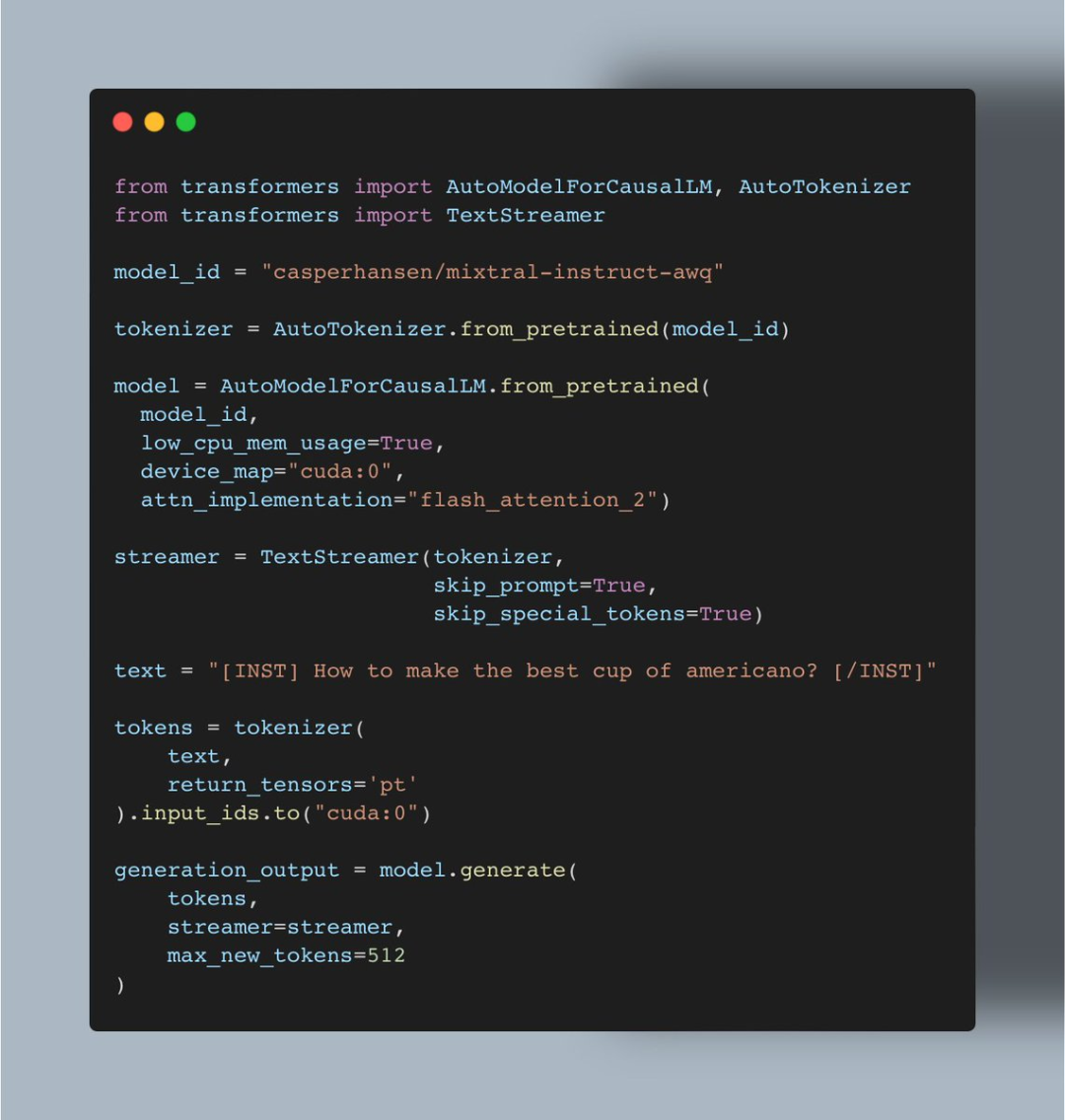
短短幾周的時(shí)間,機(jī)器學(xué)習(xí)愛(ài)好者 Vaibhav (VB) Srivastav 表示:隨著 AutoAWQ(支持 Mixtral、LLaVa 等模型的量化)最新版本的發(fā)布,現(xiàn)在用戶(hù)可以將 Mixtral 8x7B Instruct 與 Flash Attention 2 結(jié)合使用,達(dá)到快速推理的目的,實(shí)現(xiàn)這一功能大約只需 24GB GPU VRAM、不到十行代碼。
▲圖源 https://twitter.com/reach_vb/status/1741175347821883502
AutoAWQ地址:
https://github.com/casper-hansen/AutoAWQ 操作過(guò)程是這樣的: 首先是安裝 AutoAWQ 以及 transformers:
pipinstallautoawqgit+https://github.com/huggingface/transformers.git
第二步是初始化 tokenizer 和模型:
?第三步是初始化 TextStreamer:
?第四步對(duì)輸入進(jìn)行 Token 化:
?第五步生成:
?當(dāng)你配置好項(xiàng)目后,就可以與 Mixtral 進(jìn)行對(duì)話(huà),例如對(duì)于用戶(hù)要求「如何做出最好的美式咖啡?通過(guò)簡(jiǎn)單的步驟完成」,Mixtral 會(huì)按照 1、2、3 等步驟進(jìn)行回答。
項(xiàng)目中使用的代碼:
Srivastav 表示上述實(shí)現(xiàn)也意味著用戶(hù)可以使用 AWQ 運(yùn)行所有的 Mixtral 微調(diào),并使用 Flash Attention 2 來(lái)提升它們。 看到這項(xiàng)研究后,網(wǎng)友不禁表示:真的很酷。
?
聲明:本文內(nèi)容及配圖由入駐作者撰寫(xiě)或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點(diǎn)僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場(chǎng)。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問(wèn)題,請(qǐng)聯(lián)系本站處理。
舉報(bào)投訴
-
代碼
+關(guān)注
關(guān)注
30文章
4897瀏覽量
70579 -
GPT
+關(guān)注
關(guān)注
0文章
368瀏覽量
16056 -
OpenAI
+關(guān)注
關(guān)注
9文章
1206瀏覽量
8842
原文標(biāo)題:8x7B MoE與Flash Attention 2結(jié)合,不到10行代碼實(shí)現(xiàn)快速推理
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語(yǔ)言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
熱點(diǎn)推薦
華為宣布開(kāi)源盤(pán)古7B稠密和72B混合專(zhuān)家模型
關(guān)鍵一步,為全球開(kāi)發(fā)者、企業(yè)及研究人員提供了強(qiáng)大的技術(shù)支撐。 ? 華為此次開(kāi)源行動(dòng)涵蓋三大核心板塊:盤(pán)古Pro MoE 72B模型權(quán)重與基礎(chǔ)推理代碼已率先上線開(kāi)源平臺(tái);基于昇騰的超大規(guī)
華為正式開(kāi)源盤(pán)古7B稠密和72B混合專(zhuān)家模型
關(guān)鍵舉措,推動(dòng)大模型技術(shù)的研究與創(chuàng)新發(fā)展,加速推進(jìn)人工智能在千行百業(yè)的應(yīng)用與價(jià)值創(chuàng)造。 盤(pán)古Pro MoE 72B模型權(quán)重、基礎(chǔ)推理代碼,已
帶增益的 RX 分集 FEM(B26、B8、B20、B1/4、B3 和 B7) skyworksinc
電子發(fā)燒友網(wǎng)為你提供()帶增益的 RX 分集 FEM(B26、B8、B20、B1/4、B3 和 B7
發(fā)表于 06-27 18:31

具有載波聚合的 RX 分集 FEM(B26、B8、B12/13、B2/25、B4 和 B7) skyworksinc
電子發(fā)燒友網(wǎng)為你提供()具有載波聚合的 RX 分集 FEM(B26、B8、B12/13、B2/25、B4 和
發(fā)表于 06-19 18:35
潤(rùn)和軟件StackRUNS異構(gòu)分布式推理框架的應(yīng)用案例
江蘇潤(rùn)和軟件股份有限公司(以下簡(jiǎn)稱(chēng)“潤(rùn)和軟件”)自主研發(fā)的StackRUNS異構(gòu)分布式推理框架已在實(shí)際場(chǎng)景中取得顯著成效,成功應(yīng)用于大型園區(qū)多模態(tài)模型演練及高校滿(mǎn)血版DeepSeek-MoE 671B的運(yùn)行,有效推動(dòng)了大模型技術(shù)

代碼革命的先鋒:aiXcoder-7B模型介紹
? ? 國(guó)內(nèi)開(kāi)源代碼大模型 4月9日aiXcoder宣布正式開(kāi)源其7B模型Base版,僅僅過(guò)去一個(gè)禮拜,aiXcoder-7B在軟件源代碼托管服務(wù)平臺(tái)GitHub上的Star數(shù)已超過(guò)

基于小凌派RK2206開(kāi)發(fā)板:OpenHarmony如何使用IoT接口控制FLASH外設(shè)
] = a
[7] = a
[8] = a
[9] = a
[10] = a
[11] = a
[12] = a
[13] = a
[14] = a
[15] = a
Fla
發(fā)表于 04-22 15:02
7路達(dá)林頓驅(qū)動(dòng)的16KB Flash ROM的AD型MCU AiP8F3201
7路達(dá)林頓驅(qū)動(dòng)的16KB Flash ROM的AD型MCU AiP8F3201
基于1F1B的MoE A2A通信計(jì)算Overlap
在 MoE 模型的訓(xùn)練過(guò)程中,EP rank 之間的 A2A 通信在端到端時(shí)間中占據(jù)了相當(dāng)大比重,對(duì)訓(xùn)練效率影響很大,特別是對(duì)于 Fine-grained MoE model,EP size 會(huì)比較大,跨機(jī)通信基本無(wú)法避免。那么
摩爾線程Round Attention優(yōu)化AI對(duì)話(huà)
摩爾線程科研團(tuán)隊(duì)發(fā)布研究成果《Round Attention:以輪次塊稀疏性開(kāi)辟多輪對(duì)話(huà)優(yōu)化新范式》,該方法端到端延遲低于現(xiàn)在主流的Flash Attention推理引擎,kv-cac

Flexus X 實(shí)例 C#/.Net Core 結(jié)合(git 代碼管理、docker 自定義鏡像)快速發(fā)布部署 - 讓你的項(xiàng)目飛起來(lái)~
前言 ???云端部署新體驗(yàn),C# Web API 遇上 Git Docker,828 B2B 企業(yè)節(jié)特惠來(lái)襲!Flexus X 實(shí)例,為您的 C#應(yīng)用提供強(qiáng)大支撐,結(jié)合 Git 版本控制

獵戶(hù)星空發(fā)布Orion-MoE 8×7B大模型及AI數(shù)據(jù)寶AirDS
近日,獵戶(hù)星空攜手聚云科技在北京共同舉辦了一場(chǎng)發(fā)布會(huì)。會(huì)上,獵戶(hù)星空正式揭曉了其自主研發(fā)的Orion-MoE 8×7B大模型,并與聚云科技聯(lián)合推出了基于該大模型的數(shù)據(jù)服務(wù)——AI數(shù)據(jù)寶AirDS
CC13x2x7和CC26x2x7 SimpleLink無(wú)線MCU技術(shù)參考手冊(cè)
電子發(fā)燒友網(wǎng)站提供《CC13x2x7和CC26x2x7 SimpleLink無(wú)線MCU技術(shù)參考手冊(cè).pdf》資料免費(fèi)下載
發(fā)表于 11-14 14:16
?0次下載

阿里Qwen2-Math系列震撼發(fā)布,數(shù)學(xué)推理能力領(lǐng)跑全球
阿里巴巴近期震撼發(fā)布了Qwen2-Math系列模型,這一系列模型基于其強(qiáng)大的Qwen2 LLM構(gòu)建,專(zhuān)為數(shù)學(xué)解題而生,展現(xiàn)了前所未有的數(shù)學(xué)推理能力。Qwen2-Math家族包括1.5
PerfXCloud順利接入MOE大模型DeepSeek-V2
今日,在 PerfXCloud 重磅更新支持 llama 3.1 之后,其平臺(tái)再度實(shí)現(xiàn)重大升級(jí)!目前,已順利接入被譽(yù)為全球最強(qiáng)的 MOE 大模型 DeepSeek-V2 ,已在 PerfXCloud(澎峰云)官網(wǎng)的體驗(yàn)中心對(duì)平臺(tái)





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論