") 如何編寫優(yōu)質(zhì)嵌入式C程序
如何編寫優(yōu)質(zhì)嵌入式C程序
本文面向的,正是使用單片機(jī)、ARM7、Cortex-M3這類微控制器的編程人員。
C語言詭異且有種種陷阱和缺陷,需要程序員多年歷練才能達(dá)到較為完善的地步。
總是有大批的初學(xué)者,前仆后繼的倒在這些陷阱和缺陷上,民用設(shè)備、工業(yè)設(shè)備甚至是航天設(shè)備都不例外。本文將結(jié)合具體例子再次審視它們,希望引起足夠重視。深入理解C語言特性,是編寫優(yōu)質(zhì)嵌入式C程序的基礎(chǔ)。
由于篇幅限制,后續(xù)再推送編譯器、防御性編程、測(cè)試和編程思想這幾個(gè)方面的內(nèi)容,來討論如何編寫優(yōu)質(zhì)嵌入式C程序。
1 處處都是陷阱
1.1 無心之過
1) “=”和”==”
將比較運(yùn)算符”==”誤寫成賦值運(yùn)算符”=”,可能是絕大多數(shù)人都遇到過的,比如下面代碼:
if(x=5){//其它代碼}
代碼的本意是比較變量x是否等于常量5,但是誤將”==”寫成了”=”,if語句恒為真。如果在邏輯判斷表達(dá)式中出現(xiàn)賦值運(yùn)算符,現(xiàn)在的大多數(shù)編譯器會(huì)給出警告信息。比如keil MDK會(huì)給出警告提示:“warning: #187-D: use of "=" where"==" may have been intended”,但并非所有程序員都會(huì)注意到這類警告,因此有經(jīng)驗(yàn)的程序員使用下面的代碼來避免此類錯(cuò)誤:
if(5==x){//其它代碼}
將常量放在變量x的左邊,即使程序員誤將’==’寫成了’=’,編譯器會(huì)產(chǎn)生一個(gè)任誰也不能無視的語法錯(cuò)誤信息:不可給常量賦值!
2) 復(fù)合賦值運(yùn)算符
復(fù)合賦值運(yùn)算符(+=、*=等等)雖然可以使表達(dá)式更加簡(jiǎn)潔并有可能產(chǎn)生更高效的機(jī)器代碼,但某些復(fù)合賦值運(yùn)算符也會(huì)給程序帶來隱含Bug,比如”+=”容易誤寫成”=+”,代碼如下:
tmp=+1;
代碼本意是想表達(dá)tmp=tmp+1,但是將復(fù)合賦值運(yùn)算符”+=”誤寫成”=+”:將正整數(shù)常量1賦值給變量tmp。編譯器會(huì)欣然接受這類代碼,連警告都不會(huì)產(chǎn)生。
如果你能在調(diào)試階段就發(fā)現(xiàn)這個(gè)Bug,真應(yīng)該慶祝一下,否則這很可能會(huì)成為一個(gè)重大隱含Bug,且不易被察覺。
復(fù)合賦值運(yùn)算符”-=”也有類似問題存在。
3) 其它容易誤寫
- 使用了中文標(biāo)點(diǎn)
- 頭文件聲明語句最后忘記結(jié)束分號(hào)
- 邏輯與&&和位與&、邏輯或||和位或|、邏輯非!和位取反~
- 字母l和數(shù)字1、字母O和數(shù)字0
這些誤寫其實(shí)容易被編譯器檢測(cè)出,只需要關(guān)注編譯器對(duì)此的提示信息,就能很快解決。
1.2 數(shù)組下標(biāo)
數(shù)組常常也是引起程序不穩(wěn)定的重要因素,C語言數(shù)組的迷惑性與數(shù)組下標(biāo)從0開始密不可分,你可以定義int test[30],但是你絕不可以使用數(shù)組元素test [30],除非你自己明確知道在做什么。
1.3 容易被忽略的break關(guān)鍵字
1) 不能漏加的break
switch…case語句可以很方便的實(shí)現(xiàn)多分支結(jié)構(gòu),但要注意在合適的位置添加break關(guān)鍵字。程序員往往容易漏加break從而引起順序執(zhí)行多個(gè)case語句,這也許是C的一個(gè)缺陷之處。
對(duì)于switch…case語句,從概率論上說,絕大多數(shù)程序一次只需執(zhí)行一個(gè)匹配的case語句,而每一個(gè)這樣的case語句后都必須跟一個(gè)break。去復(fù)雜化大概率事件,這多少有些不合常情。
2) 不能亂加的break
break關(guān)鍵字用于跳出最近的那層循環(huán)語句或者switch語句,但程序員往往不夠重視這一點(diǎn)。
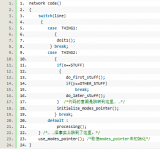
1990年1月15日,AT&T電話網(wǎng)絡(luò)位于紐約的一臺(tái)交換機(jī)宕機(jī)并且重啟,引起它鄰近交換機(jī)癱瘓,由此及彼,一個(gè)連著一個(gè),很快,114型交換機(jī)每六秒宕機(jī)重啟一次,六萬人九小時(shí)內(nèi)不能打長途電話。
當(dāng)時(shí)的解決方式:工程師重裝了以前的軟件版本。。。事后的事故調(diào)查發(fā)現(xiàn),這是break關(guān)鍵字誤用造成的。《C專家編程》提供了一個(gè)簡(jiǎn)化版的問題源碼:

那個(gè)程序員希望從if語句跳出,但他卻忘記了break關(guān)鍵字實(shí)際上跳出最近的那層循環(huán)語句或者switch語句。現(xiàn)在它跳出了switch語句,執(zhí)行了use_modes_pointer()函數(shù)。但必要的初始化工作并未完成,為將來程序的失敗埋下了伏筆。
1.4 意想不到的八進(jìn)制
將一個(gè)整形常量賦值給變量,代碼如下所示:
int a=34, b=034;
變量a和b相等嗎?
答案是不相等的。我們知道,16進(jìn)制常量以’0x’為前綴,10進(jìn)制常量不需要前綴,那么8進(jìn)制呢?它與10進(jìn)制和16進(jìn)制表示方法都不相同,它以數(shù)字’0’為前綴,這多少有點(diǎn)奇葩:三種進(jìn)制的表示方法完全不相同。
如果8進(jìn)制也像16進(jìn)制那樣以數(shù)字和字母表示前綴的話,或許更有利于減少軟件Bug,畢竟你使用8進(jìn)制的次數(shù)可能都不會(huì)有誤使用的次數(shù)多!下面展示一個(gè)誤用8進(jìn)制的例子,最后一個(gè)數(shù)組元素賦值錯(cuò)誤:
a[0]=106; /*十進(jìn)制數(shù)106*/a[1]=112; /*十進(jìn)制數(shù)112*/a[2]=052; /*實(shí)際為十進(jìn)制數(shù)42,本意為十進(jìn)制52*/
1.5指針加減運(yùn)算
**指針的加減運(yùn)算是特殊的。**下面的代碼運(yùn)行在32位ARM架構(gòu)上,執(zhí)行之后,a和p的值分別是多少?
int a=1;int *p=(int *)0x00001000;a=a+1;p=p+1;
對(duì)于a的值很容判斷出結(jié)果為2,但是p的結(jié)果卻是0x00001004。指針p加1后,p的值增加了4,這是為什么呢?原因是指針做加減運(yùn)算時(shí)是以指針的數(shù)據(jù)類型為單位。p+1實(shí)際上是按照公式p+1*sizeof(int)來計(jì)算的。不理解這一點(diǎn),在使用指針直接操作數(shù)據(jù)時(shí)極易犯錯(cuò)。
某項(xiàng)目使用下面代碼對(duì)連續(xù)RAM初始化零操作,但運(yùn)行發(fā)現(xiàn)有些RAM并沒有被真正清零。
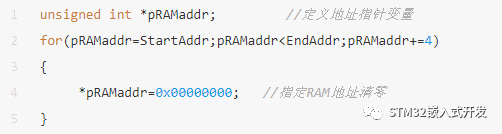
通過分析我們發(fā)現(xiàn),由于pRAMaddr是一個(gè)無符號(hào)int型指針變量,所以pRAMaddr+=4代碼其實(shí)使pRAMaddr偏移了4*sizeof(int)=16個(gè)字節(jié),所以每執(zhí)行一次for循環(huán),會(huì)使變量pRAMaddr偏移16個(gè)字節(jié)空間,但只有4字節(jié)空間被初始化為零。其它的12字節(jié)數(shù)據(jù)的內(nèi)容,在大多數(shù)架構(gòu)處理器中都會(huì)是隨機(jī)數(shù)。
1.6關(guān)鍵字sizeof
不知道有多少人最初認(rèn)為sizeof是一個(gè)函數(shù)。其實(shí)它是一個(gè)關(guān)鍵字,其作用是返回一個(gè)對(duì)象或者類型所占的內(nèi)存字節(jié)數(shù),對(duì)絕大多數(shù)編譯器而言,返回值為無符號(hào)整形數(shù)據(jù)。需要注意的是,使用sizeof獲取數(shù)組長度時(shí),不要對(duì)指針應(yīng)用sizeof操作符,比如下面的例子:
void ClearRAM(char array[]){int i ;for(i=0;i{array[i]=0x00;}}int main(void){char Fle[20];ClearRAM(Fle); //只能清除數(shù)組Fle中的前四個(gè)元素}
我們知道,對(duì)于一個(gè)數(shù)組array[20],我們使用代碼sizeof(array)/sizeof(array[0])可以獲得數(shù)組的元素(這里為20),但數(shù)組名和指針往往是容易混淆的,有且只有一種情況下數(shù)組名是可以當(dāng)做指針的,那就是**數(shù)組名作為函數(shù)形參時(shí),數(shù)組名被認(rèn)為是指針,同時(shí),它不能再兼任數(shù)組名。
**注意只有這種情況下,數(shù)組名才可以當(dāng)做指針,但不幸的是這種情況下容易引發(fā)風(fēng)險(xiǎn)。在ClearRAM函數(shù)內(nèi),作為形參的array[]不再是數(shù)組名了,而成了指針。sizeof(array)相當(dāng)于求指針變量占用的字節(jié)數(shù),在32位系統(tǒng)下,該值為4,sizeof(array)/sizeof(array[0])的運(yùn)算結(jié)果也為4。所以在main函數(shù)中調(diào)用ClearRAM(Fle),也只能清除數(shù)組Fle中的前四個(gè)元素了。
1.7增量運(yùn)算符’++’和減量運(yùn)算符‘--‘
增量運(yùn)算符”++”和減量運(yùn)算符”--“既可以做前綴也可以做后綴。**前綴和后綴的區(qū)別在于值的增加或減少這一動(dòng)作發(fā)生的時(shí)間是不同的。**作為前綴是先自加或自減然后做別的運(yùn)算,作為后綴時(shí),是先做運(yùn)算,之后再自加或自減。許多程序員對(duì)此認(rèn)識(shí)不夠,就容易埋下隱患。下面的例子可以很好的解釋前綴和后綴的區(qū)別。
int a=8,b=2,y;y=a+++--b;
代碼執(zhí)行后,y的值是多少?
這個(gè)例子并非是挖空心思設(shè)計(jì)出來專門讓你絞盡腦汁的C難題(如果你覺得自己對(duì)C細(xì)節(jié)掌握很有信心,做一些C難題檢驗(yàn)一下是個(gè)不錯(cuò)的選擇。那么,《The C Puzzle Book》這本書一定不要錯(cuò)過),你甚至可以將這個(gè)難懂的語句作為不友好代碼的例子。但是它也可以讓你更好的理解C語言。根據(jù)運(yùn)算符優(yōu)先級(jí)以及編譯器識(shí)別字符的貪心法原則,第二句代碼可以寫成更明確的形式:
y=(a++)+(--b);
當(dāng)賦值給變量y時(shí),a的值為8,b的值為1,所以變量y的值為9;賦值完成后,變量a自加,a的值變?yōu)?,千萬不要以為y的值為10。這條賦值語句相當(dāng)于下面的兩條語句:
y=a+(--b);a=a+1;
1.8邏輯與’&&’和邏輯或’||’的陷阱
為了提高系統(tǒng)效率,邏輯與和邏輯或操作的規(guī)定如下:**如果對(duì)第一個(gè)操作數(shù)求值后就可以推斷出最終結(jié)果,第二個(gè)操作數(shù)就不會(huì)進(jìn)行求值!**比如下面代碼:
if((i>=0)&&(i++ <=max)){//其它代碼}
在這個(gè)代碼中,只有當(dāng)i>=0時(shí),i++才會(huì)被執(zhí)行。這樣,i是否自增是不夠明確的,這可能會(huì)埋下隱患。邏輯或與之類似。
1.9結(jié)構(gòu)體的填充
結(jié)構(gòu)體可能產(chǎn)生填充,因?yàn)閷?duì)大多數(shù)處理器而言,訪問按字或者半字對(duì)齊的數(shù)據(jù)速度更快,當(dāng)定義結(jié)構(gòu)體時(shí),編譯器為了性能優(yōu)化,可能會(huì)將它們按照半字或字對(duì)齊,這樣會(huì)帶來填充問題。比如以下兩個(gè)個(gè)結(jié)構(gòu)體:
第一個(gè)結(jié)構(gòu)體:
struct {char c;short s;int x;}str_test1;
第二個(gè)結(jié)構(gòu)體:
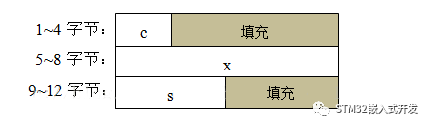
struct {char c;int x;short s;}str_test2;
這兩個(gè)結(jié)構(gòu)體元素都是相同的變量,只是元素?fù)Q了下位置,那么這兩個(gè)結(jié)構(gòu)體變量占用的內(nèi)存大小相同嗎?
其實(shí)這兩個(gè)結(jié)構(gòu)體變量占用的內(nèi)存是不同的,對(duì)于Keil MDK編譯器,默認(rèn)情況下第一個(gè)結(jié)構(gòu)體變量占用8個(gè)字節(jié),第二個(gè)結(jié)構(gòu)體占用12個(gè)字節(jié),差別很大。第一個(gè)結(jié)構(gòu)體變量在內(nèi)存中的存儲(chǔ)格式如下圖所示:
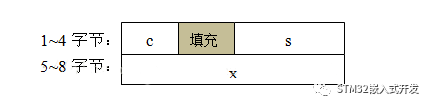
第二個(gè)結(jié)構(gòu)體變量在內(nèi)存中的存儲(chǔ)格式如下圖所示。對(duì)比兩個(gè)圖可以看出MDK編譯器是是怎么將數(shù)據(jù)對(duì)齊的,這其中的填充內(nèi)容是之前內(nèi)存中的數(shù)據(jù),是隨機(jī)的,所以不能在結(jié)構(gòu)之間逐字節(jié)比較;另外,合理的排布結(jié)構(gòu)體內(nèi)的元素位置,可以最大限度減少填充,節(jié)省RAM。
2 不可輕視的優(yōu)先級(jí)
C語言有32個(gè)關(guān)鍵字,卻有34個(gè)運(yùn)算符。要記住所有運(yùn)算符的優(yōu)先級(jí)是困難的。稍不注意,你的代碼邏輯和實(shí)際執(zhí)行就會(huì)有很大出入。
比如下面將BCD碼轉(zhuǎn)換為十六進(jìn)制數(shù)的代碼:
result=(uTimeValue>>4)*10+uTimeValue&0x0F;
這里uTimeValue存放的BCD碼,想要轉(zhuǎn)換成16進(jìn)制數(shù)據(jù),實(shí)際運(yùn)行發(fā)現(xiàn),如果uTimeValue的值為0x23,按照我設(shè)定的邏輯,result的值應(yīng)該是0x17,但運(yùn)算結(jié)果卻是0x07。經(jīng)過種種排查后,才發(fā)現(xiàn)’+’的優(yōu)先級(jí)是大于’&’的,相當(dāng)于(uTimeValue>>4)*10+uTimeValue與0x0F位與,結(jié)果自然與邏輯不符。符合邏輯的代碼應(yīng)該是:
result=(uTimeValue>>4)*10+(uTimeValue&0x0F);
不合理的#define會(huì)加重優(yōu)先級(jí)問題,讓問題變得更加隱蔽。

編譯器在編譯后將宏帶入,原代碼語句變?yōu)?
if(IO0PIN&(1<<11) ==(1<<11)){//其它代碼}
運(yùn)算符'=='的優(yōu)先級(jí)是大于'&'的,代碼IO0PIN&(1<<11) ==(1<<11))等效為IO0PIN&0x00000001:判斷端口P0.0是否為高電平,這與原意相差甚遠(yuǎn)。因此,使用宏定義的時(shí)候,最好將被定義的內(nèi)容用括號(hào)括起來。
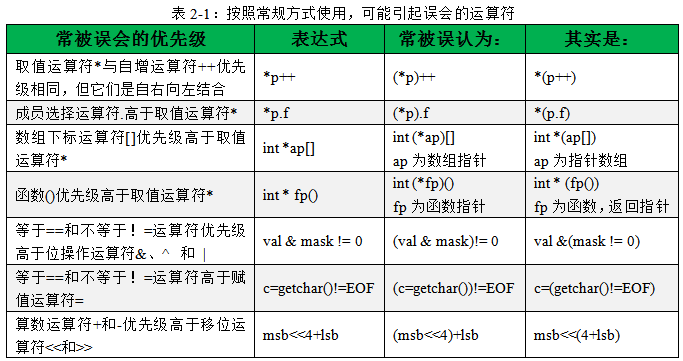
按照常規(guī)方式使用時(shí),可能引起誤會(huì)的運(yùn)算符還有很多,如下表所示。C語言的運(yùn)算符當(dāng)然不會(huì)只止步于數(shù)目繁多!
 有一個(gè)簡(jiǎn)便方法可以避免優(yōu)先級(jí)問題:不清楚的優(yōu)先級(jí)就加上”()”,但這樣至少有會(huì)帶來兩個(gè)問題:
有一個(gè)簡(jiǎn)便方法可以避免優(yōu)先級(jí)問題:不清楚的優(yōu)先級(jí)就加上”()”,但這樣至少有會(huì)帶來兩個(gè)問題:
- 過多的括號(hào)影響代碼的可讀性,包括自己和以后的維護(hù)人員
- 別人的代碼不一定用括號(hào)來解決優(yōu)先級(jí)問題,但你總要讀別人的代碼
無論如何,在嵌入式編程方面,該掌握的基礎(chǔ)知識(shí),偷巧不得。建議花一些時(shí)間,將優(yōu)先級(jí)順序以及容易出錯(cuò)的優(yōu)先級(jí)運(yùn)算符理清幾遍。
隱式轉(zhuǎn)換
C語言的設(shè)計(jì)理念一直被人吐槽,因?yàn)樗J(rèn)為C程序員完全清楚自己在做什么,其中一個(gè)證據(jù)就是隱式轉(zhuǎn)換。C語言規(guī)定,**不同類型的數(shù)據(jù)(比如char和int型數(shù)據(jù))需要轉(zhuǎn)換成同一類型后,才可進(jìn)行計(jì)算。
**如果你混合使用類型,比如用char類型數(shù)據(jù)和int類型數(shù)據(jù)做減法,C使用一個(gè)規(guī)則集合來自動(dòng)(隱式的)完成類型轉(zhuǎn)換。這可能很方便,但也很危險(xiǎn)。
這就要求我們理解這個(gè)轉(zhuǎn)換規(guī)則并且能應(yīng)用到程序中去!
- 當(dāng)出現(xiàn)在表達(dá)式里時(shí),有符號(hào)和無符號(hào)的char和short類型都將自動(dòng)被轉(zhuǎn)換為int類型,在需要的情況下,將自動(dòng)被轉(zhuǎn)換為unsigned int(在short和int具有相同大小時(shí))。這稱為類型提升。
提升在算數(shù)運(yùn)算中通常不會(huì)有什么大的壞處,但如果位運(yùn)算符 ~ 和 << 應(yīng)用在基本類型為unsigned char或unsigned short 的操作數(shù),結(jié)果應(yīng)該立即強(qiáng)制轉(zhuǎn)換為unsigned char或者unsigned short類型(取決于操作時(shí)使用的類型)。
uint8_t port =0x5aU;uint8_t result_8;result_8= (~port) >> 4;
假如我們不了解表達(dá)式里的類型提升,認(rèn)為在運(yùn)算過程中變量port一直是unsigned char類型的。我們來看一下運(yùn)算過程:~port結(jié)果為0xa5,0xa5>>4結(jié)果為0x0a,這是我們期望的值。
但實(shí)際上,result_8的結(jié)果卻是0xfa!在ARM結(jié)構(gòu)下,int類型為32位。變量port在運(yùn)算前被提升為int類型:~port結(jié)果為0xffffffa5,0xa5>>4結(jié)果為0x0ffffffa,賦值給變量result_8,發(fā)生類型截?cái)啵ㄟ@也是隱式的!),result_8=0xfa。經(jīng)過這么詭異的隱式轉(zhuǎn)換,結(jié)果跟我們期望的值,已經(jīng)大相徑庭!正確的表達(dá)式語句應(yīng)該為:
result_8=(unsigned char) (~port) >> 4; /*強(qiáng)制轉(zhuǎn)換*/
- 在包含兩種數(shù)據(jù)類型的任何運(yùn)算里,兩個(gè)值都會(huì)被轉(zhuǎn)換成兩種類型里較高的級(jí)別。類型級(jí)別從高到低的順序是long double、double、float、unsigned long long、long long、unsigned long、long、unsigned int、int。
這種類型提升通常都是件好事,但往往有很多程序員不能真正理解這句話,比如下面的例子(int類型表示16位)。
uint16_t u16a = 40000; /* 16位無符號(hào)變量*/uint16_t u16b= 30000; /*16位無符號(hào)變量*/uint32_t u32x; /*32位無符號(hào)變量 */uint32_t u32y;u32x = u16a +u16b; /* u32x = 70000還是4464 ? */u32y =(uint32_t)(u16a + u16b); /* u32y = 70000 還是4464 ? */
u32x和u32y的結(jié)果都是4464(70000%65536)!不要認(rèn)為表達(dá)式中有一個(gè)高類別uint32_t類型變量,編譯器都會(huì)幫你把所有其他低類別都提升到uint32_t類型。正確的書寫方式:
u32x = (uint32_t)u16a +(uint32_t)u16b;//或者:u32x = (uint32_t)u16a + u16b;
后一種寫法在本表達(dá)式中是正確的,但是在其它表達(dá)式中不一定正確,比如:
uint16_t u16a,u16b,u16c;uint32_t u32x;u32x= u16a + u16b + (uint32_t)u16c;/*錯(cuò)誤寫法,u16a+ u16b仍可能溢出 */
-
在賦值語句里,計(jì)算的最后結(jié)果被轉(zhuǎn)換成將要被賦予值的那個(gè)變量的類型。這一過程可能導(dǎo)致類型提升也可能導(dǎo)致類型降級(jí)。降級(jí)可能會(huì)導(dǎo)致問題。比如將運(yùn)算結(jié)果為321的值賦值給8位char類型變量。程序必須對(duì)運(yùn)算時(shí)的數(shù)據(jù)溢出做合理的處理。很多其他語言,像Pascal(C語言設(shè)計(jì)者之一曾撰文狠狠批評(píng)過Pascal語言),都不允許混合使用類型,但C語言不會(huì)限制你的自由,即便這經(jīng)常引起B(yǎng)ug。
-
當(dāng)作為函數(shù)的參數(shù)被傳遞時(shí),char和short會(huì)被轉(zhuǎn)換為int,float會(huì)被轉(zhuǎn)換為double。
當(dāng)不得已混合使用類型時(shí),一個(gè)比較好的習(xí)慣是使用類型強(qiáng)制轉(zhuǎn)換。強(qiáng)制類型轉(zhuǎn)換可以避免編譯器隱式轉(zhuǎn)換帶來的錯(cuò)誤,同時(shí)也向以后的維護(hù)人員傳遞一些有用信息。這有個(gè)前提:你要對(duì)強(qiáng)制類型轉(zhuǎn)換有足夠的了解!下面總結(jié)一些規(guī)則:
- 并非所有強(qiáng)制類型轉(zhuǎn)換都是由風(fēng)險(xiǎn)的,把一個(gè)整數(shù)值轉(zhuǎn)換為一種具有相同符號(hào)的更寬類型時(shí),是絕對(duì)安全的。
- 精度高的類型強(qiáng)制轉(zhuǎn)換為精度低的類型時(shí),通過丟棄適當(dāng)數(shù)量的最高有效位來獲取結(jié)果,也就是說會(huì)發(fā)生數(shù)據(jù)截?cái)啵⑶铱赡芨淖償?shù)據(jù)的符號(hào)位。
- 精度低的類型強(qiáng)制轉(zhuǎn)換為精度高的類型時(shí),如果兩種類型具有相同的符號(hào),那么沒什么問題;需要注意的是負(fù)的有符號(hào)精度低類型強(qiáng)制轉(zhuǎn)換為無符號(hào)精度高類型時(shí),會(huì)不直觀的執(zhí)行符號(hào)擴(kuò)展,例如:
unsigned int bob;signed char fred = -1;bob=(unsigned int )fred; /*發(fā)生符號(hào)擴(kuò)展,此時(shí)bob為0xFFFFFFFF*/
-
單片機(jī)
+關(guān)注
關(guān)注
6063文章
44915瀏覽量
646745 -
嵌入式
+關(guān)注
關(guān)注
5141文章
19524瀏覽量
314791 -
C語言
+關(guān)注
關(guān)注
180文章
7630瀏覽量
140220
原文標(biāo)題:嵌入式開發(fā)中的C語言1??——特性
文章出處:【微信號(hào):c-stm32,微信公眾號(hào):STM32嵌入式開發(fā)】歡迎添加關(guān)注!文章轉(zhuǎn)載請(qǐng)注明出處。
發(fā)布評(píng)論請(qǐng)先 登錄
怎么做好嵌入式
嵌入式C語言必學(xué)知識(shí)點(diǎn)匯總
嵌入式C程序開發(fā)需注意什么



嵌入式C的主要特點(diǎn)以及嵌入式C與標(biāo)準(zhǔn)C異同沖區(qū)重用
教你如何編寫優(yōu)質(zhì)的嵌入式C程序?
如何編寫優(yōu)質(zhì)的嵌入式C程序?

這些必須要說的C語言技巧你都知道多少?
嵌入式C語言知識(shí)總結(jié)

編寫優(yōu)質(zhì)嵌入式C程序的基礎(chǔ)
為ZynqberryZero編寫嵌入式C應(yīng)用程序





 工商網(wǎng)監(jiān)
工商網(wǎng)監(jiān)
評(píng)論