 小模型也能進行上下文學習!字節&華東師大聯合提出自進化文本識別器
小模型也能進行上下文學習!字節&華東師大聯合提出自進化文本識別器
大語言模型(LLM)能夠以一種無需微調的方式從少量示例中學習,這種方式被稱為 "上下文學習"(In-context Learning)。目前只在大模型上觀察到上下文學習現象,那么,常規大小的模型是否具備類似的能力呢?GPT4、Llama等大模型在非常多的領域中都表現出了杰出的性能,但很多場景受限于資源或者實時性要求較高,無法使用大模型。為了探索小模型的上下文學習能力,字節和華東師大的研究團隊在場景文本識別任務上進行了研究。
場景文本識別(Scene Text Recognition)的目標是將圖像中的文本內容提取出來。實際應用場景中,場景文本識別面臨著多種挑戰:不同的場景、文字排版、形變、光照變化、字跡模糊、字體多樣性等,因此很難訓練一個能應對所有場景的統一的文本識別模型。一個直接的解決辦法是收集相應的數據,然后在特定場景下對模型進行微調。但是這一過程需要重新訓練模型,當場景變多、領域任務變得復雜時,實際的訓練、存儲、維護資源則呈幾何倍增長。如果文本識別模型也能具備上下文學習能力,面對新的場景,只需少量標注數據作為提示,就能提升在新場景上的性能,那么上面的問題就迎刃而解。然而,場景文本識別是一個資源敏感型任務,將大模型當作文本識別器非常耗費資源,并且通過初步的實驗,研究人員發現傳統的訓練大模型的方法在場景文本識別任務上并不適用。
為了解決這個問題,來自字節和華東師大的研究團隊提出了自進化文本識別器,ESTR(Ego-Evolving Scene Text Recognizer),一個融合了上下文學習能力的常規大小文本識別器,無需微調即可快速適應不同的文本識別場景。ESTR配備了一種上下文訓練和上下文推理模式,不僅在常規數據集上達到了SOTA的水平,而且可以使用單一模型提升在各個場景中的識別性能,實現對新場景的快速適應,甚至超過了經過微調后專用模型的識別性能。ESTR證明,常規大小的模型足以在文本識別任務中實現有效的上下文學習能力。ESTR在各種場景中無需微調即可表現出卓越的適應性,甚至超過了經過微調后的識別性能。

論文地址:https://arxiv.org/pdf/2311.13120
方法
圖1介紹了ESTR的訓練和推理流程。
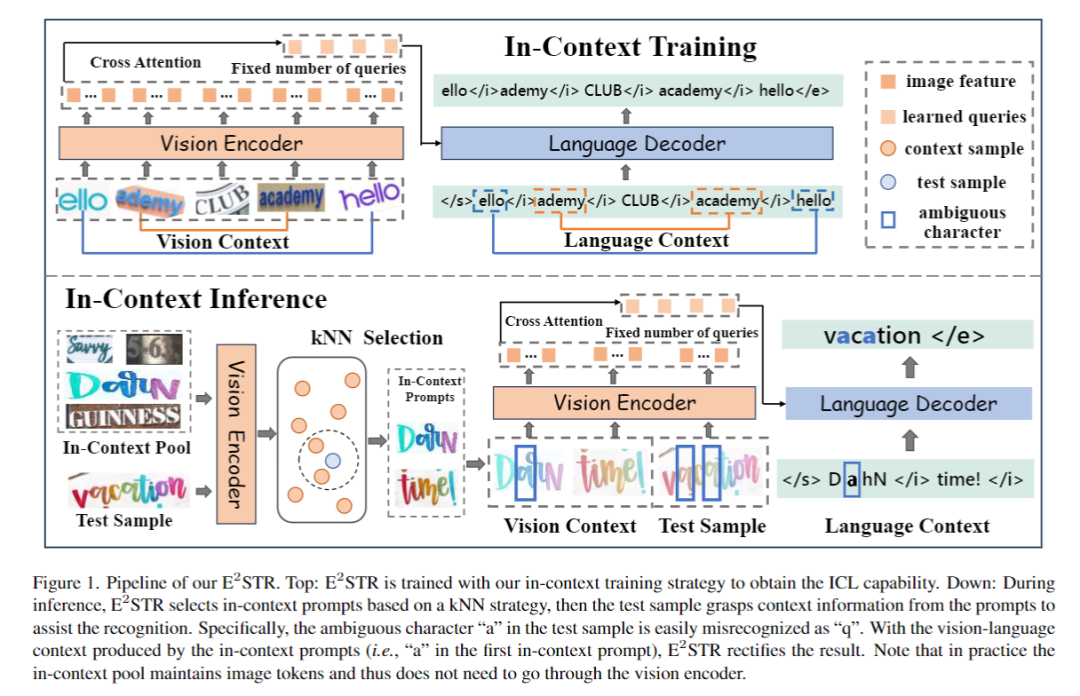
1.基礎文本識別訓練
基礎文本識別訓練階段采用自回歸框架訓練視覺編碼器和語言解碼器:
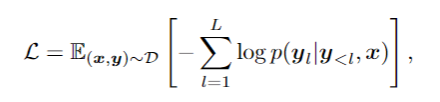
2.上下文訓練
上下文訓練階段ESTR 將根據文中提出的上下文訓練范式進行進一步訓練。在這一階段,ESTR 會學習理解不同樣本之間的聯系,從而從上下文提示中獲益。
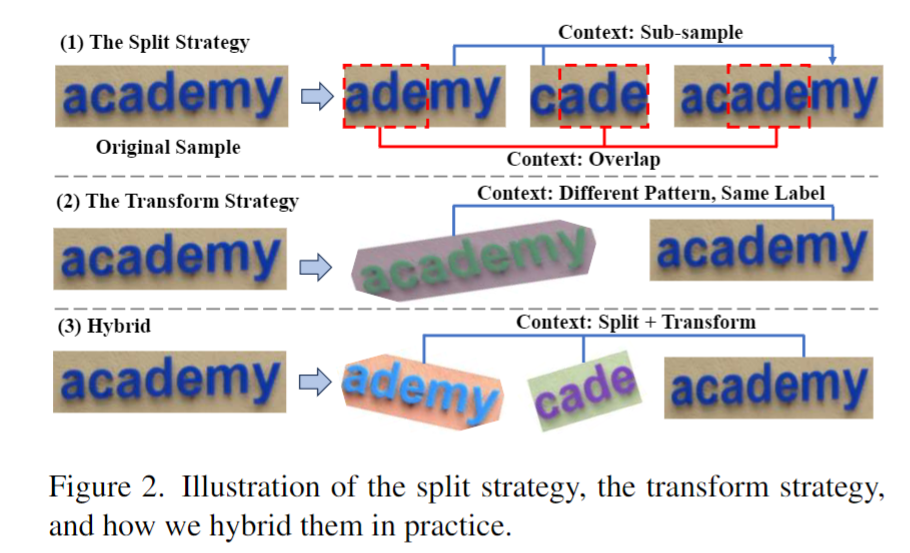
如圖2所示,這篇文章提出 ST 策略,在場景文本數據中進行隨機的分割和轉換,從而生成一組 "子樣本"。子樣本在視覺和語言方面都是內在聯系的。這些內在聯系的樣本被拼接成一個序列,模型從這些語義豐富的序列中學習上下文知識,從而獲取上下文學習的能力。這一階段同樣采用自回歸框架進行訓練:
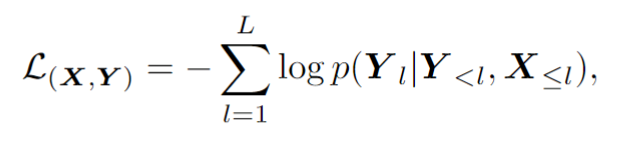
3.上下文推理
針對一個測試樣本,該框架會從上下文提示池中選擇 個樣本,這些樣本在視覺隱空間與測試樣本具有最高的相似度。具體來說,這篇文章通過對視覺token序列做平均池化,計算出圖像embedding 。然后,從上下文池中選擇圖像嵌入與 的余弦相似度最高的前 N 個樣本,從而形成上下文提示。
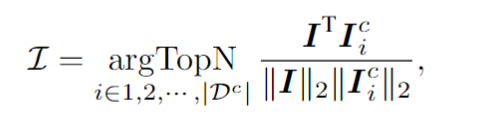
上下文提示和測試樣本拼接在一起送入模型,ESTR便會以一種無訓練的方式從上下文提示中學得新知識,提升測試樣本的識別準確率。值得注意的是,上下文提示池只保留了視覺編碼器輸出的token,使得上下文提示的選擇過程非常高效。此外,由于上下文提示池很小,而且ESTR不需要訓練就能直接進行推理,因此額外的消耗也降到了最低限度。
實驗
實驗從三個角度進行:
1.傳統數據集
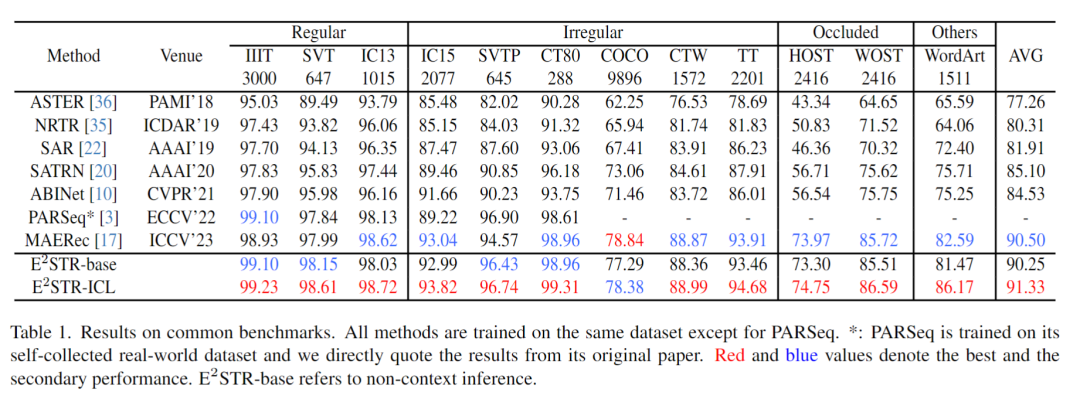
從訓練集中隨機抽取很少的樣本(1000個,訓練集 0.025% 的樣本數量)組成上下文提示池,在12個常見的場景文本識別測試集中進行的測試,結果如下:
2.跨域場景
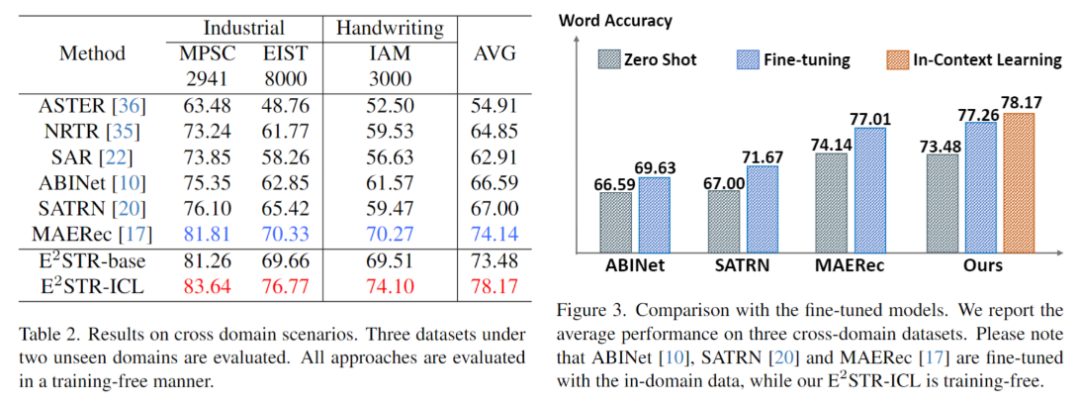
跨域場景下每個測試集僅提供100個域內訓練樣本,無訓練和微調對比結果如下。ESTR甚至超過了SOTA方法的微調結果。
3.困難樣本修正
研究人員收集了一批困難樣本,對這些樣本提供了10%~20%的標注,對比ESTR的無訓練學習方法和SOTA方法的微調學習方法,結果如下:
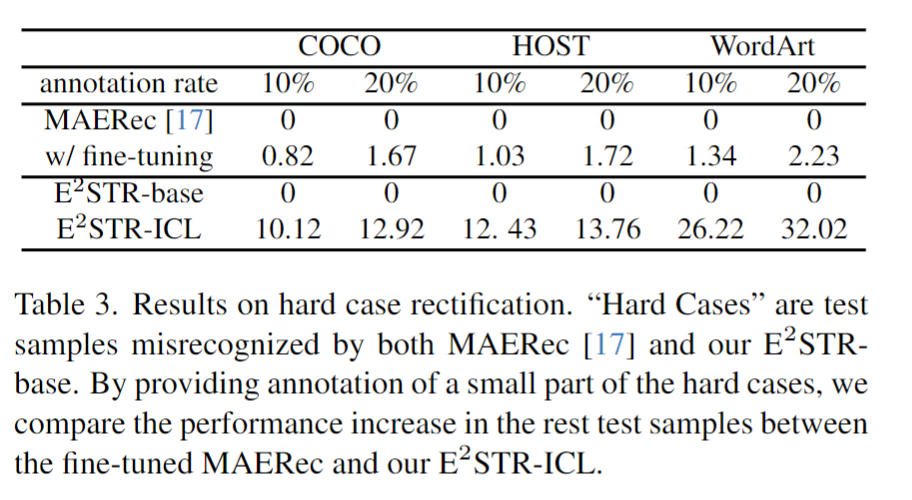
可以發現,ESTR-ICL大大降低了困難樣本的錯誤率。
未來展望
ESTR證明了使用合適的訓練和推理策略,小模型也可以擁有和LLM類似的In-context Learning的能力。在一些實時性要求比較強的任務中,使用小模型也可以對新場景進行快速的適應。更重要的是,這種使用單一模型來實現對新場景快速適應的方法使得構建統一高效的小模型更近了一步。
-
模型
+關注
關注
1文章
3483瀏覽量
49962 -
識別器
+關注
關注
0文章
21瀏覽量
7701 -
大模型
+關注
關注
2文章
3020瀏覽量
3805
原文標題:小模型也能進行上下文學習!字節&華東師大聯合提出自進化文本識別器
文章出處:【微信號:CVer,微信公眾號:CVer】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
S32K在AUTOSAR中使用CAT1 ISR,是否需要執行上下文切換?
DeepSeek推出NSA機制,加速長上下文訓練與推理
【「基于大模型的RAG應用開發與優化」閱讀體驗】RAG基本概念
【「基于大模型的RAG應用開發與優化」閱讀體驗】+Embedding技術解讀
【「基于大模型的RAG應用開發與優化」閱讀體驗】+大模型微調技術解讀
《具身智能機器人系統》第7-9章閱讀心得之具身智能機器人與大模型
Kaggle知識點:使用大模型進行特征篩選

Llama 3 語言模型應用
AI大模型在自然語言處理中的應用
onsemi LV/MV MOSFET 產品介紹 &amp;amp; 行業應用

SystemView上下文統計窗口識別阻塞原因
【《大語言模型應用指南》閱讀體驗】+ 基礎知識學習
FS201資料(pcb &amp; DEMO &amp; 原理圖)
超ChatGPT-4o,國產大模型竟然更懂翻譯,8款大模型深度測評|AI 橫評

鴻蒙Ability Kit(程序框架服務)【應用上下文Context】





 工商網監
工商網監
評論