") GTC23 | 節(jié)能提速:NVIDIA Grace CPU 為每個數(shù)據(jù)中心鋪設節(jié)能計算快車道
GTC23 | 節(jié)能提速:NVIDIA Grace CPU 為每個數(shù)據(jù)中心鋪設節(jié)能計算快車道
主流應用在運行微服務、分析、模擬等工作時的能耗相比 X86 減少了 2 倍。
各項結果都表明,一個節(jié)能計算的新時代正在到來。
在真實工作負載測試中,NVIDIA Grace CPU 超級芯片在相同的功率范圍內(nèi)運行主流數(shù)據(jù)中心 CPU 應用的性能比 X86 處理器提高了 2 倍,這將帶來許多新的可能性。
這意味著數(shù)據(jù)中心可以處理兩倍的峰值流量并減少多達一半的電費。它們還可以在空間有限的網(wǎng)絡邊緣實現(xiàn)更大的性能,甚至可以同時實現(xiàn)上述優(yōu)勢。
節(jié)能已成為數(shù)據(jù)中心的優(yōu)先事項
數(shù)據(jù)中心經(jīng)理需要依靠這些方案在當今這個節(jié)能時代中快速發(fā)展。
摩爾定律實際上已經(jīng)過時。物理學不再允許工程師在保持空間和功耗不變的情況下加入更多的晶體管。
這就是為什么新一代 X86 CPU 的性能提升相比前一代產(chǎn)品還不到 30%”,這也是為什么越來越多的數(shù)據(jù)中心設置了功率上限。
再加上全球氣候變暖的威脅,數(shù)據(jù)中心電力供應已經(jīng)沒有增容的余地,但它們?nèi)匀恍枰獫M足不斷增長的算力需求。
在保持功耗不變的情況下提高性能
麥肯錫的一項研究顯示,美國的計算需求每年增長 10%,并將在 2022 至 2030 年的八年內(nèi)翻倍。
麥肯錫表示:“因此,確保數(shù)據(jù)中心可持續(xù)性的壓力很大,一些監(jiān)管機構和政府正在對新建的數(shù)據(jù)中心推行可持續(xù)性標準。”
根據(jù)麥肯錫所引用的一項調(diào)查,隨著摩爾定律的終結,數(shù)據(jù)中心在計算效率上的進展已停滯不前(見下圖)。
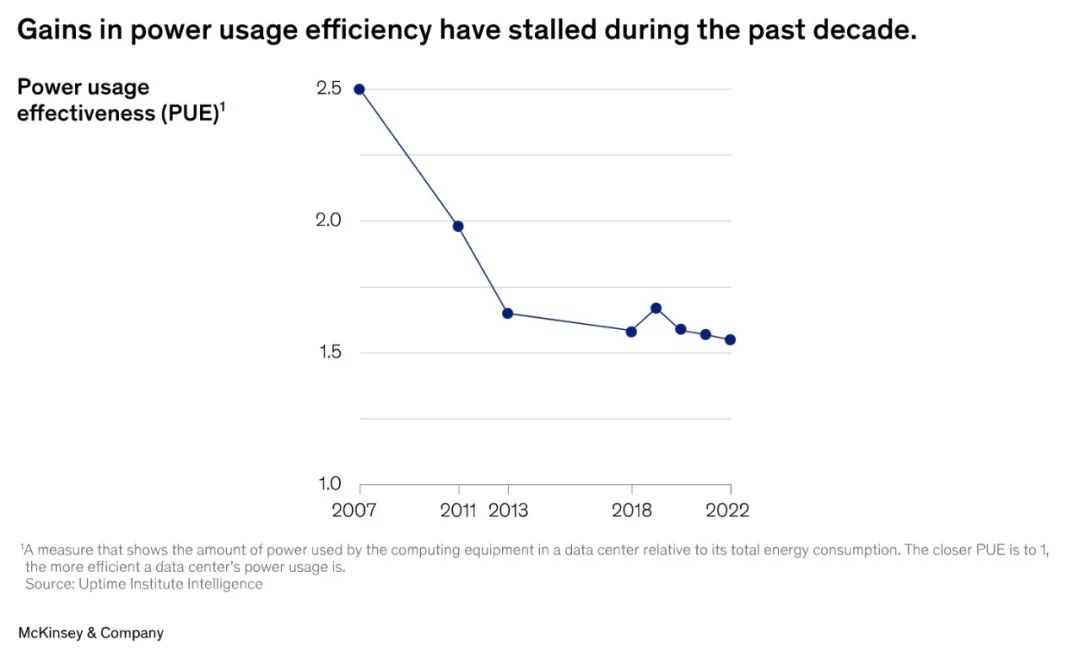
在當今的環(huán)境下,NVIDIA Grace 所實現(xiàn)的 2 倍提升等于實現(xiàn)了驚人的多代飛躍,符合當今數(shù)據(jù)中心高管的需求。
全球服務商 Equinix 管理著 240 多座數(shù)據(jù)中心。該公司的邊緣基礎設施負責人 Zac Smith 在一篇關于節(jié)能計算的文章中描述了這些需求。
“我們需要在減少碳排放的前提下提高性能。”Zac 表示:“我們有 1 萬家客戶指望我們在這個過程中提供幫助。他們需要更多的數(shù)據(jù)和更高的智能化水平,而且往往要求使用 AI。另外,他們希望以可持續(xù)的方式來實現(xiàn)這一目標。”
三項 CPU 創(chuàng)新
得益于三項創(chuàng)新,Grace CPU 提供了高效性能。
它在一塊對分帶寬(一項吞吐量指標)為 3.2 TB/s 的裸芯片中使用一種超快的結構將 72 個 Arm Neoverse V2 核心連接在一起,然后使用 NVIDIA NVLink-C2C 互連技術在一個超級芯片封裝中連接其中的兩塊裸片,實現(xiàn) 900GB/s 的帶寬。
最后,它是第一個使用服務器級 LPDDR5X 內(nèi)存的數(shù)據(jù)中心 CPU。這幫助它在成本相仿的情況下增加了高達 50%的內(nèi)存帶寬,且功耗只有常規(guī)服務器內(nèi)存的八分之一。緊湊的尺寸使其密度比典型的卡式內(nèi)存設計增加了 2 倍。
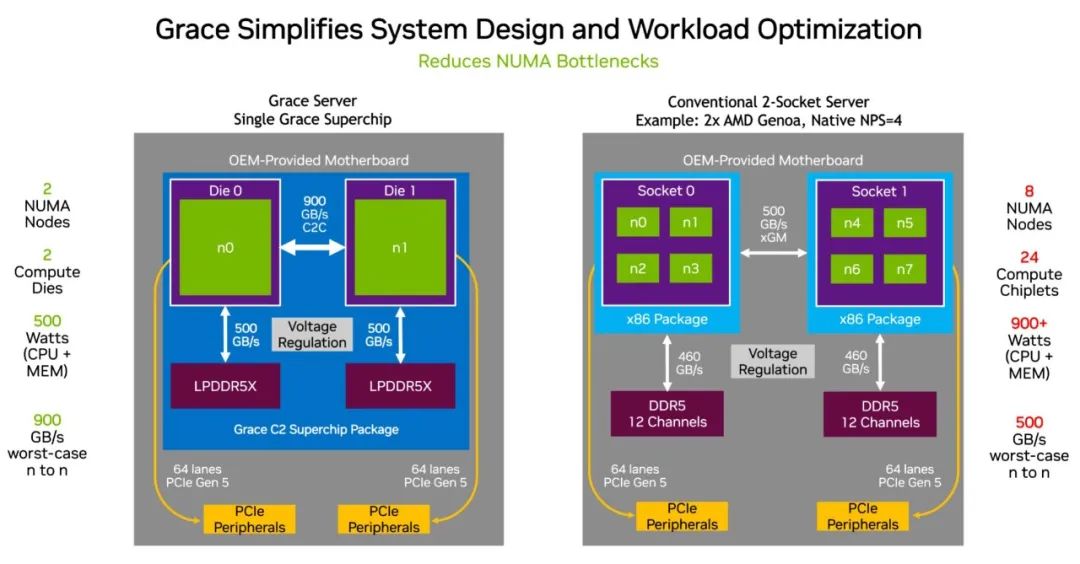
與現(xiàn)有的 x86 CPU 相比,NVIDIA Grace 的設計更加簡單,提供更高的帶寬,而且能耗更低。
首批結果揭曉
現(xiàn)今,NVIDIA 工程師在 Grace 上運行了真實的數(shù)據(jù)中心工作負載。
他們發(fā)現(xiàn),在相同的功率下,相比數(shù)據(jù)中心現(xiàn)有的 x86 CPU,Grace 更具優(yōu)勢:
-
運行微服務的速度快 2.3 倍
-
內(nèi)存密集型數(shù)據(jù)處理性能快 2 倍
-
在多個技術計算應用上運行流體力學計算工作時,速度快 1.9 倍
如下圖所示,數(shù)據(jù)中心通常需要等到兩代或兩代以上的 CPU 才能獲得以上優(yōu)勢。
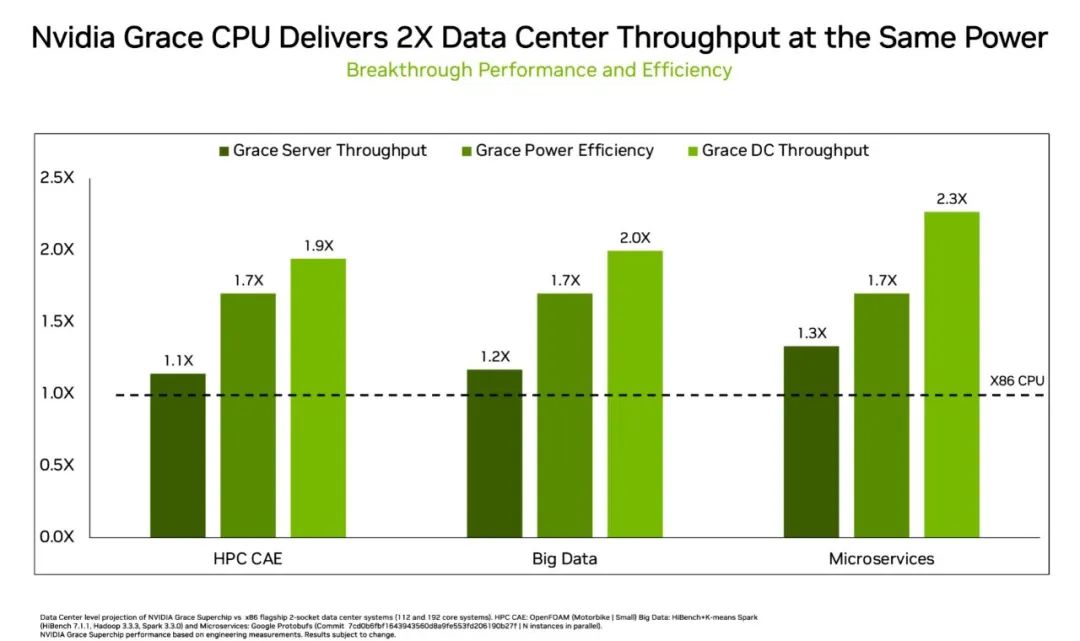
凈提升(淺綠色)來自于服務器間的性能提升(深綠色)以及附加的 Grace 服務器。憑借節(jié)能性,Grace 服務器適用于這一 x86 功率范圍(中間條)。
甚至在這些 CPU 工作結果出爐之前,用戶就對 Grace 的創(chuàng)新做出了反應。
美國洛斯阿拉莫斯國家實驗室在 5 月宣布將在 Venado 中使用 Grace。這臺 10 EXAFLOP AI 超級計算機將推動該實驗室在材料科學和可再生能源等領域的工作。同時,歐洲和亞洲的數(shù)據(jù)中心正在評估 Grace 的工作負載。
NVIDIA Grace 目前正在提供樣品,將在下半年投入生產(chǎn)。華碩、Atos、技嘉、慧與、高通、超微、緯創(chuàng)和 ZT Systems 正在建造使用該產(chǎn)品的服務器。
深入了解可持續(xù)計算
想要深入了解細節(jié),掃描二維碼閱讀關于 Grace 架構的白皮書。
 ?
?
?
? ?
?
3 月 24 日 下午 14:00-16:00,繼續(xù)鎖定 GTC23,加入在線觀看(Watch Party) 派對,從黃仁勛與 OpenAI 創(chuàng)始人兼首席科學家高能對話中,看 AI 的現(xiàn)狀和未來!
Watch Party 觀看指南
會議開始前 15 分鐘,
點擊下方出現(xiàn)的“JOIN WATCH PARTY NOW"

原文標題:GTC23 | 節(jié)能提速:NVIDIA Grace CPU 為每個數(shù)據(jù)中心鋪設節(jié)能計算快車道
文章出處:【微信公眾號:NVIDIA英偉達企業(yè)解決方案】歡迎添加關注!文章轉載請注明出處。
-
英偉達
+關注
關注
22文章
3920瀏覽量
93086
原文標題:GTC23 | 節(jié)能提速:NVIDIA Grace CPU 為每個數(shù)據(jù)中心鋪設節(jié)能計算快車道
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達企業(yè)解決方案】歡迎添加關注!文章轉載請注明出處。
發(fā)布評論請先 登錄
磁懸浮冷站引領綠色革命,維諦技術(Vertiv)助力中國電信江西云計算數(shù)據(jù)中心制冷系統(tǒng)實現(xiàn)PUE1.2

NVIDIA Grace CPU C1獲得廣泛支持
適用于數(shù)據(jù)中心和AI時代的800G網(wǎng)絡
NVIDIA GTC2025 亮點 NVIDIA推出 DGX Spark個人AI計算機

NVIDIA 宣布推出 DGX Spark 個人 AI 計算機

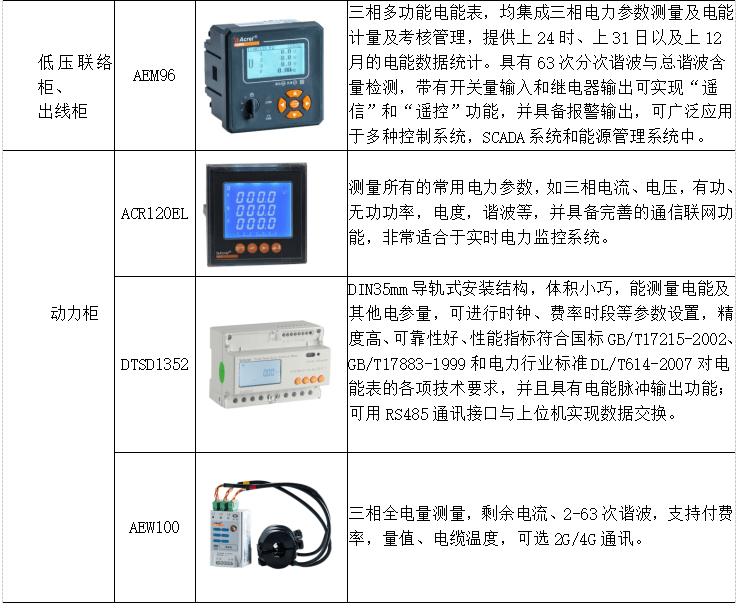
安科瑞數(shù)據(jù)中心末端配電交流出線30路監(jiān)控模塊AMC100-FAK30
2024年星閃進入規(guī)模商用快車道
云計算與數(shù)據(jù)中心的關系
ALDC 2024第四屆數(shù)據(jù)中心液冷產(chǎn)業(yè)大會圓滿舉辦

數(shù)據(jù)中心能耗較多 如何科學智慧化進行整體解決方案呢
數(shù)據(jù)中心液冷需求、技術及實際應用
數(shù)據(jù)中心布線標準有什么
安森美推出新款碳化硅芯片,助力AI數(shù)據(jù)中心節(jié)能
NVIDIA為新工業(yè)革命打造 AI 工廠和數(shù)據(jù)中心
計算機行業(yè)攜手 NVIDIA 為新工業(yè)革命打造 AI 工廠和數(shù)據(jù)中心






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論