 CPU的硬件運行效率
CPU的硬件運行效率
提到CPU性能,大部分同學想到的都是CPU利用率,這個指標確實應該首先被關注。但是除了利用率之外,還有很容易被人忽視的指標,就是指令的運行效率。如果運行效率不高,那CPU利用率再忙也都是瞎忙,產出并不高。
這就好比人,每天都是很忙,但其實每天的效率并不一樣。有的時候一天干了很多事情,但有的時候只是瞎忙了一天,回頭一看,啥也沒干!
一、CPU 硬件運行效率
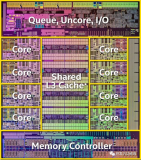
那啥是CPU的運行效率呢?介紹這個之前我們得先來簡單回顧下CPU的構成和工作原理。CPU在生產過程結束后,在硬件上就被***刻成了各種各樣的模塊。
在上面的物理結構圖中,可以看到每個物理核和L3 Cache的分布情況。另外就是在每個物理核中,還包括了更多組件。每個核都會集成自己獨占使用的寄存器和緩存,其中緩存包括L1 data、L1 code 和L2。
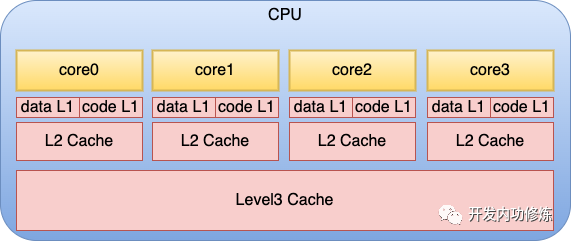
服務程序在運行的過程中,就是CPU核不斷地從存儲中獲取要執行的指令,以及需要運算的數據。這里所謂的存儲包括寄存器、L1 data緩存、L1 code緩存、L2 緩存、L3緩存,以及內存。 當一個服務程序被啟動的時候,它會通過缺頁中斷的方式被加載到內存中。當 CPU 運行服務時,它不斷從內存讀取指令和數據,進行計算處理,然后將結果再寫回內存。
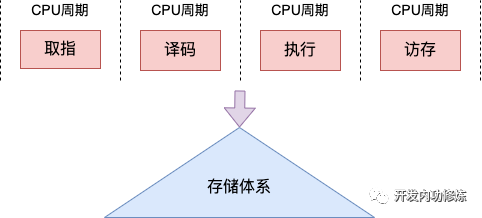
不同的 CPU 流水線不同。在經典的 CPU 的流水線中,每個指令周期通常包括取指、譯碼、執行和訪存幾個階段。
在取指階段,CPU 從內存中取出指令,將其加載到指令寄存器中。
在譯碼階段,CPU 解碼指令,確定要執行的操作類型,并將操作數加載到寄存器中。
在執行階段,CPU 執行指令,并將結果存儲在寄存器中。
在訪存階段,CPU 根據需要將數據從內存寫入寄存器中,或將寄存器中的數據寫回內存。
但,內存的訪問速度是非常慢的。CPU一個指令周期一般只是零點幾個納秒,但是對于內存來說,即使是最快的順序 IO,那也得 10 納秒左右,如果碰上隨機IO,那就是 30-40 納秒左右的開銷。
所以CPU為了加速運算,自建了臨時數據存儲倉庫。就是我們上面提到的各種緩存,包括每個核都有的寄存器、L1 data、L1 code 和L2緩存,也包括整個CPU共享的L3,還包括專門用于虛擬內存到物理內存地址轉換的TLB緩存。
拿最快的寄存器來說,耗時大約是零點幾納秒,和CPU就工作在一個節奏下了。再往下的L1大約延遲在 2 ns 左右,L2大約 4 ns 左右,依次上漲。
但速度比較慢的存儲也有個好處,離CPU核更遠,可以把容量做到更大。所以CPU訪問的存儲在邏輯上是一個金字塔的結構。越靠近金字塔尖的存儲,其訪問速度越快,但容量比較小。越往下雖然速度略慢,但是存儲體積更大。
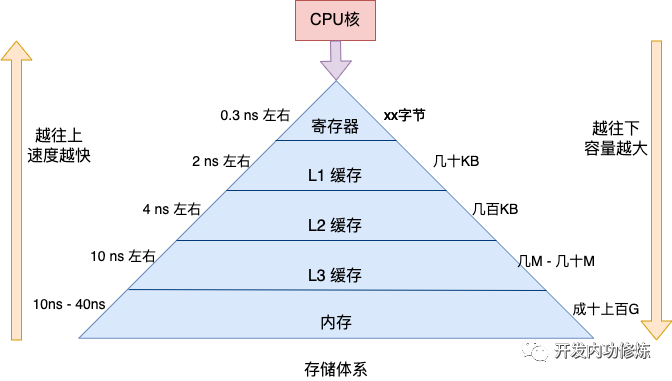
基本原理就介紹這么多。現在我們開始思考指令運行效率。根據上述金字塔圖我們可以很清楚地看到,如果服務程序運行時所需要的指令存儲都位于金字塔上方的話,那服務運行的效率就高。如果程序寫的不好,或者內核頻繁地把進程在不同的物理核之間遷移(不同核的L1和L2等緩存不是共享的),那上方的緩存就會命中率變低,更多的請求穿透到L3,甚至是更下方的內存中訪問,程序的運行效率就會變差。
那如何衡量指令運行效率呢?指標主要有以下兩類
第一類是CPI和IPC。
CPI全稱是cycle per instruction,指的是平均每條指令的時鐘周期個數。IPC的全稱是instruction per cycle,表示每時鐘周期運行多少個指令。這兩個指標可以幫助我們分析我們的可執行程序運行的快還是慢。由于這二位互為倒數,所以實踐中只關注一個CPI就夠了。
CPI 指標可以讓我們從整體上對程序的運行速度有一個把握。假如我們的程序運行緩存命中率高,大部分數據都在緩存中能訪問到,那 CPI 就會比較的低。假如說我們的程序的局部性原理把握的不好,或者是說內核的調度算法有問題,那很有可能執行同樣的指令就需要更多的CPU周期,程序的性能也會表現的比較的差,CPI 指標也會偏高。
第二類是緩存命中率。
緩存命中率指標分析的是程序運行時讀取數據時有多少沒有被緩存兜住,而穿透訪問到內存中了。穿透到內存中訪問速度會慢很多。所以程序運行時的 Cachemiss 指標就是越低越好了。
二、如何評估CPU硬件效率
上一小節我們說到CPU硬件工作效率的指標主要有 CPI 和緩存命中率。那么我們該如何獲取這些指標呢?
2.1 使用 perf 工具
第一個辦法是采用 Linux 默認自帶的 perf 工具。使用 perf list 可以查看當前系統上支持的硬件事件指標。
#perflisthwcache Listofpre-definedevents(tobeusedin-e): branch-instructionsORbranches[Hardwareevent] branch-misses[Hardwareevent] bus-cycles[Hardwareevent] cache-misses[Hardwareevent] cache-references[Hardwareevent] cpu-cyclesORcycles[Hardwareevent] instructions[Hardwareevent] ref-cycles[Hardwareevent] L1-dcache-load-misses[Hardwarecacheevent] L1-dcache-loads[Hardwarecacheevent] L1-dcache-stores[Hardwarecacheevent] L1-icache-load-misses[Hardwarecacheevent] branch-load-misses[Hardwarecacheevent] branch-loads[Hardwarecacheevent] dTLB-load-misses[Hardwarecacheevent] dTLB-loads[Hardwarecacheevent] dTLB-store-misses[Hardwarecacheevent] dTLB-stores[Hardwarecacheevent] iTLB-load-misses[Hardwarecacheevent] iTLB-loads[Hardwarecacheevent]
上述輸出中我們挑幾個重要的來解釋一下
cpu-cycles: 消耗的CPU周期
instructions: 執行的指令計數,結合cpu-cycles可以計算出CPI(每條指令需要消耗的平均周期數)
L1-dcache-loads: 一級數據緩存讀取次數
L1-dcache-load-missed: 一級數據緩存讀取失敗次數,結合L1-dcache-loads可以計算出L1級數據緩存命中率
dTLB-loads:dTLB緩存讀取次數
dTLB-load-misses:dTLB緩存讀取失敗次數,結合dTLB-loads同樣可以算出緩存命中率
使用 perf stat 命令可以統計當前系統或者指定進程的上面這些指標。直接使用 perf stat 可以統計到CPI。(如果要統計指定進程的話只需要多個 -p 參數,寫名 pid 就可以了)
#perfstatsleep5 Performancecounterstatsfor'sleep5': ...... 1,758,466cycles#2.575GHz 871,474instructions#0.50insnpercycle
從上述結果 instructions 后面的注釋可以看出,當前系統的 IPC 指標是 0.50,也就是說平均一個 CPU 周期可以執行 0.5 個指令。前面我們說過 CPI 和 IPC 互為倒數,所以 1/0.5 我們可以計算出 CPI 指標為 2。也就是說平均一個指令需要消耗 2 個CPU周期。
我們再來看看 L1 和 dTLB 的緩存命中率情況,這次需要在 perf stat 后面跟上 -e 選項來指定要觀測的指標了,因為這幾個指標默認都不輸出。
#perfstat-eL1-dcache-load-misses,L1-dcache-loads,dTLB-load-misses,dTLB-loadssleep5 Performancecounterstatsfor'sleep5': 22,578L1-dcache-load-misses#10.22%ofallL1-dcacheaccesses 220,911L1-dcache-loads 2,101dTLB-load-misses#0.95%ofalldTLBcacheaccesses 220,911dTLB-loads
上述結果中 L1-dcache-load-misses 次數為22,578,總的 L1-dcache-loads 為 220,911。可以算出 L1-dcache 的緩存訪問失敗率大約是 10.22%。同理我們可以算出 dTLB cache 的訪問失敗率是 0.95。這兩個指標雖然已經不高了,但是實踐中仍然是越低越好。
2.2 直接使用內核提供的系統調用
雖然 perf 給我們提供了非常方便的用法。但是在某些業務場景中,你可能仍然需要自己編程實現數據的獲取。這時候就只能繞開 perf 直接使用內核提供的系統調用來獲取這些硬件指標了。
開發步驟大概包含這么兩個步驟
第一步:調用 perf_event_open 創建 perf 文件描述符
第二步:定時 read 讀取 perf 文件描述符獲取數據
其核心代碼大概如下。為了避免干擾,我只保留了主干。完整的源碼我放到咱們開發內功修改的 Github 上了。
Github地址:https://github.com/yanfeizhang/coder-kung-fu/blob/main/tests/cpu/test08/main.c
intmain()
{
//第一步:創建perf文件描述符
structperf_event_attrattr;
attr.type=PERF_TYPE_HARDWARE;//表示監測硬件
attr.config=PERF_COUNT_HW_INSTRUCTIONS;//標志監測指令數
//第一個參數pid=0表示只檢測當前進程
//第二個參數cpu=-1表示檢測所有cpu核
intfd=perf_event_open(&attr,0,-1,-1,0);
//第二步:定時獲取指標計數
while(1)
{
read(fd,&instructions,sizeof(instructions));
...
}
}
在源碼中首先聲明了一個創建 perf 文件所需要的 perf_event_attr 參數對象。這個對象中 type 設置為 PERF_TYPE_HARDWARE 表示監測硬件事件。config 設置為 PERF_COUNT_HW_INSTRUCTIONS 表示要監測指令數。
然后調用 perf_event_open系統調用。在該系統調用中,除了 perf_event_attr 對象外,pid 和 cpu 這兩個參數也是非常的關鍵。其中 pid 為 -1 表示要監測所有進程,為 0 表示監測當前進程,> 0 表示要監測指定 pid 的進程。對于 cpu 來說。-1 表示要監測所有的核,其它值表示只監測指定的核。
內核在分配到 perf_event 以后,會返回一個文件句柄fd。后面這個perf_event結構可以通過read/write/ioctl/mmap通用文件接口來操作。
perf_event 編程有兩種使用方法,分別是計數和采樣。本文中的例子是最簡單的技術。對于采樣場景,支持的功能更豐富,可以獲取調用棧,進而渲染出火焰圖等更高級的功能。這種情況下就不能使用簡單的 read ,需要給 perf_event 分配 ringbuffer 空間,然后通過mmap系統調用來讀取了。在 perf 中對應的功能是 perf record/report 功能。
將完整的源碼編譯運行后。
#gccmain.c-omain #./main instructions=1799 instructions=112654 instructions=123078 instructions=133505 ...
三、perf內部工作原理
你以為看到這里本文就結束了?大錯特錯!只講用法不講原理從來不是咱們開發內功修煉公眾號的風格。
所以介紹完如何獲取硬件指標后,咱們接下來也會展開聊聊上層的軟件是如何和CPU硬件協同來獲取到底層的指令數、緩存命中率等指標的。展開聊聊底層原理。
CPU的硬件開發者們也想到了軟件同學們會有統計觀察硬件指標的需求。所以在硬件設計的時候,加了一類專用的寄存器,專門用于系統性能監視。關于這部分的描述參見Intel官方手冊的第18節。這個手冊你在網上可以搜到,我也會把它丟到我的讀者群里,還沒進群的同學加我微信 zhangyanfei748527。
這類寄存器的名字叫硬件性能計數器(PMC: Performance Monitoring Counter)。每個PMC寄存器都包含一個計數器和一個事件選擇器,計數器用于存儲事件發生的次數,事件選擇器用于確定所要計數的事件類型。例如,可以使用PMC寄存器來統計 L1 緩存命中率或指令執行周期數等。當CPU執行到 PMC 寄存器所指定的事件時,硬件會自動對計數器加1,而不會對程序的正常執行造成任何干擾。
有了底層的支持,上層的 Linux 內核就可以通過讀取這些 PMC 寄存器的值來獲取想要觀察的指標了。整體的工作流程圖如下
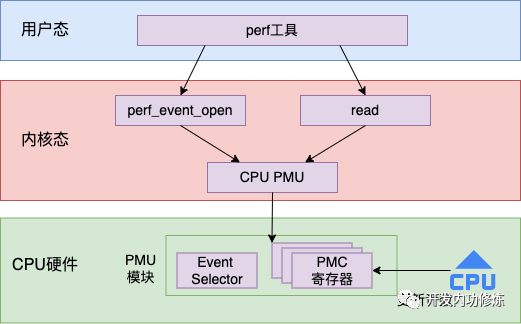
接下來我們再從源碼的視角展開看一下這個過程。
3.1 CPU PMU 的初始化
Linux 的 PMU (Performance Monitoring Unit)子系統是一種用于監視和分析系統性能的機制。它將每一種要觀察的指標都定義為了一個 PMU,通過 perf_pmu_register 函數來注冊到系統中。
其中對于 CPU 來說,定義了一個針對 x86 架構 CPU 的 PMU,并在開機啟動的時候就會注冊到系統中。
//file:arch/x86/events/core.c
staticstructpmupmu={
.pmu_enable=x86_pmu_enable,
.read=x86_pmu_read,
...
}
staticint__initinit_hw_perf_events(void)
{
...
err=perf_pmu_register(&pmu,"cpu",PERF_TYPE_RAW);
}
3.2 perf_event_open 系統調用
在前面的實例代碼中,我們看到是通過 perf_event_open 系統調用來創建了一個 perf 文件。我們來看下這個創建過程都做了啥?
//file:kernel/events/core.c
SYSCALL_DEFINE5(perf_event_open,
structperf_event_attr__user*,attr_uptr,
pid_t,pid,int,cpu,int,group_fd,unsignedlong,flags)
{
...
//1.為調用者申請新文件句柄
event_fd=get_unused_fd_flags(f_flags);
...
//2.根據用戶參數attr,定位pmu對象,通過pmu初始化event
event=perf_event_alloc(&attr,cpu,task,group_leader,NULL,
NULL,NULL,cgroup_fd);
pmu=event->pmu;
//3.創建perf_event_contextctx對象,ctx保存了事件上下文的各種信息
ctx=find_get_context(pmu,task,event);
//4.創建一個文件,指定perf類型文件的操作函數為perf_fops
event_file=anon_inode_getfile("[perf_event]",&perf_fops,event,
f_flags);
//5.把event安裝到ctx中
perf_install_in_context(ctx,event,event->cpu);
fd_install(event_fd,event_file);
returnevent_fd;
}
上面的代碼是 perf_event_open 的核心源碼。其中最關鍵的是 perf_event_alloc 的調用。在這個函數中,根據用戶傳入的 attr 來查找 pmu 對象。回憶本文的實例代碼,我們指定的是要監測CPU硬件中的指令數。
structperf_event_attrattr; attr.type=PERF_TYPE_HARDWARE;//表示監測硬件 attr.config=PERF_COUNT_HW_INSTRUCTIONS;//標志監測指令數
所以這里就會定位到我們3.1節提到的 CPU PMU 對象,并用這個 pmu 初始化 新event。接著再調用 anon_inode_getfile 創建一個真正的文件對象,并指定該文件的操作方法是 perf_fops。perf_fops 定義的操作函數如下:
//file:kernel/events/core.c staticconststructfile_operationsperf_fops={ ... .read=perf_read, .unlocked_ioctl=perf_ioctl, .mmap=perf_mmap, };
在創建完 perf 內核對象后。還會觸發在perf_pmu_enable,經過一系列的調用,最終會指定要監測的寄存器。
perf_pmu_enable ->pmu_enable ->x86_pmu_enable ->x86_assign_hw_event
//file:arch/x86/events/core.c
staticinlinevoidx86_assign_hw_event(structperf_event*event,
structcpu_hw_events*cpuc,inti)
{
structhw_perf_event*hwc=&event->hw;
...
if(hwc->idx==INTEL_PMC_IDX_FIXED_BTS){
hwc->config_base=0;
hwc->event_base=0;
}elseif(hwc->idx>=INTEL_PMC_IDX_FIXED){
hwc->config_base=MSR_ARCH_PERFMON_FIXED_CTR_CTRL;
hwc->event_base=MSR_ARCH_PERFMON_FIXED_CTR0+(hwc->idx-INTEL_PMC_IDX_FIXED);
hwc->event_base_rdpmc=(hwc->idx-INTEL_PMC_IDX_FIXED)|1<<30;
????}?else?{
????????hwc->config_base=x86_pmu_config_addr(hwc->idx);
hwc->event_base=x86_pmu_event_addr(hwc->idx);
hwc->event_base_rdpmc=x86_pmu_rdpmc_index(hwc->idx);
}
}
3.3 read 讀取計數
在實例代碼的第二步中,就是定時調用 read 系統調用來讀取指標計數。在 3.2 節中我們看到了新創建出來的 perf 文件對象在內核中的操作方法是 perf_read。
//file:kernel/events/core.c
staticconststructfile_operationsperf_fops={
...
.read=perf_read,
.unlocked_ioctl=perf_ioctl,
.mmap=perf_mmap,
};
perf_read 函數實際上支持可以同時讀取多個指標出來。但為了描述起來簡單,我只描述其讀取一個指標時的工作流程。其調用鏈如下:
perf_read __perf_read perf_read_one __perf_event_read_value perf_event_read __perf_event_read_cpu perf_event_count
其中在 perf_event_read 中是要讀取硬件寄存器中的值。
staticintperf_event_read(structperf_event*event,boolgroup)
{
enumperf_event_statestate=READ_ONCE(event->state);
intevent_cpu,ret=0;
...
again:
//如果event正在運行嘗試更新最新的數據
if(state==PERF_EVENT_STATE_ACTIVE){
...
data=(structperf_read_data){
.event=event,
.group=group,
.ret=0,
};
(void)smp_call_function_single(event_cpu,__perf_event_read,&data,1);
preempt_enable();
ret=data.ret;
}elseif(state==PERF_EVENT_STATE_INACTIVE){
...
}
returnret;
}
smp_call_function_single 這個函數是要在指定的 CPU 上運行某個函數。因為寄存器都是 CPU 專屬的,所以讀取寄存器應該要指定 CPU 核。要運行的函數就是其參數中指定的 __perf_event_read。在這個函數中,真正讀取了 x86 CPU 硬件寄存器。
__perf_event_read ->x86_pmu_read ->intel_pmu_read_event ->x86_perf_event_update
其中 __perf_event_read 調用到 x86 架構這塊是通過函數指針指過來的。
//file:kernel/events/core.c
staticvoid__perf_event_read(void*info)
{
...
pmu->read(event);
}
在3.1中我們介紹過CPU 的這個pmu,它的read函數指針是指向 x86_pmu_read的。
//file:arch/x86/events/core.c
staticstructpmupmu={
...
.read=x86_pmu_read,
}
這樣就會執行到 x86_pmu_read,最后就會調用到 x86_perf_event_update。在 x86_perf_event_update 中調用 rdpmcl 匯編指令來獲取寄存器中的值。
//file:arch/x86/events/core.c
u64x86_perf_event_update(structperf_event*event)
{
...
rdpmcl(hwc->event_base_rdpmc,new_raw_count);
returnnew_raw_count
}
最后返回到 perf_read_one 中會調用 copy_to_user 將值真正拷貝到用戶空間中,這樣我們的進程就讀取到了寄存器中的硬件執行計數了。
//file:kernel/events/core.c
staticintperf_read_one(structperf_event*event,
u64read_format,char__user*buf)
{
values[n++]=__perf_event_read_value(event,&enabled,&running);
...
copy_to_user(buf,values,n*sizeof(u64))
returnn*sizeof(u64);
}
總結
雖然內存很快,但它的速度在 CPU 面前也只是個弟弟。所以 CPU 并不直接從內存中獲取要運行的指令和數據,而是優先使用自己的緩存。只有緩存不命中的時候才會請求內存,性能也會變低。
那觀察 CPU 使用緩存效率高不高的指標主要有 CPI 和緩存命中率幾個指標。CPU 硬件在實現上,定義了專門 PMU 模塊,其中包含專門用戶計數的寄存器。當CPU執行到 PMC 寄存器所指定的事件時,硬件會自動對計數器加1,而不會對程序的正常執行造成任何干擾。有了底層的支持,上層的 Linux 內核就可以通過讀取這些 PMC 寄存器的值來獲取想要觀察的指標了。
我們可以使用 perf 來觀察,也可以直接使用內核提供的 perf_event_open 系統調用獲取 perf 文件對象,然后自己來讀取。
-
cpu
+關注
關注
68文章
11031瀏覽量
215939 -
硬件
+關注
關注
11文章
3459瀏覽量
67178 -
光刻機
+關注
關注
31文章
1163瀏覽量
48047
原文標題:人人都應該知道的CPU緩存運行效率
文章出處:【微信號:良許Linux,微信公眾號:良許Linux】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
DSP程序運行效率
CPU主頻降到極低到1Hz,系統還能運行嗎
使用智能外設提高CPU效率

配電網運行效率評價
Intel Graphics上提高CPU效率的DX12
CPU的概念是什么
cpu的程序是如何運行起來的
CPU運行模式S7-CPU工作的原理
CPU工作過程——MCU

程序是如何在 CPU 中運行的(二)
信創基礎硬件:CPU、GPU、存儲和整機
如何評估CPU硬件效率?CPU硬件運行效率介紹





 工商網監
工商網監
評論