 一種創新的存內計算架構
一種創新的存內計算架構
摘要
傳感器和數據生成設備的大規模發展推動了現代計算范式的轉變,從以算術邏輯為中心向以數據為中心的處理。在硬件層面,這迫切需要將密集、高性能和低功耗的存儲單元與Si邏輯處理器單元集成起來。然而,像搜索和模式匹配這樣的數據密集型問題也需要在電路和架構級別進行范式更改創新,以支持內存計算(CIM)操作。CIM體系結構結合了數據存儲,同時提供低延遲和小占用是非常受歡迎的,但尚未實現。在這里,我們提出了氮化鋁鈧(AlScN)鐵電二極管(FeD)憶阻器件,允許存儲,搜索和基于神經網絡的模式識別在一個無晶體管的架構。我們的設備可以直接集成在Si處理器的頂部,以可擴展的后端流程。我們利用聯邦儲備系統的現場可編程性、非波動性和非線性來演示電路塊,該電路塊可以支持原位內存搜索操作,搜索延遲時間< 0.1 ns,單元占用面積< 0.12μm2。此外,我們還演示了用FeD的4位運算進行矩陣乘法運算。我們的研究結果表明,FeD是快速、高效和多功能CIM平臺的有前途的候選者。
簡介
大數據與人工智能(AI)的融合催生了多個新興技術,涵蓋了一系列計算應用。傳感器和邊緣/物聯網設備的日益普遍的存在創造了大量的數據,這暴露了計算硬件的巨大效率差距,從移動和邊緣設備到數據中心和云計算硬件。此外,基于硅的互補金屬氧化物半導體(CMOS)器件小型化的放緩進一步加劇了基于傳統馮·諾依曼計算硬件架構(特別是中央處理單元(CPU)、圖形處理單元(GPU)和現場可編程門陣列(FPGA))之間的資源需求差距。此外,眾所周知,在馮·諾依曼架構中,許多以數據為中心的任務,大部分的能量和時間都消耗在內存訪問和數據移動上,而不是實際的計算上。為了緩解和克服這一瓶頸,已經提出了幾種解決方案,其中一個突出的解決方案是將內存和邏輯單元放置在物理上非常接近的位置。雖然在材料和設備層面上這些方面已經取得了重大進展,但一種革命性的方法將是使用原位存儲器執行計算功能。這通常稱為存內計算(CIM)。CIM的首要目標是通過在數據存儲的位置就地完成計算,從根本上改變計算架構,而不是通過在內存帶寬、新的非易失性內存(NVM)技術和數據并行性方面的單獨優化來重新設計傳統的馮·諾依曼架構架構。雖然已經有幾個使用馮·諾依曼架構的CIM體系結構演示,但大部分工作都被限制在單一類型的計算任務上,例如矩陣乘法加速器,通常使用記憶交叉條陣列實現。然而,利用“大數據”的AI計算任務通常需要在同一個芯片上進行多個數據密集型計算操作,最好使用相同的架構來處理管道中的信息。三個最重要的功能或操作是:1)片上存儲,2)并行搜索,3)矩陣乘法。構建CIM體系結構的一個關鍵挑戰是實現這三個功能所需的性能和靈活性之間的矛盾權衡。因此,雖然CIM加速器已經被證明可以在矩陣乘法加速方面實現高性能,但從根本上來說,它們并不適合于并行搜索等其他大數據操作。因此,為CIM概念化和開發可重構和操作靈活的硬件非常重要,以同時支持基本的數據操作,如片上存儲器、并行搜索和矩陣乘法加速。
在這項工作中,我們利用了氮化鋁鈧(AlScN)鐵電二極管(FeD)器件的獨特特性——特別是其現場可編程性、非波動性和非線性——并演示了基于FeD器件的電路塊,該器件在無晶體管設計中支持多個基本原始數據操作的原位存儲器(圖1)。具體來說,首先,我們展示了非易失性且具有自整流行為的FeD裝置,其非線性> 106,高開/關比超過102,續航超過104個周期,現場編程速度超過500ns,并與CMOS線后端(BEOL)處理兼容。然后,我們利用這些獨特的特性,并演示了使用0-晶體管/2-FeD單元的非易失性三元內容尋址存儲器(TCAM)。這些都是大數據應用中并行搜索過程的內存計算硬件實現的關鍵構建塊。這種無晶體管的方法是我們的設備和存儲單元設計的一個關鍵優點。因此,與基于2-晶體管/2電阻(2T-2R)的TCAM細胞相比,2-饋源TCAM具有最緊湊的設計(45 nm節點0.12μm2/cell),搜索延遲顯著降低(45 nm節點< 0.1 ns),通過集成電路強調(SPICE)模擬進行評估。最后,我們還表明,通過電脈沖,FeD器件可以編程成具有優越線性和對稱性的4位獨特導電狀態。利用這種可編程的、多比特的鐵電二極管屬性,我們以模擬電壓-振幅矩陣乘法的形式演示了神經網絡計算的硬件實現,這是神經網絡計算的一個關鍵核心。我們演示了接近理想的、基于軟件的神經網絡的準確性。通過在卷積神經網絡體系結構中將神經網絡權重映射到實驗FeD電導狀態,對矩陣乘法操作進行基準測試,用于推理和原位學習任務,結果表明我們的精度接近MNIST數據集的理想軟件級模擬。我們的研究結果表明,基于氮化鋁鈧(AlScN)、現場可編程、非volatile的FEDS為構建可重構CIM體系結構提供了獨特的機會,可以在性能和靈活性之間取得卓越的平衡。
現場可編程氮化鋁鈧(AlScN)
鐵電二極管(FeD)存儲器
我們的FeD器件由一層45納米厚的濺射沉積鐵電AlScN層夾在頂部和底部的鋁電極之間。這形成了金屬絕緣體(MIM)結構,如圖2a左面板所示。AlScN是一種新發現的鐵電材料,具有近乎理想的鐵電滯回線、剩余極化記錄值和成分可調的矯頑力場。此外,它可以直接集成在8英寸晶圓上的CMOS BEOL兼容工藝技術中。它也被證明是最有前途的高性能鐵電存儲器件的候選人之一,可擴展到小于10 nm的厚度。AlScN薄膜進行了電性表征,并表現出2-4.5 MV/cm的大矯頑力場EC。這對于擴展到更薄的鐵電層非常重要,同時保持大的內存窗口、高的開/關比和良好的保持。當結合測量到的高殘留極化(Pr為80-150μC/cm2)時,基于強的隧道勢壘調制,會產生顯著的隧穿電阻效應,從而產生高的開/關比(補充注釋1)。圖2(a)給出了MIM FeD器件的代表性截面透射電子顯微鏡(TEM)圖像,該器件由AlScN薄膜和Al頂部電極組成,沉積在Al/AlScN/Si襯底上。AlScN薄膜的原子分辨率TEM圖像如圖2(b1)所示。圖2(b2)顯示了AlScN/底部Al界面處約2nm厚的界面層。
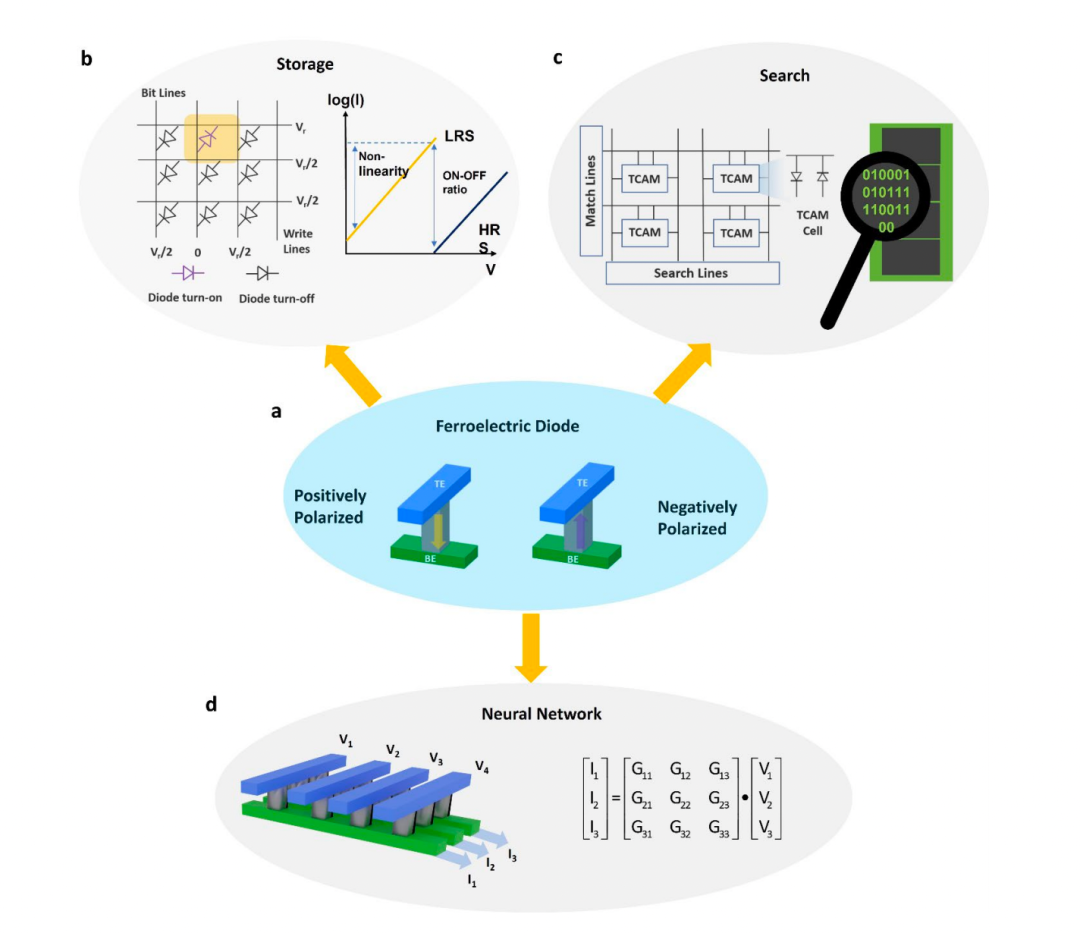
圖1所示。基于現場可編程鐵電二極管的可重構CIM。
a.具有鐵電AlScN上下極化的交叉桿結構中的FeD器件示意圖。如b-d所示,這些設備的現場可編程性、非波動性和非線性可以用于多個基本數據操作,如存儲、搜索和神經網絡,而不需要額外的晶體管。
b.兩端FeD器件表現出類似二極管的自整流行為,具有非線性> 106,同時具有超過102的開/關比和超過104循環的耐久性,使FeD器件在存儲的內存層次中處于很好的位置。此外,高非線性可以抑制潛電流,而不需要額外的接入晶體管或選擇器。
c.對于搜索操作,一個非易失性TCAM可以建立在0-晶體管/2-FeD單元上,這是大數據應用中并行搜索的內存計算硬件實現的構建塊。
d.對于神經網絡,FeD器件可以提供不同的多重導電狀態的可編程性,且與電脈沖的數量有高度的線性關系。這允許映射矩陣乘法運算(神經網絡計算的一個關鍵核心),通過將輸入向量編碼為模擬電壓幅值,并將矩陣元素編碼為一組FeD裝置的電導,讀取FeD裝置每位線上的累積電流。
45nm AlScN薄膜的鐵電響應通過在半徑為25μm的圓形金屬/鐵電/金屬電容上進行正上,負下(PUND)測量來表征,使用的方波延遲為2μs,脈沖寬度為400 ns(補充圖S11)。PUND測試優于偏振-電場遲滯回線(P-E回線)測量,因為45 nm AlScN的P-E回線顯示出偏振依賴的漏電,這妨礙了對將材料切換到金屬-極性態的正應用場的極化飽和的觀測。PUND結果顯示,殘余極化約為150 μ C/cm2,如圖2c所示,與之前的觀察結果一致。為了進一步驗證鐵電開關,進行了動態電流響應,觀察到鐵電開關對應的峰值(補充圖S12)。為了進一步表征記憶效應和可靠性,我們在正極化和負極化狀態之間進行了耐力測試,如圖2d所示。圖2d顯示了從20,000個PUND循環中提取的剩余正負極化。同一AlScNFeD裝置的循環設置/重置操作表明,正負極化狀態都是穩定的,并且在相當數量的循環內都是可重寫的。如圖2e所示,我們通過對頂部電極施加負/正電壓,同時對底部電極接地,在低電阻狀態(LRS)和高電阻狀態(HRS)之間反復設置/重置FeD裝置,使用準直流電壓掃描,循環100次。FeD器件顯示超低工作電流和自整流行為,在9v到0v之間具有非線性> 106,這有助于抑制隱藏電流,而不需要額外的接入晶體管或選擇器。LRS和HRS電阻的分布如圖2f所示,顯示了LRS和HRS之間的比值在周期與周期變化上的緊密分布。
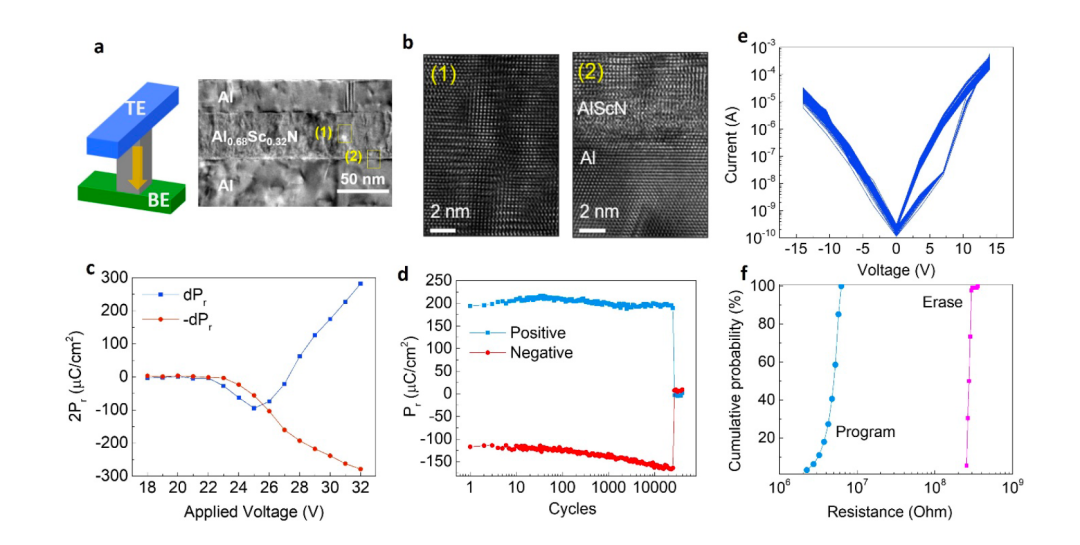
圖2所示。AlScN/MoS2 fe - fet的室溫電性表征。
a, AlScN FeD器件的3D示意圖和AlScN FeD的截面TEM圖像,顯示45nm AlScN為鐵電開關層。
b,在(a)中所示區域(1)和(2)獲得的鐵電體和界面原子結構可見的高分辨率相位對比TEM圖像。
c,脈沖寬度為400ns,脈沖間延遲為2μs的45nm AlScN薄膜的PUN結果。PUND測試顯示飽和剩余極化為150μC/cm2。
d,利用1.5μs脈沖寬度和26 V振幅對AlScN薄膜進行持久測試時的PUND測量提取的剩余極化值。
e,在基于45納米 AlScN的FEDs上進行100個周期的程序和擦除測量。
f, e中程序和擦除測量過程中HRS和LRS電阻的分布。
2-FeD TCAM單元用于搜索
接下來,我們關注CIM電路架構和計算應用程序,包括上述作為非易失性存儲器的FeDs。我們首先演示一個使用FeDs的TCAM實現。TCAM是大數據應用中快速高效并行搜索CIM硬件實現的關鍵構件。TCAM通過并行比較輸入數據與存儲在內存數組中的數據來執行搜索功能,并在檢測到匹配時返回數據地址。這種并行搜索允許TCAM在一個時鐘周期內執行查找表功能。與存儲“0”或“1”位值的二進制內容尋址存儲單元不同,TCAM單元可以存儲額外的“X”(“不在乎”)位,這將導致匹配狀態,而不管輸入的搜索數據是什么,并使TCAM在搜索應用程序中更加強大。然而,在傳統的Si CMOS結構中,需要多個晶體管(~16)來構建一個具有靜態隨機訪問存儲器(SRAM)的TCAM單元(圖3a)。由于晶體管的充放電和互連寄生電容,這種配置導致了大的占地面積和高功耗。這限制了該配置在高速、大規模和功率受限系統中的使用。非易失性存儲器(NVM)是實現TCAM的有前途的替代方案,因為它們更節約占地面積和更節能。這是因為它們在更緊湊的體系結構中形成了一個單獨的TCAM單元,并且即使電源被切斷,它們也保留了存儲的信息。基于電阻性隨機存取存儲器(RRAMs)的TCAM、磁隧道結(MTJ) RAM、浮柵晶體管存儲器(FLASH)和相變存儲器(PCMs)已經被證實。然而,所有這些架構仍然構建在線前端晶體管之上,沒有一個完全兼容BEOL。
在這項工作中,TCAM的單元結構可以通過僅使用兩個FeDs而顯著簡化,由于FeDs具有很大的非線性,因此不需要加入晶體管(圖3a)。圖3b演示了單個FeD TCAM電池的工作。電池結構使利用FeD crossbar存儲器陣列變得很自然,其中連接到陽極和陰極的信號線在TCAM演示的位搜索中并行,如補充圖S3所示。首先,我們討論了基于FeDs的TCAM如何存儲和搜索“0”或“1”位(圖3b)。在單元操作過程中,首先將互補狀態寫入兩個FeDs,如果搜索數據在搜索線(SL和非SL)上有偏差,與存儲的信息匹配,匹配線(ML)保持高;否則,ML被下拉。正如我們在超真空中所展示的,FeD設備具有高度的自整流能力,并能維持較高的開/關比。因此,只有當FeD被編程為低電阻狀態且讀電壓高于FeD的打開電壓時,ML上才會發生放電。
如圖3b所示,我們將邏輯“1”狀態寫入到FeD TCAM單元中,分別將左/右FeD設置為低阻/高阻狀態。在搜索操作中,匹配線被一個讀電壓VS所偏置,它高于FeD的啟動電壓。接下來,我們通過分別對左/右FeD施加高/低電壓來搜索邏輯“1”,并通過分別對左/右FeD施加低/高來搜索邏輯“0”。在這種情況下,“高壓”指的是讀電壓VS,它高于FeD的打開電壓,但低于寫電壓。相反,“低電壓”指的是接近零的讀電壓,遠低于FeD的打開電壓。由于左FeD與右FeD平行,只有當單元中的兩個FeD都被截斷時,才會觀察到匹配狀態(圖3b,左面板)。根據這些寫入和搜索方案,當存儲數據和搜索數據匹配時(如圖3b左面板所示,存儲位為邏輯' 1 ',搜索位為邏輯' 1 '),低電阻為0的FeD器被關閉,因為它的陽極和陰極之間的壓降接近于零,低于它的打開電壓。此外,高阻狀態下的FeD也是截止的,因為電流在高阻狀態下通過FeD時自然是低的。因此,在兩個通道的放電電流都是最小的,ML保持較高。但是,當搜索數據與存儲數據不匹配時,即使處于高阻狀態的右側FeD仍然被切斷,但左側FeD沒有被切斷。左FeD低阻通電時,其正極和陰極之間的壓降為VS,且高于其接通電壓的值為0。因此,放電電流顯著,ML電壓較低(圖3b,中面板)。我們還演示了兩個基于美聯儲的TCAM中的三元“不在乎”狀態。如圖3b的右面板所示,通過將左右兩個FeD設置為高電阻狀態,我們將邏輯“不在乎”狀態寫入FeD TCAM單元。使用上面的寫方案和邏輯“1”和“0”相同的搜索方案,無論什么信號到達兩個FeDs,這兩個FeDs總是被切斷,因為它們處于高電阻狀態。圖3c顯示了在搜索數據和存儲數據位' 1 '之間的匹配和不匹配狀態下,使用7 V的中等搜索電壓對兩個基于FeD的TCAM單元的電阻進行重復準直流讀取。圖3d顯示了使用查詢位“1”和“0”對存儲數據位“Don’t care”的兩個FeD TCAM單元電阻的重復準直流讀取。這表明,對于這兩個查詢,兩個基于FeDs的TCAM的ML阻力仍然很高,因此沒有通過任何兩個FeDs進行放電。因此,帶有兩個FeDs的TCAM單元在所有三種狀態下都能完全工作。兩種基于FeD的TCAM單元的完整查找表匯總在補充表中。
傳統的雙端憶阻器通常與前端晶體管配對構成TCAM單元。這是因為晶體管需要切斷通道,因為它們與雙端nvm串聯在一起。基于FeD的設計得益于高自整流比,無需任何晶體管就能切斷通道。換句話說,FeD將晶體管的功能抽象為自身的自整流行為。沒有晶體管導致更小的電池足跡和面積效率,并提高了基于美聯儲的TCAM的搜索速度。通過SPICE模擬,我們驗證了基于FeD的TCAM中的搜索延遲與之前基于2晶體管2電阻(2T-2R)的TCAM體系結構相比有所降低。圖3e顯示了各種TCAM單元橫向足跡與搜索延遲的基準對比圖。我們的兩個基于FeD的超CMOS SRAM TCAM和其他基于晶體管+ NVM設備的架構的卓越性能是顯而易見的。
基于FeDs的TCAM的感知度是自整流比和ON/OFF電導(或電流)比的函數。根據我們詳細的緊湊模型(見補充注釋1),通過在FeD層頂部集成一個非鐵電絕緣體,并對這些鐵電絕緣體和非鐵電絕緣體層之間的厚度比以及鐵電層的矯頑場進行工程設計,可以進一步提高FeD的開/關比。未來的研究將專注于通過設計這些變量來進一步提高感知邊緣。
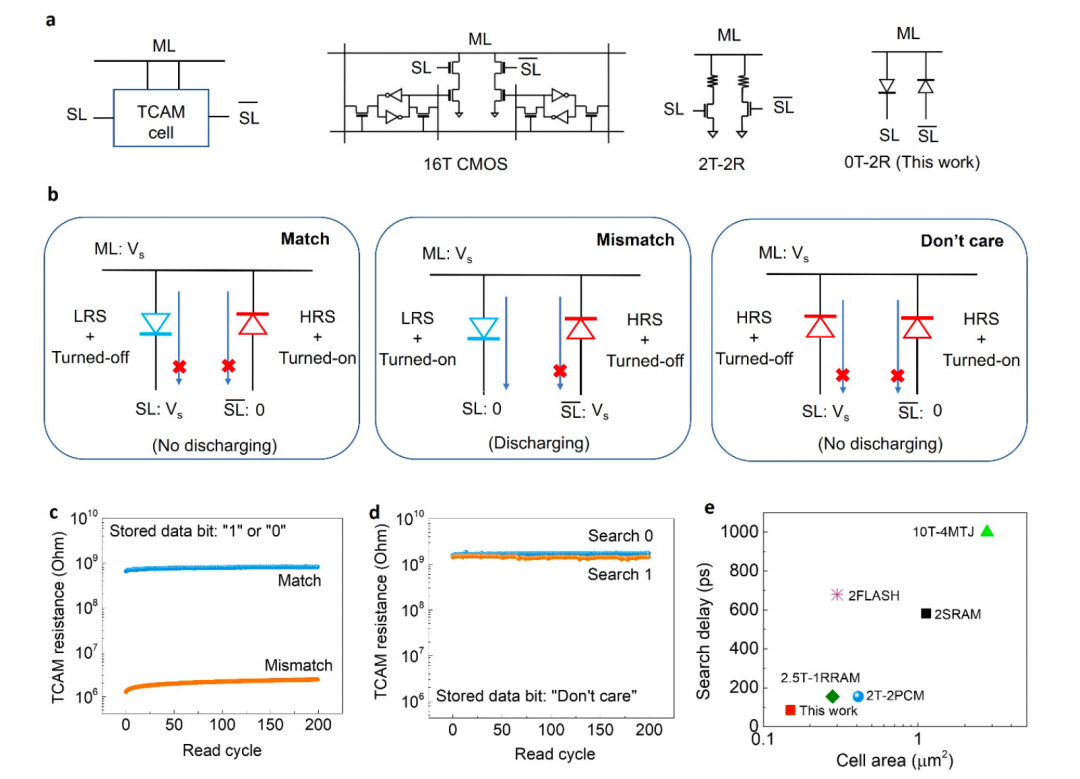
圖3。2-FeD TCAM單元用于搜索操作
a,帶有匹配線(ML)、搜索線(SL)和搜索線(SL條)電極(左)的TCAM單元的方框示意圖。基于CMOS voltle靜態隨機存取存儲器(SRAM)技術的單16晶體管(16T) TCAM電池電路圖,以及基于PCM和RRAM等電阻性存儲元件的2晶體管2電阻(2T2R) TCAM電路。(中間)。本工作中提出的兩個基于二鐵二極體的TCAM電池(右)通過使用兩個平行但極性相反的FeDs連接顯著簡化了TCAM設計。
b.由2個federal組成的單個TCAM單元對“匹配”、“不匹配”和“不在乎”狀態的操作。
c,對于搜索數據和存儲數據位' 1 '之間的匹配和不匹配狀態,重復準直流讀取兩個FeDs TCAM單元的電阻,顯示在ML電阻上有>100 X的差異。
d,使用查詢位“1”和“0”重復準dc讀取存儲數據位“Don’t care”的兩個鐵二極管TCAM單元的電阻,結果表明,對于兩個查詢,兩個FeDs TCAM的ML電阻都很高,因此沒有通過兩個FeDs中的任何一個放電。
e,各種存儲技術中TCAM細胞橫向足跡與搜索延遲的基準對比圖。這個估計假設單一FeD面積為0.0081μm2。
神經網絡
接下來,我們將關注我們的FeD設備陣列在深度神經網絡(DNN)推理中的應用,這涉及到重復矩陣乘法/累積(MMAC)操作。MMAC操作和DNN通常在軟件級別實現。然而,它們的軟件實現使得在電力和資源受限的設備或環境中部署它們特別具有挑戰性。同樣,這在很大程度上是由于傳統的馮諾依曼計算硬件方法,它在內存訪問方面是密集的,很難并行化。在模擬域進行MMAC操作提供了一種有前途的替代方案:具有模擬導管的憶阻器已被證明是執行MMAC操作的優越硬件介質。通過利用基爾霍夫電流定律(KCL)的高并行性,MMAC操作可以顯著減少到讀取單個時鐘在憶阻器的每個位線上的累積電流。這是通過將輸入矢量編碼到模擬電壓幅值和將矩陣元素編碼到憶阻器陣列的電導來實現的。
理想的適合MMAC的憶性器件應該在電氣編程中實現線性排列的電導值,電流對驅動電壓的線性依賴,以及抑制電流量的高電阻。該領域的先前研究主要集中在具有優異歐姆性能和大量電導狀態的記憶器件上,如RRAM和PCM。在DNN推理精度的背景下,電流和電壓之間的線性關系是最小化輸入基準失真的必要條件,大量的電導將使權矩陣上的精度損失最小化,這對于執行高度精確的推理任務是必不可少的。然而,從功率和面積效率的角度來看,一個優秀的歐姆行為和大量的電導狀態將損害結構指標的功率效率和每次計算的低延遲。這有幾個原因。首先,具有優異歐姆性能的憶性器件以高器件導電性為代價,這意味著高工作電流限制了陣列的縮放。其次,大量的電導將相應地需要高精度的模數轉換器(adc)。從先前的工作中我們已經知道,在憶阻陣列系統中,電路級別上的adc支配著能量和面積成本。因此,更多的電導狀態意味著在DNN推理引擎的架構級別上更多的功率開銷。因此,DNN推理的準確性與功率和面積效率之間存在明顯的權衡。在這里,我們展示了FeD憶阻器可以用于執行這些指標之間的最佳權衡。首先,為了實現器件導電性的權衡,重要的是在保持線性行為的同時降低記憶器件的操作導電性。前一個條件對于高度自整流的設備來說很容易滿足,這是聯邦儲備銀行的固有屬性;后一個條件可以通過在輸入電壓振幅上應用編碼器來線性化電流-電壓關系(見補充注2)來滿足。第二,為了放松電導狀態數量上的權衡,需要少量但稀疏且線性排列的電導狀態。與實現大量電導狀態的方法相比,這種方法可以獲得等效的推理精度。
圖4a顯示了通過逐步電壓脈沖調制的FeD系統的逐步切換。使用逐步電壓脈沖,FeD電池逐漸編程成16個不同的電導狀態。這些電導狀態顯示與編程脈沖數量的高度線性,如下所述。圖(左)顯示了一系列編程操作,其中逐步電壓脈沖(范圍從16 V到19 V)應用于FeDs的頂部電極上,然后每次都進行擦除操作。標注窗口(右)顯示了一個代表性周期的電導與脈沖數的關系。圖4b顯示,FeD器件能夠實現電壓脈沖誘導模擬雙極開關(范圍從16v到19v,左)。標注窗口(右)顯示了一個逐步編程和逐步擦除的循環。在雙向調制中,FeD器件對16種不同的電導狀態表現出優越的線性(線性擬合的R2分數為0.9997)。圖4c顯示了16種不同電導狀態下的電導保留率,并沒有顯示明顯的退化。圖4d顯示了在16個程序脈沖(脈沖寬度為2 μs),交錯讀取(8 V)的相同序列下,五個獨立的FeD器件的電導狀態分布。結果顯示,這些FeD設備之間的設備間的差異可以忽略不計。我們注意到,用于編程這些狀態的FeD器件的電導范圍(~25-250 nS)比用于TCAM操作的電導范圍(~ 2-250 nS)小得多。這主要是因為在較小的電導范圍內可以更好地實現工作中的線性。此外,DNN推理應用不一定需要高范圍的電導調制。我們在一個用于計算機視覺的訓練卷積神經網絡(CNN)的實際應用中,模擬了由這種FeD設備組成的陣列的性能。在MNIST數據集(MNIST, Modified National Institute of Standards and Technology database)上訓練一個CNN(包括兩個卷積層和一個全連接層),然后將預訓練的權重轉移到FeD電導范圍。該網絡的示意圖如圖4e所示。我們分析了由于重量轉移到低精度的電導值,加上一個附加的可變因子A,這是一個非線性指標,精度下降。A因子與非線性的關系已在補充注3中詳細討論。因此,全精度訓練網絡的權重被量化為若干電導狀態(從1位到9位不等)。然后,對網絡在MNIST測試數據集上的準確性進行重新評估。卷積神經網絡對于低精度的權值傳遞具有較低的非線性(A > 0.5)的魯棒性,如圖4f所示。圖4f中,對于低精度的權值傳遞變化,在單精度浮動點數格式(FP32)上僅用3位的權值精度恢復了97.5%的全精度測試精度。對于較高的非線性(A <0.35), FP32上需要1 ~ 2位權精度才能恢復全精度測試精度,這說明線性排列稀疏的電導狀態具有良好的線性性,可以替代大量的電導狀態,實現等效推理精度。此外,我們在FeD陣列上模擬原位訓練的內存實現,其中訓練相同的卷積神經網絡,并在每次反向傳播后將權值更新直接映射到FeD的實際電導狀態。如圖4g所示,對于圖4a中FeD器件中演示的16個獨立電導狀態,原位學習精度比在FP32上訓練的精度下降了約2%。然而,使用更先進的低精度訓練技術和軟件上的模型壓縮技術,我們相信這個數字可以大幅減少,允許在訓練階段執行低精度權重轉移到FeD設備時幾乎沒有精度下降。
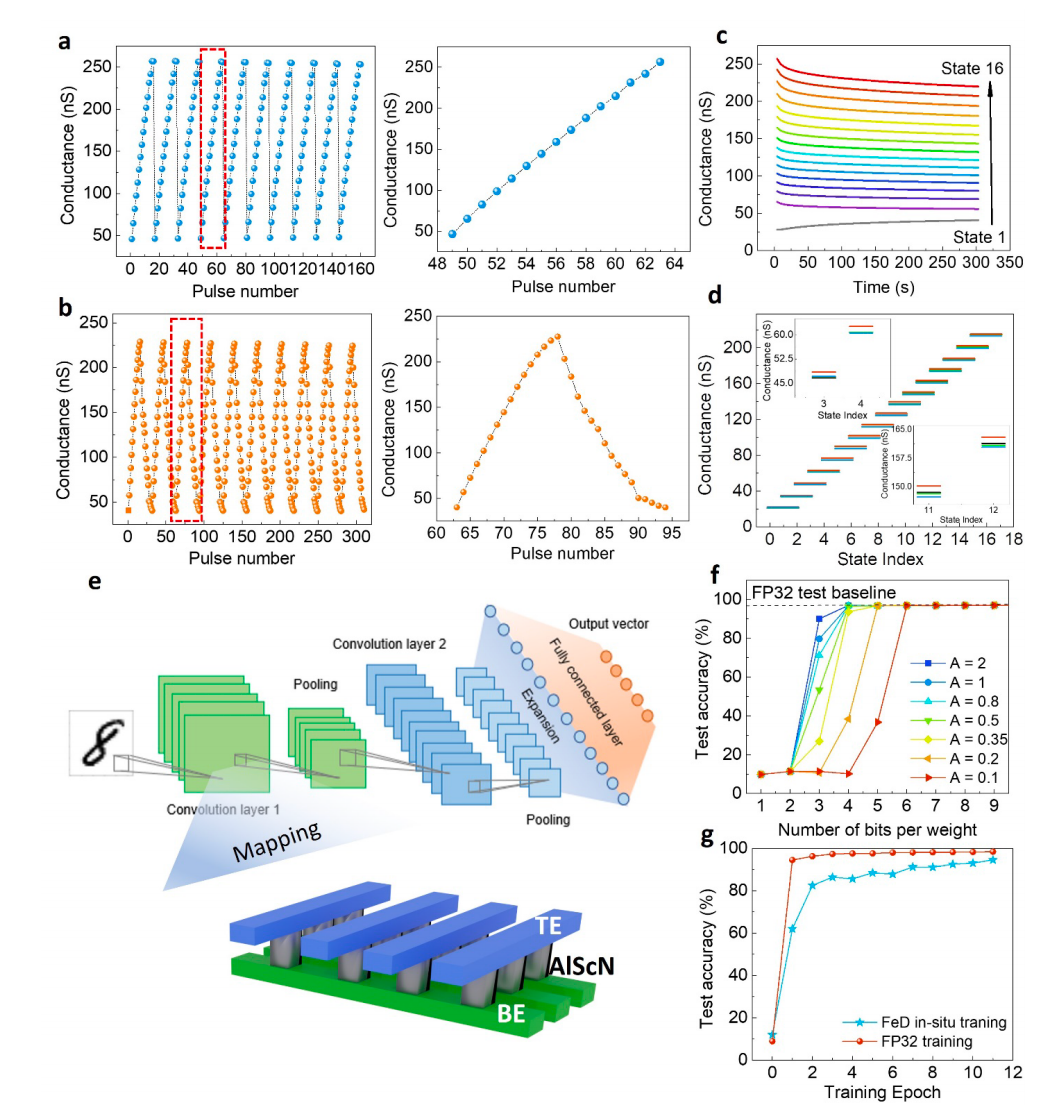
圖4。FeD-based神經網絡。
a,通過逐步電壓調制脈沖在鐵二極管(FeD)中逐步開關。使用逐步電壓脈沖將FeD電池逐步編程成各種電導狀態。左面板顯示了一系列編程操作,其中逐步電壓脈沖偏向于聯邦電極上的頂部電極,每次都跟著一個擦除操作。標注窗口(右面板)顯示一個代表性周期的電導與脈沖數的關系。
b, FeD被證明能夠進行電壓脈沖誘導模擬雙極開關(左)。標注窗口(右)顯示了一個逐步編程和逐步擦除的循環。在16個不同的狀態下,FeD器件顯示了優越的線性。
c, 16個不同電阻狀態的電阻保留率。
d,受16個程序脈沖(2 μs脈沖寬度)序列和交錯讀取(8 V)的影響,五個獨立的FeDs的電阻狀態分布。
e,為MNIST數據集訓練的CNN的插圖。使用鐵二極管陣列進行矩陣乘法的神經網絡硬件實現可以在完全模擬模式下運行,而無需外圍的模數轉換器。
f.仿真包括實現模擬權層的FeD設備,以及在MNIST上訓練的帶有FP32計算的網絡的不準確權映射。(f)中的模擬表明,當A < 0.5時權重精度僅為3位時,網絡推理精度的退化小于1%。
g,直接使用實現模擬權層的FeD設備對(e)中的網絡進行原位訓練的模擬。利用fbi漸進編程中的優越線性,模擬權值層具有16個電阻狀態,其推理精度可與FP32計算基線相媲美。
結論
總之,我們證明了基于AlScN的ferrodiode(鐵二極管器件)是一種新穎的、BEOL兼容的無晶體管架構多功能CIM平臺。我們通過一個TCAM電路實現了搜索功能的實驗演示,該電路具有橫向單元足跡和搜索延遲,優于所有現有和實驗NVM技術。最后,我們演示了一種穩定的、脈沖可編程的4位存儲器,來自ferrodiode,結合卷積神經網絡的硬件實現,其推理精度可與軟件相媲美。因此,我們的工作通過使新型ferroelectric和使用它們制造的二極管器件成為可能,為CIM平臺打開了新的可能性。
番外
FeD設備制造的方法
FeD由Si/Al0.8Sc0.2N (85 nm)襯底上的Al (80 nm)/Al0.68Sc0.32N (45 nm)/Al (30 nm) 的薄膜堆棧組成。為了準備這個堆棧,我們首先濺射沉積一層85納米厚的Al0.8Sc0.2N模板在6英寸Si <100>晶圓的頂部。采用脈沖-直流無功濺射沉積單合金Al0.8Sc0.2N靶材料,靶功率為5 kW,壓力為7.47x10-3 mbar,沉積溫度為375℃,在N2氣氛中沉積了Al0.8Sc0.2N。第一層85 nm的Al0.8Sc0.2N將隨后80 nm厚的Al層定向為{111}取向。這一層Al (80 nm厚)作為第二層Al0.68Sc0.32N(45 nm厚)的底部電極,這是本器件使用的鐵電層。在Evatec CLUSTERLINE200 II脈沖直流物理氣相沉積系統中,45nm厚的鐵電Al0.68Sc0.32N薄膜從單獨的4英寸Al和Sc目標共濺射。Al和Sc靶分別在1250 W和695 W下工作,卡盤溫度350℃,Ar氣體流量10 sccm和N2氣體流量25 sccm。腔室壓力維持在~1.45x10-3 mbar。這種濺射條件導致沉積速率為0.3 nm/秒。高取向{111}Al層促進了AlScN的生長,其[0001]軸方向垂直于襯底,因此,產生了高紋理的FE薄膜。在不破真空的情況下,濺射出一層30 nm的Al層作為頂電極和蓋層,防止鐵電Al0.68Sc0.32N的氧化。
設備特征
使用Keithley 4200A半導體表征系統在環境溫度下的空氣中進行電流電壓測量。利用Keithley 4200A半導體表征系統和輻射精度Premier II測試平臺進行了FeD AlScN的P-E遲滯回線和PUND測量。在FEI Helios Nanolab 600聚焦離子束(FIB)系統中,采用原位提升技術制備TEM橫截面樣品。樣品被涂上薄薄的碳質保護層,用記號筆在表面寫上一條線。隨后使用電子束和離子束沉積鉑保護層,以防止FIB銑削過程中的電荷和加熱效應。在最后的清洗階段,低能的Ga+離子束(5 keV)用于減少fib誘導的損傷。在200kv加速電壓下運行的JEOL F200上進行了TEM表征和圖像采集。樣品定向于[001]區軸進行成像。所有捕獲的TEM圖像都是使用數字顯微軟件收集的。
審核編輯:湯梓紅
-
存儲器
+關注
關注
38文章
7623瀏覽量
166213 -
存內計算
+關注
關注
0文章
32瀏覽量
1475
原文標題:一種創新的存內計算架構
文章出處:【微信號:半導體科技評論,微信公眾號:半導體科技評論】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
存內計算芯片研究進展及應用
探索存內計算—基于 SRAM 的存內計算與基于 MRAM 的存算一體的探究

一種基于數字改良的SRAM設計存內計算方案
?什么是存內計算
開源芯片系列講座第24期:基于SRAM存算的高效計算架構






 工商網監
工商網監
評論