") 介紹一種新的全景視覺(jué)里程計(jì)框架PVO
介紹一種新的全景視覺(jué)里程計(jì)框架PVO
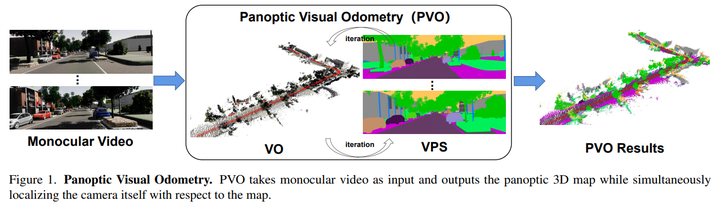
論文提出了PVO,這是一種新的全景視覺(jué)里程計(jì)框架,用于實(shí)現(xiàn)場(chǎng)景運(yùn)動(dòng)、幾何和全景分割信息的更全面建模。提出的PVO在統(tǒng)一的視圖中對(duì)視覺(jué)里程計(jì)(VO)和視頻全景分割(VPS)進(jìn)行建模,這使得這兩項(xiàng)任務(wù)互惠互利。具體來(lái)說(shuō),在圖像全景分割的指導(dǎo)下,在VO模塊中引入了全景更新模塊。
該全景增強(qiáng)VO模塊可以通過(guò)全景感知?jiǎng)討B(tài)mask來(lái)減輕動(dòng)態(tài)目標(biāo)在相機(jī)姿態(tài)估計(jì)中的影響。另一方面,VO增強(qiáng)型VPS模塊還利用從VO模塊獲得的相機(jī)姿態(tài)、深度和光流等幾何信息,將當(dāng)前幀的全景分割結(jié)果融合到相鄰幀,從而提高了分割精度,這兩個(gè)模塊通過(guò)反復(fù)迭代優(yōu)化相互促進(jìn)。大量實(shí)驗(yàn)表明,PVO在視覺(jué)里程計(jì)和視頻全景分割任務(wù)中都優(yōu)于最先進(jìn)的方法。
領(lǐng)域背景
了解場(chǎng)景的運(yùn)動(dòng)、幾何和全景分割在計(jì)算機(jī)視覺(jué)和機(jī)器人技術(shù)中發(fā)揮著至關(guān)重要的作用,其應(yīng)用范圍從自動(dòng)駕駛到增強(qiáng)現(xiàn)實(shí),本文朝著解決這個(gè)問(wèn)題邁出了一步,以實(shí)現(xiàn)單目視頻場(chǎng)景的更全面建模!已經(jīng)提出了兩項(xiàng)任務(wù)來(lái)解決這個(gè)問(wèn)題,即視覺(jué)里程計(jì)(VO)和視頻全景分割(VPS)。特別地,VO[9,11,38]將單目視頻作為輸入,并在靜態(tài)場(chǎng)景假設(shè)下估計(jì)相機(jī)姿態(tài)。為了處理場(chǎng)景中的動(dòng)態(tài)對(duì)象,一些動(dòng)態(tài)SLAM系統(tǒng)使用實(shí)例分割網(wǎng)絡(luò)進(jìn)行分割,并明確過(guò)濾出某些類(lèi)別的目標(biāo),這些目標(biāo)可能是動(dòng)態(tài)的,例如行人或車(chē)輛。
然而,這種方法忽略了這樣一個(gè)事實(shí),即潛在的動(dòng)態(tài)目標(biāo)實(shí)際上可能在場(chǎng)景中是靜止的,例如停放的車(chē)輛。相比之下,VPS專注于在給定一些初始全景分割結(jié)果的情況下,跨視頻幀跟蹤場(chǎng)景中的單個(gè)實(shí)例。當(dāng)前的VPS方法沒(méi)有明確區(qū)分目標(biāo)實(shí)例是否在移動(dòng),盡管現(xiàn)有的方法廣泛地獨(dú)立地解決了這兩個(gè)任務(wù),但值得注意的是,場(chǎng)景中的動(dòng)態(tài)目標(biāo)會(huì)使這兩項(xiàng)任務(wù)都具有挑戰(zhàn)性。認(rèn)識(shí)到兩個(gè)任務(wù)之間的這種相關(guān)性,一些方法試圖同時(shí)處理這兩個(gè)任務(wù),并以多任務(wù)的方式訓(xùn)練運(yùn)動(dòng)語(yǔ)義網(wǎng)絡(luò),如圖2所示。然而,這些方法中使用的損失函數(shù)可能相互矛盾,從而導(dǎo)致性能下降。
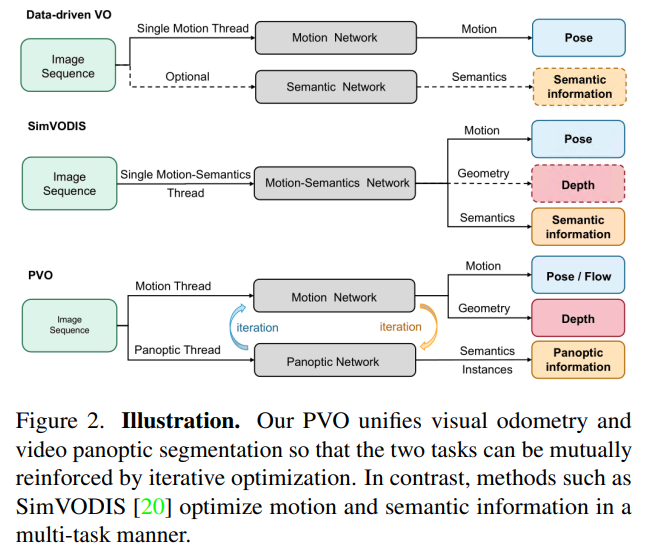
本文提出了一種新的全景視覺(jué)里程計(jì)(PVO)框架,該框架使用統(tǒng)一的視圖將這兩項(xiàng)任務(wù)緊密耦合,以對(duì)場(chǎng)景進(jìn)行全面建模。VPS可以利用全景分割信息調(diào)整VO的權(quán)重(每個(gè)實(shí)例的像素的權(quán)重應(yīng)該相互關(guān)聯(lián)),VO可以將視頻全景分割的跟蹤和融合從2D轉(zhuǎn)換為3D。受開(kāi)創(chuàng)性的期望最大化算法的啟發(fā),遞歸迭代優(yōu)化策略可以使這兩項(xiàng)任務(wù)互惠互利。
PVO由三個(gè)模塊組成,一個(gè)圖像全景分割模塊、一個(gè)全景增強(qiáng)型VO模塊和一個(gè)VO增強(qiáng)型VPS模塊。全景分割模塊獲取單個(gè)圖像并輸出圖像全景分割結(jié)果,然后被饋送到全景增強(qiáng)VO模塊中作為初始化。注意,盡管本文選擇PanopticFPN,但任何分割模型都可以用于全景分割模塊。在全景增強(qiáng)VO模塊,提出了一個(gè)全景更新模塊來(lái)過(guò)濾動(dòng)態(tài)目標(biāo)的干擾,從而提高了動(dòng)態(tài)場(chǎng)景中姿態(tài)估計(jì)的準(zhǔn)確性。在VO增強(qiáng)的VPS模塊中,引入了一種在線融合機(jī)制,根據(jù)估計(jì)的姿態(tài)、深度和光流,將當(dāng)前幀的多分辨率特征與相鄰幀對(duì)齊,這種在線融合機(jī)制可以有效地解決多目標(biāo)遮擋的問(wèn)題。實(shí)驗(yàn)表明,遞歸迭代優(yōu)化策略提高了VO和VPS的性能。本文的主要貢獻(xiàn)概括為四個(gè)方面:
1.本文提出了一種新的全景視覺(jué)里程計(jì)(PVO)框架,該框架可以將VO和VPS任務(wù)統(tǒng)一起來(lái),對(duì)場(chǎng)景進(jìn)行全面建模;
2.引入全景更新模塊,并將其納入全景增強(qiáng)VO模塊,以改進(jìn)姿態(tài)估計(jì);
3.在VOEnhanced VPS模塊中提出了一種在線融合機(jī)制,有助于改進(jìn)視頻全景分割;
4.大量實(shí)驗(yàn)表明,提出的具有遞歸迭代優(yōu)化的PVO在視覺(jué)里程計(jì)和視頻全景分割任務(wù)中都優(yōu)于最先進(jìn)的方法;
1)視頻全景分割
視頻全景分割旨在生成一致的全景分割,并跟蹤視頻幀中所有像素的實(shí)例。作為一項(xiàng)先驅(qū)工作,VPSNet定義了這項(xiàng)新任務(wù),并提出了一種基于實(shí)例級(jí)跟蹤的方法。SiamTrack通過(guò)提出pixel-tube匹配損失和對(duì)比度損失來(lái)擴(kuò)展VPSNet,以提高實(shí)例嵌入的判別能力。VIPDeplab通過(guò)引入額外的深度信息,提供了一個(gè)深度感知VPS網(wǎng)絡(luò)。而STEP提出對(duì)視頻全景分割的每個(gè)像素進(jìn)行分割和跟蹤,HybridTracker提出從兩個(gè)角度跟蹤實(shí)例:特征空間和空間位置。與現(xiàn)有方法不同,本文引入了一種VO增強(qiáng)的VPS模塊,該模塊利用VO估計(jì)的相機(jī)姿態(tài)、深度和光流來(lái)跟蹤和融合從當(dāng)前幀到相鄰幀的信息,并可以處理遮擋。
2)SLAM和視覺(jué)里程計(jì)
SLAM同時(shí)進(jìn)行定位和地圖構(gòu)建,視覺(jué)里程計(jì)作為SLAM的前端,專注于姿態(tài)估計(jì)。現(xiàn)代SLAM系統(tǒng)大致分為兩類(lèi),基于幾何的方法和基于學(xué)習(xí)的方法。由于基于監(jiān)督學(xué)習(xí)的方法具有良好的性能,基于無(wú)監(jiān)督學(xué)習(xí)的VO方法受到了廣泛的關(guān)注,但它們的性能不如有監(jiān)督的方法。一些無(wú)監(jiān)督方法利用多任務(wù)學(xué)習(xí)和深度和光流等輔助任務(wù)來(lái)提高性能。
最近,TartanVO提出建立一個(gè)可推廣基于學(xué)習(xí)的VO,并在具有挑戰(zhàn)性的SLAM數(shù)據(jù)集TartanAir上測(cè)試該系統(tǒng)。DROID-SLAM提出使用bundle adjustment層迭代更新相機(jī)姿態(tài)和像素深度,并展示了卓越的性能。DeFlowSLAM進(jìn)一步提出了dual-flow表示和自監(jiān)督方法,以提高SLAM系統(tǒng)在動(dòng)態(tài)場(chǎng)景中的性能。為了應(yīng)對(duì)動(dòng)態(tài)場(chǎng)景的挑戰(zhàn),動(dòng)態(tài)SLAM系統(tǒng)通常利用語(yǔ)義信息作為約束但它們主要作用于stereo、RGBD或LiDAR序列。相反,本文引入了全景更新模塊,并在DROID-SLAM上構(gòu)建了全景增強(qiáng)型VO,可以用于單目視頻。這樣的組合可以更好地理解場(chǎng)景幾何和語(yǔ)義,從而對(duì)場(chǎng)景中的動(dòng)態(tài)對(duì)象更加魯棒。與其它多任務(wù)端到端模型不同,本文的PVO具有循環(huán)迭代優(yōu)化策略,可以防止任務(wù)相互干擾。
本文提出的方法
給定一個(gè)單目視頻,PVO的目標(biāo)是同時(shí)定位和全景3D映射。圖3描述了PVO模型的框架,它由三個(gè)主要模塊組成:圖像全景分割模塊、全景增強(qiáng)VO模塊和VO增強(qiáng)VPS模塊。VO模塊旨在估計(jì)攝像機(jī)的姿態(tài)、深度和光流,而VPS模塊輸出相應(yīng)的視頻全景分割,最后兩個(gè)模塊以反復(fù)互動(dòng)的方式相互促進(jìn)!
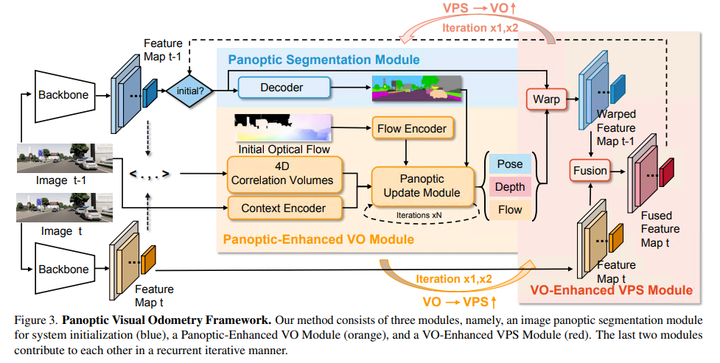
1)圖像全景分割
圖像全景分割以單個(gè)圖像為輸入,輸出圖像的全景分割結(jié)果,將語(yǔ)義分割和實(shí)例分割相結(jié)合,對(duì)圖像的實(shí)例進(jìn)行綜合建模。輸出結(jié)果用于初始化視頻全景分割,然后輸入全景增強(qiáng)VO模塊。在本文的實(shí)驗(yàn)中,如果沒(méi)有特別指出,使用廣泛使用的圖像全景分割網(wǎng)絡(luò)PanopticFPN。PanopticFPN建立在具有權(quán)重θ_e的ResNetf_{θ_e}的主干上,并提取圖像的多尺度特征I_t:

它使用具有權(quán)重θ_d的解碼器g_{θ_d}輸出全景分割結(jié)果,該解碼器由語(yǔ)義分割和實(shí)例分割組成,每個(gè)像素p的全景分割結(jié)果為:
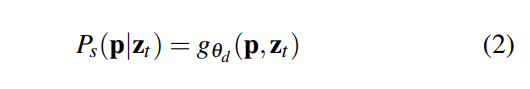
被饋送到解碼器中的多尺度特征隨著時(shí)間的推移而更新。一開(kāi)始,編碼器生成的多尺度特征被直接輸入解碼器(圖3藍(lán)色部分)。在隨后的時(shí)間步長(zhǎng)中,這些多尺度特征在被饋送到解碼器之前用在線特征融合模塊進(jìn)行更新。
2)全景增強(qiáng) VO 模塊
在視覺(jué)里程計(jì)中,動(dòng)態(tài)場(chǎng)景無(wú)處不在,過(guò)濾掉動(dòng)態(tài)目標(biāo)的干擾至關(guān)重要。DROID-SLAM的前端以單目視頻{{I_t}}^N_{t=0}為輸入,并優(yōu)化相機(jī)姿態(tài){G_t}^N_{t=0}∈SE(3)和反深度d_t∈R^{H×W}+,通過(guò)迭代優(yōu)化光流delta r{ij}∈R^{HW2}。它不考慮大多數(shù)背景是靜態(tài)的,前景目標(biāo)可能是動(dòng)態(tài)的,并且每個(gè)目標(biāo)的像素權(quán)重應(yīng)該是相關(guān)的。全景增強(qiáng)VO模塊(見(jiàn)圖4)是通過(guò)結(jié)合全景分割的信息,幫助獲得更好的置信度估計(jì)(見(jiàn)圖7),因此,全景增強(qiáng)VO可以獲得更精確的相機(jī)姿勢(shì)。接下來(lái),將簡(jiǎn)要回顧DROID-SLAM的類(lèi)似部分(特征提取和相關(guān)性),并重點(diǎn)介紹全景更新模塊的復(fù)雜設(shè)計(jì)。
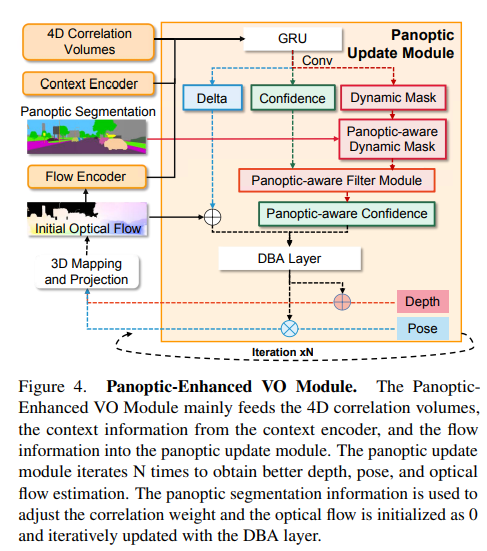

特征提取:與DROID-SLAM類(lèi)似,全景增強(qiáng)VO模塊借用了RAFT的關(guān)鍵組件來(lái)提取特征。本文使用兩個(gè)獨(dú)立的網(wǎng)絡(luò)(一個(gè)特征編碼器和一個(gè)上下文編碼器) 提取每個(gè)圖像的多尺度特征,其中利用特征編碼器的特征構(gòu)建成對(duì)圖像的4D相關(guān)volumes,并將上下文編碼器的特征注入全景更新模塊。特征編碼器的結(jié)構(gòu)類(lèi)似于全景分割網(wǎng)絡(luò)的主干,并且它們可以使用共享編碼器。
相關(guān)金字塔和查找表:與DROIDSLAM類(lèi)似,本文采用幀圖(V,E)來(lái)指示幀之間的共同可見(jiàn)性。例如,邊(i,j)∈E表示保持重疊區(qū)域的兩個(gè)圖像I_i和I_j,并且可以通過(guò)這兩個(gè)圖像的特征向量之間的點(diǎn)積來(lái)構(gòu)建4D相關(guān)volumes:
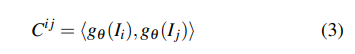
遵循平均池化層以獲得金字塔相關(guān)性,本文使用DROID-SLAM中定義的相同查找運(yùn)算符來(lái)使用雙線性插值對(duì)金字塔相關(guān)volumes值進(jìn)行索引,這些相關(guān)特征被串聯(lián),從而產(chǎn)生最終的特征向量。Panoptic增強(qiáng)型VO模塊繼承了DROID-SLAM的前端VO模塊,利用全景分割信息來(lái)調(diào)整VO的權(quán)重。將通過(guò)將初始光流饋送到流編碼器而獲得的flow信息和從兩幀建立的4D相關(guān)volumes以及上下文編碼器獲取的特征作為中間變量饋送到GRU,然后三個(gè)卷積層輸出動(dòng)態(tài)掩碼M_{d_{ij}},相關(guān)置信度map w_{ij}和稠密光流delta r_{ij}。給定初始化的全景分割,可以將動(dòng)態(tài)掩碼調(diào)整為全景感知?jiǎng)討B(tài)掩碼,為了便于理解,保持符號(hào)不變。置信度和全景感知?jiǎng)討B(tài)掩碼通過(guò)全景感知濾波器模塊以獲得全景感知置信度:
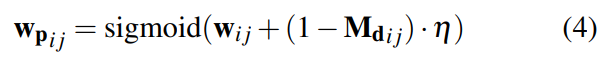
深度和動(dòng)態(tài)的殘差掩碼被添加到當(dāng)前深度和動(dòng)態(tài)掩碼,分別為:
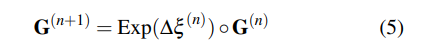
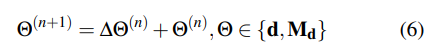
Correspondence:首先在每次迭代中使用當(dāng)前的姿態(tài)和深度估計(jì)來(lái)搜索對(duì)應(yīng)關(guān)系。參考DROID-SLAM,對(duì)于幀i中的每個(gè)像素坐標(biāo)pi,幀圖中每個(gè)邊(i,j)∈E的稠密對(duì)應(yīng)域pij可以計(jì)算如下:
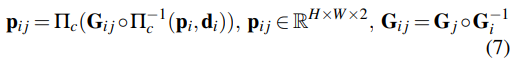
DBA層:使用DROID-SLAM中定義的密集束調(diào)整層(DBA)來(lái)map stream revisions,以更新當(dāng)前估計(jì)的逐像素深度和姿態(tài),成本函數(shù)可以定義如下:
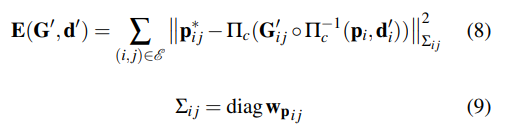
3)VO增強(qiáng)型VPS模塊
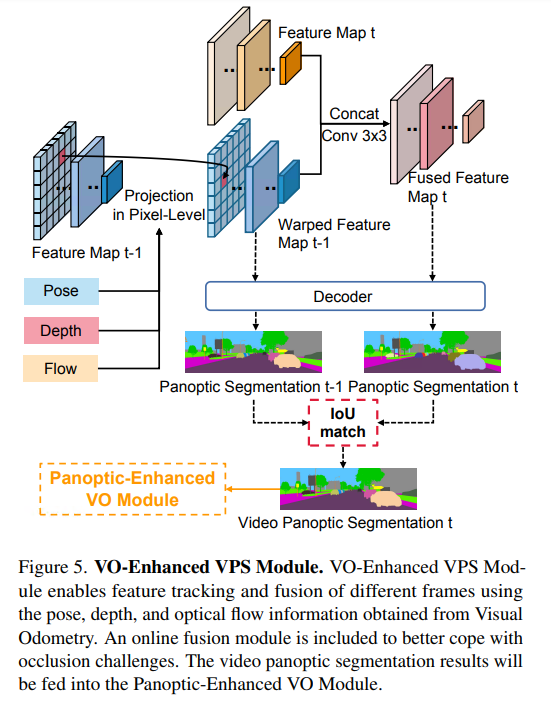
視頻全景分割旨在獲得每幀的全景分割結(jié)果,并保持幀間分割的一致性。為了提高分割精度和跟蹤精度,F(xiàn)useTrack等一些方法試圖利用光流信息對(duì)特征進(jìn)行融合,并根據(jù)特征的相似性進(jìn)行跟蹤。這些方法僅來(lái)自可能遇到遮擋或劇烈運(yùn)動(dòng)的2D視角。我們生活在一個(gè)3D世界中,可以使用額外的深度信息來(lái)更好地建模場(chǎng)景。本文的VO增強(qiáng)型VPS模塊正是基于這一理解,能夠更好地解決上述問(wèn)題。
圖5顯示了VO增強(qiáng)型VPS模塊,該模塊通過(guò)使用從視覺(jué)里程計(jì)獲得的深度、姿態(tài)和光流信息,將前一幀t?1的特征wrap到當(dāng)前幀t,從而獲得wrap的特征。在線融合模塊將融合當(dāng)前幀t的特征和wrap的特征,以獲得融合的特征。為了保持視頻分割的一致性,首先將wrap的特征t?1(包含幾何運(yùn)動(dòng)信息)和融合的特征圖t輸入解碼器,分別獲得全景分割t?1和t,然后使用簡(jiǎn)單的IoU匹配模塊來(lái)獲得一致的全景分割,該結(jié)果將被輸入Panoptic增強(qiáng)型VO模塊。
4)遞歸迭代優(yōu)化
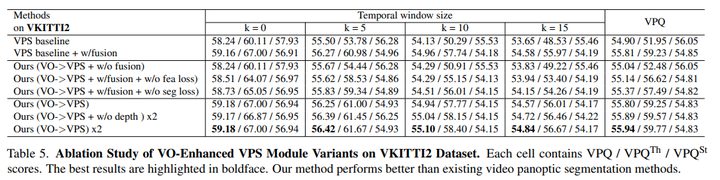
受EM算法的啟發(fā),可以以遞歸迭代的方式優(yōu)化所提出的全景增強(qiáng)VO模塊和VO增強(qiáng)VPS模塊,直到收斂。在實(shí)驗(yàn)上,循環(huán)通常只需要兩次迭代就可以收斂,表5和表6表明,反復(fù)迭代優(yōu)化可以提高VPS和VO模塊的性能。
5)實(shí)施細(xì)則
PVO由PyTorch實(shí)現(xiàn),由三個(gè)主要模塊組成:圖像全景分割、全景增強(qiáng)VO模塊和VO增強(qiáng)VPS模塊。本文使用三個(gè)階段來(lái)訓(xùn)練網(wǎng)絡(luò),在KITTI數(shù)據(jù)集上訓(xùn)練圖像全景分割作為初始化。在PanopticFCN之后,訓(xùn)練過(guò)程中采用了多尺度縮放策略。在兩個(gè)GeForce RTX 3090 GPU上以1e-4的初始速率優(yōu)化網(wǎng)絡(luò),其中每個(gè)小批量有八個(gè)圖像,SGD優(yōu)化器的使用具有1e-4的重量衰減和0.9的動(dòng)量。
全景增強(qiáng)VO模塊的訓(xùn)練遵循DROIDSLAM,只是它額外提供了地面實(shí)況全景分割結(jié)果。在訓(xùn)練VO增強(qiáng)視頻全景分割模塊時(shí),使用GT深度、光流和姿態(tài)信息作為幾何先驗(yàn)來(lái)對(duì)齊特征,并固定訓(xùn)練的單圖像全景分割的主干,然后僅訓(xùn)練融合模塊。該網(wǎng)絡(luò)在一個(gè)GeForce RTX 3090 GPU上以1e-5的初始學(xué)習(xí)率進(jìn)行了優(yōu)化,其中每個(gè)批次有八個(gè)圖像。當(dāng)融合網(wǎng)絡(luò)基本收斂時(shí),添加了一個(gè)分割一致性損失函數(shù)來(lái)進(jìn)一步完善VPS模塊!
實(shí)驗(yàn)結(jié)果
1)視覺(jué)里程計(jì)
本文在三個(gè)具有動(dòng)態(tài)場(chǎng)景的數(shù)據(jù)集上進(jìn)行實(shí)驗(yàn):Virtual KITTI、KITTI和TUM RGBD動(dòng)態(tài)序列,使用絕對(duì)軌跡誤差(ATE)進(jìn)行評(píng)估。對(duì)于視頻全景分割,在cityscape和VIPER數(shù)據(jù)集上使用視頻全景質(zhì)量(VPQ)度量。本文進(jìn)一步對(duì)Virtual KITTI進(jìn)行消融研究,以分析本文的框架設(shè)計(jì)。最后,展示了PVO在視頻編輯方面的適用性,如補(bǔ)充材料中的第B節(jié)所示。
VKITTI2
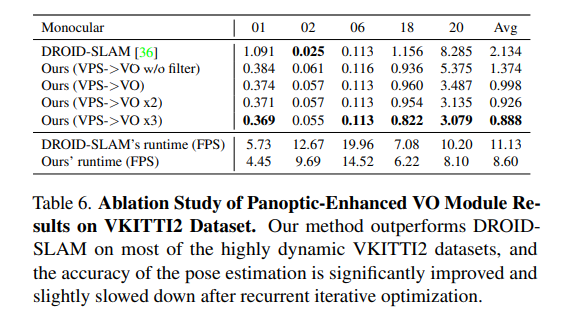
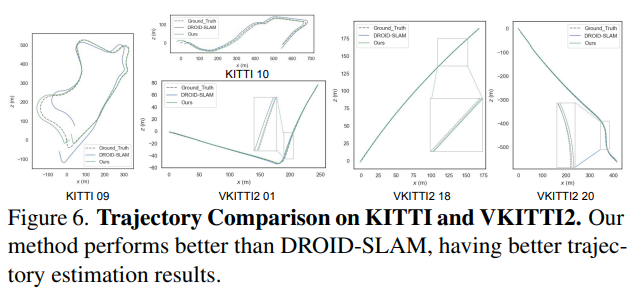
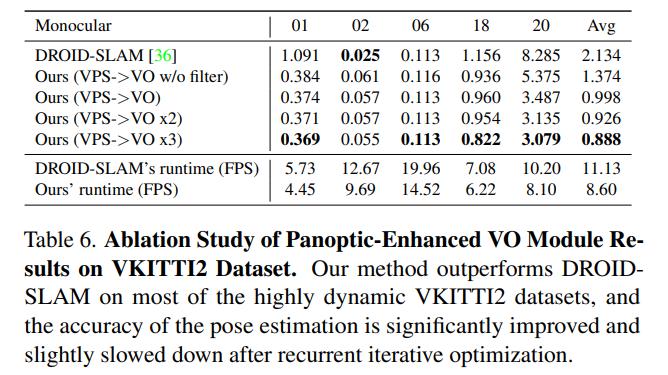
虛擬KITTI數(shù)據(jù)集[3]由從KITTI跟蹤基準(zhǔn)克隆的5個(gè)序列組成,為每個(gè)序列提供RGB、深度、類(lèi)分割、實(shí)例分割、相機(jī)姿態(tài)、flow和場(chǎng)景flow數(shù)據(jù)。如表6和圖6所示,在大多數(shù)序列中,本文的PVO以很大的優(yōu)勢(shì)優(yōu)于DROID SLAM,并在序列02中實(shí)現(xiàn)了有競(jìng)爭(zhēng)力的性能。
KITTI
KITTI是一個(gè)捕捉真實(shí)世界交通場(chǎng)景的數(shù)據(jù)集,從農(nóng)村地區(qū)的高速公路到擁有大量靜態(tài)和動(dòng)態(tài)對(duì)象的城市街道。本文將在VKITTI2[3]數(shù)據(jù)集上訓(xùn)練的PVO模型應(yīng)用于KITTI序列。如圖6所示,PVO的姿態(tài)估計(jì)誤差僅為DROID-SLAM的一半,這證明了PVO具有良好的泛化能力。表1顯示了KITTI和VKITTI數(shù)據(jù)集上的完整SLAM比較結(jié)果,其中PVO在大多數(shù)情況下都大大優(yōu)于DROID-SLAM和DynaSLAM,DynaSLAM在VKITTI2 02、06和18序列中屬于災(zāi)難性系統(tǒng)故障。

TUM-RGBD
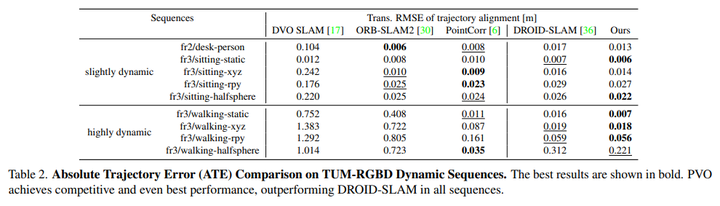
TUM RGBD是一個(gè)用手持相機(jī)捕捉室內(nèi)場(chǎng)景的數(shù)據(jù)集,本文選擇TUM RGBD數(shù)據(jù)集的動(dòng)態(tài)序列來(lái)顯示本文的方法的有效性。將PVO與DROIDSLAM以及三種最先進(jìn)的動(dòng)態(tài)RGB-D SLAM系統(tǒng)進(jìn)行了比較,即DVO-SLAM、ORB-SLAM2和PointCorr。請(qǐng)注意,PVO和DROID-SLAM僅使用單目RGB視頻。表2表明PVO在所有場(chǎng)景中都優(yōu)于DROID-SLAM,與傳統(tǒng)的RGB-D SLAM系統(tǒng)相比,本文的方法在大多數(shù)場(chǎng)景中也表現(xiàn)得更好。
2)視頻全景分割
將PVO與三種基于實(shí)例的視頻全景分割方法進(jìn)行了比較,即VPSNetTrack、VPSNetFuseTrack和SiamTrack。在圖像全景分割模型UPSNet的基礎(chǔ)上,VPSNetTrack還添加了MaskTrack head,以形成視頻全景分割模型。基于VPSNet Track的VPSNet FuseTrack額外注入了時(shí)間特征聚合和融合,而SiamTrack利用pixel-tubel 匹配損失和對(duì)比度損耗對(duì)VPSNet Track進(jìn)行微調(diào),性能略有提高,比較VPSNet FuseTrack主要是因?yàn)镾iamTrack的代碼不可用。
Cityscape:本文在VPS中采用了Cityscape的公共訓(xùn)練/val/test分割,其中每個(gè)視頻包含30個(gè)連續(xù)幀,每五幀有相應(yīng)的GT注釋。表3表明,使用PanopticFCN的方法在val數(shù)據(jù)集上優(yōu)于最先進(jìn)的方法,實(shí)現(xiàn)了比VPSNet Track高+1.6%VPQ。與VPSNetFuseTrack相比,本文的方法略有改進(jìn),可以保持一致的視頻分割,如補(bǔ)充材料中的圖A4所示。原因是由于內(nèi)存有限,論文的VO模塊只能獲得1/8分辨率的光流和深度。
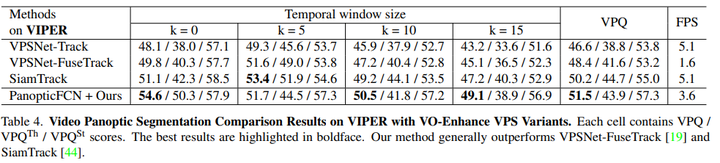
VIPER:VIPER維護(hù)了大量高質(zhì)量的全景視頻注釋,這是另一個(gè)視頻全景分割基準(zhǔn)。遵循VPS[19],并采用其公共train/val拆分。使用從日常場(chǎng)景中選擇的10個(gè)視頻,每個(gè)視頻的前60幀用于評(píng)估。表4表明,與VPSNet FuseTrack相比,PanopticFCN方法在VIPER數(shù)據(jù)集上獲得了更高的分?jǐn)?shù)(+3.1VPQ)。
3)消融實(shí)驗(yàn)
VPS增強(qiáng)型VO模塊:在全景增強(qiáng)型VO模塊中,使用DROID-SLAM作為基線,(VPS->VO)意味著增加了全景信息先驗(yàn)以增強(qiáng)VO基線,(VPS->VO x2)意味著可以迭代優(yōu)化VO模塊兩次。(VPS->VO x3)意味著對(duì)VO模塊進(jìn)行3次反復(fù)迭代優(yōu)化,表6和圖7顯示,在大多數(shù)高度動(dòng)態(tài)的VKITTI2數(shù)據(jù)集上,全景信息可以幫助提高DROID-SLAM的準(zhǔn)確性,遞歸迭代優(yōu)化可以進(jìn)一步改善結(jié)果。
VO增強(qiáng)型VPS模塊:為了評(píng)估VO是否有助于VPS,首先使用PanopticFPN來(lái)獲得每個(gè)幀的全景分割結(jié)果,然后使用來(lái)自RAFT的光流信息進(jìn)行幀間跟蹤,這被設(shè)置為VPS基線。(VPS基線+w/fusion)意味著額外地將特征與流量估計(jì)相融合。(VO->VPS+w/o融合)意味著在基線之上使用額外的深度、姿勢(shì)和其他信息,(VO->VPS)意味著我們額外融合了該功能。
VO增強(qiáng)型VPS模塊中的在線融合:為了驗(yàn)證所提出的特征對(duì)齊損失(fea損失)和分割一致性損失(seg損失)的有效性,方法如下:(VO->VPS+w/fusion+w/o fealoss)意味著在沒(méi)有特征對(duì)齊損失的情況下訓(xùn)練在線融合模塊,(VO->VPS+w/fusion+w/o-seg loss)意味著在沒(méi)有Segmentation Consistent loss的情況下訓(xùn)練在線融合模塊,表5展示了這兩種損失函數(shù)的有效性!
一些結(jié)論
論文提出了一種新的全景視覺(jué)里程計(jì)方法,該方法在統(tǒng)一的視圖中對(duì)VO和VPS進(jìn)行建模,使這兩項(xiàng)任務(wù)能夠相互促進(jìn)。全景更新模塊可以幫助改進(jìn)姿態(tài)估計(jì),而在線融合模塊有助于改進(jìn)全景分割。大量實(shí)驗(yàn)表明,本文的PVO在這兩項(xiàng)任務(wù)中都優(yōu)于最先進(jìn)的方法。局限性主要是PVO建立在DROID-SLAM和全景分割的基礎(chǔ)上,這使得網(wǎng)絡(luò)很重,需要大量?jī)?nèi)存。盡管PVO可以在動(dòng)態(tài)場(chǎng)景中穩(wěn)健地執(zhí)行,但它忽略了當(dāng)攝像機(jī)返回到之前的位置時(shí)環(huán)路閉合的問(wèn)題,探索一種低成本、高效的閉環(huán)SLAM系統(tǒng)是未來(lái)的工作。
審核編輯:劉清
-
攝像機(jī)
+關(guān)注
關(guān)注
3文章
1684瀏覽量
61021 -
Droid
+關(guān)注
關(guān)注
0文章
2瀏覽量
6463 -
SLAM
+關(guān)注
關(guān)注
24文章
434瀏覽量
32302 -
vps
+關(guān)注
關(guān)注
1文章
114瀏覽量
12184
原文標(biāo)題:CVPR 2023 | PVO:全景視覺(jué)里程計(jì)(VO和全景分割雙SOTA)!
文章出處:【微信號(hào):3D視覺(jué)工坊,微信公眾號(hào):3D視覺(jué)工坊】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
【「# ROS 2智能機(jī)器人開(kāi)發(fā)實(shí)踐」閱讀體驗(yàn)】視覺(jué)實(shí)現(xiàn)的基礎(chǔ)算法的應(yīng)用
一種新型激光雷達(dá)慣性視覺(jué)里程計(jì)系統(tǒng)介紹
一種實(shí)時(shí)多線程VSLAM框架vS-Graphs介紹
無(wú)線電愛(ài)好者實(shí)用電子制作精選
成像式亮度色度計(jì)產(chǎn)品原理及應(yīng)用介紹

AI開(kāi)發(fā)框架集成介紹
用于任意排列多相機(jī)的通用視覺(jué)里程計(jì)系統(tǒng)
一種面向飛行試驗(yàn)的數(shù)據(jù)融合框架

滲壓計(jì)和水位計(jì)之間有什么區(qū)別?

基于視覺(jué)語(yǔ)言模型的導(dǎo)航框架VLMnav
投入式水位計(jì)是什么?投入式水位計(jì)怎么安裝
基于旋轉(zhuǎn)平移解耦框架的視覺(jué)慣性初始化方法

一種完全分布式的點(diǎn)線協(xié)同視覺(jué)慣性導(dǎo)航系統(tǒng)
全景聲解碼器






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論