") GPU平臺(tái)生態(tài):英偉達(dá)CUDA和AMD ROCm對(duì)比分析
GPU平臺(tái)生態(tài):英偉達(dá)CUDA和AMD ROCm對(duì)比分析
成熟且完善的平臺(tái)生態(tài)是GPU廠(chǎng)商的護(hù)城河。相較于持續(xù)迭代的微架構(gòu)帶來(lái)的技術(shù)壁壘硬實(shí)力,成熟的軟件生態(tài)形成的強(qiáng)大用戶(hù)粘性將在長(zhǎng)時(shí)間內(nèi)塑造GPU廠(chǎng)商的軟實(shí)力。以英偉達(dá)CUDA為例的軟硬件設(shè)計(jì)架構(gòu)提供了硬件的直接訪(fǎng)問(wèn)接口,不必依賴(lài)圖形API映射,降低GPGPU開(kāi)發(fā)者編譯難度,以此實(shí)現(xiàn)高粘性的開(kāi)發(fā)者生態(tài)。目前主流的開(kāi)發(fā)平臺(tái)還包括AMD ROCm以及OpenCL。
CUDA(Compute Unified Device Architectecture),是NVIDIA于2006年推出的通用并行計(jì)算架構(gòu),包含CUDA指令集架構(gòu)(ISA)和GPU內(nèi)部的并行計(jì)算引擎。該架構(gòu)允許開(kāi)發(fā)者使用高級(jí)編程語(yǔ)言(例如C語(yǔ)言)利用GPU硬件的并行計(jì)算能力并對(duì)計(jì)算任務(wù)進(jìn)行分配和管理,CUDA提供了一種比CPU更有效的解決大規(guī)模數(shù)據(jù)計(jì)算問(wèn)題的方案,在深度學(xué)習(xí)訓(xùn)練和推理領(lǐng)域被廣泛使用。
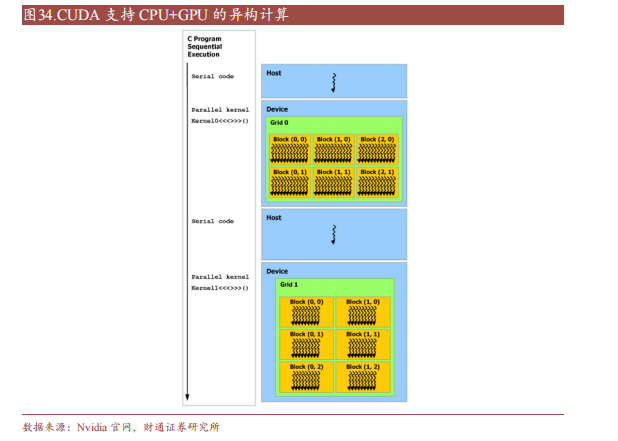
CUDA除了是并行計(jì)算架構(gòu)外,還是CPU和GPU協(xié)調(diào)工作的通用語(yǔ)言。在CUDA編程模型中,主要有Host(主機(jī))和Device(設(shè)備)兩個(gè)概念,Host包含CPU和主機(jī)內(nèi)存,Device包含GPU和顯存,兩者之間通過(guò)PCI Express總線(xiàn)進(jìn)行數(shù)據(jù)傳輸。在具體的CUDA實(shí)現(xiàn)中,程序通常劃分為兩部分,在主機(jī)上運(yùn)行的Host代碼和在設(shè)備上運(yùn)行的Device代碼。Host代碼負(fù)責(zé)程序整體的流程控制和數(shù)據(jù)交換,而Device代碼則負(fù)責(zé)執(zhí)行具體的計(jì)算任務(wù)。
一個(gè)完整的CUDA程序是由一系列的設(shè)備端函數(shù)并行部分和主機(jī)端的串行處理部分共同組成的,主機(jī)和設(shè)備通過(guò)這種方式可以高效地協(xié)同工作,實(shí)現(xiàn)GPU的加速計(jì)算。
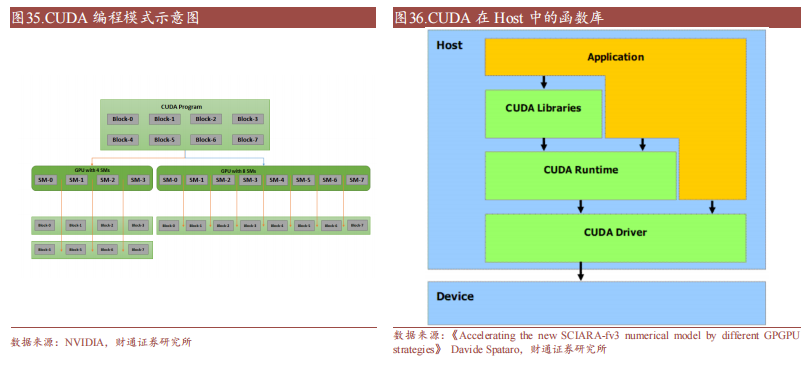
CUDA在Host運(yùn)行的函數(shù)庫(kù)包括了開(kāi)發(fā)庫(kù)(Libraries)、運(yùn)行時(shí)(Runtime)和驅(qū)動(dòng)(Driver)三大部分。其中,Libraries提供了一些常見(jiàn)的數(shù)學(xué)和科學(xué)計(jì)算任務(wù)運(yùn)算庫(kù),Runtime API提供了便捷的應(yīng)用開(kāi)發(fā)接口和運(yùn)行期組件,開(kāi)發(fā)者可以通過(guò)調(diào)用API自動(dòng)管理GPU資源,而Driver API提供了一系列C函數(shù)庫(kù),能更底層、更高效地控制GPU資源,但相應(yīng)的開(kāi)發(fā)者需要手動(dòng)管理模塊編譯等復(fù)雜任務(wù)。
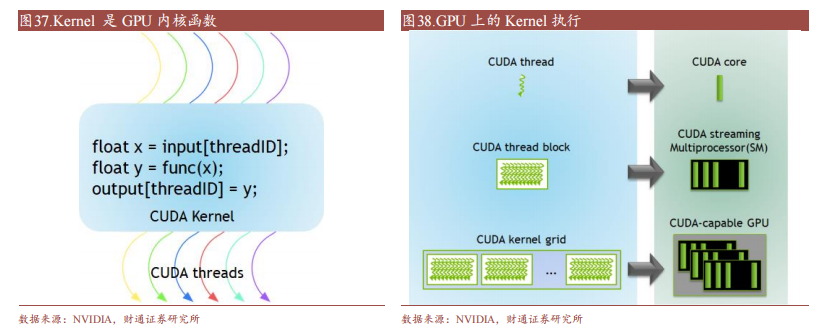
CUDA在Device上執(zhí)行的函數(shù)為內(nèi)核函數(shù)(Kernel)通常用于并行計(jì)算和數(shù)據(jù)處理。在Kernel中,并行部分由K個(gè)不同的CUDA線(xiàn)程并行執(zhí)行K次,而有別于普通的C/C++函數(shù)只有1次。每一個(gè)CUDA內(nèi)核都以一個(gè)聲明指定器開(kāi)始,程序員通過(guò)使用內(nèi)置變量__global__為每個(gè)線(xiàn)程提供一個(gè)唯一的全局ID。一組線(xiàn)程被稱(chēng)為CUDA塊(block)。CUDA塊被分組為一個(gè)網(wǎng)格(grid),一個(gè)內(nèi)核以線(xiàn)程塊的網(wǎng)格形式執(zhí)行。每個(gè)CUDA塊由一個(gè)流式多處理器(SM)執(zhí)行,不能遷移到GPU中的其他SM,一個(gè)SM可以運(yùn)行多個(gè)并發(fā)的CUDA塊,取決于CUDA塊所需的資源,每個(gè)內(nèi)核在一個(gè)設(shè)備上執(zhí)行,CUDA支持在一個(gè)設(shè)備上同時(shí)運(yùn)行多個(gè)內(nèi)核。
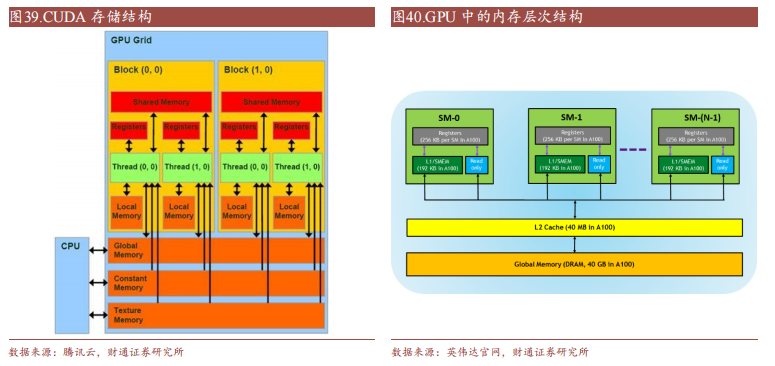
豐富而成熟的軟件生態(tài)是CUDA被廣泛使用的關(guān)鍵原因。
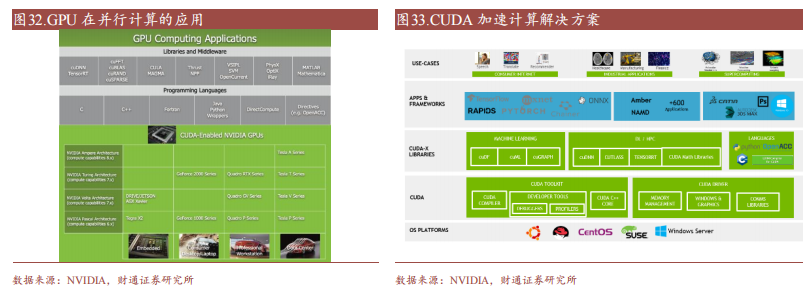
(1)編程語(yǔ)言:CUDA從最初的1.0版本僅支持C語(yǔ)言編程,到現(xiàn)在的CUDA 12.0支持C、C++、Fortran、Python等多種編程語(yǔ)言。此外,NVIDIA還支持了如PyCUDA、ltimesh Hybridizer、OpenACC等眾多第三方工具鏈,不斷提升開(kāi)發(fā)者的使用體驗(yàn)。
(2)庫(kù):NVIDIA在CUDA平臺(tái)上提供了名為CUDA-X的集合層,開(kāi)發(fā)人員可以通過(guò)CUDA-X快速部署如cuBLA、NPP、NCCL、cuDNN、TensorRT、OpenCV等多領(lǐng)域常用庫(kù)。
(3)其他:NVIDIA還為CUDA開(kāi)發(fā)人員提供了容器部署流程簡(jiǎn)化以及集群環(huán)境擴(kuò)展應(yīng)用程序的工具,讓?xiě)?yīng)用程序更易加速,使得CUDA技術(shù)能夠適用于更廣泛的領(lǐng)域。
ROCm(Radeon Open Compute Platform)是AMD基于開(kāi)源項(xiàng)目的GPU計(jì)算生態(tài)系統(tǒng),類(lèi)似于NVIDIA的CUDA。ROCm支持多種編程語(yǔ)言、編譯器、庫(kù)和工具,以加速科學(xué)計(jì)算、人工智能和機(jī)器學(xué)習(xí)等領(lǐng)域的應(yīng)用。ROCm還支持多種加速器廠(chǎng)商和架構(gòu),提供了開(kāi)放的可移植性和互操作性。
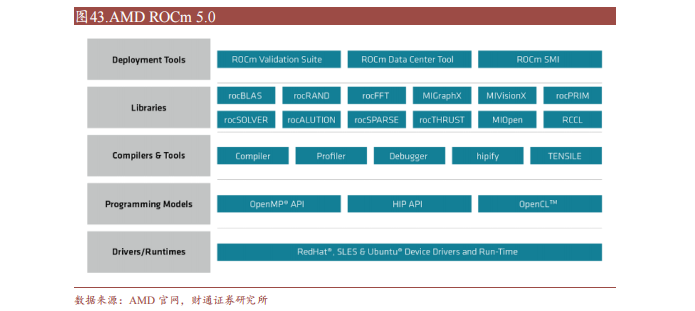
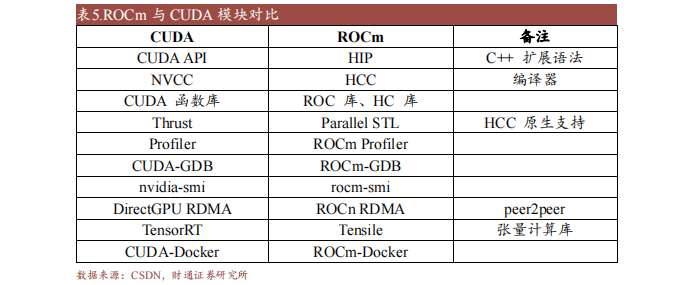
ROCm支持HIP(類(lèi)CUDA)和OpenCL兩種GPU編程模型,可實(shí)現(xiàn)CUDA到ROCm的遷移。最新的ROCm 5.0支持AMD Infinity Hub上的人工智能框架容器,包括TensorFlow 1.x、PyTorch 1.8、MXNet等,同時(shí)改進(jìn)了ROCm庫(kù)和工具的性能和穩(wěn)定性,包括MIOpen、MIVisionX、rocBLAS、rocFFT、rocRAND等。
OpenCL(Open Compute Language),是面向異構(gòu)系統(tǒng)通用并行編程、可以在多個(gè)平臺(tái)和設(shè)備上運(yùn)行的開(kāi)放標(biāo)準(zhǔn)。OpenCL支持多種編程語(yǔ)言和環(huán)境,并提供豐富的工具來(lái)幫助開(kāi)發(fā)和調(diào)試,可以同時(shí)利用CPU、GPU、DSP等不同類(lèi)型的加速器來(lái)執(zhí)行任務(wù),并支持?jǐn)?shù)據(jù)傳輸和同步。
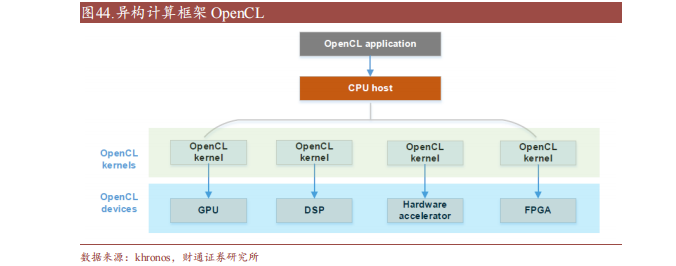
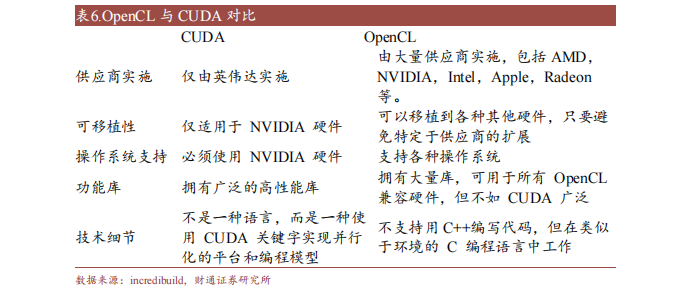
此外,OpenCL支持細(xì)粒度和粗粒度并行編程模型,可根據(jù)應(yīng)用需求選擇合適模型提高性能和效率。而OpenCL可移植性有限,不同平臺(tái)和設(shè)備的功能支持和性能表現(xiàn)存在一定差異,與CUDA相比缺少?gòu)V泛的社區(qū)支持和成熟的生態(tài)圈。
-
amd
+關(guān)注
關(guān)注
25文章
5557瀏覽量
135847 -
gpu
+關(guān)注
關(guān)注
28文章
4908瀏覽量
130622 -
C語(yǔ)言
+關(guān)注
關(guān)注
180文章
7630瀏覽量
140178 -
CUDA
+關(guān)注
關(guān)注
0文章
122瀏覽量
14049 -
英偉達(dá)
+關(guān)注
關(guān)注
22文章
3920瀏覽量
93081
原文標(biāo)題:GPU平臺(tái)生態(tài):英偉達(dá)CUDA和AMD ROCm對(duì)比分析
文章出處:【微信號(hào):AI_Architect,微信公眾號(hào):智能計(jì)算芯世界】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
英偉達(dá)、AMD、英特爾GPU產(chǎn)品及優(yōu)勢(shì)匯總
軟件生態(tài)上超越CUDA,究竟有多難?
打破英偉達(dá)CUDA壁壘?AMD顯卡現(xiàn)在也能無(wú)縫適配CUDA了
英偉達(dá)發(fā)布新一代 GPU 架構(gòu)圖靈和 GPU 系列 Quadro RTX
AMD迎頭猛追Intel 全球首發(fā)7nm GPU很威風(fēng)!
恩智浦S32V/英偉達(dá)DRIVE PX2/TI的TDA4/寒武紀(jì)1M/高通SA8155對(duì)比分析哪個(gè)好?
英偉達(dá)DPU的過(guò)“芯”之處
英偉達(dá)黃仁勛:GPU加速計(jì)算是發(fā)展方向
國(guó)產(chǎn)GPU繞不開(kāi)的CUDA生態(tài)
GPU平臺(tái)生態(tài),英偉達(dá)CUDA和AMD ROCm對(duì)比分析

AMD 發(fā)布新的AMD ROCm 5.6開(kāi)放軟件平臺(tái)
英偉達(dá)A100和A40的對(duì)比
GPU技術(shù)、生態(tài)及算力分析






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論