") 多模態(tài)上下文指令調(diào)優(yōu)數(shù)據(jù)集MIMIC-IT
多模態(tài)上下文指令調(diào)優(yōu)數(shù)據(jù)集MIMIC-IT
在包含 280 萬條多模態(tài)上下文指令 - 相應(yīng)對的數(shù)據(jù)集上訓練之后,Otter 展現(xiàn)出了優(yōu)秀的問答能力,并在 ChatGPT 及人類的兩項評估中獲得了很高的評價。
近段時間來,AI 對話助手在語言任務(wù)上取得了不小的進展。這種顯著的進步不只是基于 LLM 強大的泛化能力,還應(yīng)該歸功于指令調(diào)優(yōu)。這涉及到在一系列通過多樣化和高質(zhì)量指令的任務(wù)上對 LLM 進行微調(diào)。
借助指令調(diào)優(yōu)獲得零樣本性能的一個潛在原因是,它內(nèi)化了上下文。這很重要,特別是當用戶輸入跳過常識性的上下文時。通過納入指令調(diào)優(yōu),LLM 獲得了對用戶意圖的高度理解,即使在以前未見過的任務(wù)中也能表現(xiàn)出更好的零樣本能力。
然而,一個理想的 AI 對話助手應(yīng)該能夠解決涉及多種模態(tài)的任務(wù)。這需要獲得一個多樣化和高質(zhì)量的多模式指令跟隨數(shù)據(jù)集。比如,LLaVAInstruct-150K 數(shù)據(jù)集(也被稱為 LLaVA)就是一個常用的視覺 - 語言指令跟隨數(shù)據(jù)集,它是使用 COCO 圖像、指令和從 GPT-4 中獲得的基于圖像說明和目標邊界框的響應(yīng)構(gòu)建的。但 LLaVA-Instruct-150K 具有三個局限性:有限的視覺多樣性;使用圖片作為單一視覺數(shù)據(jù);上下文信息僅包含語言形態(tài)。
為了推動 AI 對話助手突破這些限制,來自新加坡南洋理工大學、微軟雷蒙德研究院的學者們提出了多模態(tài)上下文指令調(diào)優(yōu)數(shù)據(jù)集 MIMIC-IT,這是一個包含 280 萬條多模態(tài)上下文指令 - 相應(yīng)對的數(shù)據(jù)集,涵蓋各種現(xiàn)實生活場景。

論文地址:https://arxiv.org/pdf/2306.05425.pdf
此外,為了高效地生成指令 - 響應(yīng)對,研究者還介紹了「Sythus」,這是一個受 self-instruct 方法啟發(fā)的指令 - 響應(yīng)注釋的自動化 pipeline。Sythus 采用系統(tǒng)信息、視覺注釋和上下文中的例子來指導(dǎo)語言模型(GPT-4 或 ChatGPT)根據(jù)視覺語境生成指令 - 響應(yīng)對,針對視覺語言模型的三個基本能力:感知、推理和規(guī)劃。此外,英文的指令和響應(yīng)被譯成七種語言,以支持多種語言的使用。
特別值得注意的是,研究者在 MIMIC-IT 上訓練了基于 OpenFlamingo 的多模態(tài)模型「Otter」。通過 ChatGPT、人類兩個方面的評估,Otter 的多模態(tài)能力超越了近期的其他視覺 - 語言模型。
在一系列 Demo 中,研究者展示了 Otter 的多模態(tài)問答能力:
Q:接下來出哪張牌?
A:八筒。這樣你就能留著四條和五條,等著湊成順子。

Q:我想著陸了,怎么操作?
A:按一次左下按鈕,左轉(zhuǎn),要著陸時拉右邊的手剎。

Q:接下來怎么辦?
A:把球傳到中路,跑到球門,尋找進球機會。

接下來,讓我們看看研究細節(jié)。
MIMIC-IT 數(shù)據(jù)集
MIMIC-IT 數(shù)據(jù)集包括 280 萬個多模態(tài)指令 - 響應(yīng)對,涵蓋了基本能力:感知、推理和計劃。每個指令都伴隨著多模態(tài)的對話背景,使在 MIMIC-IT 上訓練的 VLM 能夠在交互式指令中表現(xiàn)出很好的熟練度,并能進行零樣本的概括。
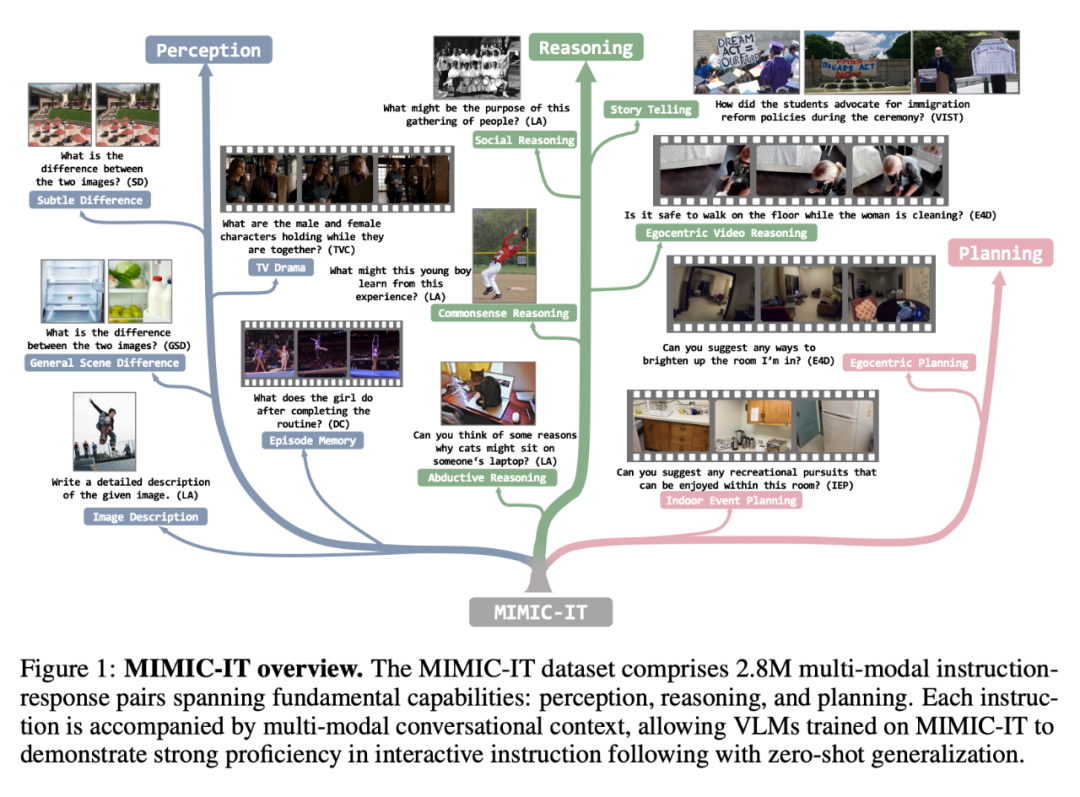
相比于 LLaVA,MIMIC-IT 的特點包括:
(1) 多樣化的視覺場景,包含了一般場景、自我中心視角場景和室內(nèi) RGB-D 圖像等不同數(shù)據(jù)集的圖像和視頻;
(2) 多個圖像(或一個視頻)作為視覺數(shù)據(jù);
(3) 多模態(tài)的上下文信息,包括多個指令 - 響應(yīng)對和多個圖像或視頻;
(4) 支持八種語言,包括英文、中文、西班牙文、日語、法語、德語、韓語和阿拉伯語。
下圖進一步展示了二者的指令 - 響應(yīng)對對比(黃色方框為 LLaVA):

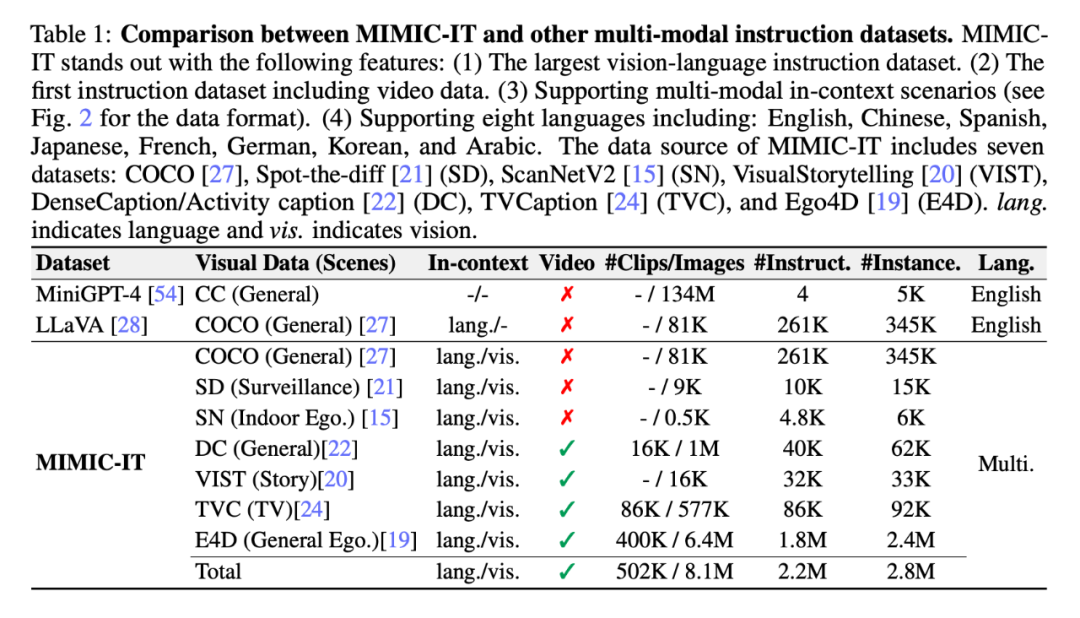
如表 1 所示,MIMIC-IT 的數(shù)據(jù)源來自七個數(shù)據(jù)集:COCO、Spot-the-diff (SD)、ScanNetV2 (SN)、VisualStorytelling (VIST) 、DenseCaption/Activity caption(DC)、TVCaption(TVC)和 Ego4D(E4D)。「上下文」這一列的「lang.」表示語言,「vis.」表示視覺。
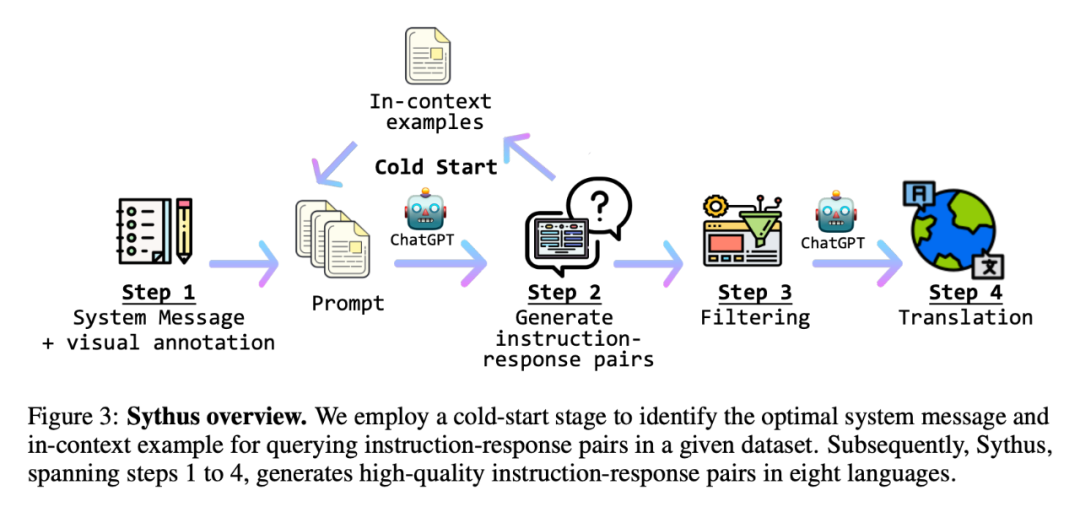
Sythus:自動化指令 - 響應(yīng)對生成 pipeline
同時,研究者提出了 Sythus(圖 3),這是一個自動化 pipeline,用于生成多種語言的高質(zhì)量指令 - 響應(yīng)對。在 LLaVA 提出的框架基礎(chǔ)上,研究者利用 ChatGPT 來生成基于視覺內(nèi)容的指令 - 響應(yīng)對。為了確保生成的指令 - 響應(yīng)對的質(zhì)量,該 pipeline 將系統(tǒng)信息、視覺注釋和上下文中的樣本作為 ChatGPT 的 prompt。系統(tǒng)信息定義了所生成的指令 - 響應(yīng)對的預(yù)期語氣和風格,而視覺注釋則提供了基本的圖像信息,如邊界框和圖像描述。上下文中的樣本幫助 ChatGPT 在語境中學習。
由于核心集的質(zhì)量會影響后續(xù)的數(shù)據(jù)收集過程,研究者采用了一個冷啟動策略,在大規(guī)模查詢之前加強上下文中的樣本。在冷啟動階段,采用啟發(fā)式方法,僅通過系統(tǒng)信息和視覺注釋來 prompt ChatGPT 收集上下文中的樣本。這個階段只有在確定了令人滿意的上下文中的樣本后才結(jié)束。在第四步,一旦獲得指令 - 響應(yīng)對,pipeline 會將它們擴展為中文(zh)、日文(ja)、西班牙文(es)、德文(de)、法文(fr)、韓文(ko)和阿拉伯語(ar)。進一步的細節(jié),可參考附錄 C,具體的任務(wù) prompt 可以在附錄 D 中找到。
經(jīng)驗性評估
隨后,研究者展示了 MIMIC-IT 數(shù)據(jù)集的各種應(yīng)用以及在其上訓練的視覺語言模型 (VLM) 的潛在能力。首先,研究者介紹了使用 MIMIC-IT 數(shù)據(jù)集開發(fā)的上下文指令調(diào)優(yōu)模型 Otter。而后,研究者探索了在 MIMIC-IT 數(shù)據(jù)集上訓練 Otter 的各種方法,并討論了可以有效使用 Otter 的眾多場景。
圖 5 是 Otter 在不同場景下的響應(yīng)實例。由于在 MIMIC-IT 數(shù)據(jù)集上進行了訓練,Otter 能夠為情境理解和推理、上下文樣本學習、自我中心的視覺助手服務(wù)。

最后,研究者在一系列基準測試中對 Otter 與其他 VLM 的性能進行了比較分析。
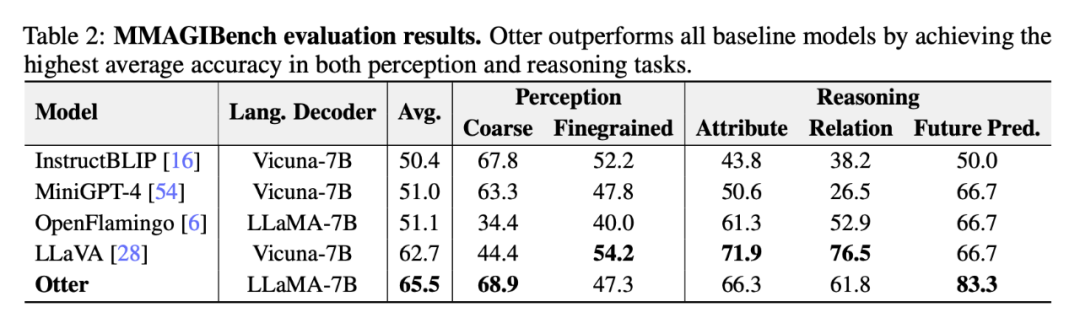
ChatGPT 評估
下表 2 展示了研究者利用 MMAGIBench 框架對視覺語言模型的感知和推理能力進行廣泛的評估。
人類評估
Multi-Modality Arena使用 Elo 評級系統(tǒng)來評估 VLM 響應(yīng)的有用性和一致性。圖 6 (b) 顯示 Otter 展示了卓越的實用性和一致性,在最近的 VLM 中獲得了最高的 Elo 評級。
少樣本上下文學習基準評估
Otter 基于 OpenFlamingo 進行微調(diào),OpenFlamingo 是一種專為多模態(tài)上下文學習而設(shè)計的架構(gòu)。使用 MIMIC-IT 數(shù)據(jù)集進行微調(diào)后,Otter 在 COCO 字幕 (CIDEr) 少樣本評估(見圖 6 (c))上的表現(xiàn)明顯優(yōu)于 OpenFlamingo。正如預(yù)期的那樣,微調(diào)還帶來了零樣本評估的邊際性能增益。

圖 6:ChatGPT 視頻理解的評估。
討論
缺陷。雖然研究者已經(jīng)迭代改進了系統(tǒng)消息和指令 - 響應(yīng)示例,但 ChatGPT 容易出現(xiàn)語言幻覺,因此它可能會生成錯誤的響應(yīng)。通常,更可靠的語言模型需要 self-instruct 數(shù)據(jù)生成。
未來工作。未來,研究者計劃支持更多具體地 AI 數(shù)據(jù)集,例如 LanguageTable 和 SayCan。研究者也考慮使用更值得信賴的語言模型或生成技術(shù)來改進指令集。
-
AI
+關(guān)注
關(guān)注
87文章
34144瀏覽量
275234 -
語言模型
+關(guān)注
關(guān)注
0文章
558瀏覽量
10659 -
數(shù)據(jù)集
+關(guān)注
關(guān)注
4文章
1222瀏覽量
25268
原文標題:280萬條多模態(tài)指令-響應(yīng)對,八種語言通用,首個涵蓋視頻內(nèi)容的指令數(shù)據(jù)集MIMIC-IT來了
文章出處:【微信號:AI智勝未來,微信公眾號:AI智勝未來】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
關(guān)于進程上下文、中斷上下文及原子上下文的一些概念理解
進程上下文與中斷上下文的理解
基于多Agent的用戶上下文自適應(yīng)站點構(gòu)架
基于交互上下文的預(yù)測方法
終端業(yè)務(wù)上下文的定義方法及業(yè)務(wù)模型
基于Pocket PC的上下文菜單實現(xiàn)
基于Pocket PC的上下文菜單實現(xiàn)
基于上下文相似度的分解推薦算法
基于低秩重檢測的多特征時空上下文的視覺跟蹤
初學OpenGL:什么是繪制上下文
如何分析Linux CPU上下文切換問題
網(wǎng)絡(luò)安全中的上下文感知
Linux技術(shù):什么是cpu上下文切換






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論