 【AI簡報第20230217期】超越GPT 3.5的小模型來了!AI網戀詐騙時代開啟
【AI簡報第20230217期】超越GPT 3.5的小模型來了!AI網戀詐騙時代開啟
嵌入式 AI
AI 簡報 20230217 期
1. 超越GPT 3.5的小模型來了!
原文:https://mp.weixin.qq.com/s/gv_FJD0aIpDNbky54unj2Q
論文地址:https://arxiv.org/abs/2302.00923
項目地址:https://github.com/amazon-science/mm-cot
去年年底,OpenAI 向公眾推出了 ChatGPT,一經發布,這項技術立即將 AI 驅動的聊天機器人推向了主流話語的中心,眾多研究者并就其如何改變商業、教育等展開了一輪又一輪辯論。
隨后,科技巨頭們紛紛跟進投入科研團隊,他們所謂的「生成式 AI」技術(可以制作對話文本、圖形等的技術)也已準備就緒。
眾所周知,ChatGPT 是在 GPT-3.5 系列模型的基礎上微調而來的,我們看到很多研究也在緊隨其后緊追慢趕,但是,與 ChatGPT 相比,他們的新研究效果到底有多好?近日,亞馬遜發布的一篇論文《Multimodal Chain-of-Thought Reasoning in Language Models》中,他們提出了包含視覺特征的 Multimodal-CoT,該架構在參數量小于 10 億的情況下,在 ScienceQA 基準測試中,比 GPT-3.5 高出 16 個百分點 (75.17%→91.68%),甚至超過了許多人類。
這里簡單介紹一下 ScienceQA 基準測試,它是首個標注詳細解釋的多模態科學問答數據集 ,由 UCLA 和艾倫人工智能研究院(AI2)提出,主要用于測試模型的多模態推理能力,有著非常豐富的領域多樣性,涵蓋了自然科學、語言科學和社會科學領域,對模型的邏輯推理能力提出了很高的要求。

下面我們來看看亞馬遜的語言模型是如何超越 GPT-3.5 的。
包含視覺特征的 Multimodal-CoT
大型語言模型 (LLM) 在復雜推理任務上表現出色,離不開思維鏈 (CoT) 提示的助攻。然而,現有的 CoT 研究只關注語言模態。為了在多模態中觸發 CoT 推理,一種可能的解決方案是通過融合視覺和語言特征來微調小型語言模型以執行 CoT 推理。
然而,根據已有觀察,小模型往往比大模型更能頻繁地胡編亂造,模型的這種行為通常被稱為「幻覺(hallucination)」。此前谷歌的一項研究也表明( 論文 Chain-of-Thought Prompting Elicits Reasoning in Large Language Models ),基于 CoT 的提示只有在模型具有至少 1000 億參數時才有用!
也就是說,CoT 提示不會對小型模型的性能產生積極影響,并且只有在與 ~100B 參數的模型一起使用時才會產生性能提升。
然而,本文研究在小于 10 億參數的情況下就產生了性能提升,是如何做到的呢?簡單來講,本文提出了包含視覺特征的 Multimodal-CoT,通過這一范式(Multimodal-CoT)來尋找多模態中的 CoT 推理。
Multimodal-CoT 將視覺特征結合在一個單獨的訓練框架中,以減少語言模型有產生幻覺推理模式傾向的影響。總體而言,該框架將推理過程分為兩部分:基本原理生成(尋找原因)和答案推理(找出答案)。
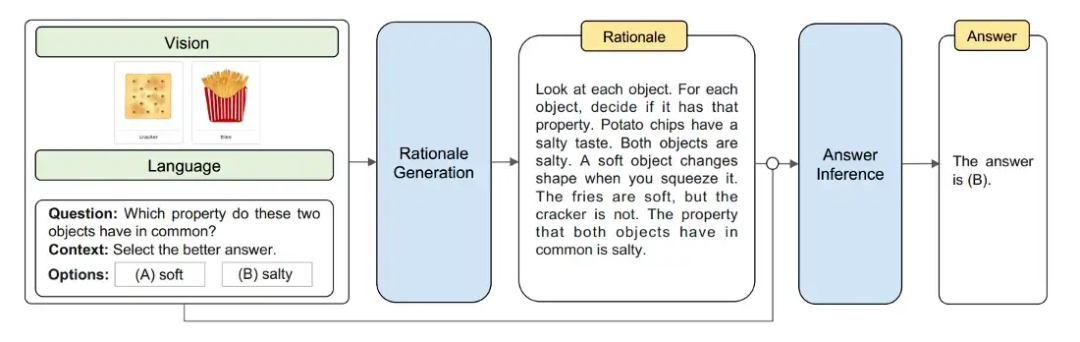
數據集
本文主要關注 ScienceQA 數據集,該數據集將圖像和文本作為上下文的一部分,此外,該數據集還包含對答案的解釋,以便可以對模型進行微調以生成 CoT 基本原理。此外,本文利用 DETR 模型生成視覺特征。
較小的 LM 在生成 CoT / 基本原理時容易產生幻覺,作者推測,如果有一個修改過的架構,模型可以利用 LM 生成的文本特征和圖像模型生成的視覺特征,那么 更有能力提出理由和回答問題。
架構
總的來說,我們需要一個可以生成文本特征和視覺特征并利用它們生成文本響應的模型。
又已知文本和視覺特征之間存在的某種交互,本質上是某種共同注意力機制,這有助于封裝兩種模態中存在的信息,這就讓借鑒思路成為了可能。為了完成所有這些,作者選擇了 T5 模型,它具有編碼器 - 解碼器架構,并且如上所述,DETR 模型用于生成視覺特征。
T5 模型的編碼器負責生成文本特征,但 T5 模型的解碼器并沒有利用編碼器產生的文本特征,而是使用作者提出的共同注意式交互層(co-attention-styled interaction layer)的輸出。
拆解來看,假設 H_language 是 T5 編碼器的輸出。X_vision 是 DETR 的輸出。第一步是確保視覺特征和文本特征具有相同的隱藏大小,以便我們可以使用注意力層。
結果
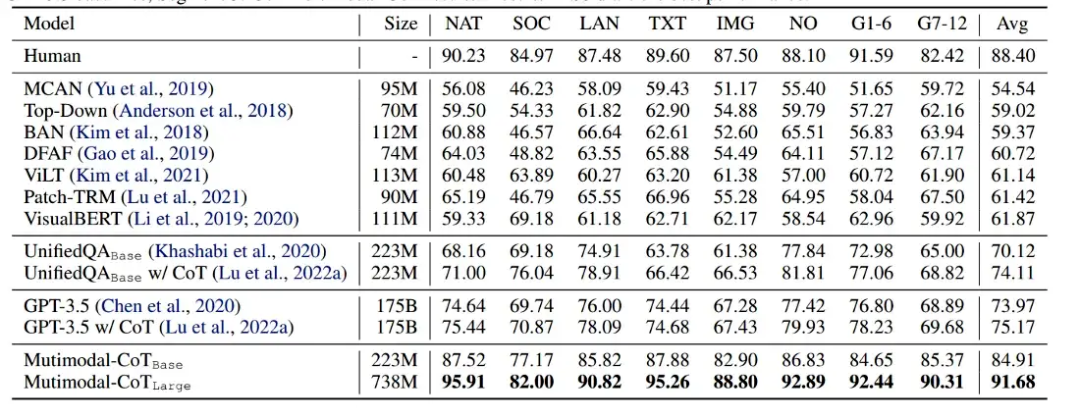
作者使用 UnifiedQA 模型的權重作為 T5 模型的初始化點,并在 ScienceQA 數據集上對其進行微調。他們觀察到他們的 Multimodal CoT 方法優于所有以前的基準,包括 GPT-3.5。
有趣的地方在于,即使只有 2.23 億個參數的基本模型也優于 GPT-3.5 和其他 Visual QA 模型!這突出了擁有多模態架構的力量。
結論
這篇論文帶來的最大收獲是多模態特征在解決具有視覺和文本特征的問題時是多么強大。
作者展示了利用視覺特征,即使是小型語言模型(LM)也可以產生有意義的思維鏈 / 推理,而幻覺要少得多,這揭示了視覺模型在發展基于思維鏈的學習技術中可以發揮的作用。
從實驗中,我們看到以幾百萬個參數為代價添加視覺特征的方式,比將純文本模型擴展到數十億個參數能帶來更大的價值。
2. AI照騙恐怖如斯!美女刷屏真假難辨,網友:AI網戀詐騙時代開啟
原文:https://mp.weixin.qq.com/s/nELNzal7tjkbZ6uKkuGkeA
什么?這些不是真人照片,都是AI畫出來的?!
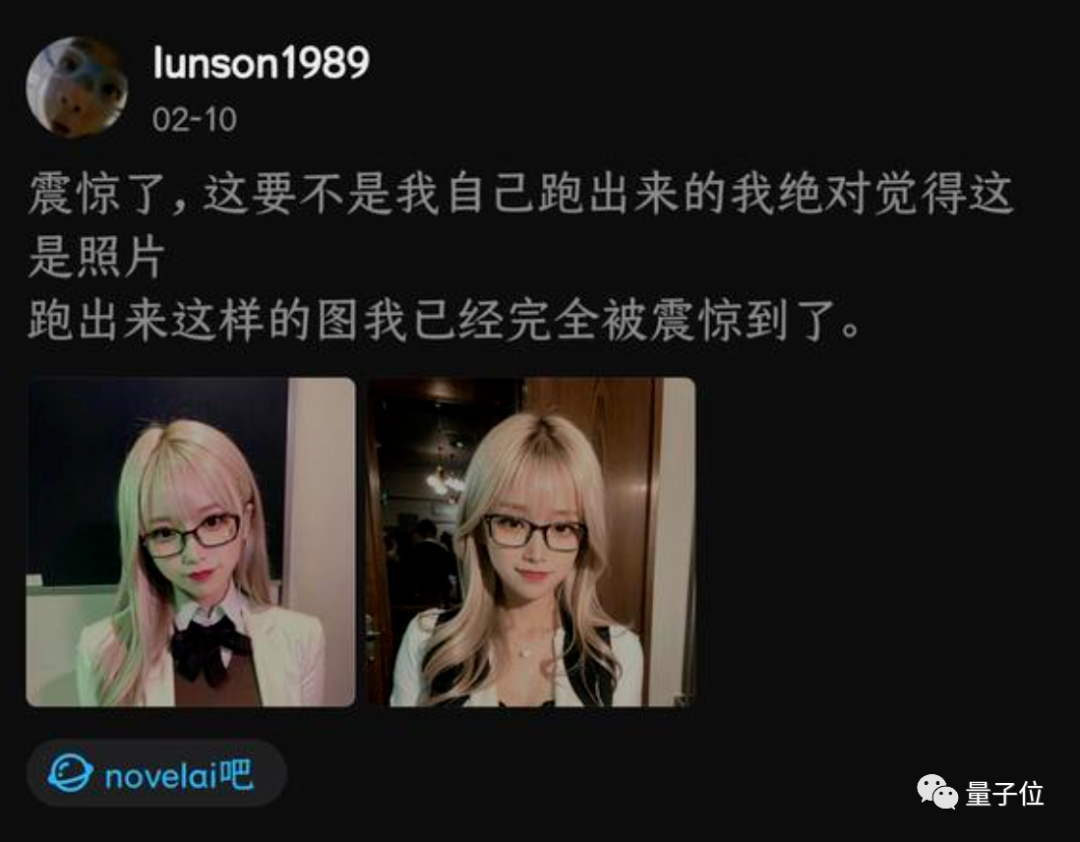
最近這樣一組美女圖片刷屏了,許多人看到第一反應都是“AI逼真到這個份上了?”。

直到看到手部露出了破綻,才敢確定確實是AI畫的。

嗯….啥都不想說,看就得了,感興趣的小伙伴直接查看原文。
3. YOLOv7農業方向應用|基于注意力機制改進的YOLOv7算法CBAM-YOLOv7
原文:https://mp.weixin.qq.com/s/HXKsTnSbr8Ks1VF2p7RoTA
論文鏈接:https://www.mdpi.com/2077-0472/12/10/1659/pdf
飼養密度是影響畜禽大規模生產和動物福利的關鍵因素。然而,麻鴨養殖業目前使用的人工計數方法效率低、人工成本高、精度低,而且容易重復計數和遺漏。
在這方面,本文使用深度學習算法來實現對密集麻鴨群數量的實時監測,并促進智能農業產業的發展。本文構建了一個新的大規模大麻鴨目標檢測圖像數據集,其中包含1500個大麻鴨目標的檢測全身幀標記和僅頭部幀標記。
此外,本文提出了一種基于注意力機制改進的YOLOv7算法CBAM-YOLOv7,在YOLOv7的主干網絡中添加了3個CBAM模塊,以提高網絡提取特征的能力,并引入SE-YOLOv7和ECA-YOLOv7進行比較實驗。實驗結果表明,CBAM-YOLOv7具有較高的精度,[email protected]和[email protected]:0.95略有改善。CBAM-YOLOv7的評價指標值比SE-YOLOw7和ECA-YOLOv 7的提高更大。此外,還對兩種標記方法進行了比較測試,發現僅頭部標記方法導致了大量特征信息的丟失,而全身框架標記方法顯示了更好的檢測效果。
算法性能評估結果表明,本文提出的智能麻鴨計數方法是可行的,可以促進智能可靠的自動計數方法的發展。

隨著技術的發展,監控設備在農業中發揮著巨大的作用。有多種方法可以監測個體動物的行為,例如插入芯片記錄生理數據、使用可穿戴傳感器和(熱)成像技術。一些方法使用附著在鳥類腳上的可穿戴傳感器來測量它們的活動,但這可能會對受監測的動物產生額外影響。特別是,在商業環境中,技術限制和高成本導致這種方法的可行性低。
因此,基于光流的視頻評估將是監測家禽行為和生理的理想方法。最初,許多監控視頻都是人工觀察的,效率低下,依賴于工作人員的經驗判斷,沒有標準。然而,近年來,由于大數據時代的到來和計算機圖形卡的快速發展,計算機的計算能力不斷增強,加速了人工智能的發展。與人工智能相關的研究正在增加,計算機視覺在動物檢測中的應用越來越廣泛。
例如,2014年Girshick等人提出的R-CNN首次引入了兩階段檢測方法。該方法使用深度卷積網絡來獲得優異的目標檢測精度,但其許多冗余操作大大增加了空間和時間成本,并且難以在實際的養鴨場中部署。Law等人提出了一種單階段的目標檢測方法CornerNet和一種新的池化方法:角點池化。
然而,基于關鍵點的方法經常遇到大量不正確的目標邊界框,這限制了其性能,無法滿足鴨子飼養模型的高性能要求。Duan等人在CornerNet的基礎上構建了CenterNet框架,以提高準確性和召回率,并設計了兩個對特征級噪聲具有更強魯棒性的自定義模塊,但Anchor-Free方法是一個具有前兩個關鍵點組合的過程,并且由于網絡結構簡單、處理耗時、速率低和測量結果不穩定,它不能滿足麻鴨工業化養殖所需的高性能和高準確率的要求。
本文的工作使用了一種單階段目標檢測算法,它只需要提取特征一次,就可以實現目標檢測,其性能高于多階段算法。目前,主流的單階段目標檢測算法主要包括YOLO系列、SSD、RetinaNet等。本文將基于CNN的人群計數思想轉移并應用到鴨計數問題中。隨著檢測結果的輸出,作者嵌入了一個目標計數模塊來響應工業化的需求。目標計數也是計算機視覺領域的一項常見任務。目標計數可分為多類別目標計數和單類別目標計數;本工作采用了一群大麻鴨的單類別計數。
本文希望實現的目標是:
建立了一個新的大規模的德雷克圖像數據集,并將其命名為“大麻鴨數據集”。大麻鴨數據集包含1500個標簽,用于全身框架和頭部框架,用于鴨的目標檢測。該團隊首次發布了大麻鴨數據集
本研究構建了大鴨識別、大鴨目標檢測、大鴨圖像計數等全面的工作基線,實現了麻鴨的智能養殖
該項目模型引入了CBAM模塊來構建CBAM-YOLOv7算法
本文很長,同時基礎理論和背景介紹的非常詳細,感興趣的小伙伴可以翻看原文,進行研究。
4. AutoML并非全能神器!新綜述爆火,網友:了解深度學習領域現狀必讀
原文:https://mp.weixin.qq.com/s/qR2bMaZby299PlEHUlNoBQ
如今深度學習模型開發已經非常成熟,進入大規模應用階段。
然而,在設計模型時,不可避免地會經歷迭代這一過程,它也正是造成模型設計復雜、成本巨高的核心原因,此前通常由經驗豐富的工程師來完成。
之所以迭代過程如此“燒金”,是因為在這一過程中,面臨大量的開放性問題 (open problems)。
這些開放性問題究竟會出現在哪些地方?又要如何解決、能否并行化解決?
現在一篇論文綜述終于對此做出介紹,發出后立刻在網上爆火。
作者嚴謹地參考了接近300篇文獻,對大量應用深度學習中的開放問題進行分析,力求讓讀者一文了解該領域最新趨勢。

這篇論文要研究什么?
眾所周知,當我們拿到一個機器學習問題時,通常處理的流程分為以下幾步:收集數據、編寫模型、訓練模型、評估模型、迭代、測試、產品化。
在這篇論文中,作者把上述這些流程比作一個雙層次的最佳化問題。
內層優化回路需要最小化衡量模型效果評估的損失函數,背后是為了尋求最佳模型參數而進行的深入研究的訓練過程。
而外層優化回路的研究較少,包括最大化一個適當選擇的性能指標來評估驗證數據,這正是我們所說的“迭代過程”,也就是追求最優模型超參數的過程。
不過,值得注意的是,面對不同的問題,它的解也需要特定分析,有時候情況甚至會非常復雜。
例如,評估度量Mval是一個離散且不可微的函數。它并未被很好地定義,有時候甚至在某些自我監督式和非監督式學習以及生成模型問題中不存在。
同時,你也可能設計了一個非常好的損失函數Ltrain,結果發現它是離散或不可微的,這種情況下它會變得非常棘手,需要用特定方法加以解決。
因此,本篇論文的研究重點就是迭代過程中遇到的各種開放性問題,以及這些問題中可以并行解決優化的部分案例。
機器學習中開放問題有哪些?
論文將開放性問題類型分為監督學習和其他方法兩大類。
值得一提的是,無論是監督學習還是其他方法,作者都貼心地附上了對應的教程地址:
如果對概念本身還不了解的話,點擊就能直接學到他教授的視頻課程,不用擔心有困惑的地方。
首先來看看監督學習。
這里我們不得不提到AutoML。作為一種用來降低開發過程中迭代復雜度的“偷懶”方法,它目前在機器學習中已經應用廣泛了。
通常來說,AutoML更側重于在監督學習方法中的應用,尤其是圖像分類問題。
畢竟圖像分類可以明確采用精度作為評估指標,使用AutoML非常方便。
但如果同時考慮多個因素,尤其是包括計算效率在內,這些方法是否還能進一步被優化?
在這種情況下,如何提升性能就成為了一類開放性問題,具體又分為以下幾類:
大模型、小模型、模型魯棒性、可解釋AI、遷移學習、語義分割、超分辨率&降噪&著色、姿態估計、光流&深度估計、目標檢測、人臉識別&檢測、視頻&3D模型等。
這些不同的領域也面臨不同的開放性問題。
例如大模型中的學習率并非常數、而是函數,會成為開放問題之一,相比之下小模型卻更考慮性能和內存(或計算效率)的權衡這種開放性問題。
其中,小模型通常會應用到物聯網、智能手機這種小型設備中,相比大模型需求算力更低。
又例如對于目標檢測這樣的模型而言,如何優化不同目標之間檢測的準確度,同樣是一種復雜的開放性問題。
在這些開放性問題中,有不少可以通過并行方式解決。如在遷移學習中,迭代時學習到的特征會對下游任務可泛化性和可遷移性同時產生什么影響,就是一個可以并行研究的過程。
同時,并行處理開放性問題面臨的難度也不一樣。
例如基于3D點云數據同時施行目標識別、檢測和語義分割,比基于2D圖像的目標識別、檢測和分割任務更具挑戰性。
再來看看監督學習以外的其他方法,具體又分為這幾類:
自然語言處理(NLP)、多模態學習、生成網絡、域適應、少樣本學習、半監督&自監督學習、語音模型、強化學習、物理知識學習等。
以自然語言處理為例,其中的多任務學習會給模型帶來新的開放性問題。
像經典的BERT模型,本身不具備翻譯能力,因此為了同時提升多種下游任務性能指標,研究者們需要權衡各種目標函數之間的結果。
又如生成模型中的CGAN(條件GAN),其中像圖像到圖像翻譯問題,即將一張圖片轉換為另一張圖片的過程。
這一過程要求將多個獨立損失函數進行加權組合,并讓總損失函數最小化,就又是一個開放性問題。
其他不同的問題和模型,也分別都會在特定應用上遇到不同類型的開放性問題,因此具體問題依舊得具體分析。
經過對各類機器學習領域進行分析后,作者得出了自己的一些看法。
一方面,AI表面上是一種“自動化”的過程,從大量數據中產生自己的理解,然而這其中其實涉及大量的人為操作,有不少甚至是重復行為,這被稱之為“迭代過程”。
另一方面,這些工作雖然能部分通過AutoML精簡,然而AutoML目前只在圖像分類中有較好的表現,并不意味著它在其他領域任務中會取得成功。
總而言之,應用深度學習中的開放性問題,依舊比許多人想象得要更為復雜。
論文地址:https://arxiv.org/abs/2301.11316
5. ChatGPT的技術體系總結
原文:https://mp.weixin.qq.com/s/woAWs9l_7Opt63-vJfmhzQ
0.參考資料
RLHF論文:Training language models to follow instructions with human feedback(https://arxiv.org/pdf/2203.02155.pdf)
摘要上下文中的 RLHF:Learning to summarize from Human Feedback (https://arxiv.org/pdf/2009.01325.pdf)
PPO論文:Proximal Policy Optimization Algorithms(https://arxiv.org/pdf/1707.06347.pdf)
Deep reinforcement learning from human preferences (https://arxiv.org/abs/1706.03741)
1.引言
1.1 ChatGPT的介紹
作為一個 AI Chatbot,ChatGPT 是當前比較強大的自然語言處理模型之一,它基于 Google 的 T5 模型進行了改進,同時加入了許多自然語言處理的技術,使得它可以與人類進行自然的、連貫的對話。ChatGPT 使用了 GPT(Generative Pre-training Transformer)架構,它是一種基于 Transformer 的預訓練語言模型。GPT 的主要思想是將大量的語料庫輸入到模型中進行訓練,使得模型能夠理解和學習語言的語法、語義等信息,從而生成自然、連貫的文本。與其他 Chatbot 相比,ChatGPT 的優勢在于它可以進行上下文感知型的對話,即它可以記住上下文信息,而不是簡單地匹配預先定義的規則或模式。此外,ChatGPT 還可以對文本進行生成和理解,支持多種對話場景和話題,包括閑聊、知識問答、天氣查詢、新聞閱讀等等。
盡管 ChatGPT 在自然語言處理領域已經取得了很好的表現,但它仍然存在一些局限性,例如對于一些復雜的、領域特定的問題,它可能無法給出正確的答案,需要通過人類干預來解決。因此,在使用 ChatGPT 進行對話時,我們仍需要謹慎對待,盡可能提供明確、簡潔、準確的問題,以獲得更好的對話體驗。
1.2 ChatGPT的訓練模式
ChatGPT 的訓練模式是基于大規模文本數據集的監督學習和自我監督學習,這些數據集包括了各種類型的文本,例如新聞文章、博客、社交媒體、百科全書、小說等等。ChatGPT 通過這些數據集進行預訓練,然后在特定任務的數據集上進行微調。
對于 Reinforcement Learning from Human Feedback 的訓練方式,ChatGPT 通過與人類進行對話來進行模型訓練。具體而言,它通過與人類進行對話,從而了解人類對話的語法、語義和上下文等方面的信息,并從中學習如何生成自然、連貫的文本。當 ChatGPT 生成回復時,人類可以對其進行反饋,例如“好的”、“不太好”等等,這些反饋將被用來調整模型參數,以提高 ChatGPT 的回復質量。Reinforcement Learning from Human Feedback 的訓練方式,可以使 ChatGPT 更加智能,更好地模擬人類的思維方式。不過這種訓練方式也存在一些問題,例如人類反饋的主觀性和不確定性等,這些問題可能會影響模型的訓練效果。因此,我們需要在使用 ChatGPT 進行對話時,謹慎對待反饋,盡可能提供明確、簡潔、準確的反饋,以獲得更好的對話體驗。
1.3 RLHF的介紹
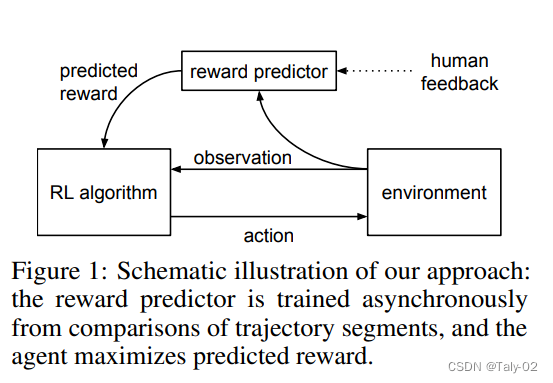
在過去的幾年中,語言模型通過根據人類輸入提示生成多樣化且引人注目的文本顯示出令人印象深刻的能力。然而,什么才是“好”文本本質上很難定義,因為它是主觀的并且依賴于上下文。有許多應用程序,例如編寫您需要創意的故事、應該真實的信息性文本片段,或者我們希望可執行的代碼片段。編寫一個損失函數來捕獲這些屬性似乎很棘手,而且大多數語言模型仍然使用簡單的下一個loss function(例如交叉熵)進行訓練。為了彌補損失本身的缺點,人們定義了旨在更好地捕捉人類偏好的指標,例如 BLEU 或 ROUGE。雖然比損失函數本身更適合衡量性能,但這些指標只是簡單地將生成的文本與具有簡單規則的引用進行比較,因此也有局限性。如果我們使用生成文本的人工反饋作為性能衡量標準,或者更進一步并使用該反饋作為損失來優化模型,那不是很好嗎?這就是從人類反饋中強化學習(RLHF)的想法;使用強化學習的方法直接優化帶有人類反饋的語言模型。RLHF 使語言模型能夠開始將在一般文本數據語料庫上訓練的模型與復雜人類價值觀的模型對齊。
在傳統的強化學習中,智能的agent需要通過不斷的試錯來學習如何最大化獎勵函數。但是,這種方法往往需要大量的訓練時間和數據,同時也很難確保智能代理所學習到的策略是符合人類期望的。Deep Reinforcement Learning from Human Preferences 則采用了一種不同的方法,即通過人類偏好來指導智能代理的訓練。具體而言,它要求人類評估一系列不同策略的優劣,然后將這些評估結果作為訓練數據來訓練智能代理的深度神經網絡。這樣,智能代理就可以在人類偏好的指導下,學習到更符合人類期望的策略。除了減少訓練時間和提高智能代理的性能之外,Deep Reinforcement Learning from Human Preferences 還可以在許多現實場景中發揮作用,例如游戲設計、自動駕駛等。通過使用人類偏好來指導智能代理的訓練,我們可以更好地滿足人類需求,并創造出更加智能和人性化的技術應用
2. 方法介紹
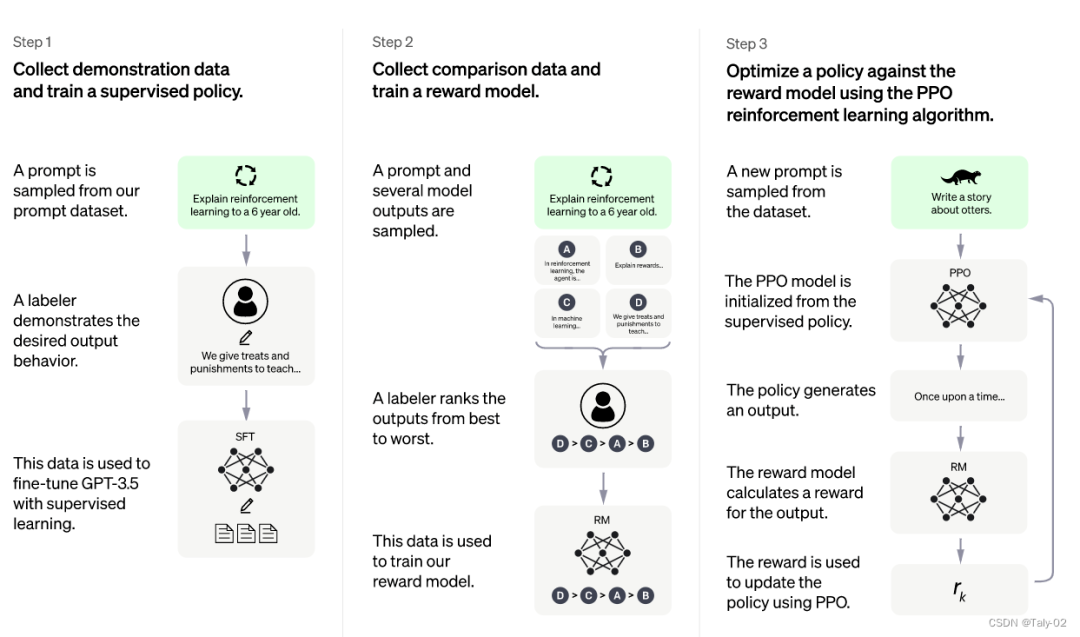
監督調優模型:在一小部分已經標注好的數據上進行有監督的調優,讓機器學習從一個給定的提示列表中生成輸出,這個模型被稱為 SFT 模型。 模擬人類偏好,讓標注者們對大量 SFT 模型輸出進行投票,這樣就可以得到一個由比較數據組成的新數據集。然后用這個新數據集來訓練一個新模型,叫做 RM 模型。 用 RM 模型進一步調優和改進 SFT 模型,用一種叫做 PPO 的方法得到新的策略模式。
2.1 監督調優模型
2.2 訓練回報模型
利用prompt 生成多個輸出。 利用標注者對這些輸出進行排序,獲得一個更大質量更高的數據集。 把模型將 SFT 模型輸出作為輸入,并按優先順序對它們進行排序。
2.3 使用 PPO 模型微調 SFT 模型
幫助性:判斷模型遵循用戶指示以及推斷指示的能力。 真實性:判斷模型在封閉領域任務中有產生虛構事實的傾向。 無害性:標注者評估模型的輸出是否適當、是否包含歧視性內容。
6. 一文梳理清楚Python OpenCV 的知識體系
原文:https://mp.weixin.qq.com/s/woAWs9l_7Opt63-vJfmhzQ
圖像讀取; 窗口創建; 圖像顯示; 圖像保存; 資源釋放。
cv2.imread()、cv2.namedWindow()、cv2.imshow()、cv2.imwrite()、cv2.destroyWindow()、cv2.destroyAllWindows()、 cv2.imshow()、cv2.cvtColor()、cv2.imwrite()、cv2.waitKey()。VideoCapture 類,該類常用的方法有:open() 函數; isOpened() 函數; release() 函數; grab() 函數; retrieve() 函數; get() 函數; set() 函數;
VideoWriter 類,用于保存視頻文件。Point 類、Rect 類、Size 類、Scalar 類,除此之外,在 Python 中用 numpy 對圖像進行操作,所以 numpy 相關的知識點,建議提前學習,效果更佳。cv2.line(); cv2.circle(); cv2.rectangle(); cv2.ellipse(); cv2.fillPoly(); cv2.polylines(); cv2.putText()。
cv2.setMouseCallback() ,滑動條涉及兩個函數,分別是:cv2.createTrackbar() 和 cv2.getTrackbarPos()。cv2.split(),通道合并函數 cv2.merge()。cv2.add(); cv2.addWeighted(); cv2.subtract(); cv2.absdiff(); cv2.bitwise_and(); cv2.bitwise_not(); cv2.bitwise_xor()。
圖像縮放 cv2.resize(); 圖像平移 cv2.warpAffine(); 圖像旋轉 cv2.getRotationMatrix2D(); 圖像轉置 cv2.transpose(); 圖像鏡像 cv2.flip(); 圖像重映射 cv2.remap()。
非線性濾波:中值濾波、雙邊濾波,
方框濾波 cv2.boxFilter(); 均值濾波 cv2.blur(); 高斯濾波 cv2.GaussianBlur(); 中值濾波 cv2.medianBlur(); 雙邊濾波 cv2.bilateralFilter()。
固定閾值:cv2.threshold(); 自適應閾值:cv2.adaptiveThreshold()。
消除噪聲; 分割獨立元素或連接相鄰元素; 尋找圖像中的明顯極大值、極小值區域; 求圖像的梯度;
膨脹 cv2.dilate(); 腐蝕 cv2.erode()。
cv2.morphologyEx() 函數進行操作。濾波:濾出噪聲対檢測邊緣的影響 ; 增強:可以將像素鄰域強度變化凸顯出來—梯度算子 ; 檢測:閾值方法確定邊緣 ;
Canny 算子,Canny 邊緣檢測函數 cv2.Canny(); Sobel 算子,Sobel 邊緣檢測函數 cv2.Sobel(); Scharr 算子,Scharr 邊緣檢測函數 cv2.Scahrr() ; Laplacian 算子,Laplacian 邊緣檢測函數 cv2.Laplacian()。
標準霍夫變換、多尺度霍夫變換 cv2.HoughLines() ; 累計概率霍夫變換 cv2.HoughLinesP() ; 霍夫圓變換 cv2.HoughCricles() 。
matplotlib 模塊對直方圖進行繪制。計算直方圖用到的函數是 cv2.calcHist()。直方圖均衡化 cv2.equalizeHist(); 直方圖對比 cv2.compareHist(); 反向投影 cv2.calcBackProject()。
模板匹配 cv2.matchTemplate(); 矩陣歸一化 cv2.normalize(); 尋找最值 cv2.minMaxLoc()。
查找輪廓 cv2.findContours(); 繪制輪廓 cv2.drawContours() 。
尋找凸包 cv2.convexHull() 與 凸性檢測 cv2.isContourConvex(); 輪廓外接矩形 cv2.boundingRect(); 輪廓最小外接矩形 cv2.minAreaRect(); 輪廓最小外接圓 cv2.minEnclosingCircle(); 輪廓橢圓擬合 cv2.fitEllipse(); 逼近多邊形曲線 cv2.approxPolyDP(); 計算輪廓面積 cv2.contourArea(); 計算輪廓長度 cv2.arcLength(); 計算點與輪廓的距離及位置關系 cv2.pointPolygonTest(); 形狀匹配 cv2.matchShapes()。
cv2.watershed() 。cv2.inpaint(),學習完畢可以嘗試人像祛斑應用。GrabCut 算法 cv2.grabCut(); 漫水填充算法 cv2.floodFill(); Harris 角點檢測 cv2.cornerHarris(); Shi-Tomasi 角點檢測 cv2.goodFeaturesToTrack(); 亞像素角點檢測 cv2.cornerSubPix()。
“FAST” FastFeatureDetector; “STAR” StarFeatureDetector; “SIFT” SIFT(nonfree module) Opencv3 移除,需調用 xfeature2d 庫; “SURF” SURF(nonfree module) Opencv3 移除,需調用 xfeature2d 庫; “ORB” ORB Opencv3 移除,需調用 xfeature2d 庫; “MSER” MSER; “GFTT” GoodFeaturesToTrackDetector; “HARRIS” (配合 Harris detector); “Dense” DenseFeatureDetector; “SimpleBlob” SimpleBlobDetector。
meanShift, camShift,粒子濾波, 光流法 等。meanShift 跟蹤算法 cv2.meanShift(); CamShift 跟蹤算法 cv2.CamShift()。
人臉檢測:從圖像中找出人臉位置并標識; 人臉識別:從定位到的人臉區域區分出人的姓名或其它信息; 機器學習。
———————End———————
你可以添加微信:rtthread2020 為好友,注明:公司+姓名,拉進RT-Thread官方微信交流群!

↓點擊閱讀原文
愛我就請給我在看
原文標題:【AI簡報第20230217期】超越GPT 3.5的小模型來了!AI網戀詐騙時代開啟
文章出處:【微信公眾號:RTThread物聯網操作系統】歡迎添加關注!文章轉載請注明出處。
-
RT-Thread
+關注
關注
32文章
1364瀏覽量
41470
原文標題:【AI簡報第20230217期】超越GPT 3.5的小模型來了!AI網戀詐騙時代開啟
文章出處:【微信號:RTThread,微信公眾號:RTThread物聯網操作系統】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
首創開源架構,天璣AI開發套件讓端側AI模型接入得心應手

當我問DeepSeek AI爆發時代的FPGA是否重要?答案是......
AI賦能邊緣網關:開啟智能時代的新藍海
AI時代算力的重要性及現狀:平衡發展與優化配置的挑戰
名單公布!【書籍評測活動NO.49】大模型啟示錄:一本AI應用百科全書
AI大模型在自然語言處理中的應用
GAP!你對AI大模型到底了解多少?
OpenAI 推出 GPT-4o mini 取代GPT 3.5 性能超越GPT 4 而且更快 API KEY更便宜

Anthropic發布最新AI模型Claude 3.5,引入Artifacts新功能
Anthropic 發布Claude 3.5 Sonnet模型運行速度是Claude 3 Opus的兩倍





 工商網監
工商網監
評論