") 探索ChatGLM2在算能BM1684X上INT8量化部署,加速大模型商業(yè)落地
探索ChatGLM2在算能BM1684X上INT8量化部署,加速大模型商業(yè)落地
1. 背景介紹
在2023年7月時(shí)我們已通過(guò)靜態(tài)設(shè)計(jì)方案完成了ChatGLM2-6B在單顆BM1684X上的部署工作,量化模式F16,模型大小12GB,平均速度約為3 token/s,詳見(jiàn)《算豐技術(shù)揭秘|探索ChatGLM2-6B模型與TPU部署》。為了進(jìn)一步提升模型的推理效率與降低存儲(chǔ)空間,我們對(duì)模型進(jìn)行了INT8量化部署,整體性能提升70%以上,模型大小降低到6.4GB,推理速度達(dá)到6.67 token/s。
2. 量化方案
首先TPU-MLIR原有的INT8量化方案并不適合直接應(yīng)用于LLM。主要是因?yàn)闊o(wú)論P(yáng)TQ的校準(zhǔn)或者QAT的訓(xùn)練對(duì)于LLM來(lái)說(shuō)成本過(guò)高,對(duì)LLM的一輪PTQ的校準(zhǔn)可能就需要1-2天時(shí)間;另外就是量化帶來(lái)的誤差在LLM上無(wú)法收斂,最終會(huì)導(dǎo)致模型精度大量損失。
在量化方案上我們沿用了ChatGLM2使用的W8A16策略,即只對(duì)GLMBlock中Linear Layer的權(quán)重進(jìn)行per-channel量化存儲(chǔ),在實(shí)際運(yùn)算時(shí)仍將其反量化回F16進(jìn)行運(yùn)算。因?yàn)長(zhǎng)LM中Linear Layer權(quán)重?cái)?shù)值間差異非常小,對(duì)INT8量化較為友好,所以量化過(guò)后的結(jié)果與F16計(jì)算結(jié)果在余弦相似度上仍然能保持99%以上,精度上幾乎可以做到0損失。
 W8A16 MatMul
W8A16 MatMul
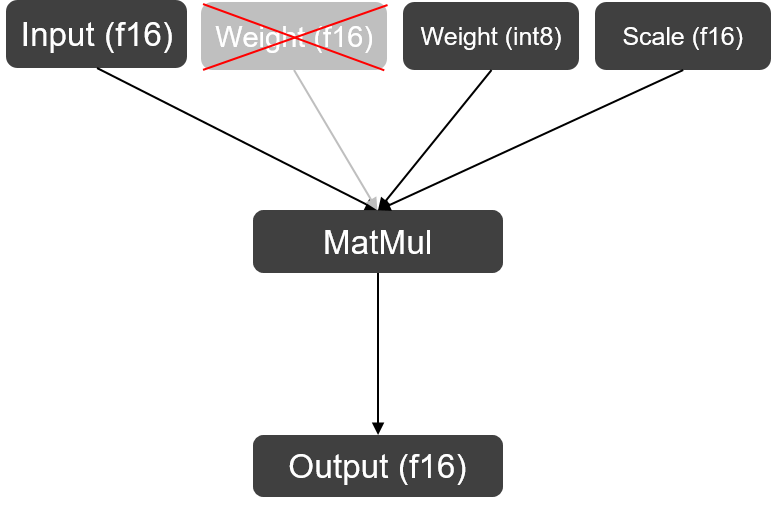
3. TPU-MLIR實(shí)現(xiàn)
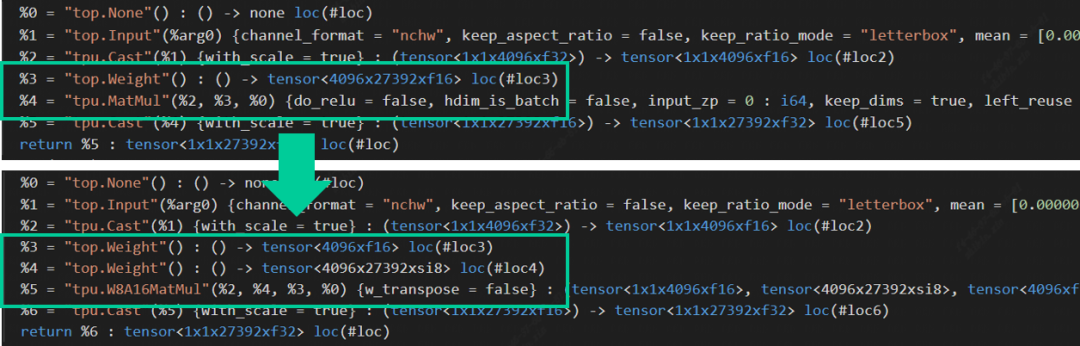
在Top到Tpu層的lowering階段,編譯器會(huì)自動(dòng)搜尋模型中右矩陣輸入為權(quán)重,且該矩陣維數(shù)為2的MatMul,將其替換為W8A16MatMul算子。此處主要是為了與左右矩陣都為Acitvation的MatMul算子區(qū)分開(kāi)(mm, bmm與linear layer在編譯器中會(huì)被統(tǒng)一轉(zhuǎn)換為MatMul算子)。以ChatGLM2中其中一個(gè)MatMul算子為例:L = (max_lengthx4096xf16), R = (4096x27392xf16),量化后的權(quán)重由原來(lái)的214MB降為107MB,額外產(chǎn)生的Scale (4096xf16)只占了0.008MB的存儲(chǔ)空間,基本上可以達(dá)到減半的效果。算子替換源碼與權(quán)重量化源碼可在TPU-MLIR倉(cāng)庫(kù)中查看。
 Op Replacement in TPU-MLIR
Op Replacement in TPU-MLIR
4. 后端性能提升原理
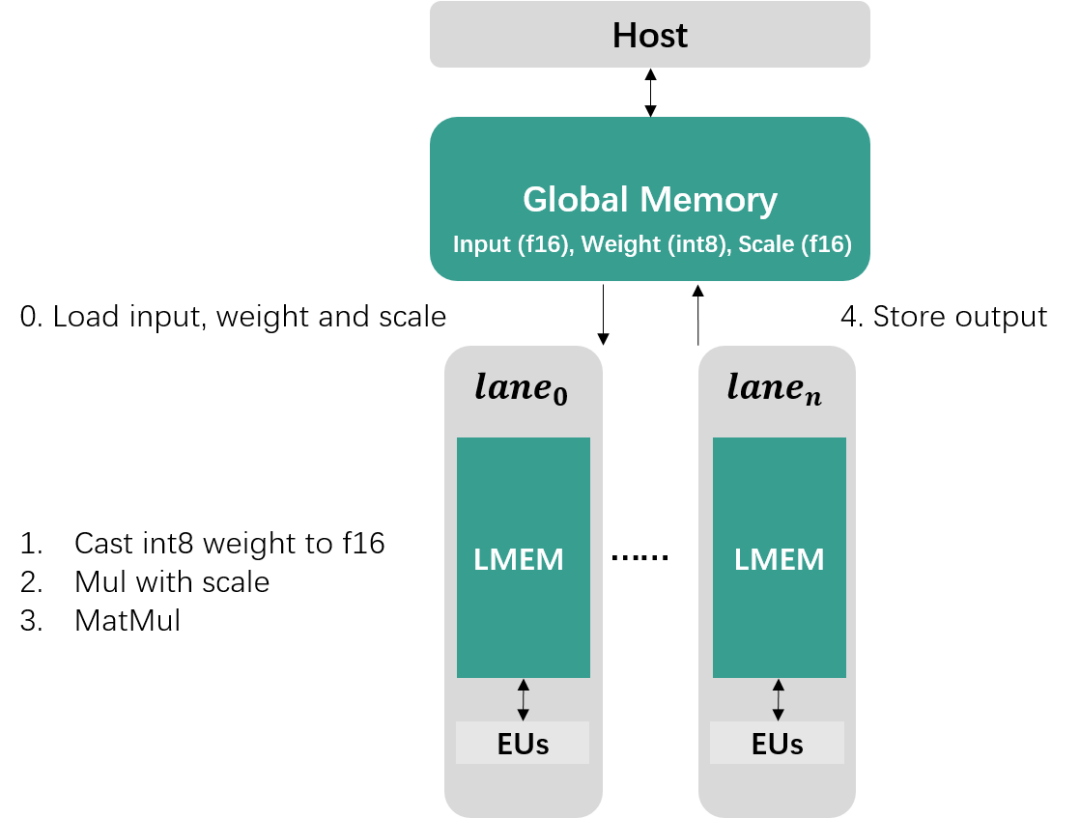
前一節(jié)介紹的量化只實(shí)現(xiàn)了存儲(chǔ)空間減半的效果,而性能提升主要在于W8A16MatMul后端算子的實(shí)現(xiàn)。如果對(duì)TPU架構(gòu)不熟悉可通過(guò)TPU原理介紹(1)和TPU原理介紹(2)兩期視頻了解(可關(guān)注b站“算能開(kāi)發(fā)者”進(jìn)行觀看)。按照算能當(dāng)前的TPU架構(gòu),W8A16的計(jì)算過(guò)程主要分為5個(gè)步驟:
1. 從Global Memory中加載數(shù)據(jù)到Local Memory
2. 將INT8權(quán)重Cast為F16
3. 與Scale數(shù)據(jù)相乘完成反量化操作
4. 與Input Activation進(jìn)行矩陣乘運(yùn)算
5. 將計(jì)算結(jié)果存儲(chǔ)回Global Memory
 W8A16Matmul Computation on TPU
W8A16Matmul Computation on TPU
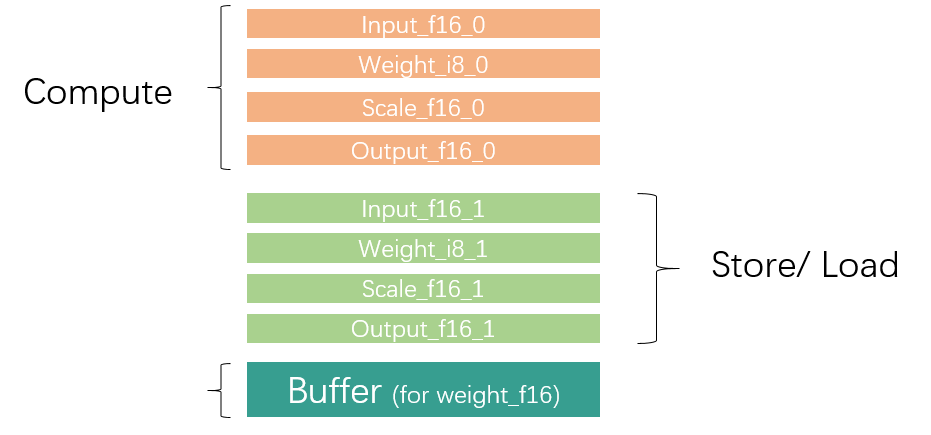
因?yàn)長(zhǎng)ocal Memory空間有限,對(duì)于大型數(shù)據(jù)通常需要進(jìn)行切分,分批對(duì)數(shù)據(jù)進(jìn)行加載、運(yùn)算與存儲(chǔ)。為了提升效率,通常我們會(huì)利用GDMA與BDC指令并行,同時(shí)進(jìn)行數(shù)據(jù)搬運(yùn)與運(yùn)算操作,所以Local Mmeory大致需要被需要被劃分為兩部分區(qū)域,同一個(gè)循環(huán)內(nèi)一個(gè)區(qū)域用于數(shù)據(jù)運(yùn)算,另一個(gè)區(qū)域存儲(chǔ)上一循環(huán)計(jì)算好的結(jié)果以及加載下一循環(huán)需要用到的數(shù)據(jù),如下圖所示。
 Local Memory Partition
Local Memory Partition
矩陣乘等式如下:
當(dāng)矩陣乘運(yùn)算中左矩陣數(shù)據(jù)量較小時(shí),性能瓶頸主要在于右矩陣的數(shù)據(jù)加載上,即數(shù)據(jù)加載時(shí)間遠(yuǎn)比數(shù)據(jù)運(yùn)算時(shí)間要長(zhǎng)很多。W8A16通過(guò)量化能夠?qū)⒂揖仃嚨臄?shù)據(jù)搬運(yùn)總量縮小為原來(lái)的一半,而且額外多出的Cast與Scale運(yùn)算時(shí)間可以被數(shù)據(jù)搬運(yùn)時(shí)間覆蓋住,因此并不會(huì)影響到整體runtime,如下圖所示。
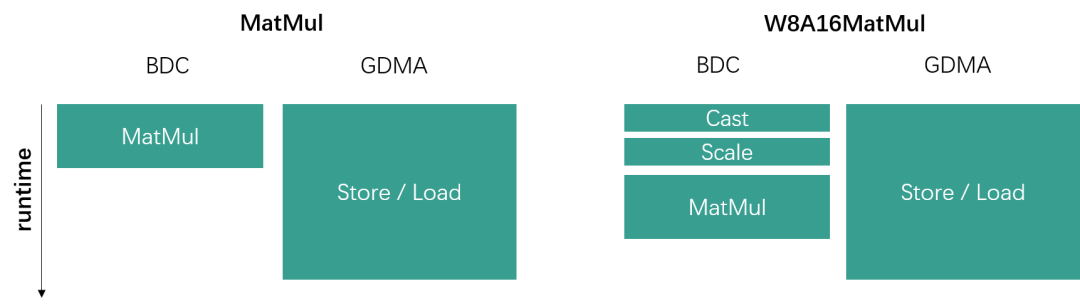 GDMA and BDC parallel
GDMA and BDC parallel
總而言之,從后端角度來(lái)說(shuō),當(dāng)越小,越大時(shí),W8A16帶來(lái)的性能提升收益越大。
從LLM的角度來(lái)看,我們以ChatGLM2為例,一次推理的完整流程分為一輪prefill與多輪decode。在prefill階段,基于我們當(dāng)前的靜態(tài)設(shè)計(jì)方案,輸入詞向量會(huì)被補(bǔ)位為當(dāng)前模型所支持的最大文本長(zhǎng)度max_length (e.g., 512, 1024, 2048)。而decode階段則固定只取前一輪生成的一個(gè)token作為輸入。
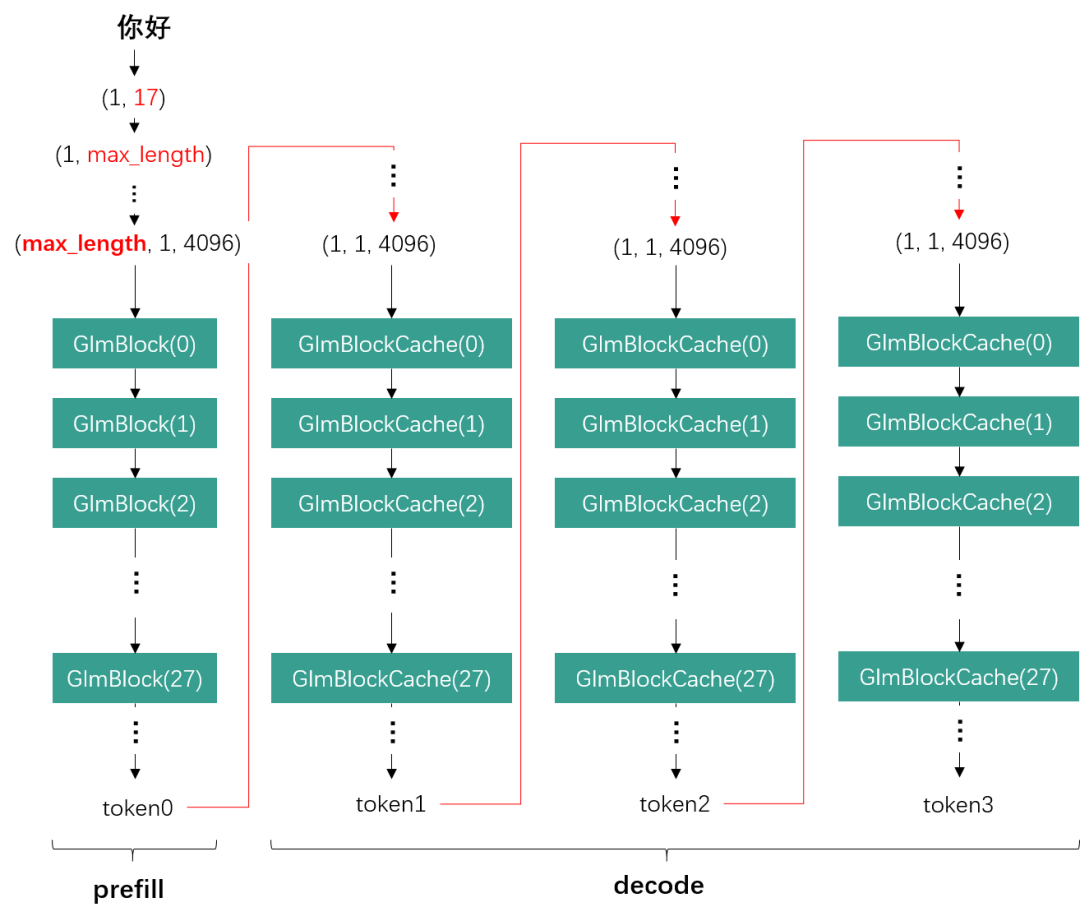 ChatGLM2 Inference
ChatGLM2 Inference
因此max_length越長(zhǎng),GLMBlock接收的輸入數(shù)據(jù)量越大,Linear Layer的也就越大,這就會(huì)導(dǎo)致W8A16的性能提升越有限。而decode階段始終保持為1,此時(shí)W8A16就能帶來(lái)明顯的性能提升。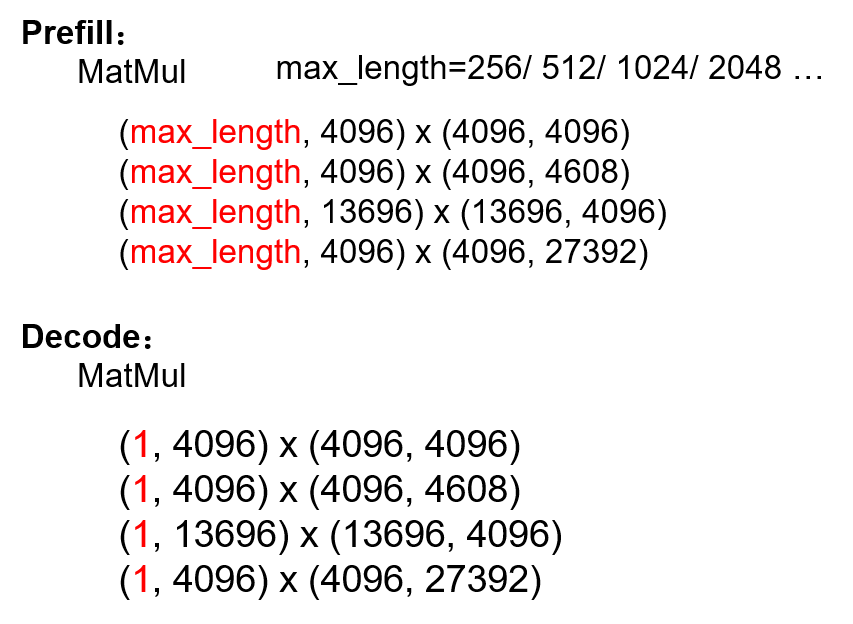 MatMuls in ChatGLM2 prefill and decode phase
MatMuls in ChatGLM2 prefill and decode phase
5. 效果展示
將W8A16量化應(yīng)用于ChatGLM2-6B后,整體性能如下所示:
- 性能:整體性能得到70%以上的提升
- 精度:與F16下的回答略有不同,但答案正確性仍然可以保證
- 模型大小:由12GB降為6.4GB
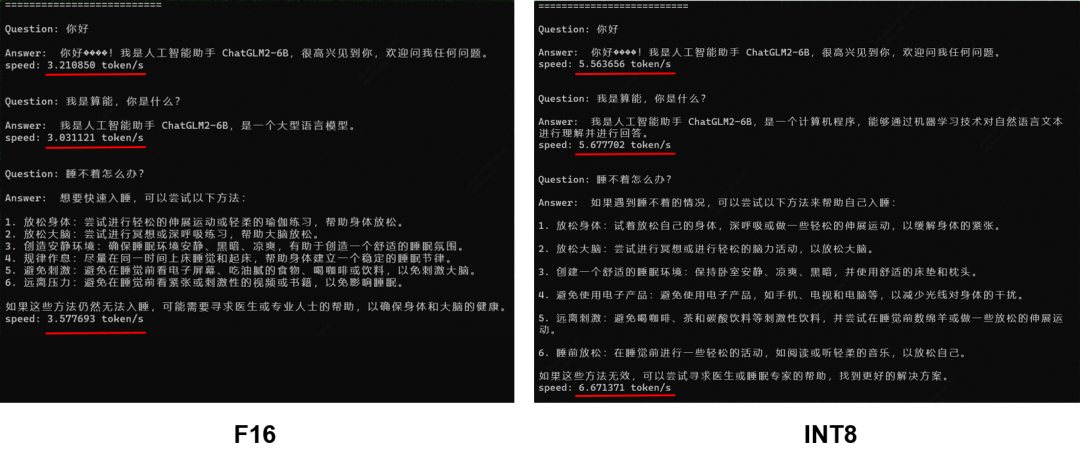 Result Comparison
Result Comparison
-
模型
+關(guān)注
關(guān)注
1文章
3483瀏覽量
49962 -
編譯器
+關(guān)注
關(guān)注
1文章
1654瀏覽量
49872 -
LLM
+關(guān)注
關(guān)注
1文章
319瀏覽量
677
發(fā)布評(píng)論請(qǐng)先 登錄
se5 8使用YOLOv5_object示例程序出錯(cuò)“Not able to open cpu.so”的原因?
RK3588核心板在邊緣AI計(jì)算中的顛覆性?xún)?yōu)勢(shì)與場(chǎng)景落地
i.mx95的EIQ轉(zhuǎn)換器將int8更改為uint8后出現(xiàn)報(bào)錯(cuò)怎么解決?
DeepSeek-R1:7B 在配備 Hailo-8L 和 M2-HAT+ 的樹(shù)莓派5上的部署實(shí)踐測(cè)試!

在OpenVINO?工具套件的深度學(xué)習(xí)工作臺(tái)中無(wú)法導(dǎo)出INT8模型怎么解決?
是否可以輸入隨機(jī)數(shù)據(jù)集來(lái)生成INT8訓(xùn)練后量化模型?
添越智創(chuàng)基于 RK3588 開(kāi)發(fā)板部署測(cè)試 DeepSeek 模型全攻略
使用OpenVINO 2024.4在算力魔方上部署Llama-3.2-1B-Instruct模型
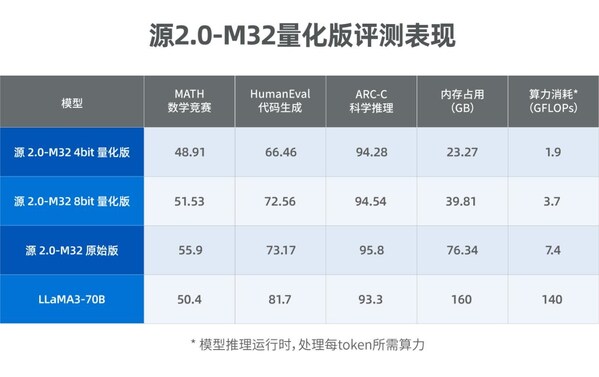
源2.0-M32大模型發(fā)布量化版 運(yùn)行顯存僅需23GB 性能可媲美LLaMA3
chatglm2-6b在P40上做LORA微調(diào)
深度神經(jīng)網(wǎng)絡(luò)模型量化的基本方法
深度學(xué)習(xí)模型量化方法

【算能RADXA微服務(wù)器試用體驗(yàn)】+ GPT語(yǔ)音與視覺(jué)交互:2,圖像識(shí)別
esp-dl int8量化模型數(shù)據(jù)集評(píng)估精度下降的疑問(wèn)求解?
產(chǎn)品應(yīng)用 | 小盒子跑大模型!英碼科技基于算能BM1684X平臺(tái)實(shí)現(xiàn)大模型私有化部署






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論