 SceneXplain:讓ChatGPT開啟視覺視角
SceneXplain:讓ChatGPT開啟視覺視角
精準的圖像描述不僅可以讓人們更容易理解圖像背后的故事和信息,還可以讓圖像更易于被檢索和識別。然而,對于那些復雜的圖像來說,寫出既準確又詳細的描述實在是件非常困難的事情。
圖像描述算法的演變
所謂 Image Caption(圖像描述)任務,就是讓計算機能夠根據一張圖片自動生成相應的文字描述。在早期的模型,比如OpenAI 的 CLIP,利用了無監督學習和微調技術,通過海量的圖片和文本數據集進行了訓練,理解了圖片和文本間的聯系,從而能夠生成有意義的圖像描述。
后來,一種名為BLIP-2的算法應運而生,它采用了更高效的預訓練策略。BLIP-2 利用現成的凍結預訓練圖像編碼器和大型語言模型,通過一個輕量級的查詢式 Transformer 來連接不同的模態。不僅減少了訓練參數,還保證了各種視覺-語言任務上取得 SOTA 表現。
得益于多模態技術的不斷發展,圖像描述這個需要結合 CV 和 NLP 的老大難問題在近些年里邁出了一大步。但直到現在,大部分 AI 生成的圖像描述都比較籠統簡短,難以充分展示圖像的豐富內涵。尤其為復雜圖像所生成的文本描述在準確性方面仍存在明顯不足,更別提那些涉及多個物體、互動和復雜細節的圖像了。
現有圖像描述解決方案面臨的挑戰
1. 過于簡化或空泛的論述
如圖,大多數圖像字幕算法給出的是“一個人和一條狗”,看似準確,但其這張圖里有非常豐富的物體和故事。他們在外面做什么,他們為什么會露營,右邊的背包有什么暗示嗎?

圖源《First Dog, 10th Man to Walk Around the World》
2. 缺少細微差別和關系
如圖,簡單地給出“對象 A 和對象 B”的描述是遠遠不夠的,兩者間的空間關系傳達了截然不同的內涵。
圖源《MESSRS: A model-based 3D system for of recognition, semantic annotation and calculating the spatial relationships of a factory’s digital facilities》
3. 處理噪音和糟糕的圖像質量
如圖,中間顯示的“攻擊”對比擾動原來照片,盡管人類眼睛瞟一眼就知道和原始圖片沒變化,但圖像描述算法依然標錯了分類。

圖源:Daniel Jakubovitz 和 Raja Giryes,Improving DNN Robustness to Adversarial Attacks using Jacobian Regularization.
4. 難以處理復雜圖像
對于經典畫作,如下圖,很多圖像描述算法只能給出簡單的“波提切利的維納斯的誕生”的說明,單單一個名字實在讓人一知半解,讓觀眾無法理解圖像所展現的品味。

SceneXplain 生成的描述
一幅標志性的畫作「維納斯的誕生」展開在眼前,女神維納斯從貝殼中誕生,周身環繞著神話人物和天界人物,包括美人魚、天使和手持花束的女人。這些人物之間微妙的交互營造出一種迷人和驚奇的感覺,宛如在慶祝維納斯降臨于人世。這優雅的構圖引領觀眾進入神話領域,驚嘆于這個永恒場景所展現的壯麗和優雅。
相比起上面生成的枯燥無味的標題,由 SceneXplain 生成的這樣一段豐富生動的描繪不僅能夠幫助我們更好地欣賞圖像,還能讓我們深入了解其審美價值。
應對多媒體內容的挑戰,SceneXplain 讓故事破圖而出
總而言之,現有圖像字幕解決方案取得了很大進步,能夠為圖片生成相關的描述,然而還無法為復雜圖像生成細節、上下文和細微差別的描述。如何進一步提高處理這樣復雜圖像的能力,是當前圖像描述技術面臨的重要挑戰。
這也正是 SceneXplain 一個箭步跨進來的契機,這是一個顛覆性的工具,它不止停留在表面,而是進一步拓寬了圖像描述的邊界。它突破了傳統圖像描述算法的局限性,提供了簡練專業、引人入勝的圖像敘事體驗。憑借用戶友好的界面、無縫 API 集成和強大的多語言支持,方便開發者輕松集成到他們的多模態應用中。

網址:scenex.jina.ai
SceneXplain 生成的文本拓展了圖片的表現力,不管是動漫,風景,商品,還是產品 UI,它都準確識別了圖片中關鍵信息,理解了畫面表達的氣氛,并深入捕捉到了圖片中的細節,并用流暢連貫的語言完成了描述。

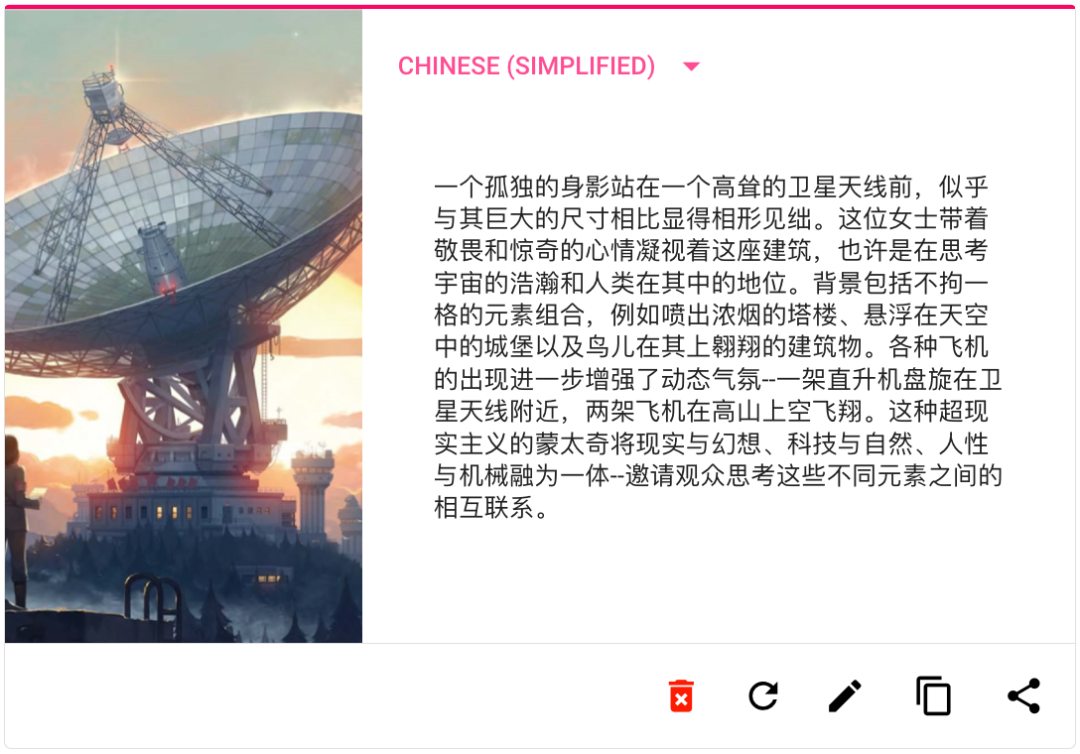
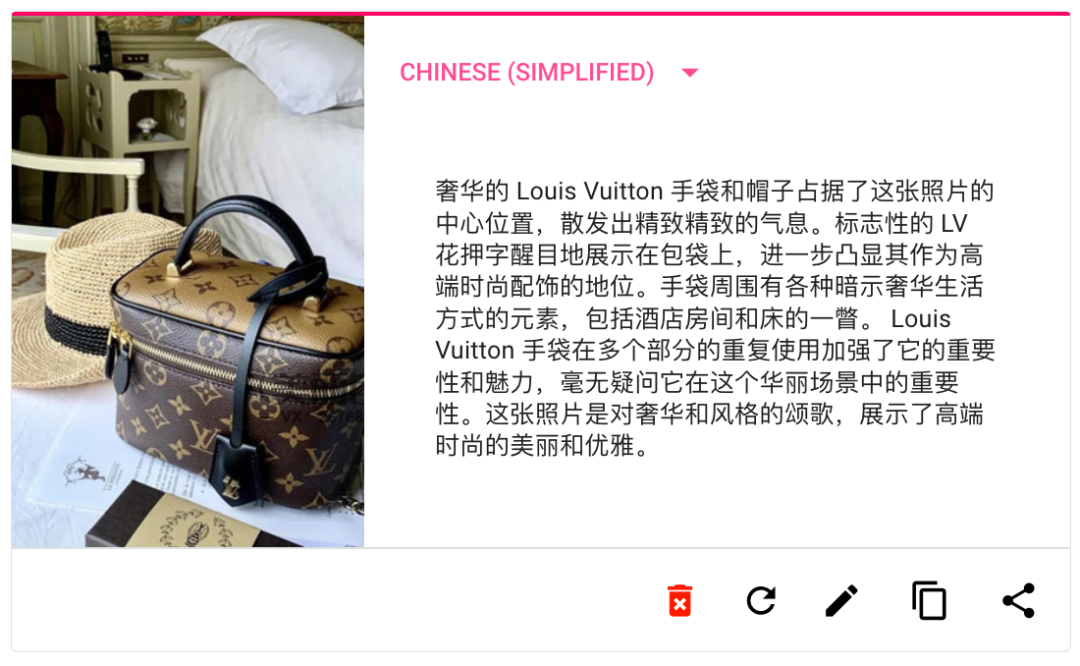
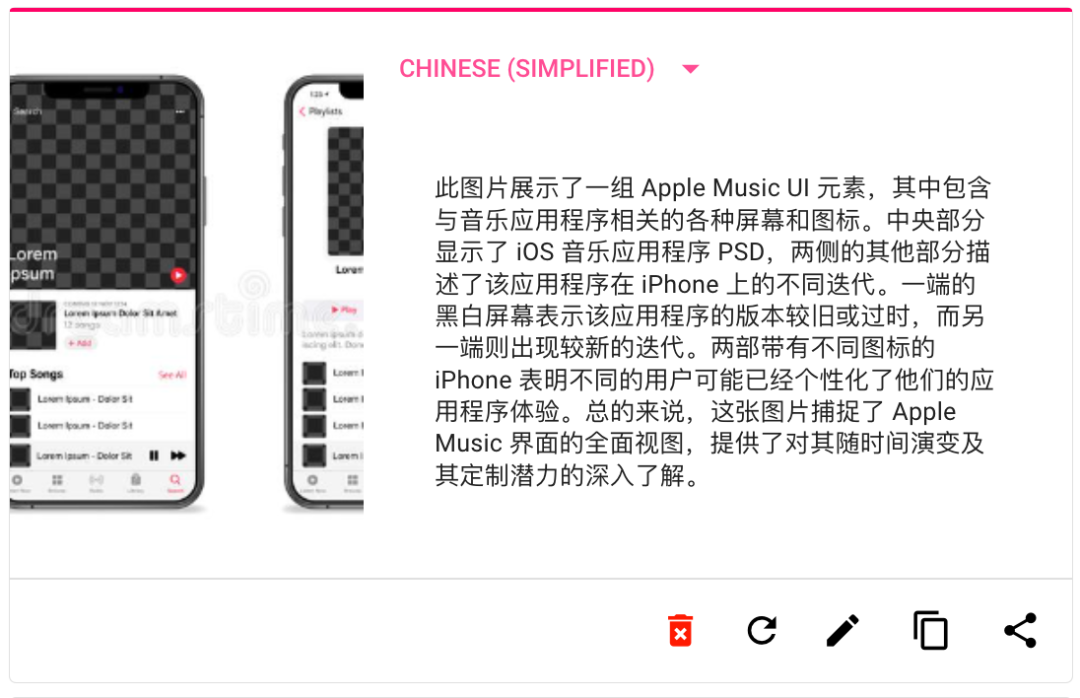
SceneXplain vs Midjourney describe
我們對 SceneXplain 與市面上流行的圖像描述工具和算法的性能進行了測評。
SceneXplain:生成詳細、復雜、生動、富有上下文的文本描述,為復雜視覺內容提供先進的圖像描述解決方案。
Midjourney:最近發布的 /describe 功能,旨在將圖像轉化為文本提示詞。
注意:相比起 /describe 生成的是圖像提示詞 Prompt,而 SceneXplain 生成出的是詳細、復雜、生動、富含上下文的圖像描述,更適合人類閱讀。此外,我們還對比了
BLIP-2:一種高效的預訓練策略,使用現成的凍結的預訓練圖像編碼器和大型語言模型進行視覺語言預訓練,可在訓練參數大大減少的情況下,實現各種視覺語言任務的 SOTA 性能。
CLIP Interrogator 2.1 專門設計給 Stable Diffusion 2.0 模型生成圖像提示詞。
接下來讓我們將這些算法對同一圖片進行描述,展示它們在各種圖像描述任務中的效果。完整的 Benchmark 表格請在公眾號回復 SceneX 獲取。





相比之下,Midjourney /describe 和 CLIP Interrogator 2.1 等解決方案側重于為圖像生成對應提示詞,而非讓人類輕松閱讀的自然語言描述。同時,BLIP-2 生成的字幕非常簡短、粗略且生硬,僅包含幾個相關詞匯,可能適用于簡單的場景,但難以捕捉到更為復雜的視覺細節,從而忽略了關鍵信息,無法展示圖像的豐富內涵。
而 SceneXplain 填補了這一塊空白,深入、準確、豐富 —— 面對復雜圖像,SceneXplain 讓圖像描述更上一層樓。它兼顧了準確性和深度,它能夠深入到復雜場景里錯綜復雜的細節,并基于這些細節的微妙關聯,比如空間位置,依賴關系等,構建出流暢連貫的敘事。這種結構化敘事讓觀眾能夠從更高的視角去理解圖像所呈現的復雜概念和場景,使得圖像栩栩如生,故事得以生動訴說。
當然,我們也必須要承認 SceneXplain 在簡單場景下有些矯枉過正,會出現一些幻覺。
SceneXplain 的優勢
與其他圖像描述解決方案相比,SceneXplain 具有許多優勢:
抗噪聲和變化的圖像質量
SceneXplain 背后強大的 AI 算法增強了其對各種圖像質量的理解能力,哪怕是低分辨率、模糊不清或帶有噪點的圖像,SceneX 也能基于有限的信息推斷圖像內涵,確保生成的描述保持準確性。



多語言支持
SceneXplain 有強大的多語言支持,可以生成多種語言的上下文豐富的圖像描述。
應用場景
我們期待您探索和體驗 SceneXplain 的能力,它的潛在應用非常廣泛,比如三個關鍵領域:
視覺敘事升級:SceneXplain 的豐富描述能夠把簡單的視覺圖像轉化為真正引人入勝的敘事體驗。這種敘事升級能夠在各個場景下得以運用,比如電商產品詳情頁的撰寫,通過詳細的圖像描述,為用戶提供更豐富的瀏覽體驗。
優化 SEO:SceneXplain 生成的生動且豐富的描述包含大量的關鍵詞,這有助于提高內容的搜索引導性和點擊率,從而有可能帶來網站排名的提升和來自搜索引擎的更多流量。
提高可訪問性:SceneXplain 生成的描述能夠充分解釋圖像細節和含義,從而有望徹底改變無障礙多媒體內容的創建和消費方式,改善視覺障礙用戶的網絡體驗。
從三個關鍵領域對應的場景上,SceneX 也有許多應用空間,對于社交媒體內容創作者,美食博主,旅游博主等為拍攝的圖片生成更加具體生動的描述,提高圖片素材的影響力;在線電商企業可以用來描述商品,用關鍵詞和描述語句豐富產品詳情頁描述,提升 SEO;博物館等公共服務行業用于為展品創建詳細的文字描述,幫助視障人士更好地欣賞等等。
如何將 SceneXplain 集成到您的應用中
SceneXplain 提供多種集成選項以滿足不同組織的需求。
1. 通過網頁生成圖像描述
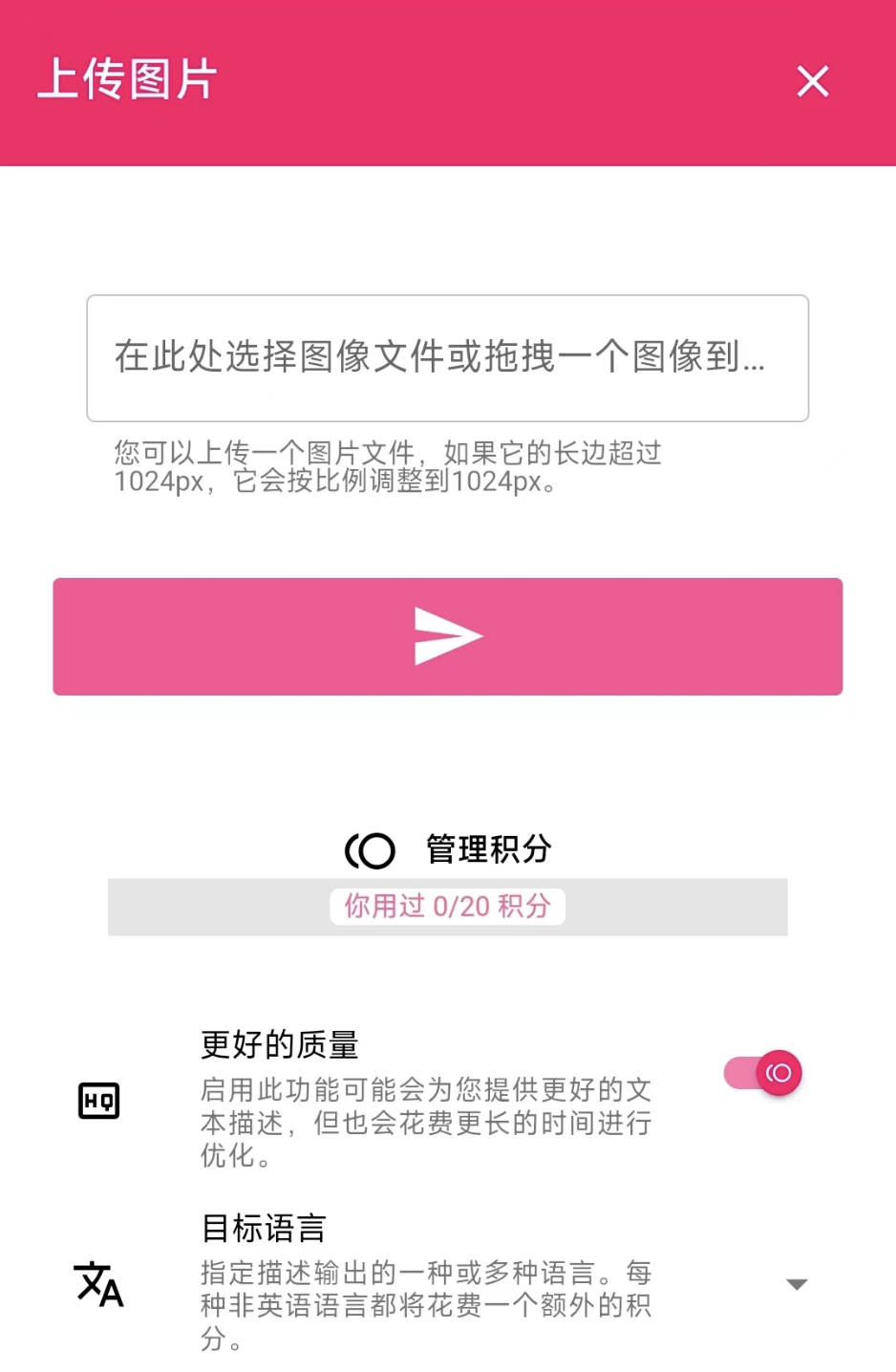
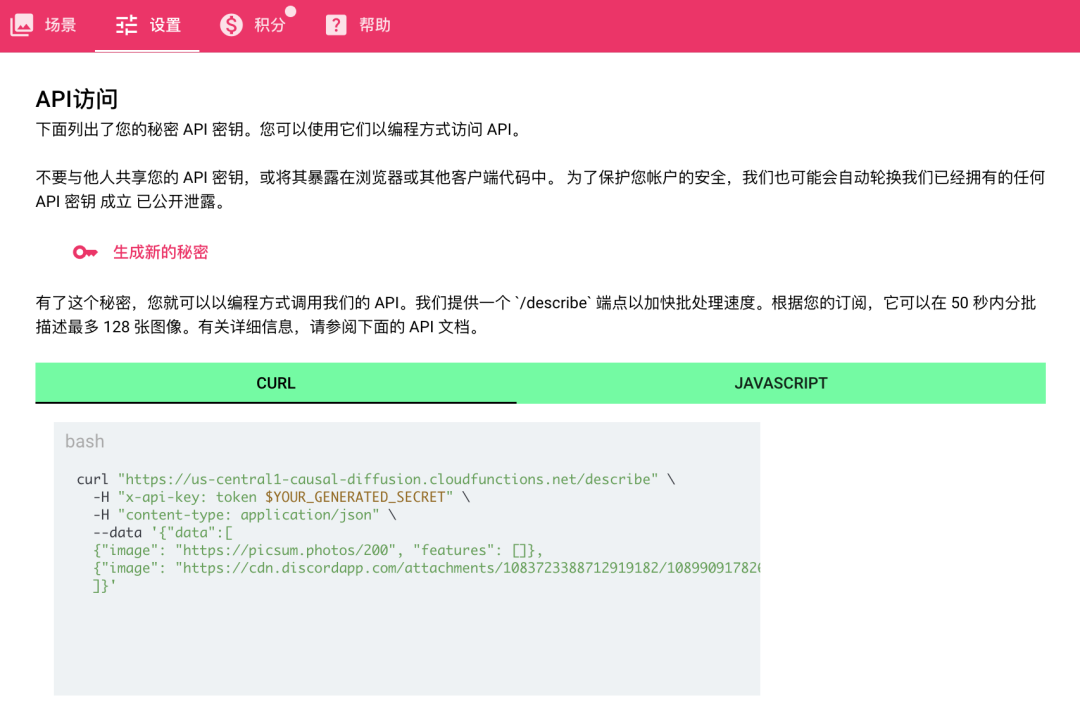
2. 通過 API 批量處理圖像
對于尋求自動化和無縫集成的組織,SceneXplain 為其系統提供了強大、可擴展且安全的 API。快速批處理 API 允許在 50 秒內在一個批次中描述多達 128 張圖像。
3. 作為 ChatGPT 插件使用
對于 ChatGPT Plus 用戶來說,可以在 ChatGPT 插件里使用。
4. 本地隱私保護解決方案
對于數據安全和隱私有嚴格要求的組織來說,我們提供本地解決方案,您可以在自己的服務器上部署 SceneXplain,確保了敏感數據保留在自己的網絡中,同樣無縫集成 SceneXplain 的高級圖像描述。
添加技術運營微信 jinaai01,或掃描文末二維碼,與我們的團隊約定會議了解本地解決方案。
SceneXplain 的核心優勢在于它能精準捕捉到圖片中多個物體之間的關系和互動,同時考慮它們在場景中的位置,以及周圍環境的氛圍。這些細節在普通的圖像描述工具里經常被忽略,但 SceneXplain 不僅在生成文本描述時保留了這些細節,還提供了更多的情境感,將視覺內容的精髓高效地呈現出來,幫助讀者更好地理解圖像所呈現的內容。無論是社交媒體、電商網站,還是公共服務領域,它都能大顯身手。
審核編輯 :李倩
-
編碼器
+關注
關注
45文章
3768瀏覽量
137033 -
算法
+關注
關注
23文章
4695瀏覽量
94649 -
ChatGPT
+關注
關注
29文章
1586瀏覽量
8778
原文標題:SceneXplain:讓 ChatGPT 開啟視覺視角
文章出處:【微信號:zenRRan,微信公眾號:深度學習自然語言處理】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
在FPGA設計中是否可以應用ChatGPT生成想要的程序呢

科技大廠競逐AIGC,中國的ChatGPT在哪?
AMOLED技術日臻成熟 即將開啟視覺新時代
機器視覺與視頻監控的結合,讓安防行業開啟一個全新的智慧時代!
iNFINITE Production使用VR作為工具 讓人們感受色盲人群的日常視角
中文版ChatGPT:開啟AI技術新時代
ChatGPT的智能來自哪里

從攻擊視角探討ChatGPT對網絡安全的影響
從防御視角探討ChatGPT對網絡安全的影響
微軟發布Visual ChatGPT:視覺模型加持ChatGPT實現絲滑聊天
一個令人驚艷的ChatGPT項目,開源了!
視覺新紀元:解碼LED顯示屏的視角、可視角、最佳視角的最終奧秘






 工商網監
工商網監
評論