") 在 NGC 上玩轉(zhuǎn)新一代推理部署工具 FastDeploy,幾行代碼搞定 AI 部署
在 NGC 上玩轉(zhuǎn)新一代推理部署工具 FastDeploy,幾行代碼搞定 AI 部署
號外:
全場景高性能 AI 部署工具
FastDeploy 發(fā)版 v1.0
幾行代碼搞定 AI 部署,快速使用 150+ 預(yù)置部署示例,支持 CV、NLP、Speech、Cross-model 模型,并提供開箱即用的云邊端部署體驗(yàn),實(shí)現(xiàn) AI 模型端到端的推理性能優(yōu)化。
歡迎廣大開發(fā)者使用 NVIDIA 與飛槳聯(lián)合深度適配的 NGC 飛槳容器,在 NVIDIA GPU 上進(jìn)行體驗(yàn) FastDeploy!
全場景高性能 AI 部署工具 FastDeploy
人工智能技術(shù)在各行各業(yè)正加速應(yīng)用落地。為了向開發(fā)者提供產(chǎn)業(yè)實(shí)踐推理部署最優(yōu)解,百度飛槳發(fā)起了 FastDeploy 開源項(xiàng)目。FastDeploy 具備全場景、簡單易用、極致高效三大特點(diǎn)。
(1)簡單易用:幾行代碼完成 AI 模型的 GPU 部署,一行命令切換推理后端,快速體驗(yàn) 150+ 熱門模型部署
FastDeploy 精心設(shè)計(jì)模型 API,不同語言統(tǒng)一 API 體驗(yàn),只需要幾行核心代碼,就可以實(shí)現(xiàn)預(yù)知模型的高性能推理,極大降低了 AI 模型部署難度和工作量。一行命令切換 TensorRT、Paddle Inference、ONNX Runtime、Poros 等不同推理后端,充分利用推理引擎在 GPU 硬件上的優(yōu)勢。
import fastdeploy as fd
import cv2
option = fd.RuntimeOption()
option.use_gpu()
option.use_trt_backend() # 一行命令切換使用 TensorRT部署
model = fd.vision.detection.PPYOLOE("model.pdmodel",
"model.pdiparams",
"infer_cfg.yml",
runtime_option=option)
im = cv2.imread("test.jpg")
result=model.predict(im)
FastDeploy 幾行命令完成 AI 模型部署
FastDeploy 支持 CV、NLP、Speech、Cross-modal(跨模態(tài))四大 AI 領(lǐng)域,覆蓋 20 多主流場景、150 多個(gè) SOTA 產(chǎn)業(yè)模型的端到端示例,包括圖像分類、圖像分割、語義分割、物體檢測、字符識別(OCR)、人臉檢測、人臉關(guān)鍵點(diǎn)檢測、人臉識別、人像扣圖、視頻扣圖、姿態(tài)估計(jì)、文本分類、信息抽取、文圖生成、行人跟蹤、語音合成等。支持飛槳 PaddleClas、PaddleDetection、PaddleSeg、PaddleOCR、PaddleNLP、PaddleSpeech 6 大熱門 AI 套件的主流模型及生態(tài)(如 PyTorch、ONNX 等)熱門模型的部署。
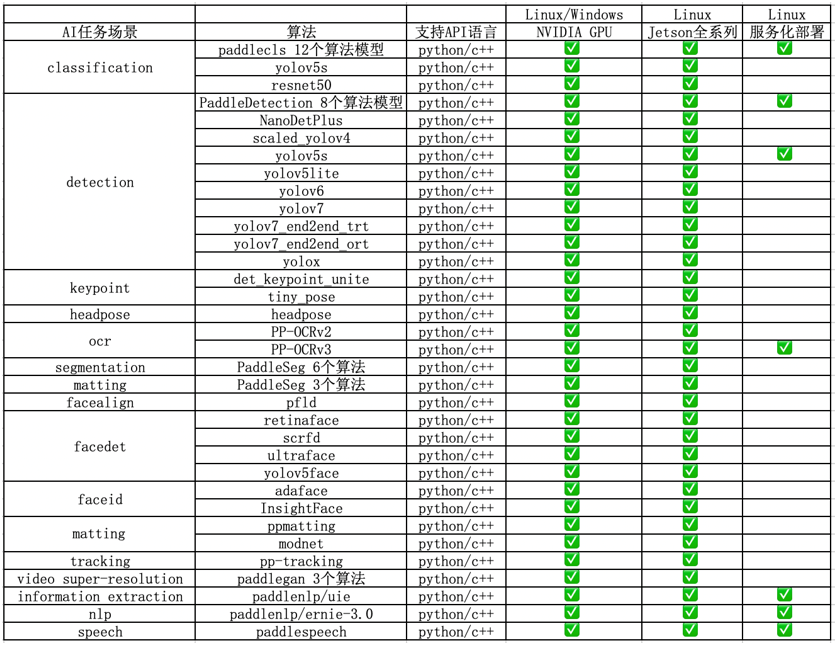
FastDeploy 在 NVIDIA GPU、Jetson上的 AI 模型部署庫
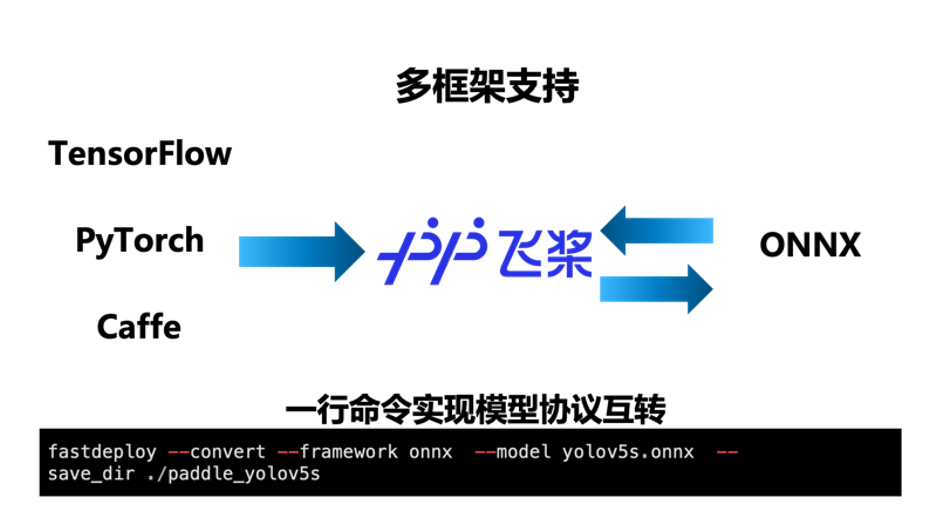
(2)全場景:支持多框架,輕松搞定 PaddlePaddle、PyTorch、ONNX 等模型部署
FastDeploy 支持 TensorRT、Paddle Inference、ONNX Runtime、Poros 推理引擎,統(tǒng)一部署 API,只需要一行代碼,便可靈活切換多個(gè) GPU 推理引擎后端。內(nèi)置了 X2Paddle 和 Paddle2ONNX 模型轉(zhuǎn)換工具,只需要一行命令便可完成其他深度學(xué)習(xí)框架到飛槳以及 ONNX 的相互轉(zhuǎn)換,讓其他框架的開發(fā)者也能通過 FastDeploy 體驗(yàn)到飛槳模型壓縮與推理引擎的端到端優(yōu)化效果。覆蓋 GPU、Jetson Nano、Jetson TX2、Jetson AGX、Jetson Orin 等云邊端場景全系列 NVIDIA 硬件部署。同時(shí)支持服務(wù)化部署、離線部署、端側(cè)部署方式。
(3)極致高效:一鍵壓縮提速,預(yù)處理加速,端到端性能優(yōu)化,提升 AI 算法產(chǎn)業(yè)落地
FastDeploy 集成了自動壓縮工具,在參數(shù)量大大減小的同時(shí)(精度幾乎無損),推理速度大幅提升。使用 CUDA 加速優(yōu)化預(yù)處理和后處理模塊,將 YOLO 系列的模型推理加速整體從 41ms 優(yōu)化到 25ms。端到端的優(yōu)化策略,徹底解決 AI 部署落地中的性能難題。更多性能優(yōu)化,歡迎關(guān)注 GitHub 了解詳情。
https://github.com/PaddlePaddle/FastDeploy
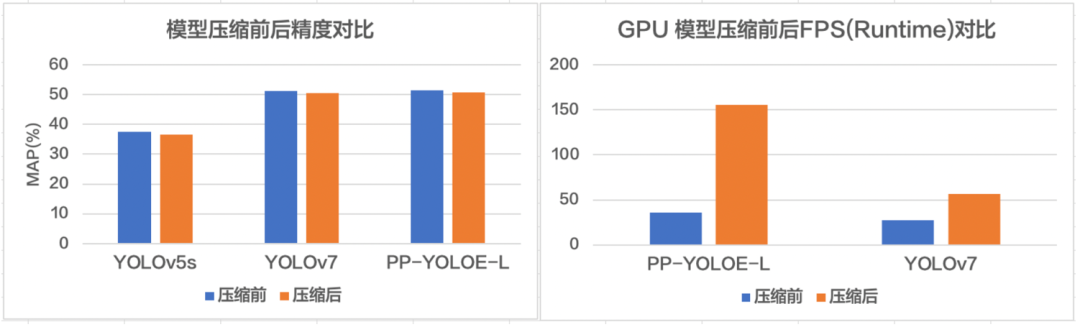
FastDeploy 一行命令實(shí)現(xiàn)自動壓縮,充分利用硬件資源提升推理速度

FastDeploy 提升 AI 任務(wù)端到端推理速
直播預(yù)告:服務(wù)化部署高并發(fā)調(diào)優(yōu)實(shí)戰(zhàn)
12 月 12 日 - 12 月 30 日,《產(chǎn)業(yè)級 AI 模型部署全攻略》系列直播課程,F(xiàn)astDeploy 聯(lián)合 10 家硬件公司與大家直播見面。
12 月 14 日 20:30 開始,NVIDIA 與百度資深專家將為大家?guī)硪浴?strong>一鍵搞定服務(wù)化部署,實(shí)現(xiàn)穩(wěn)定高并發(fā)服務(wù)”為主題的精彩分享,詳細(xì)解說 FastDeploy 服務(wù)化部署實(shí)戰(zhàn)教學(xué),以及如何提升 GPU 利用率和吞吐量!歡迎大家掃碼報(bào)名獲取直播鏈接,加入交流群與行業(yè)精英深度共同探討 AI 部署落地話題。
一鍵搞定服務(wù)化部署
實(shí)現(xiàn)穩(wěn)定高并發(fā)服務(wù)

12 月 14 日,星期三,20:30
精彩亮點(diǎn)
-
企業(yè)級 NGC 容器,快速獲取強(qiáng)大的軟硬件能力
-
三行代碼搞定 AI 部署,一鍵體驗(yàn) 150+ 部署 demo
-
服務(wù)化部署實(shí)戰(zhàn)教學(xué),提升 GPU 利用率和吞吐量
會議嘉賓

Adam | NVIDIA 亞太區(qū)資深產(chǎn)品經(jīng)理

Jason|百度資深研發(fā)工程師
參與方式

掃碼報(bào)名獲取直播鏈接
原文標(biāo)題:在 NGC 上玩轉(zhuǎn)新一代推理部署工具 FastDeploy,幾行代碼搞定 AI 部署
文章出處:【微信公眾號:NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
-
英偉達(dá)
+關(guān)注
關(guān)注
22文章
3912瀏覽量
93028
原文標(biāo)題:在 NGC 上玩轉(zhuǎn)新一代推理部署工具 FastDeploy,幾行代碼搞定 AI 部署
文章出處:【微信號:NVIDIA-Enterprise,微信公眾號:NVIDIA英偉達(dá)企業(yè)解決方案】歡迎添加關(guān)注!文章轉(zhuǎn)載請注明出處。
發(fā)布評論請先 登錄
AI端側(cè)部署開發(fā)(SC171開發(fā)套件V3)
谷歌新一代 TPU 芯片 Ironwood:助力大規(guī)模思考與推理的 AI 模型新引擎?
【幸狐Omni3576邊緣計(jì)算套件試用體驗(yàn)】DeepSeek 部署及測試
《AI Agent 應(yīng)用與項(xiàng)目實(shí)戰(zhàn)》閱讀心得3——RAG架構(gòu)與部署本地知識庫
如何部署OpenVINO?工具套件應(yīng)用程序?
是否可以使用OpenVINO?部署管理器在部署機(jī)器上運(yùn)行Python應(yīng)用程序?
C#集成OpenVINO?:簡化AI模型部署

添越智創(chuàng)基于 RK3588 開發(fā)板部署測試 DeepSeek 模型全攻略
摩爾線程宣布成功部署DeepSeek蒸餾模型推理服務(wù)

用Ollama輕松搞定Llama 3.2 Vision模型本地部署

如何在STM32f4系列開發(fā)板上部署STM32Cube.AI,
在設(shè)備上利用AI Edge Torch生成式API部署自定義大語言模型

YOLOv6在LabVIEW中的推理部署(含源碼)

三行代碼完成生成式AI部署





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論