") Python軸承故障診斷—基于EMD-CNN的故障分類
Python軸承故障診斷—基于EMD-CNN的故障分類
1 經(jīng)驗模態(tài)分解EMD的Python示例
第一步,Python 中 EMD包的下載安裝:
# 下載
pip install EMD-signal
# 導入
from PyEMD import EMD
切記,很多同學安裝失敗,不是pip install EMD,也不是pip install PyEMD, 如果 pip list 中 已經(jīng)有 emd,emd-signal,pyemd包的存在,要先 pip uninstall 移除相關包,然后再進行安裝。
第二步,導入相關包
importnumpyasnp
from PyEMD import EMD
importmatplotlib.pyplotasplt
importmatplotlib
matplotlib.rc("font", family='Microsoft YaHei')
第三步,生成一個信號示例
t = np.linspace(0, 1, 1000)
signal = np.sin(11*2*np.pi*t*t) + 6*t*t
第四步,創(chuàng)建EMD對象,進行分解
emd = EMD()
# 對信號進行經(jīng)驗模態(tài)分解
IMFs = emd(signal)
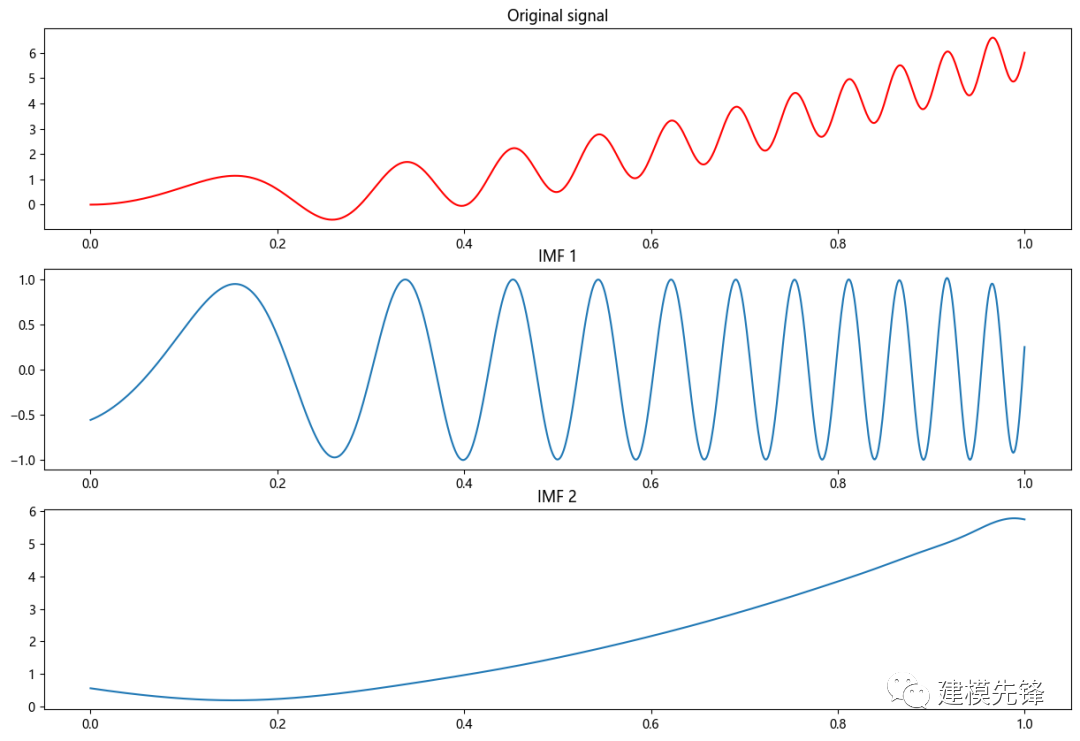
第五步,繪制原始信號和每個本征模態(tài)函數(shù)(IMF)
plt.figure(figsize=(15,10))
plt.subplot(len(IMFs)+1, 1, 1)
plt.plot(t, signal, 'r')
plt.title("原始信號")
fornum, imfinenumerate(IMFs):
plt.subplot(len(IMFs)+1, 1, num+2)
plt.plot(t, imf)
plt.title("IMF "+str(num+1))
plt.show()
2 軸承故障數(shù)據(jù)的預處理
2.1 導入數(shù)據(jù)
參考之前的文章,進行故障10分類的預處理,凱斯西儲大學軸承數(shù)據(jù)10分類數(shù)據(jù)集:
train_set、val_set、test_set 均為按照7:2:1劃分訓練集、驗證集、測試集,最后保存數(shù)據(jù)

上圖是數(shù)據(jù)的讀取形式以及預處理思路
2.2 制作數(shù)據(jù)集和對應標簽
第一步, 生成數(shù)據(jù)集
第二步,制作數(shù)據(jù)集和標簽
# 制作數(shù)據(jù)集和標簽
import torch
# 這些轉(zhuǎn)換是為了將數(shù)據(jù)和標簽從Pandas數(shù)據(jù)結(jié)構(gòu)轉(zhuǎn)換為PyTorch可以處理的張量,
# 以便在神經(jīng)網(wǎng)絡中進行訓練和預測。
def make_data_labels(dataframe):
'''
參數(shù) dataframe: 數(shù)據(jù)框
返回 x_data: 數(shù)據(jù)集 torch.tensor
y_label: 對應標簽值 torch.tensor
'''
# 信號值
x_data = dataframe.iloc[:,0:-1]
# 標簽值
y_label = dataframe.iloc[:,-1]
x_data = torch.tensor(x_data.values).float()
y_label = torch.tensor(y_label.values, dtype=torch.int64) # 指定了這些張量的數(shù)據(jù)類型為64位整數(shù),通常用于分類任務的類別標簽
return x_data, y_label
# 加載數(shù)據(jù)
train_set = load('train_set')
val_set = load('val_set')
test_set = load('test_set')
# 制作標簽
train_xdata, train_ylabel = make_data_labels(train_set)
val_xdata, val_ylabel = make_data_labels(val_set)
test_xdata, test_ylabel = make_data_labels(test_set)
# 保存數(shù)據(jù)
dump(train_xdata, 'trainX_1024_10c')
dump(val_xdata, 'valX_1024_10c')
dump(test_xdata, 'testX_1024_10c')
dump(train_ylabel, 'trainY_1024_10c')
dump(val_ylabel, 'valY_1024_10c')
dump(test_ylabel, 'testY_1024_10c')
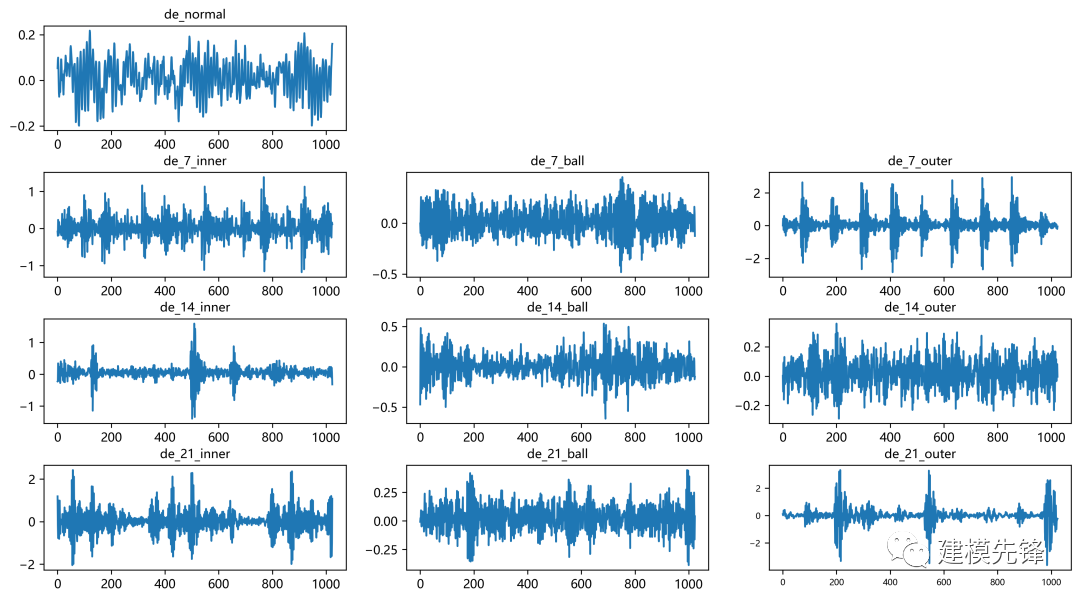
2.3 故障數(shù)據(jù)的EMD分解可視化
選擇正常信號和 0.021英寸內(nèi)圈、滾珠、外圈故障信號數(shù)據(jù)來做對比
第一步,導入包,讀取數(shù)據(jù)
import numpy as np
from scipy.io import loadmat
import numpy as np
from scipy.signal import stft
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rc("font", family='Microsoft YaHei')
# 讀取MAT文件
data1 = loadmat('0_0.mat') # 正常信號
data2 = loadmat('21_1.mat') # 0.021英寸 內(nèi)圈
data3 = loadmat('21_2.mat') # 0.021英寸 滾珠
data4 = loadmat('21_3.mat') # 0.021英寸 外圈
# 注意,讀取出來的data是字典格式,可以通過函數(shù)type(data)查看。
第二步,數(shù)據(jù)集中統(tǒng)一讀取 驅(qū)動端加速度數(shù)據(jù),取一個長度為1024的信號進行后續(xù)觀察和實驗
# DE - drive end accelerometer data 驅(qū)動端加速度數(shù)據(jù)
data_list1 = data1['X097_DE_time'].reshape(-1)
data_list2 = data2['X209_DE_time'].reshape(-1)
data_list3 = data3['X222_DE_time'].reshape(-1)
data_list4 = data4['X234_DE_time'].reshape(-1)
# 劃窗取值(大多數(shù)窗口大小為1024)
time_step= 1024
data_list1 = data_list1[0:time_step]
data_list2 = data_list2[0:time_step]
data_list3 = data_list3[0:time_step]
data_list4 = data_list4[0:time_step]
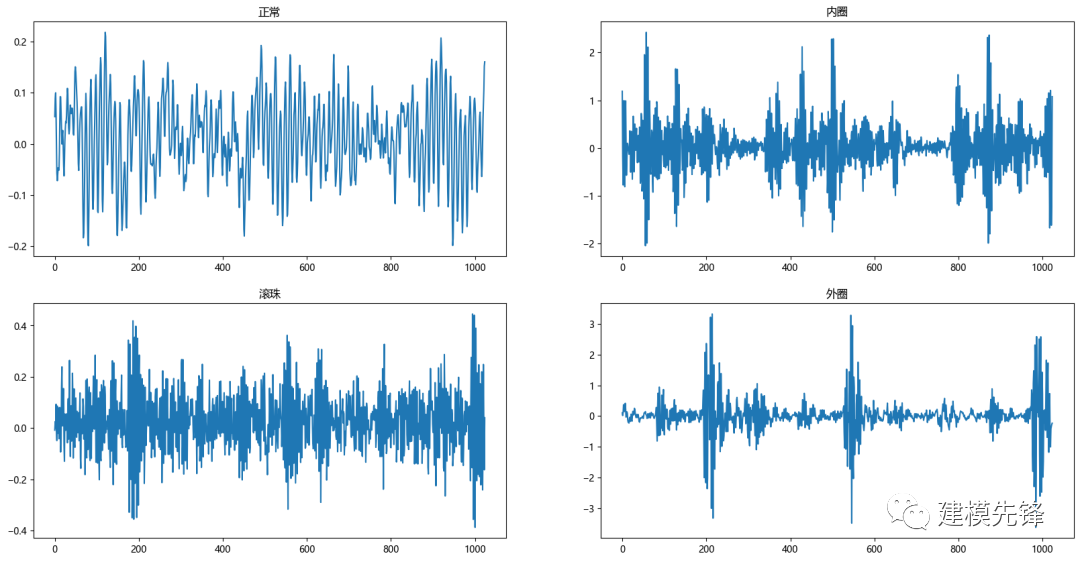
第三步,進行數(shù)據(jù)可視化
plt.figure(figsize=(20,10))
plt.subplot(2,2,1)
plt.plot(data_list1)
plt.title('正常')
plt.subplot(2,2,2)
plt.plot(data_list2)
plt.title('內(nèi)圈')
plt.subplot(2,2,3)
plt.plot(data_list3)
plt.title('滾珠')
plt.subplot(2,2,4)
plt.plot(data_list4)
plt.title('外圈')
plt.show()
第四步,首先對正常數(shù)據(jù)進行EMD分解
import numpy as np
import matplotlib.pyplot as plt
from PyEMD import EMD
t = np.linspace(0, 1, time_step)
data = np.array(data_list1)
# 創(chuàng)建 EMD 對象
emd = EMD()
# 對信號進行經(jīng)驗模態(tài)分解
IMFs = emd(data)
# 繪制原始信號和每個本征模態(tài)函數(shù)(IMF)
plt.figure(figsize=(15,10))
plt.subplot(len(IMFs)+1, 1, 1)
plt.plot(t, data, 'r')
plt.title("Original signal", fontsize=10)
for num, imf in enumerate(IMFs):
plt.subplot(len(IMFs)+1, 1, num+2)
plt.plot(t, imf)
plt.title("IMF "+str(num+1), fontsize=10)
# 增加第一排圖和第二排圖之間的垂直間距
plt.subplots_adjust(hspace=0.4, wspace=0.2)
plt.show()
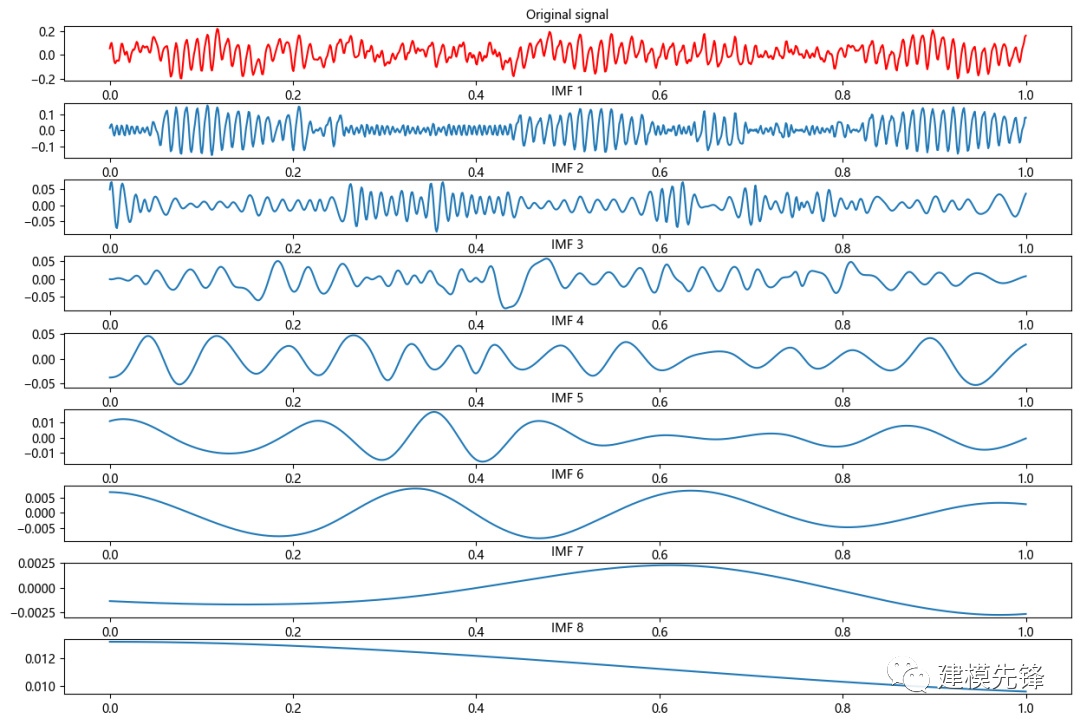
其次,內(nèi)圈故障EMD分解:

然后,滾珠故障EMD分解:
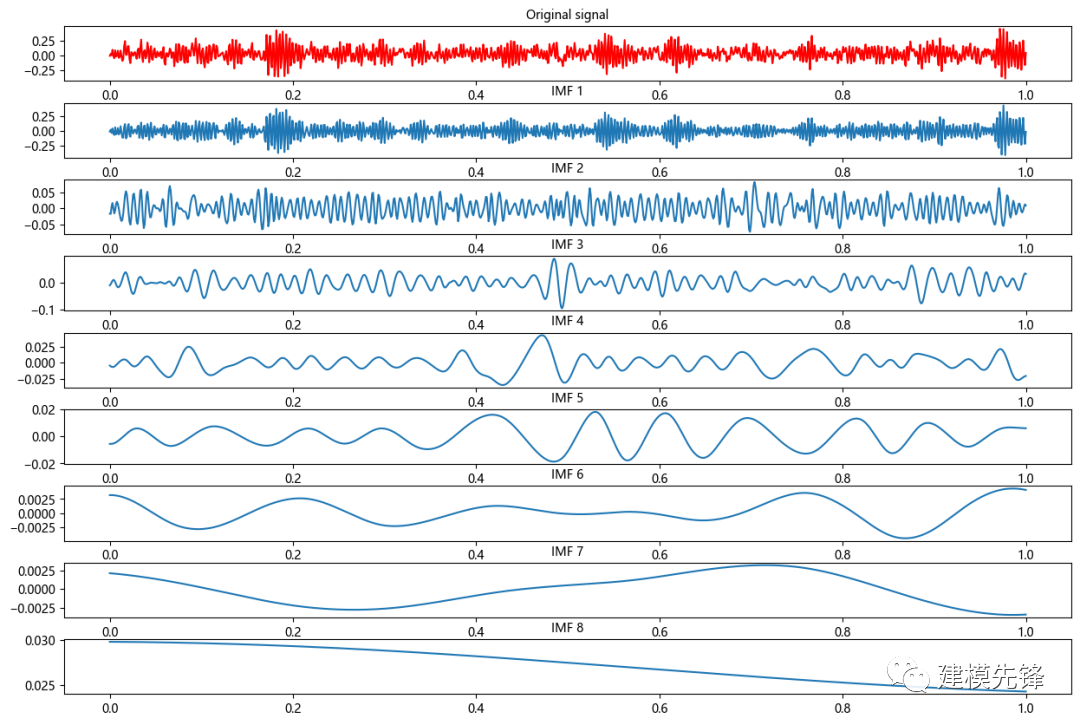
最后,外圈故障EMD分解:

注意,在信號的制作過程中,信號長度的選取比較重要,選擇信號長度為1024,既能滿足信號在時間維度上的分辨率,也能在后續(xù)的EMD分解中分解出數(shù)量相近的IMF分量,為進一步做故障模式識別打下基礎。
2.4 故障數(shù)據(jù)的EMD分解預處理
對于EMD分解出的IMF分量個數(shù),并不是所有的樣本信號都能分解出8個分量,需要做一下定量分析:
import numpy as np
from PyEMD import EMD
# 加載訓練集
train_xdata = load('trainX_1024_10c')
data = np.array(train_xdata)
# 創(chuàng)建 EMD 對象
emd = EMD()
print("測試集:", len(data))
count_min = 0
count_max = 0
count_7 = 0
# 對數(shù)據(jù)進行EMD分解
for i in range(1631):
imfs = emd(data[i], max_imf=8) # max_imf=8
if len(imfs) > 8 :
count_max += 1
elif len(imfs) < 7:
count_min += 1
elif len(imfs) == 7:
count_7 += 1
print("分解結(jié)果IMF大于8:", count_max)
print("分解結(jié)果IMF小于7:", count_min)
print("分解結(jié)果IMF等于7:", count_7)
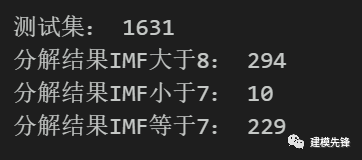
由結(jié)果可以看出,大部分信號樣本 都分解出8個分量,將近1/3的信號分解的不是8個分量。EMD設置不了分解出模態(tài)分量的數(shù)量(函數(shù)自適應),為了使一維信號分解,達到相同維度的分量特征,有如下3種處理方式:
- 刪除分解分量不統(tǒng)一的樣本(少量存在情況可以采用);
- 對于分量個數(shù)少的樣本采用0值或者其他方法進行特征填充,使其對齊其他樣本分量的維度(向多兼容);
- 合并分量數(shù)量多的信號(向少兼容);
本文采用第二、三條結(jié)合的方式進行預處理,即刪除分量小于7的樣本,對于分量大于7的樣本,把多余的分量進行合并,使所有信號的分量特征保持同樣的維度。
3 基于EMD-CNN的軸承故障診斷分類
下面基于EMD分解后的軸承故障數(shù)據(jù),通過CNN進行一維卷積作為的分類方法進行講解:
3.1 訓練數(shù)據(jù)、測試數(shù)據(jù)分組,數(shù)據(jù)分batch
import torch
from joblib import dump, load
import torch.utils.data asData
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
# 參數(shù)與配置
torch.manual_seed(100) # 設置隨機種子,以使實驗結(jié)果具有可重復性
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 有GPU先用GPU訓練
# 加載數(shù)據(jù)集
def dataloader(batch_size, workers=2):
# 訓練集
train_xdata = load('trainX_1024_10c')
train_ylabel = load('trainY_1024_10c')
# 驗證集
val_xdata = load('valX_1024_10c')
val_ylabel = load('valY_1024_10c')
# 測試集
test_xdata = load('testX_1024_10c')
test_ylabel = load('testY_1024_10c')
# 加載數(shù)據(jù)
train_loader = Data.DataLoader(dataset=Data.TensorDataset(train_xdata, train_ylabel),
batch_size=batch_size, shuffle=True, num_workers=workers, drop_last=True)
val_loader = Data.DataLoader(dataset=Data.TensorDataset(val_xdata, val_ylabel),
batch_size=batch_size, shuffle=True, num_workers=workers, drop_last=True)
test_loader = Data.DataLoader(dataset=Data.TensorDataset(test_xdata, test_ylabel),
batch_size=batch_size, shuffle=True, num_workers=workers, drop_last=True)
return train_loader, val_loader, test_loader
batch_size = 32
# 加載數(shù)據(jù)
train_loader, val_loader, test_loader = dataloader(batch_size)
3.2 定義EMDVGG1d網(wǎng)絡模型
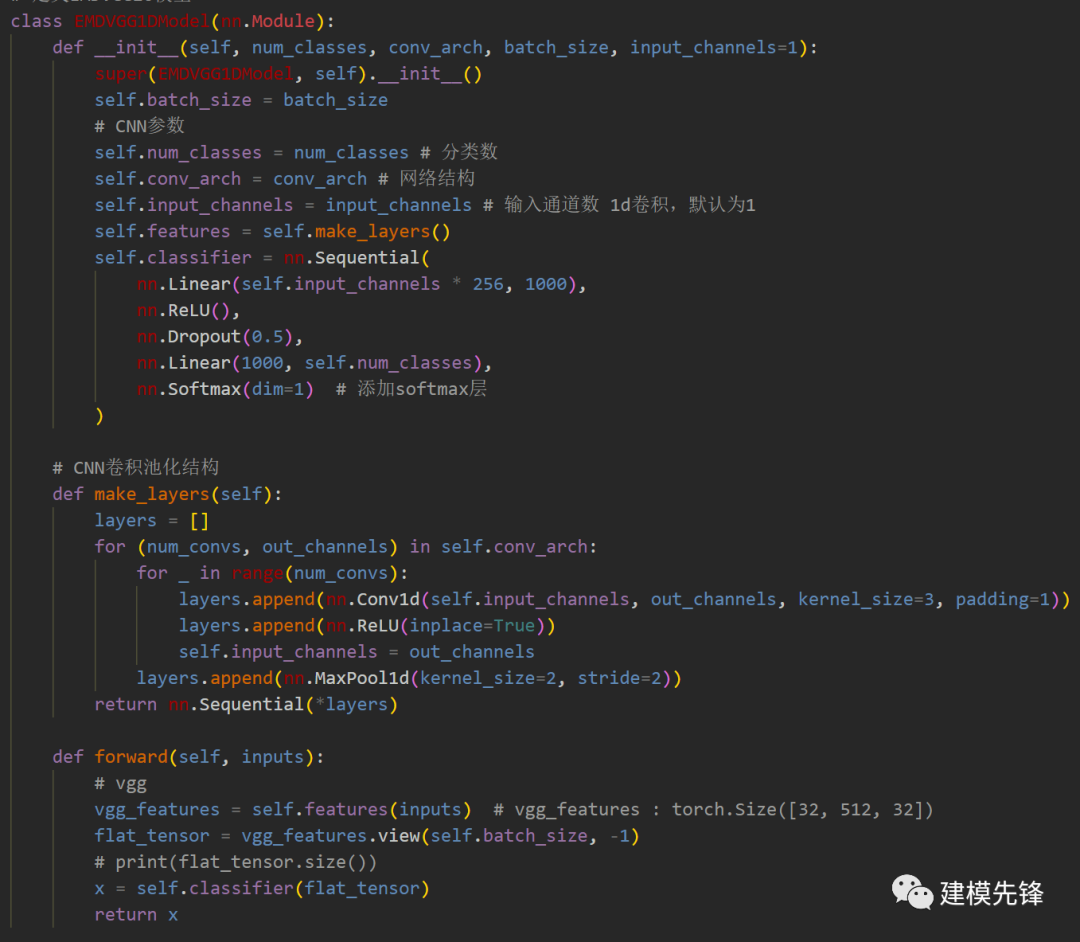
3.3 設置參數(shù),訓練模型
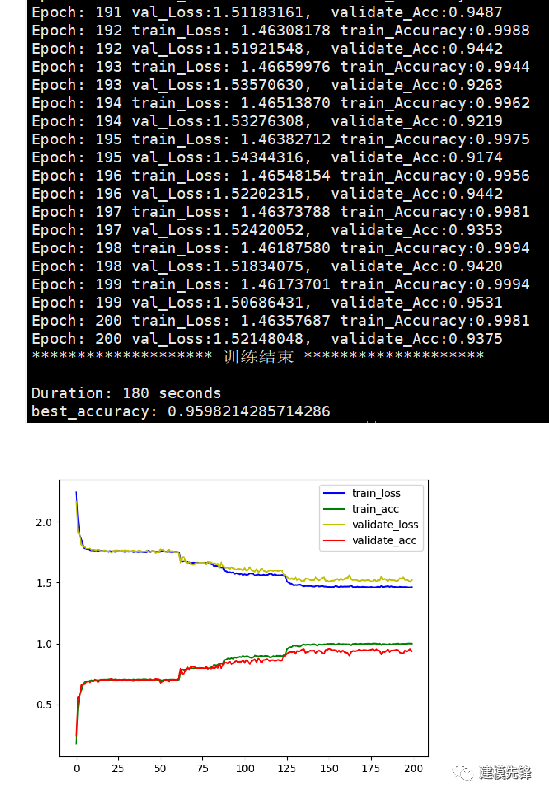
200個epoch,準確率將近96%,用淺層的VGG效果明顯,繼續(xù)調(diào)參可以進一步提高分類準確率。
-
神經(jīng)網(wǎng)絡
+關注
關注
42文章
4806瀏覽量
102706 -
EMD
+關注
關注
1文章
43瀏覽量
20280 -
python
+關注
關注
56文章
4823瀏覽量
86129 -
vgg
+關注
關注
1文章
11瀏覽量
5308
發(fā)布評論請先 登錄
基于labview的軸承故障診斷與健康監(jiān)測
DSP的滾動軸承實時故障診斷系統(tǒng)設
船舶感應電機軸承故障診斷方法的幾點研究
【轉(zhuǎn)】電力電子電路故障診斷方法
【轉(zhuǎn)帖】傳感器的故障分類與診斷方法
傳感器的故障分類與診斷方法
基于DSP+MCU的列車滾動軸承故障診斷系統(tǒng)研究
電機軸承故障診斷與分析
基于matlab的電機故障診斷
基于DSP的滾動軸承實時故障診斷系統(tǒng)設計
滾動軸承故障診斷的實用技巧
滾動軸承故障診斷方法
基于CUDA加速的高速振動信號故障診斷方法






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論