") 機(jī)器學(xué)習(xí)模型的集成方法總結(jié):Bagging, Boosting, Stacking, Voting, Blending
機(jī)器學(xué)習(xí)模型的集成方法總結(jié):Bagging, Boosting, Stacking, Voting, Blending

來源:DeepHub IMBA
作者:Abhay Parashar
機(jī)器學(xué)習(xí)是人工智能的一個(gè)分支領(lǐng)域,致力于構(gòu)建自動(dòng)學(xué)習(xí)和自適應(yīng)的系統(tǒng),它利用統(tǒng)計(jì)模型來可視化、分析和預(yù)測(cè)數(shù)據(jù)。一個(gè)通用的機(jī)器學(xué)習(xí)模型包括一個(gè)數(shù)據(jù)集(用于訓(xùn)練模型)和一個(gè)算法(從數(shù)據(jù)學(xué)習(xí))。但是有些模型的準(zhǔn)確性通常很低產(chǎn)生的結(jié)果也不太準(zhǔn)確,克服這個(gè)問題的最簡(jiǎn)單的解決方案之一是在機(jī)器學(xué)習(xí)模型上使用集成學(xué)習(xí)。
集成學(xué)習(xí)是一種元方法,通過組合多個(gè)機(jī)器學(xué)習(xí)模型來產(chǎn)生一個(gè)優(yōu)化的模型,從而提高模型的性能。集成學(xué)習(xí)可以很容易地減少過擬合,避免模型在訓(xùn)練時(shí)表現(xiàn)更好,而在測(cè)試時(shí)不能產(chǎn)生良好的結(jié)果。
總結(jié)起來,集成學(xué)習(xí)有以下的優(yōu)點(diǎn):
- 增加模型的性能
- 減少過擬合
- 降低方差
- 與單個(gè)模型相比,提供更高的預(yù)測(cè)精度。
- 可以處理線性和非線性數(shù)據(jù)。
集成技術(shù)可以用來解決回歸和分類問題
下面我們將介紹各種集成學(xué)習(xí)的方法:
Voting
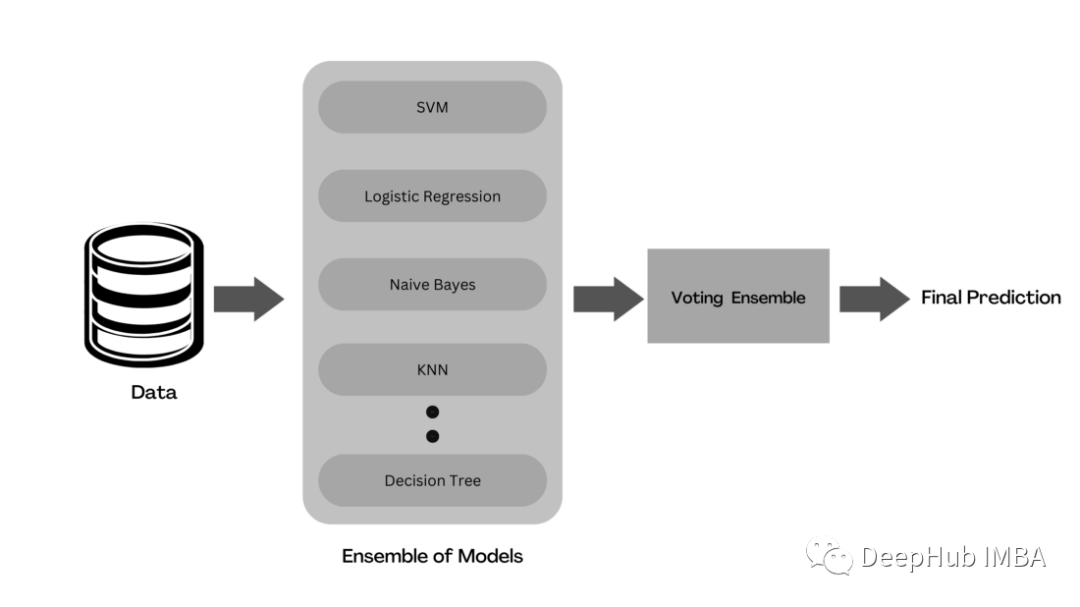
Voting是一種集成學(xué)習(xí),它將來自多個(gè)機(jī)器學(xué)習(xí)模型的預(yù)測(cè)結(jié)合起來產(chǎn)生結(jié)果。在整個(gè)數(shù)據(jù)集上訓(xùn)練多個(gè)基礎(chǔ)模型來進(jìn)行預(yù)測(cè)。每個(gè)模型預(yù)測(cè)被認(rèn)為是一個(gè)“投票”。得到多數(shù)選票的預(yù)測(cè)將被選為最終預(yù)測(cè)。
有兩種類型的投票用于匯總基礎(chǔ)預(yù)測(cè)-硬投票和軟投票。
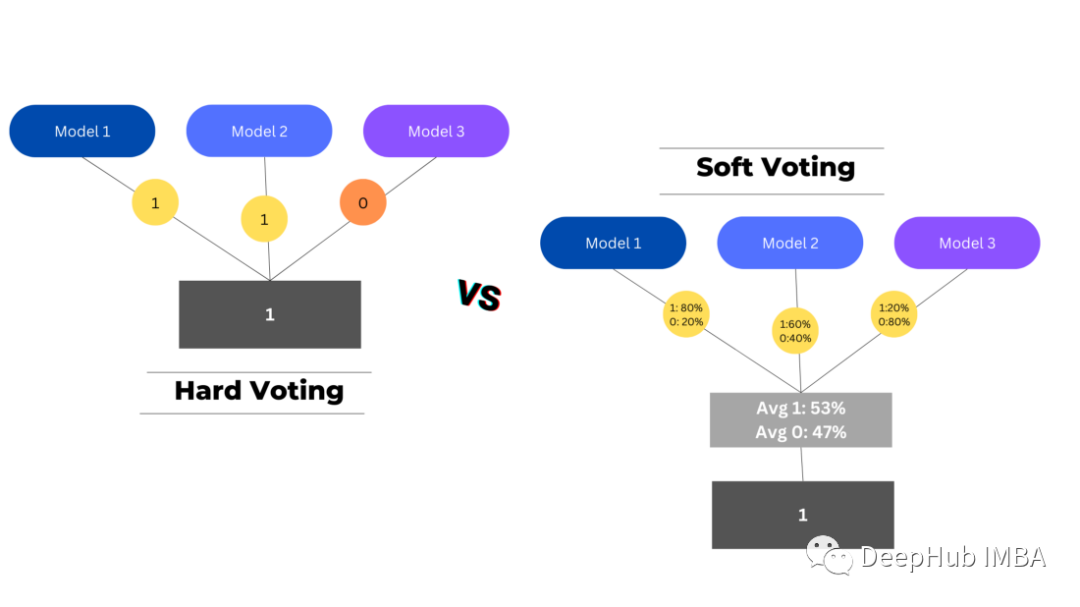
硬投票選擇投票數(shù)最高的預(yù)測(cè)作為最終預(yù)測(cè),而軟投票將每個(gè)模型中每個(gè)類的概率結(jié)合起來,選擇概率最高的類作為最終預(yù)測(cè)。
在回歸問題中,它的工作方式有些不同,因?yàn)槲覀儾皇菍ふ翌l率最高的類,而是采用每個(gè)模型的預(yù)測(cè)并計(jì)算它們的平均值,從而得出最終的預(yù)測(cè)。
from sklearn.ensemble import VotingClassifier ## Base Models from sklearn.tree import DecisionTreeClassifier from sklearn.linear_model import LogisticRegression from sklearn.naive_bayes import GaussianNB from sklearn.neighbors import KNeighborsClassifier from sklearn.svm import SVC ensemble_voting = VotingClassifier( estimators = [('dtc',DecisionTreeClassifier(random_state=42)), ('lr', LogisticRegression()), ('gnb', GaussianNB()), ('knn',KNeighborsClassifier()), ('svc',SVC())], voting='hard') ensemble_voting.fit(X_train,y_train)Bagging
Bagging是采用幾個(gè)弱機(jī)器學(xué)習(xí)模型,并將它們的預(yù)測(cè)聚合在一起,以產(chǎn)生最佳的預(yù)測(cè)。它基于bootstrap aggregation,bootstrap 是一種使用替換方法從集合中抽取隨機(jī)樣本的抽樣技術(shù)。aggregation則是利用將幾個(gè)預(yù)測(cè)結(jié)合起來產(chǎn)生最終預(yù)測(cè)的過程。
隨機(jī)森林是利用Bagging的最著名和最常用的模型之一。它由大量的決策樹組成,這些決策樹作為一個(gè)整體運(yùn)行。它使用Bagging和特征隨機(jī)性的概念來創(chuàng)建每棵獨(dú)立的樹。每棵決策樹都是從數(shù)據(jù)中隨機(jī)抽取樣本進(jìn)行訓(xùn)練。在隨機(jī)森林中,我們最終得到的樹不僅接受不同數(shù)據(jù)集的訓(xùn)練,而且使用不同的特征來預(yù)測(cè)結(jié)果。
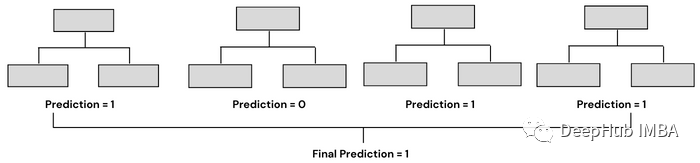
Bagging通常有兩種類型——決策樹的集合(稱為隨機(jī)森林)和決策樹以外的模型的集合。兩者的工作原理相似,都使用聚合方法生成最終預(yù)測(cè),唯一的區(qū)別是它們所基于的模型。在sklearn中,我們有一個(gè)BaggingClassifier類,用于創(chuàng)建除決策樹以外的模型。
## Bagging Ensemble of Same Classifiers (Decision Trees) from sklearn.ensemble import RandomForestClassifier classifier= RandomForestClassifier(n_estimators= 10, criterion="entropy") classifier.fit(x_train, y_train) ## Bagging Ensemble of Different Classifiers from sklearn.ensemble import BaggingClassifier from sklearn.svm import SVC clf = BaggingClassifier(base_estimator=SVC(), n_estimators=10, random_state=0) clf.fit(X_train,y_train)Boosting
增強(qiáng)集成方法通過重視先前模型的錯(cuò)誤,將弱學(xué)習(xí)者轉(zhuǎn)化為強(qiáng)學(xué)習(xí)者。Boosting以順序的方式實(shí)現(xiàn)同構(gòu)ML算法,每個(gè)模型都試圖通過減少前一個(gè)模型的誤差來提高整個(gè)過程的穩(wěn)定性。
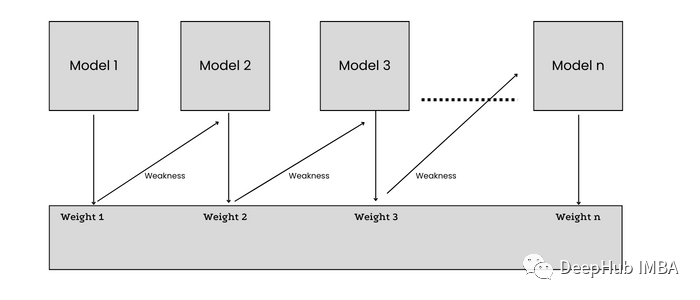
在訓(xùn)練n+1模型時(shí),數(shù)據(jù)集中的每個(gè)數(shù)據(jù)點(diǎn)都被賦予了相等的權(quán)重,這樣被模型n錯(cuò)誤分類的樣本就能被賦予更多的權(quán)重(重要性)。誤差從n個(gè)學(xué)習(xí)者傳遞給n+1個(gè)學(xué)習(xí)者,每個(gè)學(xué)習(xí)者都試圖減少誤差。
ADA Boost是使用Boost生成預(yù)測(cè)的最基本模型之一。ADA boost創(chuàng)建一個(gè)決策樹樁森林(一個(gè)樹樁是一個(gè)只有一個(gè)節(jié)點(diǎn)和兩個(gè)葉子的決策樹),不像隨機(jī)森林創(chuàng)建整個(gè)決策樹森林。它給分類錯(cuò)誤的樣本分配更高的權(quán)重,并繼續(xù)訓(xùn)練模型,直到得到較低的錯(cuò)誤率。
from sklearn.tree import DecisionTreeClassifier from sklearn.ensemble import AdaBoostClassifier dt = DecisionTreeClassifier(max_depth=2, random_state=0) adc = AdaBoostClassifier(base_estimator=dt, n_estimators=7, learning_rate=0.1, random_state=0) adc.fit(x_train, y_train)Stacking
Stacking也被稱為疊加泛化,是David H. Wolpert在1992年提出的集成技術(shù)的一種形式,目的是通過使用不同的泛化器來減少錯(cuò)誤。
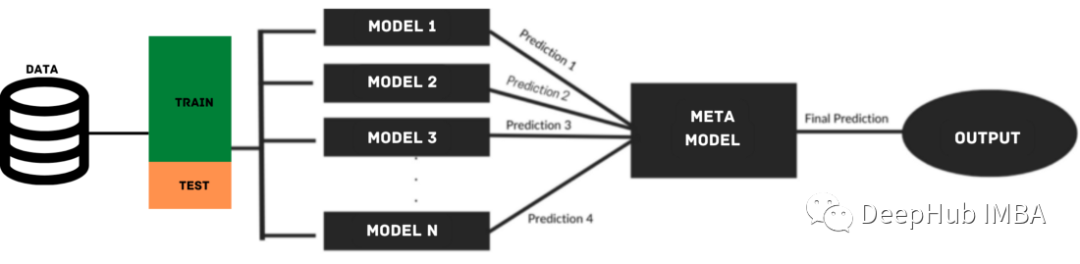
疊加模型利用來自多個(gè)基礎(chǔ)模型的預(yù)測(cè)來構(gòu)建元模型,用于生成最終的預(yù)測(cè)。堆疊模型由多層組成,其中每一層由幾個(gè)機(jī)器學(xué)習(xí)模型組成,這些模型的預(yù)測(cè)用于訓(xùn)練下一層模型。
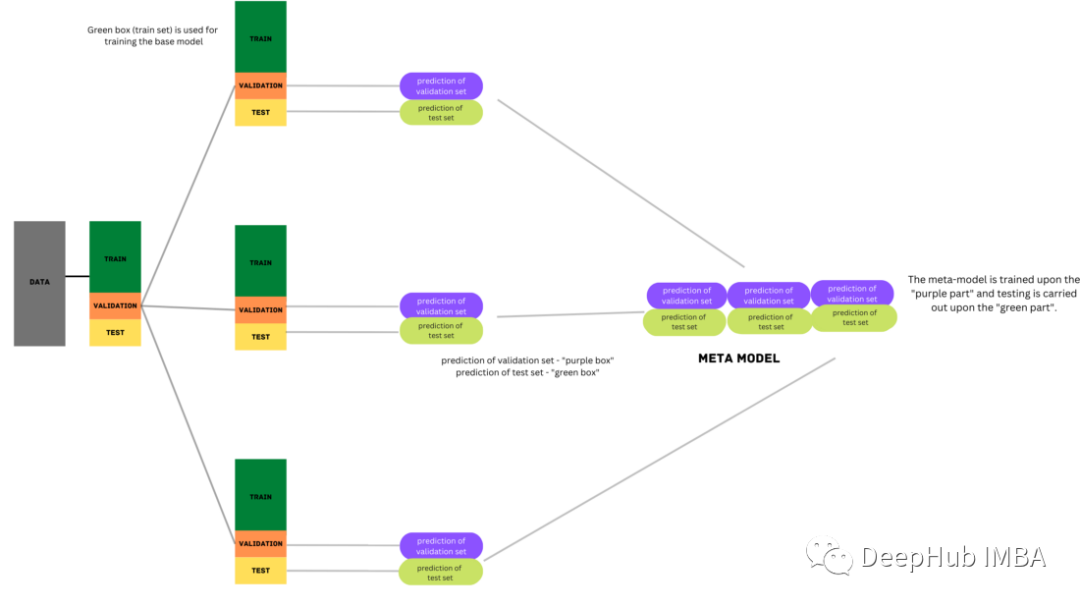
在疊加過程中,將數(shù)據(jù)分為訓(xùn)練集和測(cè)試集兩部分。訓(xùn)練集會(huì)被進(jìn)一步劃分為k-fold。基礎(chǔ)模型在k-1部分進(jìn)行訓(xùn)練,在k??部分進(jìn)行預(yù)測(cè)。這個(gè)過程被反復(fù)迭代,直到每一折都被預(yù)測(cè)出來。然后將基本模型擬合到整個(gè)數(shù)據(jù)集,并計(jì)算性能。這個(gè)過程也適用于其他基本模型。
來自訓(xùn)練集的預(yù)測(cè)被用作構(gòu)建第二層或元模型的特征。這個(gè)第二級(jí)模型用于預(yù)測(cè)測(cè)試集。
from sklearn.neighbors import KNeighborsClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.svm import SVC from sklearn.linear_model import LogisticRegression from sklearn.ensemble import StackingClassifier base_learners = [ ('l1', KNeighborsClassifier()), ('l2', DecisionTreeClassifier()), ('l3',SVC(gamma=2, C=1))) ] model = StackingClassifier(estimators=base_learners, final_estimator=LogisticRegression(),cv=5) model.fit(X_train, y_train)Blending
Blending是從Stacking派生出來另一種形式的集成學(xué)習(xí)技術(shù),兩者之間的唯一區(qū)別是它使用來自一個(gè)訓(xùn)練集的保留(驗(yàn)證)集來進(jìn)行預(yù)測(cè)。簡(jiǎn)單地說,預(yù)測(cè)只針對(duì)保留的數(shù)據(jù)集。保留的數(shù)據(jù)集和預(yù)測(cè)用于構(gòu)建第二級(jí)模型。
import numpy as np from sklearn.datasets import make_classification from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score ## Base Models from sklearn.neighbors import KNeighborsClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.svm import SVC ## Meta Learner from sklearn.linear_model import LogisticRegression ## Creating Sample Data X,y = make_classification(n_samples=10000, n_features=20, n_informative=15, n_redundant=5, random_state=42) ## Training a Individual Logistic Regression Model X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1) logrec = LogisticRegression() logrec.fit(X_train,y_train) pred = logrec.predict(X_test) score = accuracy_score(y_test, pred) print('Base Model Accuracy: %.3f' % (score*100)) ## Defining Base Models def base_models(): models = list() models.append(('knn', KNeighborsClassifier())) models.append(('dt', DecisionTreeClassifier())) models.append(('svm', SVC(probability=True))) return models ## Fitting Ensemble Blending Model ## Step 1:Splitting Data Into Train, Holdout(Validation) and Test Sets X_train_full, X_test, y_train_full, y_test = train_test_split(X, y, test_size=0.3, random_state=1) X_train, X_val, y_train, y_val = train_test_split(X_train_full, y_train_full, test_size=0.33, random_state=1) ## Step 2: train base models on train set and make predictions on validation set models = base_models() meta_X = list() for name, model in models: # training base models on train set model.fit(X_train, y_train) # predict on hold out set yhat = model.predict_proba(X_val) # storing predictions meta_X.append(yhat) # horizontal stacking predictions meta_X = np.hstack(meta_X) ## Step 3: Creating Blending Meta Learner blender = LogisticRegression() ## training on base model predictions blender.fit(meta_X, y_val) ## Step 4: Making predictions using blending meta learner meta_X = list() for name, model in models: yhat = model.predict_proba(X_test) meta_X.append(yhat) meta_X = np.hstack(meta_X) y_pred = blender.predict(meta_X) # Evaluate predictions score = accuracy_score(y_test, y_pred) print('Blending Accuracy: %.3f' % (score*100)) --------------------------------- Base Model Accuracy: 82.367 Blending Accuracy: 96.733總結(jié)
在閱讀完本文之后,您可能想知道是否有選擇一個(gè)更好的模型最好的方法或者如果需要的話,使用哪種集成技術(shù)呢?
在這個(gè)問題時(shí),我們總是建議從一個(gè)簡(jiǎn)單的個(gè)體模型開始,然后使用不同的建模技術(shù)(如集成學(xué)習(xí))對(duì)其進(jìn)行測(cè)試。在某些情況下,單個(gè)模型可能比集成模型表現(xiàn)得更好,甚至好很多。
需要說明并且需要注意的一點(diǎn)是:集成學(xué)習(xí)絕不應(yīng)該是第一選擇,而應(yīng)該是最后一個(gè)選擇。原因很簡(jiǎn)單:訓(xùn)練一個(gè)集成模型將花費(fèi)很多時(shí)間,并且需要大量的處理能力。
回到我們的問題,集成模型旨在通過組合同一類別的幾個(gè)基本模型來提高模型的可預(yù)測(cè)性。每種集成技術(shù)都是最好的,有助于提高模型性能。
如果你正在尋找一種簡(jiǎn)單且易于實(shí)現(xiàn)的集成方法,那么應(yīng)該使用Voting。如果你的數(shù)據(jù)有很高的方差,那么你應(yīng)該嘗試Bagging。如果訓(xùn)練的基礎(chǔ)模型在模型預(yù)測(cè)中有很高的偏差,那么可以嘗試不同的Boosting技術(shù)來提高準(zhǔn)確性。如果有多個(gè)基礎(chǔ)模型在數(shù)據(jù)上表現(xiàn)都很好好,并且不知道選擇哪一個(gè)作為最終模型,那么可以使用Stacking 或Blending的方法。當(dāng)然具體哪種方法表現(xiàn)得最好還是要取決于數(shù)據(jù)和特征分布。
最后集成學(xué)習(xí)技術(shù)是提高模型精度和性能的強(qiáng)大工具,它們很容易減少數(shù)據(jù)過擬合和欠擬合的機(jī)會(huì),尤其在參加比賽時(shí)這是提分的關(guān)鍵。
-
機(jī)器學(xué)習(xí)
+關(guān)注
關(guān)注
66文章
8501瀏覽量
134583
發(fā)布評(píng)論請(qǐng)先 登錄
邊緣計(jì)算中的機(jī)器學(xué)習(xí):基于 Linux 系統(tǒng)的實(shí)時(shí)推理模型部署與工業(yè)集成!

機(jī)器學(xué)習(xí)模型市場(chǎng)前景如何
傳統(tǒng)機(jī)器學(xué)習(xí)方法和應(yīng)用指導(dǎo)

【「具身智能機(jī)器人系統(tǒng)」閱讀體驗(yàn)】1.全書概覽與第一章學(xué)習(xí)
《具身智能機(jī)器人系統(tǒng)》第7-9章閱讀心得之具身智能機(jī)器人與大模型
PWM信號(hào)生成方法 PWM調(diào)制原理講解
什么是機(jī)器學(xué)習(xí)?通過機(jī)器學(xué)習(xí)方法能解決哪些問題?

LLM和傳統(tǒng)機(jī)器學(xué)習(xí)的區(qū)別
AI大模型與深度學(xué)習(xí)的關(guān)系
AI大模型與傳統(tǒng)機(jī)器學(xué)習(xí)的區(qū)別
萬界星空科技MES數(shù)據(jù)的集成方式





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論