 讓C++代碼更加高效的幾個小技巧
讓C++代碼更加高效的幾個小技巧
今天和大家介紹一下能讓C++代碼更加高效的幾個小技巧,話不多說,以下為本文目錄:
參數傳遞方式:值傳遞還是引用傳遞
函數返回方式:按值返回還是按引用返回
使用移動語義
避免創建臨時對象
了解返回值優化
考慮預分配內存
考慮內聯
迭代 vs 遞歸
選擇高效的算法
利用緩存
profiling
other碎碎念
以下為正文:
值傳遞還是引用傳遞:
一般情況下使用const的引用參數。對于函數本身會拷貝的參數,最好使用值傳遞,但只有當參數的類型支持移動語義時才這樣。
在某些情況下,值傳遞并移動實際上是向函數傳遞參數的最佳方式(注意看后面的tips),例如:
class A { public: A(const std::string &str) { str_ = str; }
private: std::string str_;};
可以考慮改為這種形式:
class A { public: A(std::string str) { str_ = std::move(str); }
private: std::string str_;};
因為無論如何都會對它們進行拷貝。
tips:看有些資料說后者值傳遞是更好的參數傳遞方式,貌似有些道理,但是我沒找到非常合理的理由,有知道的讀者可以在評論區留言。
按值返回還是按引用返回:
可以通過從函數中按引用方式返回對象,以避免對象發生不必要的復制。但有時不可能通過引用返回對象,例如編寫重載的operator+和其他類似運算符時。
永遠都不要返回指向局部對象的引用或指針,局部對象會在函數退出時被銷毀。
但是,按值返回對象通常沒啥大問題。因為一般情況下他們會觸發返回值優化或移動語義,即不會有多余的拷貝動作。
使用移動語義:
盡量確保對象擁有移動構造函數和移動賦值運算符。對象有了移動語義后,許多操作都會更加高效,特別是與標準庫和算法相結合時。
避免創建臨時對象:
沒有必要的臨時對象能避免就避免。一般來說,應該避免迫使編譯器構造臨時對象的情況。盡管有時這是不可避免的,但是至少應該意識到這項“特性”的存在,這樣才不會為實際性能和分析結果而感到驚訝。編譯器還會使用移動語義使臨時對象的效率更高。這是要在類中添加移動語義的另一個原因。
《More Effective C++》第19條款中介紹過:所謂的臨時對象并不是程序員創建的用于存儲臨時值的對象,而是指編譯器層面上的臨時對象:這種臨時對象不是由程序員創建,而是由編譯器為了實現某些功能(例如函數返回,類型轉換等)而創建。
比如下面的代碼就會有臨時對象的產生:
void Func(const std::string& s);char arr[]=“hello”;Func(aar); // here
返回值優化
通過值返回對象的函數可能導致創建一個臨時對象。看下面的代碼:
Person createPerson(){ Person newP { “Marc”, “Gregoire”, 42 }; return newP;}
假如像這樣調用這個函數(假設Person 類已經實現了operator《《運算符):
cout 《《 createPerson();
即便這個調用沒有將createPerson()的結果保存在任何地方,也必須將結果保存在某個地方,才能傳遞給operator《《。為此編譯器創建一個臨時變量,來保存createPerson()返回的Person 對象。
即使這個函數的結果沒有在任何地方使用,編譯器也仍然可能會生成創建臨時對象的代碼:
createPerson();
編譯器可能生成代碼來創建一個臨時對象來保存返回值,即使這個返回值沒有使用也是如此。
不過吧,編譯器會在大多數情況下優化掉臨時變量,以避免復制和移動。
關于返回值優化我之前有篇文章介紹過,感興趣的可以看看這個:《左值引用、右值引用、移動語義、完美轉發,你知道的不知道的都在這里》
預分配內存:
比如標準化容器中的reserve,需要頻繁創建內存的地方可以考慮預分配一塊內存出來,避免頻繁的創建內存。
內聯函數:
短函數可以使用內聯消除函數開銷。
迭代 vs 遞歸:
這里我更傾向于選擇迭代方式,而不是遞歸。遞歸占用大量棧內存,且可能會產生很多不必要的臨時對象構建。
選擇效率更高的算法:
學計算機的估計沒有不知道算法的吧,學算法估計沒有人不知道如何計算時間復雜度和空間復雜度吧,在平時開發過程中遇到算法問題時我們可盡量選擇效率更高的算法,比如O(N)和O(N2)的算法,我們肯定要選擇O(N)的呀,這里可以了解下C++的,這里引入了很多高效的算法供我們使用。
盡可能多的使用緩存:
將某些數據保存下來供下次使用,避免再次獲取或重新計算它們。如果任務或計算特別慢,應該保證不執行那些沒有必要的任務或者重復計算。
網絡通信:如果頻繁發起相同的網絡請求,可考慮將第一次的網絡請求結果保存在內存中,或文件中?
磁盤訪問:如果頻繁訪問一個文件,可考慮將這個文件的內容保存在內存中。
數學計算:某些很耗時很復雜的運算,可考慮只執行這種計算一次,然后共享結果。
對象分配:如果需要大量頻繁創建和銷毀短期對象,可考慮使用對象池。
線程創建:如果需要大量頻繁創建和銷毀線程,可考慮使用線程池。
做客戶端開發的朋友應該都聽說多級緩存的概念,就是這個原理。
profiling:
那到底什么樣的代碼才算是高質量代碼呢?
對此我整理了一份腦圖:
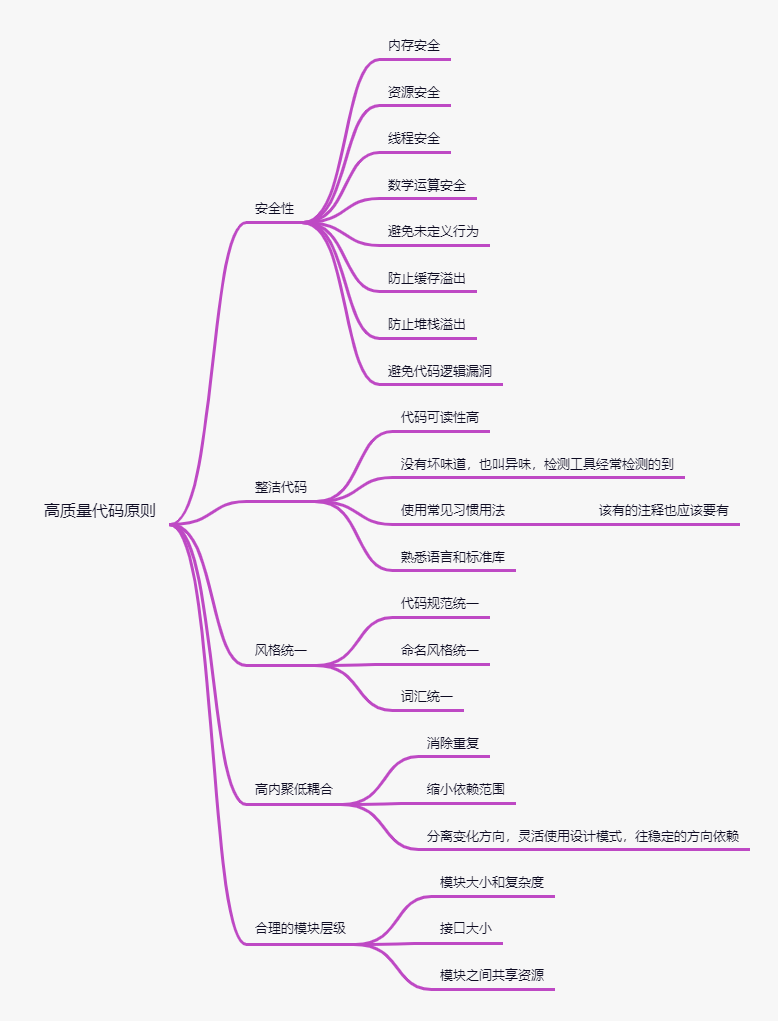
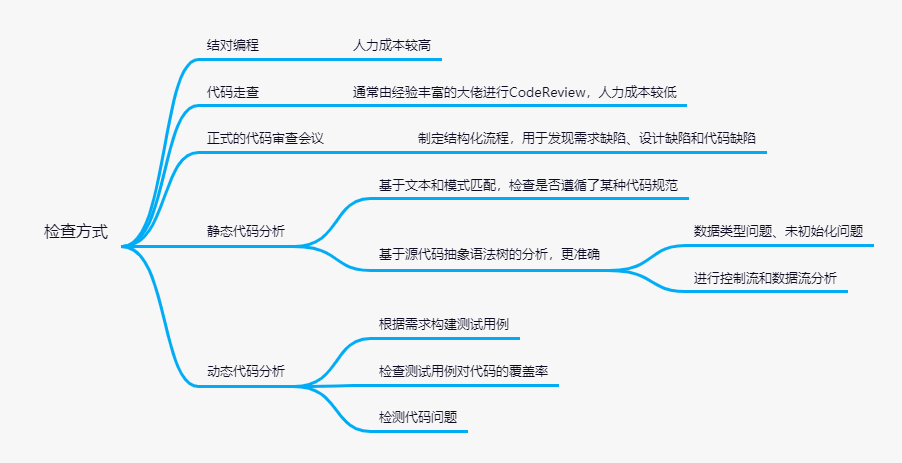
如何能夠提升代碼質量呢,除了我們自身過硬的編碼能力,還需要制定代碼檢查流程,一般代碼檢查有以下幾種方式:
代碼檢查要檢查的問題有:
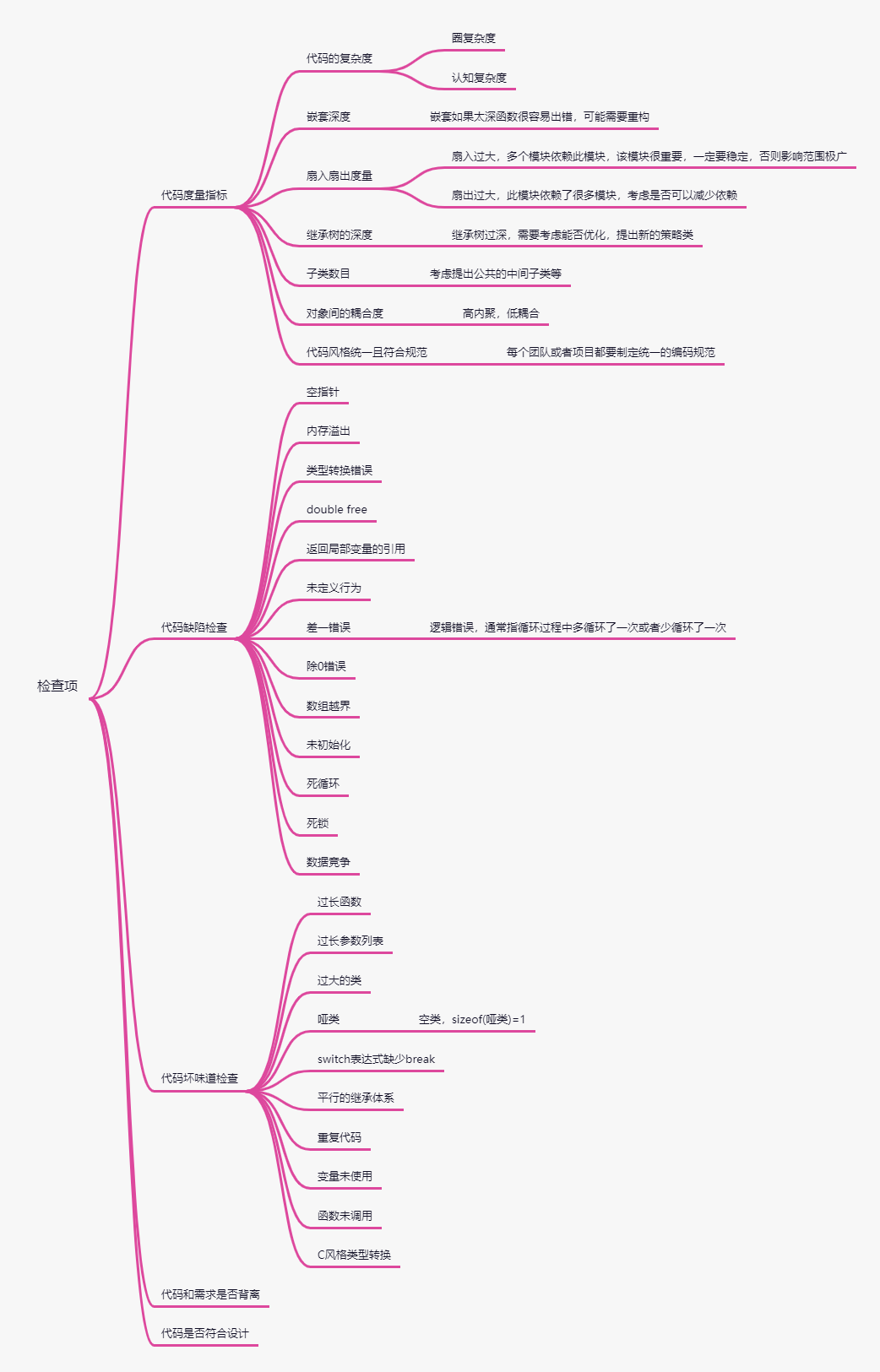
腦圖中有一些代碼度量指標,它用于量化代碼質量:
如果代碼的圈復雜度或認知復雜度過大,可能函數本身實現的過于復雜,或可能因為架構設計過于復雜,導致函數過于復雜。
如果函數嵌套過深,說明函數很可能出錯,需要仔細進???評審,并且函數可能需要重構。
如果模塊的扇入過大,說明模塊可能是公共模塊,需要??評審接?是否是穩定的,或模塊承擔過多職責,可以考慮遵循單?職責,分解模塊的職責。
如果模塊的扇出過大,說明該模塊依賴多個模塊,可以考慮把被依賴的多個模塊合并為?個模塊,重構依賴的接?。
如果類的繼承樹過深,考慮在繼承樹的深度上是否有新的變化?向,考慮提出新的策略類,或其他設計模式來優化繼承樹。
如果子類過多,檢查?類的實現中共同的地?,先考慮提出公共的中間?類,檢查是否可以通過橋接模式、裝飾模式、組合模式等結構型模式重構代碼。
上面腦圖所說的需要檢查的各種問題中,代碼和需求背離問題與代碼是否符合設計問題需要人工評審,成本較高,其它問題可以通過工具來檢測。
檢測工具主要分為靜態代碼分析工具和動態代碼檢測工具。
靜態代碼分析工具主要用于靜態代碼分析,關于靜態代碼分析,它能夠根據規則幫助檢查代碼缺陷,然而,對于檢查規則能夠覆蓋的代碼,工具能夠工作的挺好,但對于規則沒有覆蓋的代碼,它卻無能為力,而且可能存在誤報問題。
靜態代碼分析是保證代碼質量的重要手段,據說軟件開發中大概30%-70%的代碼邏輯設計和編碼缺陷都可以通過靜態代碼分析來發現和修復。它會掃描程序代碼,找出代碼中隱藏的錯誤,如參數不匹配、有歧義的嵌套語句、錯誤的遞歸、非法計算、空指針問題、越界問題、未初始化問題、內存泄漏問題等。
靜態代碼分析工具的優勢有:
自動執行靜態代碼分析,快速定位代碼隱藏錯誤和缺陷
幫助代碼設計人員更專注于分析和解決代碼設計缺陷
減少在代碼人工檢查上花費的時間,提高軟件可靠性并節省開發成本
舉例如下:
代碼規范檢查:由于拷貝粘貼造成兩個分支的代碼完全相同
void func(int in, int &out) { if (in 》 1) out++; else out++; out++;}
代碼缺陷檢查:沒有用的RAII
void func() { std::lock_guard《std::mutex》(lk); // 臨時對象,語句結束后執行析構,誤用的加鎖 。..}
下面是一些常見的靜態代碼分析工具:
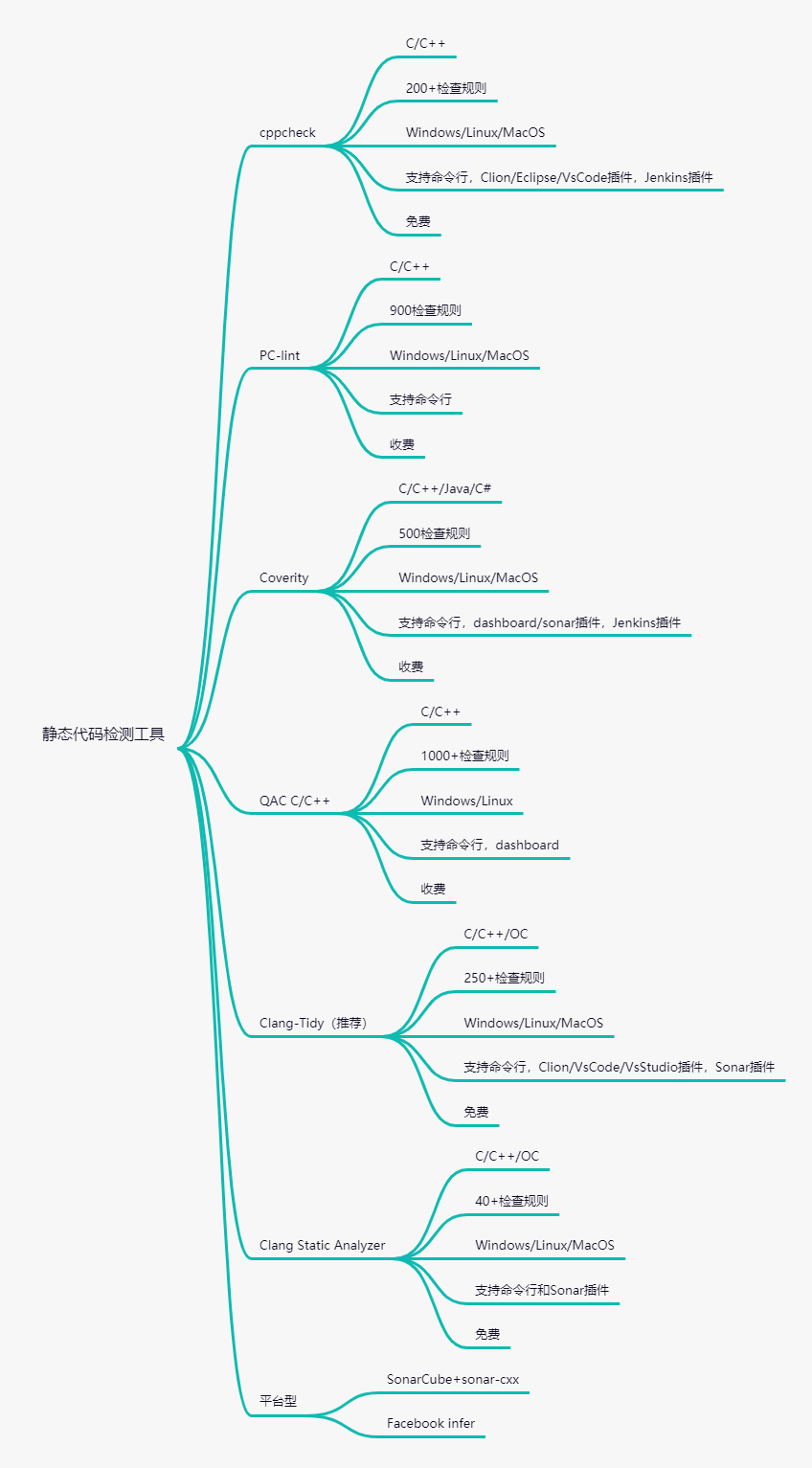
這里推薦一個常用的代碼質量管理平臺SonarCube,SonarQube是一個管理代碼質量的平臺(社區版免費),用于管理代碼的質量,它會從多個角度維護檢測代碼質量,通過插件形式支持多種語言的代碼質量管理和檢測。它可以安裝sonar-cxx插件,內置了一系列C/C++代碼檢查工具,還可以應用在CI/CD流程中,和Jenkins打通,可以在提交代碼后檢查代碼是否有壞味道,不符合規范的代碼就拒絕被合入master。
還有一個很好用的靜態代碼檢測工具是Facebook的infer,它最大的優勢是可以靜態檢測代碼內隱藏的內存泄漏問題,而且免費支持Android、C、OC語言。
靜態代碼分析工具可以在運行前幫助我們檢測缺陷,只有30%-70%,但不是所有缺陷,很多缺陷需要在運行時才會被發現。
其實我們還可以使用一些動態分析工具,通過動態分析工具可以準確定位問題,而且誤報率低,但這與測試用例強綁定,查找缺陷的比例與測試用例的覆蓋率有關,覆蓋率對于衡量代碼質量有很大意義。
代碼覆蓋率的意義:
● 幫助我們找到未覆蓋部分的代碼,分析測試用例設計的是否充分,之后視情況決定是否可以補充測試用例。
● 檢測出代碼的壞味道,提示我們修改代碼,理清代碼邏輯關系,提升代碼質量。
● 代碼覆蓋率高不能代表代碼質量一定好,但代碼覆蓋率低,代碼質量估計不會高到哪去,可以作為我們衡量代碼質量的重要手段之一。
● 對于沒有覆蓋到的錯誤,動態分析工具也無能為力。在實際工作中,我們可以動靜結合,多種檢查手段全都用上,可以更有效的提升代碼質量。
動態分析工具可以在程序運行時發現代碼的缺陷,例如內存問題、數據競爭、未定義行為等。
常用工具有GCC&Clang的Santizer系列:
● Asan-Address Sanitizer:緩存區溢出,內存泄漏
● Tsan-Thread Sanitizer:并發問題
● Msan-Memory Sanitizer:未初始化內存
● Ubsan-Undefined Behavior Sanitizer:未定義行為
● 編譯選項添加fsanitize=address/memory/thread/undefined
還有Valgrind工具:
● memchek:內存問題,包括Asan和Msan
● helgrind:線程和并發問題
● cachegrind、callgrind、massif:幫助進行性能優化
使用各種工具與單元測試、功能測試、系統測試結合,提高覆蓋率,可以幫助我們發現更多缺陷。
前面的多數都是代碼分析工具,下面介紹一些性能分析工具,關于性能分析工具Brendan Gregg大佬的網站介紹的很詳細,這里貼出來一張他總結的工具圖:
這張圖從Linux內核的各個子系統出發,匯總了對各個子系統進行性能分析時可以選擇的工具。其實還有一些好用的工具,圖里沒有提到,這里重點介紹一下:
gprof:gprof是GNU工具之一,編譯的時候,它在每個函數的出入口加入了profiling的代碼,運行時統計程序在用戶態的執行信息,可以得到每個函數的調用次數,執行時間,調用關系等信息,簡單易懂。適合于查找用戶級程序的性能瓶頸,然而對于很多耗時在內核態執行的程序,gprof不適合。
Oprofile:Oprofile也是一個開源的profiling工具,它使用硬件調試寄存器來統計信息,進行profiling的開銷比較小,而且可以對內核進行profiling。它統計的信息非常多,可以得到cache的缺失率,memory的訪存信息,分支預測錯誤率等等,這些信息gprof得不到,但是對于函數調用次數,它無能為力。
簡單來說,gprof簡單,適合于查找用戶級程序的瓶頸,而Oprofile稍微有點復雜,但是得到的信息更多,更適合調試系統軟件。
gperftools:Google出品,值得信賴,提供整個程序的熱點分布圖,找到性能瓶頸,然后可以針對性的進行性能優化,如圖:
那使用什么API效率更高呢,可以看下圖:
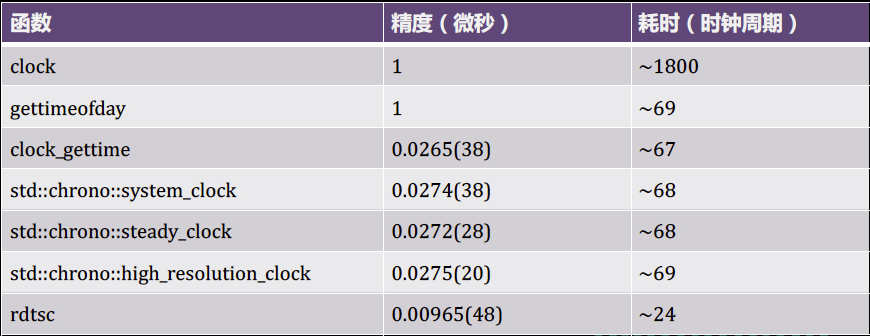
圖中的rdtsc使用較繁瑣而且不適用于所有平臺和編譯器,剩下的大家可以按需使用哈。
關于性能分析工具,程序喵整理了一份非常詳細的腦圖(精華全在腦圖里),以性能指標分類,不同指標使用什么工具進行分析,都在圖里,目錄如下:
other碎碎念:
選擇合適的數據結構:
選擇合適的STL,想清楚什么時候用棧,什么時候用隊列,什么時候用數組,什么時候用鏈表。
某些if-else可改為switch,效率可能更高(知道為什么嗎,不知道的可以留言,人多的話考慮輸出一篇文章)。
優先考慮棧內存,而不是堆內存(免得頻繁的申請釋放內存)。
如何函數不需要返回值,就不要設置返回值。
使用位操作,移位代替乘法除法操作。
構造函數時使用初始化方式,而不是賦值。
A::A() : a_(a) {} // better
A::A() { a_ = a;}
明確使用模板帶來的益處:
如果使用模板并沒有給你的開發帶來任何益處,是不是可以考慮不使用它,因為調試起來真的麻煩。
函數參數的個數不要太多。
擅用emplace,有些情況下會省去一次構造的開銷。
最后想說一句:
先完成再完美。不要一開始就想著寫最完美的代碼,很多bug都是過早過度優化導致的。一般情況下,性能較高的代碼可讀性都不是特別高。提早優化很可能引發很多bug。很多情況下,我們可以先完成代碼,確保功能完成且正確之后,再去考慮完善。完成代碼后,可以使用profiling工具,找到瓶頸所在,然后做相應優化。另外產品和測試如果沒給你提性能需求,那優化它干嘛!
責任編輯:haq
-
C++
+關注
關注
22文章
2117瀏覽量
74769 -
代碼
+關注
關注
30文章
4886瀏覽量
70237
原文標題:看完這12條,寫出高效代碼
文章出處:【微信號:gh_c472c2199c88,微信公眾號:嵌入式微處理器】歡迎添加關注!文章轉載請注明出處。
發布評論請先 登錄
創建了用于OpenVINO?推理的自定義C++和Python代碼,從C++代碼中獲得的結果與Python代碼不同是為什么?
源代碼加密、源代碼防泄漏c/c++與git服務器開發環境

Spire.XLS for C++組件說明
AKI跨語言調用庫神助攻C/C++代碼遷移至HarmonyOS NEXT
Flexus X 實例 C#/.Net Core 結合(git 代碼管理、docker 自定義鏡像)快速發布部署 - 讓你的項目飛起來~

讓單片機代碼性能起飛的七大技巧

使用OpenVINO GenAI API在C++中構建AI應用程序
技術干貨驛站 ▏深入理解C語言:掌握常量,讓你的代碼更加穩固高效!

ModusToolbox 3.2在c代碼中包含c++代碼的正確步驟是什么?
C++中實現類似instanceof的方法






 工商網監
工商網監
評論