") OneLLM:對(duì)齊所有模態(tài)的框架!
OneLLM:對(duì)齊所有模態(tài)的框架!
今天為大家介紹香港中文大學(xué)聯(lián)合上海人工智能實(shí)驗(yàn)室的最新研究論文,關(guān)于在LLM時(shí)代將各種模態(tài)的信息對(duì)齊的框架。
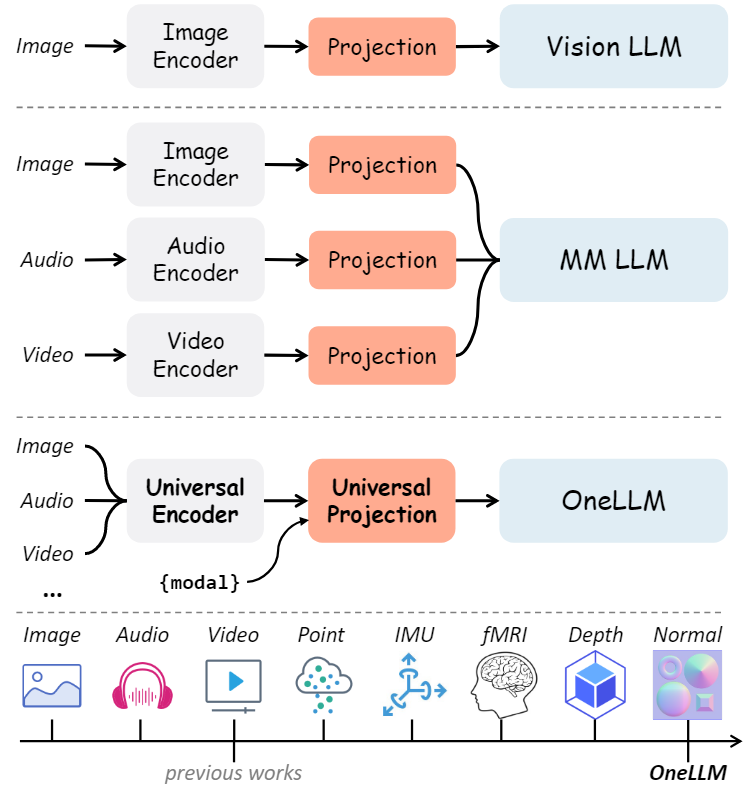
隨著LLM的興起,由于其強(qiáng)大的語言理解和推理能力,在學(xué)術(shù)和工業(yè)界中越來越受歡迎。LLM的進(jìn)展也啟發(fā)了研究人員將LLM作為多模態(tài)任務(wù)的接口,如視覺語言學(xué)習(xí)、音頻和語音識(shí)別、視頻理解等,因此多模態(tài)大語言模型(Multimodal Large Language Model, MLLM)也引起了研究人員的關(guān)注。然而,目前的研究依賴特定于單模態(tài)的編碼器,通常在架構(gòu)上有所不同,并且僅限于常見的模態(tài)。本文提出了OneLLM,這是一種MLLM,它使用一個(gè)統(tǒng)一的框架將八種模式與語言對(duì)齊。通過統(tǒng)一的多模態(tài)編碼器和漸進(jìn)式多模態(tài)對(duì)齊pipelines來實(shí)現(xiàn)這一點(diǎn)。不同多模態(tài)LLM的比較如下圖所示,可以明顯的看出OneLLM框架的工作方式與之前研究的區(qū)別。
OneLLM由輕量級(jí)模態(tài)標(biāo)記器、通用編碼器、通用投影模塊(UPM)和LLM組成。與之前的工作相比,OneLLM 中的編碼器和投影模塊在所有模態(tài)之間共享。特定于模態(tài)的標(biāo)記器,每個(gè)標(biāo)記器僅由一個(gè)卷積層組成,將輸入信號(hào)轉(zhuǎn)換為一系列標(biāo)記。此外,本文添加了可學(xué)習(xí)的模態(tài)標(biāo)記,以實(shí)現(xiàn)模態(tài)切換并將不同長度的輸入標(biāo)記轉(zhuǎn)換為固定長度的標(biāo)記。
動(dòng)機(jī)
眾多特定于模態(tài)的編碼器通常在架構(gòu)上有所不同,需要付出相當(dāng)大的努力將它們統(tǒng)一到一個(gè)框架中。此外,提供可靠性能的預(yù)訓(xùn)練編碼器通常僅限于廣泛使用的模式,例如圖像、音頻和視頻。這種限制對(duì) MLLM 擴(kuò)展到更多模式的能力施加了限制。因此,MLLM 的一個(gè)關(guān)鍵挑戰(zhàn)是如何構(gòu)建一個(gè)統(tǒng)一且可擴(kuò)展的編碼器,能夠處理廣泛的模態(tài)。
貢獻(xiàn)
本文提出了一個(gè)統(tǒng)一框架來將多模態(tài)輸入與語言對(duì)齊。與現(xiàn)有的基于模態(tài)的編碼器的工作不同,展示了一個(gè)統(tǒng)一的多模態(tài)編碼器,它利用預(yù)訓(xùn)練的視覺語言模型和投影專家的混合,可以作為 MLLM 的通用且可擴(kuò)展的組件。
OneLLM 是第一個(gè)在單個(gè)模型中集成八種不同模態(tài)的MLLM。通過統(tǒng)一的框架和漸進(jìn)式多模態(tài)對(duì)齊pipelines,可以很容易地?cái)U(kuò)展OneLLM以包含更多數(shù)據(jù)模式。
本文策劃了一個(gè)大規(guī)模的多模態(tài)指令數(shù)據(jù)集。在這個(gè)數(shù)據(jù)集上微調(diào)的 OneLLM 在多模態(tài)任務(wù)上取得了更好的性能,優(yōu)于主流模型和現(xiàn)有的 MLLM。
相關(guān)工作
LLM的迅猛發(fā)展引起了研究人員的重視,因此有研究人員提出了視覺領(lǐng)域的大型視覺語言模型,并取得了較好的性能。除了視覺領(lǐng)域大語言模型之外,研究人員將其拓展到了多模態(tài)領(lǐng)域,如音頻、視頻和點(diǎn)云數(shù)據(jù)中,這些工作使得將多種模式統(tǒng)一為一個(gè)LLM成為可能即多模態(tài)大語言模型。X-LLM,ChatBridge,Anymal,PandaGPT,ImageBind-LLM等MLLM不斷涌現(xiàn)。然而,當(dāng)前的 MLLM 僅限于支持常見的模式,例如圖像、音頻和視頻。目前尚不清楚如何使用統(tǒng)一的框架將 MLLM 擴(kuò)展到更多模式。在這項(xiàng)工作中,提出了一個(gè)統(tǒng)一的多模態(tài)編碼器來對(duì)齊所有模態(tài)和語言。將多種模式對(duì)齊到一個(gè)聯(lián)合嵌入空間中對(duì)于跨模態(tài)任務(wù)很重要,這可以分為:判別對(duì)齊和生成對(duì)齊。判別對(duì)齊最具代表性的工作是CLIP,它利用對(duì)比學(xué)習(xí)來對(duì)齊圖像和文本。后續(xù)工作將 CLIP 擴(kuò)展到音頻文本、視頻文本等。本文的工作屬于生成對(duì)齊。與之前的工作相比,直接將多模態(tài)輸入與LLM對(duì)齊,從而擺脫訓(xùn)練模態(tài)編碼器的階段。
方法
模型架構(gòu)
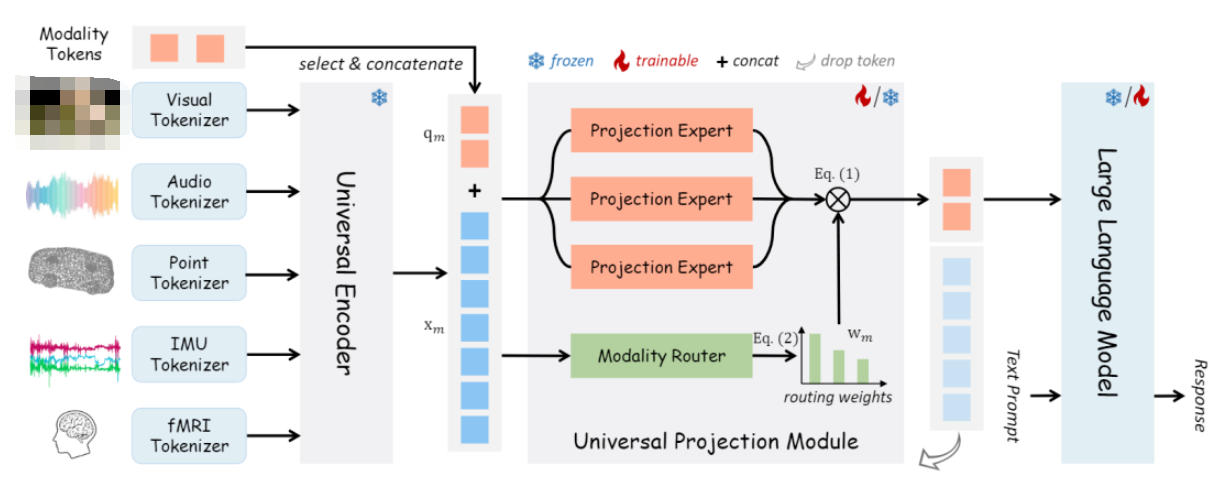
上圖展示了 OneLLM 的四個(gè)主要組件:特定于模態(tài)的標(biāo)記器、通用編碼器、通用投影模塊和 LLM。
模態(tài)標(biāo)記器:模態(tài)標(biāo)記器是將輸入信號(hào)轉(zhuǎn)換為標(biāo)記序列,因此基于轉(zhuǎn)換器的編碼器可以處理這些標(biāo)記。為每個(gè)模態(tài)設(shè)計(jì)了一個(gè)單獨(dú)的標(biāo)記器。對(duì)于圖像和視頻等二維位置信息的視覺輸入,直接使用單個(gè)二維卷積層作為標(biāo)記器。對(duì)于其他模態(tài),將輸入轉(zhuǎn)換為 2D 或 1D 序列,然后使用 2D/1D 卷積層對(duì)其進(jìn)行標(biāo)記。
通用編碼器:利用預(yù)訓(xùn)練的視覺語言模型作為所有模態(tài)的通用編碼器。視覺語言模型在對(duì)大量圖文數(shù)據(jù)進(jìn)行訓(xùn)練時(shí),通常學(xué)習(xí)視覺和語言之間的穩(wěn)健對(duì)齊,因此它們可以很容易地轉(zhuǎn)移到其他模式。在OneLLM中,使用CLIPViT作為通用計(jì)算引擎。保持CLIPViT的參數(shù)在訓(xùn)練過程中被凍結(jié)。
通用投影模塊:與現(xiàn)有的基于模態(tài)投影的工作不同,提出了一個(gè)通用投影模塊,將任何模態(tài)投影到 LLM 的嵌入空間中。由 K 個(gè)投影專家組成,其中每個(gè)專家都是在圖像文本數(shù)據(jù)上預(yù)訓(xùn)練的一堆transformer層。盡管一位專家還可以實(shí)現(xiàn)任何模態(tài)到 LLM 的投影,但實(shí)證結(jié)果表明,多個(gè)專家更有效和可擴(kuò)展。當(dāng)擴(kuò)展到更多模態(tài)時(shí),只需要添加幾個(gè)并行專家。
LLM:采用開源LLaMA2作為框架中的LLM。LLM的輸入包括投影的模態(tài)標(biāo)記和單詞嵌入后的文本提示。為了簡單起見,本文總是將模態(tài)標(biāo)記放在輸入序列的開頭。然后LLM被要求以模態(tài)標(biāo)記和文本提示為條件生成適當(dāng)?shù)捻憫?yīng)。
漸進(jìn)式多模態(tài)對(duì)齊
多模態(tài)對(duì)齊的簡單方法是在多模態(tài)文本數(shù)據(jù)上聯(lián)合訓(xùn)練模型。然而,由于數(shù)據(jù)規(guī)模的不平衡,直接在多模態(tài)數(shù)據(jù)上訓(xùn)練模型會(huì)導(dǎo)致模態(tài)之間的偏差表示。本文訓(xùn)練了一個(gè)圖像到文本模型作為初始化,并將其他模式逐步接地到LLM中。包括圖文對(duì)齊、多模態(tài)-文本對(duì)齊。同時(shí)為每個(gè)模態(tài)收集 X 文本對(duì)。圖像-文本對(duì)包括LAION-400M和LAION-COCO。視頻、音頻和視頻的訓(xùn)練數(shù)據(jù)分別為WebVid-2.5M、WavCaps和Cap3D。由于沒有大規(guī)模的deep/normal map數(shù)據(jù),使用預(yù)訓(xùn)練的 DPT 模型來生成deep/normal map。源圖像和文本以及 CC3M。對(duì)于IMU-text對(duì),使用Ego4D的IMU傳感器數(shù)據(jù)。對(duì)于fMRI-text對(duì),使用來自NSD數(shù)據(jù)集的 fMRI 信號(hào),并將與視覺刺激相關(guān)的字幕作為文本注釋。
多模態(tài)指令調(diào)優(yōu)
在多模態(tài)文本對(duì)齊之后,OneLLM 成為一個(gè)多模態(tài)字幕模型,可以為任何輸入生成簡短的描述。為了充分釋放OneLLM的多模態(tài)理解和推理能力,本文策劃了一個(gè)大規(guī)模的多模態(tài)指令調(diào)優(yōu)數(shù)據(jù)集來進(jìn)一步微調(diào)OneLLM。在指令調(diào)優(yōu)階段,完全微調(diào)LLM并保持其余參數(shù)凍結(jié)。盡管最近的工作通常采用參數(shù)高效的方法,但憑經(jīng)驗(yàn)表明,完整的微調(diào)方法更有效地利用 OneLLM 的多模態(tài)能力,特別是利用較小的 LLM(e.g.,LLaMA2-7B)。
實(shí)驗(yàn)
實(shí)現(xiàn)細(xì)節(jié)
架構(gòu):通用編碼器是在LAION上預(yù)訓(xùn)練的CLIP VIT Large。LLM 是 LLAMA2-7B。UPM有K=3個(gè)投影專家,每個(gè)專家有8個(gè)transformer塊和88M個(gè)參數(shù)。
訓(xùn)練細(xì)節(jié):使用AdamW優(yōu)化器,β1=0.9,β2==0.95,權(quán)重衰減為0.1。在前2K次迭代中應(yīng)用了線性學(xué)習(xí)速率預(yù)熱。對(duì)于階段I,在16個(gè)A100 GPU上訓(xùn)練OneLLM 200K次迭代。有效批量大小為5120。最大學(xué)習(xí)率為5e-5。對(duì)于第II階段,在8個(gè)GPU上訓(xùn)練 OneLLM 200K,有效批量大小為1080,最大學(xué)習(xí)率為1e-5。在指令調(diào)優(yōu)階段,在8個(gè)gpu上訓(xùn)練OneLLM 1 epoch,有效批大小為512,最大學(xué)習(xí)率為2e-5。
定量評(píng)價(jià)
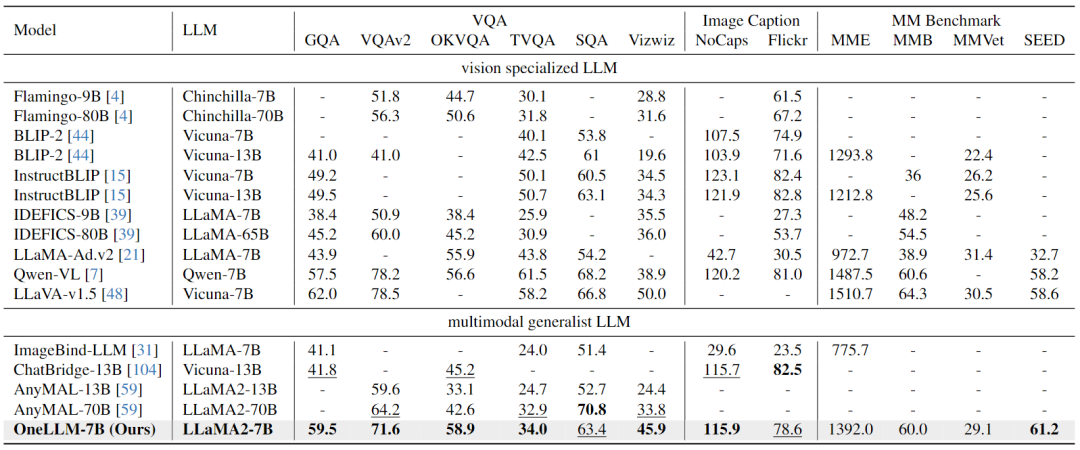
Image-Text Evaluation:下表結(jié)果表明,OneLLM還可以在視覺專門的LLM中達(dá)到領(lǐng)先水平,MLLM和視覺LLM之間的差距進(jìn)一步縮小。
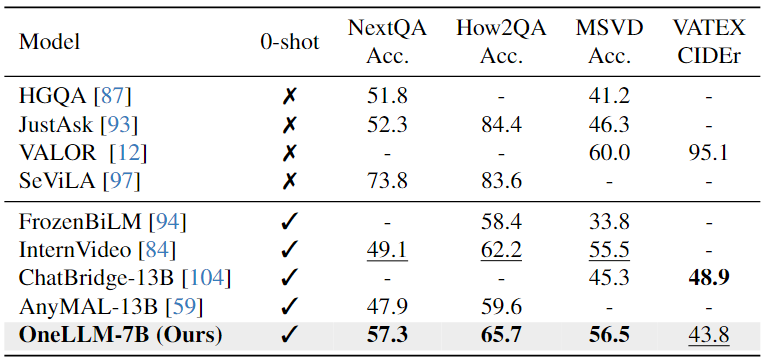
Video-Text Evaluation:下表可以看出,本文模型在相似的 VQA 數(shù)據(jù)集上進(jìn)行訓(xùn)練明顯增強(qiáng)了其緊急跨模態(tài)能力,有助于提高視頻QA任務(wù)的性能。
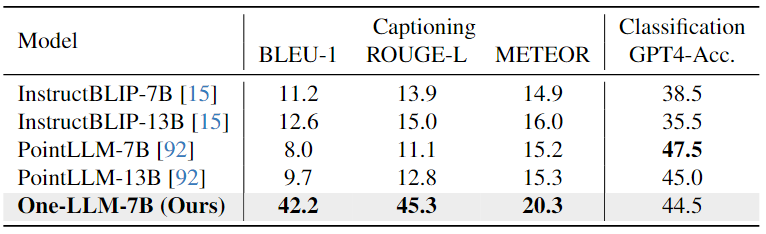
Audio-Text Evaluation:對(duì)于Audio-Text任務(wù),結(jié)果顯示,在Clotho AQA上的zero-shot結(jié)果與完全微調(diào)的Pengi相當(dāng)。字幕任務(wù)需要更多特定于數(shù)據(jù)集的訓(xùn)練,而QA任務(wù)可能是模型固有的零樣本理解能力更準(zhǔn)確的度量。
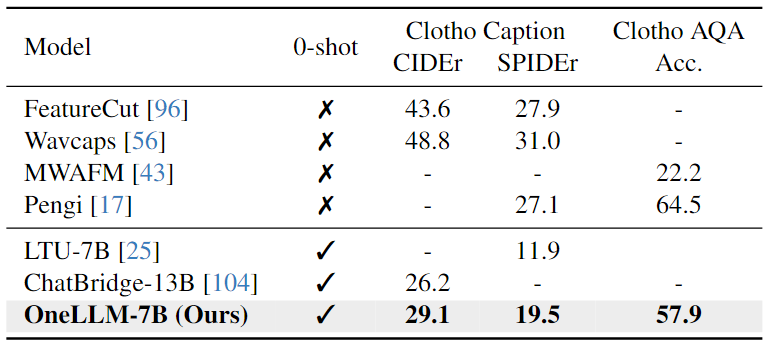
Audio-Video-Text Evaluation:下表結(jié)果表明,OneLLM-7B在所有三個(gè)數(shù)據(jù)集上都超過了 ChatBridge-13B。由于 OneLLM 中的所有模態(tài)都與語言很好地對(duì)齊,因此在推理過程中可以直接將視頻和音頻信號(hào)輸入到 OneLLM。
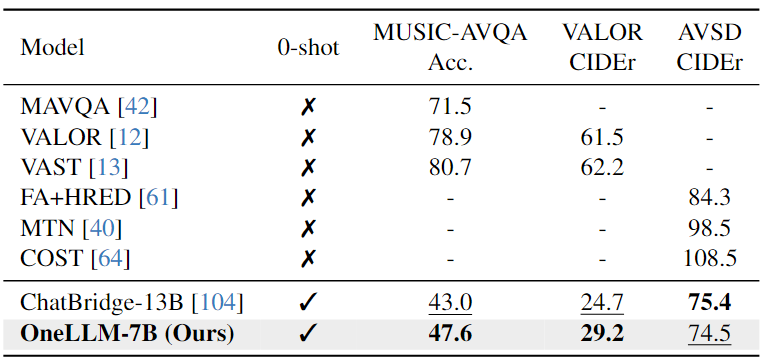
Point Cloud-Text Evaluation:從下表中可以看出,由于精心設(shè)計(jì)的指令提示在任務(wù)之間切換,OneLLM可以實(shí)現(xiàn)出色的字幕結(jié)果,而InstructBLIP和PointLLM 難以生成簡短而準(zhǔn)確的字幕。在分類任務(wù)中,OneLLM也可以獲得與 PointLLM 相當(dāng)?shù)慕Y(jié)果。
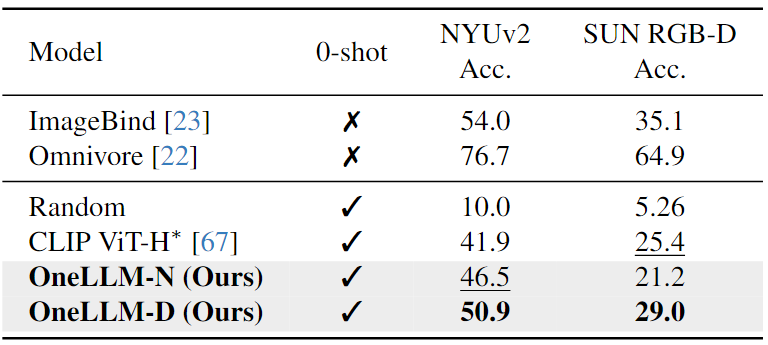
Depth/Normal Map-Text Evaluation:如下表中所示,與CLIP相比,OneLLM實(shí)現(xiàn)了優(yōu)越的zero-shot分類精度。這些結(jié)果證實(shí),在合成deep/normal map-text數(shù)據(jù)上訓(xùn)練的OneLLM可以適應(yīng)現(xiàn)實(shí)世界的場景。
消融實(shí)驗(yàn)
為了探索 OneLLM 的一些關(guān)鍵設(shè)計(jì)。消融實(shí)驗(yàn)是在訓(xùn)練數(shù)據(jù)的一個(gè)子集上進(jìn)行的,除了對(duì)專家數(shù)量的研究外,它只包含圖像、音頻和視頻的多模態(tài)對(duì)齊和指令調(diào)整數(shù)據(jù)集。如果沒有指定,其他設(shè)置保持不變。消融實(shí)驗(yàn)的結(jié)果如下表所示,
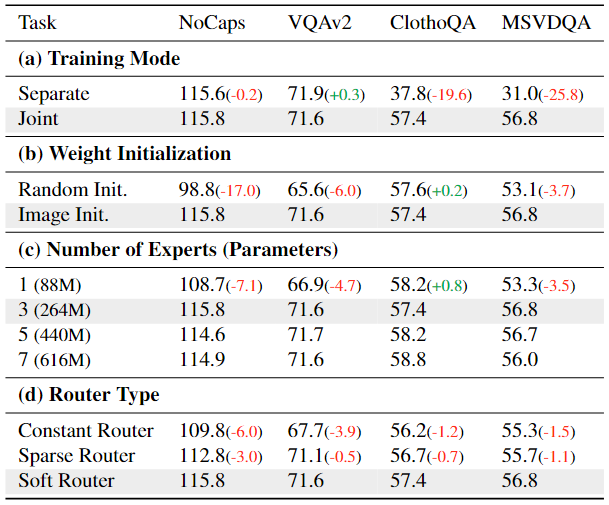
MLLM 的一個(gè)重要問題是聯(lián)合訓(xùn)練的 MLLM 是否優(yōu)于特定于模態(tài)的 MLLM。為了解決這個(gè)問題,在表7(a)中比較了單獨(dú)訓(xùn)練的MLLM與聯(lián)合訓(xùn)練的MLLMs的性能。在單獨(dú)的訓(xùn)練中,模型只能訪問自己的數(shù)據(jù);在聯(lián)合訓(xùn)練中,模型在所有數(shù)據(jù)上聯(lián)合訓(xùn)練。在兩個(gè)圖文任務(wù) NoCaps 和 VQAv2 上,可以看到單獨(dú)和聯(lián)合訓(xùn)練的模型取得了可比較的結(jié)果;雖然單獨(dú)訓(xùn)練的音頻和視頻模型比 ClothoQA 和 MSVDQA 上的聯(lián)合訓(xùn)練模型差得多。這表明聯(lián)合訓(xùn)練通過允許跨模態(tài)遷移學(xué)習(xí)知識(shí)的轉(zhuǎn)移,極大地有利于數(shù)據(jù)稀缺模態(tài)(例如音頻和視頻)。
表7(b)表明,具有圖像-文本對(duì)齊的 OneLLM 可以幫助多模態(tài)文本對(duì)齊。如果使用隨機(jī)初始化的模型直接將所有模態(tài)與文本對(duì)齊,圖像和視頻的性能會(huì)顯著下降。相反,具有圖像-文本預(yù)訓(xùn)練的 OneLLM 可以更好地平衡不同的模式。
具有三個(gè)投影專家的 OneLLM 足以保持所有模態(tài)。增加專家的數(shù)量并不能帶來所需的改進(jìn),而一位專家的結(jié)果也不能令人滿意。
軟路由器優(yōu)于其他兩個(gè)路由器,表明其對(duì)多模態(tài)信號(hào)的動(dòng)態(tài)路由的有效性。
定性分析
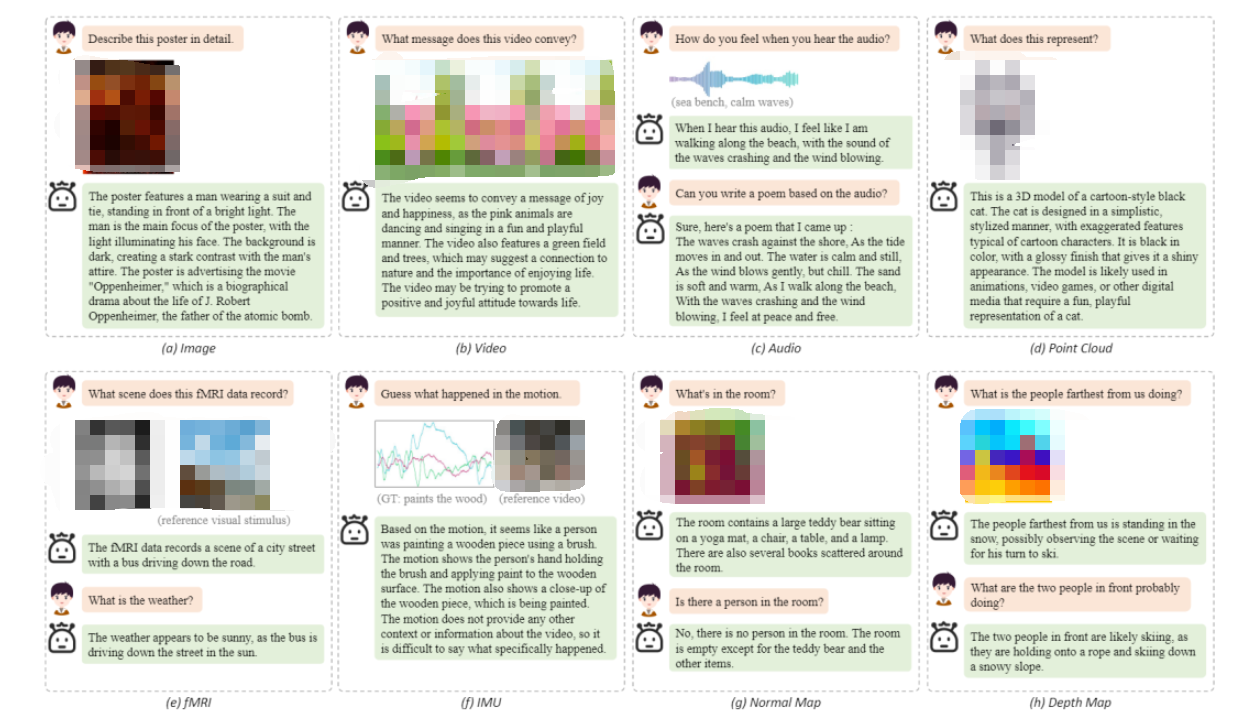
下圖中給出了 OneLLM 在八種模態(tài)上的一些定性結(jié)果。展示了 OneLLM 可以(a)理解圖像中的視覺和文本內(nèi)容,(b)利用視頻中的時(shí)間信息,(c)基于音頻內(nèi)容進(jìn)行創(chuàng)造性寫作,(d)理解3D形狀的細(xì)節(jié),(e)分析fMRI數(shù)據(jù)中記錄的視覺場景,(f)基于運(yùn)動(dòng)數(shù)據(jù)猜測人的動(dòng)作,以及(g)-(h)使用deep/normal map進(jìn)行場景理解。
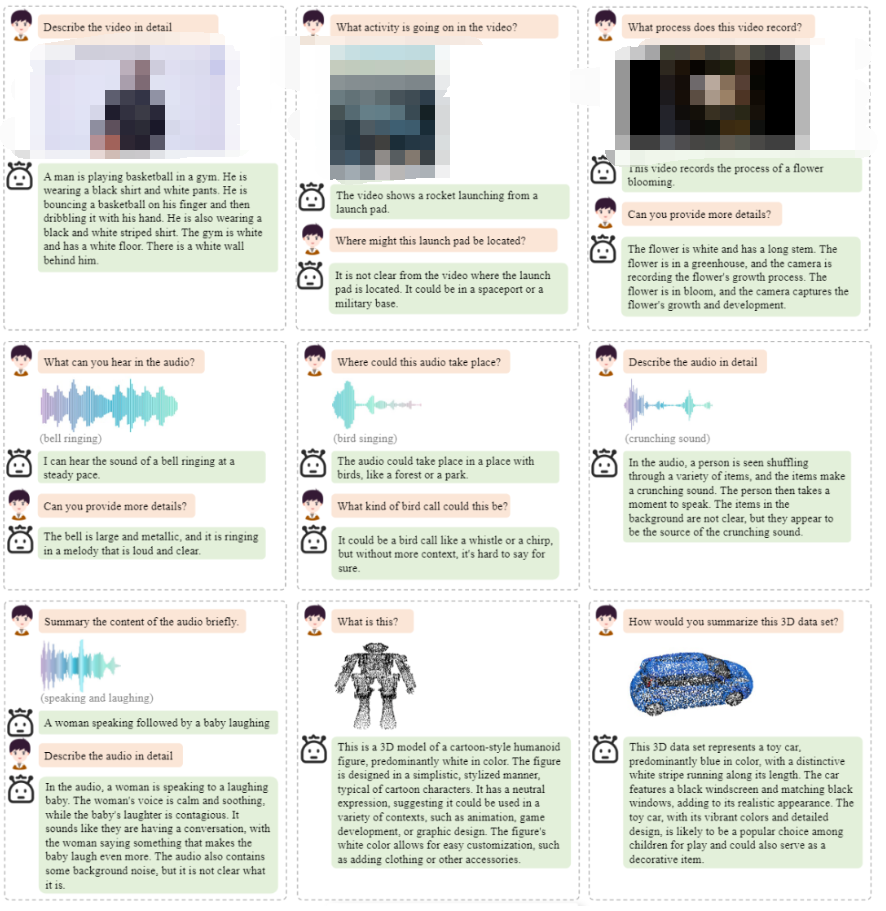
以下是OneLLM框架更多的定性分析結(jié)果。
總結(jié)
在這項(xiàng)工作中,本文介紹了 OneLLM,這是一種 MLLM,它使用一個(gè)統(tǒng)一的框架將八種模式與語言對(duì)齊。最初,訓(xùn)練一個(gè)基本的視覺LLM。在此基礎(chǔ)上,設(shè)計(jì)了一個(gè)具有通用編碼器、UPM 和 LLM 的多模態(tài)框架。通過漸進(jìn)式對(duì)齊pipelines,OneLLM 可以使用單個(gè)模型處理多模態(tài)輸入。此外,本文工作策劃了一個(gè)大規(guī)模的多模態(tài)指令數(shù)據(jù)集,以充分釋放OneLLM的指令跟蹤能力。最后,在 25 個(gè)不同的基準(zhǔn)上評(píng)估 OneLLM,顯示出其出色的性能。
限制與未來工作:本文的工作面臨兩個(gè)主要挑戰(zhàn):
缺乏圖像之外模態(tài)的大規(guī)模、高質(zhì)量的數(shù)據(jù)集,這導(dǎo)致 OneLLM 和這些模式上的專業(yè)模型之間存在一定差距。
高分辨率圖像、長序列視頻和音頻等的細(xì)粒度多模態(tài)理解。未來,將收集高質(zhì)量的數(shù)據(jù)集,設(shè)計(jì)新的編碼器來實(shí)現(xiàn)細(xì)粒度的多模態(tài)理解。
審核編輯:黃飛
-
編碼器
+關(guān)注
關(guān)注
45文章
3772瀏覽量
137092 -
路由器
+關(guān)注
關(guān)注
22文章
3809瀏覽量
115956 -
大模型
+關(guān)注
關(guān)注
2文章
3020瀏覽量
3806 -
LLM
+關(guān)注
關(guān)注
1文章
319瀏覽量
678
原文標(biāo)題:OneLLM:對(duì)齊所有模態(tài)的框架!
文章出處:【微信號(hào):zenRRan,微信公眾號(hào):深度學(xué)習(xí)自然語言處理】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
Allegro Skill布局功能--器件絲印過孔對(duì)齊介紹與演示
電機(jī)聯(lián)軸控制的旋轉(zhuǎn)機(jī)械定轉(zhuǎn)子模態(tài)分析
圖解邊沿對(duì)齊,中心對(duì)齊PWM(可下載)
一種多模態(tài)駕駛場景生成框架UMGen介紹
字節(jié)跳動(dòng)發(fā)布OmniHuman 多模態(tài)框架
Orcad繪制原理圖的元器件對(duì)齊方法


模態(tài)分解合集matlab代碼
商湯日日新多模態(tài)大模型權(quán)威評(píng)測第一
KiCad的對(duì)齊工具不好用?
HarmonyOS NEXT應(yīng)用元服務(wù)開發(fā)Intents Kit(意圖框架服務(wù))綜述
ARM嵌入式系統(tǒng)中內(nèi)存對(duì)齊的重要性

利用OpenVINO部署Qwen2多模態(tài)模型
三相三電平逆變器的中心對(duì)齊SVPWM實(shí)現(xiàn)

鴻蒙ArkTS聲明式開發(fā):跨平臺(tái)支持列表【半模態(tài)轉(zhuǎn)場】模態(tài)轉(zhuǎn)場設(shè)置






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論