") OpenAI要為GPT-4解決數(shù)學(xué)問題了:獎勵模型指錯,解題水平達到新高度
OpenAI要為GPT-4解決數(shù)學(xué)問題了:獎勵模型指錯,解題水平達到新高度
對于具有挑戰(zhàn)性的 step-by-step 數(shù)學(xué)推理問題,是在每一步給予獎勵還是在最后給予單個獎勵更有效呢?OpenAI 的最新研究給出了他們的答案。
現(xiàn)在,大語言模型迎來了「無所不能」的時代,其中在執(zhí)行復(fù)雜多步推理方面的能力也有了很大提高。不過,即使是最先進的大模型也會產(chǎn)生邏輯錯誤,通常稱為幻覺。因此,減輕幻覺是構(gòu)建對齊 AGI 的關(guān)鍵一步。
為了訓(xùn)練更可靠的模型,目前可以選擇兩種不同的方法來訓(xùn)練獎勵模型,一種是結(jié)果監(jiān)督,另一種是過程監(jiān)督。結(jié)果監(jiān)督獎勵模型(ORMs)僅使用模型思維鏈的最終結(jié)果來訓(xùn)練,而過程監(jiān)督獎勵模型(PRMs)則接受思維鏈中每個步驟的獎勵。
考慮到訓(xùn)練可靠模型的重要性以及人工反饋的高成本,仔細比較結(jié)果監(jiān)督與過程監(jiān)督非常重要。雖然最近的工作已經(jīng)開展了這種比較,但仍然存在很多問題。
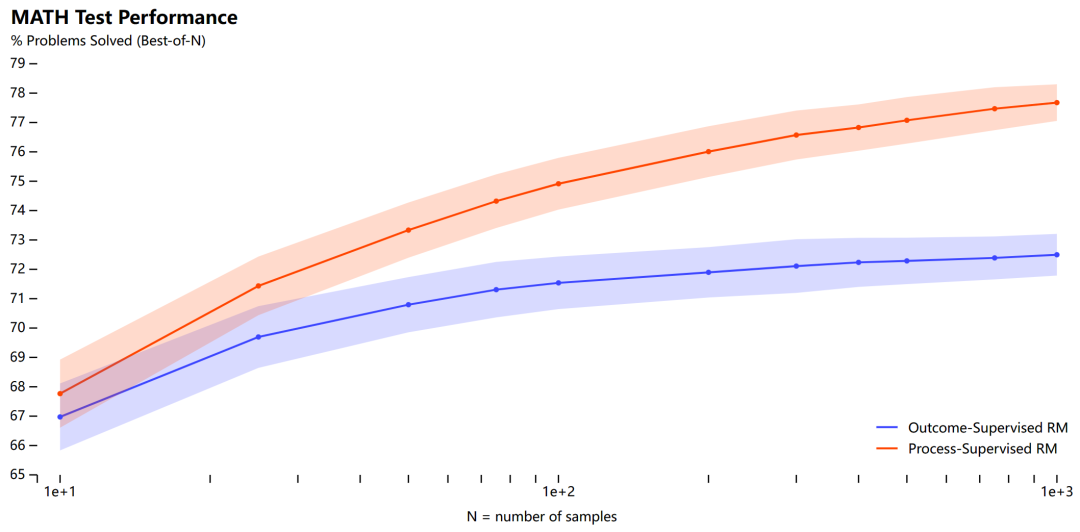
在本文中,OpenAI 進行了調(diào)研,結(jié)果發(fā)現(xiàn)在訓(xùn)練模型解決 MATH 數(shù)據(jù)集的問題時,過程監(jiān)督顯著優(yōu)于結(jié)果監(jiān)督。OpenAI 使用自己的 PRM 模型解決了 MATH 測試集中代表性子集的 78% 的問題。
此外為了支持相關(guān)研究,OpenAI 還開源了 PRM800K,它是一個包含 800K 個步級人類反饋標(biāo)簽的完整數(shù)據(jù)集,用于訓(xùn)練它們的最佳獎勵模型。
如下為一個真正(True positive)的問答示例。該問題以及 OpenAI 列舉的其他問題示例均來自 GPT-4。這個具有挑戰(zhàn)性的三角學(xué)問題需要并不明顯地連續(xù)應(yīng)用多個恒等式。大多數(shù)解決方案嘗試都失敗了,因為很難知道哪些恒等式實際上有用。盡管 GPT-4 通常無法解決這個問題(正確率僅為 0.1% ),但本文的獎勵模型正確地識別出了這個解決方案是有效的。

再看一個假正(False positive)的問答示例。在第四步中,GPT-4 錯誤地聲稱該序列每 12 個項重復(fù)一次,而實際上是每 10 個項重復(fù)一次。這種計數(shù)錯誤偶爾會愚弄獎勵模型。

論文作者之一、OpenAI Alignment 團隊負責(zé)人 Jan Leike 表示,「使用 LLM 做數(shù)學(xué)題的真正有趣結(jié)果是:監(jiān)督每一步比只檢查答案更有效。」
英偉達 AI 科學(xué)家 Jim Fan 認為,「這篇論文的觀點很簡單:對于挑戰(zhàn)性的逐步問題,要在每一步給予獎勵,而不要在最后給予單個獎勵。從根本上來說,密集獎勵信號>稀疏。」

我們接下來細看 OpenAI 這篇論文的方法和結(jié)果。

論文地址:https://cdn.openai.com/improving-mathematical-reasoning-with-process-supervision/Lets_Verify_Step_by_Step.pdf
數(shù)據(jù)集地址:https://github.com/openai/prm800k
方法概覽
該研究按照與 Uesato et al. (2022) 類似的方法對結(jié)果監(jiān)督和過程監(jiān)督進行了比較。值得注意的是這項研究無需人工即可提供結(jié)果監(jiān)督,因為 MATH 數(shù)據(jù)集中的所有問題都有可自動檢查的答案。相比之下,沒有簡單的方法來自動化過程監(jiān)督。該研究依靠人類數(shù)據(jù)標(biāo)記者來提供過程監(jiān)督,具體來說是需要人工標(biāo)記模型生成的解決方案中每個步驟的正確性。該研究在大規(guī)模和小規(guī)模兩種情況下分別進行了實驗。
范圍
對于每種模型規(guī)模,該研究都使用一個固定模型來生成所有解決方案。這個模型被稱為生成器,OpenAI 表示不會通過強化學(xué)習(xí) (RL) 來改進生成器。
基礎(chǔ)模型
所有大型模型均是基于 GPT-4 模型進行微調(diào)得來的。該研究還添加了一個額外的預(yù)訓(xùn)練步驟 —— 在含有約 1.5B 數(shù)學(xué)相關(guān) token 的數(shù)據(jù)集 MathMix 上微調(diào)所有模型。與 Lewkowycz et al. (2022) 類似,OpenAI 的研究團隊發(fā)現(xiàn)這種方法可以提高模型的數(shù)學(xué)推理能力。
生成器
為了更容易解析單個步驟,該研究訓(xùn)練生成器在生成解決方案時,步驟之間用換行符分隔。具體來說,該研究對 MATH 訓(xùn)練問題使用少樣本生成解決方案,過濾出得到最終正確答案的解決方案,并在該數(shù)據(jù)集上對基礎(chǔ)模型進行一個 epoch 的微調(diào)。
數(shù)據(jù)采集
為了收集過程監(jiān)督數(shù)據(jù),該研究向人類數(shù)據(jù)標(biāo)記者展示了大規(guī)模生成器采樣的數(shù)學(xué)問題的逐步解決方案。人類數(shù)據(jù)標(biāo)記者的任務(wù)是為解決方案中的每個步驟分配正面、負面或中性標(biāo)簽,如下圖 1 所示。

該研究只標(biāo)記大型生成器生成的解決方案,以最大限度地發(fā)揮有限的人工數(shù)據(jù)資源的價值。該研究將收集到的按步驟標(biāo)記的整個數(shù)據(jù)集稱為 PRM800K。PRM800K 訓(xùn)練集包含 800K 步驟標(biāo)簽,涵蓋 12K 問題的 75K 解決方案。為了最大限度地減少過擬合,PRM800K 訓(xùn)練集包含來自 MATH 的 4.5K 測試問題數(shù)據(jù),并僅在剩余的 500 個 MATH 測試問題上評估模型。
結(jié)果監(jiān)督獎勵模型 (ORM)
該研究按照與 Cobbe et al. (2021) 類似的方法訓(xùn)練 ORM,并從生成器中為每個問題采樣固定數(shù)量的解決方案,然后訓(xùn)練 ORM 來預(yù)測每個解決方案的正確與否。實踐中,自動檢查最終答案來確定正確性是一種常用的方法,但原則上由人工標(biāo)記者來提供標(biāo)簽。在測試時,該研究使用 ORM 在最終 token 處的預(yù)測作為每個解決方案的總分。
過程監(jiān)督獎勵模型(PRM)
PRM 用來預(yù)測每個步驟(step)中最后一個 token 之后的步驟的正確性。這種預(yù)測采用單個 token 形式,并且 OpenAI 在訓(xùn)練過程中最大化這些目標(biāo) token 的對數(shù)似然。因此,PRM 可以在標(biāo)準(zhǔn)的語言模型 pipeline 中進行訓(xùn)練,無需任何特殊的適應(yīng)措施。
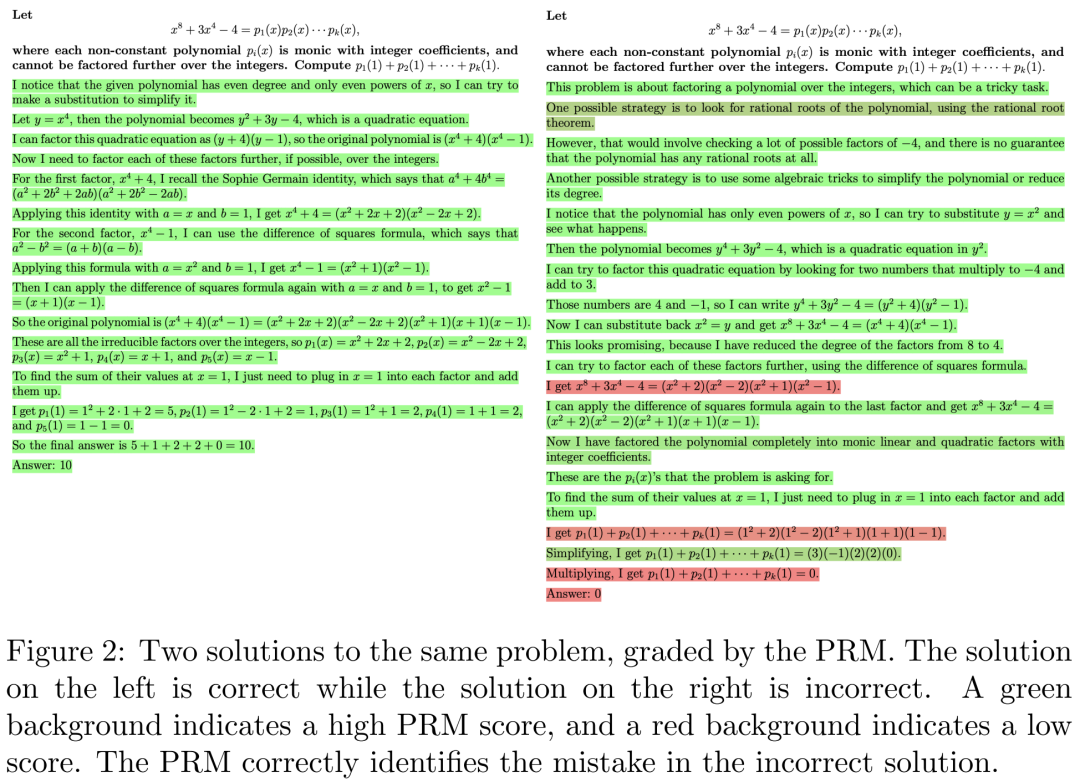
圖 2 為同一個問題的 2 種解決方案,左邊的答案是正確的,右邊的答案是錯誤的。綠色背景表示 PRM 得分高,紅色背景表示 PRM 得分低。PRM 可以正確識別錯誤解決方案中的錯誤。
在進行過程監(jiān)督時,OpenAI 有意選擇僅對第一個錯誤步驟進行監(jiān)督,從而使得結(jié)果監(jiān)督和過程監(jiān)督之間的比較更加直接。對于正確的解決方案,兩種方法提供的信息相同,因為每一步都是正確的解題方法。對于錯誤的解決方案,兩種方法都能揭示至少存在一個錯誤,并且過程監(jiān)督還揭示了該錯誤的確切位置。
大規(guī)模監(jiān)督
OpenAI 使用全流程監(jiān)督數(shù)據(jù)集 PRM800K 來訓(xùn)練 PRM,為了使 ORM 基準(zhǔn)更加強大,OpenAI 還為每個問題進行了 100 個樣本的訓(xùn)練,這些樣本均來自生成器,由此 ORM 訓(xùn)練集與 PRM800K 沒有重疊樣本。
下圖為結(jié)果監(jiān)督和過程監(jiān)督獎勵模型以及投票方案的比較,結(jié)果表明在搜索模型生成的解決方案時,PRM 比 ORM 和多數(shù)投票更有效。

小規(guī)模綜合監(jiān)督
為了更好的比較結(jié)果監(jiān)督和過程監(jiān)督,首先需要注意的是 ORM 和 PRM 的訓(xùn)練集不具有直接可比性,PRM 訓(xùn)練集是使用主動學(xué)習(xí)構(gòu)建的,偏向于答案錯誤的解決方案,還比 ORM 訓(xùn)練集少一個數(shù)量級。
過程監(jiān)督 VS 結(jié)果監(jiān)督
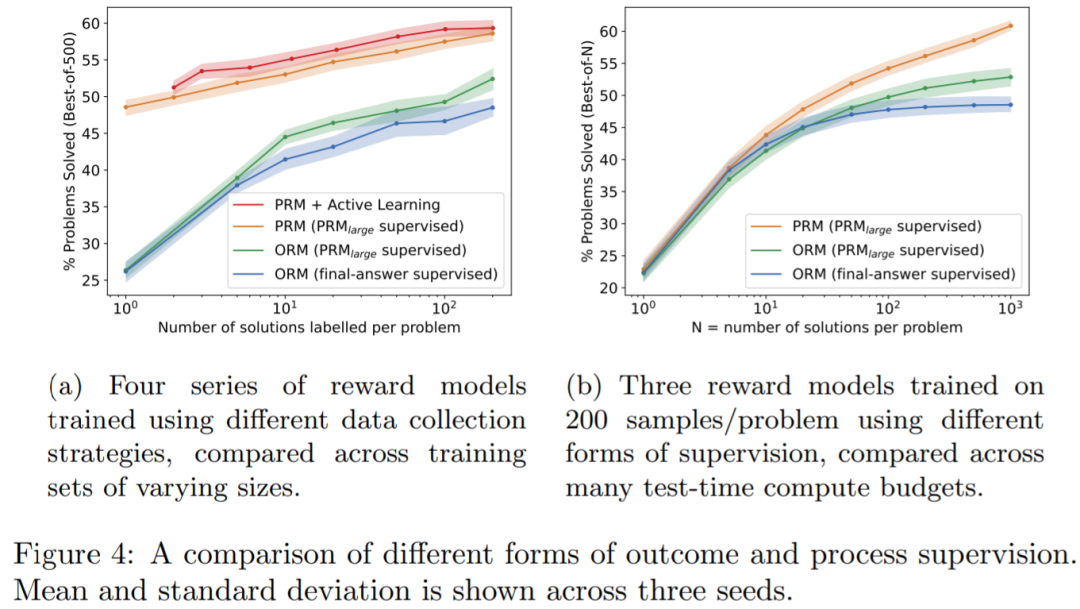
首先 OpenAI 從小規(guī)模生成器中為每個問題采樣 1 到 200 個解決方案。對于每個數(shù)據(jù)集,OpenAI 提供三種形式的監(jiān)督:來自 PRM_large 的過程監(jiān)督,來自 PRM_large 的結(jié)果監(jiān)督以及來自最終答案檢查的結(jié)果監(jiān)督。
圖 4a 表明,過程監(jiān)督明顯優(yōu)于其他兩種形式的結(jié)果監(jiān)督;圖 4b 表明,使用 PRM_large 進行結(jié)果監(jiān)督明顯比最終答案檢查的結(jié)果監(jiān)督更有效。
OOD 泛化
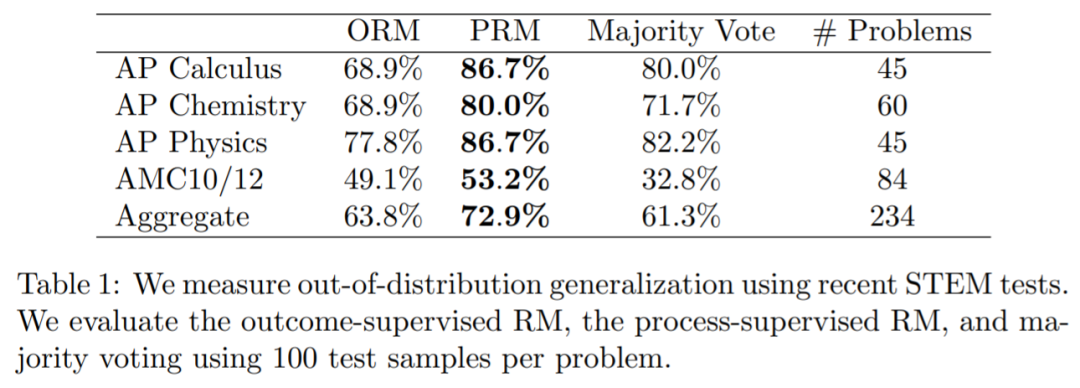
為了衡量模型在分布外(OOD)泛化的性能,OpenAI 對大規(guī)模 ORM 和 PRM 在一個由 224 個 STEM 問題組成的 held-out(留出法)上進行評估,這些問題來自最新的 AP 物理(美國大學(xué)先修課程簡稱 AP)、AP 微積分、AP 化學(xué)、AMC10(理解為數(shù)學(xué)競賽)和 AMC12 考試,模型沒有見過這些問題。表格 1 中報告了 ORM、PRM 和多數(shù)投票的前 100 個的最佳表現(xiàn)。表明,PRM 的性能優(yōu)于 ORM 和多數(shù)投票,同時意味著 PRM 在新的測試問題上性能仍然保持不變。
原文標(biāo)題:OpenAI要為GPT-4解決數(shù)學(xué)問題了:獎勵模型指錯,解題水平達到新高度
文章出處:【微信公眾號:智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
-
物聯(lián)網(wǎng)
+關(guān)注
關(guān)注
2927文章
45847瀏覽量
387664
原文標(biāo)題:OpenAI要為GPT-4解決數(shù)學(xué)問題了:獎勵模型指錯,解題水平達到新高度
文章出處:【微信號:tyutcsplab,微信公眾號:智能感知與物聯(lián)網(wǎng)技術(shù)研究所】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
OpenAI簡化大模型選擇:薩姆·奧特曼制定路線圖
OpenAI宣布GPT 4o升智計劃
OpenAI即將發(fā)布GPT-4.5與GPT-5
OpenAI即將推出GPT-5模型
OpenAI報告GPT-4o及4o-mini模型性能下降,正緊急調(diào)查
OpenAI:GPT-4o及4o-mini模型性能下降,正展開調(diào)查
Llama 3 與 GPT-4 比較
科大訊飛發(fā)布訊飛星火4.0 Turbo:七大能力超GPT-4 Turbo
OpenAI即將發(fā)布“草莓”推理大模型
OpenAI宣布啟動GPT Next計劃
OpenAI 推出 GPT-4o mini 取代GPT 3.5 性能超越GPT 4 而且更快 API KEY更便宜

OpenAI揭秘CriticGPT:GPT自進化新篇章,RLHF助力突破人類能力邊界
OpenAI推出新模型CriticGPT,用GPT-4自我糾錯
OpenAI API Key獲取:開發(fā)人員申請GPT-4 API Key教程
國內(nèi)直聯(lián)使用ChatGPT 4.0 API Key使用和多模態(tài)GPT4o API調(diào)用開發(fā)教程!






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論