 文件系統中的日志系統是如何實現的
文件系統中的日志系統是如何實現的

日志
本文來聊聊文件系統中的日志系統,來看一個簡單的日志系統是如何實現的。本文是接著前面的 xv6 系列,用到的一些前導知識不再說明,沒看的可以先看一下。
文件系統設計中通常要考慮錯誤恢復,這是因為文件系統會涉及對磁盤的多次寫操作,如果在寫的過程中系統崩潰了,就會使得磁盤上的文件系統處于不一致的錯誤狀態。
日志就是設計來解決因為系統崩潰導致的錯誤問題,本文就 來講解怎么實現一個簡單的日志系統。在 的日志系統中,文件操作方面的系統調用并不會直接對磁盤進行寫操作,而是把對磁盤寫操作描述包裝成一個日志寫在磁盤中,當該系統調用執行完成之后,再提交一個記錄到磁盤上。
為什么日志可以解決文件系統操作中出現的崩潰呢?如果崩潰發生在提交之前,那么磁盤上的日志文件就不會被標記為已完成,恢復系統的代碼就會忽視它,磁盤的狀態就好像寫操作從未進行一樣。如果是在提交之后崩潰的,恢復程序會重演所有的寫操作。在任何一種情況下,日志文件都使得磁盤操作對于系統崩潰來說是原子操作:在恢復之后,要么所有的寫操作都完成了,要么一個寫操作都沒有完成。
上面的理論大都來自 文檔,我們能了解到,最為重要的是實現寫操作的原子性,那么怎樣實現呢? 在磁盤上分配了一片日志區,假如現在內存中有一個緩存塊準備同步到磁盤區域 A, 并不立即將該緩存塊的數據寫到磁盤區域 A,而是先寫到磁盤的日志區(提交)。如果沒有問題則將日志區的數據寫到相應的磁盤區域 A。如果有問題,在提交之前發生了崩潰,則恢復代碼忽略日志信息,區域 A 根本就沒進行過寫操作,當然就能夠保證數據的一致性。如果在提交之后發生了崩潰,則恢復代碼將日志區的數據重新寫到磁盤區域 A,也保證了數據的一致性。
日志區也需要相應的數據結構來組織管理,相關的結構定義如下:
結構定義超級塊struct superblock {
uint size; // Size of file system image (blocks) 文件系統大小,也就是一共多少塊
uint nblocks; // Number of data blocks 數據塊數量
uint ninodes; // Number of inodes. //i結點數量
uint nlog; // Number of log blocks //日志塊數量
uint logstart; // Block number of first log block //第一個日志塊塊號
uint inodestart; // Block number of first inode block //第一個i結點所在塊號
uint bmapstart; // Block number of first free map block //第一個位圖塊塊號
};
文件系統的超級塊,超級塊中記錄了文件系統的元信息,比如上述 的超級塊記錄了數據塊、i 結點、日志塊的數量和第一塊的塊號。
文件系統的總體布局如下:
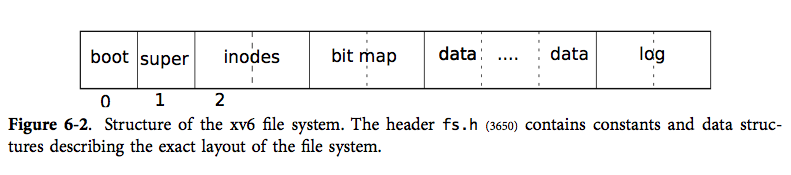
日志區位于文件系統的末尾,分為日志頭(位于第一個日志塊)和日志數據塊。
日志頭#define MAXOPBLOCKS 10 // max # of blocks any FS op writes#define LOGSIZE (MAXOPBLOCKS*3) // max data blocks in on-disk logstruct logheader { //日志頭部
int n;
int block[LOGSIZE];
};
日志頭用來記錄每次日志的大小和位置關系信息。 來記錄每次日志使用的空間大小,日志空間的總大小記錄在超級塊中(大小的單位是塊),同時 也規定每次日志使用的塊數也不能超過 。
是一個 型數組,元素個數最多為 ,用來記錄位置關系。寫入磁盤是先寫入日志區,再寫到磁盤的其他區域。這個日志區的磁盤塊和其他區域的磁盤之間需要有一個映射關系,這個關系就記錄在 數組中。舉個例子: 表示日志塊 記錄的數據應放在 號磁盤塊中。
struct log {
struct spinlock lock;
int start; //日志區第一塊塊號
int size; //日志區大小
int outstanding; // 有多少文件系統調用正在執行
int committing; // 正在提交
int dev; //設備,即主盤還是從盤,文件系統在從盤
struct logheader lh; //日志頭
};
struct log log;
這個結構體只存在于內存,用來記錄當前的日志信息。這個日志信息也是一個公共資源要避免競爭條件所以配了一把鎖。 三個屬性值從超級塊中讀取。其他的信息見注釋,具體含義后面慢慢講解。下面直接來看日志的函數實現:
函數實現void readsb(int dev, struct superblock *sb) //讀超級塊
{
struct buf *bp;
bp = bread(dev, 1); //讀取超級塊數據到緩存塊
memmove(sb, bp-》data, sizeof(*sb)); //移動數據
brelse(bp); //釋放緩存塊
}
這個函數用來讀取超級塊的內容,超級塊在第一塊,第零塊是引導塊。調用 將數據從磁盤讀取到緩存塊中,然后將緩存塊中超級塊的數據復制一份到內存中定義的超級塊數據結構中去,最后再釋放緩存塊的鎖,因為 調用 獲取了鎖,使用完該緩存塊就該釋放,詳見磁盤那篇文章
void initlog(int dev)
{
if (sizeof(struct logheader) 》= BSIZE)
panic(“initlog: too big logheader”);
struct superblock sb; //定義局部變量超級塊sb
initlock(&log.lock, “log”); //初始化日志的鎖
readsb(dev, &sb); //讀取超級塊
/*根據超級塊的信息設置日志的一些信息*/
log.start = sb.logstart; //第一個日志塊塊號
log.size = sb.nlog; //日志塊塊數
log.dev = dev; //日志所在設備
recover_from_log(); //從日志中恢復
}
這個函數來初始化日志的信息,前面應該都很好理解,超級塊中記錄的有一些元數據,讀取超級塊來初始化一些日志信息,比如日志的大小位置。最后一點不太好理解的地方便是 故名思意,從日志中恢復,每次啟動調用初始化函數它都會執行這個函數來保證文件系統的一致性,關于這個函數我們后面再詳述。
static void install_trans(void)
{
int tail;
for (tail = 0; tail 《 log.lh.n; tail++) {
struct buf *lbuf = bread(log.dev, log.start+tail+1); // read log block 讀取日志塊
struct buf *dbuf = bread(log.dev, log.lh.block[tail]); // read dst 讀取日志塊中數據本身應在的磁盤塊
memmove(dbuf-》data, lbuf-》data, BSIZE); // copy block to dst 將數據復制到目的地
bwrite(dbuf); // write dst to disk 同步緩存塊到磁盤
brelse(lbuf); //釋放 lbuf
brelse(dbuf); //釋放 dbuf
}
}
就干了一件事:將磁盤中的日志塊數據復制到應在的磁盤塊中去,前面文章曾說過針對一些列的磁盤操作,都是先在對應的緩存塊中操作再同步到相應的磁盤塊中去。所以先讀取兩部分的數據到內存中的緩存塊(不一定真的從磁盤中讀出來,要視磁盤數據在內存中是否有緩存),在內存中把數據復制過去,再同步到磁盤塊中去,最后釋放掉緩存塊。
典型的日志使用方式如下:
begin_op();
。..。..。..。
bp = bread(。..);
bp-》data[。..] = 。..;
log_write(bp);
。..。..。..。
end_op();
和 是一對兒,配套使用,表明一個文件系統調用的開始和結束。通常文件系統調用就是讀寫磁盤上的數據,所以同樣的先調用 讀取數據,然后修改,但是同步寫到磁盤上不是直接調用 而是使用 來替代。為什么這么操作,我們按照上面的順序一個一個來看:
void begin_op(void)
{
acquire(&log.lock);
while(1){
if(log.committing){ //如果日志正在提交,休眠
sleep(&log, &log.lock);
} else if(log.lh.n + (log.outstanding+1)*MAXOPBLOCKS 》 LOGSIZE){
// this op might exhaust log space; wait for commit. 如果此次文件系統調用涉及的塊數超過日志塊數上限,休眠
sleep(&log, &log.lock);
} else {
log.outstanding += 1; //文件系統調用加1
release(&log.lock); //釋放鎖
break; //退出循環
}
}
}
表明一個文件系統調用開始,它將一直等待直到日志處于未提交狀態,直到有足夠的日志空間保存當前所有調用的寫入。這個足夠的空間是保守估計的, 假設每個系統調用可能寫入 個塊, 表示正在執行的系統調用個數, 就表示加上自身這個系統調用,這個數乘以 就表示當前并發的系統調用可能寫入的塊數, 表示當前的日志空間已經使用的塊數,它們兩者之和如果小于日志空間,則可以繼續下一步,否則等待。
若能繼續下一步,表示日志空間的空閑區域足夠容納當前系統調用的寫入操作,則執行該文件系統調用,將 數量加 ,表示當前正執行的系統調用個數增加 個。
void log_write(struct buf *b)
{
int i;
if (log.lh.n 》= LOGSIZE || log.lh.n 》= log.size - 1) //當前已使用的日志空間不能大于規定的大小
panic(“too big a transaction”);
if (log.outstanding 《 1) //如果當前正執行的系統調用小于1
panic(“log_write outside of trans”);
acquire(&log.lock);
for (i = 0; i 《 log.lh.n; i++) {
if (log.lh.block[i] == b-》blockno) // log absorbtion
break;
}
log.lh.block[i] = b-》blockno;
if (i == log.lh.n)
log.lh.n++; //日志空間使用量加1
b-》flags |= B_DIRTY; // prevent eviction 設置臟位,避免緩存塊直接釋放掉了
release(&log.lock);
}
就是 一個替代品, 直接設置緩存塊的臟位然后請求磁盤同步到磁盤上去。而 只是設置緩存塊的臟位并未立即進行磁盤請求,而是后面提交的時候統一同步寫到磁盤。
同一個塊在單個事務中多次寫入的時候,會先在 數組中查找是否記錄了當前緩存塊,如果記錄了,就使用當前的日志塊,如果沒有記錄,分配一個日志塊, 數組更新信息。這樣操作即使一個塊在單個事務中多次寫入,也只會占用一個日志塊,節省了日志空間,這種優化操作就叫做吸收。
如果調用了 之后調用 釋放緩存塊,這時候日志還沒有提交,則可能會出現緩存塊引用為 0,但數據臟的情況,具體例子可參考 函數。在這兒就回答了磁盤 一文遺留的一個問題,在 函數分配緩存塊的時候一定要尋找引用為 0 且臟位沒有設置的緩存塊。因為就算緩存塊的引用為 0,只要數據臟,則代表該緩存塊仍在使用當中。
void end_op(void)
{
int do_commit = 0;
acquire(&log.lock); //取鎖
log.outstanding -= 1; //文件系統調用減1
if(log.committing) //如果正在提交,panic
panic(“log.committing”);
if(log.outstanding == 0){ //如果正在執行的文件系統調用為0,則可以提交了
do_commit = 1;
log.committing = 1;
} else {
// begin_op() may be waiting for log space,
// and decrementing log.outstanding has decreased
// the amount of reserved space.
wakeup(&log); //喚醒因日志空間不夠而休眠的進程
}
release(&log.lock);
if(do_commit){ //如果可以提交
// call commit w/o holding locks, since not allowed
// to sleep with locks.
commit(); //提交
acquire(&log.lock); //取鎖
log.committing = 0; //提交完之后設為沒有處于提交狀態
wakeup(&log); //日志空間已重置,喚醒因正在提交和空間不夠而休眠的進程
release(&log.lock); //釋放鎖
}
}
基本上是 相反的操作,它表示系統調用結束,將 減 1。如果 減為 0,表示當前沒有文件系統調用在進行,則可以提交事務了:設置 和 t 屬性為 1,具體提交操作在后面進行。
如果 不為 0,則喚醒休眠在 上的進程。前面 會因為日志空間可能不夠用而休眠,在這兒喚醒。可能有朋友疑惑,在這兒喚醒有什么用, 減 1 但是日志空間已經被占用了,似乎在這兒喚醒無用。這里要注意 中的計算空間的式子:,這是一個很保守的估計,當前系統調用完成之后 的值會變大, 的值會減 1,因此這個式子的總和完全可能變小,所以在這兒喚醒是有作用的。
執行提交的過程主要就是調用 函數,提交之后修改日志提交狀態為 0 表示并未處于提交狀態,這時候日志空間也已經清空有足夠的日志空間可以使用,所以喚醒休眠在 上的進程。
接下來看具體的日志提交:
static void commit()
{
if (log.lh.n 》 0) {
write_log(); // Write modified blocks from cache to log
write_head(); // Write header to disk -- the real commit
install_trans(); // Now install writes to home locations
log.lh.n = 0;
write_head(); // Erase the transaction from the log
}
}
static void write_log(void) //將緩存塊寫到到日志區
{
int tail;
for (tail = 0; tail 《 log.lh.n; tail++) {
struct buf *to = bread(log.dev, log.start+tail+1); // log block
struct buf *from = bread(log.dev, log.lh.block[tail]); // cache block
memmove(to-》data, from-》data, BSIZE);
bwrite(to); // write the log
brelse(from);
brelse(to);
}
}
static void write_head(void) //將日志頭寫到日志區第一塊
{
struct buf *buf = bread(log.dev, log.start); //讀取日志頭
struct logheader *hb = (struct logheader *) (buf-》data); //類型轉換
int i;
hb-》n = log.lh.n; //日志記錄大小
for (i = 0; i 《 log.lh.n; i++) {
hb-》block[i] = log.lh.block[i]; //位置信息
}
bwrite(buf); //將日志頭同步到磁盤
brelse(buf);
}
static void read_head(void) //讀取日志頭信息
{
struct buf *buf = bread(log.dev, log.start); //日志頭在日志區第一塊
struct logheader *lh = (struct logheader *) (buf-》data); //地址類型轉換
int i;
log.lh.n = lh-》n; //當前日志塊數
for (i = 0; i 《 log.lh.n; i++) {
log.lh.block[i] = lh-》block[i]; //當前日志位置信息
}
brelse(buf);
}
這幾個函數應該很好理解了,看注釋應該都能明白就不一一解釋了,在這兒主要說一些提交的具體過程:
首先判斷日志頭中的 是否大于 0,大于 0 表示有日志要提交,否則日志為空,不用提交也無可提交。
如果有日志要提交,則先根據內存中的日志頭中的 數組記錄的信息,將內存中的緩存塊寫到日志區。
然后將內存中的日志頭同步到磁盤的日志頭中去。這一步代表提交點,完成這一步表示已提交,反之則沒有提交。
經過提交點之后,再根據內存中的日志頭中的 數組記錄的信息,將日志區的數據復制到磁盤的其他區域。
之后將內存中的日志頭的 設為 0,再同步日志頭到磁盤。表示已完整的完成一次事務操作,清除日志空間,為下一次事務做準備。
static void recover_from_log(void)
{
read_head(); //讀取日志頭
install_trans(); // if committed, copy from log to disk
log.lh.n = 0;
write_head(); // clear the log
}
,從日志中恢復,可以看出這個函數與 很相似,只不過 需要從磁盤將日志頭讀出,而 的時候日志頭本身就在內存當中不用讀取,其他部分一模一樣不再解釋。
這里也解釋了為什么這個日志是一個 ,可以看出如果能從日志中恢復,它是將提交所做的事情重新做了一遍。
在這兒再來看看為什么 能夠進行錯誤恢復,使得磁盤中的數據保持一致性呢?如果在提交之前發生了崩潰,則磁盤上的日志不會被標記為已完成,也就是日志頭中的 為 0。因此在進行恢復操作執行 函數時, 讀取日志頭的時候發現 n 為 0,則執行 的時候根本就不會進入 循環進行實際的操作。也即如果在提交之前發生崩潰,對磁盤所有的操作都發生日志區,恢復代碼直接忽略該日志,不會將日志中的數據同步到磁盤的其他區域,也就保證了磁盤中文件系統的一致性。
如果崩潰發生在提交之后,則磁盤中的日志頭 n 不為 0,恢復代碼將根據 數組記錄的信息,循環 n 次把所有使用的日志塊同步到磁盤的其他區域。對磁盤所有的寫入操作先是寫入了日志區,恢復的時候又從日志區同步到磁盤相應的其他區域,這也就保證了磁盤中數據的一致性。
所以因為日志的存在,對磁盤所有的寫入操作都先是寫到日志區,再同步到磁盤的其他區域。使得對磁盤的寫入操作是一種原子操作,要么寫入操作全部完成,要么好像根本就沒有進行寫入操作一樣(實際上日志區是有寫入操作的),因此這種原子寫入操作保證了磁盤文件系統的一致性。
好啦,關于 的文件系統的日志層就聊到這里,有什么錯誤還請批評指正,也歡迎大家來同我討論交流學習進步。
責任編輯:haq
-
代碼
+關注
關注
30文章
4900瀏覽量
70715 -
日志
+關注
關注
0文章
144瀏覽量
10865
原文標題:如何實現一個簡單的日志系統
文章出處:【微信號:LinuxDev,微信公眾號:Linux閱碼場】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
飛凌嵌入式ElfBoard ELF 1板卡-文件系統簡介
服務器數據恢復—ocfs2文件系統被格式化為Ext4文件系統的數據恢復案例
技術分享 | i.MX8MPlus Journal日志管理系統

基于RV1126開發板限制系統日志大小教程

如何正確選擇嵌入式文件系統?

NFS網絡文件系統深度解析
防止根文件系統破壞,OverlayRootfs 讓你的設備更安全

華納云:VFS在提升文件系統性能方面的具體實踐
Jtti:Linux中虛擬文件系統和容器化的關系
Linux根文件系統的掛載過程
小型文件系統如何選擇?FatFs和LittleFs優缺點比較

想提高開發效率,不要忘記文件系統
如何修改buildroot和debian文件系統





 工商網監
工商網監
評論