") 國(guó)內(nèi)最大自動(dòng)駕駛智算中心發(fā)布,為何車(chē)企紛紛自建智算中心?
國(guó)內(nèi)最大自動(dòng)駕駛智算中心發(fā)布,為何車(chē)企紛紛自建智算中心?
電子發(fā)燒友網(wǎng)報(bào)道(文/李彎彎)前不久,毫末智行與火山引擎共同發(fā)布了中國(guó)自動(dòng)駕駛行業(yè)最大的智算中心——毫末“雪湖·綠洲”(MANA OASIS)。據(jù)毫末智行CEO顧維灝介紹,MANA OASIS的算力高達(dá)67億億次/秒,存儲(chǔ)帶寬可達(dá)2T/秒,通信帶寬達(dá)到800G/秒,可以為自動(dòng)駕駛技術(shù)的持續(xù)迭代提供充足動(dòng)力。
不僅僅是自動(dòng)駕駛車(chē)自身算力,智算中心也成為車(chē)企和自動(dòng)駕駛公司競(jìng)爭(zhēng)的焦點(diǎn)。眾所周知,自動(dòng)駕駛行業(yè)的領(lǐng)軍企業(yè)特斯拉在幾年前就已經(jīng)建立自己的智算中心,并且還自研芯片以提升效率。國(guó)內(nèi)除了毫末智行,小鵬汽車(chē)在今年8月也宣布已經(jīng)建成自動(dòng)駕駛智算中心。
多方面優(yōu)化,MANA OASIS訓(xùn)練效率提升100倍
結(jié)合自動(dòng)駕駛近十年的發(fā)展歷史,毫末智行認(rèn)為,可以將近十年的自動(dòng)駕駛技術(shù)發(fā)展分成三個(gè)階段:最早的硬件驅(qū)動(dòng)方式,可以稱(chēng)為自動(dòng)駕駛的1.0時(shí)代;最近幾年的軟件驅(qū)動(dòng)方式,可稱(chēng)之為自動(dòng)駕駛的2.0時(shí)代;即將發(fā)生,并將持續(xù)發(fā)展的數(shù)據(jù)驅(qū)動(dòng)方式,是自動(dòng)駕駛的3.0時(shí)代。數(shù)據(jù)驅(qū)動(dòng)也是自動(dòng)駕駛發(fā)展公認(rèn)的方向,而它對(duì)智算中心的要求很高。
因此毫末和火山引擎共同定制了一個(gè)屬于自動(dòng)駕駛的智算中心。具體來(lái)看,在系統(tǒng)架構(gòu)方面,如下圖,左邊是高性能存儲(chǔ),基于高性能并行文件系統(tǒng)VePFS,可以提供高達(dá)2T/s的讀取速度,并且支持百億級(jí)小文件高速讀寫(xiě)。右邊是計(jì)算平臺(tái),提供了充沛的算力,每臺(tái)服務(wù)器配置8個(gè)GPU卡,通過(guò)600G/s的雙向NVSwitch高速互聯(lián),進(jìn)行通信。服務(wù)器之間通過(guò)4張200G帶寬的RDMA網(wǎng)絡(luò)互聯(lián),提供高達(dá)800G/s的網(wǎng)絡(luò)帶寬。
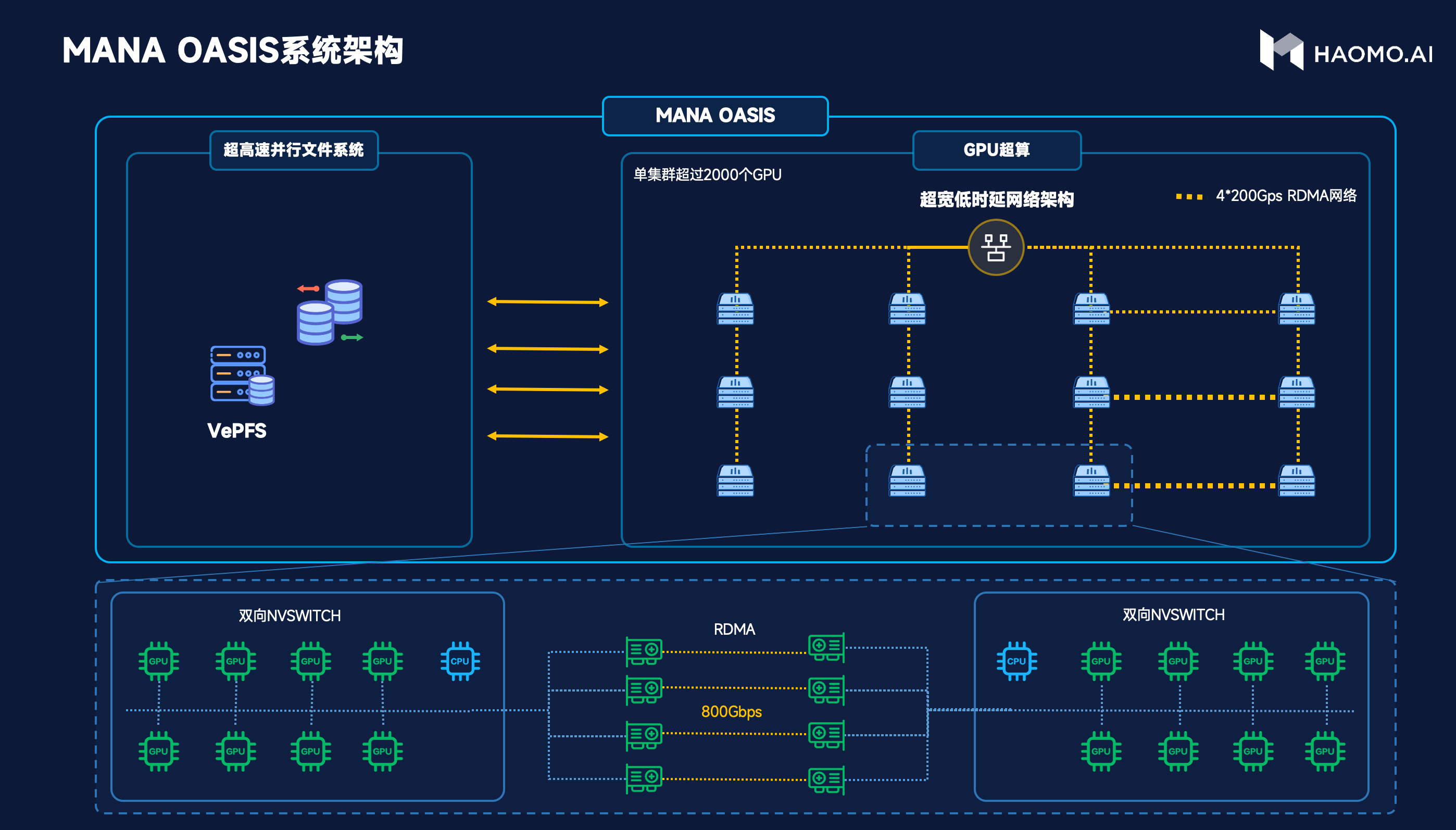
在數(shù)據(jù)管理上,為了充分發(fā)揮智算中心的價(jià)值,讓GPU持續(xù)飽和運(yùn)行,毫末經(jīng)過(guò)2年多研發(fā),建立了全套面向大規(guī)模AI訓(xùn)練的毫末文件系統(tǒng)。在采集端,把數(shù)據(jù)按照訓(xùn)練的要求,以4D Clip為單位組織文件形態(tài);在傳輸端,基于毫末場(chǎng)景庫(kù),對(duì)數(shù)據(jù)進(jìn)行場(chǎng)景化分析,打上各類(lèi)Tag,方便模型基于Tag從不同維度對(duì)數(shù)據(jù)進(jìn)行采樣、分布統(tǒng)計(jì)、語(yǔ)料提取;在訓(xùn)練端,基于分級(jí)存儲(chǔ)理念,把對(duì)象存儲(chǔ)、高性能、顯存充分整合,實(shí)現(xiàn)高容量與高性能并存。
最終實(shí)現(xiàn)了百P數(shù)據(jù)篩選速度提升10倍、百億小文件隨機(jī)讀寫(xiě)延遲小于500us。在毫末文件系統(tǒng)的加持下,消除數(shù)據(jù)瓶頸,GPU利用率從60%提升到接近80%。
在MANA OASIS的訓(xùn)練加速上也做了大量?jī)?yōu)化。大家都知道,transformer大模型的訓(xùn)練成本非常高,訓(xùn)練一個(gè)大模型有時(shí)成本高達(dá)幾千萬(wàn)。毫末在此方向深入研究,借鑒了學(xué)術(shù)界最新的研究成果,基于Sparse MoE,可以根據(jù)計(jì)算特點(diǎn),進(jìn)行稀疏激活,提高計(jì)算效率,實(shí)現(xiàn)單機(jī)8卡就能訓(xùn)練百億參數(shù)大模型的效果。
毫末智算中心也實(shí)現(xiàn)了跨機(jī)共享expert的方法,完成千億參數(shù)規(guī)模大模型的訓(xùn)練,而且訓(xùn)練成本降低到百卡周級(jí)別。在此基礎(chǔ)上,毫末基于自己的業(yè)務(wù)特點(diǎn),設(shè)計(jì)并實(shí)現(xiàn)了業(yè)界領(lǐng)先的多任務(wù)并行訓(xùn)練系統(tǒng),能同時(shí)處理圖片、點(diǎn)云、結(jié)構(gòu)化文本等多種模態(tài)的信息,既保證了模型的稀疏性,又提升了計(jì)算效率。結(jié)合多方面的優(yōu)化,毫末智算中心的訓(xùn)練效率提升了100倍。
為何小鵬、特斯拉等車(chē)企要建立自己的智算中心
除了毫末智行,小鵬汽車(chē)、特斯拉等車(chē)企也已建設(shè)自己的智算中心。今年8月,小鵬汽車(chē)宣布在烏蘭察布建成當(dāng)時(shí)中國(guó)最大的自動(dòng)駕駛智算中心“扶搖”,用于自動(dòng)駕駛模型訓(xùn)練。“扶搖”基于阿里云智能計(jì)算平臺(tái),算力可達(dá)600PFLOPS(每秒浮點(diǎn)運(yùn)算60億億次),將小鵬自動(dòng)駕駛核心模型的訓(xùn)練速度提升了近170倍。
通過(guò)與阿里云合作,“扶搖”以更低成本實(shí)現(xiàn)了更強(qiáng)算力。具體來(lái)看,對(duì)GPU資源進(jìn)行細(xì)粒度切分、調(diào)度,將GPU資源虛擬化利用率提高3倍,支持更多人同時(shí)在線(xiàn)開(kāi)發(fā),效率提升十倍以上。在通訊層面,端對(duì)端通信延遲降低80%至2微秒。
整體計(jì)算效率上,實(shí)現(xiàn)了算力的線(xiàn)性擴(kuò)展。存儲(chǔ)吞吐比業(yè)界20GB/s的普遍水準(zhǔn)提升了40倍,數(shù)據(jù)傳輸能力相當(dāng)于從送快遞的微型面包車(chē),換成了20多米長(zhǎng)的40噸集裝箱重卡。此外,阿里云機(jī)器學(xué)習(xí)平臺(tái)PAI提供了模型訓(xùn)練部署、推理優(yōu)化等AI工程化工具,比開(kāi)源框架訓(xùn)練性能提升30%以上。
“扶搖”支持小鵬自動(dòng)駕駛核心模型的訓(xùn)練時(shí)長(zhǎng)從7天,縮短至1小時(shí)內(nèi),大幅提速近170倍。據(jù)介紹,“扶搖”正用于小鵬城市NGP輔助駕駛系統(tǒng)的算法模型訓(xùn)練。和高速道路相比,城市路段的交通狀況更為復(fù)雜,自動(dòng)駕駛特殊場(chǎng)景的數(shù)據(jù)集規(guī)模增加了上百倍。
早幾年前,特斯拉就已經(jīng)建立了自己的AI計(jì)算中心——Dojo,總計(jì)使用了1.4萬(wàn)個(gè)英偉達(dá)的GPU來(lái)訓(xùn)練AI模型。為了進(jìn)一步提升效率,特斯拉在2021年發(fā)布了自研的AI加速芯片D1,25個(gè)D1封裝在一起組成一個(gè)訓(xùn)練模塊(Training tile),然后再將訓(xùn)練模塊組成一個(gè)機(jī)柜(Dojo ExaPOD)。在今年10月的AI Day上,特斯拉展示了自有AI計(jì)算中心的最新進(jìn)展,用自研的D1芯片打造的計(jì)算設(shè)備能夠提升30%的模型訓(xùn)練效率。
可以看到,車(chē)企和自動(dòng)駕駛公司自建智算中心,能夠在性能上進(jìn)行多方面的優(yōu)化,提升效率。此外在成本上也會(huì)更有利,何小鵬此前談到,對(duì)于智能汽車(chē)公司來(lái)說(shuō),算力成本將會(huì)從今天的億元級(jí)別上升到將來(lái)的十億元級(jí)別。因此,如果持續(xù)使用公有云服務(wù),邊際成本將會(huì)不斷上漲。如果自行組建智算中心,一次性投資約在數(shù)千萬(wàn)到1億元以?xún)?nèi),長(zhǎng)期來(lái)看性?xún)r(jià)比更高。
不僅僅是自動(dòng)駕駛車(chē)自身算力,智算中心也成為車(chē)企和自動(dòng)駕駛公司競(jìng)爭(zhēng)的焦點(diǎn)。眾所周知,自動(dòng)駕駛行業(yè)的領(lǐng)軍企業(yè)特斯拉在幾年前就已經(jīng)建立自己的智算中心,并且還自研芯片以提升效率。國(guó)內(nèi)除了毫末智行,小鵬汽車(chē)在今年8月也宣布已經(jīng)建成自動(dòng)駕駛智算中心。
多方面優(yōu)化,MANA OASIS訓(xùn)練效率提升100倍
結(jié)合自動(dòng)駕駛近十年的發(fā)展歷史,毫末智行認(rèn)為,可以將近十年的自動(dòng)駕駛技術(shù)發(fā)展分成三個(gè)階段:最早的硬件驅(qū)動(dòng)方式,可以稱(chēng)為自動(dòng)駕駛的1.0時(shí)代;最近幾年的軟件驅(qū)動(dòng)方式,可稱(chēng)之為自動(dòng)駕駛的2.0時(shí)代;即將發(fā)生,并將持續(xù)發(fā)展的數(shù)據(jù)驅(qū)動(dòng)方式,是自動(dòng)駕駛的3.0時(shí)代。數(shù)據(jù)驅(qū)動(dòng)也是自動(dòng)駕駛發(fā)展公認(rèn)的方向,而它對(duì)智算中心的要求很高。
因此毫末和火山引擎共同定制了一個(gè)屬于自動(dòng)駕駛的智算中心。具體來(lái)看,在系統(tǒng)架構(gòu)方面,如下圖,左邊是高性能存儲(chǔ),基于高性能并行文件系統(tǒng)VePFS,可以提供高達(dá)2T/s的讀取速度,并且支持百億級(jí)小文件高速讀寫(xiě)。右邊是計(jì)算平臺(tái),提供了充沛的算力,每臺(tái)服務(wù)器配置8個(gè)GPU卡,通過(guò)600G/s的雙向NVSwitch高速互聯(lián),進(jìn)行通信。服務(wù)器之間通過(guò)4張200G帶寬的RDMA網(wǎng)絡(luò)互聯(lián),提供高達(dá)800G/s的網(wǎng)絡(luò)帶寬。
在數(shù)據(jù)管理上,為了充分發(fā)揮智算中心的價(jià)值,讓GPU持續(xù)飽和運(yùn)行,毫末經(jīng)過(guò)2年多研發(fā),建立了全套面向大規(guī)模AI訓(xùn)練的毫末文件系統(tǒng)。在采集端,把數(shù)據(jù)按照訓(xùn)練的要求,以4D Clip為單位組織文件形態(tài);在傳輸端,基于毫末場(chǎng)景庫(kù),對(duì)數(shù)據(jù)進(jìn)行場(chǎng)景化分析,打上各類(lèi)Tag,方便模型基于Tag從不同維度對(duì)數(shù)據(jù)進(jìn)行采樣、分布統(tǒng)計(jì)、語(yǔ)料提取;在訓(xùn)練端,基于分級(jí)存儲(chǔ)理念,把對(duì)象存儲(chǔ)、高性能、顯存充分整合,實(shí)現(xiàn)高容量與高性能并存。
最終實(shí)現(xiàn)了百P數(shù)據(jù)篩選速度提升10倍、百億小文件隨機(jī)讀寫(xiě)延遲小于500us。在毫末文件系統(tǒng)的加持下,消除數(shù)據(jù)瓶頸,GPU利用率從60%提升到接近80%。
在MANA OASIS的訓(xùn)練加速上也做了大量?jī)?yōu)化。大家都知道,transformer大模型的訓(xùn)練成本非常高,訓(xùn)練一個(gè)大模型有時(shí)成本高達(dá)幾千萬(wàn)。毫末在此方向深入研究,借鑒了學(xué)術(shù)界最新的研究成果,基于Sparse MoE,可以根據(jù)計(jì)算特點(diǎn),進(jìn)行稀疏激活,提高計(jì)算效率,實(shí)現(xiàn)單機(jī)8卡就能訓(xùn)練百億參數(shù)大模型的效果。
毫末智算中心也實(shí)現(xiàn)了跨機(jī)共享expert的方法,完成千億參數(shù)規(guī)模大模型的訓(xùn)練,而且訓(xùn)練成本降低到百卡周級(jí)別。在此基礎(chǔ)上,毫末基于自己的業(yè)務(wù)特點(diǎn),設(shè)計(jì)并實(shí)現(xiàn)了業(yè)界領(lǐng)先的多任務(wù)并行訓(xùn)練系統(tǒng),能同時(shí)處理圖片、點(diǎn)云、結(jié)構(gòu)化文本等多種模態(tài)的信息,既保證了模型的稀疏性,又提升了計(jì)算效率。結(jié)合多方面的優(yōu)化,毫末智算中心的訓(xùn)練效率提升了100倍。
為何小鵬、特斯拉等車(chē)企要建立自己的智算中心
除了毫末智行,小鵬汽車(chē)、特斯拉等車(chē)企也已建設(shè)自己的智算中心。今年8月,小鵬汽車(chē)宣布在烏蘭察布建成當(dāng)時(shí)中國(guó)最大的自動(dòng)駕駛智算中心“扶搖”,用于自動(dòng)駕駛模型訓(xùn)練。“扶搖”基于阿里云智能計(jì)算平臺(tái),算力可達(dá)600PFLOPS(每秒浮點(diǎn)運(yùn)算60億億次),將小鵬自動(dòng)駕駛核心模型的訓(xùn)練速度提升了近170倍。
通過(guò)與阿里云合作,“扶搖”以更低成本實(shí)現(xiàn)了更強(qiáng)算力。具體來(lái)看,對(duì)GPU資源進(jìn)行細(xì)粒度切分、調(diào)度,將GPU資源虛擬化利用率提高3倍,支持更多人同時(shí)在線(xiàn)開(kāi)發(fā),效率提升十倍以上。在通訊層面,端對(duì)端通信延遲降低80%至2微秒。
整體計(jì)算效率上,實(shí)現(xiàn)了算力的線(xiàn)性擴(kuò)展。存儲(chǔ)吞吐比業(yè)界20GB/s的普遍水準(zhǔn)提升了40倍,數(shù)據(jù)傳輸能力相當(dāng)于從送快遞的微型面包車(chē),換成了20多米長(zhǎng)的40噸集裝箱重卡。此外,阿里云機(jī)器學(xué)習(xí)平臺(tái)PAI提供了模型訓(xùn)練部署、推理優(yōu)化等AI工程化工具,比開(kāi)源框架訓(xùn)練性能提升30%以上。
“扶搖”支持小鵬自動(dòng)駕駛核心模型的訓(xùn)練時(shí)長(zhǎng)從7天,縮短至1小時(shí)內(nèi),大幅提速近170倍。據(jù)介紹,“扶搖”正用于小鵬城市NGP輔助駕駛系統(tǒng)的算法模型訓(xùn)練。和高速道路相比,城市路段的交通狀況更為復(fù)雜,自動(dòng)駕駛特殊場(chǎng)景的數(shù)據(jù)集規(guī)模增加了上百倍。
早幾年前,特斯拉就已經(jīng)建立了自己的AI計(jì)算中心——Dojo,總計(jì)使用了1.4萬(wàn)個(gè)英偉達(dá)的GPU來(lái)訓(xùn)練AI模型。為了進(jìn)一步提升效率,特斯拉在2021年發(fā)布了自研的AI加速芯片D1,25個(gè)D1封裝在一起組成一個(gè)訓(xùn)練模塊(Training tile),然后再將訓(xùn)練模塊組成一個(gè)機(jī)柜(Dojo ExaPOD)。在今年10月的AI Day上,特斯拉展示了自有AI計(jì)算中心的最新進(jìn)展,用自研的D1芯片打造的計(jì)算設(shè)備能夠提升30%的模型訓(xùn)練效率。
可以看到,車(chē)企和自動(dòng)駕駛公司自建智算中心,能夠在性能上進(jìn)行多方面的優(yōu)化,提升效率。此外在成本上也會(huì)更有利,何小鵬此前談到,對(duì)于智能汽車(chē)公司來(lái)說(shuō),算力成本將會(huì)從今天的億元級(jí)別上升到將來(lái)的十億元級(jí)別。因此,如果持續(xù)使用公有云服務(wù),邊際成本將會(huì)不斷上漲。如果自行組建智算中心,一次性投資約在數(shù)千萬(wàn)到1億元以?xún)?nèi),長(zhǎng)期來(lái)看性?xún)r(jià)比更高。
聲明:本文內(nèi)容及配圖由入駐作者撰寫(xiě)或者入駐合作網(wǎng)站授權(quán)轉(zhuǎn)載。文章觀點(diǎn)僅代表作者本人,不代表電子發(fā)燒友網(wǎng)立場(chǎng)。文章及其配圖僅供工程師學(xué)習(xí)之用,如有內(nèi)容侵權(quán)或者其他違規(guī)問(wèn)題,請(qǐng)聯(lián)系本站處理。
舉報(bào)投訴
-
自動(dòng)駕駛
+關(guān)注
關(guān)注
788文章
14191瀏覽量
169443 -
智算中心
+關(guān)注
關(guān)注
0文章
87瀏覽量
1978
發(fā)布評(píng)論請(qǐng)先 登錄
相關(guān)推薦
熱點(diǎn)推薦
新能源車(chē)軟件單元測(cè)試深度解析:自動(dòng)駕駛系統(tǒng)視角
的潛在風(fēng)險(xiǎn)增加,尤其是在自動(dòng)駕駛等安全關(guān)鍵系統(tǒng)中。根據(jù)ISO 26262標(biāo)準(zhǔn),自動(dòng)駕駛系統(tǒng)的安全完整性等級(jí)(ASIL-D)要求單點(diǎn)故障率必須低于10^-8/小時(shí),這意味著每小時(shí)的故障概率需控制在億
發(fā)表于 05-12 15:59
信而泰CCL仿真:解鎖AI算力極限,智算中心網(wǎng)絡(luò)性能躍升之道
引言 隨著AI大模型訓(xùn)練和推理需求的爆發(fā)式增長(zhǎng),智算中心網(wǎng)絡(luò)的高效性與穩(wěn)定性成為決定AI產(chǎn)業(yè)發(fā)展的核心要素。信而泰憑借自主研發(fā)的 CCL(集合通信庫(kù))評(píng)估工具 與 DarYu-X系列測(cè)試儀 ,為智算
智算中心的核心硬件是什么?
智算中心,作為人工智能時(shí)代的關(guān)鍵基礎(chǔ)設(shè)施,其核心硬件的構(gòu)成與性能直接影響著智能計(jì)算的效率與質(zhì)量。以下是對(duì)智算中心核心硬件的詳細(xì)闡述:一、AI芯片AI芯片是專(zhuān)門(mén)為加速人工智能計(jì)算而設(shè)計(jì)的

算智算中心的算力如何衡量?
作為當(dāng)下科技發(fā)展的重要基礎(chǔ)設(shè)施,其算力的衡量關(guān)乎其能否高效支撐人工智能、大數(shù)據(jù)分析等智能應(yīng)用的運(yùn)行。以下是對(duì)智算中心算力衡量的詳細(xì)闡述:一、算力的基本定義與單位1、
智算中心會(huì)取代通用算力中心嗎?
隨著人工智能(AI)技術(shù)的飛速發(fā)展,計(jì)算需求不斷攀升,數(shù)據(jù)中心行業(yè)正經(jīng)歷著前所未有的變革。傳統(tǒng)的通用算力中心與新興的智算中心之間的競(jìng)爭(zhēng)日益激
智算中心崛起:數(shù)字化時(shí)代的新核心基礎(chǔ)設(shè)施
隨著數(shù)字化時(shí)代的到來(lái),我們的生活、工作、甚至整個(gè)社會(huì)的運(yùn)行都離不開(kāi)“算力”的支撐。為了更高效地處理這些海量的計(jì)算需求,一種新的基礎(chǔ)設(shè)施應(yīng)運(yùn)而生——智算中心。那么,智算
寧暢助推智算中心發(fā)展邁入新階段
在“全局智算”戰(zhàn)略下,寧暢正式發(fā)布“全棧全液”AI基礎(chǔ)設(shè)施方案 ,在業(yè)內(nèi)首先實(shí)現(xiàn)了“全棧全液”的智算中心建設(shè)能力,助推智算
OCTC發(fā)布"算力工廠(chǎng)"!力促智算中心高效規(guī)劃建設(shè)投運(yùn)
創(chuàng)新提出面向未來(lái)數(shù)據(jù)中心的"算力工廠(chǎng)"模式,核心是以規(guī)(劃)、建(設(shè))、運(yùn)(營(yíng))一體化的交鑰匙工程,實(shí)現(xiàn)智算中心快速投運(yùn)、綠色低碳,在當(dāng)前AIGC算

中國(guó)移動(dòng)智算中心(哈爾濱)成為最大單集群智算中心
9月6日最新資訊,中國(guó)移動(dòng)智算中心(哈爾濱)正式宣告投入運(yùn)營(yíng),這一里程碑事件不僅標(biāo)志著中國(guó)移動(dòng)在智能計(jì)算領(lǐng)域的又一重大突破,更確立了其在全球運(yùn)營(yíng)商中擁有最大規(guī)模單集群智算
國(guó)內(nèi)最大智算中心月底在哈爾濱投用
國(guó)內(nèi)算力領(lǐng)域迎來(lái)重大進(jìn)展,中國(guó)移動(dòng)智算中心(哈爾濱)節(jié)點(diǎn)即將于8月30日正式啟用,標(biāo)志著國(guó)內(nèi)最大
FPGA在自動(dòng)駕駛領(lǐng)域有哪些應(yīng)用?
FPGA(Field-Programmable Gate Array,現(xiàn)場(chǎng)可編程門(mén)陣列)在自動(dòng)駕駛領(lǐng)域具有廣泛的應(yīng)用,其高性能、可配置性、低功耗和低延遲等特點(diǎn)為自動(dòng)駕駛的實(shí)現(xiàn)提供了強(qiáng)有力的支持。以下
發(fā)表于 07-29 17:09
中國(guó)算力中心市場(chǎng)持續(xù)增長(zhǎng),智能算力規(guī)模快速崛起
7月24日,中國(guó)信息通信研究院(簡(jiǎn)稱(chēng)“中國(guó)信通院”)權(quán)威發(fā)布了《中國(guó)算力中心服務(wù)商分析報(bào)告(2024年)》,該報(bào)告深入剖析了中國(guó)算力中心市場(chǎng)
智算中心加速布局,上游計(jì)算、存儲(chǔ)、互聯(lián)都涉及哪些芯片技術(shù)
的人工智能應(yīng)用需求。 ? 近期,中國(guó)各地紛紛加快數(shù)字基建項(xiàng)目的建設(shè)步伐,智算中心成為布局重點(diǎn)。從北京到四川,從寧夏到河南,多地智算中心項(xiàng)目相
壁仞科技為中國(guó)移動(dòng)呼和浩特智算中心提供強(qiáng)大算力
? 隨著人工智能技術(shù)的飛速發(fā)展,高性能計(jì)算中心成為推動(dòng)AI創(chuàng)新和應(yīng)用的關(guān)鍵基礎(chǔ)設(shè)施。近日,中國(guó)移動(dòng)智算中心(呼和浩特)成功上線(xiàn)運(yùn)營(yíng)。國(guó)內(nèi)領(lǐng)先的GPU企業(yè)壁仞科技的壁礪系列通用GPU
云數(shù)據(jù)中心、智算中心、超算中心,有何區(qū)別?
云數(shù)據(jù)中心、智算中心和超算中心是當(dāng)前計(jì)算機(jī)領(lǐng)域中比較重要的研究方向,三者雖然都屬于數(shù)據(jù)中心的范疇





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論