 回顧歷史,從串行計算到并行計算
回顧歷史,從串行計算到并行計算
小編說:回顧計算機的發展歷史,從串行到并行,從同構到異構,接下來會持續進化到超異構:第一階段,串行計算。單核CPU和ASIC等都屬于串行計算。 第二階段,同構并行計算。CPU多核并行和GPU數以千計眾核并行均屬于同構并行計算。 第三階段,異構并行計算。CPU+GPU、CPU+FPGA、CPU+DSA以及SOC都屬于異構并行計算。(SOC屬于異構的原因是,其他所有引擎的處理都是在CPU的控制之下,其他引擎難以直接數據通信。) 未來,將走向第四階段,超異構并行階段。把眾多的CPU+xPU“有機”集成起來,形成超異構。
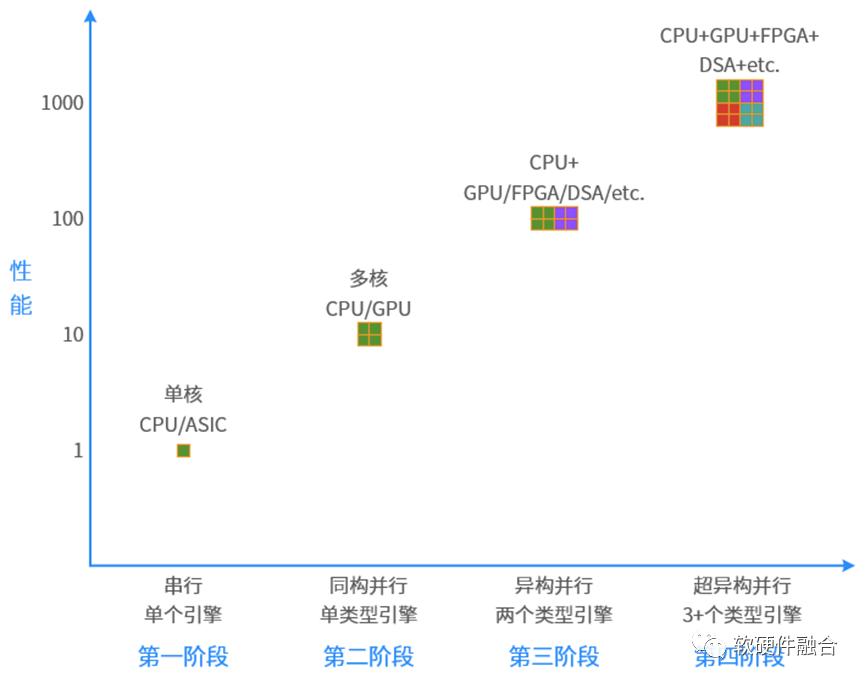
圖源:軟硬件融合 
回顧歷史,從串行計算到并行計算
① 串行計算和并行計算
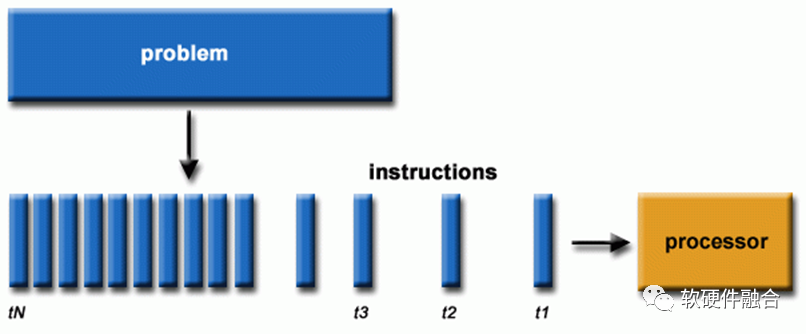
圖源:軟硬件融合軟件一般是為串行計算編寫的:① 一個問題被分解成一組指令流; ② 在單個處理器上執行; ③ 指令是依次執行的(處理器內部可能存在非依賴指令亂序,但宏觀效果上依然是串行指令流的執行)。
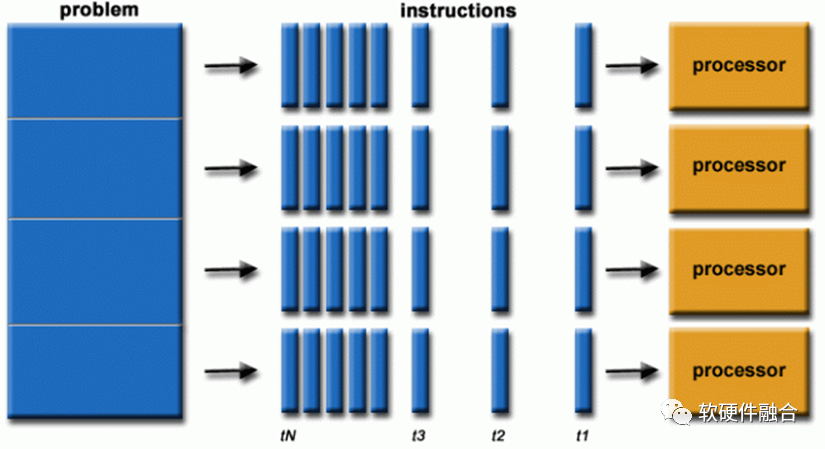
圖源:軟硬件融合
并行計算就是同時使用多個計算資源來解決一個計算問題:①一個問題被分解成可以同時解決的部分; ②每個部分進一步分解為一系列指令; ③每個部分的指令在不同的處理器上同時執行; ④需要采用整體控制/協調機制。 計算的問題應該能夠:分解成可以同時解決的離散工作;隨時執行多條程序指令;使用多個計算資源比使用單個計算資源在更短的時間內解決問題。 計算的資源通常是:具有多個處理器/內核的單臺計算機;通過網絡(或總線)連接的任意數量的此類計算機。
② 多核CPU和眾核GPU
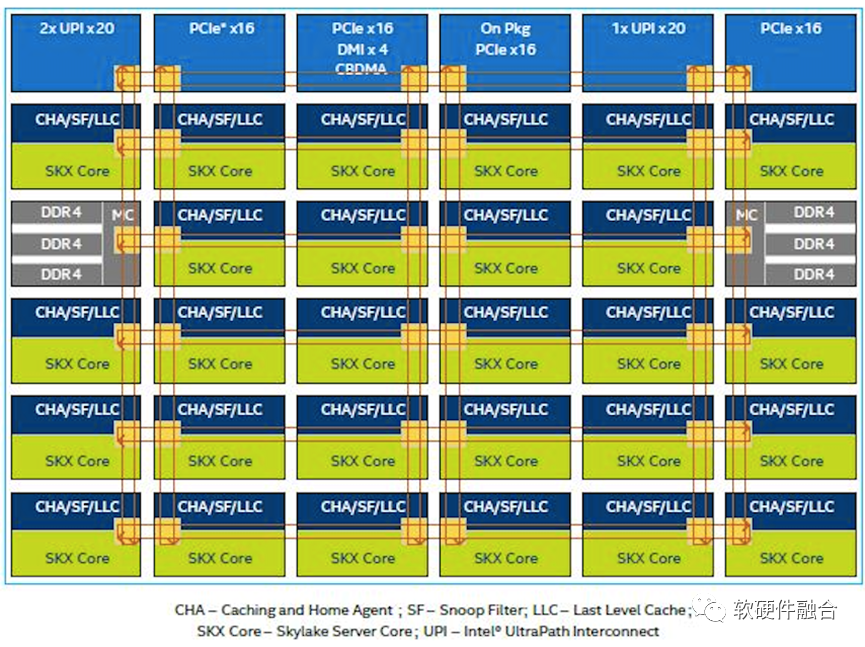
圖源:軟硬件融合
如上圖,是Intel Xeon Skylake的內部架構。可以看到,此CPU是由28個CPU核組成的同構并行。
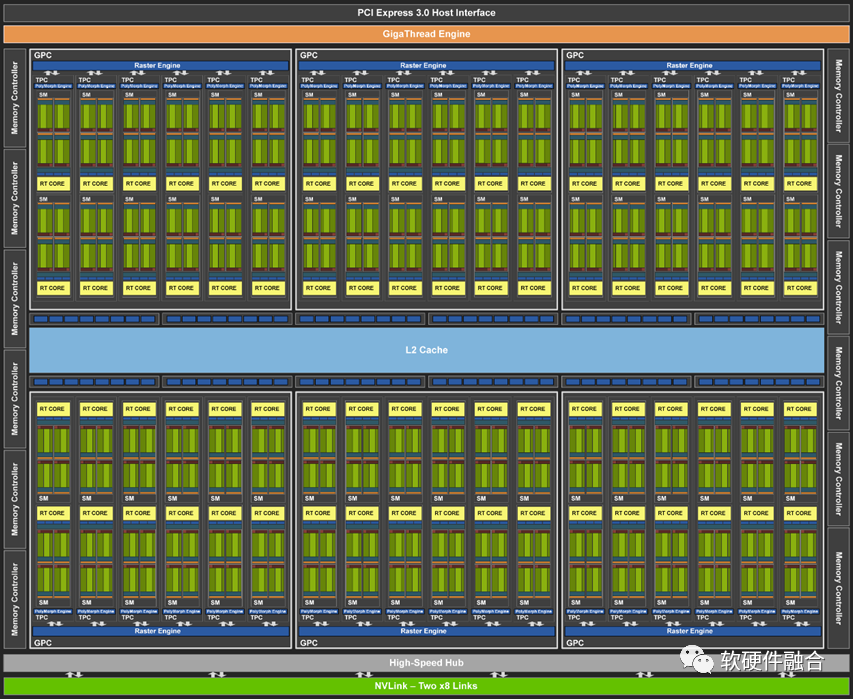
圖源:軟硬件融合 上圖是NVIDIA發布的圖靈架構GPU,此架構GPU的核心處理引擎由如下部分組成:6個圖形處理簇(GPC);每個GPC有6個紋理處理簇(TPC),共計36個TPC;每個TPC有2個流式多核處理器(SM),總共72個SM。每個SM由64個CUDA核、8個Tensor核、1個RT核、4個紋理單元。 因此,圖靈架構GPU總計有4608個CUDA核、576個Tensor核、72個RT核、288個紋理單元。 需要注意的是:GPU非圖靈完備,無法單獨運行,需要和CPU一起,通過CPU+GPU的異構方式才能工作。因為CPU是圖靈完備的,可以自主運行,因此,存在基于多核CPU組成的CPU芯片是同構并行的。
從同構并行到異構并行,異構計算蓬勃發展
① 同構并行和異構并行

圖源:軟硬件融合
但是,不存在除CPU外其他處理器引擎單獨存在的并行計算系統,如GPU、FPGA、DSA、ASIC等引擎同構并行的系統。因為這些處理引擎/芯片是非圖靈完備的,它們都是作為CPU的加速器而存在。因此,其他處理引擎的并行計算系統即為CPU+xPU的異構并行,大體分為三類: ①CPU+GPU。CPU+GPU是目前流行的異構計算系統,在HPC、圖形圖像處理以及AI訓練/推理等場景得到廣泛應用。 ②CPU+FPGA。目前數據中心流行的FaaS服務,利用FPGA的局部可編程能力,基于FPGA開發運行框架,以及借助第三方ISV支持或自研的方式,構建面向各種應用場景的FPGA加速解決方案。 ③CPU+DSA。谷歌TPU是DSA架構處理器,TPUv1采取獨立加速器的方式,實現CPU+DSA(TPU)的方式實現異構并行。 此外,需要說明的是,由于ASIC功能固定,缺乏一定的靈活適應能力,因此不存在CPU+單個ASIC的異構計算。CPU+ASIC形態通常是CPU+多個ASIC組,或在SOC中,作為一個邏輯上獨立的異構子系統存在的,需要與其他子系統協同工作。

圖源:軟硬件融合
SOC本質上也是異構并行,SOC可以看做是CPU+GPU、CPU+ISP、CPU+Modem等多個異構并行子系統組成的系統。
超異構也可以看做是由多個邏輯上獨立的異構子系統有機組成的,但SOC和超異構不同:SOC的不同模塊通常無法直接高層次數據通信,而是通過CPU調度才能間接通信。SOC和超異構的區別會在超異構部分詳細介紹。
② 基于CPU+GPU的異構并行
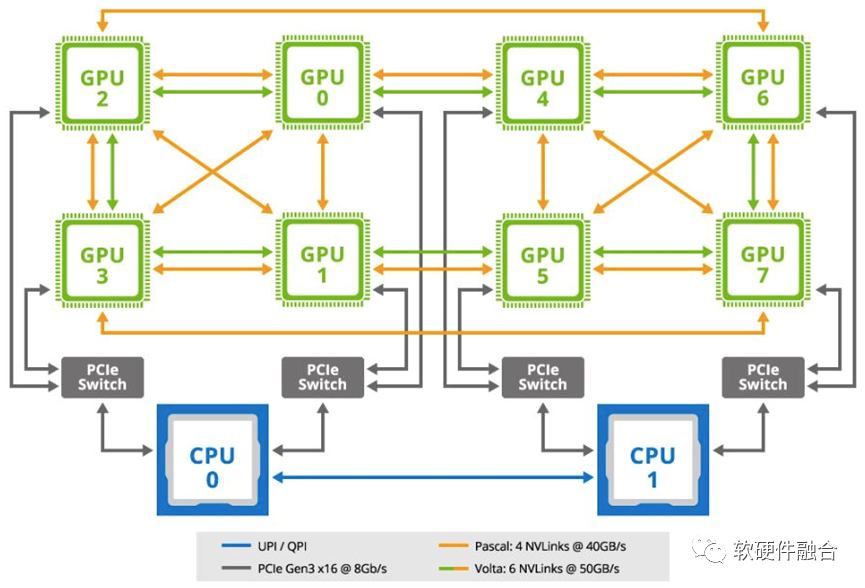
圖源:軟硬件融合
如圖所示,是典型的用于機器學習場景的GPU服務器主板拓撲結構,是一個典型的SOB(System on Board,板級系統)。在此GPU服務器的架構里,通過主板,連接了兩個通用CPU和8個GPU加速卡。兩個CPU通過UPI/QPI相連;每個CPU通過兩條PCIe總線,分別連接1個PCIe交換機;每個PCIe交換機再連接到兩個GPU;另外,GPU間還通過NVLink總線相互連接。
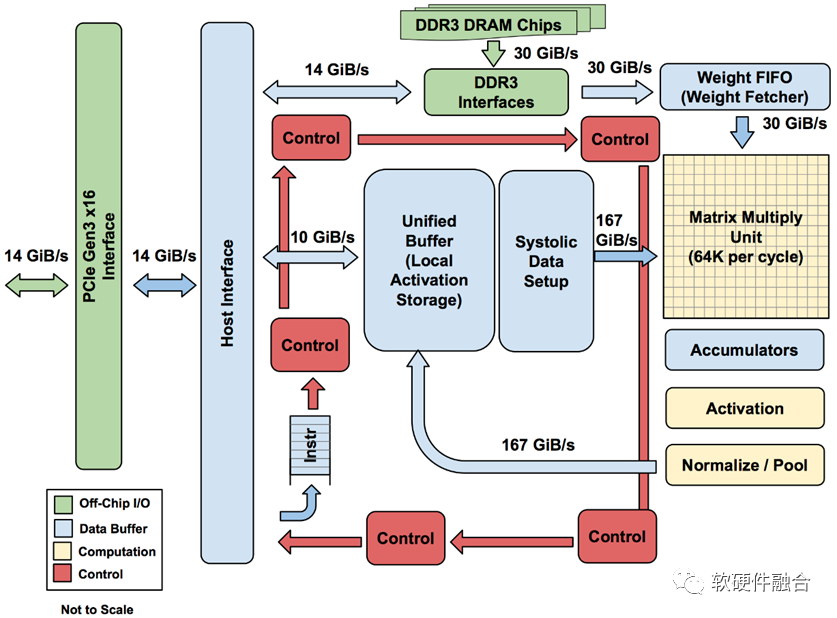
圖源:軟硬件融合
TPU是業界第一款DSA架構芯片,上圖是TPU v1的結構框圖。TPU v1通過PCIe Gen3 x16總線和CPU相連,從CPU發送指令到TPU的指令緩沖區,由CPU控制TPU的運行;數據交互在兩者的內存之間進行,由CPU發起控制,TPU的DMA執行具體的數據搬運。
從異構持續進化到超異構
① CPU、GPU、DPU、AI等大算力芯片面臨的共同挑戰
在云計算、邊緣計算、終端超級計算機(如自動駕駛)等復雜計算場景,對芯片的可編程能力要求非常高,甚至高過對性能的要求。如果不是基于CPU的摩爾定律失效,數據中心依然會是CPU的天下(雖然CPU的性能效率是低的)。
性能和靈活可編程性,是影響大算力芯片大規模落地非常重要的兩個因素。兩者如何均衡,甚至兼顧,是大芯片設計永恒的話題。
CPU、GPU、DPU、AI等大算力芯片,面臨著共同的挑戰,包括:
①單類型引擎性能和靈活性的矛盾。CPU靈活性好,但性能不夠;ASIC性能優質,但靈活性不夠。
②不同用戶的業務差異以及用戶的業務迭代。針對這一問題,目前主要做法是針對場景定制。通過FPGA定制,規模太小,成本和功耗太高;通過芯片定制,導致場景碎片化,芯片難以大規模落地,難以攤薄成本。
③宏觀算力要求芯片能夠支撐大規模部署。宏觀算力與單位芯片算力,以及芯片的落地規模成正比。但各類性能提升的方案會損失可編程靈活性,使得芯片難以實現大規模部署,從而進一步影響宏觀算力的增長。典型的例子就是目前AI芯片的大規模落地困難。
④芯片的一次性成本過高。數以億計的NRE成本,需要芯片的大規模落地,才能夠攤薄一次性成本。這就需要芯片足夠“通用”,在很多場景可以落地。
⑤生態建設的門檻。大芯片需要框架和生態,門檻高且需要長期積累,小公司難以長期大量投入。
⑥計算平臺的融合。云網邊端融合,需要構建統一的硬件平臺和系統堆棧。
⑦等等......
② 解決方案,把異構計算的孤島連接在一起,形成超異構
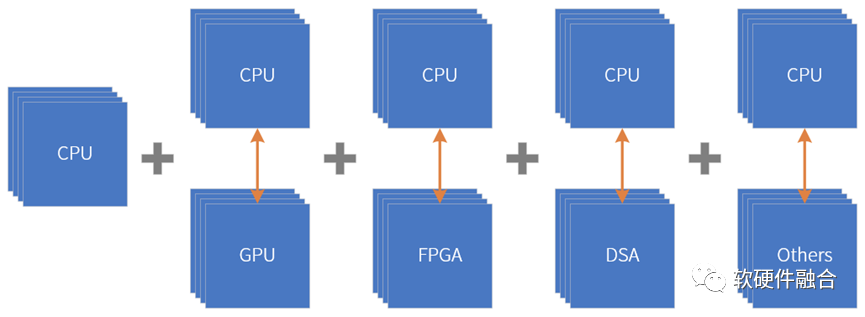
圖源:軟硬件融合
超異構可以看做是CPU+CPU的同構并行和CPU+其他xPU的異構并行“有機”組合到一起,形成的一個新的超大系統。
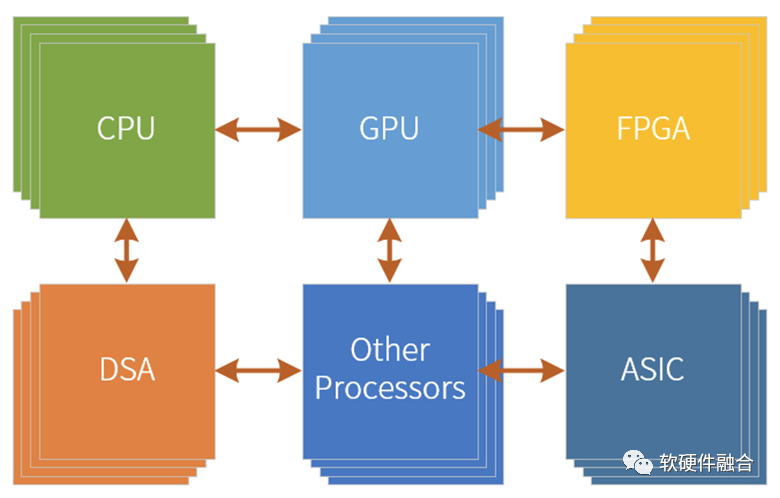
圖源:軟硬件融合
超異構是由CPU、GPU、FPGA、DSA、ASIC以及其他各種加速引擎“有機”組成的新的宏系統。
③ 超異構和SOC的不同之處超異構處理器HPU,可以算是SOC,但又跟傳統的SOC有很大的不同。如果無法認識到這些不同,就無法理解到HPU的本質。下表是一些典型的差異性對比。
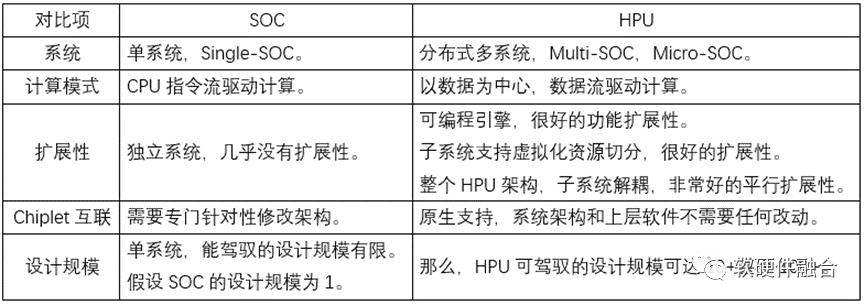
圖源:軟硬件融合
為什么是現在(才興起超異構計算)?
① 基于CPU的摩爾定律失效,引發連鎖反應
系統越來越復雜,需要選擇越來越靈活的處理器;而性能挑戰越來越大,需要我們選擇定制加速的處理器。這是一對矛盾,拉扯著我們的各類算力芯片設計。本質矛盾是:單一處理器無法兼顧性能和靈活性,即使我們拼盡全力平衡,也只“治標不治本”。
CPU靈活性很好,在符合性能要求的情況下,在云計算、邊緣計算等復雜計算場景,CPU是優質的處理器。但受限于CPU的性能瓶頸,以及對算力需求的持續不斷上升,(站在算力視角)CPU逐漸成為了非主流的算力芯片。
CPU+xPU的異構計算,由于主要算力是由xPU完成,因此,xPU的性能/靈活性特征,決定了整個異構計算的性能、靈活性特征:
①CPU+GPU的異構計算。雖然在足夠靈活的基礎上,能夠滿足(相對CPU的)數量級的性能提升,但算力效率仍然無法做到更優質。
②CPU+DSA的異構計算。由于DSA的靈活性較低,因此不適合應用層加速。典型案例是AI,目前主要是由基于CPU+GPU完成訓練和部分推理,DSA架構的AI芯片目前還沒有大范圍落地。
② Chiplet技術成熟,量變引起質變:需要架構創新,而不是簡單集成
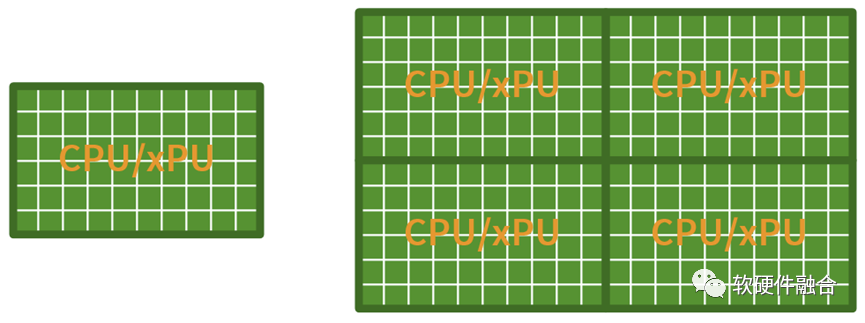
圖源:軟硬件融合
假設,在沒有Chiplet的時候,我們的CPU或xPU可以集成50個核,有了Chiplet互聯,把4個DIE拼起來,我們就可以單芯片集成200個核心。 但是,上圖的平行擴展方式,真的就是Chiplet的價值嗎? 結論是,這樣的Chiplet集成,暴殄天物!

圖源:軟硬件融合
Chiplet使得我們在單個芯片的層次,可以構建規模數量級提升的超大系統。這樣,我們可以利用大系統的一些“特點”,來進一步優化。這些特點是:
①復雜系統是由分層分塊的任務組成;
②基礎設施層的任務,相對確定,適合放在DSA/ASIC。可以在滿足任務基本靈活性的基礎上,極限的提升性能;
③應用不可加速部分的任務,不確定,適合CPU。系統符合二八定律,用戶關心的應用只占整個系統的20%,而不可加速部分,占比通常會少于10%。為了提供用戶優質的體驗,這部分任務建議放在CPU上。
④應用可加速部分的任務,由于應用的算法差異化和迭代較大,適合放在GPU、FPGA等彈性加速引擎。可以提供足夠靈活可編程的同時,可以提供盡可能好的性能。
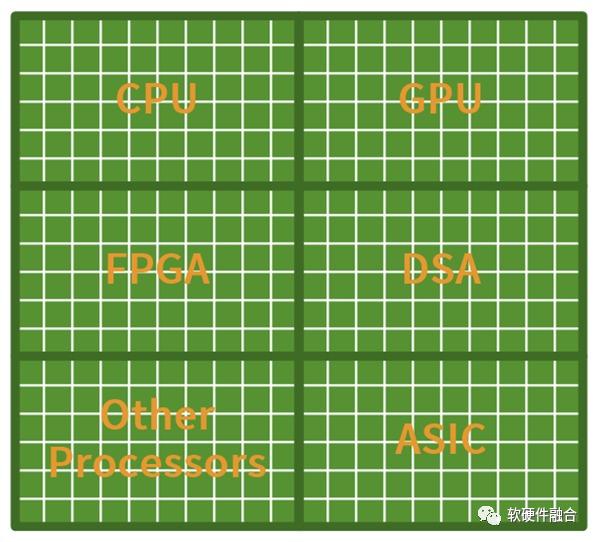
圖源:軟硬件融合
這樣,基于超異構實現的整個系統:
①從宏觀視角看,80%甚至90%以上的計算,都是在DSA中完成。這樣,整個系統是接近于DSA/ASIC的優質性能;
②用戶關心的應用不可加速部分,只占10%以內,依然運行在CPU上。也即用戶看到的仍然是100%的CPU級別的靈活可編程性。
也即,通過超異構架構,可以在實現靈活性的同時,實現優質的性能。
③ 超異構更難駕馭,需要創新的理念和技術
異構編程很難,NVIDIA經過數年的努力,才讓CUDA的編程對開發者足夠友好,形成了健康的生態。超異構就更是難上加難:超異構的難,不僅僅體現在編程上,也體現在處理引擎的設計和實現上,還體現在整個系統的軟硬件能力整合上。那么,該如何更好的駕馭超異構?經過慎重思考,我們從以下幾個方面入手:
①性能和靈活性。從系統的角度,系統的任務從CPU往硬件加速下沉,如何選擇合適的處理引擎,達到優質性能的同時,有優越的靈活性。并且不僅僅是平衡,更是兼顧。
②編程及易用性。系統逐漸從硬件定義軟件,轉向了軟件定義硬件。如何利用這些特征,如何利用已有軟件資源,以及如何融入云服務。
③產品。用戶的需求,除了需求本身之外,還需要考慮不同用戶需求的差異性,和單個用戶需求的長期迭代。該如何提供給用戶更好的產品,滿足不同用戶短期和長期的需求。授人以魚不如授人以漁,該如何提供用戶沒有特定的具體功能的、性能優質的、完全可編程的硬件平臺。
④等等。
軟硬件融合,為解決上述問題,提供了成體系化的理念、方法、技術和解決方案,為輕松駕馭超異構提供了切實可行的路徑。
關于軟硬件融合,請看文章:軟硬件融合:超異構算力革命。
未來,所有的大算力芯片都是超異構芯片
圖源:軟硬件融合
Intel高級副總裁兼加速計算系統和圖形部門負責人Raja Koduri表示:要想實現《雪崩》和《頭號玩家》中天馬行空的體驗,需將現在的算力至少再提升1000倍。應用不斷發展,軟硬件根本的矛盾仍然是“硬件的性能提升,永遠趕不上軟件對性能的需求”。可以說,對算力的需求,永無止境!
要保證宏觀算力的精準,一方面是要持續不斷的提升性能,另一方面還要保證芯片的靈活可編程性。唯有通過超異構的方式,分門別類,針對每個任務的特征采用優質的引擎方案,才能在確保靈活可編程的同時,實現優質的性能。從而,真正實現性能和靈活性的既要又要。
單兵作戰,顧此失彼;團隊協作,互補共贏。
未來,唯有超異構計算,才能保證算力數量級提升的同時,不損失靈活可編程性。才能夠真正實現宏觀算力的數量級提升,才能夠更好的支撐數字經濟社會發展。
審核編輯 :李倩
-
處理器
+關注
關注
68文章
19799瀏覽量
233484 -
cpu
+關注
關注
68文章
11031瀏覽量
215944 -
串行
+關注
關注
0文章
237瀏覽量
34312
原文標題:超異構計算:大算力芯片的未來
文章出處:【微信號:electronicaChina,微信公眾號:e星球】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
量子計算最新突破!“量子+AI”開啟顛覆未來的指數級革命

解鎖樹莓派集群:一步步打造你的超級計算陣列!

讀懂極易并行計算:定義、挑戰與解決方案

濾波器在量子計算中的潛在應用:噪聲控制與信號提純
GPU加速計算平臺的優勢
云 GPU 加速計算:突破傳統算力瓶頸的利刃
解析DeepSeek MoE并行計算優化策略
xgboost的并行計算原理
直播預告|RISC-V 并行計算技術沙龍,邀您與國內外專家共探 AI 時代無限可能






 工商網監
工商網監
評論