") 什么是大數(shù)據(jù)?大數(shù)據(jù)技術(shù)有哪些?
什么是大數(shù)據(jù)?大數(shù)據(jù)技術(shù)有哪些?
“大數(shù)據(jù) ”這個概念火了很久,但又很不容易說得清楚(不然呢?怎么會是個位數(shù)的回答),這時候買本書來看看可能會更香。
先說結(jié)論——大數(shù)據(jù)技術(shù),其實就是一套完整的“數(shù)據(jù)+業(yè)務(wù)+需求”的解決方案。
它其實是一個很寬泛的概念,涉及五個領(lǐng)域:
- 業(yè)務(wù)分析;2.數(shù)據(jù)分析;3.數(shù)據(jù)挖掘;4.機器學(xué)習(xí);5.人工智能。
從1到5,越來越需要技術(shù)背景;從5到1,越來越貼近具體業(yè)務(wù)。
其實,除了像搜索引擎這樣依靠數(shù)據(jù)技術(shù)而誕生的產(chǎn)品外,大部分互聯(lián)網(wǎng)產(chǎn)品在生存期,即一個產(chǎn)品從0到1的階段,并不是特別需要大數(shù)據(jù)技術(shù)的。而在產(chǎn)品的發(fā)展期,也就是從“1”到“無窮”的階段,“大數(shù)據(jù)技術(shù)”對產(chǎn)品的作用才會逐漸體現(xiàn)。
主要原因是初期產(chǎn)品的功能和服務(wù)較少,也沒有“積累的用戶數(shù)據(jù)”用于模型研發(fā)。所以,我們常聽說“構(gòu)建大數(shù)據(jù)的壁壘”,這里面,“數(shù)據(jù)技術(shù)”是小壁壘,“大數(shù)據(jù)”本身才是大壁壘。
這里就從“大數(shù)據(jù)”開始說起。
什么是大數(shù)據(jù)?
“大數(shù)據(jù) ”從字面上看,就是很“大”的“數(shù)據(jù)”。先別急著打我。有多大呢?
早N多年前,百度首頁導(dǎo)航每天需要提供的數(shù)據(jù)超過1.5PB(1PB=1024TB),這些數(shù)據(jù)如果打印出來將超過5千億張A4紙。
5千億張,是不是很暴力了。
再來兩個不暴力的:
“廣西人最愛點贊,河北人最愛看段子,最關(guān)心時政的是山西人,最關(guān)注八卦的是天津。”
這組有趣的數(shù)據(jù),是今日頭條根據(jù)用戶閱讀大數(shù)據(jù)得出的結(jié)論。
而比這個更精準(zhǔn)的數(shù)據(jù),是三年前美國明尼蘇達州的一則八卦新聞:
一位氣勢洶洶的老爸沖進Target的一家連鎖超市,質(zhì)問超市為什么把嬰兒用品的廣告發(fā)給他正在念高中的女兒。
但非常打臉的是,這位父親跟他女兒溝通后發(fā)現(xiàn)女兒真的懷孕了。
在大數(shù)據(jù)的世界里,事情的原理很簡單——這位姑娘搜尋商品的關(guān)鍵詞,以及她在社交網(wǎng)站所顯露的行為軌跡,使超市的營銷系統(tǒng)捕捉到了她懷孕的信息。
你看,單個的數(shù)據(jù)并沒有價值,但越來越多的數(shù)據(jù)累加,量變會產(chǎn)生質(zhì)的飛躍。
腦補一下上面這個事件中的“女兒”,她在網(wǎng)絡(luò)營銷系統(tǒng)中的用戶畫像標(biāo)準(zhǔn)可能包括:用戶ID、性別 、性格描述、資產(chǎn)狀況、信用狀況、喜歡的顏色、鐘愛的品牌、大姨媽的日期、上周購物清單等等,有了這些信息,系統(tǒng)就可以針對這個用戶,進行精準(zhǔn)的廣告營銷和個性化購物推薦。
當(dāng)然,除了獲得大數(shù)據(jù)的個性化推薦,一不留神也容易被大數(shù)據(jù)割一波韭菜。
亞馬遜在一次新碟上市時,根據(jù)潛在客戶的人口信息、購物歷史、上網(wǎng)記錄等,給同一張碟片報出了不同的價格。這場“殺熟事件”的結(jié)局就是:亞馬遜的 CEO 貝索斯不得不親自出來道歉,解釋只是在進行價格測試。
大數(shù)據(jù) ,說白了,就是巨量數(shù)據(jù)集合。
大數(shù)據(jù)來源于海量用戶的一次次的行為數(shù)據(jù),是一個數(shù)據(jù)集合;但大數(shù)據(jù)的戰(zhàn)略意義不在于掌握龐大的數(shù)據(jù)信息,而在于對這些含有意義的數(shù)據(jù)進行專業(yè)化處理。
在電影《美國隊長2》里,系統(tǒng)能把一個人從出生開始的所有行為特征,如消費行為,生活行為等,作為標(biāo)簽存入數(shù)據(jù)庫中,最后推測出未來這個人是否會對組織產(chǎn)生威脅,然后使用定位系統(tǒng),把這些預(yù)測到有威脅的人殺死。
而在《點球成金》里,球隊用數(shù)據(jù)建模的方式,挖掘潛在的明星隊員(但其實這個案例并非典型的大數(shù)據(jù)案例,因為用到的是早已存在的數(shù)據(jù)思維和方法)。
麥肯錫全球研究所曾給出過大數(shù)據(jù)一個相當(dāng)規(guī)矩的定義:一種規(guī)模大到在獲取、存儲、管理、分析方面大大超出了傳統(tǒng)數(shù)據(jù)庫軟件工具能力范圍的數(shù)據(jù)集合,具有海量的數(shù)據(jù)規(guī)模、快速的數(shù)據(jù)流轉(zhuǎn)、多樣的數(shù)據(jù)類型和價值密度低四大特征。
上面這四個特征,也就是人們常說的大數(shù)據(jù)的4V特征(volume,variety,value,velocity),即大量,多樣性,價值,及時性。
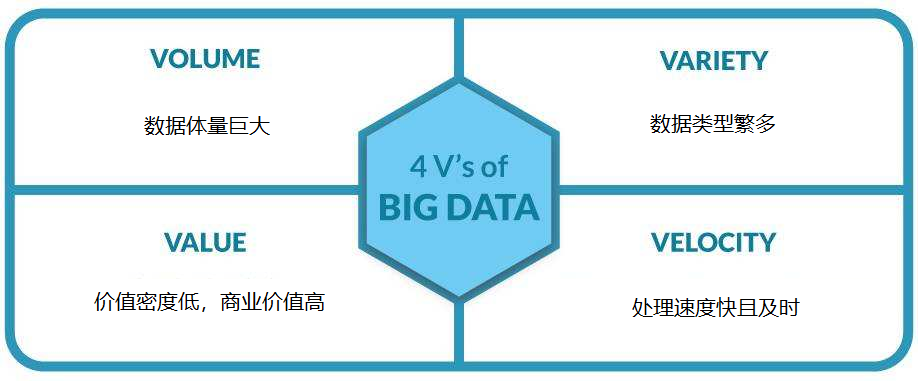
具體來說就是:
- 數(shù)據(jù)體量巨大(這是大數(shù)據(jù)最明顯的特征),有人認為,大數(shù)據(jù)的起始計量單位至少是P(1000個T)、E(100萬個T)或Z(10億個T);這里按順序給出所有單位:bit、Byte、KB、MB、GB、TB、PB、EB、ZB、YB、BB、NB、DB(進率2^10)。
不過,數(shù)據(jù)的體量有時可能并沒那么重要。比如13億人口的名字,只占硬盤幾百M空間的數(shù)據(jù),但已經(jīng)是這個領(lǐng)域里非常大的數(shù)據(jù)。
- 數(shù)據(jù)類型繁多(也就是多維度的表現(xiàn)形式)。比如,網(wǎng)絡(luò)日志、視頻、圖片、地理位置信息等等。
- 價值密度低,商業(yè)價值高。以視頻為例,一小時的視頻,在不間斷的監(jiān)控過程中,可能有用的數(shù)據(jù)僅僅只有一兩秒。因此,如何結(jié)合業(yè)務(wù)邏輯并通過強大的機器算法來挖掘數(shù)據(jù)價值(所謂“浪里淘金”吧),是最需要解決的問題。
- 處理速度快且及時。數(shù)據(jù)處理遵循“1秒定律”,可從各種類型的數(shù)據(jù)中快速獲得高價值的信息。
事實上,關(guān)于這個“4V”,業(yè)界還是有不少爭議的。比如阿里技術(shù)委員會的王堅博士,就直接把4V“扔”進了***堆。王堅在《在線》這本書里說過:“我分享時說‘大數(shù)據(jù)’這個名字叫錯了,它沒有反映出數(shù)據(jù)最本質(zhì)的東西。”
他認為,今天數(shù)據(jù)的意義并不在于有多“大”,真正有意思的是數(shù)據(jù)變得“在線”了,這恰恰是互聯(lián)網(wǎng)的特點。所有東西都能“在線”這件事(數(shù)據(jù)隨時能調(diào)用和計算),遠比“大”更能反映本質(zhì)。
什么是大數(shù)據(jù)技術(shù)?
對于一個從事大數(shù)據(jù)行業(yè)人來說,一切數(shù)據(jù)都是有意義的。因為通過數(shù)據(jù)采集、數(shù)據(jù)存儲、數(shù)據(jù)管理、數(shù)據(jù)分析與挖掘、數(shù)據(jù)展現(xiàn)等,我們可以發(fā)現(xiàn)很多有用的或有意思的規(guī)律和結(jié)論。
比如,北京公交一卡通每天產(chǎn)生4千萬條刷卡記錄,分析這些刷卡記錄,可以清晰了解北京市民的出行規(guī)律,來有效改善城市交通。
但這4千萬條刷卡數(shù)據(jù) ,不是想用就能用的,需要通過“存儲”“計算”“智能”來對數(shù)據(jù)進行加工和支撐,從而實現(xiàn)數(shù)據(jù)的增值。
而在這其中,最關(guān)鍵的問題不在于數(shù)據(jù)技術(shù)本身,而在于是否實現(xiàn)兩個標(biāo)準(zhǔn):第一,這4千萬條記錄,是否足夠多,足夠有價值;第二,是否找到適合的數(shù)據(jù)技術(shù)的業(yè)務(wù)應(yīng)用。
下面就來簡單說說上述提到的一些和“大數(shù)據(jù)“”形影不離的“小伙伴們”——
1.云計算
由于大數(shù)據(jù)的采集、存儲和計算的量都非常大,所以大數(shù)據(jù)需要特殊的技術(shù),以有效地處理大量的數(shù)據(jù)。
從技術(shù)上看,大數(shù)據(jù)與云計算的關(guān)系就像一枚硬幣的正反面一樣密不可分。大數(shù)據(jù)無法用單臺的計算機進行處理,必須采用分布式架構(gòu)。它的特色在于對海量數(shù)據(jù)進行分布式數(shù)據(jù)挖掘。但它必須依托云計算的分布式處理、分布式數(shù)據(jù)庫和云存儲、虛擬化技術(shù)。
可以說,大數(shù)據(jù)相當(dāng)于海量數(shù)據(jù)的“數(shù)據(jù)庫”,云計算相當(dāng)于計算機和操作系統(tǒng),將大量的硬件資源虛擬化后再進行分配使用。
整體來看,未來的趨勢是,云計算作為計算資源的底層,支撐著上層的大數(shù)據(jù)處理,而大數(shù)據(jù)的發(fā)展趨勢是,實時交互式的查詢效率和分析能力, “動一下鼠標(biāo)就可以在秒級操作PB級別的數(shù)據(jù)”。
2.Hadoop/HDFS /Mapreduce/Spark
除了云計算,分布式系統(tǒng)基礎(chǔ)架構(gòu)Hadoop的出現(xiàn),為大數(shù)據(jù)帶來了新的曙光。
Hadoop是Apache軟件基金會旗下的一個分布式計算平臺,為用戶提供了系統(tǒng)底層細節(jié)透明的開源分布式基礎(chǔ)架構(gòu)。它是一款用Java編寫的開源軟件框架,用于分布式存儲,并對非常大的數(shù)據(jù)集進行分布式處理,用戶可以在不了解分布式底層細節(jié)的情況下,開發(fā)分布式程序,現(xiàn)在Hadoop被公認為行業(yè)大數(shù)據(jù)標(biāo)準(zhǔn)開源軟件。
而HDFS為海量的數(shù)據(jù)提供了存儲;Mapreduce則為海量的數(shù)據(jù)提供了并行計算,從而大大提高計算效率。它是一種編程模型,用于大規(guī)模數(shù)據(jù)集(大于1TB)的并行運算,能允許開發(fā)者在不具備開發(fā)經(jīng)驗的前提下也能夠開發(fā)出分布式的并行程序,并讓其運行在數(shù)百臺機器上,在短時間完成海量數(shù)據(jù)的計算。
在使用了一段時間的 MapReduce 以后,程序員發(fā)現(xiàn) MapReduce 的程序?qū)懫饋硖闊M軌蚍庋b出一種更簡單的方式去完成 MapReduce 程序,于是就有了 Pig 和 Hive。
同時Spark/storm/impala等各種各樣的技術(shù)也相繼進入數(shù)據(jù)科學(xué)的視野。比如Spark是Apache Software Foundation中最活躍的項目,是一個開源集群計算框架,也是一個非常看重速度的大數(shù)據(jù)處理平臺。
打個比方,如果我們把上面提到的4千萬條記錄比喻成“米”,那么,我們可以用“HDFS”儲存更多的米,更豐富的食材;如果我們有了“Spark”這些組件(包括深度學(xué)習(xí)框架Tensorflow),就相當(dāng)于有了“鍋碗瓢盆”,基本上就能做出一頓可口的飯菜了。

其實,大數(shù)據(jù)火起來的時候,很多做統(tǒng)計出身的人心里曾經(jīng)是有一萬個***的——因為大數(shù)據(jù)實在太火,以至于很多公司在招人的時候,關(guān)注的是這個人對計算工具的使用,而忽略了人對數(shù)據(jù)價值和行業(yè)的理解。
但目前統(tǒng)計學(xué)專業(yè)人士確實面臨的一個現(xiàn)實問題是:隨著客戶企業(yè)的數(shù)據(jù)量逐漸龐大,不用編程的方式很難做數(shù)據(jù)分析。所以,越來越多的統(tǒng)計學(xué)家也拿自己開涮:“統(tǒng)計學(xué)要被計算機學(xué)替代了,因為現(xiàn)在幾乎沒有非大數(shù)據(jù)量的統(tǒng)計應(yīng)用”。
總之,掌握編程的基礎(chǔ),大量的項目實踐,是從事大數(shù)據(jù)技術(shù)領(lǐng)域的必要條件。
-
云計算
+關(guān)注
關(guān)注
39文章
7965瀏覽量
139248 -
數(shù)據(jù)庫
+關(guān)注
關(guān)注
7文章
3893瀏覽量
65709 -
大數(shù)據(jù)
+關(guān)注
關(guān)注
64文章
8948瀏覽量
139342
發(fā)布評論請先 登錄





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論