") 跨域小樣本語(yǔ)義分割新基準(zhǔn)介紹
跨域小樣本語(yǔ)義分割新基準(zhǔn)介紹
前言
繼醫(yī)學(xué)圖像處理系列之后,我們又回到了小樣本語(yǔ)義分割主題上,之前閱讀筆記的鏈接我也在文末整理了一下。
小樣本語(yǔ)義分割旨在學(xué)習(xí)只用幾個(gè)帶標(biāo)簽的樣本來(lái)分割一個(gè)新的對(duì)象類,大多數(shù)現(xiàn)有方法都考慮了從與新類相同的域中采樣基類的設(shè)置(假設(shè)源域和目標(biāo)域相似)。
然而,在許多應(yīng)用中,為元學(xué)習(xí)收集足夠的訓(xùn)練數(shù)據(jù)是不可行的。這篇論文也將小樣本語(yǔ)義分割擴(kuò)展到了一項(xiàng)新任務(wù),稱為跨域小樣本語(yǔ)義分割(CD-FSS),將具有足夠訓(xùn)練標(biāo)簽的域的元知識(shí)推廣到低資源域,建立了 CD-FSS 任務(wù)的新基準(zhǔn)。
在開(kāi)始介紹 CD-FSS 之前,我們先分別搞明白廣義上跨域和小樣本學(xué)習(xí)的概念(這個(gè)系列后面的文章就不仔細(xì)介紹了)。小樣本學(xué)習(xí)可以分為 Zero-shot Learning(即要識(shí)別訓(xùn)練集中沒(méi)有出現(xiàn)過(guò)的類別樣本)和 One-Shot Learning/Few shot Learning(即在訓(xùn)練集中,每一類都有一張或者幾張樣本)。幾個(gè)相關(guān)的重要概念:
域:一個(gè)域 D 由一個(gè)特征空間 X 和特征空間上的邊緣概率分布 P(X) 組成,其中 X=x1,x2,.....,xn,P(X) 代表 X 的分布。
任務(wù):在給定一個(gè)域 D={X, P(X)} 之后,一個(gè)任務(wù) T 由一個(gè)標(biāo)簽空間 Y 以及一個(gè)條件概率分布 P(Y|X) 構(gòu)成,其中,這個(gè)條件概率分布通常是從由特征—標(biāo)簽對(duì) ∈X,∈Y 組成的訓(xùn)練數(shù)據(jù)(已知)中學(xué)習(xí)得到。父任務(wù),如分類任務(wù);子任務(wù),如貓咪分類任務(wù),狗狗分類任務(wù)。
Support set:支撐集,每次訓(xùn)練的樣本集合。
Query set:查詢集,用于與訓(xùn)練樣本比對(duì)的樣本,一般來(lái)說(shuō) Query set 就是一個(gè)樣本。
在 Support set 中,如果有 n 個(gè)種類,每個(gè)種類有 k 個(gè)樣本,那么這個(gè)訓(xùn)練過(guò)程叫 n-way k-shot。如每個(gè)類別是有 5 個(gè) examples 可供訓(xùn)練,因?yàn)橛?xùn)練中還要分 Support set 和 Query set,那么 5-shots 場(chǎng)景至少需要 5+1 個(gè)樣例,至少一個(gè) Query example 去和 Support set 的樣例做距離(分類)判斷。
現(xiàn)階段絕大部分的小樣本學(xué)習(xí)都使用 meta-learning 的方法,即 learn to learn。將模型經(jīng)過(guò)大量的訓(xùn)練,每次訓(xùn)練都遇到的是不同的任務(wù),這個(gè)任務(wù)里存在以前的任務(wù)中沒(méi)有見(jiàn)到過(guò)的樣本。所以模型處理的問(wèn)題是,每次都要學(xué)習(xí)一個(gè)新的任務(wù),遇見(jiàn)新的 class。 經(jīng)過(guò)大量的訓(xùn)練,這個(gè)模型就理所當(dāng)然的能夠很好的處理一個(gè)新的任務(wù),這個(gè)新的任務(wù)就是小樣本啦。
meta-learning 共分為 Training 和 Testing 兩個(gè)階段。
Training 階段的思路流程如下:
將訓(xùn)練集采樣成支撐集和查詢集。
基于支撐集生成一個(gè)分類模型。
利用模型對(duì)查詢集進(jìn)行預(yù)測(cè)生成 predict labels。
通過(guò)查詢集 labels(即ground truth)和 predict labels 進(jìn)行 loss 計(jì)算,從而對(duì)分類模型 C 中的參數(shù) θ 進(jìn)行優(yōu)化。
Testing 階段的思路:
利用 Training 階段學(xué)來(lái)的分類模型 C 在 Novel class 的支撐集上進(jìn)一步學(xué)習(xí)。
學(xué)到的模型對(duì) Novel class 的查詢集進(jìn)行預(yù)測(cè)(輸出)。
總的來(lái)說(shuō),meta-learning 核心點(diǎn)之一是如何通過(guò)少量樣本學(xué)習(xí)分類模型C。
再來(lái)解釋下為什么要研究跨域的小樣本學(xué)習(xí),當(dāng)目標(biāo)任務(wù)與源任務(wù)中數(shù)據(jù)分布差距過(guò)大,在源域上訓(xùn)練得到的模型無(wú)法很好的泛化到目標(biāo)域上(尤其是基于元學(xué)習(xí)的方法,元學(xué)習(xí)假設(shè)源域和目標(biāo)域相似),從而無(wú)法提升目標(biāo)任務(wù)的效果,即在某一個(gè)域訓(xùn)練好的分類模型在其他域上進(jìn)行分類測(cè)試時(shí),效果不理想。
如果能用某種方法使得源域和目標(biāo)域的數(shù)據(jù)在同一分布,則源任務(wù)會(huì)為目標(biāo)任務(wù)提供更加有效的先驗(yàn)知識(shí)。至此,如何解決跨域時(shí)目標(biāo)任務(wù)效果不理想的問(wèn)題成了跨域的小樣本學(xué)習(xí)。
如下圖,跨域小樣本學(xué)習(xí)對(duì)應(yīng)當(dāng)源域和目標(biāo)域在不同子任務(wù)(父任務(wù)相同)且不同域下時(shí),利用通過(guò)源域獲得的先驗(yàn)知識(shí)幫助目標(biāo)任務(wù)提高其 performance,其中已有的知識(shí)叫做源域(source domain),要學(xué)習(xí)的新知識(shí)叫目標(biāo)域(target domain)。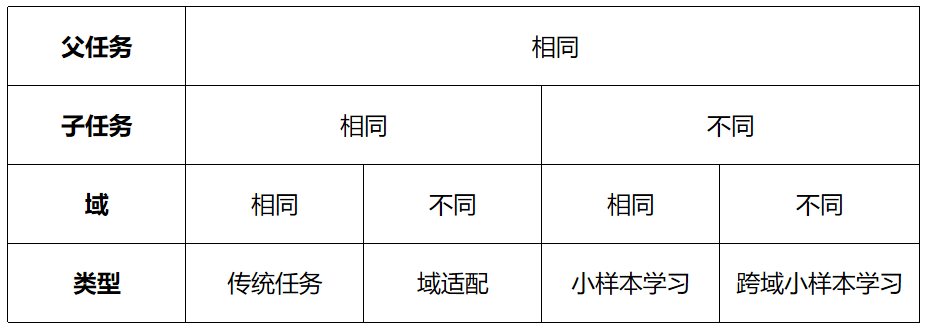
概述
在經(jīng)過(guò)對(duì)跨域小樣本學(xué)習(xí)的詳細(xì)介紹后,我們?cè)倩氐桨l(fā)表在 ECCV 2022 的 Cross-Domain Few-Shot Semantic Segmentation 這篇論文上。這篇文章為 CD-FSS 建立了一個(gè)新的基準(zhǔn),在提出的基準(zhǔn)上評(píng)估了具有代表性的小樣本分割方法和基于遷移學(xué)習(xí)的方法,發(fā)現(xiàn)當(dāng)前的小樣本分割方法無(wú)法解決 CD-FSS。
所以,提出了一個(gè)新的模型,被叫做 PATNet(Pyramid-Anchor-Transformation),通過(guò)將特定領(lǐng)域的特征轉(zhuǎn)化為下游分割模塊的領(lǐng)域無(wú)關(guān)的特征來(lái)解決 CD-FSS 問(wèn)題,以快速適應(yīng)新的任務(wù)。
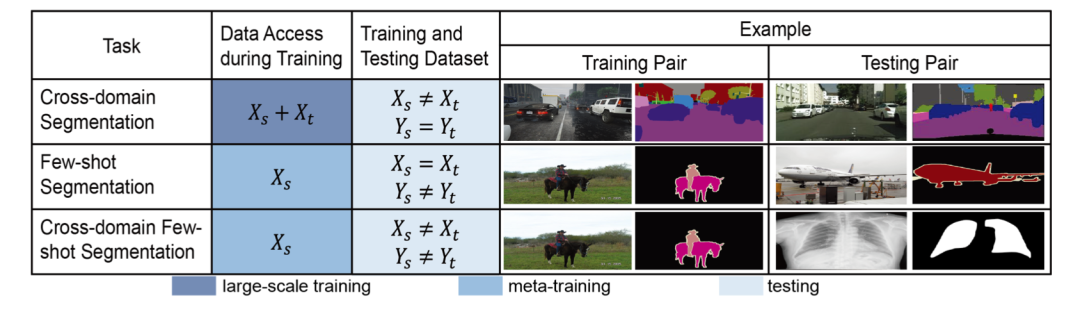
下圖是論文里給出的跨域的小樣本分割與現(xiàn)有任務(wù)的區(qū)別。 和 分別表示源域和目標(biāo)域的數(shù)據(jù)分布。 代表源標(biāo)簽空間, 代表目標(biāo)標(biāo)簽空間。
Proposed benchmark
提出的 CD-FSS 基準(zhǔn)由四個(gè)數(shù)據(jù)集組成,其特征在于不同大小的域偏移。包括來(lái)自 FSS-1000 、Deepglobe、ISIC2018 和胸部 X-ray 數(shù)據(jù)集的圖像和標(biāo)簽。
這些數(shù)據(jù)集分別涵蓋日常物體圖像、衛(wèi)星圖像、皮膚損傷的皮膚鏡圖像和 X 射線圖像。所選數(shù)據(jù)集具有類別多樣性,并反映了小樣本語(yǔ)義分割任務(wù)的真實(shí)場(chǎng)景。如下圖:
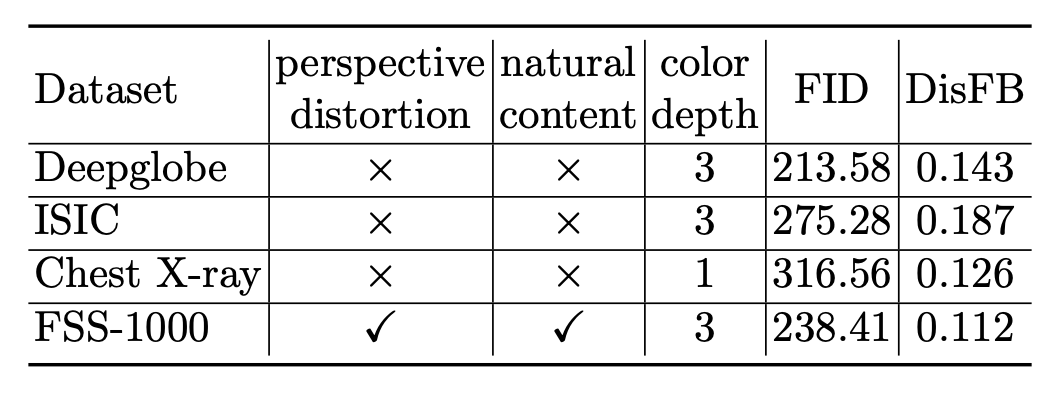
在下表中,每個(gè)域的任務(wù)難度從兩個(gè)方面進(jìn)行衡量:1)域遷移(跨數(shù)據(jù)集)和 2)單個(gè)圖像中的類別區(qū)分(在數(shù)據(jù)集中)。 F?echet Inception Distance (FID) 用于測(cè)量這四個(gè)數(shù)據(jù)集相對(duì)于 PASCAL 的域偏移,于是單個(gè)圖像中的域偏移和類別區(qū)分分別由 FID 和 DisFB 測(cè)量。由于單個(gè)圖像中類別之間的區(qū)分對(duì)分割任務(wù)有重要影響,使用 KL 散度測(cè)量前景和背景類別之間的相似性。
整體機(jī)制 with CD-FSS
CD-FSS 的主要挑戰(zhàn)是如何減少領(lǐng)域轉(zhuǎn)移帶來(lái)的性能下降。以前的工作主要是學(xué)習(xí) Support-Query 匹配模型,假設(shè)預(yù)訓(xùn)練的編碼器足夠強(qiáng)大,可以將圖像嵌入到下游匹配模型的可區(qū)分特征中。
然而在大領(lǐng)域差距下,只在源域中預(yù)訓(xùn)練的 backbone 在目標(biāo)域中失敗了,如日常生活中的物體圖像到 X-ray 圖像。
為了解決這個(gè)問(wèn)題,模型需要學(xué)會(huì)將特定領(lǐng)域的特征轉(zhuǎn)化為領(lǐng)域無(wú)關(guān)的特征。這樣一來(lái),下游模型就可以通過(guò)匹配 Support-Query 的領(lǐng)域無(wú)關(guān)的特征來(lái)進(jìn)行分割,從而很好地適應(yīng)新領(lǐng)域。
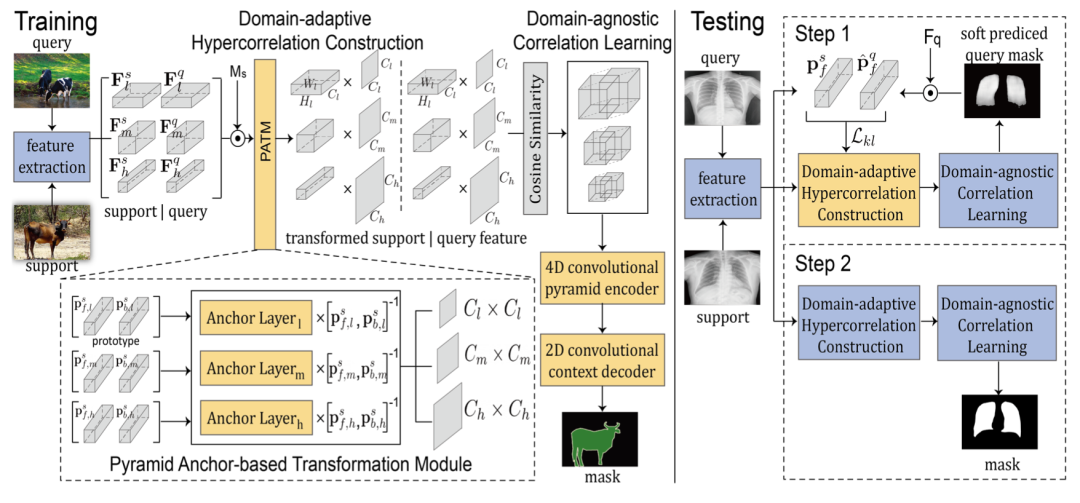
如下圖所示(左邊訓(xùn)練,右邊測(cè)試),整體機(jī)制由三個(gè)主要部分組成,即特征提取 backbone、domain-adaptive hypercorrelation construction 和 domain-agnostic correlation learning。對(duì)于輸入的 Support-Query 圖像,首先用特征提取器提取所有的中間特征。然后,我們?cè)?domain-adaptive hypercorrelation construction 部分引入一個(gè)特別新穎的模塊,稱為 Pyramid Anchor-based Transformation Module(PATM),將特定領(lǐng)域的特征轉(zhuǎn)換為領(lǐng)域無(wú)關(guān)的特征。
接下來(lái),用所有轉(zhuǎn)換后的特征圖計(jì)算多層次的相關(guān)圖,并將其送入 domain-agnostic correlation learning 部分。使用兩個(gè)現(xiàn)成的模塊,分別為 4D 卷積金字塔編碼器和 2D 卷積上下文解碼器,被用來(lái)以粗到細(xì)的方式產(chǎn)生預(yù)測(cè)掩碼,并具有高效的 4D 卷積。
在測(cè)試階段,論文里還提出了一個(gè)任務(wù)自適應(yīng)微調(diào)推理(TFI)策略,以鼓勵(lì)模型通過(guò) Lkl 損失微調(diào) PATM 來(lái)快速適應(yīng)目標(biāo)領(lǐng)域,Lkl 損失衡量 Support-Query 預(yù)測(cè)之間的前景原型相似度。
PATNet
上一部分提到 PATM 將特定領(lǐng)域的特征轉(zhuǎn)換為領(lǐng)域無(wú)關(guān)的特征,這一部分我們仔細(xì)看一下。Pyramid Anchor-based Transformation Module(PATM)的核心思想是學(xué)習(xí) pyramid anchor layers,將特定領(lǐng)域的特征轉(zhuǎn)換為領(lǐng)域無(wú)關(guān)的特征。直觀地說(shuō),如果我們能找到一個(gè)轉(zhuǎn)化器,將特定領(lǐng)域的特征轉(zhuǎn)化為領(lǐng)域無(wú)關(guān)的度量空間,它將減少領(lǐng)域遷移帶來(lái)的不利影響。由于領(lǐng)域無(wú)關(guān)的度量空間是不變的,所以下游的分割模塊在這樣一個(gè)穩(wěn)定的空間中進(jìn)行預(yù)測(cè)會(huì)更容易。
理想情況下,屬于同一類別的特征在以同樣的方式進(jìn)行轉(zhuǎn)換時(shí)將產(chǎn)生類似的結(jié)果。因此,如果將 Support 特征轉(zhuǎn)換為領(lǐng)域空間中的相應(yīng)錨點(diǎn),那么通過(guò)使用相同的轉(zhuǎn)換,也可以使屬于同一類別的 Query 特征轉(zhuǎn)換為接近領(lǐng)域空間中的錨點(diǎn)。采用線性變換矩陣作為變換映射器,因?yàn)樗氲目蓪W(xué)習(xí)參數(shù)較少。
如上一部分中的圖,使用 anchor layers 和 Support 圖像的原型集來(lái)計(jì)算變換矩陣。如果 A 代表 anchor layers 的權(quán)重矩陣,P 表示 Support 圖像的原型矩陣。既通過(guò)尋找一個(gè)矩陣來(lái)構(gòu)建轉(zhuǎn)換矩陣 W,使 WP=A。
任務(wù)自適應(yīng)微調(diào)推理(TFI)策略
為了進(jìn)一步提高 Query 圖像預(yù)測(cè)的準(zhǔn)確率,提出了一個(gè)任務(wù)自適應(yīng)微調(diào)推理(TFI,Task- adaptive Fine-tuning Inference)策略,以便在測(cè)試階段快速適應(yīng)新的對(duì)象。
如果模型能夠?yàn)?Query 圖像預(yù)測(cè)一個(gè)好的分割結(jié)果,那么分割后的 Query 圖像的前景類原型應(yīng)該與 Support 的原型相似。
與優(yōu)化模型中的參數(shù)不同,我們只對(duì) anchor layers 進(jìn)行微調(diào),以避免過(guò)擬合。上圖右側(cè)顯示了該策略的流程,在測(cè)試階段,在第 1 步(step 1)中,只有錨層使用提議的 Lkl 進(jìn)行相應(yīng)的更新,Lkl 衡量 Support 和 Query set 的前景類原型之間的相似性。在第 2 步(step 1)中,模型中的所有層都被凍結(jié),并對(duì) Query 圖像進(jìn)行最終預(yù)測(cè)。通過(guò)這種方式,模型可以快速適應(yīng)目標(biāo)域,并利用經(jīng)過(guò)微調(diào)的 anchor layers 產(chǎn)生的輔助校準(zhǔn)特征對(duì)分割結(jié)果進(jìn)行完善。
如下圖是幾個(gè) 1-shot 任務(wù)的可視化比較結(jié)果。對(duì)于每個(gè)任務(wù),前三列顯示 Support 和 Query set 的金標(biāo)準(zhǔn)。接下來(lái)的兩列分別表示沒(méi)有PATM 和沒(méi)有 TFI 的分割結(jié)果,最后一列顯示了用 Lkl 微調(diào)后的最終分割結(jié)果。
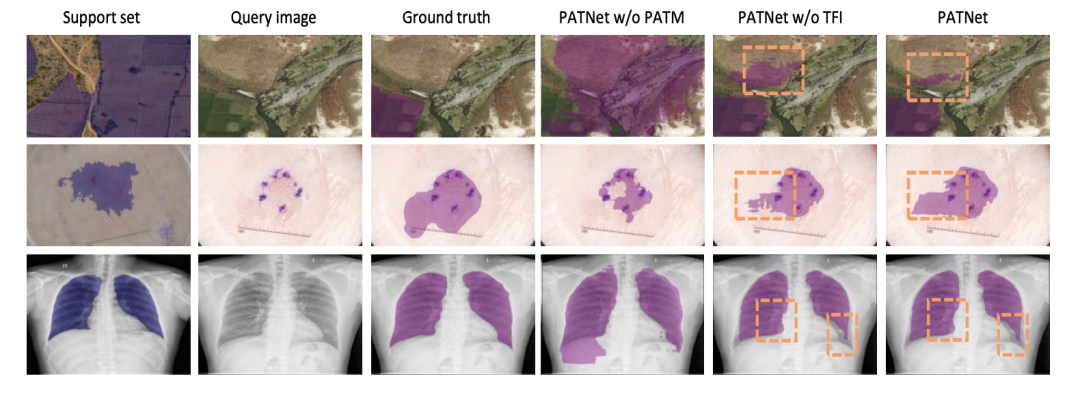
實(shí)驗(yàn)和可視化
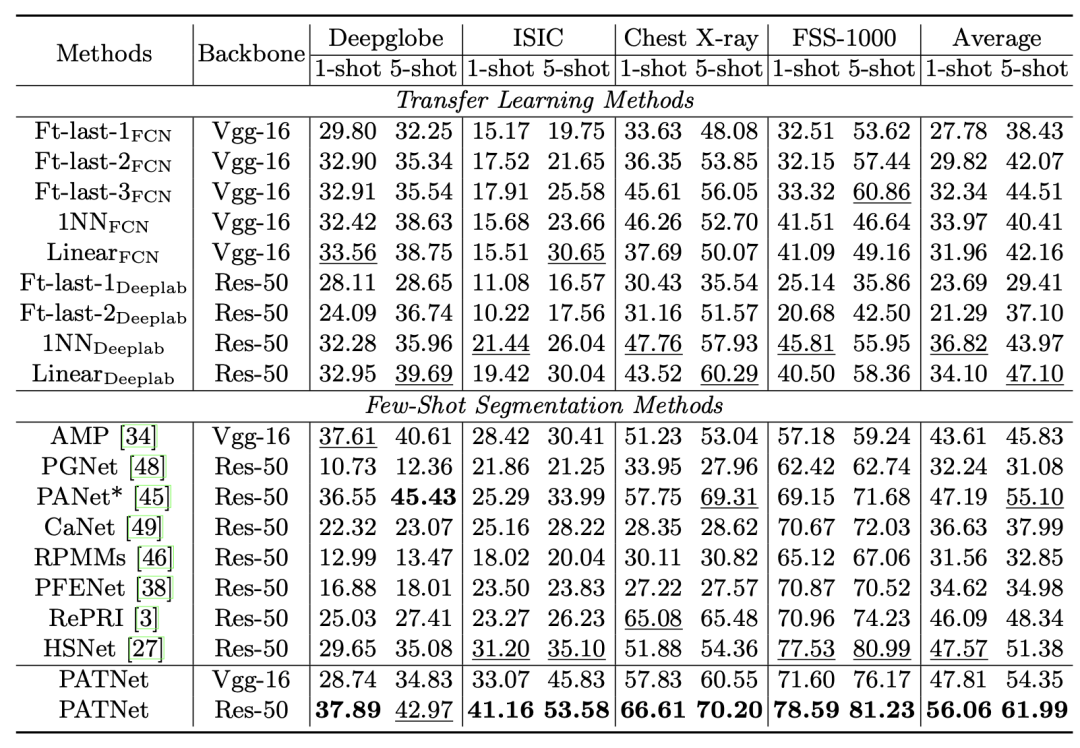
如下表所示,是元學(xué)習(xí)和遷移學(xué)習(xí)方法在 CD-FSS 基準(zhǔn)上的 1-way 1-shot 和 5-shot 結(jié)果的平均 IoU。所有的方法都是在 PASCAL VOC 上訓(xùn)練,在 CD-FSS 上測(cè)試。
下圖是模型在 CD-FSS 上進(jìn)行 1-way 1-shot 分割的定性結(jié)果。其中,Support 圖像標(biāo)簽是藍(lán)色。Query 圖像標(biāo)簽和預(yù)測(cè)結(jié)果是另一種顏色。
總結(jié)
這篇論文也將小樣本語(yǔ)義分割擴(kuò)展到了一項(xiàng)新任務(wù),稱為跨域小樣本語(yǔ)義分割(CD-FSS)。建立了一個(gè)新的 CD-FSS benchmark 來(lái)評(píng)估不同域轉(zhuǎn)移下小樣本分割模型的跨域泛化能力。實(shí)驗(yàn)表明,由于跨域特征分布的巨大差異,目前 SOTA 的小樣本分割模型不能很好地泛化到來(lái)自不同域的類別。所以,提出了一種新模型,被叫做 PATNet,通過(guò)將特定領(lǐng)域的特征轉(zhuǎn)換為與領(lǐng)域無(wú)關(guān)的特征,用于下游分割模塊以快速適應(yīng)新的領(lǐng)域,從而也解決了 CD-FSS 問(wèn)題。
審核編輯:劉清
-
圖像處理
+關(guān)注
關(guān)注
27文章
1324瀏覽量
57683 -
FSS
+關(guān)注
關(guān)注
0文章
13瀏覽量
9795
原文標(biāo)題:ECCV 2022: 跨域小樣本語(yǔ)義分割新基準(zhǔn)
文章出處:【微信號(hào):GiantPandaCV,微信公眾號(hào):GiantPandaCV】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
跨異步時(shí)鐘域處理方法大全
探索對(duì)抗訓(xùn)練的概率分布偏差:DPA雙概率對(duì)齊的通用域自適的目標(biāo)檢測(cè)方法

SparseViT:以非語(yǔ)義為中心、參數(shù)高效的稀疏化視覺(jué)Transformer

TSP研究:車內(nèi)網(wǎng)聯(lián)服務(wù)向跨域融合、全場(chǎng)景融合、艙駕融合方向拓展
利用VLM和MLLMs實(shí)現(xiàn)SLAM語(yǔ)義增強(qiáng)

一文解析跨時(shí)鐘域傳輸
手冊(cè)上新 |迅為RK3568開(kāi)發(fā)板NPU例程測(cè)試
語(yǔ)義分割25種損失函數(shù)綜述和展望






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論