 linux內核是怎么管理物理內存的呢?
linux內核是怎么管理物理內存的呢?
1, 介紹
我們可以把物理內存簡單地看成一個大的數組,其中每個字節都可以通過物理地址進行訪問。
前面的文章《一文搞懂DDR SDRAM工作原理》介紹過物理內存的物理結構,及怎么通過控制器、PHY讀、寫SDRAM芯片獲取、寫入數據,讓我們明白物理內存在硬件原理方面的實現是什么樣的。
在《一文搞懂CPU的工作原理》介紹過CPU訪問物理內存的全過程,總結下來就是:
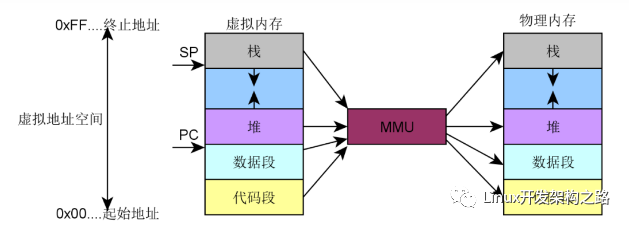
CPU寫物理內存的過程:CPU先給出要寫入數據的物理地址對應的虛擬地址,通過MMU轉化為物理地址,若cache中沒有命中,則將要寫入數據的物理地址放到系統總線上。DDR的控制器感受到總線上的地址信號以及寫控制信號,將物理地址從總線上讀出來,并等待數據的到達。CPU將數據發送到系統總線上,DDR控制器感受到總線上的數據信號,將數據從總線上讀取出來。DDR控制器通過物理地址找到相應的存儲模塊,然后將數據寫入到物理地址對應的存儲模塊。
CPU讀物理內存的過程:CPU給出要讀數據的物理地址對應的虛擬地址,通過MMU轉化為物理地址,若cache中沒有命中,則將物理地址放到系統總線上。DDR控制器感受到總線上的地址型號及讀控制信號,將物理地址從總線上讀取出來,DDR控制器根據物理地址找到存儲模塊中數據的位置,并從SDRAM芯片中取出物理地址對應的數據,DDR控制器將數據放到總線上,CPU從總線上獲取數據,并存放到寄存器上。
之前已經講述過CPU讀、寫物理內存的過程,本文主要講述linux內核是怎么管理物理內存,包括物理內存涉及的數據結構、內存模型、內存架構、物理內存的管理流程。
2, 數據結構
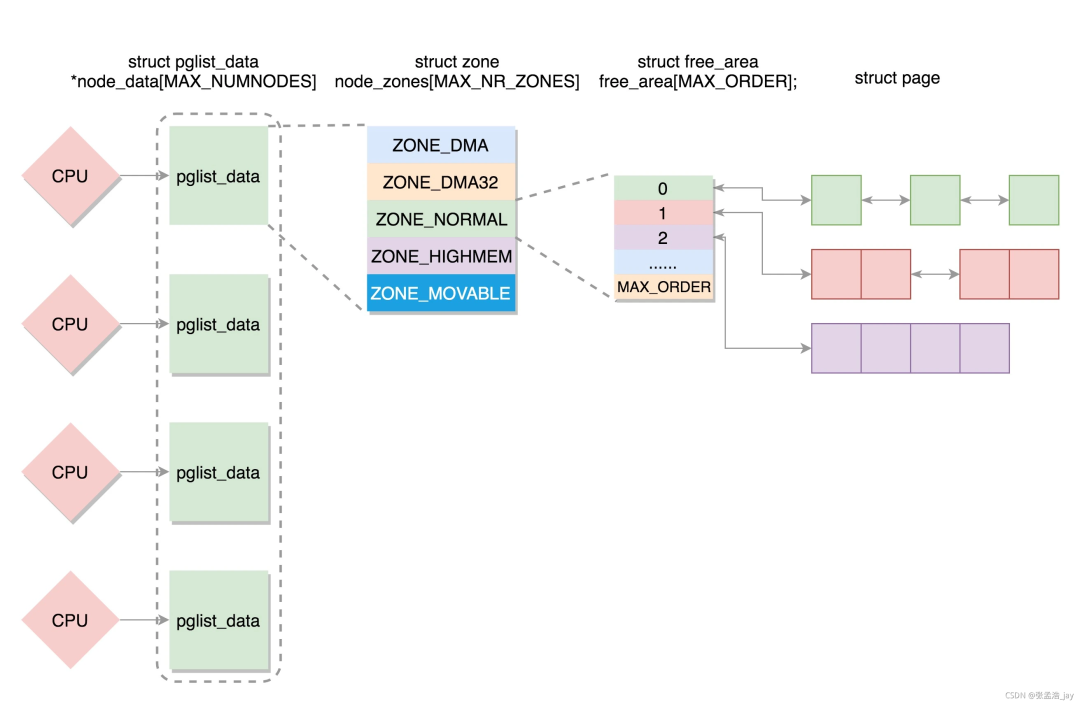
與物理內存相關的數據結構有內存節點(pglist_data)、內存管理區(zone)、物理頁面(page)、mem_map數組、頁表項(PTE)、頁幀號(PFN)、物理地址(paddress)。
Linux內核通過struct page來管理物理內存中的一個頁。內核為每個物理頁定義了一個索引編號PFN(Page Frame Number,頁幀號),這個PFN與struct page是一一對應的。通過page_to_pfn/pfn_to_page兩個宏實現物理頁和struct page之間的相互轉換。

3, 框架
3.1 內存架構
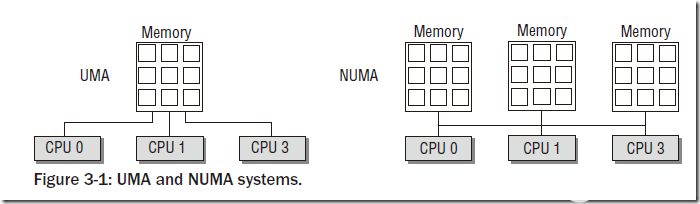
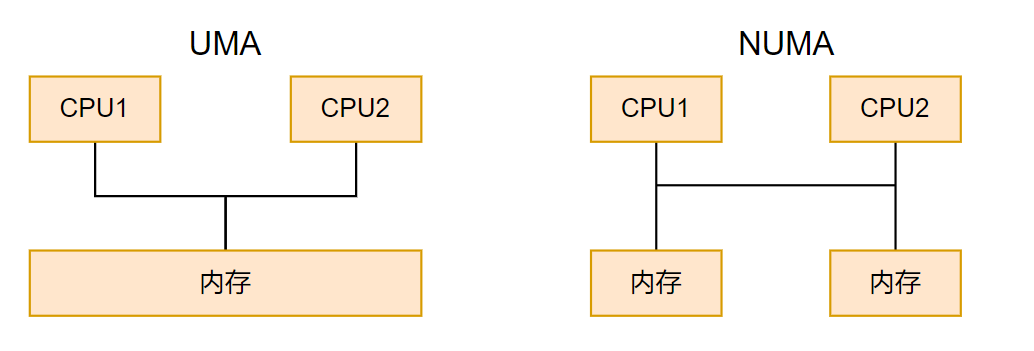
在當前的計算機、嵌入式系統中,以內存為研究對象可以分成兩種架構。一種是UMA(Uniform Memory Access,統一內存訪問)架構,另外一種是NUMA(Non-Uniform Memory Access,非統一內存訪問)架構。
1) UMA內存架構
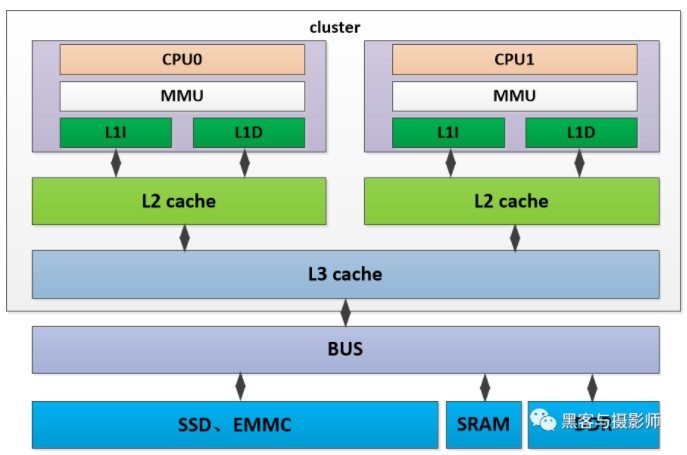
內存可以被其他模塊統一尋址,有統一的結構。目前,大部分嵌入式系統及計算機系統都采用UMA架構。如上圖所示,是一個UMA架構的系統,有兩個cpu位于同一個cluster中,cpu分別有自己的L1D、L1I cache及L2 cache。兩個cpu共享L3 cache,通過系統總線可以訪問物理內存DDR,SRAM、SSD等模塊,并且兩個CPU對物理內存的訪問消耗是一樣的。這種訪問模式的處理器被成為SMP(Aymmetric Multiprocessing,對稱多處理器)
2) NUMA內存架構
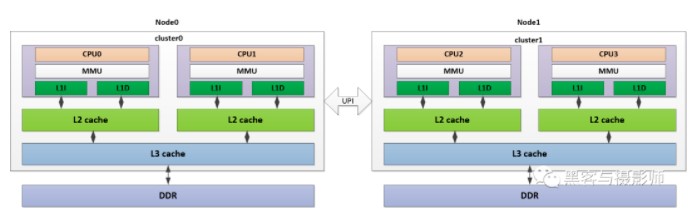
系統中有多個內存節點和多個cpu cluster,CPU訪問本地內存節點的時間開銷最小,訪問遠端的內存節點的時間開銷要大。如上圖所示,是一個NUMA架構的系統,其中cpu0、cpu1在cluster0中,與相應的L1I/L1D cache、L2 cache、L3 cache及DDR組成node0節點。同樣的,CPU2、CPU3在cluster1中,與相應的L1I/L1D cache、L2 cache、L3 cache及DDR組成node1節點。兩個node節點,通過UPI(Ultra Path Interconnect,超路徑互聯)總線連接。CPU0可以通過這個UPI訪問遠端node1上的物理內存,但是要比本地node0的內存訪問慢得多。
3.2 內存模型
內核是以頁為單位使用struct page數據結構來管理物理內存的。內核通過物理內存模型來實現組織管理這些物理內存頁,不同的物理內存模型,應對的場景及頁幀號與物理頁之間的計算方式也不一樣。
1) 平坦內存模型:FLATMEM
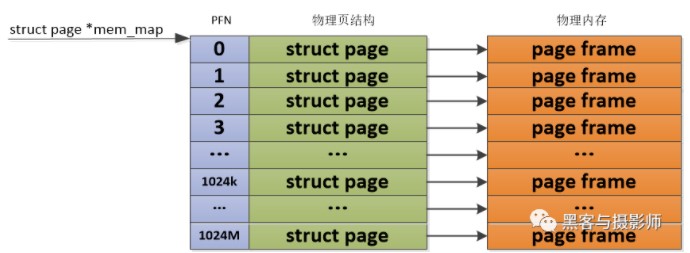
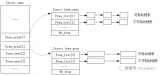
Linux早期使用的物理內存比較小,比如幾十MB,并且這些物理內存是一片連續的存儲空間,這樣物理地址也是連續的,按固定頁大小劃分出來的物理頁也是連續的。Linux內核會用一個mem_map全局數組來組織管理所有的物理頁,其中物理頁是通過struct page來管理,這樣每個數組的下標便是PFN。這種連續的物理內存便是平坦內存模型。
2) 非連續內存模型:DISCONTIGMEM
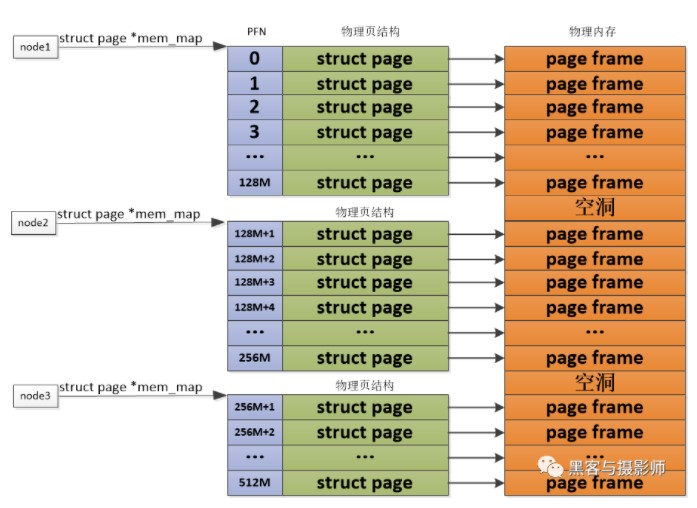
對于PLATMEM適合管理一整塊連續的物理內存,但是對于多塊非連續的物理內存,若使用FLATMEM來管理,這時mem_map全局數組中會有不連續內存地址區的內存空洞,這會造成內存空間的浪費。為了管理這種不連續的物理內存,內核引入了DISCONTIGMEM非連續內存模型來管理,以便消除不連續的內存地址空洞對mem_map全局數組造成的空間浪費。
DISCONTIGMEM非連續內存模型的思路是:將物理內存從宏觀上劃分成一個個節點node,但是微觀上還是以物理頁為單位,每個node節點管理一塊連續的物理內存,這樣這些非連續的內存,會以連續的內存方式劃分到node節點中管理起來,這樣便可以避免內存空洞造成的空間浪費。
3) 稀疏內存模型:SPARSEMEM
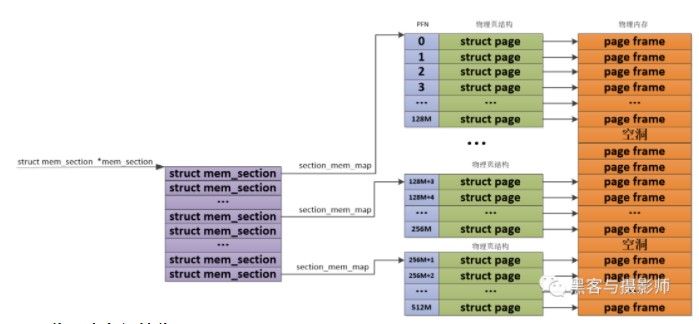
由于物理內存在使用的時候,會有很多空洞,這樣物理內存存在多處不連續。如果利用上面講的DISCONTIGMEM內存模型,會造成node眾多,這樣開銷就大了。為了能夠更靈活、更高效的、更小的管理連續物理內存。SPARSEMEM系數內存模型就是為了對粒度更小的連續內存塊進行精細的管理,用于管理連續內存塊的單元被稱為section。在內存中用struct mem_section結構體表示SPARSEMEM模型中的section。
由于section被用作管理小粒度的連續內存塊,這些小的連續物理內存在section中也是通過數組的方式被組織管理,其中mem_section結構體中的section_mem_map指針用于指向section中管理連續內存的page數組。SPARSEMEM內存模型中的mem_section會存在放在一個全局的數組中,并且每個mem_section都可以在系統運行的時候進行內存的offline/online,這樣便可以支持內存的熱拔插。
4, 物理內存初始化
4.1 內存大小初始化
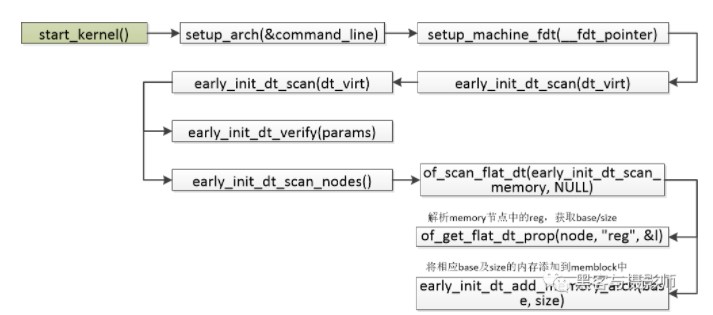
物理內存的大小會在DTS(Device Tree Source,設備樹)中描述,如下dts的描述:
memory { device_type = "memory"; reg = <0x000000000 0x80000000 0x00000000 0x40000000>; };
起始地址為0x80000000,大小為0x40000000
內存在啟動的過程中,會解析上面的DTS,相應的調用過程如下:
4.2 memblock內存分配器
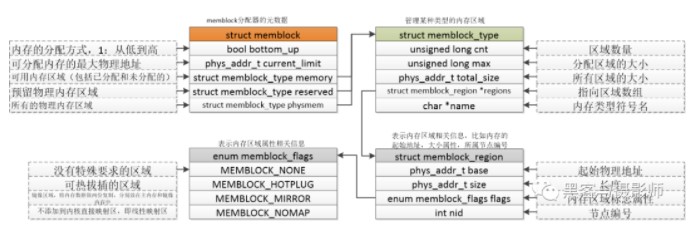
在伙伴系統沒有初始化前,在內核中需要一套機制管理內存的申請與釋放。在啟動的過程中,會解析設備樹中的memory節點,把所有物理內存添加到memblock中。后面會通過一篇文章講解memblock分配器。這里先把結構體及函數接口列出來。

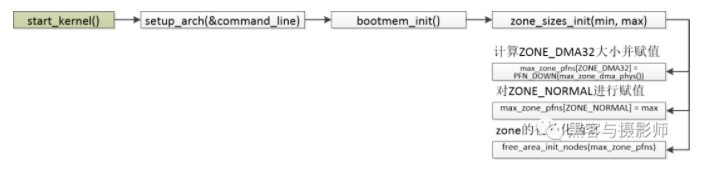
4.3 ZONE初始化
在對頁表初始化后,內核就會對內存進行管理。內核會將這些物理內存分配成不同的內存管理區(ZONE),分別針對這些內存管理區進行管理。
常見的內存管理區如下:
ZONE_DMA:用于inter X86 ISA設備的DMA操作,范圍是0~16MB,ARM沒有這個內存管理區。
ZONE_DMA32:用于最低4GB的內存訪問的設備,如只支持32位的DMA設備。
ZONE_NORMAL:4GB 以后的物理內存,用于線性映射物理內存。若系統內存小于4GB,則沒有這個內存管理區。
ZONE_HIGHMEM:用于管理高端內存,這些高端內存是不能線性映射到內核地址空間的。64位Linux是沒有這個內存管理區的。
其中ZONE是利用struct zone數據結構進行管理的,zone數據結構經常會被訪問,因此為了提升性能,這個數據結構要求以L1高速緩存對齊。數據結構zone中關鍵的成員如下:
Watermark:每個zone在系統啟動時會計算出3個水位,分別是WMARK_MIN(最低警戒水位)、WMARK_LOW(低水位)、WMARK_HIGH(高水位),這些在頁面分配器和kswapd頁面回收中會用到。
Lowemem_reserve:防止頁面分配器過渡使用低端zone的內存。
Zone_pgdat:指向內存節點。
Pageset:用于維護每個cpu上的一些列頁面,以減少自旋鎖的使用
Zone_start_pfn:zone的起始頁幀號。
Managed_pages:zone中被伙伴系統管理的頁面數量。
Spanned_pages:zone中包含的頁面數量。
Present_pages:zone里實際管理的頁面數量。對于一些架構來說,它和spanned_pages數量一致。
Free_area:伙伴系統核心的數據結構,管理空閑也快鏈表的數組。
Lock:并行訪問時用于保護zone的自旋鎖。
Lruvec:LRU鏈表集合。
4.4 伙伴系統
內核啟動完成后,物理內存的頁面就要添加到伙伴系統中來管理了。伙伴系統(buddy system)是操作系統中常用的動態內存管理方法。用戶提出申請時,分配一個大小合適的物理內存,當用戶釋放后,回收相應的物理內存。后面會專門寫一篇介紹伙伴系統的文章,這里只做簡單的介紹。
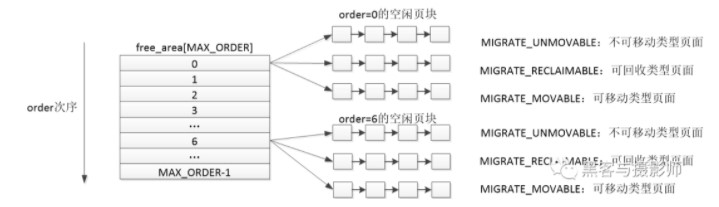
在伙伴系統中,內存塊的大小是2的order次冪個頁幀。Linux中order的最大值是11。伙伴系統大致的思想是,將所有空閑的物理內存頁面分組成11個內存塊的鏈表,每個內存塊的鏈表分別包含1、2、4、8、16、32、…、1024個連續的物理頁面。1024個物理頁面對應著4MB大小的連續物理內存。
由上一節我們了解到,物理內存在linux中分出了幾個ZONE來管理空閑物理頁塊。ZONE可以根據內核的配置來劃分。每個ZONE又是利用伙伴系統來管理。ZONE的數據結構有一個free_area數據結構,數據結構的大小是MAX_ORDER(11)。free_area數據結構中包含了MIGRATE_TYPES個鏈表。可以理解成ZONE根據order的大小由0~(MAX_ORDER-1)個free_area,每個free_area根據MIGRATE_TYPES類型,由幾個相應的鏈表組成。
審核編輯:劉清
-
控制器
+關注
關注
114文章
16912瀏覽量
182644 -
DDR
+關注
關注
11文章
730瀏覽量
66308 -
Linux
+關注
關注
87文章
11442瀏覽量
212609 -
LINUX內核
+關注
關注
1文章
317瀏覽量
22153 -
MMU
+關注
關注
0文章
92瀏覽量
18608
原文標題:一文搞懂linux物理內存管理
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
Linux內核內存管理架構解析

Linux內核內存管理之內核非連續物理內存分配
Linux系統中通過預留物理內存實現ARM與FPGA高效通信的方法

Linux內核地址映射模型與Linux內核高端內存詳解
如何避免Linux的物理內存碎片化
鴻蒙內核源碼分析: 虛擬內存和物理內存是怎么管理的






 工商網監
工商網監
評論