") LLM風(fēng)口背后,ChatGPT的成本問(wèn)題
LLM風(fēng)口背后,ChatGPT的成本問(wèn)題
趁著ChatGPT這一熱門(mén)話題還未消退,我們來(lái)聊一聊這類大規(guī)模語(yǔ)言模型(LLM)或通用人工智能(AGI)背后的細(xì)節(jié)。畢竟目前相關(guān)的概念股跟風(fēng)大漲,但還是有不少人在持觀望態(tài)度。無(wú)論是國(guó)外還是國(guó)內(nèi),有沒(méi)有可能做出下一個(gè)ChatGPT?以及打造這樣一個(gè)模型所需的研發(fā)成本和運(yùn)營(yíng)成本究竟是多少。
ChatGPT背后的成本,以及GPU廠商等候多時(shí)的增長(zhǎng)點(diǎn)
首先,ChatGPT是OpenAI預(yù)訓(xùn)練的對(duì)話模型,除去訓(xùn)練本身所需的硬件與時(shí)間成本外,運(yùn)營(yíng)時(shí)的推理成本也要算在其中。根據(jù)UBS分析師Timothy Arcuri的觀點(diǎn),ChatGPT使用到了至少1萬(wàn)塊英偉達(dá)的GPU來(lái)運(yùn)營(yíng)這一模型。不過(guò)這還是相對(duì)較為保守的數(shù)據(jù),根據(jù)Semianalysis分析師Dylan Patel對(duì)模型參數(shù)、日活躍用戶數(shù)以及硬件利用率等種種因素的分析,他粗略估計(jì)OpenAI需要用到3617個(gè)HGX A100服務(wù)器來(lái)維持ChatGPT的運(yùn)轉(zhuǎn)。

HGX A100 / 英偉達(dá)
需要注意的是,該分析中的HGX A100服務(wù)器是8塊A100 SXM的定制化模塊,并非DGX A100這樣集成了AMD CPU的標(biāo)準(zhǔn)服務(wù)器模塊,也就是說(shuō)共需28936塊英偉達(dá)A100 GPU。且不說(shuō)A100本身就高昂的售價(jià),更何況現(xiàn)在還有一定的溢價(jià)。一張40GB的A100 PCIe卡,目前在亞馬遜上的單價(jià)為8000多美元,而80GB的A100 PCIe卡價(jià)格在15000美元左右浮動(dòng)。
由此估算,運(yùn)行ChatGPT的前期設(shè)備投入成本少說(shuō)也有2.3億美元,這其中還沒(méi)算進(jìn)CPU、內(nèi)存、硬盤(pán)和網(wǎng)關(guān)等設(shè)備的硬件成本。所有GPU同時(shí)運(yùn)轉(zhuǎn)時(shí)的TDP功耗達(dá)到7234kW。按照美國(guó)商用電價(jià)來(lái)計(jì)算的話,哪怕是每日運(yùn)轉(zhuǎn)單由GPU帶來(lái)的電費(fèi)也至少要兩萬(wàn)美元以上。這樣的設(shè)備成本除非是微軟、谷歌、亞馬遜這樣本就手握大把服務(wù)器硬件資源的廠商,否則很難支撐這一模型的日常運(yùn)轉(zhuǎn)。
接著我們?cè)購(gòu)拿看尾樵兊耐评沓杀具@個(gè)角度來(lái)看,如果只負(fù)責(zé)在服務(wù)器上部署ChatGPT的OpenAI無(wú)需考慮設(shè)備購(gòu)入成本,而是只考慮GPU云服務(wù)器的定價(jià)。根據(jù)Dylan Patel的估算,ChatGPT每次查詢的成本為0.36美分,約合2.4分人民幣,每天在硬件推理上的成本也高達(dá)70萬(wàn)美元。由此來(lái)看,無(wú)論是OpenAI現(xiàn)在免費(fèi)提供的ChatGPT,還是微軟在Bing上啟用的ChatGPT,其實(shí)都是在大把燒錢(qián)。
要知道,現(xiàn)在還只是用到了ChatGPT這一文本語(yǔ)言模型,根據(jù)OpenAI的CEO Sam Altman的說(shuō)法,他們的AI視頻模型也在準(zhǔn)備當(dāng)中。而要想打造更復(fù)雜的視頻模型,勢(shì)必會(huì)對(duì)GPU算力提出更高的要求。
未來(lái)的硬件成本會(huì)更低嗎?
對(duì)于任何一個(gè)想要運(yùn)行ChatGPT這類服務(wù)的廠商,打造這樣一款應(yīng)用都要付出不小的成本,所以現(xiàn)階段還是微軟、谷歌之類的巨頭相互博弈。但Sam Altman也表示,隨著越來(lái)越多的競(jìng)爭(zhēng)出現(xiàn),毋庸置疑會(huì)把硬件成本壓低,也會(huì)把每個(gè)Token的定價(jià)壓低。
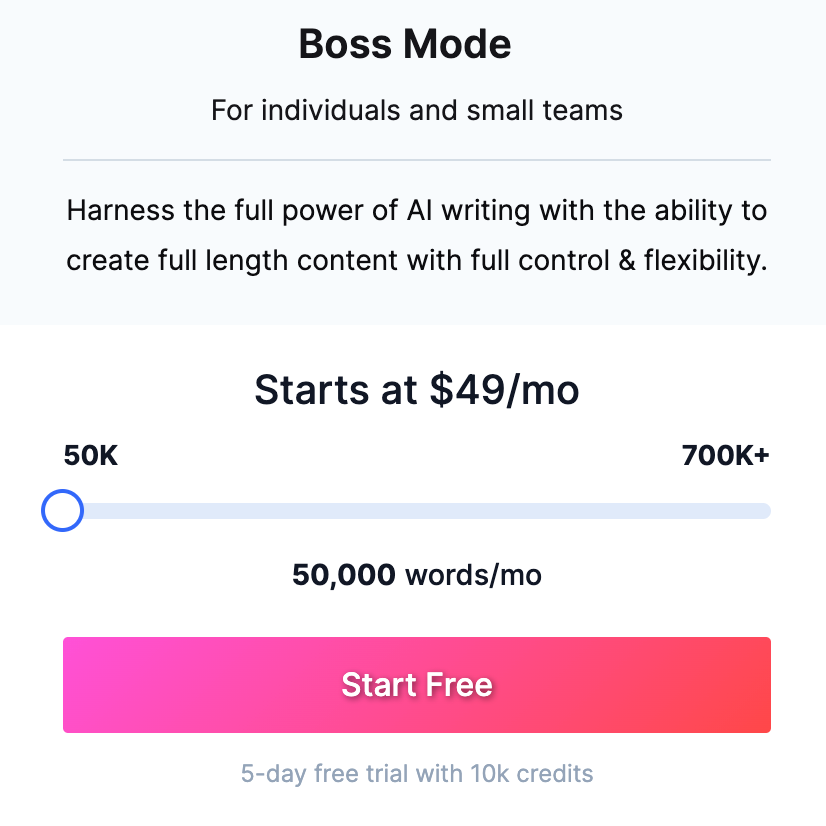
Jasper AI寫(xiě)作工具的定價(jià) / Jasper.ai
大家可以參照一下其他利用OpenAI的GPT-3的AI工具,比如Jasper。Jasper作為一個(gè)人工智能寫(xiě)作軟件,每月需要繳納50美元,才能享受5萬(wàn)字的寫(xiě)作字?jǐn)?shù)上限。而反觀ChatGPT,哪怕是目前的免費(fèi)版也能幫你寫(xiě)就長(zhǎng)篇故事了。而這些工具鼓吹的多種模板,在ChatGPT中也只是換一種問(wèn)法而已。
Sam Altman認(rèn)為會(huì)有更多的玩家入局AGI,如此一來(lái)ChatGPT這種類型的服務(wù)會(huì)出現(xiàn)在更多的產(chǎn)品和應(yīng)用中,而不再只是作為大廠的附庸,比如只在微軟的Bing、Office中大規(guī)模使用等,這也是OpenAI還考慮授權(quán)給其他公司的原因。
不過(guò)如果依照谷歌的訪問(wèn)和搜索量來(lái)部署ChatGPT或Bard這樣類似模型的話,所需的成本必定要遠(yuǎn)遠(yuǎn)高于Bing,畢竟谷歌依然是目前國(guó)際領(lǐng)先的搜索引擎。
如果谷歌用其TPU之類的專用硬件來(lái)完成LLM的訓(xùn)練與推理,其成本必然顯著低于GPU這類通用硬件的,畢竟TPU這類ASIC芯片在量產(chǎn)成本和運(yùn)行功耗上都有著得天獨(dú)厚的優(yōu)勢(shì)。
但谷歌如果使用專用硬件的話,可能會(huì)存在強(qiáng)制綁定的問(wèn)題,哪怕谷歌選擇公開(kāi)TPU商業(yè)運(yùn)營(yíng),如果想用集成Bard的合作客戶也基本與谷歌云綁定了,就像現(xiàn)在的ChatGPT與微軟Azure強(qiáng)制綁定一樣。而且如果Bard出現(xiàn)算法路線上的大變動(dòng),TPU這種ASIC方案很難再對(duì)其進(jìn)行針對(duì)性優(yōu)化。
由此可以看出,雖然大小入局者眾多,但真正落地、可大規(guī)模使用且還算好用的產(chǎn)品還是只有ChatGPT一個(gè),要想等到行業(yè)內(nèi)卷壓低成本,可能還得等上很長(zhǎng)一段時(shí)間。
ChatGPT如何實(shí)現(xiàn)盈利?
微軟高調(diào)宣布與OpenAI合作,并將ChatGPT融入Bing等一系列微軟產(chǎn)品中,這已經(jīng)不是什么新聞了。但其實(shí)這樣的合作關(guān)系昭示了ChatGPT的一種盈利方式,那就是授權(quán)。除了微軟這種深度合作的廠商以外,其他應(yīng)用開(kāi)發(fā)商也可以采用授權(quán)的方式,將ChatGPT集成到自己的產(chǎn)品中去。
不過(guò)Sam Altman在接受外媒采訪時(shí)表示,他們目前在授權(quán)上的合作還并不多。由此猜測(cè),要么是此類授權(quán)費(fèi)用昂貴,要么就是缺少成熟的產(chǎn)品形態(tài)來(lái)應(yīng)用這一技術(shù),畢竟當(dāng)下還算強(qiáng)相關(guān)的應(yīng)用也只有搜索引擎、寫(xiě)作工具以及AI助手等。再說(shuō),對(duì)于感興趣想嘗鮮的廠商來(lái)說(shuō),直接接入OpenAI的API或許價(jià)格反倒更低。
另一種盈利方式,也是現(xiàn)在最流行且已被普遍接受的收費(fèi)模式,訂閱制。2月1日,OpenAI正式推出了20美元一個(gè)月的ChatGPT Plus,提供高峰時(shí)期的訪問(wèn)、更快的響應(yīng)速度以及新功能和改進(jìn)的搶先體驗(yàn)。
結(jié)語(yǔ)
總的來(lái)說(shuō),ChatGPT這類AGI作為元宇宙之后的又一大風(fēng)口,激發(fā)了一股初創(chuàng)公司入局LLM的熱潮。但從客觀來(lái)看,對(duì)于這些初創(chuàng)公司來(lái)說(shuō),他們打從一開(kāi)始根本不需要考慮市場(chǎng)風(fēng)險(xiǎn),比如這會(huì)不會(huì)是個(gè)偽需求。他們更應(yīng)該擔(dān)心的應(yīng)該是技術(shù)風(fēng)險(xiǎn),也就是究竟有沒(méi)有這個(gè)實(shí)力和資本去打造一個(gè)可用的LLM。
ChatGPT背后的成本,以及GPU廠商等候多時(shí)的增長(zhǎng)點(diǎn)
首先,ChatGPT是OpenAI預(yù)訓(xùn)練的對(duì)話模型,除去訓(xùn)練本身所需的硬件與時(shí)間成本外,運(yùn)營(yíng)時(shí)的推理成本也要算在其中。根據(jù)UBS分析師Timothy Arcuri的觀點(diǎn),ChatGPT使用到了至少1萬(wàn)塊英偉達(dá)的GPU來(lái)運(yùn)營(yíng)這一模型。不過(guò)這還是相對(duì)較為保守的數(shù)據(jù),根據(jù)Semianalysis分析師Dylan Patel對(duì)模型參數(shù)、日活躍用戶數(shù)以及硬件利用率等種種因素的分析,他粗略估計(jì)OpenAI需要用到3617個(gè)HGX A100服務(wù)器來(lái)維持ChatGPT的運(yùn)轉(zhuǎn)。
HGX A100 / 英偉達(dá)
需要注意的是,該分析中的HGX A100服務(wù)器是8塊A100 SXM的定制化模塊,并非DGX A100這樣集成了AMD CPU的標(biāo)準(zhǔn)服務(wù)器模塊,也就是說(shuō)共需28936塊英偉達(dá)A100 GPU。且不說(shuō)A100本身就高昂的售價(jià),更何況現(xiàn)在還有一定的溢價(jià)。一張40GB的A100 PCIe卡,目前在亞馬遜上的單價(jià)為8000多美元,而80GB的A100 PCIe卡價(jià)格在15000美元左右浮動(dòng)。
由此估算,運(yùn)行ChatGPT的前期設(shè)備投入成本少說(shuō)也有2.3億美元,這其中還沒(méi)算進(jìn)CPU、內(nèi)存、硬盤(pán)和網(wǎng)關(guān)等設(shè)備的硬件成本。所有GPU同時(shí)運(yùn)轉(zhuǎn)時(shí)的TDP功耗達(dá)到7234kW。按照美國(guó)商用電價(jià)來(lái)計(jì)算的話,哪怕是每日運(yùn)轉(zhuǎn)單由GPU帶來(lái)的電費(fèi)也至少要兩萬(wàn)美元以上。這樣的設(shè)備成本除非是微軟、谷歌、亞馬遜這樣本就手握大把服務(wù)器硬件資源的廠商,否則很難支撐這一模型的日常運(yùn)轉(zhuǎn)。
接著我們?cè)購(gòu)拿看尾樵兊耐评沓杀具@個(gè)角度來(lái)看,如果只負(fù)責(zé)在服務(wù)器上部署ChatGPT的OpenAI無(wú)需考慮設(shè)備購(gòu)入成本,而是只考慮GPU云服務(wù)器的定價(jià)。根據(jù)Dylan Patel的估算,ChatGPT每次查詢的成本為0.36美分,約合2.4分人民幣,每天在硬件推理上的成本也高達(dá)70萬(wàn)美元。由此來(lái)看,無(wú)論是OpenAI現(xiàn)在免費(fèi)提供的ChatGPT,還是微軟在Bing上啟用的ChatGPT,其實(shí)都是在大把燒錢(qián)。
要知道,現(xiàn)在還只是用到了ChatGPT這一文本語(yǔ)言模型,根據(jù)OpenAI的CEO Sam Altman的說(shuō)法,他們的AI視頻模型也在準(zhǔn)備當(dāng)中。而要想打造更復(fù)雜的視頻模型,勢(shì)必會(huì)對(duì)GPU算力提出更高的要求。
未來(lái)的硬件成本會(huì)更低嗎?
對(duì)于任何一個(gè)想要運(yùn)行ChatGPT這類服務(wù)的廠商,打造這樣一款應(yīng)用都要付出不小的成本,所以現(xiàn)階段還是微軟、谷歌之類的巨頭相互博弈。但Sam Altman也表示,隨著越來(lái)越多的競(jìng)爭(zhēng)出現(xiàn),毋庸置疑會(huì)把硬件成本壓低,也會(huì)把每個(gè)Token的定價(jià)壓低。
Jasper AI寫(xiě)作工具的定價(jià) / Jasper.ai
大家可以參照一下其他利用OpenAI的GPT-3的AI工具,比如Jasper。Jasper作為一個(gè)人工智能寫(xiě)作軟件,每月需要繳納50美元,才能享受5萬(wàn)字的寫(xiě)作字?jǐn)?shù)上限。而反觀ChatGPT,哪怕是目前的免費(fèi)版也能幫你寫(xiě)就長(zhǎng)篇故事了。而這些工具鼓吹的多種模板,在ChatGPT中也只是換一種問(wèn)法而已。
Sam Altman認(rèn)為會(huì)有更多的玩家入局AGI,如此一來(lái)ChatGPT這種類型的服務(wù)會(huì)出現(xiàn)在更多的產(chǎn)品和應(yīng)用中,而不再只是作為大廠的附庸,比如只在微軟的Bing、Office中大規(guī)模使用等,這也是OpenAI還考慮授權(quán)給其他公司的原因。
不過(guò)如果依照谷歌的訪問(wèn)和搜索量來(lái)部署ChatGPT或Bard這樣類似模型的話,所需的成本必定要遠(yuǎn)遠(yuǎn)高于Bing,畢竟谷歌依然是目前國(guó)際領(lǐng)先的搜索引擎。
如果谷歌用其TPU之類的專用硬件來(lái)完成LLM的訓(xùn)練與推理,其成本必然顯著低于GPU這類通用硬件的,畢竟TPU這類ASIC芯片在量產(chǎn)成本和運(yùn)行功耗上都有著得天獨(dú)厚的優(yōu)勢(shì)。
但谷歌如果使用專用硬件的話,可能會(huì)存在強(qiáng)制綁定的問(wèn)題,哪怕谷歌選擇公開(kāi)TPU商業(yè)運(yùn)營(yíng),如果想用集成Bard的合作客戶也基本與谷歌云綁定了,就像現(xiàn)在的ChatGPT與微軟Azure強(qiáng)制綁定一樣。而且如果Bard出現(xiàn)算法路線上的大變動(dòng),TPU這種ASIC方案很難再對(duì)其進(jìn)行針對(duì)性優(yōu)化。
由此可以看出,雖然大小入局者眾多,但真正落地、可大規(guī)模使用且還算好用的產(chǎn)品還是只有ChatGPT一個(gè),要想等到行業(yè)內(nèi)卷壓低成本,可能還得等上很長(zhǎng)一段時(shí)間。
ChatGPT如何實(shí)現(xiàn)盈利?
微軟高調(diào)宣布與OpenAI合作,并將ChatGPT融入Bing等一系列微軟產(chǎn)品中,這已經(jīng)不是什么新聞了。但其實(shí)這樣的合作關(guān)系昭示了ChatGPT的一種盈利方式,那就是授權(quán)。除了微軟這種深度合作的廠商以外,其他應(yīng)用開(kāi)發(fā)商也可以采用授權(quán)的方式,將ChatGPT集成到自己的產(chǎn)品中去。
不過(guò)Sam Altman在接受外媒采訪時(shí)表示,他們目前在授權(quán)上的合作還并不多。由此猜測(cè),要么是此類授權(quán)費(fèi)用昂貴,要么就是缺少成熟的產(chǎn)品形態(tài)來(lái)應(yīng)用這一技術(shù),畢竟當(dāng)下還算強(qiáng)相關(guān)的應(yīng)用也只有搜索引擎、寫(xiě)作工具以及AI助手等。再說(shuō),對(duì)于感興趣想嘗鮮的廠商來(lái)說(shuō),直接接入OpenAI的API或許價(jià)格反倒更低。
另一種盈利方式,也是現(xiàn)在最流行且已被普遍接受的收費(fèi)模式,訂閱制。2月1日,OpenAI正式推出了20美元一個(gè)月的ChatGPT Plus,提供高峰時(shí)期的訪問(wèn)、更快的響應(yīng)速度以及新功能和改進(jìn)的搶先體驗(yàn)。
結(jié)語(yǔ)
總的來(lái)說(shuō),ChatGPT這類AGI作為元宇宙之后的又一大風(fēng)口,激發(fā)了一股初創(chuàng)公司入局LLM的熱潮。但從客觀來(lái)看,對(duì)于這些初創(chuàng)公司來(lái)說(shuō),他們打從一開(kāi)始根本不需要考慮市場(chǎng)風(fēng)險(xiǎn),比如這會(huì)不會(huì)是個(gè)偽需求。他們更應(yīng)該擔(dān)心的應(yīng)該是技術(shù)風(fēng)險(xiǎn),也就是究竟有沒(méi)有這個(gè)實(shí)力和資本去打造一個(gè)可用的LLM。
聲明:本文內(nèi)容及配圖由入駐作者撰寫(xiě)或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點(diǎn)僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場(chǎng)。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問(wèn)題,請(qǐng)聯(lián)系本站處理。
舉報(bào)投訴
-
ChatGPT
+關(guān)注
關(guān)注
29文章
1585瀏覽量
8743 -
LLM
+關(guān)注
關(guān)注
1文章
318瀏覽量
659
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
熱點(diǎn)推薦
小白學(xué)大模型:構(gòu)建LLM的關(guān)鍵步驟
隨著大規(guī)模語(yǔ)言模型(LLM)在性能、成本和應(yīng)用前景上的快速發(fā)展,越來(lái)越多的團(tuán)隊(duì)開(kāi)始探索如何自主訓(xùn)練LLM模型。然而,是否從零開(kāi)始訓(xùn)練一個(gè)LLM,并非每個(gè)組織都適合。本文將根據(jù)不同的需求

什么是LLM?LLM在自然語(yǔ)言處理中的應(yīng)用
隨著人工智能技術(shù)的飛速發(fā)展,自然語(yǔ)言處理(NLP)領(lǐng)域迎來(lái)了革命性的進(jìn)步。其中,大型語(yǔ)言模型(LLM)的出現(xiàn),標(biāo)志著我們對(duì)語(yǔ)言理解能力的一次飛躍。LLM通過(guò)深度學(xué)習(xí)和海量數(shù)據(jù)訓(xùn)練,使得機(jī)器能夠以前
如何訓(xùn)練自己的LLM模型
訓(xùn)練自己的大型語(yǔ)言模型(LLM)是一個(gè)復(fù)雜且資源密集的過(guò)程,涉及到大量的數(shù)據(jù)、計(jì)算資源和專業(yè)知識(shí)。以下是訓(xùn)練LLM模型的一般步驟,以及一些關(guān)鍵考慮因素: 定義目標(biāo)和需求 : 確定你的LLM將用
LLM技術(shù)對(duì)人工智能發(fā)展的影響
隨著人工智能技術(shù)的飛速發(fā)展,大型語(yǔ)言模型(LLM)技術(shù)已經(jīng)成為推動(dòng)AI領(lǐng)域進(jìn)步的關(guān)鍵力量。LLM技術(shù)通過(guò)深度學(xué)習(xí)和自然語(yǔ)言處理技術(shù),使得機(jī)器能夠理解和生成自然語(yǔ)言,極大地?cái)U(kuò)展了人工智能的應(yīng)用范圍
LLM和傳統(tǒng)機(jī)器學(xué)習(xí)的區(qū)別
在人工智能領(lǐng)域,LLM(Large Language Models,大型語(yǔ)言模型)和傳統(tǒng)機(jī)器學(xué)習(xí)是兩種不同的技術(shù)路徑,它們?cè)谔幚頂?shù)據(jù)、模型結(jié)構(gòu)、應(yīng)用場(chǎng)景等方面有著顯著的差異。 1. 模型結(jié)構(gòu)
端到端InfiniBand網(wǎng)絡(luò)解決LLM訓(xùn)練瓶頸
ChatGPT對(duì)技術(shù)的影響引發(fā)了對(duì)人工智能未來(lái)的預(yù)測(cè),尤其是多模態(tài)技術(shù)的關(guān)注。OpenAI推出了具有突破性的多模態(tài)模型GPT-4,使各個(gè)領(lǐng)域取得了顯著的發(fā)展。 這些AI進(jìn)步是通過(guò)大規(guī)模模型訓(xùn)練實(shí)現(xiàn)

ChatGPT背后的AI背景、技術(shù)門(mén)道和商業(yè)應(yīng)用
作者:京東科技 李俊兵 各位看官好,我是球神(江湖代號(hào))。 自去年11月30日ChatGPT問(wèn)世以來(lái),迅速爆火出圈。 起初我依然以為這是和當(dāng)年Transformer, Bert一樣的“熱點(diǎn)”模型

大模型LLM與ChatGPT的技術(shù)原理
在人工智能領(lǐng)域,大模型(Large Language Model, LLM)和ChatGPT等自然語(yǔ)言處理技術(shù)(Natural Language Processing, NLP)正逐步改變著人類
llm模型有哪些格式
LLM(Large Language Model,大型語(yǔ)言模型)是一種深度學(xué)習(xí)模型,主要用于處理自然語(yǔ)言處理(NLP)任務(wù)。LLM模型的格式多種多樣,以下是一些常見(jiàn)的LLM模型格式
llm模型和chatGPT的區(qū)別
,有許多不同的LLM模型,如BERT、GPT、T5等。 ChatGPT是一種基于GPT(Generative Pre-trained Transformer)模型的聊天機(jī)器人。GPT模型是一種
LLM模型的應(yīng)用領(lǐng)域
在本文中,我們將深入探討LLM(Large Language Model,大型語(yǔ)言模型)的應(yīng)用領(lǐng)域。LLM是一種基于深度學(xué)習(xí)的人工智能技術(shù),它能夠理解和生成自然語(yǔ)言文本。近年來(lái),隨著計(jì)算能力的提高
什么是LLM?LLM的工作原理和結(jié)構(gòu)
隨著人工智能技術(shù)的飛速發(fā)展,大型語(yǔ)言模型(Large Language Model,簡(jiǎn)稱LLM)逐漸成為自然語(yǔ)言處理(NLP)領(lǐng)域的研究熱點(diǎn)。LLM以其強(qiáng)大的文本生成、理解和推理能力,在文本
使用espbox lite進(jìn)行chatgpt_demo的燒錄報(bào)錯(cuò)是什么原因?
我使用espbox lite進(jìn)行chatgpt_demo的燒錄
我的idf是v5.1release版本的,espbox是master版本的
在編譯時(shí)似乎沒(méi)有什么問(wèn)題
在燒錄時(shí)報(bào)錯(cuò)
請(qǐng)問(wèn)這是什么原因
發(fā)表于 06-11 08:45
大語(yǔ)言模型(LLM)快速理解
自2022年,ChatGPT發(fā)布之后,大語(yǔ)言模型(LargeLanguageModel),簡(jiǎn)稱LLM掀起了一波狂潮。作為學(xué)習(xí)理解LLM的開(kāi)始,先來(lái)整體理解一下大語(yǔ)言模型。一、發(fā)展歷史大語(yǔ)言模型的發(fā)展
OpenAI 深夜拋出王炸 “ChatGPT- 4o”, “她” 來(lái)了
當(dāng)?shù)貢r(shí)間5月13日OpenAI推出ChatGPT-4o,代表了人工智能向前邁出的一大步。在GPT-4turbo的強(qiáng)大基礎(chǔ)上,這種迭代擁有顯著的改進(jìn)。在發(fā)布會(huì)的演示中,OpenAI展示該模型的高級(jí)
發(fā)表于 05-27 15:43





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論