 文生圖大型實踐:揭秘百度搜索AIGC繪畫工具的背后故事!
文生圖大型實踐:揭秘百度搜索AIGC繪畫工具的背后故事!
自從進入 2023 年以來,AIGC 技術已催生了新一輪人工智能浪潮。AI 繪畫作為大模型最引人矚目的應用領域之一,近年來也取得了重大突破。AI 繪畫系統可以根據用戶的輸入或提示生成各種風格的圖像,這為藝術家、設計師和創作者提供了強大的工具,也為數字創意領域帶來了新的可能性。在本期“極客有約”對話節目中,魚哲和百度搜索主任架構師 TianBao 就圖像生成技術進行了深入探討,包括百度搜索的應用場景、相關技術的思考,以及在搜索業務場景的應用落地經驗。
亮點:
這是一個巨大的變革,從過去用戶在全網尋找圖像,轉變為結合了查找圖像和生成圖像兩種方式,以滿足用戶更具體的需求,這也在一定程度上鼓勵用戶更主動地表達他們真正的需求。
要使一個模型更好地理解中文,準備和清理與中文語義相關的語料非常重要。
對于去除低質量樣本和構建高價值樣本,這些都是圖文對齊所必需的能力。
百度搜索需要滿足用戶在內容和風格方面多樣化的需求,因此在百度搜索目前支持上千種不同的畫面風格定義。
遵循美學標準,構建自己的美學認知,無論是在整體模型構建方面還是在算法優化方面,都需要按照這些先進標準來進行相關的指導和評估。
文生圖的技術發展過程
魚哲:AIGC 從去年 9 月到現在,我們能看到各種各樣的模型和公司不斷涌現。從最初大家使用 Stable Diffusion 來生成簡單的圖像,到后來用一些其它方法進行生成式圖像編輯,后來甚至 Adobe Photoshop 支持使用自然語言方式修改圖片。我覺得從之前看到的 AIGC 在生成文本方面取得的成就之外,還有更多有趣的應用領域。除了生成圖片,還能夠生成視頻和音頻。最近,我也看到了一些令人驚艷的生成視頻產品。今天想請 TianBao 老師跟大家展開介紹一下文生圖技術目前的整體發展趨勢是什么樣的。
TianBao:2022 年可以算是文生圖的元年,整體上分為以 Stable Diffusion 為代表的開源的流派,以及 Midjourney 、Adobe 的 Firefly、Dall-E 3 為代表的閉源模型。而之所以說這一年是元年,是源于 Disco Diffusion。Disco Diffusion 的目標主要是 landscape 等風景類創作,風景類場景是一個容錯率比較高的場景,并結合了富有視覺沖擊的色彩,極具藝術質感,這在 2021 年底至 2022 年初,是一個很大膽、很驚艷的一個嘗試。
直到 2022 年 2 月,Midjourney 發布了 v1 版本。v1 的整體效果相當令人吃驚,但在生成人像方面還差強人意。直到同年 7 月中旬,Midjourney v3 才能正常地生成一些常規人像。在 8 月份時,作品《太空歌劇院》就通過 Midjourney v3 進行生成,加上 Photoshop 的后期處理,這使得 Midjourney 成功引起了轟動。
stable-diffusion 1.5 版本也在同一時期開源,這個開源事件具有里程碑的意義,因為從那時起,像 C 站這樣的更多用戶開始涌向去中心化的模型和優化領域。隨著開源技術的發展,整個生態系統,包括下游應用,都經歷了爆發式增長和涌現。之后,技術的進步以及下游應用的發展持續在相互促進。
百度文生圖的探索和成果
魚哲:我大致還記得 Stable Diffusion 剛開始的效果并不太好,例如在嘗試生成人像時,出現了很多扭曲的結果,如一個人有三條腿或多個眼睛。隨著時間推移,這一技術逐漸變得更加逼真。同時,類似 Civitai 的 AI 技術也興起,允許人們根據他們的圖像進行各種場景的創作,比如受歡迎的原神系列。這種生成圖像技術的發展催生了多種應用。比如,在抽卡類游戲中,原畫師可以利用這一技術來創建游戲組件。在百度搜索等國民級應用中,文生圖又如何與場景相結合的?剛開始,我理解它可能是在搜索框中,用戶輸入關鍵詞后能夠找到相關的圖像,但我相信你們會有更多不同的創新。
TianBao:早期,百度也進行了一些 AIGC 圖像生成的嘗試。正如剛才和大家討論的,文生圖技術從最初的結果不夠可用,逐漸變得可用,并能夠釋放想象力,帶來了引人注目的視覺沖擊。對于搜索,用戶以前要找一張圖片,通常會進行文本搜索。例如,一個戴著太陽鏡和帽子的貓,做著憤怒的手勢,用戶在腦海中構想的畫面,他們通常只能在全網中搜索到已經被創作好的、可感知的內容。但對于一些更具體的場景,比如貓要做著憤怒的手勢,穿著特殊服飾,如果全網沒有人創作這種圖片,用戶需求的滿足就會受到限制,導致需求退化成尋找一個憤怒的貓,之后,他們將變成瀏覽型需求,查看全網上是否有類似的憤怒的貓來滿足他們的需求。
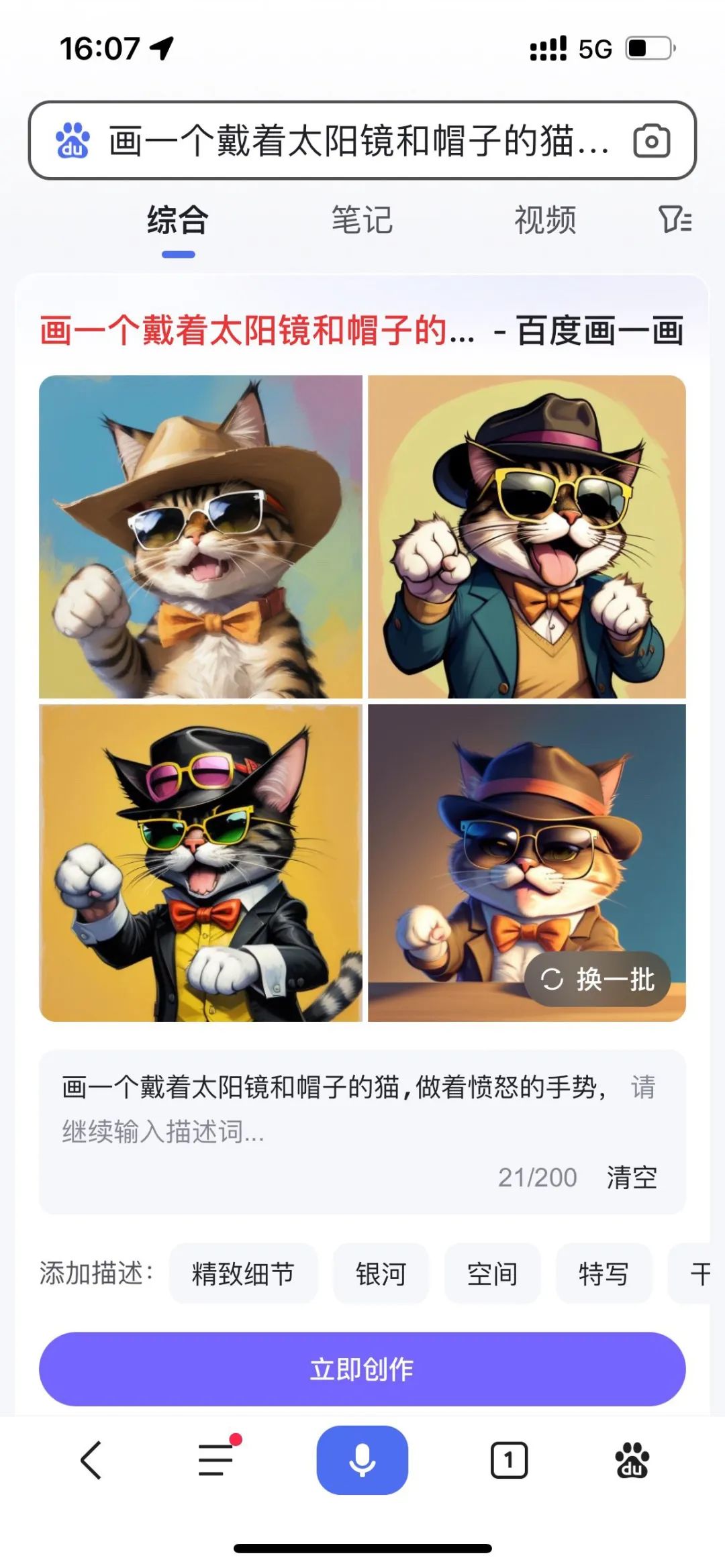
然而,隨著生成式技術的迅速發展,我們現在有能力將用戶腦海中的圖像具體呈現出來,以滿足他們的需求。我們將用戶的查找需求,轉變為結合了查找圖像和生成圖像兩種方式,以滿足用戶更具體的需求,這也在一定程度上鼓勵用戶更主動地表達他們真正的需求。在產品方面,用戶可以通過百度的 App,搜索"畫一個憤怒的貓"或者"畫一畫",然后進入文生圖的相關功能頁面,大家可以親自體驗一下。
尋找一張圖片是搜索的第一步。在圖像領域,許多創作者首先需要找到適合他們需求的圖像,然后他們可能需要用這張圖像作為頭像,或者用它作為創作素材,或者在工作中使用它。因此,在生成的過程中,我們正在加入編輯工作,例如修復(inpainting)、擴展(outpainting)。舉個例子,如果畫面中有一只戴著帽子的貓,通過自然語言交互,我們可以將貓替換為一只狗,從而增加了圖像的再利用能力。這背后通常會涉及一個基于文生圖的預訓練大模型,用于圖像編輯。整體而言,從最初的尋找圖像,變成了“找圖”加“生圖”的過程,然后進入到第二個階段,即圖像的用途,以滿足用戶在圖像領域的需求。
文生圖的實踐及挑戰
魚哲:聽起來這是一個非常有趣的應用場景,因為很多時候,比如我以前制作 PPT 時,需要找到能滿足我的想象場景的圖像,例如客戶使用產品的場景或某個行業的照片。然而,我又不希望侵犯版權,或者避免涉及各種圖像來源的糾紛。在這種情況下,能夠找到圖像,并在此基礎上進行 inpainting 修改、邊框補全,甚至進行圖像超分辨率處理,這實際上是一個非常實用的應用場景。
外界可能認為我們只支持一些基本的圖像生成和編輯功能,如生成、簡單編輯、邊框展開以及高分辨率圖像的補全。但實際上,根據我的了解,這項技術在中文語境下是相當具有挑戰性的。特別是針對中文文化和語義場景,大部分模型通常是在以英語為基礎的語境下進行訓練的,其原始語料庫也是英語為主。然而,百度作為中文搜索引擎領域的巨頭,需要處理中文和英文,甚至一些方言的情況,面對這種挑戰是如何應對的?
TianBao:作為最大的中文搜索引擎,百度在理解中文方面具有更強的優勢,包括對中文特有元素、中文習慣表達以及方言的理解。要使一個模型更好地理解中文,準備和清理與中文語義相關的語料顯然是不可或缺的步驟。
我們在搜索領域擁有感知全網最全的中文語料的能力,這是天然優勢。但除此之外,還需要進行樣本的清理、更全面的知識覆蓋、獲取更多多樣性的高質量樣本等,以更好地理解整體模型的語義。同時,如果我們希望模型生成的圖像質量更高,就需要考慮圖像質量、美學因素,例如圖像中物體的明顯特征和美學風格的準確呈現。此外,還需要進行去重處理,這些都需要有基礎的算子能力支持。
所以對于清洗來說,底層基礎算子的基建也是一個非常重要的工作。百度在圖片基礎層面的刻畫體系上有多年的積累,所以我們在收錄的數據優勢之上,可以快速根據模型的不同目標,進行樣本的組織和篩選。例如,我們想要更好的語義樣本,要做到樣本的均衡,要積累不同等級質量和美觀度的樣本,包括一些人像或者是特殊的 IP 概念等。我們對這些樣本進行快速學習,而后應用在模型里。
魚哲:對于生成圖像大模型,一方面,在訓練過程中,我們需要準備高質量的數據集,建立一個良好的基礎。另一方面,用戶在使用時可能會提供各種各樣的復雜描述,例如描述一個杯子,用戶可能會加入很多形容詞,比如高的、透明的、藍色的,里面裝了一只蟋蟀等,這些描述詞可能超出了標準模型支持的 Token 長度。特別是在中文語境中,用戶的描述可能更長,就像您剛才提到的,一只戴著帽子、站在山峰頂、吹著西北風、雪花在背后飄落的貓。在這種情況下,如何處理具有大量描述詞和形容詞的圖像是一個挑戰嗎?
TianBao:這是一個非常好的問題。圖文配對的質量非常重要。目前,大家主要關注的是開源的 Laion-5b,一個包含 50 億樣本的英文模型,主要基于英文數據集,中文數據相對較少。同時,從這個數據集中,我們也觀察到許多不相關的圖文對的問題,這些問題可能是由一些雜質引起的。因此,我們需要使用相關性建模算法來過濾掉這些不相關的圖文對。
對于使用中文數據集,例如 Laion-5b,有一種較快速的方法,即通過英文翻譯成中文。然而,這種方法可能會引入很多語言上的歧義,特別是中英文之間表達上的歧義,以及中文所特有的一些語義。例如,如果我們將"transformer"翻譯成中文,它可能會變成"變壓器",而如果是指一個頭像,對應的英文可能會是"阿凡達"。這些情況都是由于中文語料建設不足導致的中文理解能力上的不足。關于剛才提到的圖文對的相關性質量問題,過濾低質量的圖文對,需要使用類似于常規的 CLIPScore 等方式來度量圖文的相關性。
另一個方向是在優質數據集的構建上。畢竟,一張圖片可以被非常詳細地描述成上百個字,而當前互聯網上這種詳細描述的數據還相對較少。當前互聯網上的描述通常較為簡短,可能只包含幾十個標記,甚至更短。因此,在構建優質數據集方面,需要將一些高質量的圖像與文本描述的力度和視角相結合,以進行文本描述的補充。通常,人們描述的可能是圖像的主體和意境,但他們可能會忽略掉圖像中的背景、物體的數量以及基本實體的描述。因此,如何實現圖像和文本的對齊理解對于文生圖的構建非常重要。
因此,對于提供高質量樣本的問題,可能需要更適合于圖像生成任務的模型,例如 caption 生成模型。百度在這方面積累了一些經驗,所以對于去除低質量樣本和構建高價值樣本,這些都是圖文對齊所必需的能力。
圖片美感的評估
魚哲:確實,與我想象的相比,這個處理的復雜度要高得多。您剛才提到的去除低質量、保留高質量的很重要。您所說的低值和高值是指圖像質量對嗎?在生成圖像時,如果要生成一只貓,首先它必須是一只貓,其次重要的是它必須符合美感。它必須符合一只貓的形狀,或者說它必須符合一只狗的形狀,而美感是一個非常主觀的事情。例如,即使是一只貓,有些人喜歡圓圓的、胖胖的、毛發豐富的貓,他們認為最好是長得像個球一樣,但有些人認為貓應該像貓一樣,應該有貓的特征,頭是頭,腿是腿,脖子是脖子。在這種情況下,百度如何處理關于貓應該長成什么樣子的問題呢?

TianBao:對于美學,確實像剛才提到的,它是一個偏主觀的一個感知,其實是千人千面的,大家可能對美的認知是不太一樣的,但是這里面我們其實是期望通過大部分人的美學認知,提出一些美學的定義。
例如,美學的定義通常包括圖像的構圖,整個畫面的結構是什么樣的,還包括色彩的應用,如飽和度、對比度、整體的配色,以及光感,例如在攝影棚中的光線設置,如何為不同場景創造更好和更合適的光感。除了視覺色彩方面的定義,畫面的內容也可以體現美學,例如畫面內容的豐富度或畫面的敘事性,這些都是由畫面內的內容構成的。因此,這些維度形成了更具普世性的美學標準。
我們遵循這些美學標準,然后構建自己的美學認知,無論是在整體模型構建方面還是在算法優化方面,都按照這些先進標準來進行相關的指導和評估。除了美學之外,圖像的清晰度也會影響整體的質感。同時,內容的一致性也很重要,如果看到一只貓有三只腿,內容實體的不一致性將會導致缺陷,從而間接影響圖像的可用性和美感。
魚哲:您剛剛提到內容的一致性,可以展開這個解釋一下這個概念嗎?
TianBao:內容一致性可以大概理解為內容的質量或可用性。比如,如果畫一只手,出現了手部的畸形或畸變,這實際上與我們通常對手的概念不符。這會導致手的實體不一致,因此可以認為它存在質量問題。
文生圖提示工程
魚哲:不同場景和用途對美學要求不同,以戴帽子和太陽鏡的貓為例,用戶可能希望生成不同風格的漫畫,如日漫和美漫,它們在視覺體驗上有顯著差異。美漫通常色彩豐富、輪廓鮮明,而日漫則以黑白為主,視覺沖擊力較強。在保障在內容一致性的要求下,百度是如何在不同風格的情況下,從用戶的 prompt 中獲取相關信息,以支持不同畫風的生成?
TianBao:我們來看一下當前文生成圖的應用場景。目前,在主流的交互中,通常提供了一些明確定義的特定風格選項,如漫畫風格或水彩畫風格。但對于用戶而言,不應該受到過多的限制,例如,如果用戶需要生成一個賽博朋克風格的貓,將其繪制成卡通風格就無法滿足用戶需求。也就是說,用戶不僅可以描述生成畫面中出現的內容,如貓,還可以描述他們期望的畫面風格。因此,百度搜索需要滿足用戶在內容和風格方面多樣化的需求。
在百度搜索中,我們目前支持上千種不同的畫面風格定義。舉例來說,用戶可以將一只貓呈現為水墨畫或卡通畫,也可以將它呈現為鋁制品或雕刻品,甚至以不同的材質。此外,用戶還可以選擇不同的視角,如帶有運動模糊效果、延時攝影效果,或者魚眼和廣角視角等。我們覆蓋了多種不同的風格和分類,因此用戶如果有更具體的風格要求,只需在他們的 prompt 中包含相關風格,即可獲得符合他們期望的畫面并具備相應風格。
魚哲:我還有一個問題,就是關于風格的疊加,是否支持這種操作?例如,能否將魚眼廣角和水墨畫的風格同時應用在圖像上?因為一個是關于畫風,另一個是視角,那如果我們想要將水墨畫與卡通風格結合,這是否也是支持的呢?
TianBao:在模型方面,支持多風格是可行的,這樣可以激發新的風格創意。然而,我們面臨的另一個問題是如何在保持內容一致性的前提下,有效地融合和協調多種風格。因為不同風格之間的差異可能很大,可能會發生一些相互制約的情況,但這確實為用戶提供了更多的實驗和探索機會,可以通過嘗試不同風格的組合,實現更廣泛的創意空間。
魚哲:如果我有多個風格的關鍵詞去描述最后的主體,最后整張圖出來的效果和關鍵詞所在的位置的關聯度大嗎?比如說水墨、卡通風格的貓和卡通、水墨風格的貓,這兩個出來的效果會是一樣的嗎?
TianBao:這個其實就會涉及到剛才說的一個可控性。最基本的,就像剛才提到的貓一樣。它關系到我們如何控制生成的內容,尤其是在涉及到風格方面。實際上,可控性與我們整體的 prompt 方式相關,因為不同的 prompt 方式可以導致不同的結果。有些人可能會提供簡短的提示,可能前后并列會輸入兩個不同的風格,而其他人可能更喜歡更詳細的 prompt 表達方式,比如他們可能希望描述一個場景的畫面,指定特定的風格,或者強調某種風格在生成中的比重。這些都是不同的 prompt 方式,可以影響生成內容的方式。
然后對于這種可控來說,其實現在這種順序上會有一些 Bias。比如 Stable Diffusion 的 prompt 煉丹,也會提及一些,比如怎么寫 prompt,是放到前面好還是后面好,其實本質上是一種控制的能力,理想的話應該不會存在這樣的一些偏差。當然最理想的還是我們可以引導用戶能夠去更精準的去表達自己腦海中的畫面。
魚哲:剛才提到百度支持上千種風格,我想問,這上千種風格是人工梳理的,還是通過模型聚類后自動生成的?對于用戶來說,知道有這么多風格可選可能一開始會覺得有點過多,有點難以選擇。
TianBao:關于風格,基于我們之前提到的,我們對全網內容的感知非常廣泛,因此我們有能力感知到全網存在的各種風格數據。第二點是,我們也依賴于對圖像相關的理解,無論是聚合算法還是風格美觀度的描述,都需要首先有數據,然后通過數據的篩選和識別能力,對這些風格進行自然而然的呈現。這是對風格定義的方式。
另外剛才提到的,比如說我們當前支持上千種風格,對于用戶來說,其實大家可能還是得有一個認知的過程,因為每一種風格可能對于藝術向的用戶來說還是會有比較大的一些驚喜的。比如我們看到某種風格和我們常規看到的畫面有很大的這種區別,也具備很強的視覺沖擊感。所以這里面怎么樣能夠把我們已有的這些風格能夠更好的傳遞給用戶,讓用戶理解這種風格,并且在后續的這些需求滿足創作中能夠應用上這些風格,這其實是需要整體的產品和技術來引導的一個工作。
魚哲:正如你剛提到的,有上千種不同的藝術風格。即使對于非專業和一些專業的美術生來說,通常只了解一兩種風格,比如素描或水墨畫。實際上,很少有人能深入了解這么多不同風格并寫出好的提示詞。那么,當用戶不太了解如何編寫 prompt 提示詞時,我們該怎么處理呢?比如,用戶第一次使用百度,除非有人告訴他們,他們可能不知道支持上千種風格。在這種情況下,我們應該如何處理,并引導他們了解更多有關百度的各種風格以及可以編寫的其他提示詞呢?
TianBao:對于藝術風格和創造性而言,大家更常接觸到關鍵詞"Midjourney",可以將其作為一個例子,來講述一個從零開始激發想象力的過程。在早期的運營推廣中,有些資源并未過多優化提示詞。通常,它們提供了一些相對簡單的提示詞,比如"dog"(狗)。然而,這是建立在 disco 社區基礎之上的,允許所有用戶參與。一些用戶嘗試將他們的提示詞更改為描述一只毛茸茸的狗,而其他用戶可能更喜歡科幻題材,例如一只擁有鐳射眼睛的狗是什么樣子。通過不斷的嘗試,他們會發現在不同的提示詞下可以獲得更引人入勝或有趣的效果。這導致了彼此學習,觀察其他人如何生成內容,如何設置提示詞,以及這會產生什么樣的效果。因此,提示詞的優化逐漸變得流行起來。這個問題對于整個業界,包括百度搜索和文生圖,也是類似的。
對于一般用戶而言,他們可能較少接觸文生圖這個場景。對于初次使用的用戶,通常只是嘗試繪制一只貓或一只小狗,這引出了一個問題,即如何在用戶使用環境相對簡單的情況下,為他們生成更好的效果。
這里就會涉及到 prompt 的擴充或者是改寫。這里有兩種思路,一種是去擴充畫面的內容,類似于內容的一個豐富性或者是故事感。比如剛才說的戴著帽子,然后做著憤怒的手勢的狗,把畫面更具象,其實這是 prompt 的優化所做的一個工作。同樣也可以對風格進行一些擴展,我們可以感知到大部分人對于這個內容之下更喜歡哪些風格,我們就可以通過這種 prompt 來做更多風格的一些擴寫。像剛才說的內容以及在風格上的一些擴寫多樣性之后,就可以極大的去優化畫面的內容豐富度、故事性,以及風格和美觀的程度。所以這里面會涉及到怎么樣把一個簡單的表達的 prompt 的輸入,通過優化的方式變成一個對模型來說效果更好的一組 prompt。
魚哲:有一個更具體的問題需要討論,涉及到 prompt 的改寫。例如,當我們將一個提示從描述一只狗轉變為一只帶帽子的生氣的手勢狗時,用戶實際上無法看到被改寫的部分。我們是否能夠確保每次改寫都是一樣的,或者每次改寫的內容可能略有不同?舉例來說,第一次可能是一只戴帽子的狗,而第二次可能是一只戴眼鏡躺在沙灘上的狗。這個過程是否具有隨機性,或者每次都是固定的?
TianBao:對于 prompt 的改寫來說,其實我們更期望給到用戶更多多樣性、更多豐富的結果。因為如果是一條狗的話,我們可以想象到的是一個主體是一條狗,可能會有不同的一些犬類的品種,但是狗可能穿著不同服飾出現在不同場景之下,這個對更多人來說會有更多樣的一些結果,大家會有更多的預期。所以在模型層面,我們期望通過 prompt 這種改寫和優化,有更多的多樣性的備選,然后基于用戶實際的反饋,去來感知用戶對哪些風格,對什么類型的內容場景的一個畫面結果會感興趣,后驗反饋會比較高,這對于整體的 prompt 的改寫模型也會有數據促進的作用。
反饋和評估
魚哲:剛剛提到了改寫,從用戶側收集反饋來迭代模型,有一個詞叫做 RLHF(Reinforcement Learning from Human Feedback)。這里我覺得最難的點是 human feedback 是不穩定的,因為人與人之間的主觀觀點會差很多。如果我們需要依賴人的反饋來去迭代模型,其實是比較困難的。如果再落實到說模型的 evaluation 上來說,在這種情況下,百度是如何去 manage balance,在圖像生成的方向上去做評估。
TianBao:關于后驗反饋,首先需要考慮反饋數據是否確實能夠代表人類的后驗反饋,這對于反饋質量有更高的要求。因此,可以將這一方面與產品的整體設計和用戶交互相結合,以收集更多積極的用戶行為反饋。例如,當用戶對某個結果感興趣時,他們可能會點擊圖片以進行放大查看,然后進行下載等后續行為,這些都是積極的反饋。如果用戶對某張圖片點贊或進行評論,也提供了直接的反饋。我們希望在整個反饋系統中更有效地收集這些反饋,因為它們實際上反映了用戶的偏好。至于模棱兩可的反饋,只能通過更大的樣本量來收集更具代表性的數據。
魚哲:過去,無論是傳統的統計機器學習還是標準的深度學習模型,基本上都是監督學習,需要樣本或監督來計算 F1 分數、IQZ 和 VCR 等指標。然而,對于生成式模型,如 GPT 系列模型或 DALL-E 這樣的生成式模型,技術上并沒有像以前那樣的標準基準數據集,大家可以根據這些基準數據集來生成和評估。相比之下,生成式模型需要一種更高效的評價方法,而不是依賴人工逐個觀察。在這個領域,與其讓人們用肉眼逐個觀察,是否有方法可以更高效地進行評估呢?
TianBao:更高效的方法實際上更多地涉及到人機結合的手段。就像之前提到的圖像評價,我們可以通過一些初步的機器指標來進行觀察。如果我們關注整體的相關性或質量美觀度,那么在某些機器指標上可以進行一些刻畫。但如果需要精確評估兩張圖片之間的差異,這些機器指標可能并不具備太大的意義,更需要人工進行判斷。前面提到的機器初步評估可以幫助人們進行初步的篩選,從而在人工評價方面節省一些勞動力。
未來展望
魚哲:好的,接下來的問題稍微展望未來,盡管并不是非常遙遠,因為最近我看到許多初創團隊和相關公司正在嘗試這個領域。以動畫為例,動畫實際上是將多幅圖像的幀疊加在一起呈現的。通常,動畫電影以每秒 24 幀或 16 幀的速度播放。除了靜態單幅圖像的編輯,我們可以看到在 AIGC 領域,對于視頻生成或短視頻生成,無論是三秒還是七八秒的視頻,都在不斷發展。之前 Runway 團隊曾舉辦了一個使用文生圖進行視頻生成的比賽。您認為在未來多久內,我們會看到第一部完全由 AI 生成的電影或電影狀態?
TianBao:簡要回顧一下圖像生成,在 2022 年初,圖像生成效果并不是特別理想,但到了 2022 年的七八月份,整體變得更加可行。根據技術發展趨勢,對于動態圖或視頻的生成,預計不會太久就會迎來技術的飛速發展。因為最近在視頻生成領域還有很多探索,無論是基于可控生成的方法還是像 Runway 這樣生成幾秒小短片的方法。對于幾秒小短片,大家通常會將生成的最后一幀作為下一段的第一幀,以實現更連貫的長視頻。然而,對于視頻生成來說,面臨更大的挑戰,因為它不僅要保證空間效果,還需要確保時間上的一致性,這引入了一個額外的維度,對技術要求更高。隨著最近對視頻生成的不斷探索,我們可以預計未來一到兩年內可能會出現類似于 Stable Diffusion 這樣革命性的時刻。
-
百度
+關注
關注
9文章
2324瀏覽量
91785 -
模型
+關注
關注
1文章
3483瀏覽量
49955 -
AIGC
+關注
關注
1文章
383瀏覽量
2194
原文標題:文生圖大型實踐:揭秘百度搜索 AIGC 繪畫工具的背后故事!
文章出處:【微信號:AI前線,微信公眾號:AI前線】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
百度搜索接入DeepSeek,業內人士開始擔心

百度地圖在汽車智能化領域的應用實踐
百度搜索全量接入DeepSeek-R1滿血版

百度搜索全量上線DeepSeek滿血版
百度搜索全量上線DeepSeek滿血版,開啟AI搜索新體驗
百度搜索與文心智能體平臺接入DeepSeek及文心大模型深度搜索
百度百科啟動“繁星計劃”
李彥宏:大模型行業消除幻覺,iRAG技術引領文生圖新紀元
百度文心一言APP升級為文小言
百度聯合英偉達舉辦全球規模最大智能體大賽
百度前高管景鯤與朱凱華創立AI搜索公司,Genspark產品驚艷上線
百度搜索AI生成內容占比達11%
百度搜索、文庫等全新升級!以智能體為支點,撬動時代紅利






 工商網監
工商網監
評論