 MiniGPT-4,開源了!
MiniGPT-4,開源了!
大家好,我是程序羊。
上個月GPT-4發布時,我曾寫過一篇文章分享過有關GPT-4的幾個關鍵信息。
當時的分享就提到了GPT-4的一個重要特性,那就是多模態能力。
比如發布會上演示的,輸入一幅圖(手套掉下去會怎么樣?)。

GPT-4可以理解并輸出給到:它會掉到木板上,并且球會被彈飛。
再比如給GPT-4一張長相奇怪的充電器圖片,問為什么這很可笑?

GPT-4回答道,VGA 線充 iPhone。
用戶甚至還可以直接畫一個網站草圖拍照丟給GPT-4,它就可以立馬幫助生成代碼。

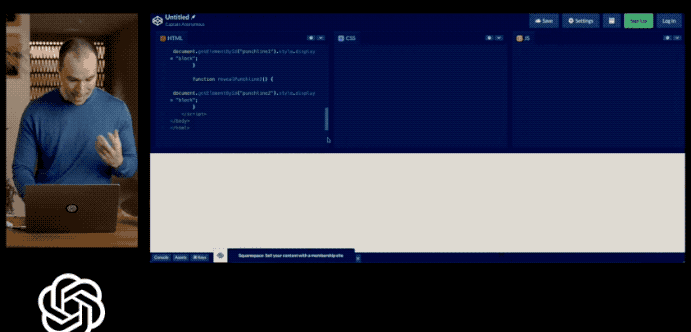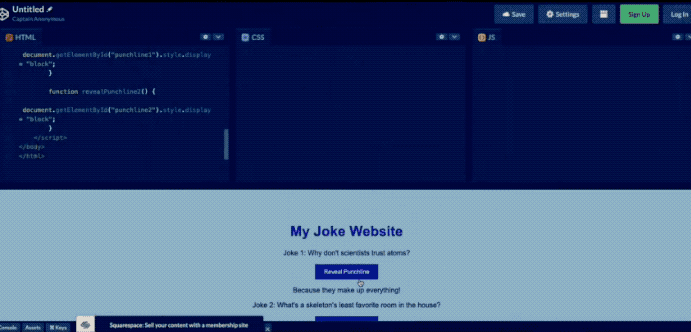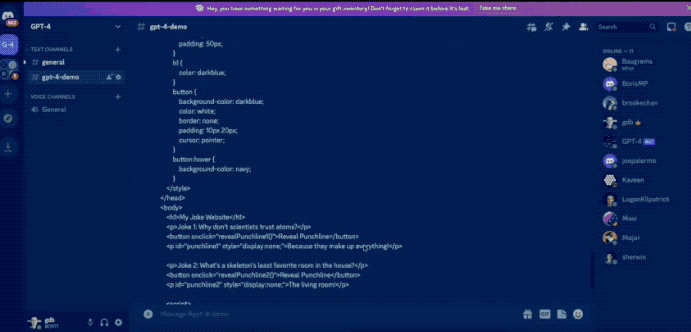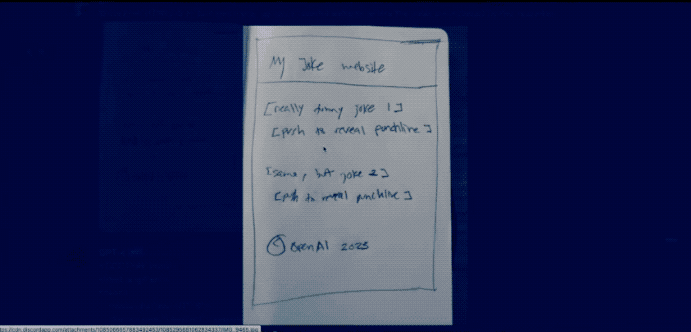
但是時間過去了這么久,GPT-4像這樣的識圖功能也遲遲沒有開放。
就在大家都在等待這個功能開放的時候,一個名為MiniGPT-4的開源項目悄悄做了這件事情。
沒錯,就是為了增強視覺語言理解。
MiniGPT-4背后團隊來自KAUST(沙特阿卜杜拉國王科技大學),項目是幾位博士開發的。

項目除了是開源的之外,而且還提供了網頁版的demo,用戶可以直接進去體驗。
在線體驗:https://minigpt-4.github.io
GitHub倉庫:https://github.com/Vision-CAIR/MiniGPT-4
論文:https://github.com/Vision-CAIR/MiniGPT-4/blob/main/MiniGPT_4.pdf
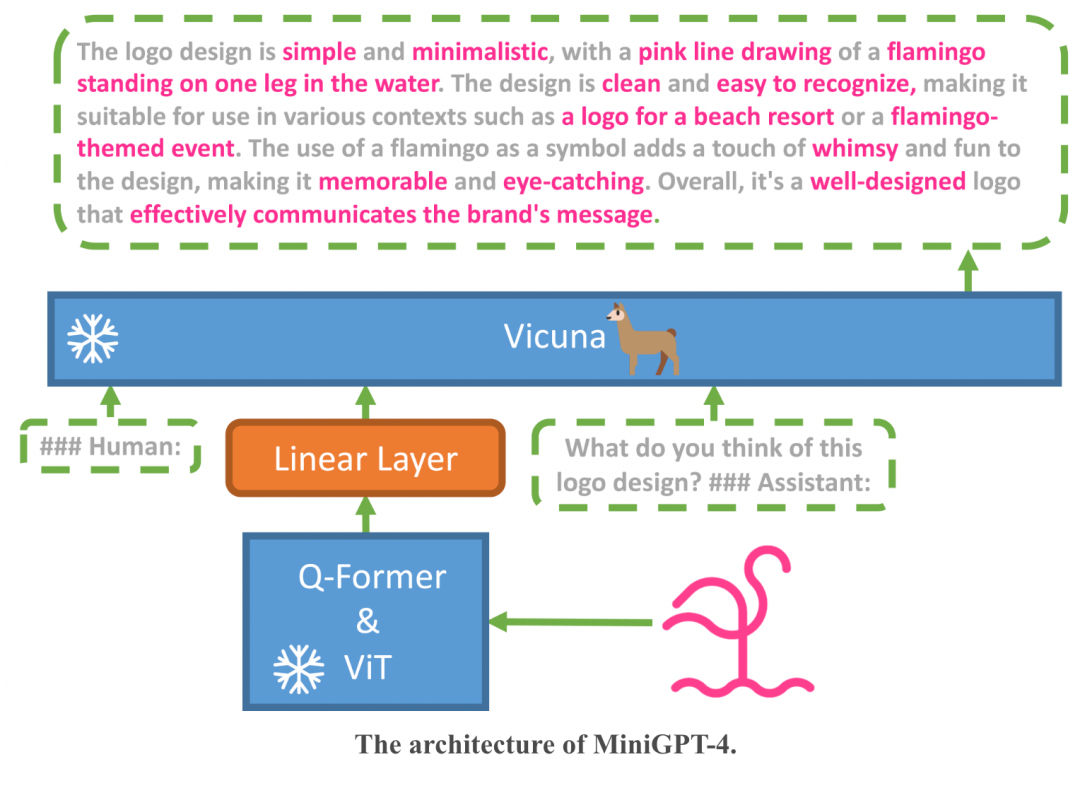
MiniGPT-4也是基于一些開源大模型來訓練得到的。 團隊把圖像編碼器與開源語言模型Vicuna(小羊駝)整合起來,并且凍結了兩者的大部分參數,只需要訓練很少一部分。
訓練分為兩個階段。
傳統預訓練階段,在4張A100上使用500萬圖文對,10個小時內就可以完成,此時訓練出來的Vicuna已能夠理解圖像,但生成能力有限。
然后在第二個調優階段再用一些小的高質量數據集進行訓練。這時候的計算效率很高,單卡A100只需要7分鐘。
并且團隊正在準備一個更輕量級的版本,部署起來只需要23GB顯存,這也就意味著未來可以在一些消費級的顯卡中或許就可以進行本地訓練了。
這里也給大家看幾個例子。
比如丟一張食物的照片進去來獲得菜譜。

或者給出一張商品的照片來讓其幫忙寫一篇文案。

當然也可以像之前GPT-4發布會上演示的那樣,畫出一個網頁,讓其幫忙生成代碼。

可以說,GPT-4發布會上演示過的功能,MiniGPT-4基本也都有。
這一點可以說非常amazing了!
可能由于目前使用的人比較多,在MiniGPT-4網頁demo上試用時會遇到排隊的情況,需要在隊列中等待。
但是用戶也可以自行本地部署服務,過程并不復雜。
首先是下載項目&準備環境:
gitclonehttps://github.com/Vision-CAIR/MiniGPT-4.git cdMiniGPT-4 condaenvcreate-fenvironment.yml condaactivateminigpt4
然后下載預訓練模型:
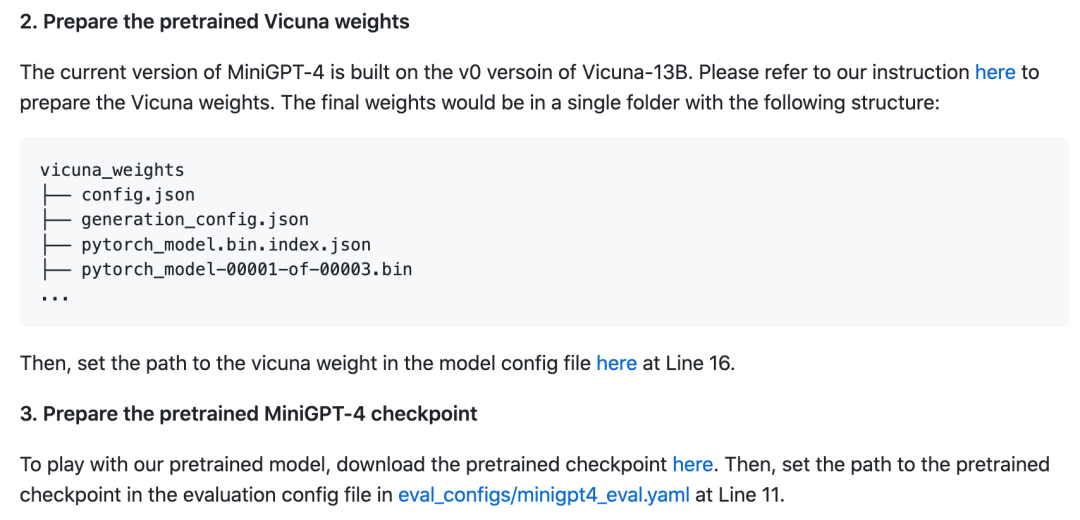
最后在本地啟動Demo:
pythondemo.py--cfg-patheval_configs/minigpt4_eval.yaml
通過這個項目我們也再一次看出大模型在視覺領域的可行性,未來在圖像、音頻、視頻等方面的應用前景應該也是非常不錯的,我們可以期待一下。
審核編輯 :李倩
-
開源
+關注
關注
3文章
3582瀏覽量
43440 -
模型
+關注
關注
1文章
3483瀏覽量
49955 -
GPT
+關注
關注
0文章
368瀏覽量
15919
原文標題:MiniGPT-4,開源了!
文章出處:【微信號:CodeSheep,微信公眾號:CodeSheep】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
【開源】4G遠程GPS定位器
【開源】智慧氣象盒子(4G_GPS)
4ChannelLedStrip控制與Nodemcu開源分享






 工商網監
工商網監
評論