 使用Vitis HLS創建Vivado IP
使用Vitis HLS創建Vivado IP
使用Vitis HLS創建屬于自己的IP
副標題-FPGA高層次綜合HLS(三)-Vitis HLS創建Vivado IP
高層次綜合(High-level Synthesis)簡稱HLS,指的是將高層次語言描述的邏輯結構,自動轉換成低抽象級語言描述的電路模型的過程。
對于AMD Xilinx而言,Vivado 2019.1之前(包括),HLS工具叫Vivado HLS,之后為了統一將HLS集成到Vitis里了,集成之后增加了一些功能,同時將這部分開源出來了。Vitis HLS是Vitis AI重要組成部分,所以我們將重點介紹Vitis HLS。
官方指南:
https://docs.xilinx.com/r/_lSn47LKK31fyYQ_PRDoIQ/root
重要術語
LUT 或 SICE
LUT 或 SICE是構成了 FPGA 的區域。它的數量有限,當它用完時,意味著您的設計太大了!
BRAM 或 Block RAM
FPGA中的內存。在 Z-7010 FPGA上,有 120 個,每個都是 2KiB(實際上是 18 kb)。
Latency延遲
設計產生結果所需的時鐘周期數。
循環的延遲是一次迭代所需的時鐘周期數。
Initiation Interval (or II, or Interval間隔)
在接受新數據之前必須執行的時鐘周期數。
循環的間隔是可以開始循環迭代的最大速率,以時鐘周期為單位。
之前,我們一直在使用Vivado給我們提供的IP或者使用硬件描述語言制作 IP 。今天我們將講解如何使用HLS-高級綜合語言來創建屬于我們自己的IP。我們將使用的工具稱為Vitis HLS,此后稱為 HLS。HLS 采用 C 和 C++ 描述并將它們轉換為自定義硬件 IP,完成后我們就可以在 Vivado 項目中使用該IP。
Vitis HLS
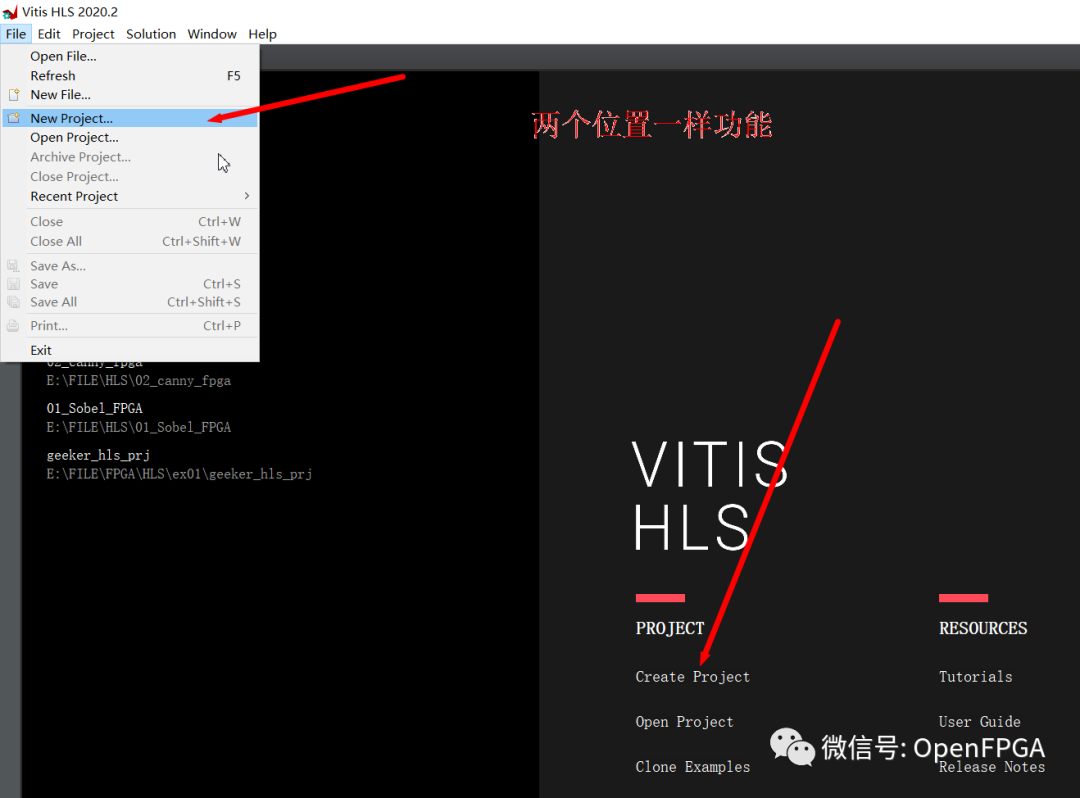
創建一個新的 HLS 項目:
通過從Linux 終端鍵入 vitis_hls 或從 Windows 開始菜單運行 HLS 。
PS:Linux系統下可能并沒有安裝到命令行,所以可能需要使用下面完整命令才能運行HLS:
/opt/york/cs/net/xilinx_vitis-2020.2/Vitis_HLS/2020.2/bin/vitis_hls
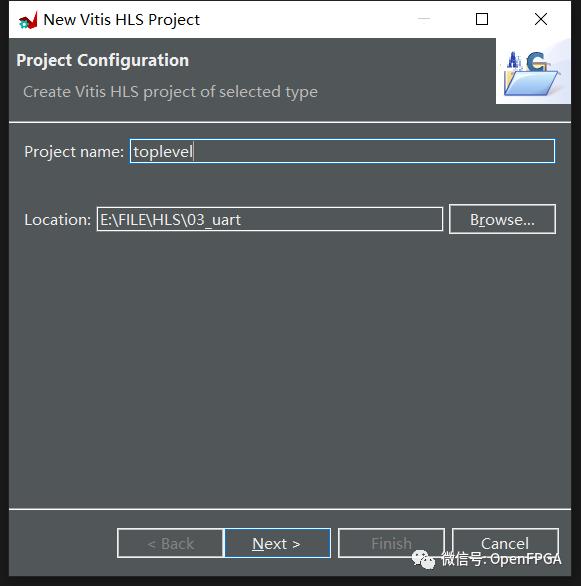
選擇創建新項目并為其指定合適的名稱和位置。同樣,請記住 Xilinx 工具不允許路徑或者名稱中有空格或者中文。點擊下一步。
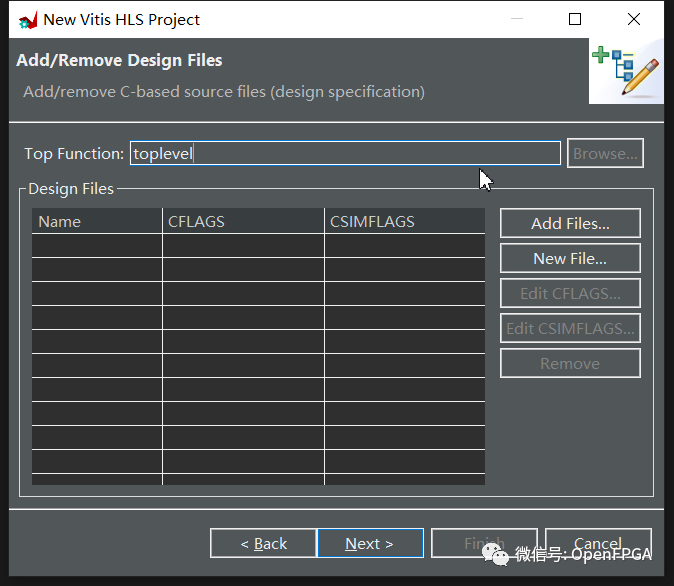
將頂部函數設置為 toplevel。點擊下一步。
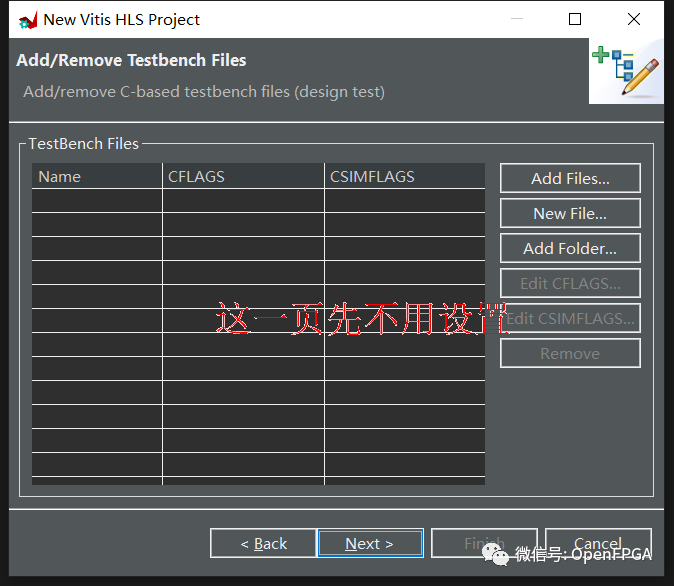
將時鐘周期設置為 10(以納秒為單位,因此對應于 100MHz 時鐘頻率,這是提供給 FPGA 架構的默認時鐘頻率)。
選擇FPGA到xc7z020clg484-2。
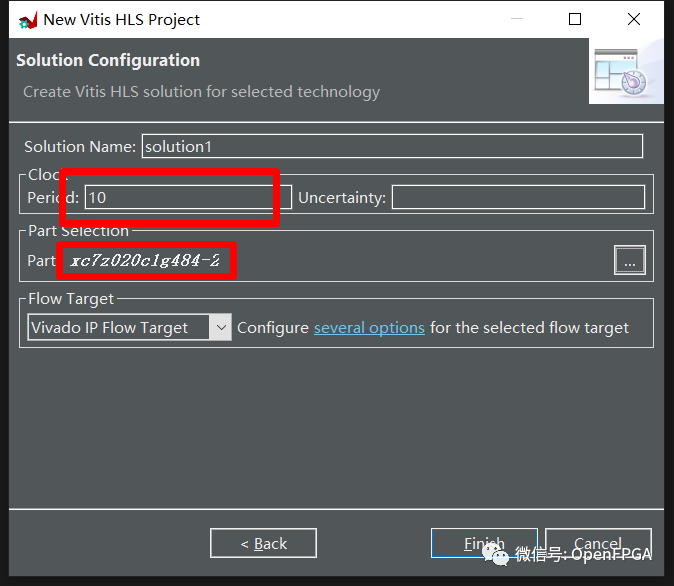
單擊完成。
現在我們就能看到一個 HLS 項目,但它是空的。創建兩個名為toplevel.cpp和toplevel.h
toplevel.cpp
#include"toplevel.h" //Inputdatastorage #defineNUMDATA100 uint32inputdata[NUMDATA]; //Prototypes uint32addall(uint32*data); uint32subfromfirst(uint32*data); uint32toplevel(uint32*ram,uint32*arg1,uint32*arg2,uint32*arg3,uint32*arg4){ #pragmaHLSINTERFACEm_axiport=ramoffset=slavebundle=MAXI #pragmaHLSINTERFACEs_axiliteport=arg1bundle=AXILiteS #pragmaHLSINTERFACEs_axiliteport=arg2bundle=AXILiteS #pragmaHLSINTERFACEs_axiliteport=arg3bundle=AXILiteS #pragmaHLSINTERFACEs_axiliteport=arg4bundle=AXILiteS #pragmaHLSINTERFACEs_axiliteport=returnbundle=AXILiteS readloop:for(inti=0;i
toplevel.h
#ifndef__TOPLEVEL_H_ #define__TOPLEVEL_H_ #include#include #include //Typedefs typedefunsignedintuint32; typedefintint32; uint32toplevel(uint32*ram,uint32*arg1,uint32*arg2,uint32*arg3,uint32*arg4); #endif
檢查文件
toplevel.cpp 包含整個 EMBS 結構。toplevel函數有五個uint32類型的參數。在typedef.h中描述寬度為32位的無符號整數。
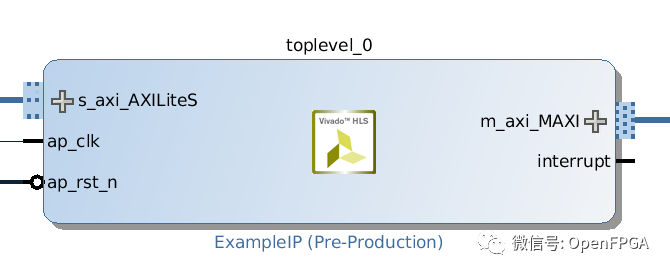
該文件還包含被HLS稱為指令的雜注。指令用于告訴HLS如何制作硬件。這里的指令告訴HLS創建AXI主接口和AXI從接口。主接口允許組件訪問主存儲器,從接口允許ARM內核傳入一些變量,并啟動、復位和停止組件。一旦構建完成并導出硬件IP,IP將在Vivado中顯示如下:
注意三個重要的事情:
沒有 main 函數。
我們已經聲明了一個函數 toplevel。這將是硬件的“入口點”。
代碼中的循環被賦予了標簽(readloop、addloop和subloop)。軟件中大多數程序員都不這樣做,但它在HLS中很有用,稍后您我們將講解。
測試組件
硬件綜合需要的時間比較長。因此,在構建硬件之前,應該充分的驗證我們設計的硬件是正確的。測試平臺是其中的重要組成部分。測試平臺測試代碼的功能屬性,以確保它不包含任何邏輯錯誤并且它大致符合要求。因為測試平臺是在軟件中模擬的,所以無法測試最終硬件的速度。
在 HLS 中,右鍵單擊左側資源管理器中的“Test Bench”,然后選擇“New File”。命名testbench.cpp 并將其放在合理的地方(與之前的toplevel.h文件相同的文件夾中,否則將需要編輯 #include 以獲得頭文件的相對路徑)。
復制以下代碼:
testbench.cpp
#include"toplevel.h" #defineNUMDATA100 uint32mainmemory[NUMDATA]; intmain(){ //Createinputdata for(inti=0;i
注意事項:
我們將一塊內存聲明為“主內存”。在實際系統中,這是 Z7 板上的 1GB DDR 內存,但對于測試平臺,我們只需分配一個足夠大的ARRAY即可滿足我們的目的。
如果一切正常,測試平臺應該返回 0。它將從硬件返回的值與預先計算的值對比,以確保是正確的。
要運行測試平臺,請選擇 Project | 運行 C Simulation 并在出現的對話框中單擊確定。應該會看到 HLS 做了很多工作,但最終會看到測試平臺的輸出。
Sumofinput:12950 Values1to99subtractedfromvalue0:3050 INFO:[SIM211-1]CSimdonewith0errors. INFO:[SIM211-3]***************CSIMfinish*************** INFO:[HLS200-111]FinishedCommandcsim_designCPUusertime:0seconds.CPUsystemtime:0seconds.Elapsedtime:4.582seconds;currentallocatedmemory:191.719MB. FinishedCsimulation.
我們已經驗證了我們的設計。(如果需求,應該更嚴格地測試一個真實的設計!)
高層次綜合
所以現在我們有了一個仿真好的設計,我們需要研究如何將其轉化為硬件。在窗口的右上角,應該看到一行三個按鈕-Debug, Synthesis, 和 Analysis(調試、合成和分析)。
這些是透視圖,我們將通過單擊它們切換。單擊合成按鈕以確保處于合成透視圖中。
打開 toplevel.cpp. 現在單擊Solution | Run C Synthesis | C Synthesis(或單擊工具欄中的綠色箭頭)。將開始進行綜合(綜合是將 C++ 描述轉化為硬件的過程)。
綜合完成后,將打開綜合報告窗口。這會告訴有關剛剛構建的設計的所有信息。在 Performance Estimates下 查看 Latency 摘要。這應該類似于:
該報告說明設計具有 709 個時鐘周期的總體延遲(從第一個數據輸入到最后一個數據輸出的時間)。它的間隔是 710,這是從一次運行的第一個數據到設計能夠接受另一次運行的第一個數據的周期數。
在toplevel行下方,它顯示了代碼中的三個循環(說明為什么給它們標簽是有用的)。循環的延遲是完成所需的周期數。有時 HLS 不會知道這一點(例如,如果循環變量不是靜態的)。迭代延遲是一次迭代所花費的周期數。啟動間隔僅對流水線循環有效(見下文),行程計數是將計算的迭代總數。
與性能一樣重要的是利用率。進一步查看利用率摘要,將看到設計在 FF(觸發器)和 LUT(查找表)中的用法。這些是可重構邏輯的度量。還有 DSP(數字信號處理)單元和 BRAM(Block RAM)。Block RAM 是整個 FPGA 架構中非常高速的內存小塊。可以在單個時鐘周期內讀取或寫入它們,但每個時鐘周期每個 Block RAM 最多可訪問兩次。這些數字脫離上下文可能有點無意義,因此可以單擊表格上方的 % 符號將這些數字轉換為 FPGA 的百分比。
上表中主要注意的是 BRAM 和 FF/LUT。此表有助于對大部分設計使用資源的位置進行粗略分類匯總。隨著設計變得越來越復雜,可以進一步檢查資源以獲取更詳細的信息。
使用指令調整綜合
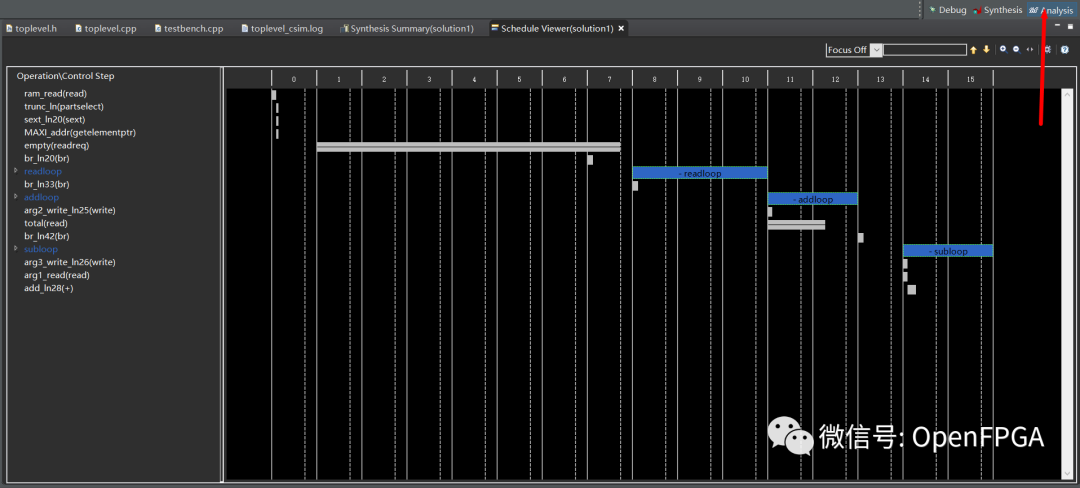
上邊的設計整體看還可以,但可以通過指令進行進一步優化。首先,讓我們仔細看看設計是如何實現的。單擊“ Analysis”按鈕(右上角)轉到“ Analysis”透視圖。這應該會打開一個性能選項卡。
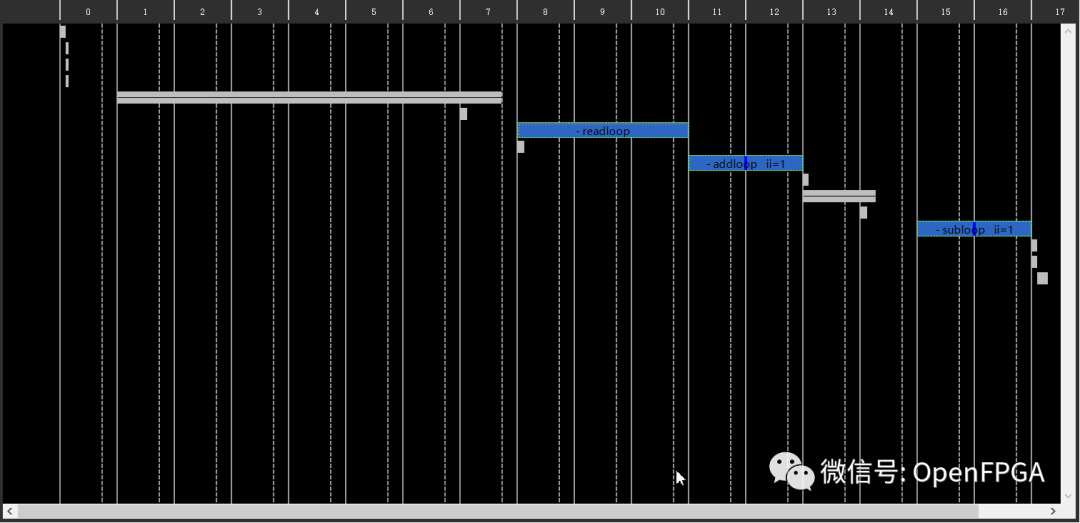
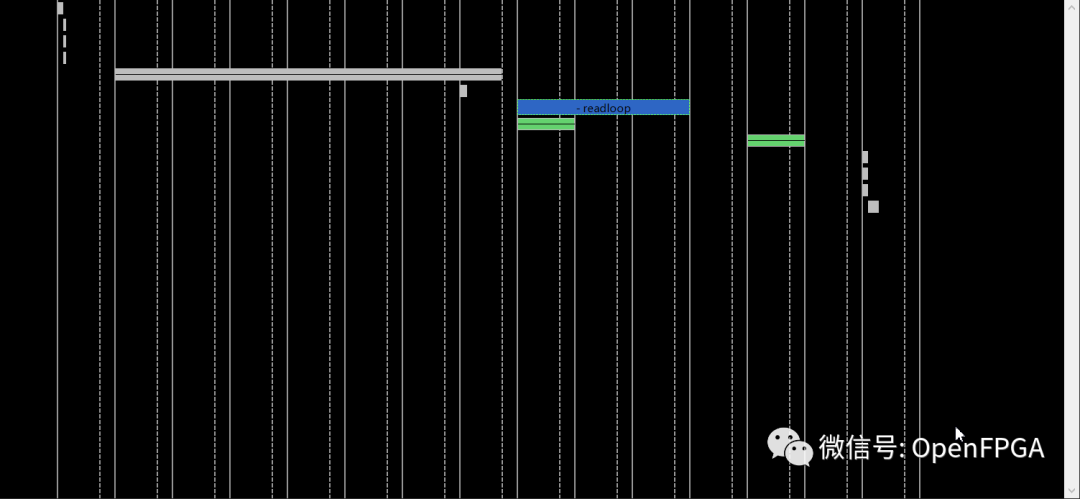
這些行是來自已編譯代碼的操作。列是狀態,因此垂直查看會顯示并行發生的所有進程,如果兩件事在同一列中,它們會并行發生。目前我們可以看到addloop和subloop循環不重疊,因此它們不是并行完成的。還要注意,addloop和subloop有兩種狀態。這對應于我們從綜合報告中得到的性能估計,該報告告訴我們這兩個循環的迭代延遲都是2。
這是因為我作弊了,對不起!
HLS 實際上會做得更好,但我在上面的代碼中包含了一些指令,故意關閉一些優化,以便我們更好地了解它們的作用。我們將在下一節中撤消它。可以完全展開每個循環以查看在每個狀態下發生的各個操作。還可以右鍵單擊操作并選擇 Goto Source 以查看創建它的 C++ 代碼行,或者將創建實際 FPGA 硬件的生成的 Verilog 或 VHDL 行。
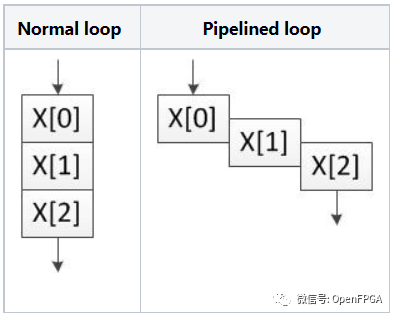
流水線循環
我們要做的第一個優化是告訴 HLS 流水線 addloop 和 subloop,它們都有兩種狀態,因此它們可以同時處理兩個數據元素。沒有流水線,一次只能運行一個迭代,如這些圖所示。
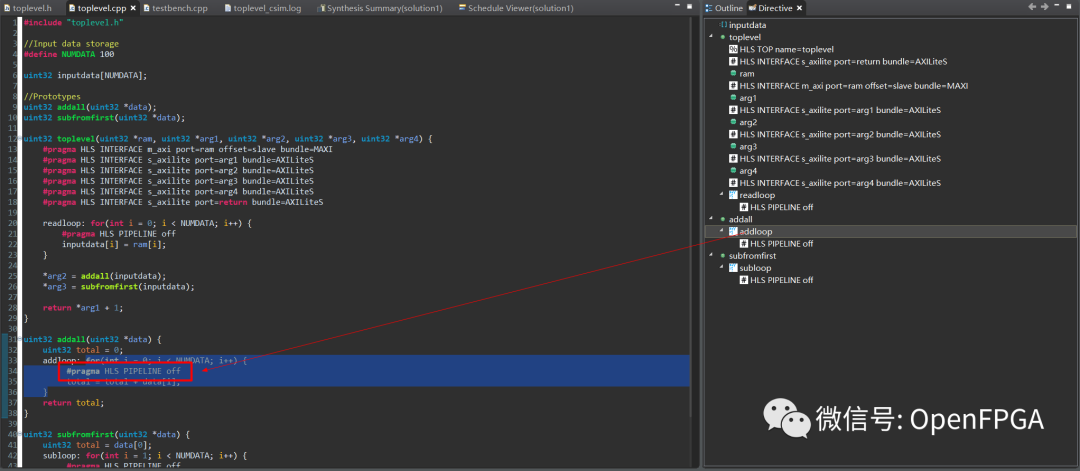
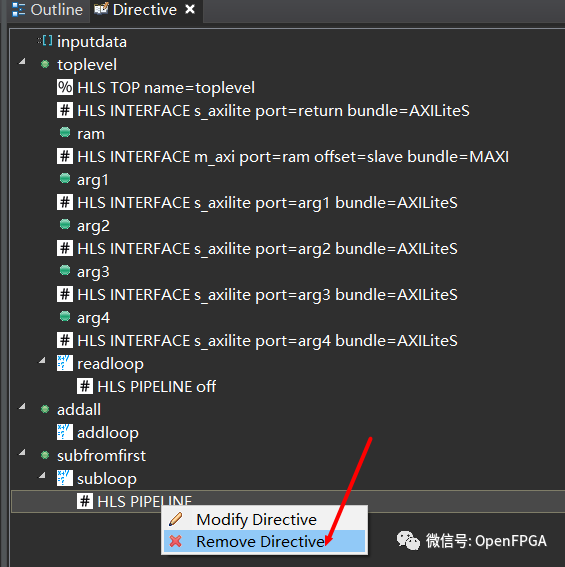
關閉性能報告并返回Synthesis透視圖。打開 toplevel.cpp并選擇右側的 Directive 選項卡(或 Window → Show View → Directive)。此選項卡顯示源文件中可以附加指令的項目。查找addloop,并注意我包含了指令“HLS PIPELINE off”。這告訴它不要PIPELINE循環。
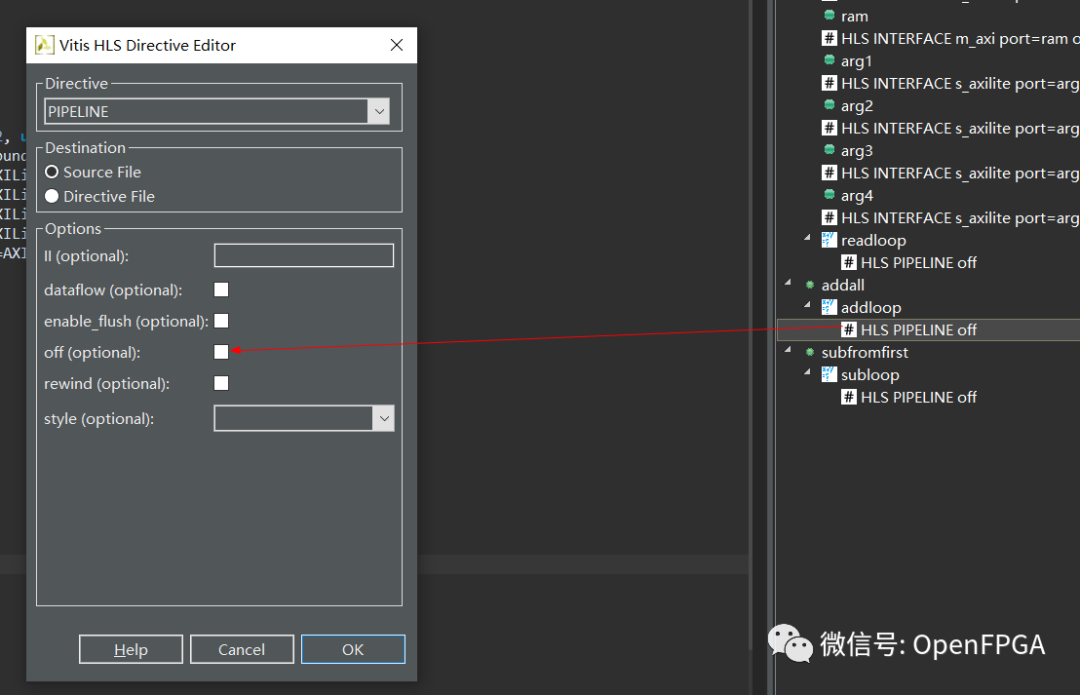
雙擊該指令并在彈出的對話框中取消選中“關閉”。接下來,重復subloop指令。
保存文件并重新運行綜合(單擊綠色箭頭)。完成后查看報告。我們立即看到設計的延遲現在是 512 個周期,低于之前的710個。這是因為兩個循環同時處理多個數據項。
在綜合報告中,將看到兩個循環現在已流水線化,它們的 Initiation Interval 現在為 1。這意味著每個時鐘周期都可以將數據項推入循環。它們的行程計數(它們執行的次數)是 100 和 99,因此它們的延遲是 100 和 99 個周期,低于之前的 200 和 198。
單擊Analysis透視圖。流水線還是沒有使循環并行發生。速度提升來自于數據項被更快地推入循環的事實。關閉 Performance 選項卡并返回 Synthesis 透視圖。
展開循環
比流水線循環更有效地操作是展開它們。UNROLL 指令告訴 HLS 嘗試并行執行循環的各個迭代。 這是非常快的,但根據展開的級別可能會花費更多的硬件資源。
在 Synthesis 透視圖中, toplevel.cpp 右鍵單擊 addloop 和 subloop 循環上的 PIPELINE 指令并刪除它們。有時,上述操作會導致 HLS 弄亂源代碼,如果是,請修復它。
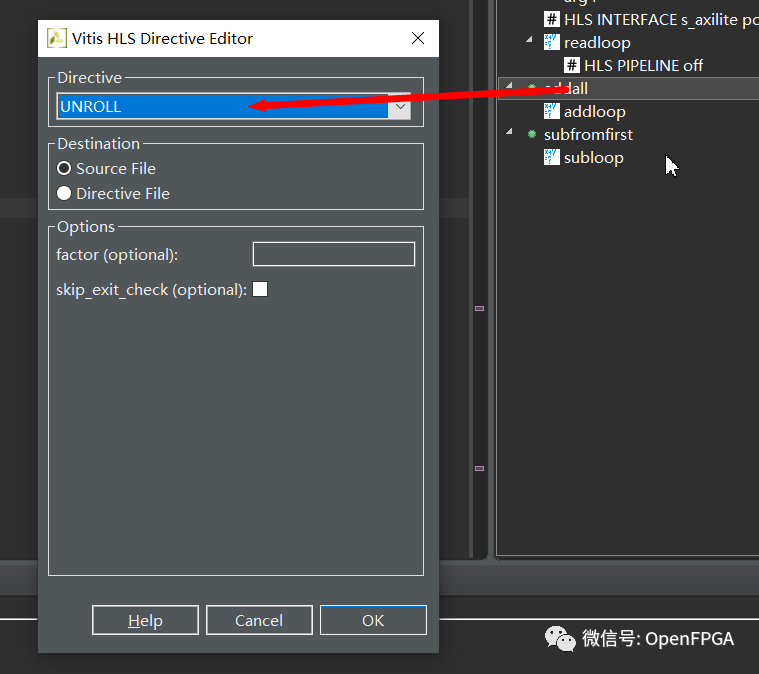
右鍵單擊 addloop 指令面板中的循環,然后選擇插入指令,選擇 UNROLL。
添加指令時,可以選擇將指令放在源文件中(作為#pragma指令)或單獨的指令文件。我更喜歡使用指令文件,但總的來說沒關系。
我們可以在此處添加一個因素來限制展開,但讓其留空以表示盡可能展開。單擊subloop并重復上訴操作 ,再綜合。
現在我們的設計延遲降低到大約 415 個周期,這意味著我們的整體運行速度幾乎是原始設計(沒有指令)的兩倍。然而,我們現在使用了大約 7200 個 LUT——我們的大小超過了 3 倍!HLS 還決定使用 4 個 Block RAM 作為內存而不是 1 個,以便可以并行訪問更多數據。這是一個經典的速度/資源權衡,請注意,如果在綜合報告中展開“Loop”,則現在只有 readloop。另外兩個不見了,因為它們已經完全展開。
單擊Analysis透視圖。我們的設計看起來完全不同!
我們注意到的第一件事是函數是可見的。這是因為以前函數非常簡單,HLS已經自動內聯了它們。現在它們是巨大的硬件,所以它沒有。因此,硬件在啟動subfromfirst函數之前完成addall函數。讓我們強制它內聯這些函數,這樣它就可以將兩個函數的操作安排在一起。將INLINE指令添加到addall和subfromfirst函數中,然后重新綜合。
現在我們減少到 364 個周期,并且我們節省了一些硬件,因為 HLS 已經能夠優化這兩個功能。盡管如此,我們仍然可以做得更好!
為 LUT 交換 Block RAM
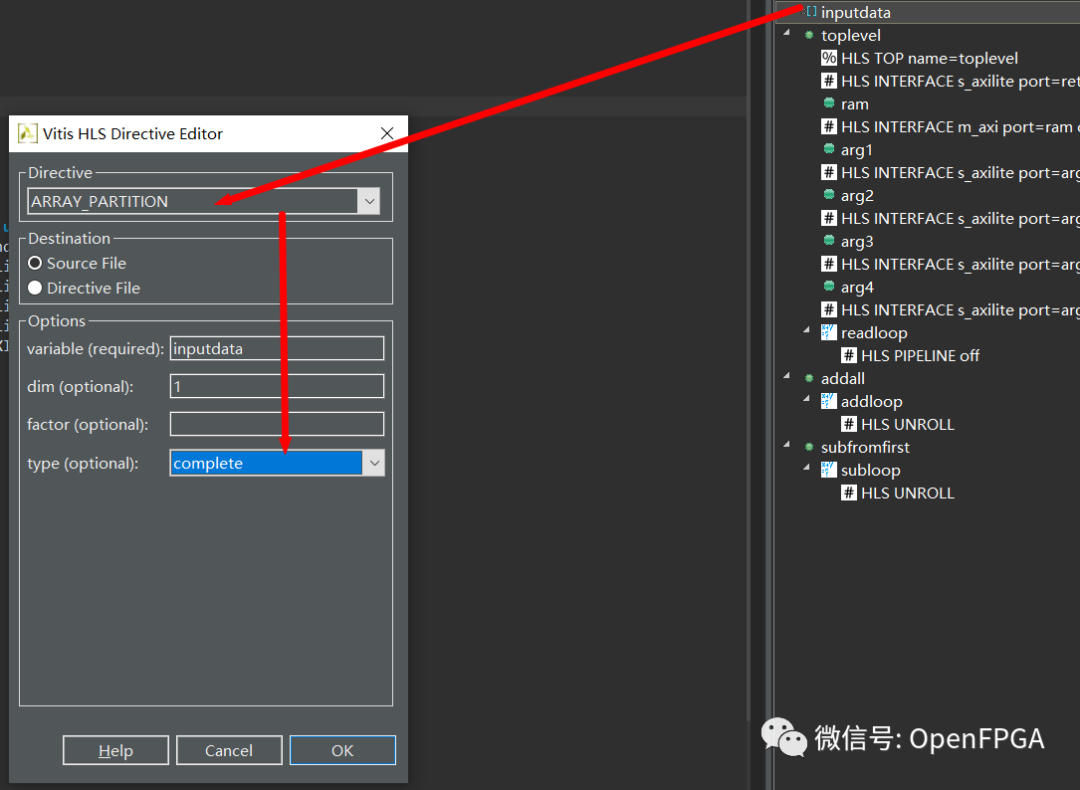
讓我們告訴 HLS 不要使用 Block RAM,而只使用普通寄存器。在某些設計中,Block RAM 非常 昂貴,但它將允許真正的并行訪問。 關閉 Performance 選項卡并返回 Synthesis 透視圖。右鍵單擊 inputdata 指令選項卡并選擇插入指令。插入 ARRAY_PARTITION 類型的指令 complete。它將詢問將其應用于哪個功能。選擇 toplevel。
此外,也適用 UNROLL 于 readloop ,因此我們可以完全利用分布式 RAM。
你應該有上面的指令,再綜合。
我們現在只有 333 個周期的微小設計延遲。因為設計讀取 100 個數據項,我們知道我們的設計永遠不會快于 101 個周期,所以這非常好!另請注意,現在我們的 Block RAM 數量減少了,我們的LUT 使用量再次增加。通常ARRAY_PARTITION會顯著增加 LUT 的使用,但在這種情況下,我們之前的設計有很多中間存儲寄存器,我們基本上已經在這樣做了,所以增加并不算太糟糕。請記住,第一次展開使我們的 LUT 使用量增加了 3 倍。這表明了試驗指令的重要性,并使用分析視角來計算并行發生的事情。
所以我們現在有一個非常快的設計,但如果我們需要通過流水線而不是展開來使其更小(和更慢),我們也知道如何使其更小(和更慢)。
真正實現它
我們現在將使用測試平臺純粹在 HLS 內部工作。以后的實踐將采用 HLS 設計并將它們連接到 ARM 處理系統。
總結
這是《FPGA高層次綜合HLS》系列教程第三篇,后面會按照專題繼續更新,文章有什么問題,歡迎大家批評指正~感謝大家支持。
審核編輯:彭靜





-
硬件
+關注
關注
11文章
3459瀏覽量
67181 -
電路模型
+關注
關注
1文章
43瀏覽量
9713 -
Vivado
+關注
關注
19文章
828瀏覽量
68205
原文標題:使用Vitis HLS創建屬于自己的IP
文章出處:【微信號:Open_FPGA,微信公眾號:OpenFPGA】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
怎么在vivado HLS中創建一個IP
使用Vitis HLS創建屬于自己的IP相關資料分享
如何創建Vivado HLS項目
如何在Vitis HLS中使用C語言代碼創建AXI4-Lite接口
Vivado HLS和Vitis HLS 兩者之間有什么區別
Vitis初探—1.將設計從SDSoC/Vivado HLS遷移到Vitis上的教程
Vitis初探—1.將設計從SDSoC/Vivado HLS遷移到Vitis上
如何導出IP以供在Vivado Design Suite中使用?
基于Vitis HLS的加速圖像處理
Vitis HLS工具簡介及設計流程
使用AXI4-Lite將Vitis HLS創建的IP連接到PS
Vitis HLS知識庫總結
AMD全新Vitis HLS資源現已推出





 工商網監
工商網監
評論