 大語言模型推斷中的批處理效應
大語言模型推斷中的批處理效應
作者 | 陳樂群
單位 | 華盛頓大學博士生
方向 | 機器學習系統及分布式系統
來自 | PaperWeekly
隨著開源預訓練大型語言模型(Large Language Model, LLM )變得更加強大和開放,越來越多的開發者將大語言模型納入到他們的項目中。其中一個關鍵的適應步驟是將領域特定的文檔集成到預訓練模型中,這被稱為微調。
通常情況下,來自領域特定文檔的額外知識與預訓練模型已經知道的相比微不足道。在這種情況下,低秩適應(Low-Rank Adaptation,LoRA )技術證明是有價值的。
通過 LoRA,微調模型僅向預訓練模型添加不到 0.1% 的參數。具體來說,這意味著 LoRA 微調模型僅增加了10~200MB 的存儲,具體取決于配置。從計算角度來看,考慮到與預訓練模型相比參數的增加極少,額外的計算負載相對較小。
基于存儲和計算的額外開銷都很小這一點,我相信構建一個多租戶的大語言微調模型的推斷服務具有很大潛力。這個服務可以托管成千上萬個 LoRA 模型,它們都共享相同的預訓練大語言模型。在每個批次的執行中,每個用戶請求都會調用一個獨立的微調模型,從而分攤存儲和計算成本到各種不同的模型中。
在我的上一篇文章中,我深入探討了大語言模型推斷中的批處理效應。在這篇文章中,我將詳細介紹為什么多租戶 LoRA 推斷服務具有巨大的潛力。
背景知識:文本生成
文本生成服務,如 ChatGPT,接受用戶文本輸入并提供文本響應。這個輸入被稱為“提示”(prompt)。在內部,當大語言模型處理文本時,它在一系列“詞元”(token)上操作。我們可以大致將詞元視為幾個字符或一個單詞。文本生成過程有兩個主要階段:
預填充階段(或稱“編碼”,“初始化”)接受整個提示并生成隨后的詞元以及一個“鍵值緩存”(KV Cache)。
解碼階段處理新生成的詞元和鍵值緩存,然后生成下一個詞元,同時更新鍵值緩存。這個階段不斷重復,直到模型完成其輸出。
有趣的是,盡管預填充階段處理的詞元數量比解碼階段多 100 倍,但它們的計算延遲是在同一數量級的。由于解碼階段會重復執行上百次,因此在這篇文章中,我將集中討論如何優化解碼階段。
背景知識:大語言模型的架構和批處理
在其核心,大語言模型的架構非常簡單。它主要包括多個 Transformer 層,所有層都共享相同的架構。每一層包括四個計算密集型組件:QKV 投影、自注意力、輸出投影和前饋網絡(Feed-Forward Network, FFN )。

▲ Transformer 層在解碼階段的運算圖示
概括地說,其中包含了兩種算子:
自注意力(Self-Attention,黃色標出)涉及矩陣-矩陣乘法。
密集投影(Dense Projection,綠色標出)涉及向量-矩陣乘法。
考慮到每個批次中每個序列只有一個詞元,密集投影計算也非常微小,不足以充分利用 GPU 。因此,擴大批處理大小幾乎不會影響密集投影的延遲,這使得大批處理大小對于構建高吞吐、低延遲的推斷服務至關重要。
關于大語言模型推斷中的批處理的更詳細分析,請查看我的以前的博客文章。
背景知識:LoRA
給定形狀為 [H1, H2] 的預訓練參數矩陣 W ,LoRA 微調訓練一個形狀為。 [H1, R] 的小矩陣 A 和形狀為 [R, H2] 的 B 。我們使用(W+AB)作為微調模型的權重。這里的 R 是 LoRA 微調指定的秩,通常遠小于原始維度(>= 4096),通常在 8~32 之間。
這種方法背后的邏輯是,與原始權重相比,新增加的知識只占一小部分,因此 LoRA 將增量壓縮成兩個低秩矩陣。
與完全微調相比,LoRA 預訓練顯著降低了微調模型的存儲和內存需求。
在大語言模型中,由于所有參數都位于密集投影中,LoRA 可以集成到 Transformer 層中的任何位置。雖然 HuggingFace PEFT 庫僅將 LoRA 加到 q_proj 和 v_proj ,但一些研究,如 QLoRA,主張將其包含在所有的密集投影中。
LoRA 延遲和批處理效應
盡管在存儲方面,LoRA 矩陣明顯小于原始權重矩陣,但計算的延遲并不成比例地減少。我們可以使用以下代碼對骨干模型和 LoRA 增量的延遲進行基準測試:
h1=4096 h2=11008 r=16 forbsinrange(1,33): w=torch.randn(h1,h2,dtype=torch.float16,device="cuda:0") a=torch.randn(bs,h1,r,dtype=torch.float16,device="cuda:0") b=torch.randn(bs,r,h2,dtype=torch.float16,device="cuda:0") x=torch.randn(bs,1,h1,dtype=torch.float16,device="cuda:0") bench(lambda:x@w) bench(lambda:x@a@b)
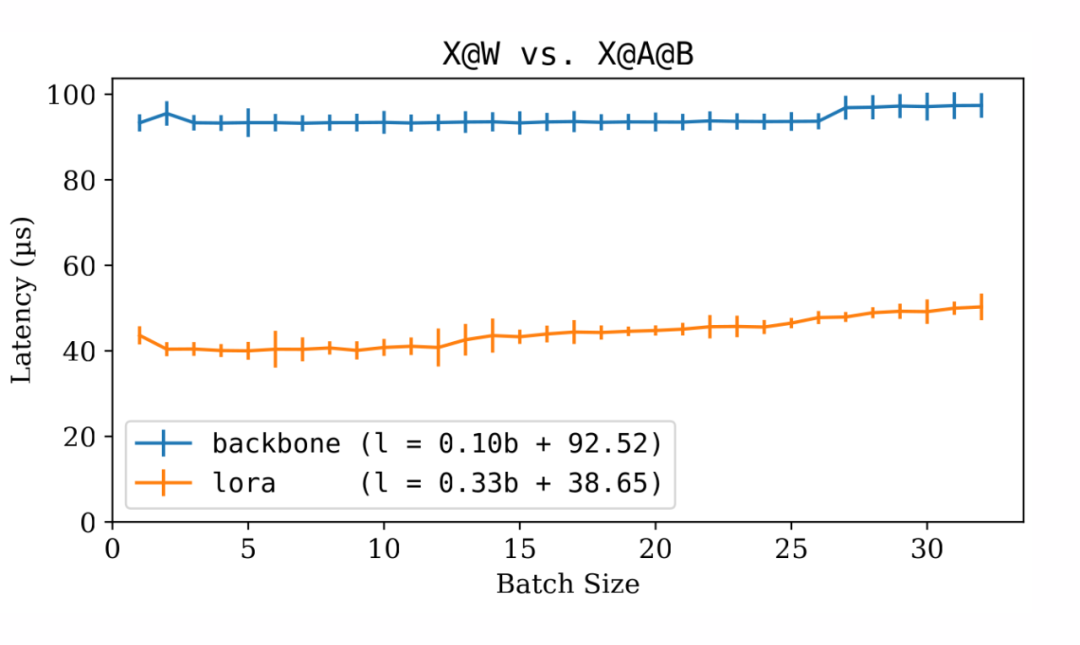
▲ 骨干大語言模型和 LoRA 微調模型的推斷延遲比較
上圖表明,LoRA 增量僅比骨干模型快 2.5 倍。
然而,顯然 LoRA 批處理效應與骨干模型的效應相似。批處理大小的增加僅在較小程度上影響延遲。這個特性使得多租戶 LoRA 非常可行。
在骨干模型中,所有一個批次中的所有請求都針對同一模型。而在多租戶 LoRA 服務中,一個批次中的請求可能會調用不同的 LoRA 微調模型。數學表達如下:
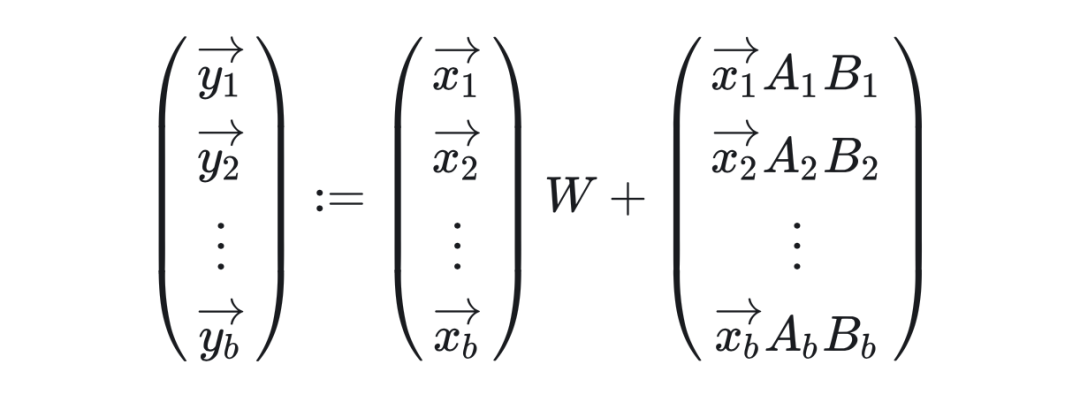
挑戰在于以批處理的方式將不同的 LoRA 增量應用于一個批處理中的各個輸入,與此同時還要維持“白吃的午餐”式的批處理效應。
批處理 LoRA 算子
我們想要的批處理 LoRA 算子具有以下函數簽名:
defadd_lora( y:torch.Tensor,#(batch_size,1,out_features) x:torch.Tensor,#(batch_size,1,in_features) A:torch.Tensor,#(num_loras,in_features,lora_rank) B:torch.Tensor,#(num_loras,lora_rank,out_features) I:torch.LongTensor,#(batch_size,) ): """Semantics:y[i]+=x[i]@A[I[i]]@B[I[i]]""" raiseNotImplementedError()
一個最簡單的實現方法是在批處理維度上進行循環:?
deflora_loop( y:torch.Tensor,#(batch_size,1,out_features) x:torch.Tensor,#(batch_size,1,in_features) A:torch.Tensor,#(num_loras,in_features,lora_rank) B:torch.Tensor,#(num_loras,lora_rank,out_features) I:torch.LongTensor,#(batch_size,) ): fori,idxinenumerate(I.cpu().numpy()): y[i]+=x[i]@A[idx]@B[idx]
讓我們對循環版本進行基準測試。為了進行比較,我們可以包括一個“作弊”實現,其中我們假設批處理中每個請求的 LoRA 矩陣已經被合并在一起。這樣,我們只測量批量矩陣乘法(Batched Matrix Multiplication, bmm)的延遲。??
deflora_cheat_bmm( y:torch.Tensor,#(batch_size,1,out_features) x:torch.Tensor,#(batch_size,1,in_features) cheat_A:torch.Tensor,#(batch_size,in_features,lora_rank) cheat_B:torch.Tensor,#(batch_size,lora_rank,out_features) ): y+=x@cheat_A@cheat_B num_loras=50 h1=4096 h2=11008 r=16 A=torch.randn(num_loras,h1,r,dtype=torch.float16,device="cuda:0") B=torch.randn(num_loras,r,h2,dtype=torch.float16,device="cuda:0") forbsinrange(1,33): x=torch.randn(bs,1,h1,dtype=torch.float16,device="cuda:0") y=torch.randn(bs,1,h2,dtype=torch.float16,device="cuda:0") I=torch.randint(num_loras,(bs,),dtype=torch.long,device="cuda:0") cheat_A=A[I,:,:] cheat_B=B[I,:,:] bench(lambda:lora_loop(y,x,A,B,I)) bench(lambda:lora_cheat_bmm(y,x,cheat_A,cheat_B))
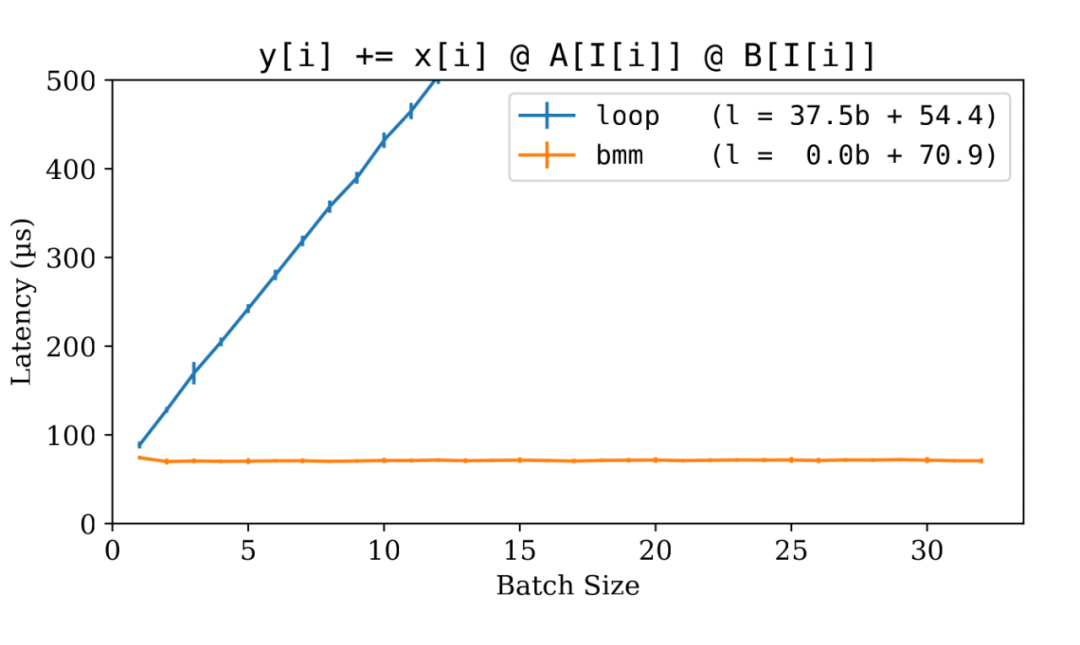
▲ LoRA 實現:for-loop vs bmm
可預見的是,循環版本明顯較慢,并且失去了批處理效應。這是因為它逐個處理輸入,而不是利用為批處理數據設計的高效 CUDA 核心。
然而, bmm 方法提供了一個很好的啟發。我們的目標變得清晰起來:首先將所有 LoRA 矩陣匯總到一個臨時的張量中,然后使用 bmm 。經過一番挖掘,我發現了 torch.index_select() 函數,它可以高效地執行批量匯總(Batched Gather)。于是我們可以如下一個 gbmm?( gather-bmm )實現:?
deflora_gbmm( y:torch.Tensor,#(batch_size,1,out_features) x:torch.Tensor,#(batch_size,1,in_features) A:torch.Tensor,#(num_loras,in_features,lora_rank) B:torch.Tensor,#(num_loras,lora_rank,out_features) I:torch.LongTensor,#(batch_size,) ): a=torch.index_select(A,0,I)#(batch_size,in_features,lora_rank) b=torch.index_select(B,0,I)#(batch_size,lora_rank,out_features) y+=x@a@b
BGMV 算子
雖然 gbmm 非常有效,但它并不是最終解決方案。我們沒有必要僅僅是因為 bmm 需要連續的存儲而將 LoRA 增量而匯總到一個連續的空間中。理想情況下,聚合可以在 CUDA 核心內部進行,于 bmm 操作同事進行。如果可能的話,這將消除與 torch.index_select() 相關的 GPU 內存讀寫操作。
我請葉子豪大牛幫忙,他是精通高性能 CUDA 核心的編寫。經過幾輪迭代,子豪開發了一個非常快的 CUDA 程序,把 LoRA 所需的計算分成兩半。我們將這個算子命名為 BGMV(Batched Gather Matrix-Vector Multiplication):
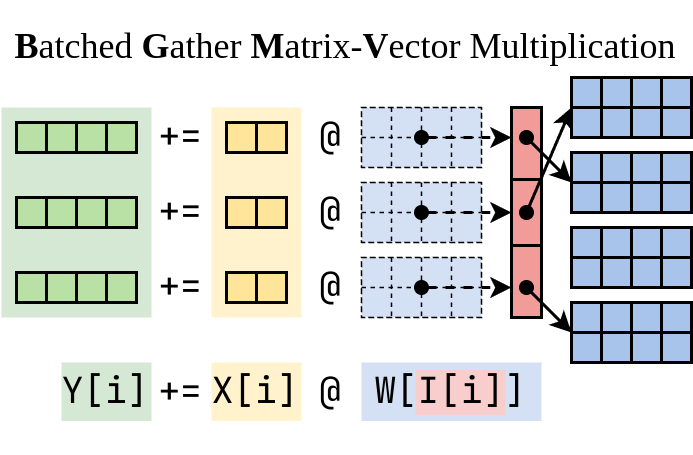
▲ Batched Gather Matrix-Vector Multiplication (BGMV)
deflora_bgmv( y:torch.Tensor,#(batch_size,1,out_features) x:torch.Tensor,#(batch_size,1,in_features) A:torch.Tensor,#(num_loras,in_features,lora_rank) B:torch.Tensor,#(num_loras,lora_rank,out_features) I:torch.LongTensor,#(batch_size,) ): tmp=torch.zeros((x.size(0),A.size(-1)),dtype=x.dtype,device=x.device) bgmv(tmp,x,A,I) bgmv(y,tmp,B,I)
這是 gbmm 和 bgmv 的基準結果:
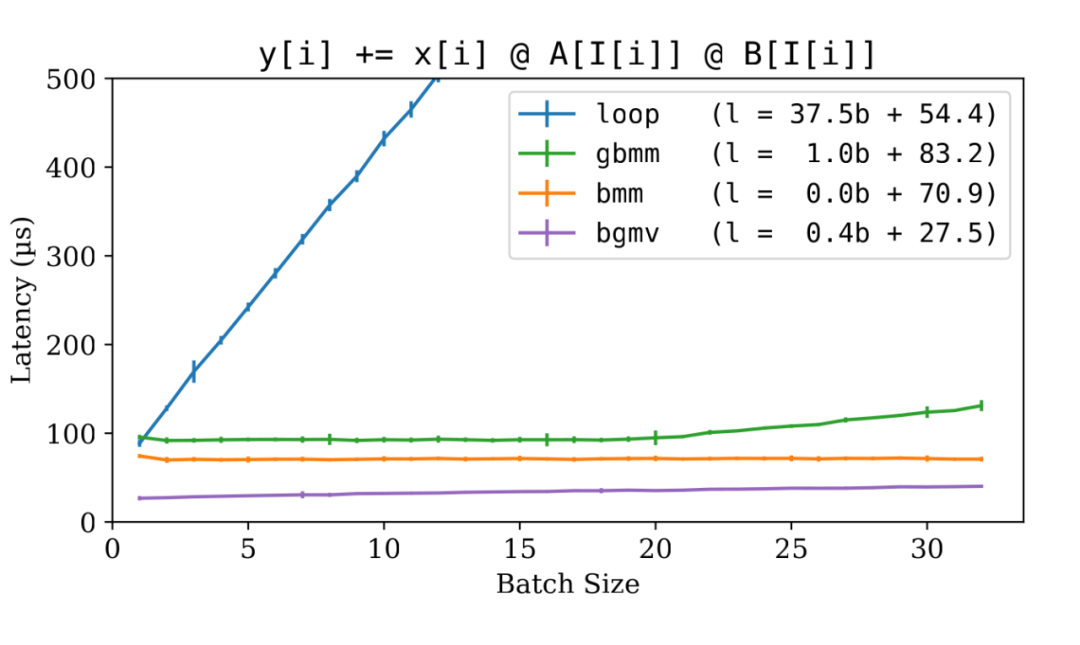
▲ LoRA 實現: for-loop vs bmm vs gbmm vs bgmv
如圖所示, gbmm 非常有效。聚合過程相對于 bmm 增加了約 20% 的延遲,但保持了令人滿意的批處理效應。而子豪編寫的 bgmv 算子更加高效,甚至超過了 bmm 。
多租戶 LoRA 文本生成性能
在 bgmv 算子的基礎上,我開發了一個名為Punica的實驗項目,支持多個 LoRA 模型。Punica 的獨特能力是能把不同 LoRA 模型的請求合并在一個批處理中。我對比了 Punica 和一系列知名系統的性能,包括 HuggingFace Transformers、DeepSpeed、Faster Transformer 和 vLLM。
在測試中,每個請求都針對不同的 LoRA 模型。鑒于其他系統沒有明確針對多租戶 LoRA 服務進行優化,它們的批處理大小為 1。我使用了 HuggingFace PEFT庫來把 LoRA 加到 HuggingFace Transformers 和 DeepSpeed 中。我尚未調整 vLLM 和 Faster Transformer,所以它們在沒有 LoRA 的情況下運行。以下是結果:
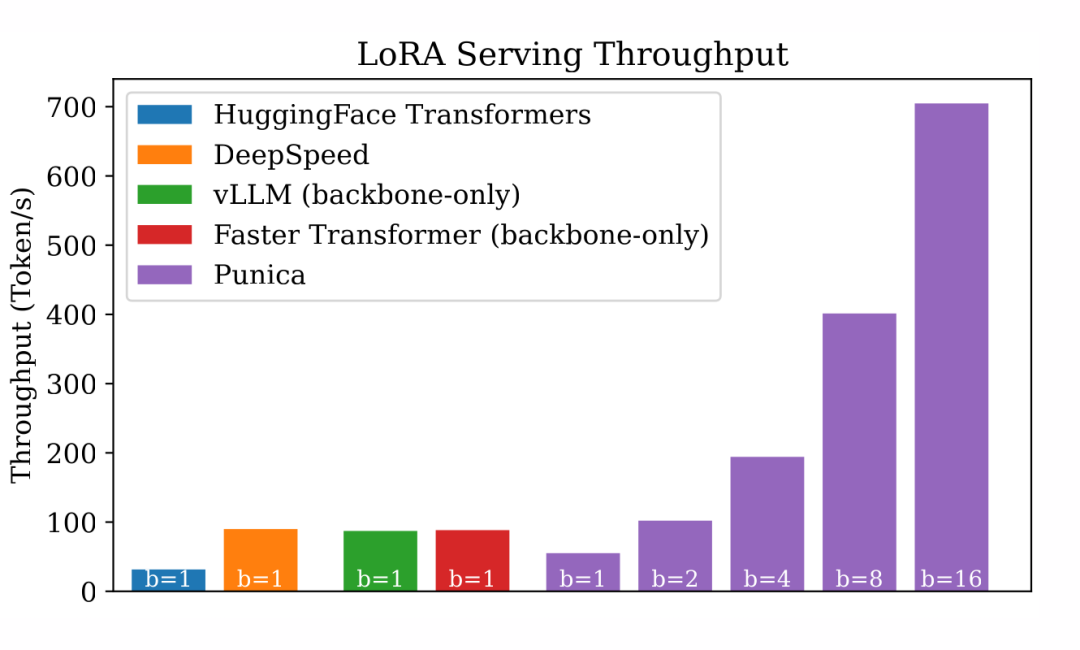
▲ 多租戶 LoRA 文本生成的吞吐量
DeepSpeed、vLLM 和 Faster Transformers 都有高度優化的 Transformer 實現,這些系統的吞吐量比標準的 HuggingFace Transformers 高出 3 倍。但由于批處理大小被限制在 1,它們在多租戶 LoRA 服務效率方面表現不佳。
相反,Punica 在批處理大小為 16 時比這些系統高出 8 倍,與普通的 HuggingFace Transformers 相比,甚至高達 23 倍。值得注意的是,Punica 的吞吐量幾乎與批處理大小呈線性關系。
值得注意的是,Punica 仍然是一個早期的研究原型。它目前使用與普通的 HuggingFace Transformers 相同的 Transformer 實現,除了 LoRA 和自注意力運算符。一些已知的 Transformer 層的優化在 Punica 中尚未實現。這解釋了在批處理大小為 1 時 Punica 與其他高度優化的系統之間的性能差距。
吞吐量不錯,那么從延遲方面表現如何?
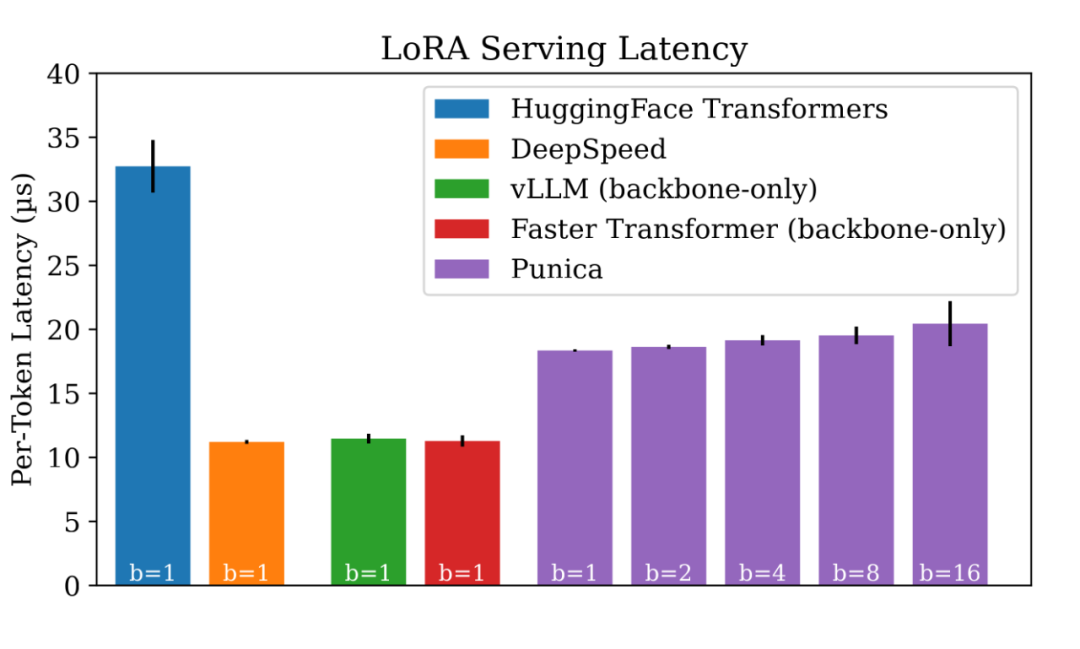
▲ 多租戶 LoRA 文本生成的延遲
如圖所示,Punica 中的批處理不會引入顯著的延遲。
示例用途
在展示了多租戶 LoRA 服務的高效性后,讓我們設想一些潛在的應用場景:
用一本新的小說對 LoRA 模型進行細調,以幫助讀者總結每個角色的旅程。
針對迅速發展的新聞對 LoRA 模型進行調整,以讓讀者了解最新動態。
基于網頁內容對 LoRA 模型進行優化,提高讀者的理解能力。
我將這種方法稱為“即時細調”(Just-in-time Fine-tuning),因為 LoRA 的訓練速度非常快(在我的試驗中,每個訓練周期不到一秒)。
總結
本文展示了用批處理加速多個 LoRA 微調模型并行推斷的可行性。我實現的 Punica 項目展現出了關于批處理大小幾乎線性的吞吐量擴展,并且增加批處理大小并不顯著增加延遲。
這項研究仍然在進行中。我正在積極開展這項研究項目,預計很快會發布一個在線演示。我歡迎任何反饋或想法,請隨時在評論部分中分享。
最近這幾個月出來了很多非常棒的開源大語言模型。要讓開源預訓練模型能更好的跑在我們要做的事情上,我們可以對這些預訓練模型進行微調。LoRA 是一種非常高效的微調技術,哪怕預訓練模型要占好幾百 GB 空間,用 LoRA 進行微調也只需要增加 1% 左右的空間。
這里我先簡單概括一下 LoRA 是怎么做的。假設預訓練模型有一個形狀是 [H1, H2] 的參數矩陣 W ,用 LoRA 進行微調的時候,我們會增加兩個小矩陣, [H1, r] 的的矩陣 A ,以及 [r, H2] 的矩陣 B, H1 和 H2 遠大于 r 。
舉個 Llama2-7B 的例子, H1=4096, H2=11008 ,而我們只需要設置 r=16 就能獲得還不錯的效果。在計算的時候,我們把 W+AB 作為微調后的參數。對于給定一個輸入 x ,計算微調模型就是 y := x @ (W + A@B) ,等價于 y := x@W + x@A@B 。
當我們有 n 個 LoRA 微調模型的時候,我們就會有一堆小矩陣, A1, B1, A2, B2, ..., An, Bn 。對于一個輸入 batch X := (x1,x2,..,xn) ,我們假設 batch 其中的每一個輸入都對應一個 LoRA 微調模型,那么這個 batch 的計算結果就是 Y := X@W + (x1@A1@B1, x2@A2@B2, ..., xn@An@Bn) 。
注意到這個加法的左邊就是直接把這個 batch 輸入給原來的預訓練模型。我們知道預訓練模型 batch 起來跑其實是很快的,因為大語言模型有很強的批處理效應(我之前有發過一篇知乎講這個事情: 剖析 GPT 推斷中的批處理效應。)所以這里的難題就是,右手邊這一項 LoRA 要怎么高效的計算?
我們最近做了一個項目叫做 Punica,能夠非常高效的計算右邊這一項,延遲非常低,而且保留了和預訓練模型一樣的很強的批處理效應。我們實現了一個 CUDA kernel,叫做 SGMV,用來把 LoRA 這部分的計算 batch 起來算。下面這個圖介紹了 SGMV 的語義:
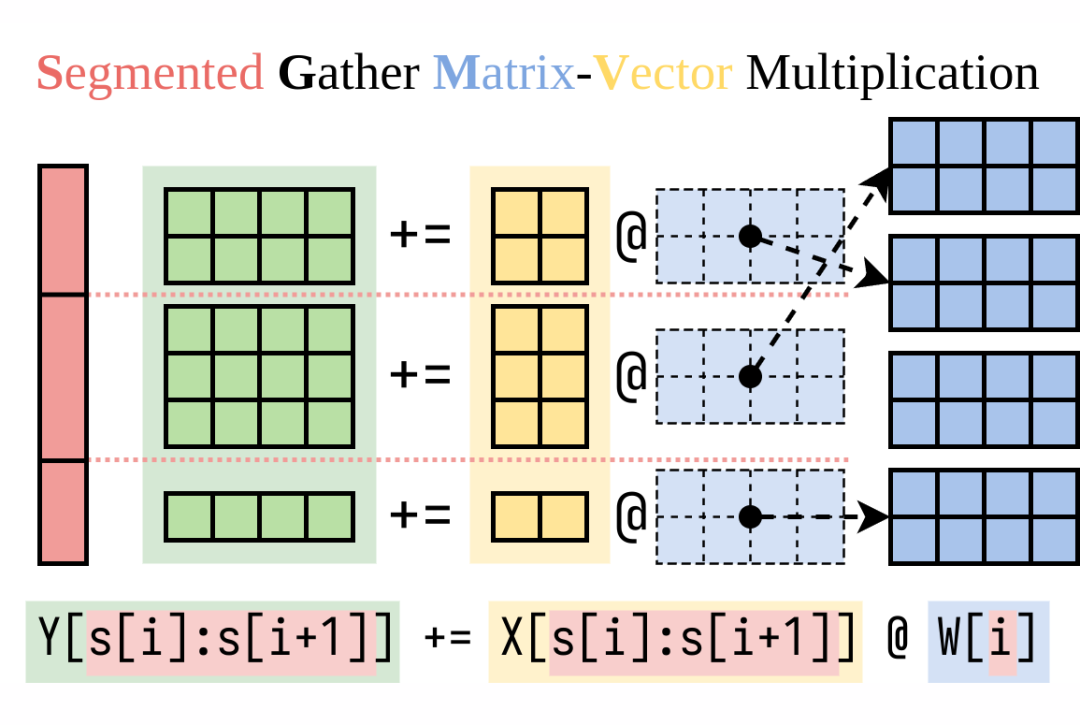
▲ SGMV 的語義
我們測了一下性能,從下面這張圖可以看出來三個事情。(1)預訓練模型有很強的批處理效應,增加批處理大小不會顯著增加延遲。(2)用簡單的方法計算 LoRA 跑起來非常慢,而且破壞了這個批處理效應。(3)我們用 SGMV 計算 LoRA 非常地快,而且保留了很強的批處理效應。
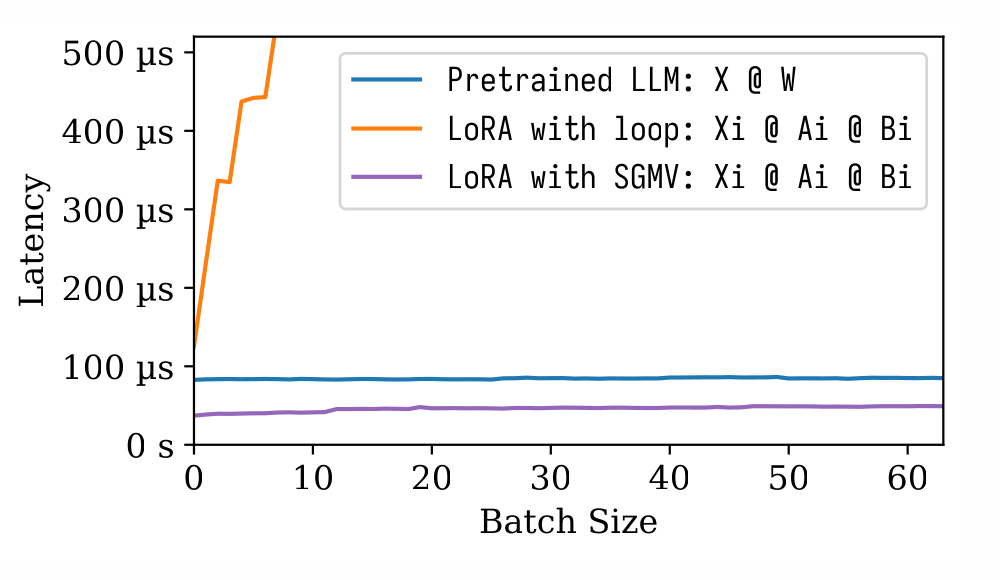
▲ 算子的性能測試
我們還跟主流的大語言模型系統做了比較了一下文本生成的性能,包括 HuggingFace Transformers, DeepSpeed, FasterTransformer, vLLM。我們考慮了 4 種不同的運行場景。
Distinct 是每一個輸入對應一個不同的 LoRA 微調模型,Identical 是所有的輸入都指向同一個 LoRA 微調模型(也就是整個系統只有一個模型),Uniform 和 Skewed 介于兩者之間,也就是有的 LoRA 微調模型更熱門一點,有的 LoRA 微調模型更冷門一點。從下面這個圖中我們可以看出,Punica 可以達到 12 倍于現有系統的吞吐量。
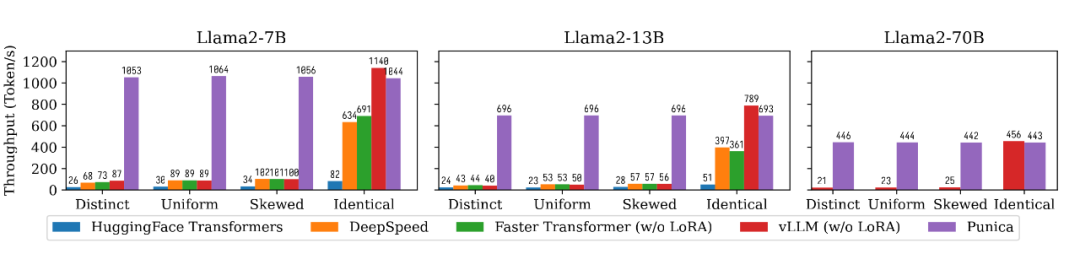
▲ 文本生成的性能比較
審核編輯:湯梓紅
-
語言模型
+關注
關注
0文章
558瀏覽量
10661 -
機器學習
+關注
關注
66文章
8490瀏覽量
134034 -
LoRa
+關注
關注
351文章
1760瀏覽量
234248 -
ChatGPT
+關注
關注
29文章
1586瀏覽量
8785
原文標題:用跑1個LoRA微調大語言模型的延遲跑10個!
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
GPT推斷中的批處理(Batching)效應簡析
【大語言模型:原理與工程實踐】大語言模型的基礎技術
【大語言模型:原理與工程實踐】大語言模型的評測
大語言模型:原理與工程時間+小白初識大語言模型
基于python的批處理方法
推斷FP32模型格式的速度比CPU上的FP16模型格式快是為什么?
批處理常用命令大全






 工商網監
工商網監
評論