") 使用OpenCL for FPGA設(shè)計200萬點(diǎn)頻域?yàn)V波器
使用OpenCL for FPGA設(shè)計200萬點(diǎn)頻域?yàn)V波器
考慮在當(dāng)前 FPGA 架構(gòu)上創(chuàng)建一個支持 100 萬到 1600 萬個點(diǎn)的頻域濾波器,采樣率從每秒 1.2 億到 2.4 億個樣本。該示例著眼于使用 OpenCL 的 200 萬點(diǎn)單精度頻域?yàn)V波器的設(shè)計決策選項。
這種濾波器使用數(shù)百萬點(diǎn)一維 (1D) FFT 將其輸入轉(zhuǎn)換為頻域,將每個頻率和相位分量乘以一個單獨(dú)的用戶提供的值,然后將結(jié)果轉(zhuǎn)換回時域快速傅里葉變換。整個系統(tǒng)的總體目標(biāo)性能要求是每秒 1.5 億個樣本 (MSPS),在具有兩個 DDR3 外部存儲器組的當(dāng)前一代 FPGA 上實(shí)現(xiàn) 200 萬點(diǎn)的樣本大小。輸入和輸出通過 10 Gb 以太網(wǎng) (GbE) 直接進(jìn)入 FPGA。
該設(shè)計使用面向具有 Stratix V GSD8 FPGA 的 BittWare S5-PCIe-HQ 板的 Altera SDK for OpenCL FPGA 編譯器。使用 OpenCL 而不是低級語言有兩個原因:
第一個原因是設(shè)計數(shù)百萬點(diǎn)濾波器需要構(gòu)建復(fù)雜但高效的外部存儲系統(tǒng)。使用較低級別的設(shè)計工具,創(chuàng)建單個塊,例如片上 FFT 或拐角轉(zhuǎn)角相對容易(特別是因?yàn)槊總€ FPGA 供應(yīng)商都已經(jīng)提供了包含此類塊的庫)。然而,創(chuàng)建外部存儲器系統(tǒng)通常需要大量的 HDL 工作。正如我們稍后會看到的,這種情況可能特別具有挑戰(zhàn)性,因?yàn)檎麄€系統(tǒng)的配置在一開始是未知的。
選擇 OpenCL 的第二個原因是對 FPGA 邏輯的主機(jī)級控制。對于這個設(shè)計,從一開始就很明顯,兩個完整副本的數(shù)百萬點(diǎn) FFT 內(nèi)核無法容納在單個設(shè)備上,因此單個數(shù)據(jù)集必須至少通過 FPGA 邏輯兩次才能產(chǎn)生最終輸出。協(xié)調(diào)這種共享,同時允許動態(tài)改變數(shù)據(jù)集大小、乘法系數(shù),甚至完全改變 FPGA 功能以實(shí)現(xiàn)其他功能,最好留給 CPU。
使用面向 FPGA 的 OpenCL 編譯器解決了這兩個挑戰(zhàn),因?yàn)樗鼧?gòu)建了一個定制的高效外部存儲器系統(tǒng),同時允許對 FPGA 邏輯進(jìn)行細(xì)粒度控制。
片上 FFT
對于這個設(shè)計,假設(shè)我們已經(jīng)有一個 FFT 內(nèi)核,可以處理完全適合 FPGA 的數(shù)據(jù)大小(稱為“片上 FFT”),因?yàn)槊總€ FPGA 供應(yīng)商都提供這樣的內(nèi)核。這樣的核心至少可以通過以下方式參數(shù)化:
數(shù)據(jù)類型(固定或單精度浮點(diǎn))
要處理的點(diǎn)數(shù) (N)
并行處理的點(diǎn)數(shù) (POINTS)
動態(tài)支持更改要處理的點(diǎn)數(shù)
給定這樣一個片上 FFT 核,構(gòu)建整個系統(tǒng)需要兩個步驟:首先,構(gòu)建一個可以處理數(shù)百萬點(diǎn)的 FFT 核,其次,將兩個這樣的核拼接在一起,并在它們之間進(jìn)行復(fù)雜的乘法運(yùn)算以創(chuàng)建整個系統(tǒng)。
數(shù)百萬點(diǎn) FFT
使用外部存儲實(shí)現(xiàn) FFT 的經(jīng)典方法是圖 1 所示的六步算法,該算法將單個一維數(shù)據(jù)集視為二維 (2M = 2K x 1K)[1]。
圖 1:六步 FFT 算法的邏輯視圖。
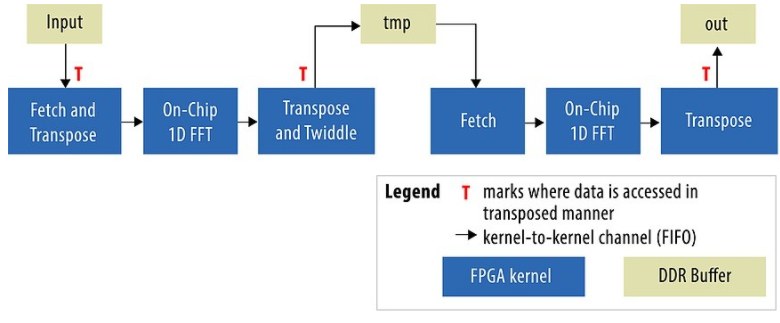
六步算法顯示了單獨(dú)的計算內(nèi)核和外部內(nèi)存緩沖區(qū)。“Fetch”內(nèi)核從外部存儲器讀取數(shù)據(jù),可選擇轉(zhuǎn)置,并將其輸出到通道(在 OpenCL 2.0 命名法中也稱為“管道”)。在硬件中,通道被實(shí)現(xiàn)為具有編譯器計算深度的 FIFO。“片上 1D FFT”是未經(jīng)修改的供應(yīng)商的 FFT 內(nèi)核,使用通道獲取輸入并產(chǎn)生位反轉(zhuǎn)輸出。“轉(zhuǎn)置”總是轉(zhuǎn)置從其輸入通道讀取的數(shù)據(jù),可選擇將其乘以特殊的旋轉(zhuǎn)因子,并以自然順序?qū)⑤敵鰧懭胪獠看鎯ζ鳌?/p>
如圖所示,數(shù)據(jù)通過 Fetch ? 1D FFT ? Transpose (F1T) 管道發(fā)送兩次以產(chǎn)生最終輸出。這為我們提供了第一個重要的設(shè)計選擇:要么擁有一個 F1T 管道副本以節(jié)省空間,要么擁有兩個副本以獲得更高的吞吐量。
該算法的初始原型設(shè)計是在模擬器中完成的,以確保轉(zhuǎn)置和旋轉(zhuǎn)因子的地址操作是正確的。仿真器將 OpenCL 內(nèi)核編譯為 x86-64 二進(jìn)制代碼,可以在沒有 FPGA 的開發(fā)機(jī)器上運(yùn)行。從模擬器到硬件編譯是一個輕松的步驟,因?yàn)槟M器中功能正確的代碼變成了硬件中功能正確的代碼,因此不需要模擬。
出于性能和面積原因,唯一需要修改的是 Fetch 和 Transpose 內(nèi)核使用的本地內(nèi)存系統(tǒng)。高效的轉(zhuǎn)置需要緩沖POINTS本地內(nèi)存中的列/行數(shù)據(jù)。OpenCL 編譯器分析 OpenCL 代碼中對本地存儲器的所有訪問,并創(chuàng)建針對該代碼優(yōu)化的自定義片上存儲器系統(tǒng)。在 POINTS=4 的情況下,原始轉(zhuǎn)置內(nèi)核有四次寫入和四次讀取。一個雙泵的片上 RAM 塊最多可以服務(wù)四個單獨(dú)的請求,其中最多兩個是寫入。為了支持四寫四讀,片上存儲器需要同時復(fù)制并包含請求仲裁邏輯,這會導(dǎo)致區(qū)域膨脹和性能損失。但是,可以更改寫入模式以使所有四個寫入連續(xù)。OpenCL 編譯器將這四次寫入分組為一次寬寫入,只提供對本地內(nèi)存系統(tǒng)的五次訪問:一次寫入和四次讀取。有了這樣的改變,
將設(shè)計編譯到硬件后,就可以測量性能了。使用 FPGA 上的 F1T 流水線的單個副本,我們測量了 217 MSPS,POINTS=4 和 457 MSPS,POINTS=8,對于 400 萬-點(diǎn) FFT[2]。POINTS=8 版本使用了兩倍的片上 Block RAM,并且此配置中的兩個副本不適合。這為我們提供了第一個要探索的設(shè)計維度——并行處理的點(diǎn)數(shù)與面積。
全過濾設(shè)計
現(xiàn)在我們有了數(shù)百萬點(diǎn)的 FFT,我們準(zhǔn)備將整個設(shè)計放在一起。只需拼接兩個片外 FFT,我們就可以得到圖 2 中整個流水線的邏輯視圖。
圖 2:為簡潔起見,完整過濾器系統(tǒng)的此邏輯視圖顯示 F1T 管道表示為單個塊。
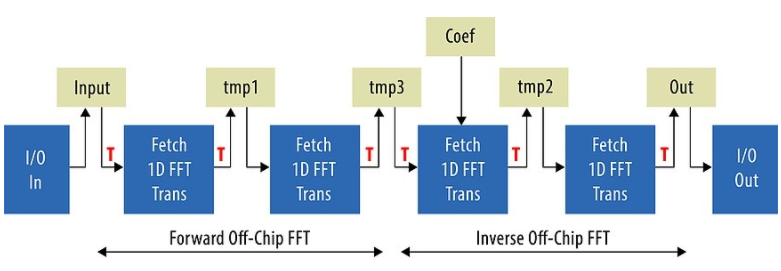
除了復(fù)制單個片外 FFT 計算流水線外,系統(tǒng)還添加了以下部分:
頻域中的復(fù)數(shù)乘法被吸收到第三個 F1T 塊中。coef緩沖區(qū)保存著兩百萬個復(fù)數(shù)乘法系數(shù)。
添加了 I/O 輸入和 I/O 輸出內(nèi)核,以真實(shí)地模擬外部存儲器上 10 GbE 通道的額外負(fù)載。使用這些內(nèi)核,我們可以繼續(xù)純粹基于軟件的開發(fā),并在核心計算管道完全優(yōu)化之前離開以太網(wǎng)通道集成。內(nèi)核中的 I/O 每個時鐘周期生成一個樣本,而 I/O 輸出每個時鐘周期消耗一個樣本。
正如片外 FFT 的實(shí)驗(yàn)所示,我們只能擬合兩個 F1T 塊,并且只能使用 POINTS=4。因此,數(shù)據(jù)必須通過硬件兩次才能進(jìn)行完整計算。這使我們的 200 萬個點(diǎn)的整體系統(tǒng)吞吐量僅為 120 MSPS,低于我們 150 MSPS 的目標(biāo)。但是,通過將數(shù)據(jù)大小減少到 100 萬個點(diǎn),我們能夠擬合 POINTS=8 的版本并獲得 198 MSPS 的吞吐量。這表明,只要我們能制作一個適合 200 萬個點(diǎn)的 POINTS=8 版本,性能還是有的。
選擇圖 2 中完整流水線的優(yōu)化結(jié)構(gòu)是整個設(shè)計過程的下一步。我們可以做的第一個改進(jìn)是刪除tmp3緩沖區(qū)。雙方以相同的方式訪問它(轉(zhuǎn)置寫入和讀取),因此第二個和第三個 F1T 塊可以通過通道直接連接。這需要讓 Transpose 內(nèi)核將其輸出寫入外部存儲器或?qū)懭胪ǖ溃?Fetch 進(jìn)行類似的更改。這種變化是由主機(jī)動態(tài)控制的,因此可以使用單個物理 Fetch 實(shí)例。請注意,這會改變我們與外部存儲器的連接,但我們完全不必?fù)?dān)心這一點(diǎn),因?yàn)?OpenCL 編譯器總是為我們的系統(tǒng)生成高效的自定義外部存儲器互連。
進(jìn)一步的改進(jìn)是將第二個轉(zhuǎn)置“T”從寫入tmp1移動到從tmp1讀取(tmp1中的數(shù)據(jù)存儲方式不同,但最終效果相同)。這消除了對轉(zhuǎn)置使用的一個本地內(nèi)存緩沖區(qū)的需要。盡管這種改變并不難實(shí)施,但我們決定放棄它以代替更激進(jìn)的想法。
我們最初的轉(zhuǎn)置實(shí)現(xiàn)分兩個階段完成:
首先將所有需要的數(shù)據(jù)加載到本地內(nèi)存中,然后使用轉(zhuǎn)置地址從本地內(nèi)存中讀取。為了有效利用這樣的管道,OpenCL 編譯器會自動對本地內(nèi)存系統(tǒng)進(jìn)行雙緩沖。這樣,管道的加載部分可以將數(shù)據(jù)加載到一個副本中,而讀取部分可以從另一個副本中讀取先前的數(shù)據(jù)集。
這種自動雙緩沖對我們的轉(zhuǎn)置算法來說是正確的,但它很昂貴。相反,我們將轉(zhuǎn)置內(nèi)核重寫為就地。這樣的內(nèi)核只需要一個緩沖區(qū),并且支持同時讀取和寫入多個數(shù)據(jù)點(diǎn)(但是關(guān)于這個轉(zhuǎn)置內(nèi)核我們將在另一時間詳細(xì)描述)。
通過這些更改,我們能夠在 POINTS=8 配置中安裝 200 萬點(diǎn) FFT,并實(shí)現(xiàn) 164 MSPS 吞吐量。
調(diào)度
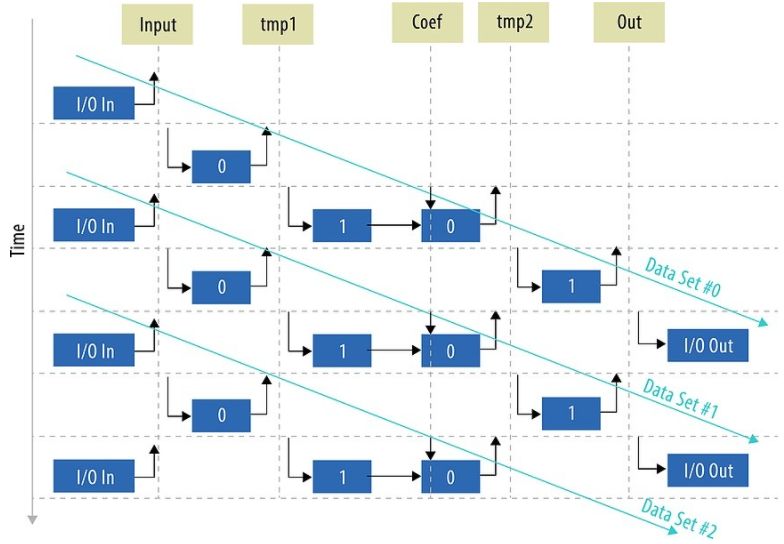
只有兩個 F1T 副本可以容納,但圖 3 顯示了如何安排數(shù)據(jù)流以充分利用管道。請注意,在穩(wěn)定狀態(tài)下,管道會在一次處理兩個和三個數(shù)據(jù)集之間交替,而無需額外的緩沖區(qū)。此調(diào)度由在 CPU 上運(yùn)行的主機(jī)程序控制,并使用 Dynamic Profiler 工具進(jìn)行驗(yàn)證。
圖 3:在內(nèi)核調(diào)度方面,“0”是 F1T 管道的第一個物理副本,“1”是第二個副本。紫色箭頭通過管道跟隨單個數(shù)據(jù)集。
緩沖區(qū)分配
在 OpenCL 系統(tǒng)中,主機(jī)程序控制哪個 DDR bank 包含哪些緩沖區(qū)。由于 DDR bank 在讀取或?qū)懭霑r效率最高,但不是兩者兼而有之,因此我們可以將五個緩沖區(qū)拆分為兩個 DDR bank,如下所示:
DDR bank #0 獲得輸入和tmp2
DDR bank #1 獲取tmp1、coef和out
將緩沖區(qū)分配給 DDR bank 是 OpenCL 主機(jī)程序中的一行更改。編譯器和底層平臺負(fù)責(zé)其余的工作。鑒于這種自動化,我們可以在 2-DDR 和 4-DDR 板上進(jìn)行試驗(yàn),以找到每個板的緩沖區(qū)到 bank 的最佳映射。
結(jié)論
本文介紹如何使用 Altera OpenCL SDK for FPGA 設(shè)計 200 萬點(diǎn)頻域?yàn)V波器。所有功能驗(yàn)證均使用軟件樣式的仿真完成,并且每個硬件編譯都能正常工作。我們沒有打開硬件模擬器,也從不擔(dān)心時序收斂。
作者:Dmitry Denisenko,Mykhailo Popryaga
審核編輯:郭婷
-
濾波器
+關(guān)注
關(guān)注
162文章
8065瀏覽量
180931 -
DDR
+關(guān)注
關(guān)注
11文章
731瀏覽量
66354 -
模擬器
+關(guān)注
關(guān)注
2文章
892瀏覽量
44012
發(fā)布評論請先 登錄
模擬低通濾波器的設(shè)計方法有哪些
基于FPGA實(shí)現(xiàn)FIR數(shù)字濾波器
emi濾波器是什么濾波器
帶通濾波器的插損與哪些因素有關(guān)
濾波器的零點(diǎn)和極點(diǎn)與s參數(shù)有關(guān)嗎
全通濾波器系統(tǒng)函數(shù)穩(wěn)定嗎
全通濾波器零極點(diǎn)的特點(diǎn)有哪些
零極點(diǎn)怎么判斷濾波器類型
陷波濾波器怎么進(jìn)行濾波
陷波濾波器和超前滯后濾波器的差別是什么
iir濾波器和fir濾波器的優(yōu)勢和特點(diǎn)
高通濾波器和低通濾波器判別方法
低通濾波器、高通濾波器、帶通濾波器的簡單介紹
梳狀濾波器的相關(guān)知識

濾波器濾波的本質(zhì):信號時頻特性的選擇與處理|維愛普電源濾波器






 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評論