 無鎖隊列解決的問題
無鎖隊列解決的問題
為什么需要無鎖隊列
無鎖隊列解決了什么問題?無鎖隊列解決了鎖引起的問題。
cache失效
當CPU要訪問主存的時候,這些數據首先要被copy到cache中,因為這些數據在不久的將來可能又會被處理器訪問;CPU訪問cache的速度要比訪問內存要快的多;由于線程頻繁切換,會造成cache失效,將導致應用程序性能下降。
阻塞引起的CPU浪費
mutex是阻塞的,在一個負載較重的應用程序中使用阻塞隊列來在線程之間傳遞消息,會導致頻繁的線程切換,大量的時間將被浪費在獲取mutex,而不是處理任務上。
這就需要非阻塞來解決問題。任務之間不爭搶任何資源,在隊列中預定一個位置,然后在這個位置上插入或提取數據。這種機制使用了cas(compare and swap)的操作,它是一個原子操作,需要CPU指令支持。它的思想是先比較,再賦值。具體操作如下:它需要3個操作數,m,A, B,其中m是一個內存地址,將m指向的內存中的數據與A比較,如果相等則將B寫入到m指向的內存并返回true,如果不相等則什么也不做返回false。
cas語義如下
if (a == b) {
a = c;
}
cmpxchg(a, b, c)
bool CAS( int * pAddr, int nExpected, int nNew )
atomically {
if ( *pAddr == nExpected ) {
*pAddr = nNew ;
return true ;
}
return false ;
}
內存的頻繁申請和釋放
當一個任務從堆中分配內存時,標準的內存分配機制會阻塞所有與這個任務共享地址空間的其它任務(進程中的所有線程)。malloc本身也是加鎖的,保證線程安全。這樣也會造成線程之間的競爭。標準隊列插入數據的時候,都回導致堆上的動態內存分配,會導致應用程序性能下降。
小結
- cache失效
- 阻塞引起的CPU浪費
- 內存的頻繁申請和釋放
這3個問題,本質上都是由于線程切換帶來的問題。無鎖隊列就是從這幾個方面解決問題。
無鎖隊列使用場景
無鎖隊列適用于隊列push、pop非常頻繁的場景,效率要比mutex高很多; 比如,股票行情,1秒鐘至少幾十萬數據量。
無鎖隊列一般也會結合mutex + condition使用,如果數據量很小,比如一秒鐘幾百個、幾千個消息,那就會有很多時間是沒有消息需要處理的,消費線程就會休眠,等待喚醒;所以對于消息量很小的情況,無鎖隊列的吞吐量并不會有很大的提升,沒有必要使用無鎖隊列。
無鎖隊列的實現,主要分為兩類:
- 鏈表實現;
- 數組實現。
鏈表實現有一個問題,就是會頻繁的從堆上申請內存,所以效率也不會很高。
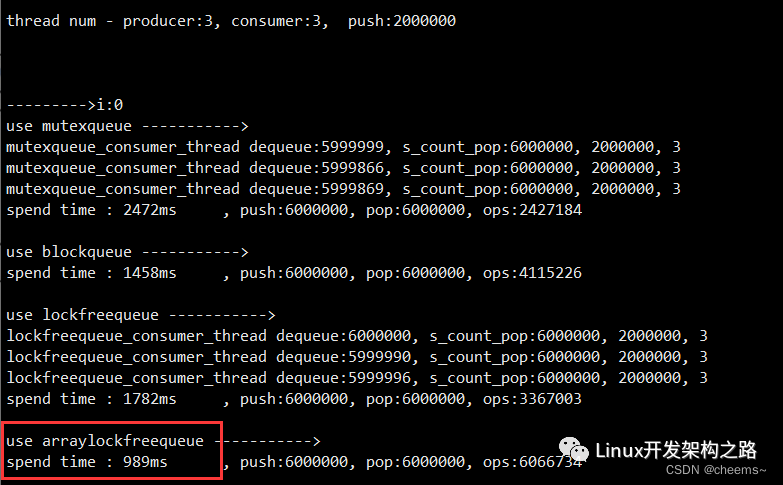
對于一寫一讀場景下,各種消息隊列的測試結果對比:
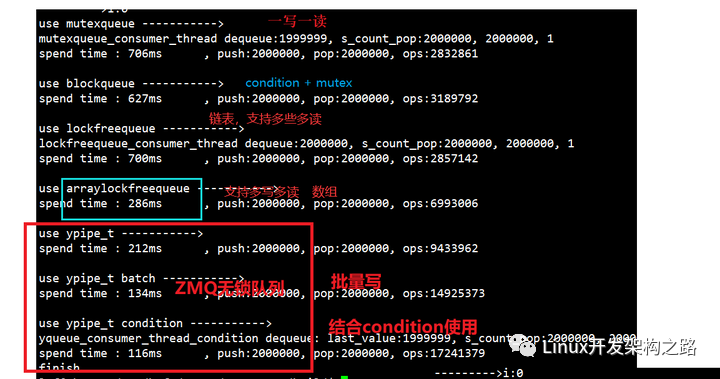
zmq無鎖隊列的實現原理
zmq中實現了一個無鎖隊列,這個無鎖隊列只支持單寫單讀的場景。zmq的無鎖隊列是十分高效的,號稱全世界最快的無鎖隊列。它的設計是非常優秀的,有很多設計是值得借鑒的。我們可以直接把它用到項目中去,zmq只用了不到600行代碼就實現了無鎖隊列。
zmq的無鎖隊列主要由yqueue和ypipe組成。yqueue負責隊列的數據組織,ypipe負責隊列的操作。
原子操作函數
無鎖隊列的實現,一定是基于原子操作的。
zmq無鎖隊列使用如下原子操作函數
template class atomic_ptr_t
{
public:
inline void set (T *ptr_); //非原子操作
inline T *xchg (T *val_); //原子操做,設置新值,返回舊值
inline T *cas (T *cmp_, T *val_);//原子操作
private:
volatile T *ptr;
}
set函數,把私有成員ptr指針設置成參數ptr_的值,不是一個原子操作,需要使用者確保執行set過程沒有其他線程使用ptr的值。
xchg函數,把私有成員ptr指針設置成參數val_的值,并返回ptr設置之前的值。原子操作,線程安全。
cas函數,原子操作,線程安全,把私有成員ptr指針與參數cmp_指針比較:
如果相等返回ptr設置之前的值,并把ptr更新為參數val_的值;
如果不相等直接返回ptr值。
chunk機制
每次分配可以存放N個元素的大塊內存,減少內存的分配和釋放。N值還有元素的類型,是可以根據自己的需要進行設置的。N不能太小,如果太小,就退化成鏈表方式了,就會有內存頻分的申請和釋放的問題。
// 鏈表結點稱之為chunk_t
struct chunk_t
{
T values[N]; //每個chunk_t可以容納N個T類型的元素,以后就以一個chunk_t為單位申請內存
chunk_t *prev;
chunk_t *next;
};

當隊列空間不足時每次分配一個chunk_t,每個chunk_t能存儲N個元素。
當一個chunk中的元素都出隊后,回收的chunk也不是馬上釋放,而是根據局部性原理先回收到spare_chunk里面,當再次需要分配chunk_t的時候從spare_chunk中獲取。spare_chunk只保存一個chunk,即只保存最新的要回收的chunk;如果spare_chunk現在保存了一個chunk A,如果現在有一個更新的chunk B需要回收,那么spare_chunk會更新為chunk B,chunk A會被釋放;這個操作是通過cas完成的。
批量寫入
支持批量寫入,批量能夠提高吞吐量。
// set to true the item is assumed to be continued by items
// subsequently written to the pipe. Incomplete items are neverflushed down the stream.
// 寫入數據,incomplete參數表示寫入是否還沒完成,在沒完成的時候不會修改flush指針,即這部分數據不會讓讀線程看到。
inline void write(const T &value_, bool incomplete_)
{
// Place the value to the queue, add new terminator element.
queue.back() = value_;
queue.push();
// Move the "flush up to here" poiter.
if (!incomplete_)
{
f = &queue.back(); // 記錄要刷新的位置
// printf("1 f:%p, w:%pn", f, w);
}
else
{
// printf("0 f:%p, w:%pn", f, w);
}
}
通過第二個參數incomplete_來判斷write是否結束。
write(b, true);
write(c, false);
flush();
flush后才更新到讀端。
怎樣喚醒讀端?
讀端沒有數據可讀,這個時候應該怎么辦?
使用mutex + condition進行wait,休眠;
寫端怎么喚醒讀端去讀取數據呢?
很多消息隊列,都是每次有消息,都進行notify。如果發送端每發送一個消息都notify,性能會下降。調用notify,涉及到線程切換,內核態與用戶態切換,會影響性能;檢測到讀端處于阻塞狀態,在notify,效率才高。
zmq的無鎖隊列寫端只有在讀端處于休眠狀態的時候才會發送notify,是不是很厲害的樣子?寫端是怎么檢測到讀端處于休眠狀態的呢?
寫端在進行flush的時候,如果返回false,說明讀端處于等待喚醒的狀態,就可以進行notify。

condition wait和notify,都需要由應用程序自己去做。
我們修改代碼,將寫端修改為每次flush都notify;經過測試,性能是會明顯下降的。
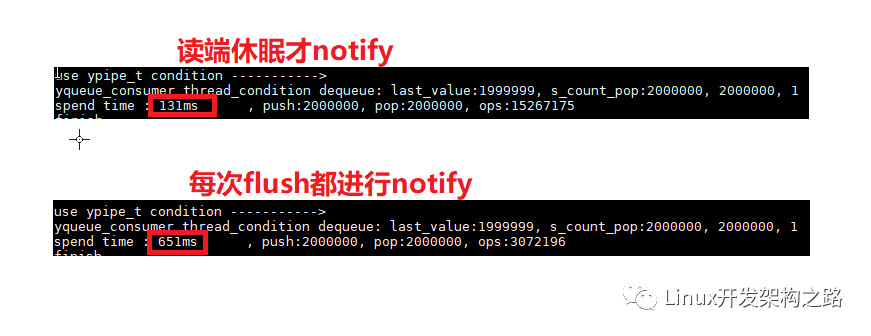
寫端為什么可以檢測到讀端的狀態的?
c值是唯一一個讀端和寫端都要設置的值,通過對c值進行cas操作,寫端就可以判斷讀端是否處于等待喚醒的狀態。
yqueue的實現
yqueue主要負責隊列的數據組織,通過chunk機制進行管理。
class yqueue_t
{
public:
inline yqueue_t();
inline ~yqueue_t();
inline T &front();
inline T &back();
inline void push();
inline void unpush();
inline void pop();
private:
struct chunk_t
{
T values[N];
chunk_t *prev;
chunk_t *next;
};
chunk_t *begin_chunk;
int begin_pos;
chunk_t *back_chunk;
int back_pos;
chunk_t *end_chunk;
int end_pos;
atomic_ptr_t spare_chunk; // 空閑塊(把所有元素都已經出隊的塊稱為空閑塊),讀寫線程的共享變量
// 操作的時候使用xchg原子操作
// Disable copying of yqueue.
yqueue_t(const yqueue_t &);
const yqueue_t &operator=(const yqueue_t &);
};
數據的組織
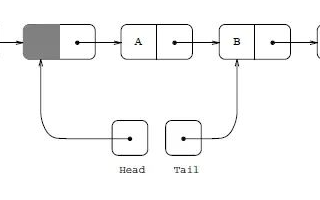
chunk是通過鏈表進行組織的;
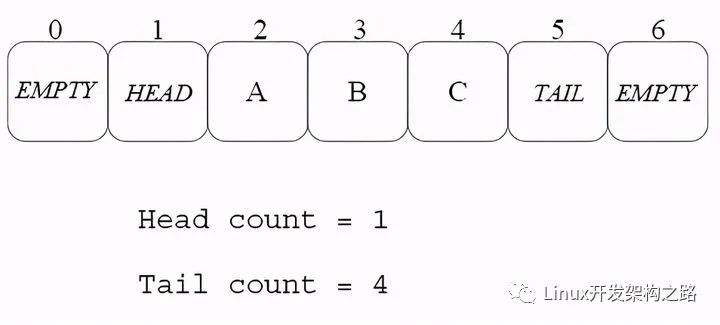
yqueue_t內部有三個chunk_t類型指針以及對應的索引位置:
begin_chunk/begin_pos:begin_chunk指向第一個的chunk;begin_pos是隊列第一個元素在當前chunk中的位置;
back_chunk/back_pos:back_chunk指向隊列尾所在的chunk;back_pos是隊列最后一個元素在當前chunk的位置;
end_chunk/end_pos: end_chunk指向最后一個chunk;end_chunk和back_chunk大部分情況是一致的;end_pos 大部分情況是 back_pos + 1; end_pos主要是用來判斷是否要分配新的chunk。
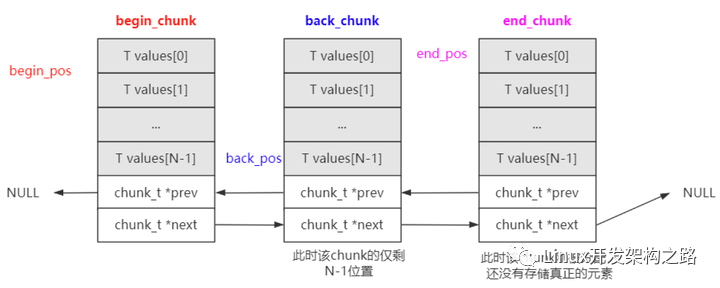
上圖中:
由于back_pos已經指向了back_chunk的最后一個元素,所以end_pos就指向了end_chunk的第一個元素。
back、push函數
back函數返回隊列尾部元素的引用;
// If the queue is empty, behaviour is undefined.
// 返回隊列尾部元素的引用,調用者可以通過該引用更新元素,結合push實現插入操作。
// 如果隊列為空,該函數是不允許被調用。
inline T &back() // 返回的是引用,是個左值,調用者可以通過其修改容器的值
{
return back_chunk->values[back_pos];
}
push函數,更新back_chunk、back_pos的值,并且判斷是否需要新的chunk;如果需要新的chunk,先看spare_chunk是否為空: 如果spare_chunk有值,則將spare_chunk作為end_chunk; 否則新malloc一個chunk。
inline void push()
{
back_chunk = end_chunk;
back_pos = end_pos; //
if (++end_pos != N) //end_pos!=N表明這個chunk節點還沒有滿
return;
chunk_t *sc = spare_chunk.xchg(NULL); // 為什么設置為NULL?因為如果把之前值取出來了則沒有spare chunk了,所以設置為NULL
if (sc) // 如果有spare chunk則繼續復用它
{
end_chunk->next = sc;
sc->prev = end_chunk;
}
else // 沒有則重新分配
{
// static int s_cout = 0;
// printf("s_cout:%dn", ++s_cout);
end_chunk->next = (chunk_t *)malloc(sizeof(chunk_t)); // 分配一個chunk
alloc_assert(end_chunk->next);
end_chunk->next->prev = end_chunk;
}
end_chunk = end_chunk->next;
end_pos = 0;
}
可以使用back和push函數向隊列中插入元素:
queue.back() = value_;
queue.push();
front、pop函數
front函數返回隊列頭部元素的引用。
// If the queue is empty, behaviour is undefined.
// 返回隊列頭部元素的引用,調用者可以通過該引用更新元素,結合pop實現出隊列操作。
inline T &front() // 返回的是引用,是個左值,調用者可以通過其修改容器的值
{
return begin_chunk->values[begin_pos];
}
pop函數,主要更新begin_pos;如果begin_pos == N,則回收chunk;將chunk保存到spare_chunk中。
inline void pop()
{
if (++begin_pos == N) // 刪除滿一個chunk才回收chunk
{
chunk_t *o = begin_chunk;
begin_chunk = begin_chunk->next;
begin_chunk->prev = NULL;
begin_pos = 0;
// 'o' has been more recently used than spare_chunk,
// so for cache reasons we'll get rid of the spare and
// use 'o' as the spare.
chunk_t *cs = spare_chunk.xchg(o); //由于局部性原理,總是保存最新的空閑塊而釋放先前的空閑快
free(cs);
}
}
可以使用front和pop函數進行出隊列操作
// Return it to the caller.
*value_ = queue.front();
queue.pop();
這里有兩點需要注意:
- pop掉的元素,其銷毀工作交給調用者完成,即是pop前調用者需要通過front()接口讀取并進行銷毀(比如動態分配的對象);
- 空閑塊的保存,要求是原子操作;因為閑塊是讀寫線程的共享變量,因為在push中也使用了spare_chunk。
ypipe的實現
ypipe_t在yqueue_t的基礎上構建一個單寫單讀的無鎖隊列。
class ypipe_t
{
public:
// Initialises the pipe.
inline ypipe_t();
// The destructor doesn't have to be virtual. It is mad virtual
// just to keep ICC and code checking tools from complaining.
inline virtual ~ypipe_t();
// Write an item to the pipe. Don't flush it yet. If incomplete is
// set to true the item is assumed to be continued by items
// subsequently written to the pipe. Incomplete items are neverflushed down the stream.
// 寫入數據,incomplete參數表示寫入是否還沒完成,在沒完成的時候不會修改flush指針,即這部分數據不會讓讀線程看到。
inline void write(const T &value_, bool incomplete_);
// Pop an incomplete item from the pipe. Returns true is such
// item exists, false otherwise.
inline bool unwrite(T *value_);
// Flush all the completed items into the pipe. Returns false if
// the reader thread is sleeping. In that case, caller is obliged to
// wake the reader up before using the pipe again.
// 刷新所有已經完成的數據到管道,返回false意味著讀線程在休眠,在這種情況下調用者需要喚醒讀線程。
// 批量刷新的機制, 寫入批量后喚醒讀線程;
// 反悔機制 unwrite
inline bool flush();
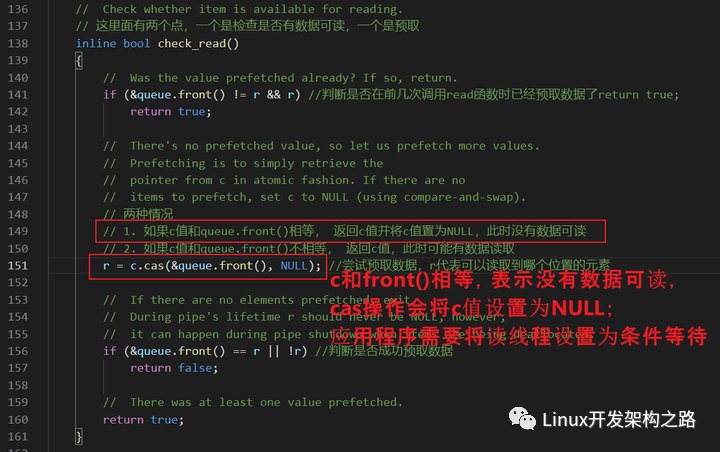
// Check whether item is available for reading.
// 這里面有兩個點,一個是檢查是否有數據可讀,一個是預取
inline bool check_read();
// Reads an item from the pipe. Returns false if there is no value.
// available.
inline bool read(T *value_);
protected:
// Allocation-efficient queue to store pipe items.
// Front of the queue points to the first prefetched item, back of
// the pipe points to last un-flushed item. Front is used only by
// reader thread, while back is used only by writer thread.
yqueue_t queue;
// Points to the first un-flushed item. This variable is used
// exclusively by writer thread.
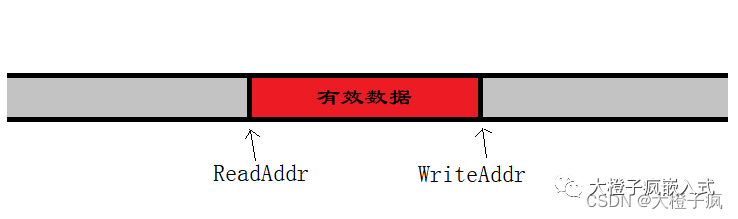
T *w; //指向第一個未刷新的元素,只被寫線程使用
// Points to the first un-prefetched item. This variable is used
// exclusively by reader thread.
T *r; //指向第一個還沒預提取的元素,只被讀線程使用;代表可以讀取到哪個位置的元素
// Points to the first item to be flushed in the future.
T *f; //指向下一輪要被刷新的一批元素中的第一個
// The single point of contention between writer and reader thread.
// Points past the last flushed item. If it is NULL,
// reader is asleep. This pointer should be always accessed using
// atomic operations.
atomic_ptr_t c; //讀寫線程共享的指針,指向每一輪刷新的起點。當c為空時,表示讀線程睡眠(只會在讀線程中被設置為空)
// Disable copying of ypipe object.
ypipe_t(const ypipe_t &);
const ypipe_t &operator=(const ypipe_t &);
},>
核心思想是通過w、r、f指針,通過對c值的cas操作,解決讀寫線程的數據競爭問題。
write
將一個元素入隊列;incomplete_表示write是否結束,如果是flase,將f設置為queue.back()。write最終只是更新了f值。
// set to true the item is assumed to be continued by items
// subsequently written to the pipe. Incomplete items are neverflushed down the stream.
// 寫入數據,incomplete參數表示寫入是否還沒完成,在沒完成的時候不會修改flush指針,即這部分數據不會讓讀線程看到。
inline void write(const T &value_, bool incomplete_)
{
// Place the value to the queue, add new terminator element.
queue.back() = value_;
queue.push();
// Move the "flush up to here" poiter.
if (!incomplete_)
{
f = &queue.back(); // 記錄要刷新的位置
}
else
{
}
}
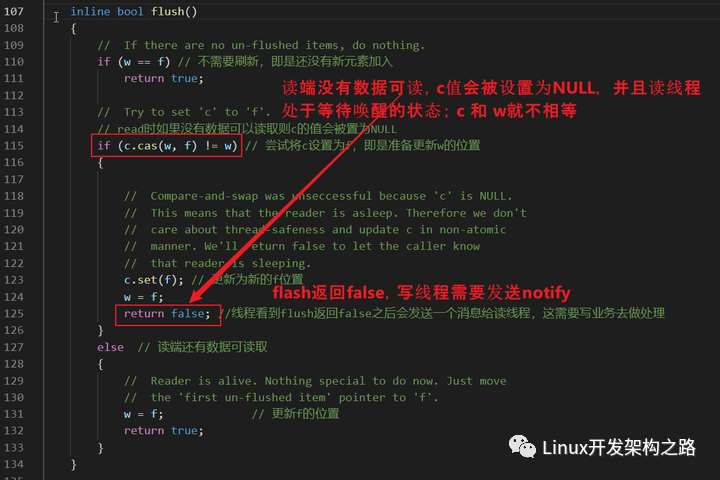
flush
主要是將w更新到f的位置,說明已經寫到的位置。
通過cas操作,嘗試將c值設置為f。通過flush的返回值,可以判斷讀端是否處于等待喚醒的狀態。
// the reader thread is sleeping. In that case, caller is obliged to
// wake the reader up before using the pipe again.
// 刷新所有已經完成的數據到管道,返回false意味著讀線程在休眠,在這種情況下調用者需要喚醒讀線程。
// 批量刷新的機制, 寫入批量后喚醒讀線程;
// 反悔機制 unwrite
inline bool flush()
{
// If there are no un-flushed items, do nothing.
if (w == f) // 不需要刷新,即是還沒有新元素加入
return true;
// Try to set 'c' to 'f'.
// read時如果沒有數據可以讀取則c的值會被置為NULL
if (c.cas(w, f) != w) // 嘗試將c設置為f,即是準備更新w的位置
{
// Compare-and-swap was unseccessful because 'c' is NULL.
// This means that the reader is asleep. Therefore we don't
// care about thread-safeness and update c in non-atomic
// manner. We'll return false to let the caller know
// that reader is sleeping.
c.set(f); // 更新為新的f位置
w = f;
return false; //線程看到flush返回false之后會發送一個消息給讀線程,這需要寫業務去做處理
}
else // 讀端還有數據可讀取
{
// Reader is alive. Nothing special to do now. Just move
// the 'first un-flushed item' pointer to 'f'.
w = f; // 更新f的位置
return true;
}
}
check_read
是一種預讀的機制,檢查是否有數據可讀;通過對c值的cas操作,來更新r值;r就是可以讀取到的位置。
c值如果和&queue.front()相等,標志沒有數據可讀,將c值設置為NULL;寫端就可以通過c值判斷出讀端的狀態。
// 這里面有兩個點,一個是檢查是否有數據可讀,一個是預取
inline bool check_read()
{
// Was the value prefetched already? If so, return.
if (&queue.front() != r && r) //判斷是否在前幾次調用read函數時已經預取數據了return true;
return true;
// There's no prefetched value, so let us prefetch more values.
// Prefetching is to simply retrieve the
// pointer from c in atomic fashion. If there are no
// items to prefetch, set c to NULL (using compare-and-swap).
// 兩種情況
// 1. 如果c值和queue.front()相等, 返回c值并將c值置為NULL,此時沒有數據可讀
// 2. 如果c值和queue.front()不相等, 返回c值,此時可能有數據讀取
r = c.cas(&queue.front(), NULL); //嘗試預取數據,r代表可以讀取到哪個位置的元素
// If there are no elements prefetched, exit.
// During pipe's lifetime r should never be NULL, however,
// it can happen during pipe shutdown when items are being deallocated.
if (&queue.front() == r || !r) //判斷是否成功預取數據
return false;
// There was at least one value prefetched.
return true;
}
基于環形數組的無鎖隊列
基于環形數組的無鎖隊列,也是利用cas操作解決多線程數據競爭的問題;它支持多謝多讀。
class ArrayLockFreeQueue
{
public:
ArrayLockFreeQueue();
virtual ~ArrayLockFreeQueue();
QUEUE_INT size();
bool enqueue(const ELEM_T &a_data);
bool dequeue(ELEM_T &a_data);
bool try_dequeue(ELEM_T &a_data);
private:
ELEM_T m_thequeue[Q_SIZE];
volatile QUEUE_INT m_count;
volatile QUEUE_INT m_writeIndex;
volatile QUEUE_INT m_readIndex;
volatile QUEUE_INT m_maximumReadIndex;
inline QUEUE_INT countToIndex(QUEUE_INT a_count);
};
關鍵是對于三種下標的操作:
- m_writeIndex;//新元素入列時存放位置在數組中的下標
- m_readIndex;/ 下一個出列的元素在數組中的下標
- m_maximumReadIndex; //最后一個已經完成入列操作的元素在數組中的下標, 即可以讀到的最大索引。
通過對這3個下標的cas操作,解決多線程數據競爭的問題。
enqueue
bool ArrayLockFreeQueue::enqueue(const ELEM_T &a_data)
{
QUEUE_INT currentWriteIndex; // 獲取寫指針的位置
QUEUE_INT currentReadIndex;
// 1. 獲取可寫入的位置
do
{
currentWriteIndex = m_writeIndex;
currentReadIndex = m_readIndex;
if(countToIndex(currentWriteIndex + 1) ==
countToIndex(currentReadIndex))
{
return false; // 隊列已經滿了
}
// 目的是為了獲取一個能寫入的位置
} while(!CAS(&m_writeIndex, currentWriteIndex, (currentWriteIndex+1)));
// 獲取寫入位置后 currentWriteIndex是一個臨時變量,保存我們寫入的位置
// We know now that this index is reserved for us. Use it to save the data
m_thequeue[countToIndex(currentWriteIndex)] = a_data; // 把數據更新到對應的位置
// 2. 更新可讀的位置,按著currentWriteIndex + 1的操作
// update the maximum read index after saving the data. It wouldn't fail if there is only one thread
// inserting in the queue. It might fail if there are more than 1 producer threads because this
// operation has to be done in the same order as the previous CAS
while(!CAS(&m_maximumReadIndex, currentWriteIndex, (currentWriteIndex + 1)))
{
// this is a good place to yield the thread in case there are more
// software threads than hardware processors and you have more
// than 1 producer thread
// have a look at sched_yield (POSIX.1b)
sched_yield(); // 當線程超過cpu核數的時候如果不讓出cpu導致一直循環在此。
}
AtomicAdd(&m_count, 1);
return true;
},>
首先判斷隊列是否已滿:(m_writeIndex + 1) %/Q_SIZE == m_readIndex;如果隊列已滿,則返回false。
enqueu的核心思想是預先占用一個可寫的位置,保證同一個位置只有一個線程會進行寫操作;并且保證先獲取到位置的線程,先操作,保證了操作的順序性。這兩個都是通過cas操作保證的。
dequeue
bool ArrayLockFreeQueue::dequeue(ELEM_T &a_data)
{
QUEUE_INT currentMaximumReadIndex;
QUEUE_INT currentReadIndex;
do
{
// to ensure thread-safety when there is more than 1 producer thread
// a second index is defined (m_maximumReadIndex)
currentReadIndex = m_readIndex;
currentMaximumReadIndex = m_maximumReadIndex;
if(countToIndex(currentReadIndex) ==
countToIndex(currentMaximumReadIndex)) // 如果不為空,獲取到讀索引的位置
{
// the queue is empty or
// a producer thread has allocate space in the queue but is
// waiting to commit the data into it
return false;
}
// retrieve the data from the queue
a_data = m_thequeue[countToIndex(currentReadIndex)];
// try to perfrom now the CAS operation on the read index. If we succeed
// a_data already contains what m_readIndex pointed to before we
// increased it
if(CAS(&m_readIndex, currentReadIndex, (currentReadIndex + 1)))
{
AtomicSub(&m_count, 1); // 真正讀取到了數據
return true;
}
} while(true);
assert(0);
// Add this return statement to avoid compiler warnings
return false;
},>
判斷隊列是否有數據可讀:m_readIndex == m_maximumReadIndex;
通過cas操作保證同一個位置,只有一個線程讀取。
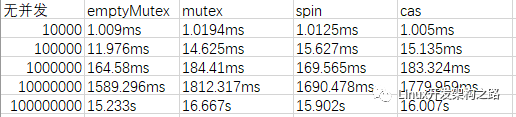
多寫多讀測試結果
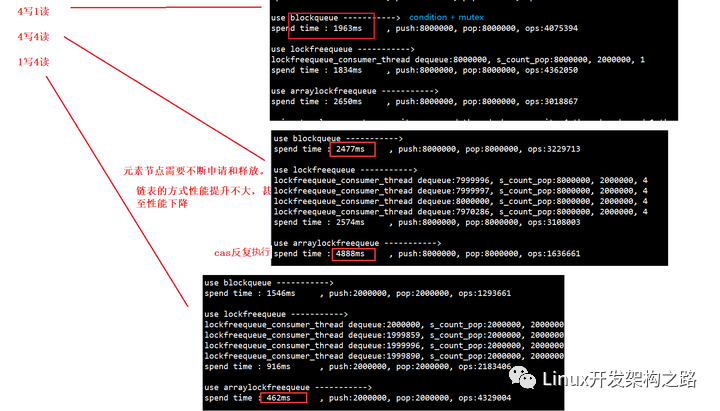
從測試結果可以看出,這個基于環形數組的隊列,比較適合1寫多讀的場景,性能會有很大的提升。
總結
本文主要介紹了以下內容:
- 無鎖隊列所解決的問題;
- 無鎖隊列都是利用了cas操作,來解決多線程數據競爭的問題;因為cas操作的粒度要比mutex,spinlock要小很多;
- zmq無鎖隊列實現原理,包括chunk機制、批量寫入、怎樣喚醒讀端等;yqueue、ypipe的具體的實現,預讀機制、寫端如何檢測到讀端的狀態等;它只支持單寫單讀的場景;
- 基于環形數組的無鎖隊列,它支持多寫多讀的場景;對于1寫多讀的場景,性能有很大提升;它是如何解決多線程競爭問題的。
-
cpu
+關注
關注
68文章
11031瀏覽量
215951 -
數據
+關注
關注
8文章
7239瀏覽量
90987 -
內存
+關注
關注
8文章
3108瀏覽量
74981 -
線程
+關注
關注
0文章
507瀏覽量
20070
發布評論請先 登錄
《有鎖》/《無鎖》/《簽約》/《解鎖》/《越獄》/《激活》專
AWorks軟件設計,郵箱、消息隊列和自旋鎖使用方法
由淺入深的一步步迭代出無鎖隊列的實現原理
測控軟件研發,助力儀器進行遠程數據管理
關于CAS等原子操作介紹 無鎖隊列的鏈表實現方法

一文徹底搞懂內存屏障與volatile
怎么設計實現一個無鎖高并發的環形連續內存緩沖隊列
發燒友實測 | i.MX8MP 編譯DPDK源碼實現rte_ring無鎖環隊列進程間通信


CAS如何實現各種無鎖的數據結構
無鎖CAS如何實現各種無鎖的數據結構





 工商網監
工商網監
評論